
Irreführende Statistiken können gefährlich sein (einige Beispiele)
Veröffentlicht: 2022-12-06Menschen verlassen sich auf Statistiken, um wichtige Informationen zu erhalten. In der Geschäftswelt können Statistiken nützlich sein, um Trends zu verfolgen und die Produktivität zu maximieren. Aber manchmal können Statistiken irreführend dargestellt werden . Beispielsweise erhielt die Advertising Standards Authority (ADA) im Vereinigten Königreich 2007 eine Beschwerde über eine Anzeige von Colgate.
Die Anzeige behauptet bekanntlich, dass 80 % der Zahnärzte die Verwendung von Colgate-Zahnpasta empfehlen. In der Beschwerde, die die ADA erhielt, wurde argumentiert, dass dies ein Verstoß gegen die Werberegeln im Vereinigten Königreich sei. Nachdem die ADA die Angelegenheit untersucht hatte, stellte sie fest, dass die Anzeige irreführende Statistiken verwendete.
Es stimmt, dass viele Zahnärzte Colgate Zahnpasta empfehlen. Aber nicht alle nannten Colgate als ihre Empfehlung Nummer eins. Die meisten Zahnärzte empfahlen auch andere Arten von Zahnpasta, und Colgate tauchte normalerweise irgendwann später auf.
Dies ist nur ein Beispiel dafür, wie irreführende Statistiken verwendet werden. Menschen stoßen in vielen verschiedenen Lebensbereichen auf irreführende statistische Beispiele. Beispiele finden sich in den Nachrichten, in der Werbung, in der Politik und sogar in der Wissenschaft.
Dieser Beitrag hilft Ihnen, irreführende Statistiken und andere irreführende Daten zu erkennen . Es wird diskutiert, wie diese Daten Menschen in die Irre führen. Sie erfahren auch, wann und wie Sie Daten verwenden, wenn Sie kritische Entscheidungen treffen.
Was sind irreführende Statistiken?
Statistiken sind das Ergebnis des Sammelns numerischer Daten, ihrer sorgfältigen Analyse und ihrer anschließenden Interpretation . Statistiken sind besonders nützlich, wenn Sie mit großen Datenmengen zu tun haben, aber alles, was gemessen werden kann, kann zu einer Statistik werden. Statistiken verraten oft viel über die Welt und ihre Funktionsweise.
Wenn diese Informationen jedoch missbraucht werden, sogar aus Versehen, werden sie zu einer irreführenden Statistik. Irreführende Statistiken geben Menschen falsche Informationen, die sie eher täuschen als informieren .
Wenn Menschen eine Statistik aus dem Kontext reißen, verliert sie ihren Wert und kann dazu führen, dass Menschen falsche Schlussfolgerungen ziehen. Der Begriff „irreführende Statistik“ beschreibt jede statistische Methode, die Daten falsch darstellt. Ob es beabsichtigt war oder nicht , es würde immer noch als irreführende Statistik gelten.
Bei der Erhebung von Daten für eine Statistik sind drei grundsätzliche Punkte zu beachten. An jedem dieser Punkte kann ein Problem mit der Datenanalyse auftreten.
- Sammlung: Beim Sammeln der Daten
- Verarbeitung: Bei der Analyse der Daten und ihrer Auswirkungen
- Präsentation: Wenn Sie Ihre Erkenntnisse mit anderen teilen
Eine kleine Stichprobengröße
Stichprobenerhebungen sind ein Beispiel für die Erstellung irreführender Statistiken. Umfragen oder Studien, die an einer Zielgruppe mit Stichprobengröße durchgeführt werden, liefern oft Ergebnisse, die so irreführend sind, dass sie unbrauchbar sind.
Zur Veranschaulichung stellt eine Umfrage 20 Personen eine Ja-oder-Nein-Frage. 19 der Personen antworten mit Ja auf die Umfrage. Die Ergebnisse zeigen also, dass 95 % der Menschen diese Frage mit Ja beantworten würden. Aber das ist keine gute Umfrage, weil die Informationen begrenzt sind.
Diese Statistik hat keinen wirklichen Wert. Wenn Sie nun 1.000 Personen dieselbe Frage stellen und 950 mit Ja antworten, dann ist dies eine viel zuverlässigere Statistik, die zeigt, dass 95 % der Personen mit Ja antworten würden.
