
So erstellen Sie eine MongoDB-Datenbank: 6 wichtige Aspekte, die Sie kennen sollten
Veröffentlicht: 2022-11-07Basierend auf Ihren Anforderungen an Ihre Software können Sie Flexibilität, Skalierbarkeit, Leistung oder Geschwindigkeit priorisieren. Daher sind Entwickler und Unternehmen oft verwirrt, wenn sie eine Datenbank für ihre Bedürfnisse auswählen. Wenn Sie eine Datenbank benötigen, die hohe Flexibilität und Skalierbarkeit sowie Datenaggregation für Kundenanalysen bietet, ist MongoDB möglicherweise genau das Richtige für Sie!
In diesem Artikel besprechen wir die Struktur der MongoDB-Datenbank und wie Sie Ihre Datenbank erstellen, überwachen und verwalten! Lass uns anfangen.
Wie ist eine MongoDB-Datenbank aufgebaut?
MongoDB ist eine schemalose NoSQL-Datenbank. Das bedeutet, dass Sie für die Tabellen/Datenbanken keine Struktur angeben, wie Sie dies für SQL-Datenbanken tun.
Wussten Sie, dass NoSQL-Datenbanken tatsächlich schneller sind als relationale Datenbanken? Dies liegt an Merkmalen wie Indizierung, Sharding und Aggregationspipelines. MongoDB ist auch für seine schnelle Abfrageausführung bekannt. Aus diesem Grund wird es von Unternehmen wie Google, Toyota und Forbes bevorzugt.
Im Folgenden werden wir einige Schlüsselmerkmale von MongoDB untersuchen.
Unterlagen
MongoDB verfügt über ein Dokumentdatenmodell, das Daten als JSON-Dokumente speichert. Die Dokumente werden auf natürliche Weise den Objekten im Anwendungscode zugeordnet, was die Verwendung für Entwickler einfacher macht.
In einer relationalen Datenbanktabelle müssen Sie eine Spalte hinzufügen, um ein neues Feld hinzuzufügen. Bei Feldern in einem JSON-Dokument ist das nicht der Fall. Felder in einem JSON-Dokument können sich von Dokument zu Dokument unterscheiden, sodass sie nicht jedem Datensatz in der Datenbank hinzugefügt werden.
Dokumente können Strukturen wie Arrays speichern, die verschachtelt werden können, um hierarchische Beziehungen auszudrücken. Darüber hinaus konvertiert MongoDB Dokumente in einen binären JSON-Typ (BSON). Dies gewährleistet einen schnelleren Zugriff und eine verbesserte Unterstützung für verschiedene Datentypen wie Zeichenfolgen, Ganzzahlen, boolesche Zahlen und vieles mehr!
Replikat-Sets
Wenn Sie eine neue Datenbank in MongoDB erstellen, erstellt das System automatisch mindestens 2 weitere Kopien Ihrer Daten. Diese Kopien werden als „Replikatsätze“ bezeichnet und replizieren kontinuierlich Daten zwischen ihnen, um eine verbesserte Verfügbarkeit Ihrer Daten sicherzustellen. Sie bieten auch Schutz vor Ausfallzeiten während eines Systemausfalls oder einer geplanten Wartung.
Sammlungen
Eine Sammlung ist eine Gruppe von Dokumenten, die einer Datenbank zugeordnet sind. Sie ähneln Tabellen in relationalen Datenbanken.
Sammlungen sind jedoch viel flexibler. Zum einen verlassen sie sich nicht auf ein Schema. Zweitens müssen die Dokumente nicht vom gleichen Datentyp sein!
Um eine Liste der Sammlungen anzuzeigen, die zu einer Datenbank gehören, verwenden Sie den Befehl listCollections .
Aggregationspipelines
Sie können dieses Framework verwenden, um mehrere Operatoren und Ausdrücke zu vereinen. Es ist flexibel, weil es Ihnen ermöglicht, Daten beliebiger Struktur zu verarbeiten, umzuwandeln und zu analysieren.
Aus diesem Grund ermöglicht MongoDB schnelle Datenflüsse und Funktionen über 150 Operatoren und Ausdrücke. Es hat auch mehrere Stufen, wie die Union-Stufe, die flexibel Ergebnisse aus mehreren Sammlungen zusammenführt.
Indizes
Sie können jedes Feld in einem MongoDB-Dokument indizieren, um seine Effizienz zu steigern und die Abfragegeschwindigkeit zu verbessern. Die Indexierung spart Zeit, indem der Index gescannt wird, um die geprüften Dokumente zu begrenzen. Ist das nicht viel besser, als jedes Dokument in der Sammlung zu lesen?
Sie können verschiedene Indizierungsstrategien verwenden, einschließlich zusammengesetzter Indizes für mehrere Felder. Angenommen, Sie haben mehrere Dokumente, die den Vor- und Nachnamen des Mitarbeiters in separaten Feldern enthalten. Wenn Sie möchten, dass der Vor- und Nachname zurückgegeben wird, können Sie einen Index erstellen, der sowohl „Nachname“ als auch „Vorname“ enthält. Das wäre viel besser, als einen Index auf „Nachname“ und einen anderen auf „Vorname“ zu haben.
Sie können Tools wie Performance Advisor nutzen, um besser zu verstehen, welche Abfrage von Indizes profitieren könnte.
Scherben
Sharding verteilt ein einzelnes Dataset auf mehrere Datenbanken. Dieser Datensatz kann dann auf mehreren Computern gespeichert werden, um die Gesamtspeicherkapazität eines Systems zu erhöhen. Dies liegt daran, dass größere Datensätze in kleinere Blöcke aufgeteilt und in verschiedenen Datenknoten gespeichert werden.
MongoDB fragmentiert Daten auf Sammlungsebene und verteilt Dokumente in einer Sammlung über die Shards in einem Cluster. Dies stellt die Skalierbarkeit sicher, indem es der Architektur ermöglicht wird, die größten Anwendungen zu handhaben.
So erstellen Sie eine MongoDB-Datenbank
Sie müssen zuerst das richtige MongoDB-Paket installieren, das für Ihr Betriebssystem geeignet ist. Rufen Sie die Seite „MongoDB Community Server herunterladen“ auf. Wählen Sie aus den verfügbaren Optionen die neueste „Version“, das „Paket“-Format als ZIP-Datei und „Plattform“ als Ihr Betriebssystem aus und klicken Sie auf „Herunterladen“, wie unten dargestellt:
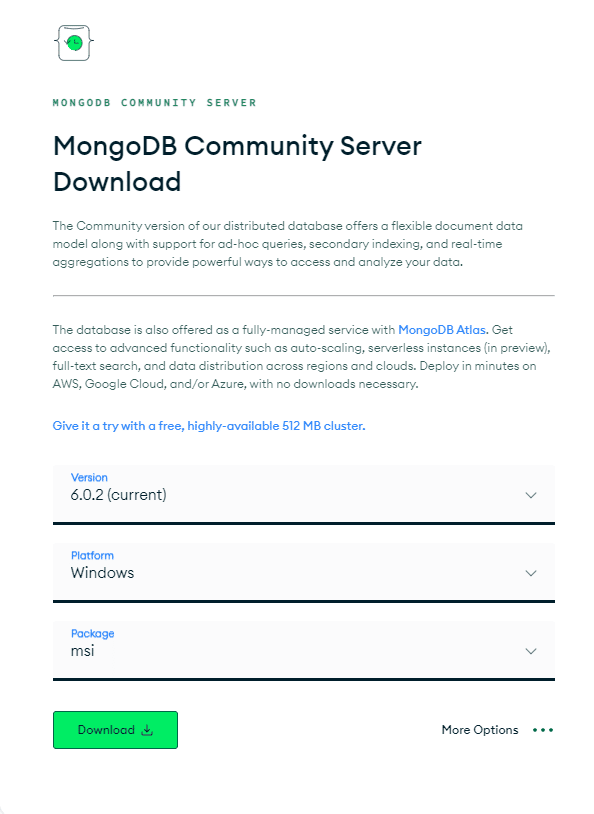
Der Prozess ist ganz einfach, sodass Sie MongoDB im Handumdrehen in Ihrem System installiert haben!
