
Persistent Storage: Langzeitgedächtnis im Zeitalter der Container
Veröffentlicht: 2023-04-17Persistente Speicherung bezieht sich auf die Aufbewahrung von Daten auf nichtflüchtige Weise, sodass sie auch nach dem Ausschalten oder Neustarten eines Geräts oder einer Anwendung verfügbar bleiben. Das Speichern und Abrufen von Daten ermöglicht es Webanwendungen, Benutzerinformationen und -zustände zu speichern und zuverlässig zu arbeiten.
In monolithischen Anwendungen ist der Speicherzugriff unkompliziert, da Server und Speicher zusammenleben. Geografisch verteilte Systeme machen den Zugriff jedoch komplexer, da das Speichersystem allen Komponenten weltweit zur Verfügung stehen muss.
Die Containerisierung verkompliziert das Problem weiter, da Container leichtgewichtig, zustandslos und flüchtig sind – ungeeignete Eigenschaften zum Speichern von Daten. Daher muss jede dauerhafte Speicherlösung in der Lage sein, nahtlos mit Containern zusammenzuarbeiten, was eine weitere Ebene der Komplexität hinzufügt.
Dieser Artikel befasst sich mit persistentem Speicher, indem er seine Typen, Architektur und Anwendungsfälle untersucht. Es bietet auch eine praktische Demonstration, die den Unterschied zwischen Volume-Speicherung und dauerhafter Volume-Speicherung in Docker veranschaulicht.
Arten von persistentem Speicher
Es gibt verschiedene Arten von nichtflüchtigem Speicher, darunter traditionelle sich drehende Festplatten (Festplattenlaufwerke oder HDDs), Solid-State-Laufwerke (SSDs), Network Attached Storage (NAS) und Storage Area Networks (SANs).
- HDDs sind elektromechanische Datenspeichergeräte, die digitale Daten unter Verwendung von sich drehenden Platten magnetischer Medien speichern und abrufen. Die Platten verwenden Magnetköpfe auf einem beweglichen Betätigungsarm, die Daten lesen und schreiben.
- SSDs , manchmal auch als Halbleiterspeichergeräte, Solid-State-Geräte oder Solid-State-Disks bezeichnet, verwenden integrierte Schaltungsanordnungen, um Daten dauerhaft zu speichern, normalerweise unter Verwendung von miteinander verbundenen Flash-Geräten, die keine beweglichen Teile enthalten. Ihre stationäre Natur macht sie schneller und zuverlässiger als HDDs.
- Network Attached Storage ist eine Gruppe von HDDs, SSDs oder beidem, die über ein lokales Netzwerk mit einem Dateisystem wie dem New Technology File System (NTFS) oder dem vierten erweiterten Dateisystem (EXT4) verbunden sind.
- SANs sind vernetzte Hochgeschwindigkeitsspeichergeräte auf Blockebene, wie Bandbibliotheken oder Plattenarrays. Ihre Verbindung erscheint dem Betriebssystem als lokaler Speicher und ist nicht über das lokale Netzwerk (LAN) zugänglich.
Persistente Speicherarchitektur
Es gibt drei Ansätze für persistente Speicherung, jede mit einzigartigen Anwendungsfällen und Einschränkungen.
Objektpersistente Architektur
Der Ansatz der objektpersistenten Architektur verwendet objektrelationales Mapping (ORM), um Daten als Objekte in einer relationalen oder Schlüsselwertdatenbank zu speichern. Dieser Ansatz ist nützlich, wenn die Daten kein definiertes Schema haben, da das ORM die Speicherung und den Abruf übernimmt.
Persistente Architektur blockieren
Die blockpersistente Architektur verwendet Speichergeräte auf Blockebene, die beim Speichern großer Dateien nützlich sind. Dieser Ansatz ist beim Speichern großer Datenmengen von Vorteil, da Sie mehrere Blöcke verwenden können, um die Speicherkapazität zu erhöhen.
Persistente Filestore-Architektur
Wie der Name schon sagt, verwendet der Ansatz der persistenten Dateispeicherarchitektur ein Dateisystem zum Speichern von Daten. Eine Methode beinhaltet die Verwendung von Datenbankservern, die eine zentralisierte Möglichkeit zum Speichern von Daten bieten. Cloud-Hosting-Lösungen wie die von Kinsta verwenden Datenbankserver, die einfach an Anwendungen angehängt werden können und Persistenz bieten.
