
Crawler-Liste: Web-Crawler-Bots und wie man sie für den Erfolg nutzt
Veröffentlicht: 2022-12-03Für die meisten Vermarkter sind ständige Updates erforderlich, um ihre Website auf dem neuesten Stand zu halten und ihre SEO-Rankings zu verbessern.
Einige Websites haben jedoch Hunderte oder sogar Tausende von Seiten, was es zu einer Herausforderung für Teams macht, die die Updates manuell an Suchmaschinen weitergeben. Wenn die Inhalte so häufig aktualisiert werden, wie können Teams sicherstellen, dass sich diese Verbesserungen auf ihre SEO-Rankings auswirken?
Hier kommen Crawler-Bots ins Spiel. Ein Web-Crawler-Bot durchsucht Ihre Sitemap nach neuen Updates und indiziert den Inhalt in Suchmaschinen.
In diesem Beitrag skizzieren wir eine umfassende Crawler-Liste, die alle Webcrawler-Bots abdeckt, die Sie kennen müssen. Bevor wir eintauchen, wollen wir Webcrawler-Bots definieren und zeigen, wie sie funktionieren.
Was ist ein Webcrawler?
Ein Webcrawler ist ein Computerprogramm, das Webseiten automatisch scannt und systematisch liest, um die Seiten für Suchmaschinen zu indizieren. Webcrawler werden auch als Spider oder Bots bezeichnet.
Damit Suchmaschinen Benutzern, die eine Suche starten, aktuelle, relevante Webseiten präsentieren können, muss ein Crawl von einem Webcrawler-Bot erfolgen. Dieser Vorgang kann manchmal automatisch erfolgen (abhängig von den Einstellungen des Crawlers und Ihrer Website) oder direkt initiiert werden.
Viele Faktoren beeinflussen das SEO-Ranking Ihrer Seiten, einschließlich Relevanz, Backlinks, Webhosting und mehr. All dies spielt jedoch keine Rolle, wenn Ihre Seiten nicht von Suchmaschinen gecrawlt und indexiert werden. Aus diesem Grund ist es so wichtig sicherzustellen, dass Ihre Website die richtigen Crawls zulässt und alle Hindernisse auf ihrem Weg beseitigt.
Bots müssen das Web kontinuierlich scannen und kratzen, um sicherzustellen, dass die genauesten Informationen präsentiert werden. Google ist die meistbesuchte Website in den Vereinigten Staaten und etwa 26,9 % der Suchanfragen stammen von amerikanischen Nutzern:

Es gibt jedoch keinen Webcrawler, der für jede Suchmaschine crawlt. Jede Suchmaschine hat einzigartige Stärken, daher erstellen Entwickler und Vermarkter manchmal eine „Crawler-Liste“. Diese Crawler-Liste hilft ihnen, verschiedene Crawler in ihrem Site-Protokoll zu identifizieren, um sie zu akzeptieren oder zu blockieren.
Vermarkter müssen eine Crawler-Liste mit den verschiedenen Web-Crawlern zusammenstellen und verstehen, wie sie ihre Website bewerten (im Gegensatz zu Content Scrapern, die den Inhalt stehlen), um sicherzustellen, dass sie ihre Zielseiten korrekt für Suchmaschinen optimieren.
Wie funktioniert ein Webcrawler?
Ein Webcrawler scannt Ihre Webseite nach der Veröffentlichung automatisch und indexiert Ihre Daten.
Webcrawler suchen nach bestimmten Schlüsselwörtern, die mit der Webseite verknüpft sind, und indizieren diese Informationen für relevante Suchmaschinen wie Google, Bing und mehr.
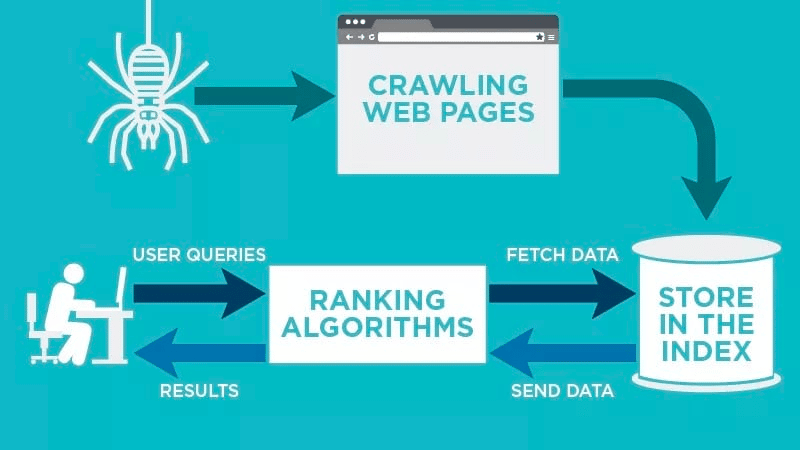
Algorithmen für die Suchmaschinen werden diese Daten abrufen, wenn ein Benutzer eine Anfrage nach dem relevanten Schlüsselwort sendet, das damit verknüpft ist.
Crawls beginnen mit bekannten URLs. Dies sind etablierte Webseiten mit verschiedenen Signalen, die Webcrawler zu diesen Seiten leiten. Diese Signale könnten sein:
- Backlinks: Die Häufigkeit, mit der eine Website auf sie verlinkt
- Besucher: Wie viel Verkehr geht auf diese Seite
- Domain Authority: Die Gesamtqualität der Domain
Anschließend speichern sie die Daten im Index der Suchmaschine. Wenn der Benutzer eine Suchanfrage einleitet, ruft der Algorithmus die Daten aus dem Index ab und sie erscheinen auf der Ergebnisseite der Suchmaschine. Dieser Vorgang kann innerhalb weniger Millisekunden ablaufen, weshalb sich Ergebnisse oft schnell zeigen.
Als Webmaster können Sie steuern, welche Bots Ihre Website crawlen. Deshalb ist es wichtig, eine Crawler-Liste zu haben. Es ist das robots.txt-Protokoll , das auf den Servern jeder Website lebt und Crawler zu neuen Inhalten leitet, die indiziert werden müssen.
Je nachdem, was Sie auf jeder Webseite in Ihr robots.txt -Protokoll eingeben, können Sie einen Crawler anweisen, diese Seite in Zukunft zu scannen oder zu vermeiden, diese Seite zu indizieren.
Indem Sie verstehen, wonach ein Webcrawler bei seinem Scan sucht, können Sie verstehen, wie Sie Ihre Inhalte besser für Suchmaschinen positionieren können.
Zusammenstellung Ihrer Crawler-Liste: Was sind die verschiedenen Arten von Web-Crawlern?
Wenn Sie anfangen, über die Zusammenstellung Ihrer Crawler-Liste nachzudenken, gibt es drei Haupttypen von Crawlern, nach denen Sie Ausschau halten sollten. Diese beinhalten:
- Interne Crawler: Dies sind Crawler, die vom Entwicklungsteam eines Unternehmens entwickelt wurden, um seine Website zu scannen. Typischerweise werden sie zur Prüfung und Optimierung von Websites verwendet.
- Kommerzielle Crawler: Dies sind speziell entwickelte Crawler wie Screaming Frog, mit denen Unternehmen ihre Inhalte crawlen und effizient auswerten können.
- Open-Source-Crawler : Dies sind kostenlos nutzbare Crawler, die von einer Vielzahl von Entwicklern und Hackern auf der ganzen Welt erstellt werden.
Es ist wichtig, die verschiedenen Arten von Crawlern zu verstehen, damit Sie wissen, welche Art Sie für Ihre eigenen Geschäftsziele nutzen müssen.
Die 11 häufigsten Web-Crawler, die Sie Ihrer Crawler-Liste hinzufügen sollten
Es gibt keinen Crawler, der die ganze Arbeit für jede Suchmaschine erledigt.
Stattdessen gibt es eine Vielzahl von Webcrawlern, die Ihre Webseiten auswerten und die Inhalte für alle Suchmaschinen scannen, die Benutzern auf der ganzen Welt zur Verfügung stehen.
Sehen wir uns einige der heute gängigsten Webcrawler an.
1. Googlebot
Googlebot ist der generische Web-Crawler von Google, der für das Crawlen von Websites verantwortlich ist, die in der Google-Suchmaschine angezeigt werden.