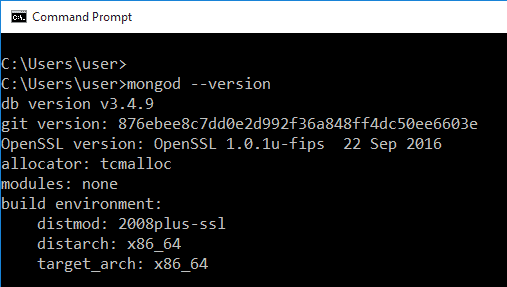
Sobald Sie die Installation abgeschlossen haben, öffnen Sie Ihre Eingabeaufforderung und mongod -version , um sie zu überprüfen. Wenn Sie die folgende Ausgabe nicht erhalten und stattdessen eine Reihe von Fehlern sehen, müssen Sie sie möglicherweise neu installieren:
Verwenden der MongoDB-Shell
Bevor wir beginnen, vergewissern Sie sich, dass:
- Ihr Client verfügt über Transport Layer Security und befindet sich auf Ihrer IP-Zulassungsliste.
- Sie haben ein Benutzerkonto und ein Passwort für den gewünschten MongoDB-Cluster.
- Sie haben MongoDB auf Ihrem Gerät installiert.
Schritt 1: Greifen Sie auf die MongoDB-Shell zu
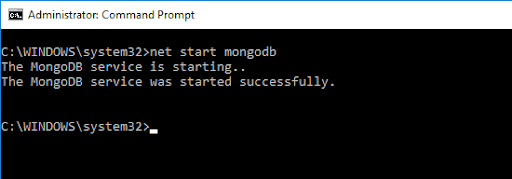
Geben Sie den folgenden Befehl ein, um Zugriff auf die MongoDB-Shell zu erhalten:
net start MongoDBDies sollte die folgende Ausgabe ergeben:
Der vorherige Befehl hat den MongoDB-Server initialisiert. Um es auszuführen, müssten wir mongo in die Eingabeaufforderung eingeben.
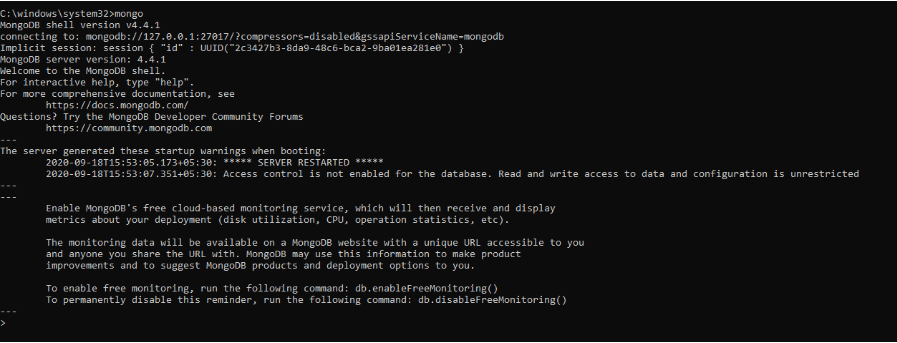
Hier in der MongoDB-Shell können wir Befehle ausführen, um Datenbanken zu erstellen, Daten einzufügen, Daten zu bearbeiten, Verwaltungsbefehle auszugeben und Daten zu löschen.
Schritt 2: Erstellen Sie Ihre Datenbank
Im Gegensatz zu SQL hat MongoDB keinen Befehl zur Datenbankerstellung. Stattdessen gibt es ein Schlüsselwort namens use , das zu einer bestimmten Datenbank wechselt. Wenn die Datenbank nicht existiert, wird eine neue Datenbank erstellt, andernfalls wird sie mit der vorhandenen Datenbank verknüpft.
Um beispielsweise eine Datenbank mit dem Namen „Firma“ zu initiieren, geben Sie Folgendes ein:
use Company 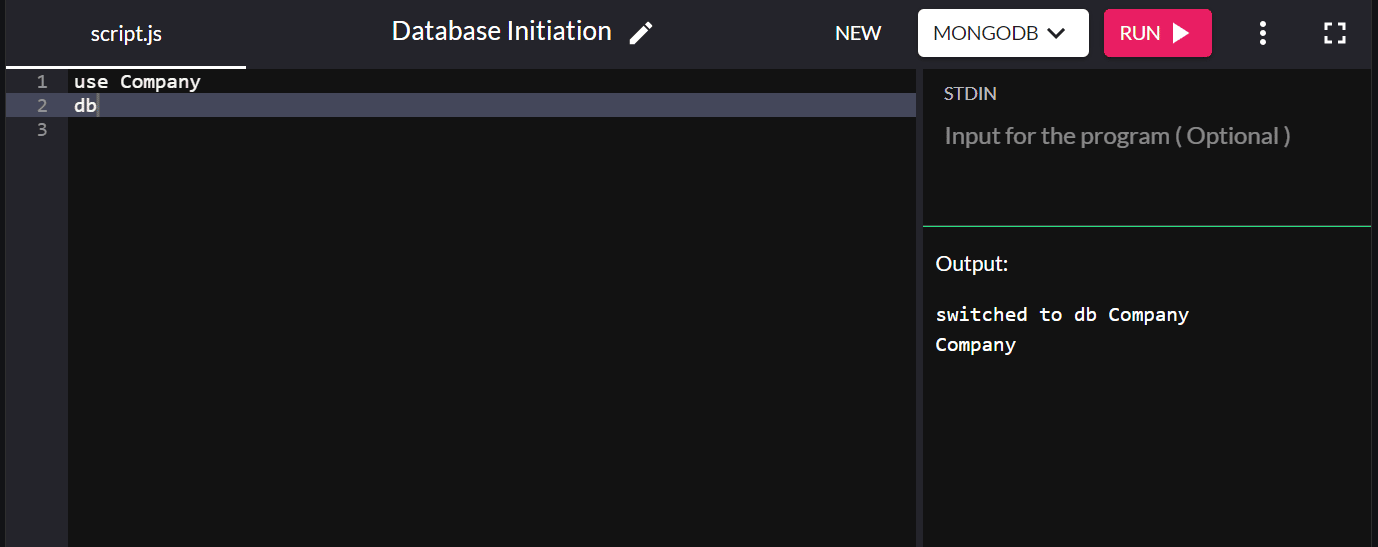
Sie können db , um die Datenbank zu bestätigen, die Sie gerade in Ihrem System erstellt haben. Wenn die neue Datenbank, die Sie erstellt haben, angezeigt wird, haben Sie erfolgreich eine Verbindung damit hergestellt.
Wenn Sie die vorhandenen Datenbanken überprüfen möchten, geben Sie show dbs und es werden alle Datenbanken in Ihrem System zurückgegeben:
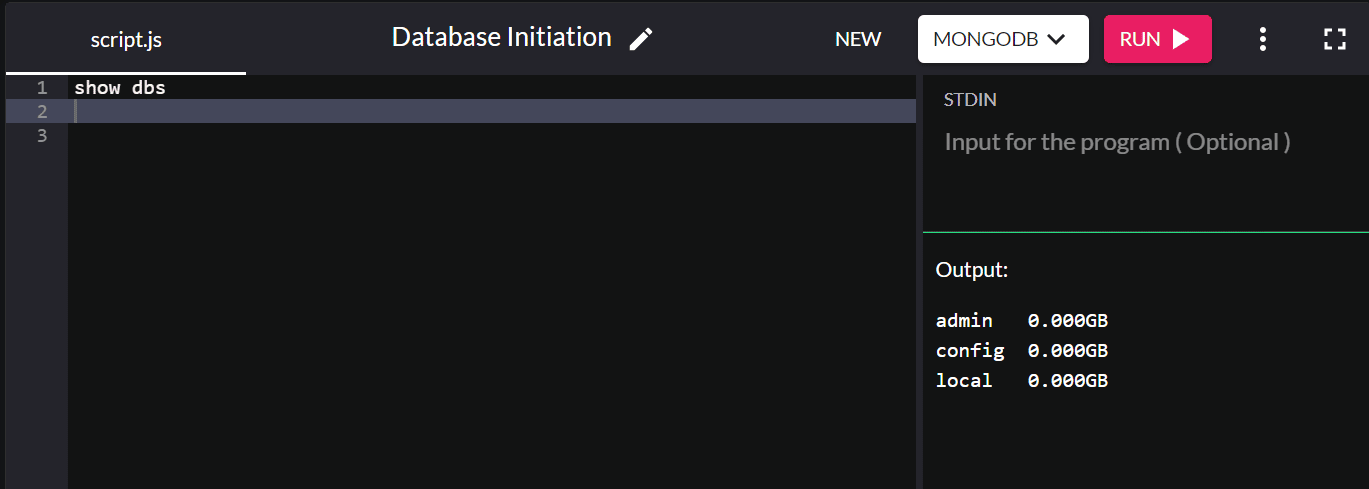
Standardmäßig werden bei der Installation von MongoDB die Datenbanken „admin“, „config“ und „local“ erstellt.
