
ملف robots.txt: ما هو وكيفية إنشائه (الدليل الكامل)
نشرت: 2023-05-05إذا كنت تمتلك موقعًا على الويب أو تدير محتواه ، فمن المحتمل أنك سمعت عن ملف robots.txt. إنه ملف يوجه روبوتات محركات البحث حول كيفية الزحف إلى صفحات موقع الويب الخاص بك وفهرستها. على الرغم من أهميته في تحسين محركات البحث (SEO) ، يتجاهل العديد من مالكي مواقع الويب أهمية ملف robots.txt المصمم جيدًا.
في هذا الدليل الكامل ، سوف نستكشف ماهية ملف robots.txt ، وسبب أهميته بالنسبة إلى مُحسّنات محرّكات البحث وكيفية إنشاء ملف robots.txt لموقعك على الويب.
ما هو ملف Robots.txt؟
ملف robots.txt هو ملف يخبر روبوتات محرك البحث (المعروفة أيضًا باسم برامج الزحف أو العناكب) بالصفحات أو الأقسام من موقع الويب التي يجب الزحف إليها أم لا. إنه ملف نصي عادي موجود في الدليل الجذر لموقع ويب ، ويتضمن عادةً قائمة بالأدلة أو الملفات أو عناوين URL التي يريد مشرف الموقع منعها من فهرسة محرك البحث أو الزحف إليه.
هذا شكل ملف robots.txt:

لماذا يعتبر ملف robots.txt مهمًا؟
هناك ثلاثة أسباب رئيسية وراء أهمية ملف robots.txt لموقعك على الويب:
1. تعظيم ميزانية الزحف
تشير "ميزانية الزحف" إلى عدد الصفحات التي سيزحف إليها محرك بحث Google على موقعك في أي وقت. يعتمد العدد على حجم الروابط الخلفية على موقعك وصحتها وكميتها.
تعتبر ميزانية الزحف مهمة لأنه إذا تجاوز عدد الصفحات على موقعك ميزانية الزحف ، فستكون لديك صفحات غير مفهرسة.
علاوة على ذلك ، الصفحات التي لم تتم فهرستها لن يتم تصنيفها لأي شيء.
باستخدام ملف robots.txt لحظر الصفحات غير المفيدة ، قد ينفق Googlebot (زاحف الويب الخاص بـ Google) قدرًا أكبر من ميزانية الزحف على الصفحات المهمة.
2. حظر الصفحات غير العامة
لديك العديد من الصفحات على موقعك التي لا تريد فهرستها.
على سبيل المثال ، قد يكون لديك صفحة نتائج بحث داخلية أو صفحة تسجيل دخول. يجب أن تكون هذه الصفحات موجودة. ومع ذلك ، فأنت لا تريد أن يهبط عليها أشخاص عشوائيون.
في هذه الحالة ، يمكنك استخدام ملف robots.txt لمنع برامج الزحف وبرامج الروبوت لمحركات البحث من الوصول إلى صفحات معينة.
3. منع فهرسة الموارد
قد ترغب في بعض الأحيان في استبعاد Google لموارد مثل ملفات PDF ومقاطع الفيديو والصور من نتائج البحث.
ربما تريد الاحتفاظ بهذه الموارد خاصة ، أو تريد أن تركز Google أكثر على المحتوى المهم.
في مثل هذه الحالات ، يعد استخدام ملف robots.txt هو أفضل طريقة لمنع فهرستها.
كيف يعمل ملف Robots.txt؟
ترشد ملفات Robots.txt روبوتات محرك البحث إلى صفحات أو أدلة موقع الويب التي ينبغي أو لا ينبغي الزحف إليها أو فهرستها.
أثناء الزحف ، تعثر روبوتات محركات البحث على الروابط وتتبعها. تقودهم هذه العملية من الموقع X إلى الموقع Y إلى الموقع Z عبر مليارات الروابط والمواقع الإلكترونية.
