
Eine Einführung in das Verständnis von Database Sharding
Veröffentlicht: 2022-11-05Das Erstellen einer Website ist der erste Schritt beim Aufbau Ihrer Präsenz im Internet. Um langfristig erfolgreich zu sein, müssen Sie auch sicherstellen, dass Ihre Website an Wachstum angepasst werden kann. Und einer der ersten Schritte ist die Implementierung einer Datenbank, die mit Ihnen skalieren kann. Andernfalls riskieren Sie eine langsame Abfrageleistung und Datenbankausfälle.
In diesem Beitrag wird erläutert, wie Sie Datenbank-Sharding verwenden können, um eine hohe Skalierbarkeit und Verfügbarkeit für Ihre Daten zu erreichen. Wir werden auch die Nachteile von Sharding und die verschiedenen Sharding-Architekturen ansprechen, die Sie verwenden können.
Was ist Datenbank-Sharding?
Sharding ist eine Optimierungstechnik, die Tabellen auf andere Datenbankserver verteilt. Es ist wie eine Partitionierung in dem Sinne, dass beide die Aufteilung von Daten in kleinere Teilmengen beinhalten. Der Unterschied besteht darin, dass Sharding diese Teilmengen auf verschiedene Server verteilt, während die Partitionierung sie in einer Datenbank speichert. Diese Server verwenden dieselbe Datenbank-Engine und denselben Hardwaretyp, um für alle Shards ein ähnliches Leistungsniveau zu erreichen.
Sharding zielt darauf ab, eine Share-Nothing-Architektur zu erreichen, die Verarbeitungsengpässe und Single Points of Failure beseitigt.
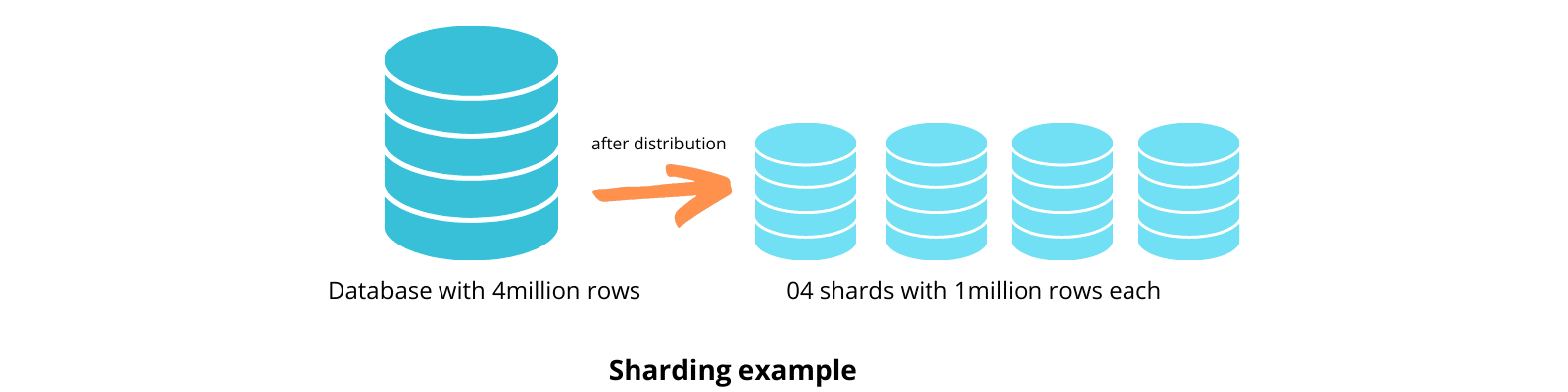
Sie können Sharding auf zwei Arten implementieren – horizontal und vertikal. Horizontales Sharding teilt die Tabelle basierend auf Zeilen, während vertikales Sharding die Tabellen basierend auf Spalten unterteilt.
Sharding ist in dieser Hinsicht wie eine Partitionierung, die große Tabellen in kleinere aufteilt.
Horizontales Sharding ist effektiv für Datenbanken, bei denen die meisten Abfragen eine Teilmenge von Zeilen zurückgeben, z. B. eine Kundendatenbank, die Daten (wie Name, Adresse, E-Mail usw.) auf einmal zurückgibt.
Vertikales Sharding ist effektiv für Datenbanken, deren Abfragen einzelne Spalten zurückgeben. Wenn die Kundendatenbank beispielsweise den Namen oder die E-Mail-Adresse des Kunden separat zurückgibt, könnten Sie den Namen und die E-Mail-Adresse in verschiedene Cluster aufteilen.
Vorteile von Database Sharding
Nachfolgend sind einige der Vorteile des Datenbank-Shardings aufgeführt.