Haben Sie bemerkt, dass die von uns erstellte Datenbank nicht angezeigt wird? Dies liegt daran, dass wir noch keine Werte in der Datenbank gespeichert haben! Wir werden das Einfügen im Abschnitt Datenbankverwaltung besprechen.
Verwenden der Atlas-Benutzeroberfläche
Sie könnten auch mit Atlas, dem Datenbankdienst von MongoDB, beginnen. Während Sie möglicherweise bezahlen müssen, um auf einige Funktionen von Atlas zuzugreifen, sind die meisten Datenbankfunktionen mit dem kostenlosen Kontingent verfügbar. Die Funktionen der kostenlosen Stufe sind mehr als genug, um eine MongoDB-Datenbank zu erstellen.
Bevor wir beginnen, vergewissern Sie sich, dass:
- Ihre IP ist auf der Zulassungsliste.
- Sie haben ein Benutzerkonto und ein Passwort für den MongoDB-Cluster, den Sie verwenden möchten.
Öffnen Sie zum Erstellen einer MongoDB-Datenbank mit AtlasUI ein Browserfenster und melden Sie sich bei https://cloud.mongodb.com an. Klicken Sie auf Ihrer Cluster-Seite auf Sammlungen durchsuchen . Wenn im Cluster keine Datenbanken vorhanden sind, können Sie Ihre Datenbank erstellen, indem Sie auf die Schaltfläche Eigene Daten hinzufügen klicken.
In der Eingabeaufforderung werden Sie aufgefordert, eine Datenbank und einen Sammlungsnamen anzugeben. Sobald Sie sie benannt haben, klicken Sie auf Erstellen und Sie sind fertig! Sie können jetzt neue Dokumente eingeben oder sich über Treiber mit der Datenbank verbinden.
Verwalten Ihrer MongoDB-Datenbank
In diesem Abschnitt gehen wir auf ein paar raffinierte Möglichkeiten zur effektiven Verwaltung Ihrer MongoDB-Datenbank ein. Sie können dies entweder mit dem MongoDB-Kompass oder über Sammlungen tun.
Sammlungen verwenden
Während relationale Datenbanken wohldefinierte Tabellen mit festgelegten Datentypen und Spalten besitzen, hat NoSQL Sammlungen anstelle von Tabellen. Diese Sammlungen haben keine Struktur und Dokumente können variieren – Sie können unterschiedliche Datentypen und Felder haben, ohne das Format eines anderen Dokuments in derselben Sammlung anpassen zu müssen.
Um dies zu demonstrieren, erstellen wir eine Sammlung mit dem Namen „Employee“ und fügen ihr ein Dokument hinzu:
db.Employee.insert( { "Employeename" : "Chris", "EmployeeDepartment" : "Sales" } ) Wenn das Einfügen erfolgreich ist, wird WriteResult({ "nInserted" : 1 }) :
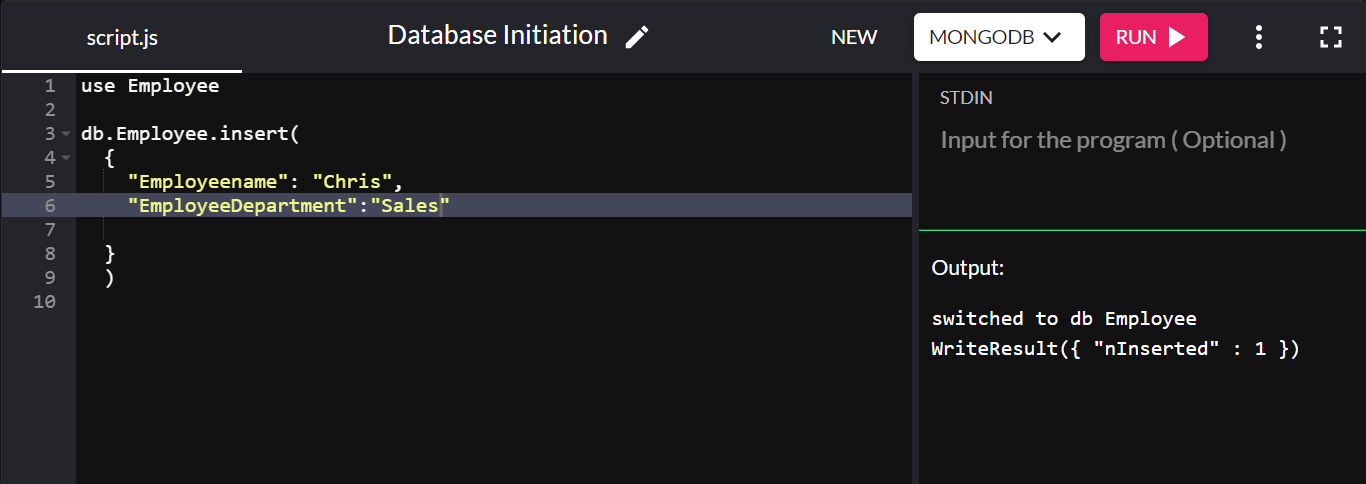
„db“ bezieht sich hier auf die aktuell verbundene Datenbank. „Mitarbeiter“ ist die neu erstellte Sammlung in der Unternehmensdatenbank.
Wir haben hier keinen Primärschlüssel festgelegt, da MongoDB automatisch ein Primärschlüsselfeld namens „_id“ erstellt und einen Standardwert dafür festlegt.
Führen Sie den folgenden Befehl aus, um die Sammlung im JSON-Format auszuchecken:
db.Employee.find().forEach(printjson)Ausgabe:
{ "_id" : ObjectId("63151427a4dd187757d135b8"), "Employeename" : "Chris", "EmployeeDepartment" : "Sales" }Während der „_id“-Wert automatisch zugewiesen wird, könnten Sie den Wert des Standard-Primärschlüssels ändern. Dieses Mal fügen wir ein weiteres Dokument in die „Employee“-Datenbank ein, wobei der „_id“-Wert „1“ ist:
db.Employee.insert( { "_id" : 1, "EmployeeName" : "Ava", "EmployeeDepartment" : "Public Relations" } ) Beim Ausführen des Befehls db.Employee.find().forEach(printjson) erhalten wir die folgende Ausgabe:
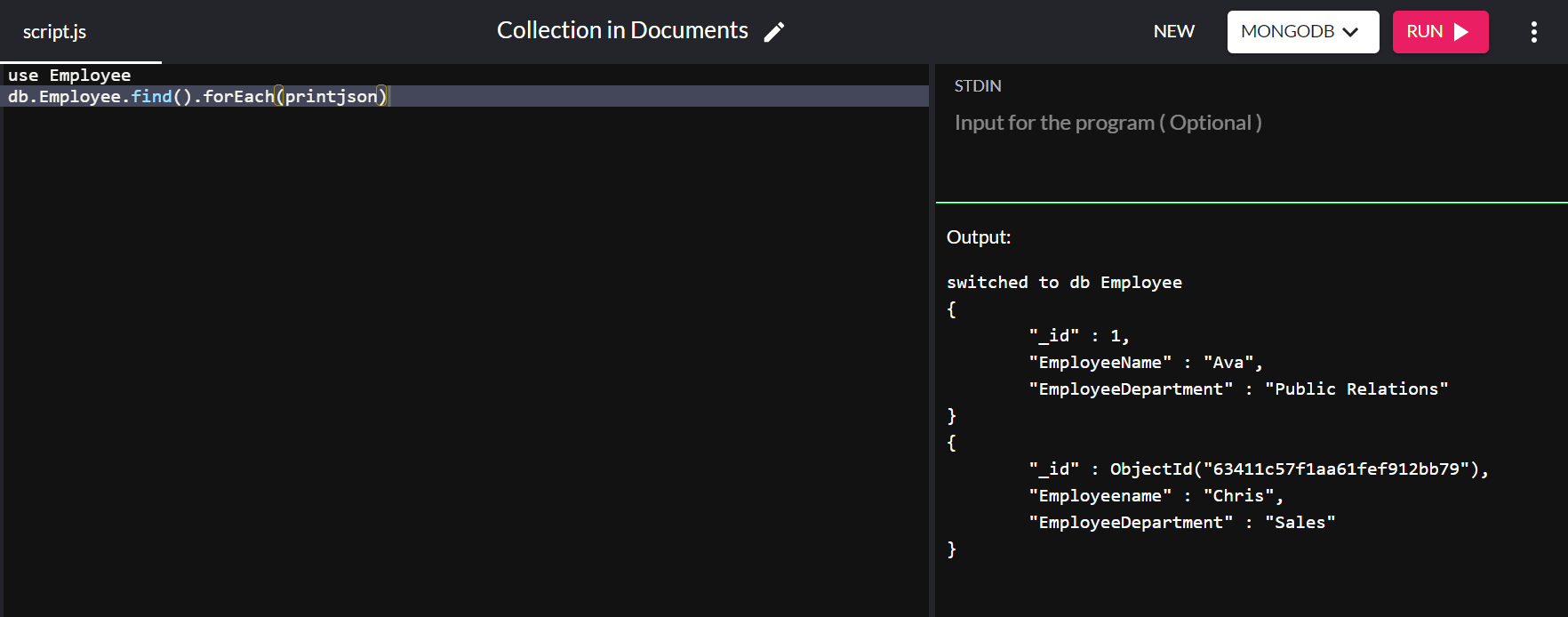
In der obigen Ausgabe wird der „_id“-Wert für „Ava“ auf „1“ gesetzt, anstatt automatisch einen Wert zuzuweisen.