عندما يزور الروبوت أحد المواقع ، فإن أول شيء يفعله هو البحث عن ملف robots.txt.
إذا اكتشف أحدها ، فسيقرأ الملف قبل القيام بأي شيء آخر.
على سبيل المثال ، لنفترض أنك تريد السماح لجميع برامج الروبوت باستثناء DuckDuckGo بالزحف إلى موقعك:
User-agent: DuckDuckBot Disallow: /
ملاحظة: يمكن لملف robots.txt تقديم التعليمات فقط ؛ لا تستطيع فرضها. إنه مشابه لقواعد السلوك. ستتبع الروبوتات الجيدة (مثل روبوتات محرك البحث) القواعد ، بينما ستتجاهلها الروبوتات السيئة (مثل روبوتات البريد العشوائي).
كيفية البحث عن ملف Robots.txt؟
يتم استضافة ملف robots.txt ، مثل أي ملف آخر على موقع الويب الخاص بك ، على الخادم الخاص بك.
يمكنك الوصول إلى ملف robots.txt لأي موقع ويب عن طريق إدخال عنوان URL الكامل للصفحة الرئيسية ثم إضافة /robots.txt في النهاية ، مثل https://pickupwp.com/robots.txt.
ومع ذلك ، إذا لم يكن موقع الويب يحتوي على ملف robots.txt ، فستتلقى رسالة خطأ "404 غير موجود".
كيفية إنشاء ملف Robots.txt؟
قبل توضيح كيفية إنشاء ملف robots.txt ، دعنا نلقي نظرة أولاً على بنية ملف robots.txt.
يمكن تقسيم بنية ملف robots.txt إلى المكونات التالية:
- وكيل المستخدم: يحدد هذا الروبوت أو الزاحف الذي ينطبق عليه السجل. على سبيل المثال ، ينطبق "User-agent: Googlebot" فقط على زاحف بحث Google ، بينما ينطبق "User-agent: *" على جميع برامج الزحف.
- Disallow: يحدد هذا الصفحات أو الأدلة التي يجب على الروبوت عدم الزحف إليها. على سبيل المثال ، يمنع "Disallow: / private /" برامج الروبوت من الزحف إلى أي صفحات داخل الدليل "الخاص".
- سماح: يحدد هذا الصفحات أو الأدلة التي يجب السماح للروبوت بالزحف إليها ، حتى إذا كان الدليل الرئيسي غير مسموح به. على سبيل المثال ، يسمح "Allow: / public /" لبرامج الروبوت بالزحف إلى أي صفحات داخل الدليل "العام" ، حتى إذا كان الدليل الرئيسي غير مسموح به.
- تأخير الزحف: يحدد هذا مقدار الوقت بالثواني الذي يجب أن ينتظره الروبوت قبل الزحف إلى موقع الويب. على سبيل المثال ، "تأجيل الزحف: 10" يوجه الروبوت إلى الانتظار لمدة 10 ثوانٍ قبل الزحف إلى موقع الويب.
- خريطة الموقع: تحدد موقع خريطة موقع الويب. على سبيل المثال ، يُعلم "ملف Sitemap: https://www.example.com/sitemap.xml" الروبوت بموقع ملف Sitemap لموقع الويب.
فيما يلي مثال على ملف robots.txt:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
ملاحظة: من المهم ملاحظة أن ملفات robots.txt حساسة لحالة الأحرف ، لذلك من المهم استخدام الحالة الصحيحة عند تحديد عناوين URL.
على سبيل المثال ، / public / ليست هي نفسها / Public /.
من ناحية أخرى ، فإن التوجيهات مثل "Allow" و "Disallow" ليست حساسة لحالة الأحرف ، لذا فالأمر متروك لك لتكبيرها أم لا.
بعد التعرف على بنية ملف robots.txt ، يمكنك إنشاء ملف robots.txt باستخدام أداة إنشاء ملف robots.txt أو إنشاء ملف بنفسك.
