
ملف WordPress robots.txt ... ما هو وماذا يفعل
نشرت: 2020-11-25هل تساءلت يومًا عن ملف robots.txt وماذا يفعل؟ يتم استخدام ملف robots.txt للتواصل مع برامج زحف الويب (المعروفة باسم برامج الروبوت) التي تستخدمها Google ومحركات البحث الأخرى. يخبرهم أي أجزاء من موقع الويب الخاص بك يجب فهرستها وأي أجزاء يجب تجاهلها. على هذا النحو ، يمكن أن يساعد ملف robots.txt في بذل جهود تحسين محركات البحث (أو ربما كسرها!). إذا كنت تريد ترتيب موقع الويب الخاص بك جيدًا ، فمن الضروري فهم ملف robots.txt جيدًا!
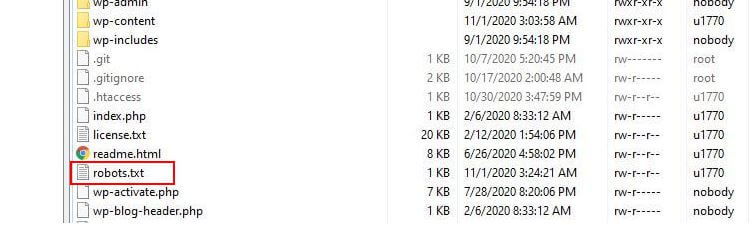
أين يقع ملف robots.txt؟
عادةً ما يقوم WordPress بتشغيل ما يسمى بملف robots.txt "الظاهري" مما يعني أنه لا يمكن الوصول إليه عبر SFTP. ومع ذلك ، يمكنك عرض محتوياتها الأساسية بالانتقال إلى yourdomain.com/robots.txt. من المحتمل أن ترى شيئًا كهذا:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpيحدد السطر الأول الروبوتات التي سيتم تطبيق القواعد عليها. في مثالنا ، تعني علامة النجمة أنه سيتم تطبيق القواعد على جميع برامج الروبوت (مثل تلك من Google و Bing وما إلى ذلك).
يحدد السطر الثاني قاعدة تمنع وصول الروبوتات إلى مجلد / wp-admin ، بينما ينص السطر الثالث على أنه يُسمح للروبوتات بتحليل ملف /wp-admin/admin-ajax.php.
أضف القواعد الخاصة بك
بالنسبة إلى موقع ويب WordPress بسيط ، قد تكون القواعد الافتراضية التي يطبقها WordPress على ملف robots.txt أكثر من كافية. ومع ذلك ، إذا كنت تريد مزيدًا من التحكم والقدرة على إضافة القواعد الخاصة بك من أجل تقديم إرشادات أكثر تحديدًا لروبوتات محرك البحث حول كيفية فهرسة موقع الويب الخاص بك ، فستحتاج إلى إنشاء ملف robots.txt المادي الخاص بك ووضعه تحت الجذر دليل التثبيت الخاص بك.
هناك عدة أسباب قد ترغب في إعادة تكوين ملف robots.txt الخاص بك وتحديد ما الذي سيسمح لهذه الروبوتات بالزحف إليه بالضبط. أحد الأسباب الرئيسية هو الوقت الذي يقضيه الروبوت في الزحف إلى موقعك. لا تسمح Google (وغيرها) للروبوتات بقضاء وقت غير محدود على كل موقع ويب ... مع تريليونات من الصفحات ، يتعين عليهم اتباع نهج أكثر دقة لما ستزحف إليه برامج الروبوت الخاصة بهم وما ستتجاهله في محاولة لاستخراج المعلومات الأكثر فائدة عن موقع على شبكة الإنترنت.

استضافة موقع الويب الخاص بك مع Pressidium
ضمان استرداد الأموال لمدة 60 يومًا
عندما تسمح للروبوتات بالزحف إلى جميع الصفحات على موقع الويب الخاص بك ، يتم إنفاق جزء من وقت الزحف على الصفحات غير المهمة أو حتى ذات الصلة. هذا يترك لهم وقتًا أقل لشق طريقهم عبر المناطق الأكثر صلة بموقعك. من خلال عدم السماح بوصول برنامج الروبوت إلى بعض أجزاء موقع الويب الخاص بك ، فإنك تزيد من الوقت المتاح للروبوتات لاستخراج المعلومات من الأجزاء الأكثر صلة بموقعك (والتي نأمل أن تنتهي بالفهرسة). نظرًا لأن الزحف أسرع ، فمن المرجح أن يزور محرك بحث Google موقع الويب الخاص بك مرة أخرى ويحافظ على فهرس موقعك محدثًا. هذا يعني أنه من المحتمل أن تتم فهرسة منشورات المدونات الجديدة والمحتويات الجديدة الأخرى بشكل أسرع ، وهذا أمر جيد.