Um eine zuverlässige Studie zur Stichprobengröße durchzuführen, müssen Sie drei Dinge berücksichtigen:
- Eins : Was für eine Frage stellst du?
- Zweitens : Welche Bedeutung hat die Statistik, die Sie finden möchten?
- Und drittens : Welche statistische Technik werden Sie verwenden?
Um zuverlässige Ergebnisse zu erhalten, sollte jede quantitative Analyse mit Stichprobengröße mindestens 200 Personen umfassen.
Geladene Fragen

Es ist wichtig, nach Daten aus einer neutralen Quelle zu suchen . Andernfalls sind die Informationen schräg. Geladene Fragen verwenden eine umstrittene oder ungerechtfertigte Annahme, um die Antwort zu manipulieren. Ein Beispiel hierfür ist das Stellen einer Frage, die mit „Was liebst du?“ beginnt. Diese Frage leistet großartige Arbeit, um positives Feedback zu sammeln, bringt Ihnen aber nichts Nützliches bei. Es bietet der Person keine Gelegenheit, ihre ehrlichen Gedanken und Meinungen zu äußern.
Betrachten Sie den Unterschied in den folgenden zwei Fragen:
- Unterstützen Sie eine Steuerreform, die höhere Steuern implizieren würde?
- Befürworten Sie eine Steuerreform, die der sozialen Umverteilung förderlich wäre?
Die Frage bezieht sich im Wesentlichen auf dasselbe Thema, aber die Ergebnisse aus jeder dieser Fragen wären ziemlich unterschiedlich. Umfragen sollten unvoreingenommen und unvoreingenommen durchgeführt werden. Sie möchten die ehrlichen Meinungen der Leute und ein vollständiges Bild davon erhalten, was die Leute denken. Um dies zu erreichen, sollten Ihre Fragen weder die Antwort implizieren noch eine emotionale Reaktion hervorrufen .
Zitieren irreführender „Durchschnittswerte“
Einige Leute verwenden den Begriff „Durchschnitt“, um die Wahrheit zu verschleiern oder zu lügen, um Informationen besser aussehen zu lassen.
Diese Technik ist besonders nützlich, wenn jemand eine Zahl größer oder besser erscheinen lassen möchte, als sie ist. Beispielsweise kann eine Universität, die neue Studenten anwerben möchte, ein „durchschnittliches“ Jahresgehalt für Absolventen ihrer Schule bereitstellen. Aber es gibt vielleicht nur eine Handvoll Studenten, die tatsächlich hohe Gehälter haben. Aber ihre Gehälter machen das Durchschnittseinkommen für alle Studenten höher. Das sieht für den gesamten Durchschnitt besser aus.
Durchschnitte sind auch nützlich, um Ungleichheiten zu verbergen. Nehmen wir als weiteres Beispiel an, ein Unternehmen zahlt 20.000 US-Dollar pro Jahr an seine 90 Mitarbeiter. Aber ihr Chef bekommt 200.000 Dollar im Jahr. Wenn Sie den Lohn des Chefs und die Löhne der Angestellten kombinieren, beträgt das Durchschnittseinkommen für jedes Mitglied des Unternehmens 21.978 USD.
Auf dem Papier sieht das toll aus. Aber diese Zahl kann nicht die ganze Geschichte erzählen, weil einer der Angestellten (der Chef) viel mehr verdient als die anderen Arbeiter. Daher gelten solche Ergebnisse als irreführende Statistiken.
Kumulative vs. jährliche Daten
Kumulative Daten verfolgen Informationen in einem Diagramm über die Zeit. Jedes Mal, wenn Sie Daten in die Diagramme eingeben, steigt das Diagramm an.
Jahresdaten zeigt alle Daten für ein bestimmtes Jahr.
Tracking-Informationen für jedes Jahr liefern ein genaueres Bild der allgemeinen Trends.
Ein Beispiel für ein kumulatives Diagramm ist das Worldometer-COVID-19-Diagramm. Während der COVID-19-Pandemie sind viele Beispiele für kumulative Diagramme aufgetaucht. Sie spiegeln oft die kumulierte Anzahl von COVID-Fällen in einem bestimmten Gebiet wider.