Die persistente Filestore-Architektur ist hilfreich bei Anwendungen, die häufiges Abrufen von Dateien erfordern, und wenn Sie eine Schnittstelle zu deren Verwaltung benötigen.
Anwendungsfälle für persistente Speicherung
In diesem Abschnitt werden einige der Anwendungsfälle der einzelnen Speichertypen erläutert.
Objektpersistenter Speicher
- Cloud-Speicher: Objektpersistenter Speicher wird häufig in Cloud-Speicherlösungen verwendet, um große Mengen unstrukturierter Daten wie Bilder, Videos und Dokumente zu speichern und abzurufen. Cloud-Anbieter verwenden Objektspeicher, um Kunden skalierbare, hochverfügbare und dauerhafte Speicherdienste bereitzustellen.
- Big-Data-Analyse: Objektpersistenter Speicher wird in der Big-Data-Analyse verwendet, um große Datensätze zu speichern und zu verwalten, die häufig für Datenanalyse, maschinelles Lernen und KI verwendet werden. Object Storage ermöglicht einen schnellen und effizienten Zugriff auf Daten und ist damit eine Schlüsselkomponente von Big-Data-Architekturen.
- Content-Delivery-Netzwerke: Persistenter Objektspeicher wird in Content-Delivery-Netzwerken (CDNs) verwendet, um Inhalte wie Bilder, Videos und statische Dateien über ein globales Netzwerk von Servern zu speichern und zu verteilen. Die Objektspeicherung ermöglicht es CDNs, Benutzern weltweit und unabhängig vom Standort Hochgeschwindigkeitsinhalte bereitzustellen.
Persistenten Speicher blockieren
- High Performance Computing (HPC) : HPC-Umgebungen zur schnellen und effizienten Verarbeitung beträchtlicher Datenmengen. Persistenter Blockspeicher ermöglicht es HPC-Clustern, große Datensätze zu speichern und abzurufen, z. B. wissenschaftliche Simulationen, Wettermodelle und Finanzanalysen. Blockspeicher wird häufig für HPC bevorzugt, da er einen leistungsstarken Datenzugriff mit geringer Latenz bietet und parallele Eingabe-/Ausgabevorgänge (E/A) ermöglicht, wodurch die Verarbeitungszeiten erheblich verkürzt werden können.
- Videobearbeitung: Videobearbeitungsanwendungen erfordern einen leistungsstarken und latenzarmen Zugriff auf große Videodateien. Sie müssen außerdem eine beträchtliche Anzahl von I/O-Vorgängen pro Sekunde und eine geringe Latenz bewältigen, um Videodateien in Echtzeit zu rendern und zu bearbeiten. Blockspeicher bietet diese Funktionen und ist damit eine ideale Lösung für Videobearbeitungs-Workflows.
- Spiele: Spieleanwendungen erfordern auch eine hohe Leistung und geringe Latenz, um auf Spielressourcen und Spielerdaten zuzugreifen. Blockspeicher speichert und ruft große Datenmengen schnell ab und stellt sicher, dass Spielumgebungen schnell geladen werden und während des Spiels reaktionsfähig bleiben.
Persistenter Filestore-Speicher
- Medien und Unterhaltung: Videobearbeitungs-, Animations- und Rendering-Anwendungen verwenden häufig persistenten Speicher. Diese Anwendungen erfordern einen leistungsstarken und latenzarmen Zugriff auf große Mediendateien wie Video, Audio und Bilder. Filestore bietet ein gemeinsam genutztes Dateisystem, auf das mehrere Clients zugreifen können, was es zu einer idealen Speicherlösung für diese Anwendungen macht.
- Web-Content-Management: Web-Content-Management-Systeme (CMSs) verwenden den persistenten Filestore-Speicher in gemeinsam genutzten Dateisystemen, um Website-Inhalte wie Text, Bilder und Multimediadateien zu speichern und zu verwalten. Filestore bietet einen zentralen Speicherort für Website-Inhalte, wodurch die Verwaltung und Aktualisierung vereinfacht wird. Es ermöglicht auch mehreren Benutzern, gleichzeitig an denselben Inhalten zu arbeiten, was die Zusammenarbeit und Produktivität verbessert.