أمثلة على تحرير Robots.txt
يوفر ملف robots.txt مساحة كبيرة للتخصيص. على هذا النحو ، قدمنا مجموعة من الأمثلة للقواعد التي يمكن استخدامها لإملاء كيفية قيام الروبوتات بفهرسة موقعك.
السماح أو عدم السماح بالروبوتات
أولاً ، دعنا نلقي نظرة على كيفية تقييد روبوت معين. للقيام بذلك ، كل ما نحتاج إلى القيام به هو استبدال العلامة النجمية (*) باسم وكيل مستخدم الروبوت الذي نريد حظره ، على سبيل المثال "MSNBot". تتوفر قائمة شاملة بوكلاء المستخدم المعروفين هنا.
User-agent: MSNBot Disallow: /سيؤدي وضع شرطة في السطر الثاني إلى تقييد وصول الروبوت إلى جميع الأدلة.
للسماح لروبوت واحد فقط بالزحف إلى موقعنا ، سنستخدم عملية من خطوتين. أولاً ، قمنا بتعيين هذا الروبوت كاستثناء ثم رفض جميع الروبوتات مثل هذا:
User-agent: Google Disallow: User-agent: * Disallow: /للسماح بالوصول إلى جميع برامج الروبوت على كل المحتوى ، نضيف هذين السطرين:
User-agent: * Disallow:يمكن تحقيق نفس التأثير بمجرد إنشاء ملف robots.txt ثم تركه فارغًا.
منع الوصول إلى ملفات معينة
هل تريد إيقاف برامج الروبوت عن فهرسة ملفات معينة على موقع الويب الخاص بك؟ هذا سهل! في المثال أدناه ، منعنا محركات البحث من الوصول إلى جميع ملفات .pdf على موقعنا.
User-agent: * Disallow: /*.pdf$يُستخدم الرمز "$" لتحديد نهاية عنوان URL. نظرًا لأن هذا حساس لحالة الأحرف ، فسيستمر الزحف إلى ملف باسم my.PDF (لاحظ الأحرف الكبيرة).
التعبيرات المنطقية المعقدة
تفهم بعض محركات البحث ، مثل Google ، استخدام التعبيرات العادية الأكثر تعقيدًا. من المهم ملاحظة أنه قد لا تتمكن جميع محركات البحث من فهم التعبيرات المنطقية في ملف robots.txt.

أحد الأمثلة على ذلك هو استخدام الرمز $. يشير هذا الرمز في ملفات robots.txt إلى نهاية عنوان url. لذلك ، في المثال التالي ، منعنا روبوتات البحث من قراءة وفهرسة الملفات التي تنتهي بـ .php
Disallow: /*.php$هذا يعني أنه لا يمكن فهرسة /index.php ، لكن /index.php؟p=1 يمكن أن يكون. هذا مفيد فقط في ظروف محددة للغاية ويجب استخدامه بحذر وإلا فإنك تخاطر بحظر وصول الروبوت إلى الملفات التي لم تقصدها!
يمكنك أيضًا تعيين قواعد مختلفة لكل روبوت من خلال تحديد القواعد التي تنطبق عليهم بشكل فردي. سيقيد رمز المثال أدناه الوصول إلى مجلد wp-admin لجميع برامج الروبوت بينما يمنع في نفس الوقت الوصول إلى الموقع بالكامل لمحرك بحث Bing. قد لا ترغب في القيام بذلك بالضرورة ، ولكنه عرض مفيد لمدى مرونة القواعد في ملف robots.txt.
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /خرائط مواقع XML
تساعد خرائط مواقع XML حقًا في روبوتات البحث في فهم تخطيط موقع الويب الخاص بك. ولكن لكي يكون الروبوت مفيدًا ، يحتاج إلى معرفة مكان ملف Sitemap. يتم استخدام "توجيه خريطة الموقع" لإخبار محركات البحث على وجه التحديد بأن أ) خريطة موقع لموقعك موجودة و ب) أين يمكنهم العثور عليها.