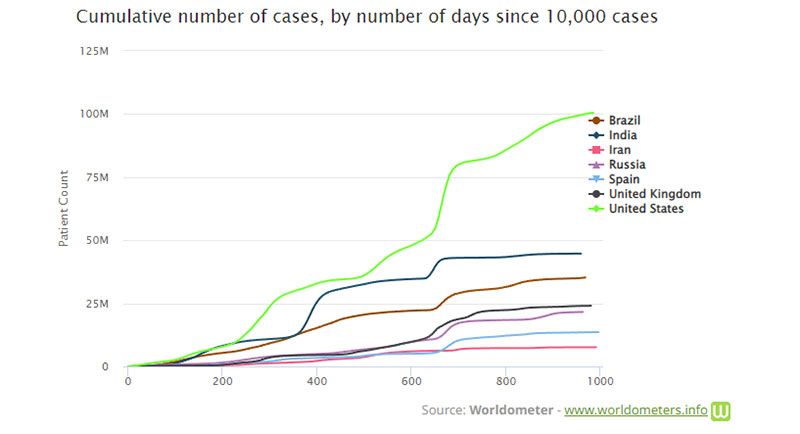
Einige Unternehmen verwenden Diagramme wie dieses, um den Umsatz größer erscheinen zu lassen, als er ist. Im Jahr 2013 wurde Apples CEO Tim Cook dafür kritisiert, dass er eine Präsentation verwendet hatte, die nur die kumulative Zahl der iPhone-Verkäufe zeigte. Viele glaubten damals, er habe dies absichtlich getan, um die Tatsache zu verbergen, dass die iPhone-Verkäufe zurückgingen.
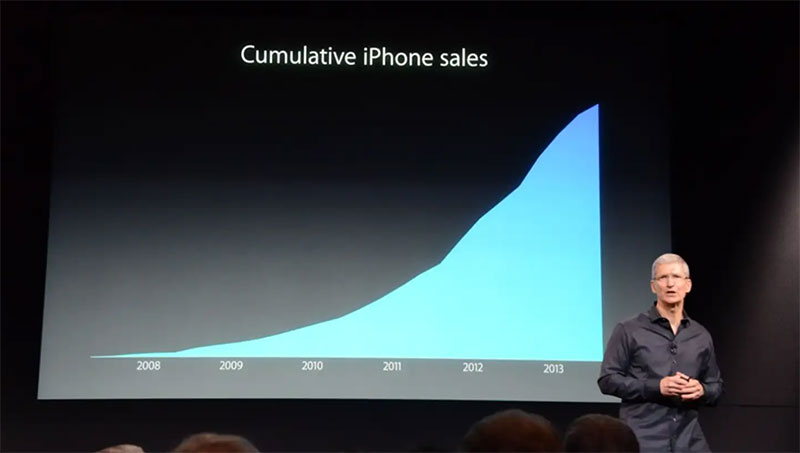
Das soll nicht heißen, dass alle kumulativen Daten schlecht oder falsch sind. Tatsächlich kann es nützlich sein, um Änderungen oder Wachstum und verschiedene Summen zu verfolgen. Aber das Wichtigste ist, auf Änderungen in den Daten zu achten. Sehen Sie sich dann genauer an, was sie verursacht hat, anstatt sich auf das Diagramm zu verlassen, um Ihnen alles zu sagen.
Übergeneralisierung und voreingenommene Stichproben
Überverallgemeinerung tritt auf, wenn jemand annimmt, dass das, was für eine Person gilt, auch für alle anderen gelten muss. Normalerweise tritt dieser Irrtum auf, wenn jemand eine Studie mit einer bestimmten Gruppe von Menschen durchführt. Sie gehen dann davon aus, dass die Ergebnisse für eine andere, nicht verwandte Personengruppe gelten.
Nicht repräsentative Stichproben oder voreingenommene Stichproben sind Umfragen, die die allgemeine Bevölkerung nicht genau repräsentieren.
Ein Beispiel für voreingenommene Stichproben ereignete sich während der Präsidentschaftswahlen 1936 in den Vereinigten Staaten von Amerika.