Verbesserte horizontale Skalierung
Sie können Ihre Datenbank vertikal oder horizontal skalieren. Vertikale Skalierung bezieht sich auf das Hinzufügen weiterer CPUs (Central Processing Units) und RAM (Random Access Memory) zum Server, um die Leistung zu verbessern. Die vertikale Skalierung ist eine hilfreiche Lösung für kleine bis mittlere Datenbanken. Wenn Ihre Daten jedoch wachsen, wird die vertikale Skalierung undurchführbar. Es gibt nur eine begrenzte Leistung, die Sie einem einzelnen Server hinzufügen können.
Die horizontale Skalierung ist flexibler. Sie können Ihre Datenbank nach Bedarf skalieren, indem Sie Ihrem System weitere Server hinzufügen. Jeder dieser Server stellt Ressourcen für verschiedene Datenbank-Shards bereit. Dies verteilt die Arbeitslast und verbessert die Fähigkeit des Systems, mehr Anfragen zu verarbeiten.
Schnellere Antwortzeiten für Abfragen
Shards haben nur wenige Zeilen und Spalten. Aus diesem Grund dauert die Verarbeitung von Datenbankabfragen weniger Zeit. Im Gegensatz dazu kann eine Abfrage einer nicht fragmentierten Datenbank eine Suche durch Hunderte – oder sogar Tausende – von Zeilen erfordern.
Erhöhte Zuverlässigkeit in Ausfallsituationen
Datenbankausfälle treten aus verschiedenen Gründen auf, darunter versehentliches Löschen von Daten, Verbindungsfehler und Cybersicherheitsangriffe. Sharding minimiert die Auswirkungen von Ausfällen. Da jeder Shard autonom ist, ist nur der betroffene Shard mit Ausfallzeiten konfrontiert. Wenn Sie beispielsweise vier Shards haben und bei einem davon ein Ausfall auftritt, sind nur 25 Prozent der Vorgänge betroffen.
Nachteile von Sharding
Obwohl Sharding die Zuverlässigkeit und Verfügbarkeit einer Datenbank verbessert, ist die Implementierung komplex. Die Verwendung der falschen Sharding-Architektur kann die Leistung verlangsamen und zu Datenverlust führen.
Achten Sie darauf, eine Sharding-Technik zu wählen, die eine ausgewogene Datenverteilung auf alle Shards ermöglicht. Ohne dieses Gleichgewicht riskieren Sie die Erstellung von Datenbank-Hotspots, die auftreten, wenn ein Shard die meisten Daten speichert, während andere Shards praktisch leer bleiben. Dadurch wird der Schreibdurchsatz auf den einzelnen Shard reduziert.
Um dies zu lösen, könnten Sie den unausgeglichenen Shard noch weiter partitionieren, aber dieser Prozess ist eine Herausforderung und kann Ihre Datenbank während der Datenmigration zum Erliegen bringen.
Möchten Sie wissen, wie wir unseren Traffic um über 1000 % gesteigert haben?
Schließen Sie sich über 20.000 anderen an, die unseren wöchentlichen Newsletter mit WordPress-Insidertipps erhalten!

Ein weiterer Nachteil des Shardings besteht darin, dass SQL-Joins mit mehreren Tabellen in verschiedenen Shards zu langsam werden und die Leistung beeinträchtigen können. Mit der richtigen Architektur können Sie dieses Problem jedoch vermeiden.
Sharding-Architekturen
Sie können Sharding mit drei Architekturen implementieren:
- Schlüsselbasiertes Sharding
- Bereichsbasiertes Sharding
- Verzeichnisbasiertes Sharding
Welche Architektur Sie wählen, hängt von Ihrem Anwendungsfall ab.
Schlüsselbasiertes Sharding
In einer Schlüssel- oder Hash-basierten Sharding-Architektur verwendet eine Datenbankanwendung einen Shard-Schlüssel, um einen Shard zu lokalisieren. Eine Hash-Funktion hasht den Sharding-Schlüsselwert, und die Ausgabe ordnet Daten einem bestimmten Shard zu. Eine einfache Hash-Funktion kann der Modulus des Schlüssels und die Anzahl der Shards sein.
Die Hash-Funktion kann mehr als einen Sharding-Schlüssel annehmen. Aus diesem Grund eignet sich das schlüsselbasierte Sharding für Datensätze, die möglicherweise gemeinsame Schlüssel haben. Die algorithmische Verteilung der Daten minimiert die Möglichkeit, Datenbank-Hotspots zu erstellen, bei denen ein Shard mehr Daten enthält als der andere.
Da die Verteilung jedoch nur auf der Hash-Funktion beruht, ist es unmöglich, Daten logisch zusammenzufassen. Daher können Datenbankoperationen, die Daten von mehreren Shards erfordern, ineffizient sein, da sie das Lesen von Daten aus jedem Shard erfordern.
Reichweitenbasiertes Sharding
Bereichsbasiertes Sharding beinhaltet das Sharding einer Datenbank in Abhängigkeit von einem angegebenen Wertebereich.