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:يمكنك أيضًا تحديد مواقع متعددة لخريطة الموقع:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* Disallowتأخيرات زحف الروبوت
هناك وظيفة أخرى يمكن تحقيقها من خلال ملف robots.txt وهي إخبار الروبوتات "بإبطاء" زحفها إلى موقعك. قد يكون هذا ضروريًا إذا وجدت أن خادمك مثقل بمستويات عالية من حركة مرور الروبوت. للقيام بذلك ، عليك تحديد وكيل المستخدم الذي تريد إبطائه ثم إضافة تأخير.
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10علامات الاقتباس (10) في هذا المثال هي التأخير الذي تريد حدوثه بين الزحف إلى صفحات فردية على موقعك. لذلك ، في المثال أعلاه ، طلبنا من Bing Bot التوقف مؤقتًا لمدة عشر ثوانٍ بين كل صفحة يزحف إليها ، وبذلك يمنح خادمنا مساحة للتنفس.
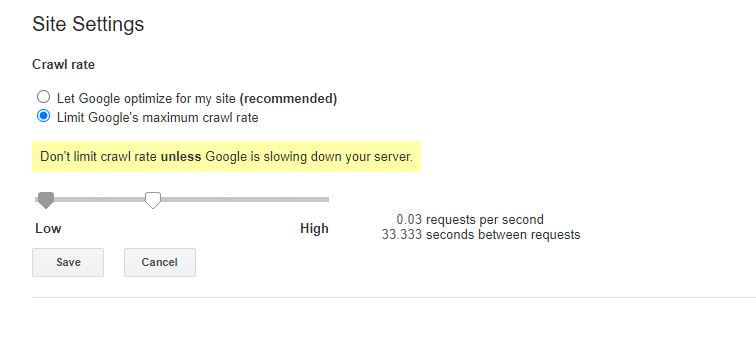
الأخبار السيئة قليلاً حول قاعدة robots.txt هي أن روبوت Google لا يحترمها. ومع ذلك ، يمكنك توجيه برامج الروبوت الخاصة بهم إلى الإبطاء من داخل Google Search Console.