Der Literary Digest, ein damals populäres Magazin, führte eine Umfrage durch, um vorherzusagen, wer die Wahlen gewinnen würde. Die Ergebnisse sagten voraus, dass Alfred Landon durch einen Erdrutschsieg gewinnen würde.
Dieses Magazin war dafür bekannt, den Ausgang von Wahlen genau vorherzusagen. In diesem Jahr lagen sie jedoch völlig falsch. Franklin Roosevelt gewann mit fast doppelt so vielen Stimmen wie sein Gegner.
Einige weitere Untersuchungen ergaben, dass zwei Variablen ins Spiel gekommen waren, die die Ergebnisse verzerrten.
Erstens waren die meisten Teilnehmer an der Umfrage Personen, die im Telefonbuch und auf Autoregistrierungslisten gefunden wurden. Die Befragung wurde also nur mit Personen ab einem bestimmten sozioökonomischen Status durchgeführt.
Der zweite Faktor war, dass diejenigen, die für Landon gestimmt hatten, eher bereit waren, an der Umfrage teilzunehmen, als diejenigen, die sich entschieden, für Roosevelt zu stimmen. Die Ergebnisse spiegelten also diese Voreingenommenheit wider.
Abschneiden einer Achse
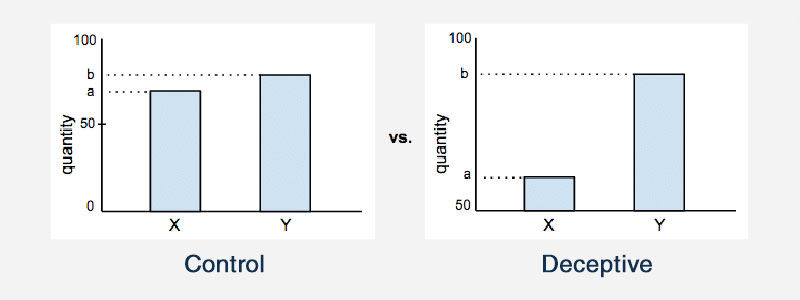
Das Abschneiden der Achse in einem Diagramm ist ein weiteres Beispiel für irreführende Statistiken. Bei den meisten statistischen Diagrammen beginnen vermutlich sowohl die x- als auch die y-Achse bei Null. Das Abschneiden der Achse bedeutet jedoch, dass der Graph die Achsen tatsächlich bei einem anderen Wert beginnt. Dies wirkt sich auf die Art und Weise aus, wie ein Diagramm aussieht, und beeinflusst die Schlussfolgerungen, die eine Person ziehen wird.
Hier ist ein Beispiel, das dies verdeutlicht:
Ein weiteres Beispiel dafür ereignete sich kürzlich im September 2021. In einer Sendung von Fox News verwendete der Moderator ein Diagramm, das die Anzahl der Amerikaner zeigt, die behaupteten, Christen zu sein. Das Diagramm zeigte, dass die Zahl der Amerikaner, die sich als Christen identifizierten, in den letzten 10 Jahren drastisch gesunken war.

In der folgenden Grafik sehen wir, dass sich 2009 77 % der Amerikaner als Christen identifizierten.
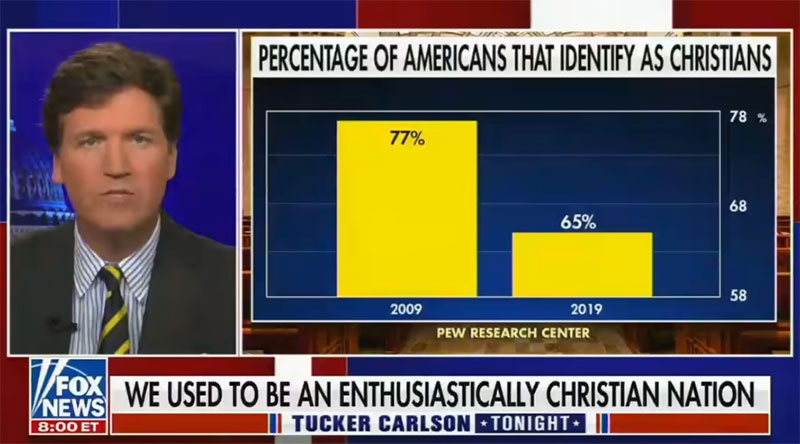
Bis 2019 sank die Zahl auf 65 %. In Wirklichkeit ist das kein großer Rückgang. Aber die Achse in diesem Diagramm beginnt bei 58 % und endet bei 78 %. Der Rückgang um 12 % von 2009 bis 2019 erscheint also viel drastischer, als er tatsächlich ist.