Obwohl es technisch gesehen zwei Versionen des Googlebot gibt – Googlebot Desktop und Googlebot Smartphone (Mobile) – betrachten die meisten Experten den Googlebot als einen einzigen Crawler.
Dies liegt daran, dass beide demselben eindeutigen Produkt-Token folgen (bekannt als User-Agent-Token), das in der robots.txt -Datei jeder Website geschrieben ist. Der Googlebot-Benutzeragent ist einfach „Googlebot“.
Der Googlebot geht an die Arbeit und greift normalerweise alle paar Sekunden auf Ihre Website zu (es sei denn, Sie haben ihn in der robots.txt -Datei Ihrer Website blockiert). Ein Backup der gescannten Seiten wird in einer einheitlichen Datenbank namens Google Cache gespeichert. Auf diese Weise können Sie sich alte Versionen Ihrer Website ansehen.
Darüber hinaus ist die Google Search Console ein weiteres Tool, das Webmaster verwenden, um zu verstehen, wie der Googlebot ihre Website crawlt, und um ihre Seiten für die Suche zu optimieren.
2. Binbot
Bingbot wurde 2010 von Microsoft entwickelt, um URLs zu scannen und zu indizieren, um sicherzustellen, dass Bing relevante, aktuelle Suchmaschinenergebnisse für die Benutzer der Plattform anbietet.
Ähnlich wie Googlebot können Entwickler oder Vermarkter in ihrer robots.txt auf ihrer Website festlegen, ob sie die Agentenkennung „Bingbot“ zum Scannen ihrer Website genehmigen oder ablehnen.
Darüber hinaus haben sie die Möglichkeit, zwischen Mobile-First-Indizierungs-Crawlern und Desktop-Crawlern zu unterscheiden, da Bingbot kürzlich auf einen neuen Agententyp umgestellt hat. Zusammen mit den Bing-Webmaster-Tools bietet dies Webmastern mehr Flexibilität, um zu zeigen, wie ihre Website gefunden und in den Suchergebnissen präsentiert wird.
3. Yandex-Bot
Yandex Bot ist ein Crawler speziell für die russische Suchmaschine Yandex. Dies ist eine der größten und beliebtesten Suchmaschinen in Russland.

Webmaster können ihre Seiten für Yandex Bot über ihre robots.txt -Datei zugänglich machen.
Darüber hinaus könnten sie bestimmten Seiten ein Yandex.Metrica -Tag hinzufügen, Seiten im Yandex-Webmaster neu indizieren oder ein IndexNow-Protokoll ausgeben, einen einzigartigen Bericht, der auf neue, geänderte oder deaktivierte Seiten hinweist.
4. Apple-Bot
Apple beauftragte den Apple Bot mit dem Crawlen und Indizieren von Webseiten für Apples Siri- und Spotlight-Vorschläge.
Apple Bot berücksichtigt mehrere Faktoren bei der Entscheidung, welche Inhalte in Siri und Spotlight-Vorschlägen hervorgehoben werden sollen. Zu diesen Faktoren gehören das Nutzerengagement, die Relevanz von Suchbegriffen, die Anzahl/Qualität der Links, ortsbezogene Signale und sogar das Design der Webseite.
5. DuckDuck-Bot
Der DuckDuckBot ist der Webcrawler für DuckDuckGo, der „nahtlosen Datenschutz in Ihrem Webbrowser“ bietet.
Webmaster können die DuckDuckBot-API verwenden, um zu sehen, ob der DuckDuck Bot ihre Website gecrawlt hat. Während des Crawlens aktualisiert es die DuckDuckBot-API-Datenbank mit aktuellen IP-Adressen und Benutzeragenten.
Dies hilft Webmastern, Betrüger oder böswillige Bots zu identifizieren, die versuchen, mit DuckDuck Bot in Verbindung gebracht zu werden.
6. Baidu-Spinne
Baidu ist die führende chinesische Suchmaschine und Baidu Spider ist der einzige Crawler der Website.