Persistente Speicherung in Containern
Container sind leicht, tragbar, sicher und unkompliziert und bieten eine Fusion zwischen verschiedenen Anwendungen. Sie müssen über einen Mechanismus verfügen, um Daten zwischen Container-Neustarts und -Entfernung beizubehalten. Container verfügen über einen Dateispeicher oder ein Dateisystem wie herkömmliche Anwendungen, aber wenn Sie sie mit neuen Änderungen neu erstellen, verlieren Sie alle nicht persistenten Daten.
Aus diesem Grund bieten Container die Möglichkeit, Volume-Speicher einzuschließen oder ein Speichervolume bereitzustellen. Container behandeln Speichervolumes wie ein Verzeichnis. Alle auf das Volume geschriebenen Daten gehen in das Host-Dateisystem.
Persistenter Speicher für Container muss auf diese Weise funktionieren, da beim Neustart eines Containers eine neue Instanz erstellt und die alte Instanz verworfen wird. Wenn ein Container keine konsistente Ansicht der Daten hat, verschwinden die Daten, wenn der Container neu gestartet wird. Ein Speichervolume bewahrt die Daten über Sitzungen und Containerneustarts hinweg auf, sodass der Container seinen Zustand auch dann beibehalten kann, wenn er verschoben oder neu gestartet wird.

Volumen vs. Persistentes Volumen
Container bieten zwei Möglichkeiten zum Speichern persistenter Daten: die Verwendung von Volumes und persistente Volumes. Es gibt einen signifikanten Unterschied zwischen ihnen. Ein Container verwaltet die Daten im Datenträgerspeicher. Wenn Sie einen Container stoppen, bleiben die Daten erhalten und sind verfügbar, wenn Sie den Container neu starten. Wenn Sie jedoch einen Container löschen oder entfernen, gehen die Daten verloren, da Sie auch den zugrunde liegenden Volume-Speicher löschen.
Persistent Volume Storage oder Bind Mounts ist eine Möglichkeit, die Daten außerhalb des Dateisystems des Containers zu speichern. So gehen die Daten auch beim Löschen des Containers nicht verloren. Es bleibt bestehen, bis es manuell gelöscht wird.
Der folgende Abschnitt demonstriert beide Volume-Typen anhand von Beispielen.
Container Persistent Storage Demo
Wir haben eine kleine Webanwendung erstellt, um die dauerhafte Speicherung mit Docker-Containern zu demonstrieren. Sie können mitmachen, indem Sie Docker installieren und den Code aus diesem GitHub-Repository abrufen.
Die Anwendung ist ein elementares Formular mit 2 Feldern für Benutzereingaben:
- Titel
- Dokumententext
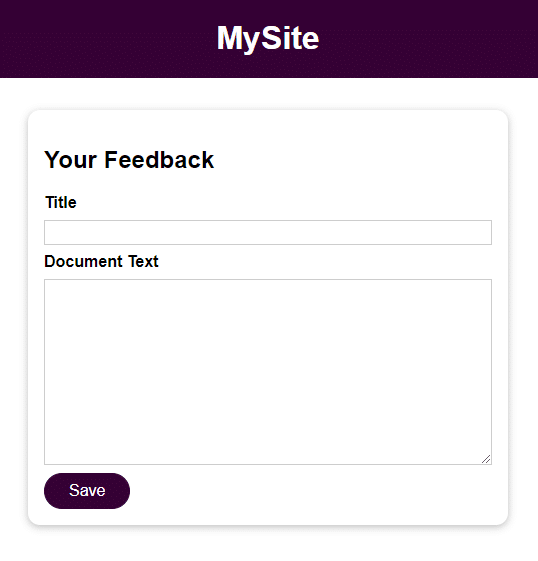
Nachdem Sie die Benutzereingabe gespeichert haben, können Sie darauf zugreifen, indem Sie die Datei im Feedback- Verzeichnis mit dem im Titelfeld angegebenen Namen öffnen. Die Eingabe aus dem Feld Dokumenttext ist der Inhalt der Datei.