Nachdem wir der Datenbank erfolgreich Werte hinzugefügt haben, können wir mit dem folgenden Befehl überprüfen, ob sie unter den vorhandenen Datenbanken in unserem System angezeigt werden:
show dbs 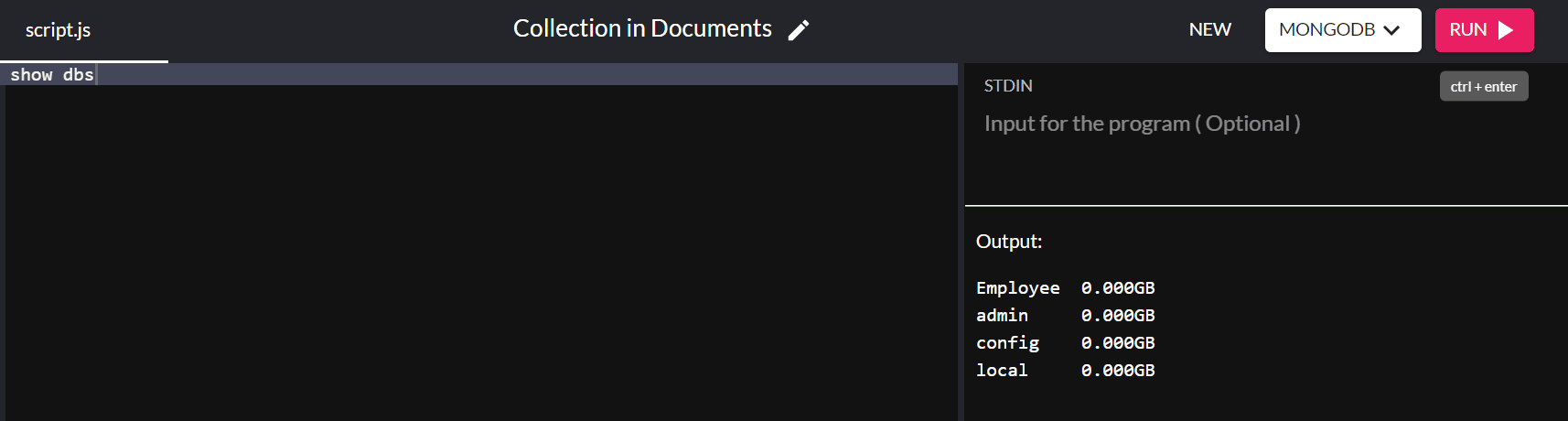
Und voila! Sie haben erfolgreich eine Datenbank in Ihrem System erstellt!
Verwenden des MongoDB-Kompasses
Obwohl wir mit MongoDB-Servern aus der Mongo-Shell arbeiten können, kann es manchmal mühsam sein. Dies kann in einer Produktionsumgebung auftreten.
Es gibt jedoch ein von MongoDB erstelltes Kompass-Tool (mit dem passenden Namen Compass), das dies vereinfachen kann. Es verfügt über eine bessere GUI und zusätzliche Funktionen wie Datenvisualisierung, Leistungsprofilerstellung und CRUD-Zugriff (Erstellen, Lesen, Aktualisieren, Löschen) auf Daten, Datenbanken und Sammlungen.
Sie können die Compass IDE für Ihr Betriebssystem herunterladen und mit einem einfachen Prozess installieren.
Öffnen Sie als Nächstes die Anwendung und erstellen Sie eine Verbindung mit dem Server, indem Sie die Verbindungszeichenfolge einfügen. Wenn Sie es nicht finden können, können Sie auf Verbindungsfelder einzeln ausfüllen klicken. Wenn Sie die Portnummer während der Installation von MongoDB nicht geändert haben, klicken Sie einfach auf die Schaltfläche „Verbinden“ und schon sind Sie dabei! Andernfalls geben Sie einfach die von Ihnen festgelegten Werte ein und klicken Sie auf Verbinden .
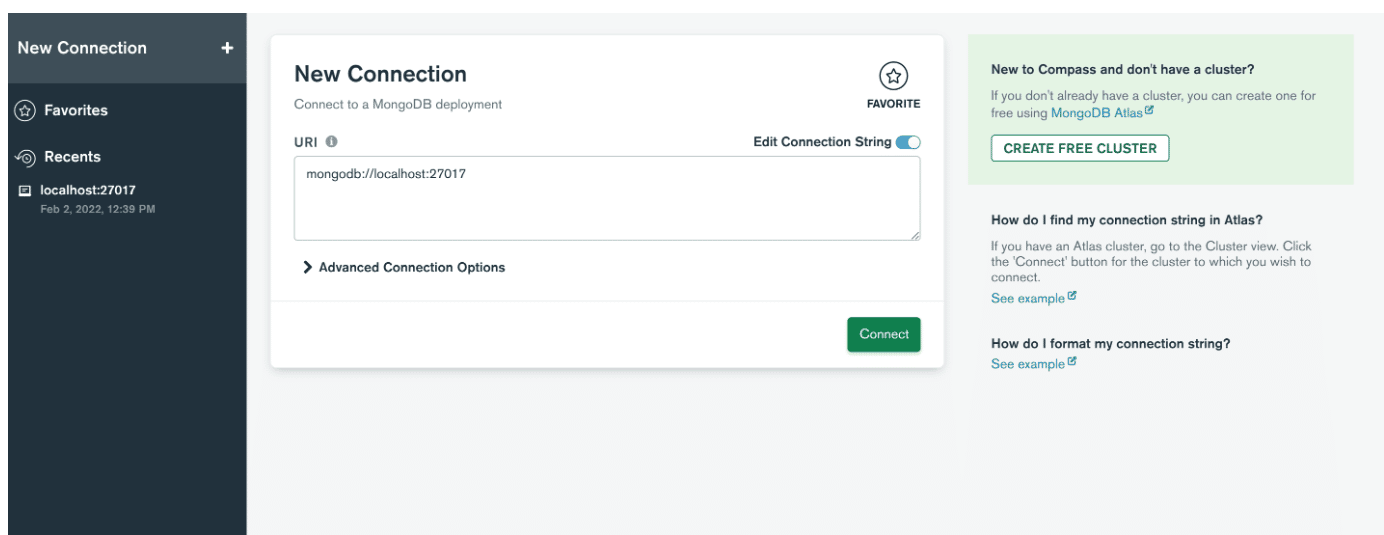
Geben Sie als Nächstes den Hostnamen, den Port und die Authentifizierung im Fenster „Neue Verbindung“ an.
In MongoDB Compass können Sie eine Datenbank erstellen und gleichzeitig ihre erste Sammlung hinzufügen. So geht's:
- Klicken Sie auf Datenbank erstellen , um die Eingabeaufforderung zu öffnen.
- Geben Sie den Namen der Datenbank und ihre erste Sammlung ein.
- Klicken Sie auf Datenbank erstellen .
Sie können weitere Dokumente in Ihre Datenbank einfügen, indem Sie auf den Namen Ihrer Datenbank und dann auf den Namen der Sammlung klicken, um die Registerkarte Dokumente anzuzeigen. Sie können dann auf die Schaltfläche Daten hinzufügen klicken, um ein oder mehrere Dokumente in Ihre Sammlung einzufügen.