ملاحظات حول قواعد ملف robots.txt:
- جميع قواعد ملف robots.txt حساسة لحالة الأحرف. اكتب بعناية!
- تأكد من عدم وجود مسافات قبل الأمر في بداية السطر.
- يمكن أن تستغرق التغييرات التي تم إجراؤها في ملف robots.txt من 24 إلى 36 ساعة لتقوم برامج الروبوت بتدوينها.
كيفية اختبار وإرسال ملف robots.txt في WordPress الخاص بك
عند إنشاء ملف robots.txt جديد ، يجدر التحقق من عدم وجود أخطاء فيه. يمكنك القيام بذلك باستخدام Google Search Console.
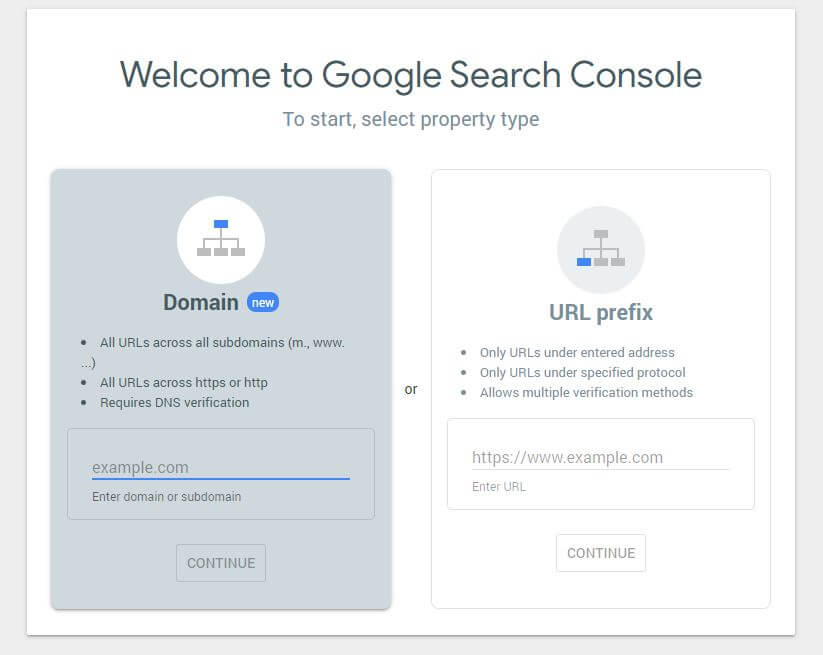
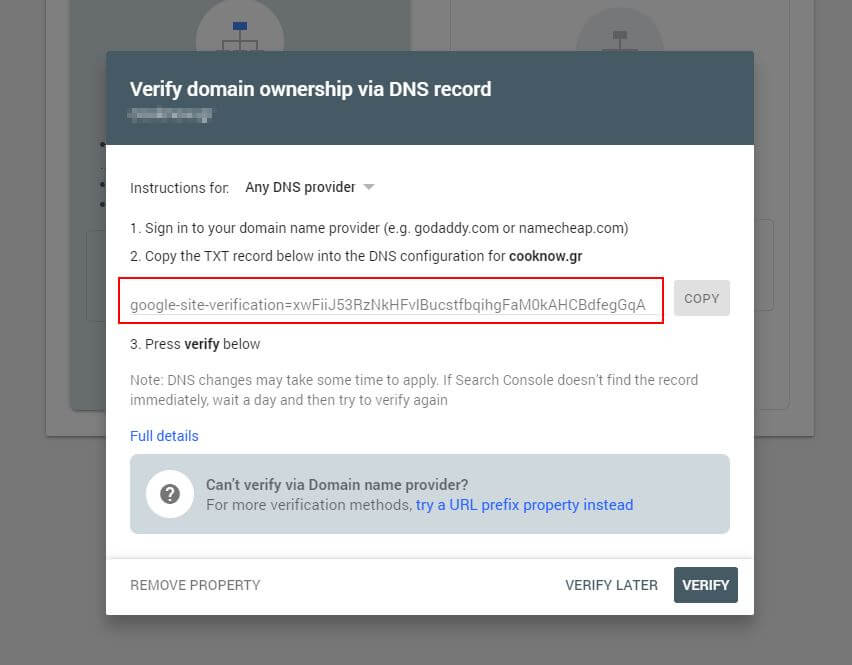
أولاً ، سيتعين عليك إرسال المجال الخاص بك (إذا لم يكن لديك بالفعل حساب Search Console لإعداد موقع الويب الخاص بك). ستزودك Google بسجل TXT الذي يجب إضافته إلى DNS الخاص بك من أجل التحقق من نطاقك.
بمجرد نشر تحديث DNS هذا (الشعور بفارغ الصبر ... حاول استخدام Cloudflare لإدارة DNS الخاص بك) ، يمكنك زيارة أداة اختبار ملف robots.txt والتحقق مما إذا كانت هناك أية تحذيرات حول محتويات ملف robots.txt الخاص بك.