Kausalität und Korrelation
Es kann leicht sein, eine Verbindung zwischen zwei scheinbar verbundenen Datenpunkten anzunehmen. Es wird jedoch gesagt, dass Korrelation nicht Kausalität impliziert . Warum ist das so?
Diese Grafik veranschaulicht, warum Korrelation nicht dasselbe ist wie Kausalität.
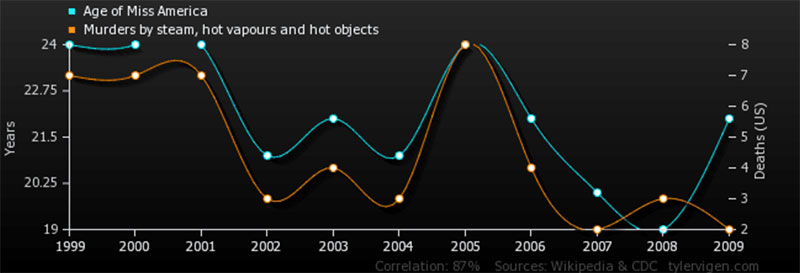
Forscher stehen oft unter großem Druck, neue, nützliche Daten zu entdecken. Die Versuchung, voreilige Schlüsse zu ziehen und voreilige Schlüsse zu ziehen, ist also immer da. Deshalb ist es wichtig , in jeder Situation nach der eigentlichen Ursache und Wirkung zu suchen .
Verwenden von Prozentsätzen zum Ausblenden von Zahlen und Berechnungen
Ein Prozentsatz kann genaue Zahlen verbergen und Ergebnisse seriöser und zuverlässiger erscheinen lassen, als sie sind.
Wenn beispielsweise zwei von drei Personen ein bestimmtes Reinigungsprodukt bevorzugen, könnten Sie sagen, dass 66,667 % der Personen dieses Produkt bevorzugen. Dadurch sieht die Zahl offizieller aus, insbesondere wenn die Zahlen nach dem Komma enthalten sind.
Hier sind ein paar andere Möglichkeiten, wie Dezimalzahlen und Prozentsätze die Wahrheit verschleiern können:
- Ausblenden roher Zahlen und kleiner Stichprobengrößen . Prozentangaben verschleiern den absoluten Wert von Rohzahlen. Dies macht sie nützlich für Personen, die wenig schmeichelhafte Zahlen oder Ergebnisse mit geringem Stichprobenumfang verbergen möchten.
- Verwendung verschiedener Basen. Da Prozentsätze nicht die ursprünglichen Zahlen liefern, auf denen sie basieren, können die Ergebnisse leicht verfälscht werden. Wenn jemand eine Zahl besser aussehen lassen wollte, konnte er diese Zahl aus einer anderen Basis berechnen.
Dies geschah einmal in einem Bericht der New York Times über gewerkschaftlich organisierte Arbeiter. Die Arbeiter hatten in einem Jahr eine Lohnkürzung von 20 %, und im nächsten Jahr berichtete die Times, dass die Gewerkschaftsarbeiter eine Gehaltserhöhung von 5 % erhielten. Die Behauptung war also, dass sie ein Viertel ihrer Gehaltskürzung zurückbekamen.
Die Arbeiter erhielten jedoch eine 5-prozentige Gehaltserhöhung auf der Grundlage ihres aktuellen Lohns, nicht des Lohns, den sie vor der Lohnkürzung hatten. Obwohl es auf dem Papier gut aussah, wurden die 20-prozentige Lohnkürzung und die 5-prozentige Gehaltserhöhung aus unterschiedlichen Basiszahlen berechnet. Die beiden Nummern passten überhaupt nicht zusammen.