Google ist in China verboten, daher ist es wichtig, Baidu Spider das Crawlen Ihrer Website zu ermöglichen, wenn Sie den chinesischen Markt erreichen möchten.
Um den Baidu-Spider zu identifizieren, der Ihre Website durchsucht, suchen Sie nach den folgenden Benutzeragenten: baiduspider, baiduspider-image, baiduspider-video und mehr.
Wenn Sie nicht in China geschäftlich tätig sind, kann es sinnvoll sein, den Baidu Spider in Ihrem robots.txt-Skript zu blockieren. Dadurch wird verhindert, dass der Baidu-Spider Ihre Website durchsucht, wodurch jede Möglichkeit beseitigt wird, dass Ihre Seiten auf den Suchmaschinen-Ergebnisseiten (SERPs) von Baidu erscheinen.
7. Sogou-Spinne
Sogou ist eine chinesische Suchmaschine, die Berichten zufolge die erste Suchmaschine mit 10 Milliarden indexierten chinesischen Seiten ist.

Wenn Sie auf dem chinesischen Markt Geschäfte machen, ist dies ein weiterer beliebter Suchmaschinen-Crawler, den Sie kennen sollten. Die Sogou-Spinne folgt dem Ausschlusstext und den Crawl-Verzögerungsparametern des Roboters.

Wie beim Baidu-Spider sollten Sie diesen Spider deaktivieren, wenn Sie keine Geschäfte auf dem chinesischen Markt machen möchten, um langsame Ladezeiten der Website zu vermeiden.
8. Externer Facebook-Hit
Facebook External Hit, auch als Facebook Crawler bekannt, durchsucht den HTML-Code einer App oder Website, die auf Facebook geteilt wird.

Dadurch kann die soziale Plattform eine teilbare Vorschau jedes auf der Plattform geposteten Links erstellen. Der Titel, die Beschreibung und das Miniaturbild werden dank des Crawlers angezeigt.
Wenn der Crawl nicht innerhalb von Sekunden ausgeführt wird, zeigt Facebook den Inhalt nicht in dem vor dem Teilen generierten benutzerdefinierten Snippet an.
9. Exabot
Exalead ist ein im Jahr 2000 gegründetes Softwareunternehmen mit Hauptsitz in Paris, Frankreich. Das Unternehmen stellt Suchplattformen für Privat- und Unternehmenskunden bereit.
Exabot ist der Crawler für ihre zentrale Suchmaschine, die auf ihrem CloudView-Produkt aufbaut.
Wie die meisten Suchmaschinen berücksichtigt Exalead beim Ranking sowohl Backlinks als auch den Inhalt von Webseiten. Exabot ist der Benutzeragent des Roboters von Exalead. Der Roboter erstellt einen „Hauptindex“, der die Ergebnisse zusammenstellt, die die Suchmaschinenbenutzer sehen werden.
10. Swiftbot
Swiftype ist eine benutzerdefinierte Suchmaschine für Ihre Website. Es kombiniert „die beste Suchtechnologie, Algorithmen, Content-Ingestion-Framework, Clients und Analysetools“.