إليك كيفية إنشاء ملف robots.txt في أربع خطوات فقط:
1. قم بإنشاء ملف جديد وقم بتسميته Robots.txt
ما عليك سوى فتح مستند .txt باستخدام أي محرر نصوص أو مستعرض ويب.
بعد ذلك ، قم بتسمية المستند باسم robots.txt. للعمل ، يجب تسمية ملف robots.txt.
بمجرد الانتهاء ، يمكنك الآن البدء في كتابة التوجيهات.
2. أضف توجيهات إلى ملف Robots.txt
يحتوي ملف robots.txt على مجموعة أو أكثر من الأوامر ، كل منها يحتوي على عدة أسطر من التعليمات.
تبدأ كل مجموعة بـ "وكيل مستخدم" وتحتوي على البيانات التالية:
- من تنطبق عليه المجموعة (وكيل المستخدم)
- ما الدلائل (الصفحات) أو الملفات التي يمكن للوكيل الوصول إليها؟
- ما الدلائل (الصفحات) أو الملفات التي لا يمكن للوكيل الوصول إليها؟
- خريطة موقع (اختياري) لإعلام محركات البحث بالمواقع والملفات التي تعتقد أنها مهمة.
تتجاهل برامج الزحف الأسطر التي لا تتطابق مع أي من هذه الأوامر.
على سبيل المثال ، تريد منع Google من الزحف إلى دليلك / الخاص /.

انها تبدو مثل هذا:
User-agent: Googlebot Disallow: /private/
إذا كان لديك المزيد من الإرشادات مثل هذه لـ Google ، فستضعها في سطر منفصل أدناه مباشرةً على النحو التالي:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
علاوة على ذلك ، إذا انتهيت من إرشادات Google المحددة وتريد إنشاء مجموعة جديدة من التوجيهات.
على سبيل المثال ، إذا أردت منع جميع محركات البحث من الزحف إلى الدلائل / archive / و / support /.
انها تبدو مثل هذا:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
عند الانتهاء ، يمكنك إضافة خريطة الموقع الخاصة بك.
يجب أن يبدو ملف robots.txt المكتمل كما يلي:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
بعد ذلك ، احفظ ملف robots.txt الخاص بك. تذكر أنه يجب تسمية ملف robots.txt.
لمزيد من قواعد robots.txt المفيدة ، راجع هذا الدليل المفيد من Google.
3. قم بتحميل ملف Robots.txt
بعد حفظ ملف robots.txt على جهاز الكمبيوتر الخاص بك ، قم بتحميله على موقع الويب الخاص بك واجعله متاحًا لمحركات البحث للزحف إليه.
لسوء الحظ ، لا توجد أداة يمكن أن تساعد في هذه الخطوة.
يعتمد تحميل ملف robots.txt على بنية ملف موقعك واستضافة الويب.
للحصول على إرشادات حول كيفية تحميل ملف robots.txt الخاص بك ، ابحث عبر الإنترنت أو اتصل بمزود الاستضافة.
4. اختبر ملف robots.txt الخاص بك
بعد تحميل ملف robots.txt ، يمكنك بعد ذلك التحقق مما إذا كان بإمكان أي شخص رؤيته وما إذا كان بإمكان Google قراءته.
ما عليك سوى فتح علامة تبويب جديدة في متصفحك والبحث عن ملف robots.txt الخاص بك.
على سبيل المثال ، https://pickupwp.com/robots.txt.
إذا رأيت ملف robots.txt ، فأنت جاهز لاختبار الترميز (كود HTML).
لهذا ، يمكنك استخدام Google robots.txt Tester.
ملاحظة: لديك حساب Search Console تم إعداده لاختبار ملف robots.txt باستخدام أداة اختبار robots.txt.
سيجد مُختبِر ملف robots.txt أي تحذيرات في بناء الجملة أو أخطاء منطقية ويقوم بتمييزها.