Beim Hinzufügen Ihrer Dokumente können Sie diese einzeln oder als mehrere Dokumente in einer Reihe eingeben. Wenn Sie mehrere Dokumente hinzufügen, stellen Sie sicher, dass diese durch Kommas getrennten Dokumente in eckige Klammern eingeschlossen sind. Zum Beispiel:
{ _id: 1, item: { name: "apple", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }, { _id: 2, item: { name: "banana", code: "123" }, qty: 20, tags: [ "B" ] }, { _id: 3, item: { name: "spinach", code: "456" }, qty: 25, tags: [ "A", "B" ] }, { _id: 4, item: { name: "lentils", code: "456" }, qty: 30, tags: [ "B", "A" ] }, { _id: 5, item: { name: "pears", code: "000" }, qty: 20, tags: [ [ "A", "B" ], "C" ] }, { _id: 6, item: { name: "strawberry", code: "123" }, tags: [ "B" ] }Klicken Sie abschließend auf Einfügen , um die Dokumente zu Ihrer Sammlung hinzuzufügen. So würde der Körper eines Dokuments aussehen:
{ "StudentID" : 1 "StudentName" : "JohnDoe" }Die Feldnamen lauten hier „StudentID“ und „StudentName“. Die Feldwerte sind „1“ bzw. „JohnDoe“.
Nützliche Befehle
Sie können diese Sammlungen über Rollenverwaltungs- und Benutzerverwaltungsbefehle verwalten.
Benutzerverwaltungsbefehle
MongoDB-Benutzerverwaltungsbefehle enthalten Befehle, die sich auf den Benutzer beziehen. Mit diesen Befehlen können wir die Benutzer erstellen, aktualisieren und löschen.
dropUser
Dieser Befehl entfernt einen einzelnen Benutzer aus der angegebenen Datenbank. Unten ist die Syntax:
db.dropUser(username, writeConcern) username ist hier ein Pflichtfeld, das das Dokument mit Authentifizierungs- und Zugangsinformationen über den Benutzer enthält. Das optionale Feld writeConcern enthält den Grad der Schreibbetroffenheit für die Erstellungsoperation. Der Grad der Schreibbedenken kann durch das optionale Feld writeConcern bestimmt werden.
Stellen Sie vor dem Löschen eines Benutzers mit der Rolle userAdminAnyDatabase sicher, dass es mindestens einen anderen Benutzer mit Benutzerverwaltungsberechtigungen gibt.
In diesem Beispiel löschen wir den Benutzer „user26“ in der Testdatenbank:
use test db.dropUser("user26", {w: "majority", wtimeout: 4000})Ausgabe:
> db.dropUser("user26", {w: "majority", wtimeout: 4000}); trueBenutzer erstellen
Dieser Befehl erstellt wie folgt einen neuen Benutzer für die angegebene Datenbank:
db.createUser(user, writeConcern) user ist hier ein Pflichtfeld, das das Dokument mit Authentifizierungs- und Zugangsinformationen über den zu erstellenden Benutzer enthält. Das optionale Feld writeConcern enthält den Grad der Schreibbetroffenheit für die Erstellungsoperation. Die Ebene der Schreibbedenken kann durch das optionale Feld writeConcern bestimmt werden.
createUser gibt einen doppelten Benutzerfehler zurück, wenn der Benutzer bereits in der Datenbank vorhanden ist.
Sie können einen neuen Benutzer in der Testdatenbank wie folgt erstellen:
use test db.createUser( { user: "user26", pwd: "myuser123", roles: [ "readWrite" ] } );Die Ausgabe ist wie folgt:
Successfully added user: { "user" : "user26", "roles" : [ "readWrite", "dbAdmin" ] }GrantRolesToUser
Sie können diesen Befehl nutzen, um einem Benutzer zusätzliche Rollen zuzuweisen. Um es zu verwenden, müssen Sie die folgende Syntax beachten:
db.runCommand( { grantRolesToUser: "<user>", roles: [ <roles> ], writeConcern: { <write concern> }, comment: <any> } ) Sie können in den oben genannten Rollen sowohl benutzerdefinierte als auch integrierte Rollen angeben. Wenn Sie eine Rolle angeben möchten, die in derselben Datenbank vorhanden ist, in der grantRolesToUser wird, können Sie die Rolle entweder mit einem Dokument angeben, wie unten erwähnt:
{ role: "<role>", db: "<database>" }Oder Sie können die Rolle einfach mit dem Namen der Rolle angeben. Zum Beispiel:
"readWrite"Wenn Sie die Rolle angeben möchten, die in einer anderen Datenbank vorhanden ist, müssen Sie die Rolle mit einem anderen Dokument angeben.
Um einer Datenbank eine Rolle zuzuweisen, benötigen Sie die Aktion grantRole für die angegebene Datenbank.
Hier ist ein Beispiel, um Ihnen ein klares Bild zu geben. Nehmen Sie zum Beispiel einen Benutzer productUser00 in der Produktdatenbank mit den folgenden Rollen:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" } ] Die Operation grantRolesToUser stellt „productUser00“ die readWrite Rolle in der Bestandsdatenbank und die read-Rolle in der Produktdatenbank bereit:
use products db.runCommand({ grantRolesToUser: "productUser00", roles: [ { role: "readWrite", db: "stock"}, "read" ], writeConcern: { w: "majority" , wtimeout: 2000 } })Der Benutzer productUser00 in der Produktdatenbank besitzt nun folgende Rollen:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ]BenutzerInfo
Sie können den Befehl usersInfo verwenden, um Informationen zu einem oder mehreren Benutzern zurückzugeben. Hier ist die Syntax:
db.runCommand( { usersInfo: <various>, showCredentials: <Boolean>, showCustomData: <Boolean>, showPrivileges: <Boolean>, showAuthenticationRestrictions: <Boolean>, filter: <document>, comment: <any> } ) { usersInfo: <various> } In Bezug auf den Zugriff können Benutzer immer ihre eigenen Informationen einsehen. Um die Informationen eines anderen Benutzers anzuzeigen, muss der Benutzer, der den Befehl ausführt, über Berechtigungen verfügen, die die Aktion viewUser für die Datenbank des anderen Benutzers beinhalten.
Beim Ausführen des userInfo können Sie abhängig von den angegebenen Optionen die folgenden Informationen abrufen:
{ "users" : [ { "_id" : "<db>.<username>", "userId" : <UUID>, // Starting in MongoDB 4.0.9 "user" : "<username>", "db" : "<db>", "mechanisms" : [ ... ], // Starting in MongoDB 4.0 "customData" : <document>, "roles" : [ ... ], "credentials": { ... }, // only if showCredentials: true "inheritedRoles" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedPrivileges" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedAuthenticationRestrictions" : [ ] // only if showPrivileges: true or showAuthenticationRestrictions: true "authenticationRestrictions" : [ ... ] // only if showAuthenticationRestrictions: true }, ], "ok" : 1 } Nachdem Sie nun eine allgemeine Vorstellung davon haben, was Sie mit dem Befehl usersInfo erreichen können, könnte die nächste offensichtliche Frage auftauchen, welche Befehle nützlich wären, um bestimmte Benutzer und mehrere Benutzer zu untersuchen.
Hier sind zwei praktische Beispiele, um dasselbe zu veranschaulichen:
Führen Sie den folgenden Befehl aus, um die spezifischen Berechtigungen und Informationen für bestimmte Benutzer, aber nicht die Anmeldeinformationen, für einen Benutzer „Anthony“ anzuzeigen, der in der „Office“-Datenbank definiert ist:
db.runCommand( { usersInfo: { user: "Anthony", db: "office" }, showPrivileges: true } )Wenn Sie sich einen Benutzer in der aktuellen Datenbank ansehen möchten, können Sie den Benutzer nur namentlich nennen. Wenn Sie sich beispielsweise in der Home-Datenbank befinden und ein Benutzer namens „Timothy“ in der Home-Datenbank vorhanden ist, können Sie den folgenden Befehl ausführen:
db.getSiblingDB("home").runCommand( { usersInfo: "Timothy", showPrivileges: true } ) Als Nächstes können Sie ein Array verwenden, wenn Sie die Informationen für verschiedene Benutzer anzeigen möchten. Sie können entweder die optionalen Felder showCredentials und showPrivileges oder sie weglassen. So würde der Befehl aussehen:
db.runCommand({ usersInfo: [ { user: "Anthony", db: "office" }, { user: "Timothy", db: "home" } ], showPrivileges: true })WiderrufenRolesFromUser
Sie können den Befehl revokeRolesFromUser , um eine oder mehrere Rollen von einem Benutzer in der Datenbank zu entfernen, in der die Rollen vorhanden sind. Der Befehl revokeRolesFromUser hat die folgende Syntax:
db.runCommand( { revokeRolesFromUser: "<user>", roles: [ { role: "<role>", db: "<database>" } | "<role>", ], writeConcern: { <write concern> }, comment: <any> } ) In der oben erwähnten Syntax können Sie sowohl benutzerdefinierte als auch integrierte Rollen im roles angeben. Ähnlich wie beim Befehl grantRolesToUser können Sie die Rolle, die Sie widerrufen möchten, in einem Dokument angeben oder ihren Namen verwenden.