So verwenden Sie den Volume-Speicher
Sobald Sie die Anwendung auf Ihrem eigenen Computer installiert haben, kann sie den Volume-Speicher verwenden, wie in der Dockerfile gezeigt.
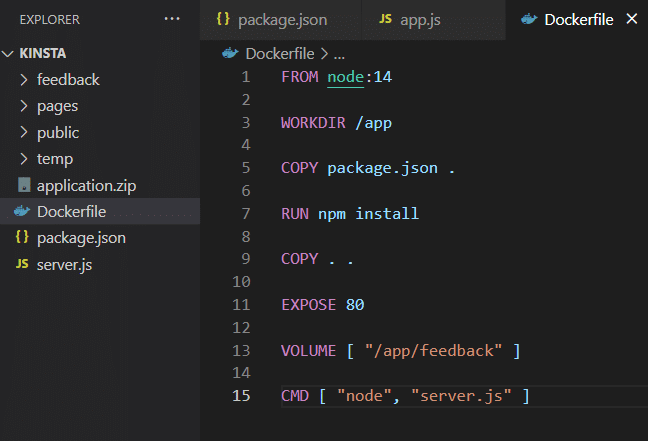
Jetzt erstellen Sie das Image und führen den Container aus. Führen Sie dazu die folgenden Befehle aus.
docker build -t feedback-node:volumes . docker run -d -p 3000:80 --name feedback-app feedback-node:volumes 
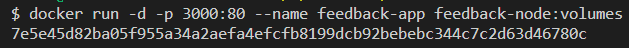
Sobald die Anwendung ausgeführt wird, navigieren Sie zu localhost:3000, um Feedback zu senden.
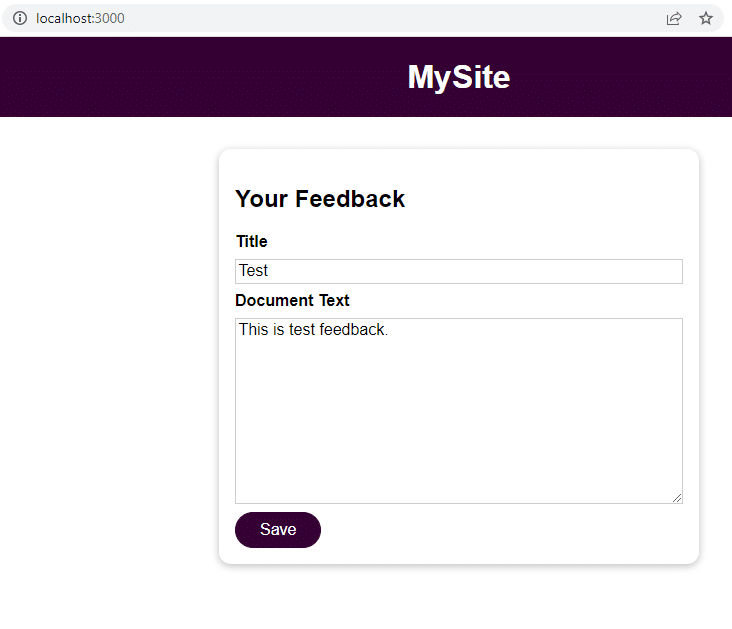
Klicken Sie auf Speichern und navigieren Sie zu localhost:3000/feedback/test.txt, um zu sehen, ob die Eingabe erfolgreich gespeichert wurde oder nicht.
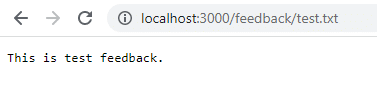
Entfernen Sie den Container und starten Sie ihn neu, um zu sehen, ob die Eingabe weiterhin besteht.
docker stop feedback-app docker start feedback-appWenn Sie jetzt dieselbe URL besuchen, sehen Sie, dass das Feedback immer noch da ist. Aber was passiert, wenn Sie den Container entfernen und neu starten?
docker stop feedback-app docker rm feedback-app docker run -d -p 3000:80 --name feedback-app feedback-node:volumesWenn Sie nach dem Neustart zu dieser URL zurückkehren, ist sie nicht mehr vorhanden, da die Daten beim Entfernen des Containers verloren gegangen sind. Volume-Daten bleiben nur bestehen, wenn der Container gestoppt wird, nicht wenn er entfernt wird.