Wenn Sie eine komplexe Website mit vielen Seiten haben, bietet Swiftype eine nützliche Schnittstelle, um alle Ihre Seiten für Sie zu katalogisieren und zu indizieren.
Swiftbot ist der Webcrawler von Swiftype. Im Gegensatz zu anderen Bots crawlt Swiftbot jedoch nur Websites, die von seinen Kunden angefordert werden.
11. Slurp-Bot
Slurp Bot ist der Suchroboter von Yahoo, der Seiten für Yahoo durchsucht und indiziert.
Dieses Crawling ist sowohl für Yahoo.com als auch für seine Partnerseiten wie Yahoo News, Yahoo Finance und Yahoo Sports unerlässlich. Ohne sie würden relevante Site-Listings nicht angezeigt.
Der indizierte Inhalt trägt mit relevanteren Ergebnissen zu einem personalisierteren Weberlebnis für Benutzer bei.
Die 8 kommerziellen Crawler, die SEO-Profis kennen müssen
Nachdem Sie nun 11 der beliebtesten Bots auf Ihrer Crawler-Liste haben, schauen wir uns einige der gängigen kommerziellen Crawler und SEO-Tools für Profis an.
1. Ahrefs-Bot
Der Ahrefs Bot ist ein Web-Crawler, der die 12 Billionen Linkdatenbank der beliebten SEO-Software Ahrefs kompiliert und indiziert.
Der Ahrefs Bot besucht täglich 6 Milliarden Websites und gilt als „der zweitaktivste Crawler“ hinter nur dem Googlebot.
Ähnlich wie andere Bots folgt der Ahrefs-Bot robots.txt -Funktionen sowie erlaubt/verbietet Regeln im Code jeder Seite.
2. Semrush-Bot
Der Semrush Bot ermöglicht es Semrush, einer führenden SEO-Software, Website-Daten zur Nutzung durch seine Kunden auf seiner Plattform zu sammeln und zu indizieren.

Die Daten werden in der öffentlichen Backlink-Suchmaschine von Semrush, dem Site-Audit-Tool, dem Backlink-Audit-Tool, dem Linkbuilding-Tool und dem Schreibassistenten verwendet.
Es durchsucht Ihre Website, indem es eine Liste mit Webseiten-URLs erstellt, diese besucht und bestimmte Hyperlinks für zukünftige Besuche speichert.
3. Moz' Kampagnen-Crawler Rogerbot
Rogerbot ist der Crawler für die führende SEO-Website Moz. Dieser Crawler sammelt speziell Inhalte für Website-Audits der Moz Pro-Kampagne.

Rogerbot befolgt alle Regeln, die in robots.txt -Dateien festgelegt sind, sodass Sie entscheiden können, ob Sie Rogerbot blockieren/erlauben möchten, Ihre Website zu scannen.
Webmaster können aufgrund seines facettenreichen Ansatzes nicht nach einer statischen IP-Adresse suchen, um zu sehen, welche Seiten Rogerbot gecrawlt hat.
4. Schreiender Frosch
Screaming Frog ist ein Crawler, den SEO-Experten verwenden, um ihre eigene Website zu prüfen und Verbesserungsbereiche zu identifizieren, die sich auf ihre Suchmaschinen-Rankings auswirken werden.