شيء آخر يمكنك القيام به لاختبار القواعد التي لديك هو التأثير المطلوب وهو استخدام أداة اختبار robots.txt مثل Ryte.
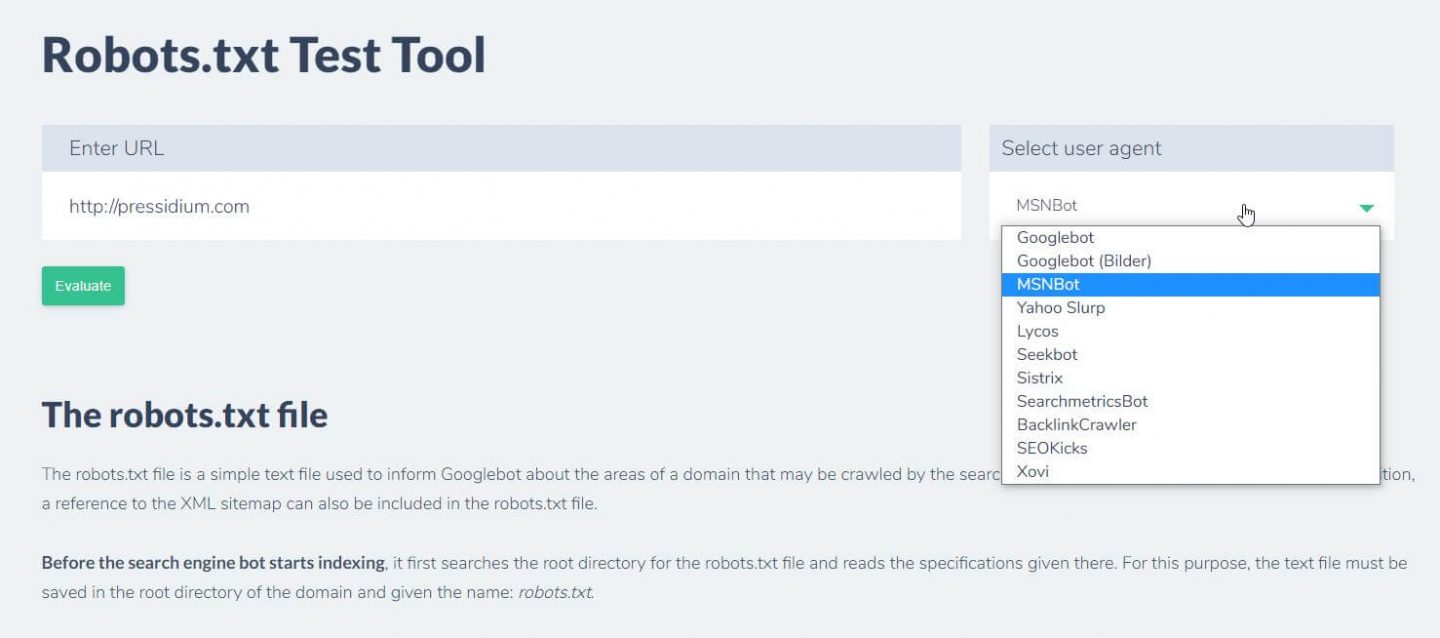
ما عليك سوى إدخال المجال الخاص بك واختيار وكيل مستخدم من اللوحة الموجودة على اليمين. بعد إرسال هذا سترى النتائج الخاصة بك.
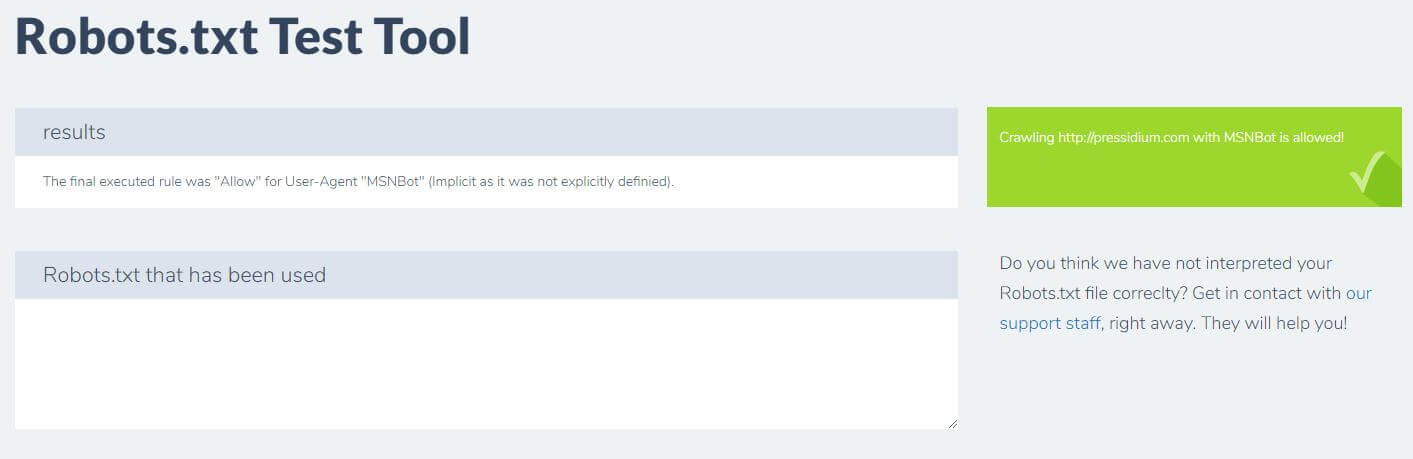
استنتاج
تعد معرفة كيفية استخدام ملف robots.txt أداة مفيدة أخرى في مجموعة أدوات المطور لديك. إذا كان الشيء الوحيد الذي تستبعده من هذا البرنامج التعليمي هو القدرة على التحقق من أن ملف robots.txt الخاص بك لا يحظر برامج الروبوت مثل Google (وهو أمر من غير المرجح أن ترغب في القيام به) ، فهذا ليس بالأمر السيئ! وبالمثل ، كما ترى ، يوفر ملف robots.txt مجموعة كاملة من التحكم الدقيق الإضافي في موقع الويب الخاص بك والذي قد يكون مفيدًا في يوم من الأيام.