Cherry Picking / Verwerfen ungünstiger Daten
Der Begriff „Rosinenpflücken“ basiert auf der Idee, nur die besten Früchte von einem Baum zu pflücken. Jeder, der diese Früchte sieht, muss denken, dass alle Früchte am Baum gleich gesund sind. Offensichtlich ist das nicht unbedingt der Fall.
Dasselbe Prinzip kommt beim Klimawandel zum Tragen. Viele Diagramme beschränken ihren Datenrahmen darauf, nur Klimaveränderungen der Jahre 2000 bis 2013 darzustellen.
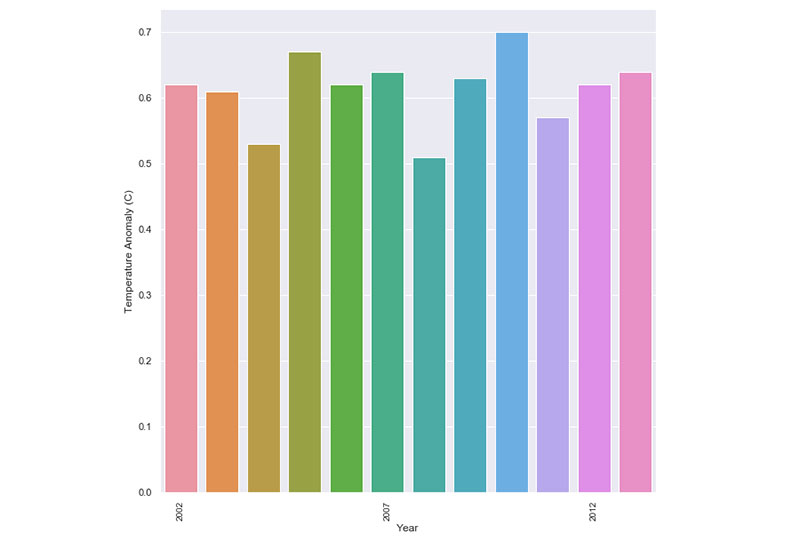
Als Ergebnis scheint es, dass Temperaturänderungen und Anomalien konsistent sind und sich nicht stark ändern. Tritt man jedoch einen Schritt zurück und betrachtet das große Ganze, wird deutlich, wo die Veränderungen und Anomalien liegen.
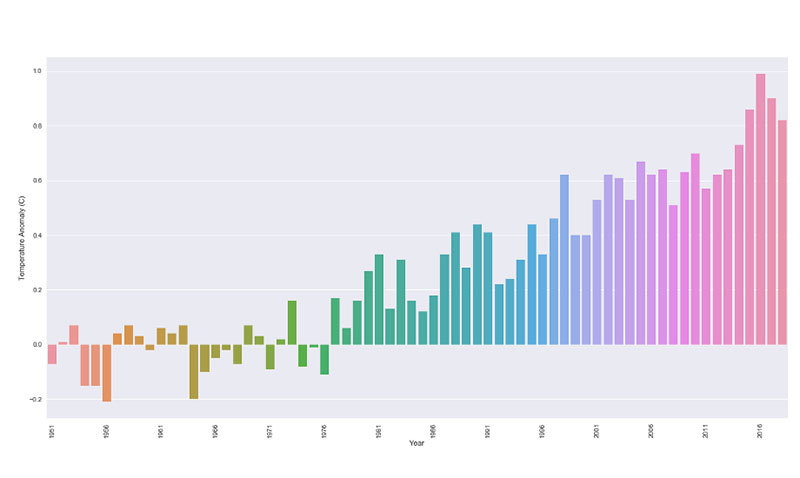
Dies geschieht auch im Bereich der Veterinärmedizin. Wenn Tierärzte gebeten werden, die Ergebnisse eines neuen Prüfmedikaments vorzustellen, präsentieren sie in der Regel die besten Ergebnisse. Besonders wenn ein Pharmaunternehmen die Studie unterstützt, möchte es nur die besten Ergebnisse sehen.
Ihre schönen Daten verdienen es, online zu sein
wpDataTables kann es so machen. Es gibt einen guten Grund, warum es das Nr. 1-WordPress-Plugin zum Erstellen reaktionsschneller Tabellen und Diagramme ist.