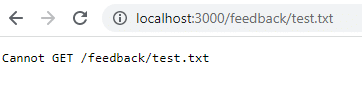
Um dieses Problem zu mindern und die Daten auch dann beizubehalten, wenn Sie den Container entfernen, müssen Sie persistenten Volume-Speicher oder benannten Speicher verwenden. Zuerst sollten Sie die Container und Images bereinigen.
docker stop feedback-app docker rm feedback-app docker rmi feedback-node:volumesVerwendung von Persistent Volume Storage
Bevor Sie dies testen, müssen Sie das VOLUME-Attribut aus der Dockerfile entfernen und das Image neu erstellen.
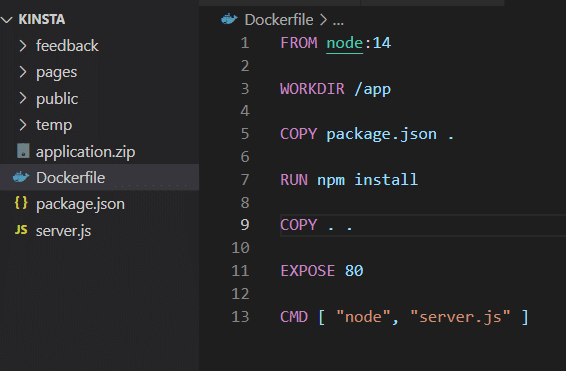
docker build -t feedback-node:volumes . docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumes Wie Sie sehen können, verwenden Sie im zweiten Befehl das Flag -v , um das persistente Volume außerhalb des Containers zu definieren, das auch dann bestehen bleibt, wenn Sie den Container entfernen.
Versuchen Sie wie im vorherigen Schritt, Feedback hinzuzufügen und darauf zuzugreifen, nachdem Sie den Container angehalten, entfernt und neu gestartet haben.
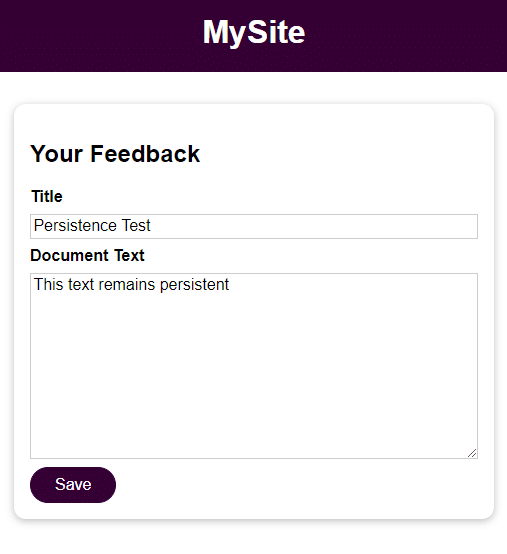
docker stop feedback-app docker rm feedback-app docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesWie Sie sehen, sind die Daten auch nach dem Stoppen und Entfernen des Containers zugänglich und bleiben erhalten.
Zusammenfassung
Persistenter Speicher ist für containerisierte Anwendungen von entscheidender Bedeutung, da er die Persistenz von Daten außerhalb des Lebenszyklus eines Containers ermöglicht. Die 2 Haupttypen von persistentem Speicher für containerisierte Anwendungen sind Volumes und Bind-Mounts, jede mit ihren Vorteilen und Anwendungsfällen.
Volumes werden im Dateisystem des Containers gespeichert, während Bind-Mounts direkt auf dem Host-Rechner zugänglich sind.
Persistenter Speicher ermöglicht die gemeinsame Nutzung von Daten zwischen Containern, wodurch komplexe, mehrschichtige Anwendungen erstellt werden können. Persistenter Speicher ist unerlässlich, um die Stabilität und Kontinuität von containerisierten Anwendungen zu gewährleisten, und bietet eine zuverlässige und flexible Möglichkeit, wichtige Daten zu speichern.
Und wenn du Docker verwendest, um deine Webanwendungen zu entwickeln, wirst du feststellen, dass es ein Kinderspiel ist, Dockerfile-Bereitstellungen mit dem Application Hosting-Service von Kinsta zu konfigurieren.