Um den Befehl revokeRolesFromUser erfolgreich auszuführen, muss die Aktion revokeRole in der angegebenen Datenbank vorhanden sein.
Hier ist ein Beispiel, um den Punkt nach Hause zu bringen. Die Entität productUser00 in der Produktdatenbank hatte die folgenden Rollen:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ] Der folgende Befehl revokeRolesFromUser entfernt zwei der Rollen des Benutzers: die Rolle „Lesen“ aus products und die Rolle „ assetsWriter “ aus der Datenbank „Assets“:
use products db.runCommand( { revokeRolesFromUser: "productUser00", roles: [ { role: "AssetsWriter", db: "assets" }, "read" ], writeConcern: { w: "majority" } } )Der Benutzer „productUser00“ in der Produktdatenbank hat jetzt nur noch eine Rolle:

"roles" : [ { "role" : "readWrite", "db" : "stock" } ]Befehle zur Rollenverwaltung
Rollen gewähren Benutzern Zugriff auf Ressourcen. Mehrere integrierte Rollen können von Administratoren verwendet werden, um den Zugriff auf ein MongoDB-System zu steuern. Wenn die Rollen die gewünschten Berechtigungen nicht abdecken, können Sie sogar noch weiter gehen und neue Rollen in einer bestimmten Datenbank erstellen.
dropRole
Mit dem Befehl dropRole können Sie eine benutzerdefinierte Rolle aus der Datenbank löschen, auf der Sie den Befehl ausführen. Um diesen Befehl auszuführen, verwenden Sie die folgende Syntax:
db.runCommand( { dropRole: "<role>", writeConcern: { <write concern> }, comment: <any> } ) Für eine erfolgreiche Ausführung muss die dropRole Aktion in der angegebenen Datenbank vorhanden sein. Die folgenden Operationen würden die Rolle „ writeTags “ aus der „products“-Datenbank entfernen:
use products db.runCommand( { dropRole: "writeTags", writeConcern: { w: "majority" } } )Rolle erstellen
Sie können den Befehl createRole , um eine Rolle zu erstellen und ihre Berechtigungen anzugeben. Die Rolle gilt für die Datenbank, für die Sie den Befehl ausführen möchten. Der Befehl createRole würde einen doppelten Rollenfehler zurückgeben, wenn die Rolle bereits in der Datenbank vorhanden ist.
Um diesen Befehl auszuführen, folgen Sie der angegebenen Syntax:
db.adminCommand( { createRole: "<new role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], roles: [ { role: "<role>", db: "<database>" } | "<role>", ], authenticationRestrictions: [ { clientSource: ["<IP>" | "<CIDR range>", ...], serverAddress: ["<IP>" | "<CIDR range>", ...] }, ], writeConcern: <write concern document>, comment: <any> } )Die Berechtigungen einer Rolle gelten für die Datenbank, in der die Rolle erstellt wurde. Die Rolle kann Berechtigungen von anderen Rollen in ihrer Datenbank erben. Beispielsweise kann eine Rolle, die für die Datenbank „admin“ erstellt wurde, Berechtigungen enthalten, die entweder für einen Cluster oder für alle Datenbanken gelten. Es kann auch Berechtigungen von Rollen erben, die in anderen Datenbanken vorhanden sind.
Um eine Rolle in einer Datenbank zu erstellen, benötigen Sie zwei Dinge:
- Die Aktion
grantRolein dieser Datenbank, um Berechtigungen für die neue Rolle sowie Rollen zu erwähnen, von denen geerbt werden soll. - Die
createRoleAktion für diese Datenbankressource.
Der folgende createRole Befehl erstellt eine clusterAdmin Rolle in der Benutzerdatenbank:
db.adminCommand({ createRole: "clusterAdmin", privileges: [ { resource: { cluster: true }, actions: [ "addShard" ] }, { resource: { db: "config", collection: "" }, actions: [ "find", "remove" ] }, { resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert" ] }, { resource: { db: "", collection: "" }, actions: [ "find" ] } ], roles: [ { role: "read", db: "user" } ], writeConcern: { w: "majority" , wtimeout: 5000 } })GrantRolesToRole
Mit dem Befehl grantRolesToRole können Sie einer benutzerdefinierten Rolle Rollen zuweisen. Der Befehl grantRolesToRole würde sich auf Rollen in der Datenbank auswirken, in der der Befehl ausgeführt wird.
Dieser grantRolesToRole Befehl hat die folgende Syntax:
db.runCommand( { grantRolesToRole: "<role>", roles: [ { role: "<role>", db: "<database>" }, ], writeConcern: { <write concern> }, comment: <any> } ) Die Zugriffsrechte ähneln denen des Befehls grantRolesToUser – für die ordnungsgemäße Ausführung des Befehls benötigen Sie eine grantRole Aktion für eine Datenbank.
Im folgenden Beispiel können Sie den Befehl grantRolesToUser verwenden, um die Rolle productsReader in der Datenbank „products“ so zu aktualisieren, dass sie die Berechtigungen der Rolle productsWriter erbt:
use products db.runCommand( { grantRolesToRole: "productsReader", roles: [ "productsWriter" ], writeConcern: { w: "majority" , wtimeout: 5000 } } )revokePrivilegesFromRole
Sie können revokePrivilegesFromRole verwenden, um die angegebenen Berechtigungen von der benutzerdefinierten Rolle in der Datenbank zu entfernen, in der der Befehl ausgeführt wird. Für eine ordnungsgemäße Ausführung müssen Sie die folgende Syntax beachten:
db.runCommand( { revokePrivilegesFromRole: "<role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], writeConcern: <write concern document>, comment: <any> } )Um eine Berechtigung zu widerrufen, muss das Muster „Ressourcendokument“ mit dem „Ressourcen“-Feld dieser Berechtigung übereinstimmen. Das Feld „Aktionen“ kann entweder eine genaue Übereinstimmung oder eine Teilmenge sein.
Betrachten Sie beispielsweise die Rolle manageRole in der Produktdatenbank mit den folgenden Berechtigungen, die die Datenbank „managers“ als Ressource angeben:
{ "resource" : { "db" : "managers", "collection" : "" }, "actions" : [ "insert", "remove" ] }Sie können die Aktionen „Einfügen“ oder „Entfernen“ nicht von nur einer Sammlung in der Manager-Datenbank widerrufen. Die folgenden Operationen bewirken keine Änderung der Rolle:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert", "remove" ] } ] } ) db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert" ] } ] } ) Um die „insert“- und/oder „remove“-Aktionen der Rolle manageRole zu widerrufen, müssen Sie das Ressourcendokument genau abgleichen. Beispielsweise widerruft die folgende Operation nur die Aktion „Entfernen“ von der vorhandenen Berechtigung:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "" }, actions : [ "remove" ] } ] } )Der folgende Vorgang entfernt mehrere Berechtigungen von der Rolle „Executive“ in der Manager-Datenbank:
use managers db.runCommand( { revokePrivilegesFromRole: "executive", privileges: [ { resource: { db: "managers", collection: "" }, actions: [ "insert", "remove", "find" ] }, { resource: { db: "managers", collection: "partners" }, actions: [ "update" ] } ], writeConcern: { w: "majority" } } )RollenInfo
Der Befehl rolesInfo gibt Berechtigungs- und Vererbungsinformationen für bestimmte Rollen zurück, einschließlich integrierter und benutzerdefinierter Rollen. Sie können auch den Befehl rolesInfo , um alle Rollen abzurufen, die für eine Datenbank gelten.
Befolgen Sie für eine ordnungsgemäße Ausführung diese Syntax:
db.runCommand( { rolesInfo: { role: <name>, db: <db> }, showPrivileges: <Boolean>, showBuiltinRoles: <Boolean>, comment: <any> } )Um Informationen für eine Rolle aus der aktuellen Datenbank zurückzugeben, können Sie ihren Namen wie folgt angeben:
{ rolesInfo: "<rolename>" }Um Informationen für eine Rolle aus einer anderen Datenbank zurückzugeben, können Sie die Rolle mit einem Dokument erwähnen, das die Rolle und die Datenbank erwähnt:
{ rolesInfo: { role: "<rolename>", db: "<database>" } }Der folgende Befehl gibt beispielsweise die Rollenvererbungsinformationen für die in der Manager-Datenbank definierte Rollenführungskraft zurück:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" } } ) Dieser nächste Befehl gibt die Rollenvererbungsinformationen zurück: accountManager in der Datenbank, in der der Befehl ausgeführt wird:
db.runCommand( { rolesInfo: "accountManager" } )Der folgende Befehl gibt sowohl die Berechtigungen als auch die Rollenvererbung für die Rolle „Executive“ zurück, wie sie in der Manager-Datenbank definiert ist:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" }, showPrivileges: true } )Um mehrere Rollen zu erwähnen, können Sie ein Array verwenden. Sie können auch jede Rolle im Array als Zeichenfolge oder Dokument erwähnen.