Und es ist wirklich einfach, so etwas zu tun:
- Sie stellen die Tabellendaten bereit
- Konfigurieren und anpassen
- Veröffentlichen Sie es in einem Beitrag oder einer Seite
Und es ist nicht nur hübsch, sondern auch praktisch. Sie können große Tabellen mit bis zu Millionen von Zeilen erstellen, oder Sie können erweiterte Filter und Suchen verwenden, oder Sie können wild werden und sie bearbeitbar machen.
„Ja, aber ich mag Excel einfach zu sehr und auf Websites gibt es so etwas nicht“. Ja, das gibt es. Sie können die bedingte Formatierung wie in Excel oder Google Sheets verwenden.
Habe ich Ihnen schon gesagt, dass Sie mit Ihren Daten auch Diagramme erstellen können? Und das ist nur ein kleiner Teil. Es gibt viele andere Funktionen für Sie.
Datenangeln
Datenfischen, auch Data Dredging genannt, ist die Analyse großer Datenmengen mit dem Ziel, einen Zusammenhang zu finden. Wie jedoch bereits in diesem Beitrag besprochen, impliziert Korrelation keine Kausalität. Beharren darauf, dass dies nur zu irreführenden Statistiken führt.
Sie können jeden Tag Beispiele für das Datenfischen in Industriebereichen sehen. Eine Woche wird ein Skandal über Data Mining veröffentlicht, und eine Woche später wird er durch einen noch empörenderen Bericht widerlegt.
Ein weiteres Problem bei dieser Art der Datenanalyse besteht darin, dass Menschen nur die Daten auswählen, die ihre Ansicht stützen, und den Rest ignorieren. Indem widersprüchliche Informationen weggelassen werden, wirken die Ergebnisse überzeugender .
Verwirrende Diagramm- und Diagrammbeschriftungen
Als die COVID-19-Pandemie begann, wandten sich mehr Menschen denn je Datenvisualisierungen der Ausbreitung des Virus zu. Menschen, die nie mit einer visuellen Darstellung von Statistiken arbeiten mussten, wurden plötzlich aus dem tiefen Ende der statistischen Daten geworfen.
Außerdem versuchten Organisationen oft, schnell an Informationen zu gelangen. Manchmal bedeutete das, genaue Statistiken zu opfern. Dies führte zu einem Anstieg irreführender Statistiken und Fehlinterpretationen von Daten.
Ungefähr fünf Monate nach Beginn der Verbreitung von COVID-19 veröffentlichte das US-Gesundheitsministerium von Georgia diese Tabelle:
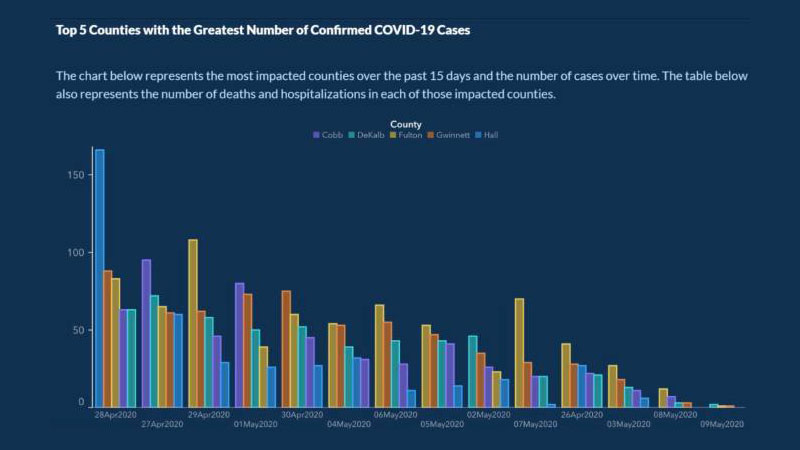
Der Zweck des Diagramms bestand darin, die 5 Länder mit den höchsten COVID-Fällen in den letzten 15 Tagen und die Anzahl der Fälle über einen bestimmten Zeitraum anzuzeigen.
Dieses Diagramm enthält einige Fehler, die es leicht machen, es misszuverstehen. Die x-Achse hat beispielsweise keine Beschriftung, die erklärt, dass sie den Verlauf der Fälle im Laufe der Zeit darstellt.