بالإضافة إلى ذلك ، فإنه يعرض لك أيضًا التحذيرات والأخطاء الموجودة أسفل المحرر.
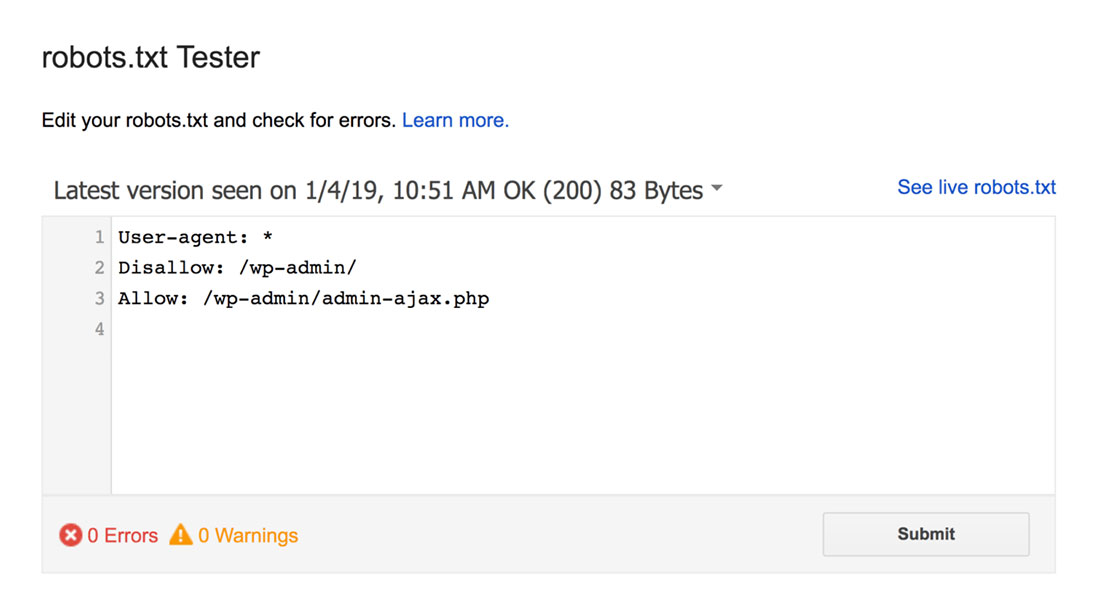
يمكنك تعديل الأخطاء أو التحذيرات على الصفحة وإعادة الاختبار كلما لزم الأمر.
فقط ضع في اعتبارك أن التغييرات التي تم إجراؤها على الصفحة لا يتم حفظها في موقعك.
لإجراء أي تغييرات ، انسخ هذا والصقه في ملف robots.txt الخاص بموقعك.
أفضل ممارسات Robots.txt
ضع في اعتبارك أفضل الممارسات هذه أثناء إنشاء ملف robots.txt لتجنب بعض الأخطاء الشائعة.
1. استخدم أسطرًا جديدة لكل توجيه
لمنع حدوث ارتباك لبرامج زحف محركات البحث ، أضف كل توجيه إلى سطر جديد في ملف robots.txt. ينطبق هذا على كل من قواعد "السماح" و "عدم السماح".
على سبيل المثال ، إذا كنت لا تريد أن يقوم زاحف الويب بالزحف إلى مدونتك أو صفحة الاتصال الخاصة بك ، فأضف القواعد التالية:
Disallow: /blog/ Disallow: /contact/
2. استخدم كل وكيل مستخدم مرة واحدة فقط
لا تواجه برامج الروبوت أي مشكلة إذا كنت تستخدم نفس وكيل المستخدم مرارًا وتكرارًا.
ومع ذلك ، فإن استخدامه مرة واحدة فقط يحافظ على تنظيم الأشياء ويقلل من فرصة حدوث خطأ بشري.