Sie sollten nur dann eine Zeichenfolge verwenden, wenn die Rolle in der Datenbank vorhanden ist, auf der der Befehl ausgeführt wird:
{ rolesInfo: [ "<rolename>", { role: "<rolename>", db: "<database>" }, ] }Der folgende Befehl gibt beispielsweise Informationen für drei Rollen in drei verschiedenen Datenbanken zurück:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ] } )Sie können sowohl die Privilegien als auch die Rollenvererbung wie folgt erhalten:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ], showPrivileges: true } )Einbetten von MongoDB-Dokumenten für eine bessere Leistung
Mit Dokumentendatenbanken wie MongoDB können Sie Ihr Schema gemäß Ihren Anforderungen definieren. Um optimale Schemas in MongoDB zu erstellen, können Sie die Dokumente verschachteln. Anstatt also Ihre Anwendung an ein Datenmodell anzupassen, können Sie ein Datenmodell erstellen, das zu Ihrem Anwendungsfall passt.
Mit eingebetteten Dokumenten können Sie zusammengehörige Daten speichern, auf die Sie gemeinsam zugreifen. Beim Entwerfen von Schemas für MongoDB wird empfohlen, Dokumente standardmäßig einzubetten. Verwenden Sie datenbankseitige oder anwendungsseitige Verknüpfungen und Verweise nur dann, wenn sie sich lohnen.
Stellen Sie sicher, dass die Workload ein Dokument so oft wie nötig abrufen kann. Gleichzeitig sollte das Dokument auch alle Daten enthalten, die es benötigt. Dies ist entscheidend für die außergewöhnliche Leistung Ihrer Anwendung.
Nachfolgend finden Sie einige verschiedene Muster zum Einbetten von Dokumenten:
Eingebettetes Dokumentmuster
Damit können Sie auch komplizierte Unterstrukturen in die verwendeten Dokumente einbetten. Das Einbetten verbundener Daten in ein einzelnes Dokument kann die Anzahl der zum Abrufen von Daten erforderlichen Lesevorgänge verringern. Im Allgemeinen sollten Sie Ihr Schema so strukturieren, dass Ihre Anwendung alle erforderlichen Informationen in einem einzigen Lesevorgang erhält. Daher gilt hier die Regel, was zusammen verwendet wird, sollte zusammen aufbewahrt werden .
Eingebettetes Teilmengenmuster
Das eingebettete Teilmengenmuster ist ein Hybridfall. Sie würden es für eine separate Sammlung einer langen Liste verwandter Elemente verwenden, in der Sie einige dieser Elemente zur Anzeige bereithalten können.
Hier ist ein Beispiel, das Filmkritiken auflistet:
> db.movie.findOne() { _id: 321475, title: "The Dark Knight" } > db.review.find({movie_id: 321475}) { _id: 264579, movie_id: 321475, stars: 4 text: "Amazing" } { _id: 375684, movie_id: 321475, stars:5, text: "Mindblowing" }Stellen Sie sich jetzt tausend ähnliche Rezensionen vor, aber Sie planen, nur die letzten zwei anzuzeigen, wenn Sie einen Film zeigen. In diesem Szenario ist es sinnvoll, diese Teilmenge als Liste im Filmdokument zu speichern:
> db.movie.findOne({_id: 321475}) { _id: 321475, title: "The Dark Knight", recent_reviews: [ {_id: 264579, stars: 4, text: "Amazing"}, {_id: 375684, stars: 5, text: "Mindblowing"} ] }</codeEinfach ausgedrückt: Wenn Sie routinemäßig auf eine Teilmenge verwandter Elemente zugreifen, stellen Sie sicher, dass Sie diese einbetten.
Unabhängiger Zugriff
Möglicherweise möchten Sie Unterdokumente in ihrer Sammlung speichern, um sie von ihrer übergeordneten Sammlung zu trennen.
Nehmen Sie zum Beispiel die Produktlinie eines Unternehmens. Wenn das Unternehmen eine kleine Gruppe von Produkten verkauft, möchten Sie diese möglicherweise im Unternehmensdokument speichern. Wenn Sie sie jedoch unternehmensübergreifend wiederverwenden oder direkt über ihre Lagerhaltungseinheit (SKU) darauf zugreifen möchten, sollten Sie sie auch in ihrer Sammlung speichern.
Wenn Sie eine Entität unabhängig manipulieren oder darauf zugreifen, erstellen Sie eine Sammlung, um sie als Best Practice separat zu speichern.
Unbegrenzte Listen
Das Speichern kurzer Listen verwandter Informationen in ihrem Dokument hat einen Nachteil. Wenn Ihre Liste unkontrolliert weiterwächst, sollten Sie sie nicht in einem einzigen Dokument zusammenfassen. Dies liegt daran, dass Sie es nicht sehr lange unterstützen könnten.
Dafür gibt es zwei Gründe. Erstens hat MongoDB eine Begrenzung der Größe eines einzelnen Dokuments. Zweitens, wenn Sie zu oft auf das Dokument zugreifen, sehen Sie negative Ergebnisse durch unkontrollierte Speichernutzung.
Einfach ausgedrückt: Wenn eine Liste unbegrenzt wächst, erstellen Sie eine Sammlung, um sie separat zu speichern.
Erweitertes Referenzmuster
Das erweiterte Referenzmuster ist wie das Teilmengenmuster. It also optimizes information that you regularly access to store on the document.
Here, instead of a list, it's leveraged when a document refers to another that is present in the same collection. At the same time, it also stores some fields from that other document for ready access.
Zum Beispiel:
> db.movie.findOne({_id: 245434}) { _id: 245434, title: "Mission Impossible 4 - Ghost Protocol", studio_id: 924935, studio_name: "Paramount Pictures" }As you can see, “the studio_id” is stored so that you can look up more information on the studio that created the film. But the studio's name is also copied to this document for simplicity.
To embed information from modified documents regularly, remember to update documents where you've copied that information when it is modified. In other words, if you routinely access some fields from a referenced document, embed them.
How To Monitor MongoDB
You can use monitoring tools like Kinsta APM to debug long API calls, slow database queries, long external URL requests, to name a few. You can even leverage commands to improve database performance. You can also use them to inspect the ase/” data-mce-href=”https://kinsta.com/knowledgebase/wordpress-repair-database/”>health of your database instances.
Why Should You Monitor MongoDB Databases?
A key aspect of database administration planning is monitoring your cluster's performance and health. MongoDB Atlas handles the majority of administration efforts through its fault-tolerance/scaling abilities.
Despite that, users need to know how to track clusters. They should also know how to scale or tweak whatever they need before hitting a crisis.
By monitoring MongoDB databases, you can:
- Observe the utilization of resources.
- Understand the current capacity of your database.
- React and detect real-time issues to enhance your application stack.
- Observe the presence of performance issues and abnormal behavior.
- Align with your governance/data protection and service-level agreement (SLA) requirements.
Key Metrics To Monitor
While monitoring MongoDB, there are four key aspects you need to keep in mind:
1. MongoDB Hardware Metrics
Here are the primary metrics for monitoring hardware:
Normalized Process CPU
It's defined as the percentage of time spent by the CPU on application software maintaining the MongoDB process.
You can scale this to a range of 0-100% by dividing it by the number of CPU cores. It includes CPU leveraged by modules such as kernel and user.
High kernel CPU might show exhaustion of CPU via the operating system operations. But the user linked with MongoDB operations might be the root cause of CPU exhaustion.
Normalized System CPU
It's the percentage of time the CPU spent on system calls servicing this MongoDB process. You can scale it to a range of 0-100% by dividing it by the number of CPU cores. It also covers the CPU used by modules such as iowait, user, kernel, steal, etc.
User CPU or high kernel might show CPU exhaustion through MongoDB operations (software). High iowait might be linked to storage exhaustion causing CPU exhaustion.
Disk IOPS
Disk IOPS is the average consumed IO operations per second on MongoDB's disk partition.
Disk Latency
This is the disk partition's read and write disk latency in milliseconds in MongoDB. High values (>500ms) show that the storage layer might affect MongoDB's performance.
System Memory
Use the system memory to describe physical memory bytes used versus available free space.
The available metric approximates the number of bytes of system memory available. You can use this to execute new applications, without swapping.