Schlimmer noch, die Daten auf dem Diagramm sind nicht chronologisch organisiert. Die Daten für April und Mai sind in der Grafik verstreut, um den Eindruck zu erwecken, dass die Zahl der Fälle stetig zurückging. Jedes Land ist auch so aufgelistet, dass es den Anschein erweckt, dass die Fälle zurückgegangen sind.
Später veröffentlichten sie das Diagramm mit besser organisierten Daten und Landkreisen erneut:
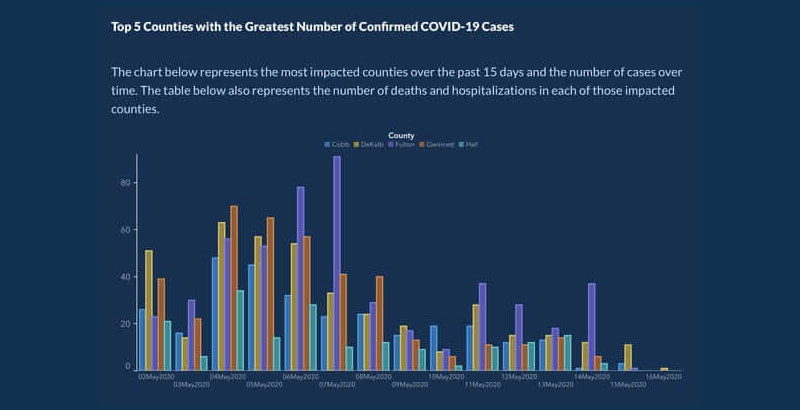
Ungenaue Zahlen
Ein weiteres Beispiel für irreführende Statistiken sind ungenaue Zahlen. Beachten Sie diese Aussage aus einer alten Reebok-Kampagne.
Die Werbung behauptet, dass der Schuh die Kniesehnen und Waden einer Person um 11 % härter trainiert und den Hintern einer Person um bis zu 28 % mehr straffen kann als andere Turnschuhe . Alles, was die Person tun muss, ist in den Turnschuhen zu laufen.
Diese Zahlen lassen den Eindruck entstehen, dass Reebok die Vorteile des Schuhs umfassend erforscht hat.
Die Realität war, dass diese Zahlen komplett erfunden waren. Die Marke erhielt eine Strafe für die Verwendung solcher irreführenden Statistiken. Sie mussten auch die Aussage ändern und die gefälschten Nummern entfernen.
Wie man den Missbrauch von Statistiken vermeidet und erkennt
Statistiken haben das Potenzial, äußerst nützlich zu sein. Aber irreführende Statistiken haben auch das Potenzial, Menschen zu verwirren und zu täuschen. Statistiken geben einer Aussage Autorität und überzeugen die Menschen, auf ein bestimmtes Argument zu vertrauen.
Solide, wahre Statistiken helfen, den Menschen Einblicke zu geben und ihnen zu helfen, Entscheidungen zu treffen. Aber irreführende Statistiken sind gefährlich . Anstatt Menschen dabei zu helfen, Fallstricke und Schlaglöcher zu vermeiden, führen sie Menschen direkt in die Situationen, die sie vermeiden wollten.
Aber es ist möglich, irreführende Statistiken und Daten zu identifizieren. Wenn Sie auf eine Statistik stoßen, halten Sie inne und stellen Sie die folgenden Fragen:
- Woher stammen diese Daten?
- Ist die Quelle kontrolliert? Oder handelt es sich um ein Stichprobenexperiment?
- Welche anderen Faktoren könnten bei diesem Ergebnis eine Rolle spielen?
- Versuchen die Informationen, mich zu informieren, oder leiten sie mich zu einer vorab festgelegten Schlussfolgerung?
Unabhängig davon, ob Sie Daten sammeln oder die Ergebnisse der Forschung anderer anzeigen, stellen Sie sicher, dass die Daten korrekt sind. Auf diese Weise tragen Sie nicht zur Verbreitung irreführender Statistiken bei .
Wenn Ihnen dieser Artikel über irreführende Statistiken gefallen hat, sollten Sie auch diese lesen:
- Die beeindruckendste interaktive Datenvisualisierung, die Sie online finden werden
- Die besten WordPress-Tools zur Datenvisualisierung, die Sie finden können
- Die besten Datenvisualisierungstools und -plattformen für Sie