Sobald ein Crawl gestartet wurde, können Sie Echtzeitdaten überprüfen und defekte Links oder Verbesserungen identifizieren, die an Ihren Seitentiteln, Metadaten, Robotern, doppelten Inhalten und mehr erforderlich sind.
Um die Crawling-Parameter zu konfigurieren, müssen Sie eine Screaming Frog-Lizenz erwerben.
5. Lumar (ehemals Deep Crawl)
Lumar ist eine „zentrale Kommandozentrale zur Aufrechterhaltung des technischen Zustands Ihrer Website“. Mit dieser Plattform können Sie einen Crawl Ihrer Website initiieren, um Ihnen bei der Planung Ihrer Website-Architektur zu helfen.
Lumar ist stolz darauf, der „schnellste Website-Crawler auf dem Markt“ zu sein und rühmt sich, dass er bis zu 450 URLs pro Sekunde crawlen kann.
6. Majestätisch
Majestic konzentriert sich hauptsächlich auf die Verfolgung und Identifizierung von Backlinks auf URLs.
Das Unternehmen ist stolz darauf, „eine der umfassendsten Quellen für Backlink-Daten im Internet“ zu haben, und hebt seinen historischen Index hervor, der von 5 auf 15 Jahre Links im Jahr 2021 gestiegen ist.
All diese Daten stellt der Crawler der Seite den Kunden des Unternehmens zur Verfügung.
7. kognitives SEO
CognitiveSEO ist eine weitere wichtige SEO-Software, die viele Fachleute verwenden.
Der kognitive SEO-Crawler ermöglicht es Benutzern, umfassende Website-Audits durchzuführen, die ihre Website-Architektur und übergreifende SEO-Strategie informieren.
Der Bot durchsucht alle Seiten und stellt „einen vollständig angepassten Datensatz“ bereit, der für den Endbenutzer einzigartig ist. Dieser Datensatz enthält auch Empfehlungen für den Benutzer, wie er seine Website für andere Crawler verbessern kann – sowohl um das Ranking zu beeinflussen als auch unnötige Crawler zu blockieren.
8. Oncrawl
Oncrawl ist ein „branchenführender SEO-Crawler und Protokollanalysator“ für Kunden auf Unternehmensebene.

Benutzer können „Crawling-Profile“ einrichten, um bestimmte Parameter für das Crawling zu erstellen. Sie können diese Einstellungen (einschließlich Start-URL, Crawling-Limits, maximale Crawling-Geschwindigkeit und mehr) speichern, um das Crawlen einfach mit denselben festgelegten Parametern erneut auszuführen.
Muss ich meine Website vor bösartigen Web-Crawlern schützen?
Nicht alle Crawler sind gut. Einige können sich negativ auf Ihre Seitengeschwindigkeit auswirken, während andere möglicherweise versuchen, Ihre Website zu hacken, oder böswillige Absichten haben.
Aus diesem Grund ist es wichtig zu verstehen, wie Sie Crawler daran hindern, auf Ihre Website zuzugreifen.
Indem Sie eine Crawler-Liste erstellen, wissen Sie, auf welche Crawler Sie achten sollten. Dann können Sie die faulen aussortieren und zu Ihrer Sperrliste hinzufügen.
So blockieren Sie bösartige Web-Crawler
Mit Ihrer Crawler-Liste in der Hand können Sie feststellen, welche Bots Sie genehmigen möchten und welche Sie blockieren müssen.
Der erste Schritt besteht darin, Ihre Crawler-Liste durchzugehen und den Benutzeragenten und die vollständige Agentenzeichenfolge zu definieren, die jedem Crawler zugeordnet ist, sowie seine spezifische IP-Adresse. Dies sind wichtige Identifizierungsfaktoren, die mit jedem Bot verbunden sind.
Mit dem Benutzeragenten und der IP-Adresse können Sie sie in Ihren Site-Einträgen über eine DNS-Suche oder einen IP-Abgleich abgleichen. Wenn sie nicht genau übereinstimmen, haben Sie möglicherweise einen böswilligen Bot, der versucht, sich als der tatsächliche Bot auszugeben.
Anschließend können Sie den Betrüger blockieren, indem Sie die Berechtigungen mithilfe Ihres robots.txt -Site-Tags anpassen.
Zusammenfassung
Webcrawler sind nützlich für Suchmaschinen und wichtig für Vermarkter, um sie zu verstehen.
Sicherzustellen, dass Ihre Website von den richtigen Crawlern korrekt gecrawlt wird, ist wichtig für den Erfolg Ihres Unternehmens. Indem Sie eine Crawler-Liste führen, wissen Sie, auf welche Sie achten müssen, wenn sie in Ihrem Site-Protokoll erscheinen.
Wenn Sie den Empfehlungen kommerzieller Crawler folgen und den Inhalt und die Geschwindigkeit Ihrer Website verbessern, erleichtern Sie Crawlern den Zugriff auf Ihre Website und indizieren die richtigen Informationen für Suchmaschinen und die Verbraucher, die danach suchen.