3. استخدم أحرف البدل لتبسيط التعليمات
إذا كان لديك عدد كبير من الصفحات لمنعها ، فقد تستغرق إضافة قاعدة لكل منها وقتًا طويلاً. لحسن الحظ ، يمكنك استخدام أحرف البدل لتبسيط تعليماتك.
حرف البدل هو حرف يمكن أن يمثل حرفًا واحدًا أو أكثر. أكثر أحرف البدل شيوعًا هي العلامة النجمية (*).
على سبيل المثال ، إذا كنت تريد حظر جميع الملفات التي تنتهي بـ .jpg ، فيمكنك إضافة القاعدة التالية:
Disallow: /*.jpg
4. استخدم “$” لتحديد نهاية عنوان URL
علامة الدولار ($) هي حرف بدل آخر يمكن استخدامه لتحديد نهاية عنوان URL. هذا مفيد إذا كنت تريد تقييد صفحة معينة ولكن ليس الصفحات التي تليها.
لنفترض أنك تريد حظر صفحة جهة الاتصال وليس صفحة نجاح الاتصال ، يمكنك إضافة القاعدة التالية:
Disallow: /contact$
5. استخدم الهاش (#) لإضافة التعليقات
تتجاهل برامج الزحف كل ما يبدأ بعلامة التجزئة (#).
نتيجة لذلك ، غالبًا ما يستخدم المطورون التجزئة لإضافة تعليقات إلى ملف robots.txt. يحافظ على الوثيقة منظمة وقابلة للقراءة.
على سبيل المثال ، إذا كنت تريد منع جميع الملفات التي تنتهي بـ jpg ، فيمكنك إضافة التعليق التالي:
# Block all files that end in .jpg Disallow: /*.jpg
يساعد هذا أي شخص في فهم الغرض من القاعدة وسبب وجودها.
6. استخدم ملفات Robots.txt منفصلة لكل مجال فرعي
إذا كان لديك موقع ويب يحتوي على عدة نطاقات فرعية ، فمن المستحسن إنشاء ملف robots.txt فردي لكل منها. هذا يحافظ على الأشياء منظمة ويساعد برامج الزحف لمحركات البحث على فهم القواعد الخاصة بك بسهولة أكبر.
تغليف!
يعد ملف robots.txt أداة مفيدة لتحسين محركات البحث لأنه يوجه روبوتات محرك البحث إلى ما يجب فهرسته وما لا يجب.
ومع ذلك ، من المهم استخدامه بحذر. نظرًا لأن التهيئة الخاطئة يمكن أن تؤدي إلى إلغاء فهرسة كامل لموقع الويب الخاص بك (على سبيل المثال ، استخدام Disallow: /).
بشكل عام ، تتمثل الطريقة الجيدة في السماح لمحركات البحث بمسح أكبر قدر ممكن من موقعك مع الاحتفاظ بالمعلومات الحساسة وتجنب المحتوى المكرر. على سبيل المثال ، يمكنك استخدام التوجيه Disallow لمنع صفحات أو أدلة معينة أو التوجيه Allow لتجاوز قاعدة Disallow لصفحة معينة.
تجدر الإشارة أيضًا إلى أنه لا تتبع جميع برامج الروبوت القواعد المنصوص عليها في ملف robots.txt ، لذا فهي ليست طريقة مثالية للتحكم في ما يتم فهرسته. لكنها لا تزال أداة قيمة في إستراتيجية تحسين محركات البحث الخاصة بك.
نأمل أن يساعدك هذا الدليل في التعرف على ملف robots.txt وكيفية إنشائه.
لمزيد من المعلومات ، يمكنك الاطلاع على هذه الموارد المفيدة الأخرى:
- 15 نصيحة تدوين قابلة للتنفيذ للمدونين الجدد
- إطلاق العنان لقوة الكلمات الرئيسية طويلة الذيل (دليل المبتدئين)
أخيرًا ، تابعنا على Twitter للحصول على تحديثات منتظمة حول المقالات الجديدة.