Disk Space Free
This is defined as the total bytes of free disk space on MongoDB's disk partition. MongoDB Atlas provides auto-scaling capabilities based on this metric.
Swap Usage
You can leverage a swap usage graph to describe how much memory is being placed on the swap device. A high used metric in this graph shows that swap is being utilized. This shows that the memory is under-provisioned for the current workload.
MongoDB Cluster's Connection and Operation Metrics
Here are the main metrics for Operation and Connection Metrics:
Operation Execution Times
The average operation time (write and read operations) performed over the selected sample period.
Opcounters
It is the average rate of operations executed per second over the selected sample period. Opcounters graph/metric shows the operations breakdown of operation types and velocity for the instance.
Connections
This metric refers to the number of open connections to the instance. High spikes or numbers might point to a suboptimal connection strategy either from the unresponsive server or the client side.
Query Targeting and Query Executors
This is the average rate per second over the selected sample period of scanned documents. For query executors, this is during query-plan evaluation and queries. Query targeting shows the ratio between the number of documents scanned and the number of documents returned.
Ein hohes Zahlenverhältnis weist auf einen suboptimalen Betrieb hin. Diese Vorgänge scannen viele Dokumente, um einen kleineren Teil zurückzugeben.
Scannen und bestellen
Sie beschreibt die durchschnittliche Rate pro Sekunde über den gewählten Stichprobenzeitraum von Abfragen. Es gibt sortierte Ergebnisse zurück, die die Sortieroperation nicht mithilfe eines Index ausführen können.
Warteschlangen
Warteschlangen können die Anzahl der Operationen beschreiben, die auf eine Sperre warten, entweder schreibend oder lesend. Hohe Warteschlangen können auf das Vorhandensein eines suboptimalen Schemadesigns hindeuten. Es könnte auch auf widersprüchliche Schreibpfade hinweisen, was zu einem starken Wettbewerb um Datenbankressourcen führt.
MongoDB-Replikationsmetriken
Hier sind die primären Metriken für die Replikationsüberwachung:
Replikations-Oplog-Fenster
Diese Metrik listet die ungefähre Anzahl der Stunden auf, die im Replikations-Oplog des Primärsystems verfügbar sind. Wenn eine sekundäre Verzögerung mehr als diesen Betrag aufweist, kann sie nicht mithalten und muss vollständig neu synchronisiert werden.
Replikationsverzögerung
Die Replikationsverzögerung ist definiert als die ungefähre Anzahl von Sekunden, die ein sekundärer Knoten bei Schreibvorgängen hinter dem primären Knoten liegt. Eine hohe Replikationsverzögerung würde auf eine Sekundärseite hinweisen, die Schwierigkeiten bei der Replikation hat. Dies kann sich angesichts der Lese-/Schreibprobleme der Verbindungen auf die Latenz Ihres Vorgangs auswirken.
Replikations-Headroom
Diese Metrik bezieht sich auf den Unterschied zwischen dem Oplog-Fenster der primären Replikation und der Replikationsverzögerung der sekundären. Wenn dieser Wert auf Null geht, könnte dies dazu führen, dass eine Sekundärseite in den WIEDERHERSTELLUNGS-Modus wechselt.
Opcounter -repl
Opcounters -repl ist definiert als die durchschnittliche Rate der pro Sekunde ausgeführten Replikationsvorgänge für den ausgewählten Stichprobenzeitraum. Mit opcounters -graph/metric können Sie sich die Operationsgeschwindigkeit und die Aufschlüsselung der Operationstypen für die angegebene Instanz ansehen.
Oplog GB/Stunde
Dies ist definiert als die durchschnittliche Oplog-Rate in Gigabyte, die der primäre Server pro Stunde generiert. Hohe unerwartete Volumina von oplog können auf eine äußerst unzureichende Schreibarbeitslast oder ein Schemaentwurfsproblem hinweisen.
MongoDB-Leistungsüberwachungstools
MongoDB verfügt über integrierte Benutzeroberflächen-Tools in Cloud Manager, Atlas und Ops Manager für die Leistungsverfolgung. Es bietet auch einige unabhängige Befehle und Tools, um mehr Rohdaten zu betrachten. Wir werden über einige Tools sprechen, die Sie von einem Host ausführen können, der Zugriff und entsprechende Rollen hat, um Ihre Umgebung zu überprüfen:
Mongotop
Sie können diesen Befehl nutzen, um die Zeit zu verfolgen, die eine MongoDB-Instance mit dem Schreiben und Lesen von Daten pro Sammlung verbringt. Verwenden Sie die folgende Syntax:
mongotop <options> <connection-string> <polling-interval in seconds>rs.status()
Dieser Befehl gibt den Replikatsatzstatus zurück. Sie wird aus der Sicht des Mitglieds ausgeführt, in dem die Methode ausgeführt wird.
mongostat
Sie können den Befehl mongostat verwenden, um sich einen schnellen Überblick über den Status Ihrer MongoDB-Serverinstanz zu verschaffen. Für eine optimale Ausgabe können Sie es verwenden, um eine einzelne Instanz auf ein bestimmtes Ereignis zu überwachen, da es eine Echtzeitansicht bietet.
Nutzen Sie diesen Befehl, um grundlegende Serverstatistiken wie Sperrwarteschlangen, Betriebsunterbrechungen, MongoDB-Speicherstatistiken und Verbindungen/Netzwerke zu überwachen:
mongostat <options> <connection-string> <polling interval in seconds>dbStats
Dieser Befehl gibt Speicherstatistiken für eine bestimmte Datenbank zurück, z. B. die Anzahl der Indizes und ihre Größe, die gesamten Sammlungsdaten im Vergleich zur Speichergröße und sammlungsbezogene Statistiken (Anzahl der Sammlungen und Dokumente).
db.serverStatus()
Sie können den Befehl db.serverStatus() nutzen, um sich einen Überblick über den Zustand der Datenbank zu verschaffen. Sie erhalten ein Dokument, das die aktuellen Instanzmetrikzähler darstellt. Führen Sie diesen Befehl in regelmäßigen Abständen aus, um Statistiken über die Instanz zu sammeln.
collStat
Der Befehl collStats sammelt ähnliche Statistiken wie dbStats auf Sammlungsebene. Seine Ausgabe besteht aus der Anzahl der Objekte in der Sammlung, der Menge an Speicherplatz, die von der Sammlung verbraucht wird, der Größe der Sammlung und Informationen zu ihren Indizes für eine bestimmte Sammlung.
Sie können alle diese Befehle verwenden, um Echtzeit-Berichte und -Überwachung des Datenbankservers bereitzustellen, mit denen Sie die Datenbankleistung und -fehler überwachen und fundierte Entscheidungen zur Optimierung einer Datenbank treffen können.
So löschen Sie eine MongoDB-Datenbank
Um eine in MongoDB erstellte Datenbank zu löschen, müssen Sie sich über das Schlüsselwort use mit ihr verbinden.
Angenommen, Sie haben eine Datenbank mit dem Namen „Ingenieure“ erstellt. Um eine Verbindung zur Datenbank herzustellen, verwenden Sie den folgenden Befehl:
use Engineers Geben Sie als Nächstes db.dropDatabase() ein, um diese Datenbank loszuwerden. Nach der Ausführung ist dies das Ergebnis, das Sie erwarten können:
{ "dropped" : "Engineers", "ok" : 1 } Sie können den Befehl showdbs , um zu überprüfen, ob die Datenbank noch vorhanden ist.
Zusammenfassung
Um den letzten Tropfen Wert aus MongoDB herauszuholen, müssen Sie ein starkes Verständnis der Grundlagen haben. Daher ist es entscheidend, MongoDB-Datenbanken wie Ihre Westentasche zu kennen. Dazu müssen Sie sich zuerst mit den Methoden zum Erstellen einer Datenbank vertraut machen.
In diesem Artikel beleuchten wir die verschiedenen Methoden, mit denen Sie eine Datenbank in MongoDB erstellen können, gefolgt von einer detaillierten Beschreibung einiger raffinierter MongoDB-Befehle, mit denen Sie Ihre Datenbanken immer im Griff haben. Schließlich haben wir die Diskussion abgerundet, indem wir besprochen haben, wie Sie eingebettete Dokumente und Leistungsüberwachungstools in MongoDB nutzen können, um sicherzustellen, dass Ihre Workflows mit maximaler Effizienz funktionieren.
Was halten Sie von diesen MongoDB-Befehlen? Haben wir einen Aspekt oder eine Methode übersehen, die Sie hier gerne gesehen hätten? Lass es uns in den Kommentaren wissen!