Es verwendet einen Sharding-Schlüssel, um zu bestimmen, welchem Shard ein Wert zugewiesen werden soll. Die Datenbankanwendung prüft den Sharding, der dem Sharding-Schlüssel entspricht, in einer Nachschlagetabelle und speichert die Daten. Aus diesem Grund ist bereichsbasiertes Sharding einfach zu entwerfen und zu implementieren.
Beispielsweise könnten Sie den Benutzer-ID-Wert in einer Benutzerdatenbank als Sharding-Schlüssel verwenden. Sie könnten Benutzer mit IDs von 0–2.000 auf einem Shard speichern, Benutzer mit IDs zwischen 2.000 und 4.000 auf einem anderen Shard und so weiter.
Bereichsbasiertes Sharding kann Datenbank-Hotspots verursachen. Stellen Sie sich eine Benutzerdatenbank vor, in der die meisten Ihrer Benutzer-IDs zwischen 2.001 und 4.000 liegen. Der Prozess weist sie einem einzigen Shard zu, wodurch im Laufe der Zeit ein Ungleichgewicht entsteht. Bereichsbasiertes Sharding funktioniert daher am besten für gleichmäßig verteilte Daten.
Verzeichnisbasiertes Sharding
Verzeichnisbasiertes Sharding gruppiert logisch verwandte Daten im selben Shard. Es verwendet eine Nachschlagetabelle, die eine Liste von Zuordnungen für jede Entität in der Datenbank enthält. Jede Zuordnung entspricht einem Datenbank-Shard.
Verzeichnisbasiertes Sharding ist flexibler als bereichsbasiertes oder schlüsselbasiertes Sharding, da Sie Daten dynamisch zu Shards hinzufügen können. Es gibt keine Sharding-Funktion, die befolgt werden muss, oder Bereichswerte, innerhalb derer man bleiben muss. Diese Flexibilität erhöht die Datenbankeffizienz: Sie können zusammengehörige Daten in einem Shard speichern, was bedeutet, dass die Ausführung allgemeiner Abfragen weniger Zeit in Anspruch nimmt.
Wenn Sie beispielsweise verzeichnisbasiertes Sharding verwendet und Benutzer nach ihrem Standort gruppiert haben, um Benutzer von einem bestimmten Ort abzurufen, fragen Sie nur ein einzelnes Shard ab.
Datenbank-Sharding mit Kinsta
Die meisten modernen Datenbank-Engines bieten Unterstützung für Datenbank-Sharding. Eine dieser Datenbank-Engines ist MariaDB, ein kommerziell unterstützter Fork von MySQL. Es ist ein leistungsstarkes Open-Source-Datenbanksystem, das von Unternehmen wie IBM, GitHub und Wikimedia übernommen wird. Es ist auch Teil des Hochleistungsserver-Stacks bei Kinsta.
MariaDB bietet integrierte Sharding-Funktionen über die Spider-Speicher-Engine. Die Spider-Speicher-Engine ist eine Clusterbildungs-Engine, die Partitionierung und Transaktionen mit erweiterter Architektur (XA) unterstützt. Es ermöglicht Ihnen, entfernte Tabellen aus verschiedenen Instanzen so zu behandeln, als ob sie sich in derselben Instanz befinden. Sobald Sie eine Tabelle in der Spider-Speicher-Engine erstellt haben, wird die Tabelle mit einer anderen Tabelle auf dem Remote-MariaDB-Server verknüpft. Sobald die Verbindung hergestellt ist, teilt die Speicher-Engine den Link mit allen Tabellen, die Teil derselben Transaktion sind.
Zusammenfassung
Datenbank-Sharding ist eine Skalierungstechnik, bei der Tabellen in kleinere Teilmengen partitioniert und auf verschiedene Server, sogenannte Shards, verteilt werden. Sie können Sharding auf verschiedene Weise implementieren, z. B. schlüsselbasiertes Sharding, bereichsbasiertes Sharding und verzeichnisbasiertes Sharding.
Während Sharding die Skalierbarkeit, Zuverlässigkeit und Verfügbarkeit einer Datenbank verbessert, ist es sehr komplex zu implementieren. Darüber hinaus ist es nach dem Erstellen eines Shards nicht einfach, die Datenbank in ihren Zustand ohne Shard zurückzusetzen. Aus diesem Grund sollten Sie Sharding nur dann zur Optimierung verwenden, wenn Sie sicher sind, dass andere Skalierbarkeitsoptionen nicht funktionieren.
Unabhängig davon, ob es sich bei Ihrem Unternehmen um eine gemeinnützige Organisation oder ein Unternehmen auf Unternehmensebene handelt, können die Expertenlösungen von Kinsta Ihre Sorgen um das Hosten von Websites beseitigen, sodass Sie sich auf das konzentrieren können, was am wichtigsten ist.