
Robots.txt: Was es ist und wie man es erstellt (vollständige Anleitung)
Veröffentlicht: 2023-05-05Wenn Sie eine Website besitzen oder deren Inhalt verwalten, haben Sie wahrscheinlich schon von robots.txt gehört. Es ist eine Datei, die Suchmaschinenroboter anweist, wie die Seiten Ihrer Website gecrawlt und indexiert werden sollen. Trotz ihrer Bedeutung für die Suchmaschinenoptimierung (SEO) übersehen viele Websitebesitzer die Bedeutung einer gut gestalteten robots.txt-Datei.
In diesem vollständigen Leitfaden untersuchen wir, was robots.txt ist, warum es für SEO wichtig ist und wie Sie eine robots.txt-Datei für Ihre Website erstellen.
Was ist die Robots.txt-Datei?
Eine robots.txt ist eine Datei, die Suchmaschinenrobotern (auch bekannt als Crawler oder Spider) mitteilt, welche Seiten oder Bereiche einer Website gecrawlt werden sollen oder nicht. Es handelt sich um eine einfache Textdatei, die sich im Stammverzeichnis einer Website befindet und normalerweise eine Liste von Verzeichnissen, Dateien oder URLs enthält, die der Webmaster für die Indizierung oder das Crawlen durch Suchmaschinen sperren möchte.
So sieht eine robots.txt-Datei aus:

Warum ist robots.txt wichtig?
Es gibt drei Hauptgründe, warum robots.txt für Ihre Website wichtig ist:
1. Crawl-Budget maximieren
„Crawl-Budget“ steht für die Anzahl der Seiten, die Google zu einem bestimmten Zeitpunkt auf Ihrer Website crawlt. Die Anzahl hängt von der Größe, Gesundheit und Menge der Backlinks auf Ihrer Website ab.
Das Crawl-Budget ist wichtig, denn wenn die Anzahl der Seiten auf Ihrer Website das Crawl-Budget überschreitet, werden Sie Seiten haben, die nicht indexiert sind.
Darüber hinaus werden Seiten, die nicht indiziert sind, für nichts gerankt.
Durch die Verwendung von robots.txt zum Blockieren nutzloser Seiten kann der Googlebot (der Web-Crawler von Google) einen größeren Teil Ihres Crawling-Budgets für relevante Seiten ausgeben.
2. Blockieren Sie nicht öffentliche Seiten
Sie haben viele Seiten auf Ihrer Website, die Sie nicht indizieren möchten.
Beispielsweise könnten Sie eine interne Suchergebnisseite oder eine Anmeldeseite haben. Diese Seiten müssen vorhanden sein. Sie möchten jedoch nicht, dass zufällige Personen darauf landen.
In diesem Fall würden Sie robots.txt verwenden, um zu verhindern, dass Suchmaschinen-Crawler und Bots auf bestimmte Seiten zugreifen.
3. Indizierung von Ressourcen verhindern
Manchmal möchten Sie, dass Google Ressourcen wie PDFs, Videos und Bilder aus den Suchergebnissen ausschließt.
Möglicherweise möchten Sie diese Ressourcen privat halten oder Google soll sich mehr auf wichtige Inhalte konzentrieren.
In solchen Fällen ist die Verwendung von robots.txt der beste Ansatz, um zu verhindern, dass sie indexiert werden.
Wie funktioniert eine Robots.txt-Datei?
Robots.txt-Dateien weisen Suchmaschinen-Bots an, welche Seiten oder Verzeichnisse der Website sie crawlen oder indizieren sollen oder nicht.
Beim Crawlen finden und folgen Suchmaschinen-Bots Links. Dieser Prozess führt sie über Milliarden von Links und Websites von Site X zu Site Y zu Site Z.
Wenn ein Bot eine Website besucht, sucht er als Erstes nach einer robots.txt-Datei.
Wenn es einen erkennt, liest es die Datei, bevor es etwas anderes tut.
Angenommen, Sie möchten allen Bots außer DuckDuckGo erlauben, Ihre Website zu crawlen:
User-agent: DuckDuckBot Disallow: /
Hinweis: Eine robots.txt-Datei kann nur Anweisungen geben; es kann sie nicht auferlegen. Es ist vergleichbar mit einem Verhaltenskodex. Gute Bots (z. B. Suchmaschinen-Bots) befolgen die Regeln, während schlechte Bots (z. B. Spam-Bots) sie ignorieren.
Wie finde ich eine Robots.txt-Datei?
Die robots.txt-Datei wird wie jede andere Datei auf Ihrer Website auf Ihrem Server gehostet.
Sie können auf die robots.txt-Datei jeder Website zugreifen, indem Sie die vollständige URL der Homepage eingeben und dann /robots.txt am Ende hinzufügen, z. B. https://pickupwp.com/robots.txt.
Wenn die Website jedoch keine robots.txt-Datei hat, erhalten Sie eine „404 Not Found“-Fehlermeldung.
Wie erstelle ich eine Robots.txt-Datei?
Bevor wir zeigen, wie eine robots.txt-Datei erstellt wird, sehen wir uns zunächst die robots.txt-Syntax an.
Die Syntax einer robots.txt-Datei kann in die folgenden Komponenten unterteilt werden:
- User-Agent: Dies gibt den Robot oder Crawler an, für den der Datensatz gilt. „User-agent: Googlebot“ würde beispielsweise nur für den Such-Crawler von Google gelten, während „User-agent: *“ für alle Crawler gelten würde.
- Disallow: Dies gibt die Seiten oder Verzeichnisse an, die der Robot nicht crawlen soll. Beispielsweise würde „Disallow: /private/“ verhindern, dass Robots Seiten innerhalb des „private“-Verzeichnisses crawlen.
- Zulassen: Dies gibt die Seiten oder Verzeichnisse an, die der Roboter durchsuchen darf, auch wenn das übergeordnete Verzeichnis nicht zugelassen ist. Zum Beispiel würde „Allow: /public/“ Robots erlauben, alle Seiten innerhalb des „public“-Verzeichnisses zu crawlen, selbst wenn das übergeordnete Verzeichnis nicht erlaubt ist.
- Crawl-Verzögerung: Dies gibt die Zeit in Sekunden an, die der Roboter warten soll, bevor er die Website durchsucht. Beispielsweise würde „Crawl-Verzögerung: 10“ den Roboter anweisen, 10 Sekunden zu warten, bevor er die Website durchsucht.
- Sitemap: Dies gibt den Speicherort der Sitemap der Website an. Beispielsweise würde „Sitemap: https://www.example.com/sitemap.xml“ den Roboter über den Speicherort der Sitemap der Website informieren.
Hier ist ein Beispiel für eine robots.txt-Datei:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
Hinweis: Es ist wichtig zu beachten, dass bei robots.txt-Dateien zwischen Groß- und Kleinschreibung unterschieden wird, daher ist es wichtig, bei der Angabe von URLs die richtige Groß- und Kleinschreibung zu verwenden.
Beispielsweise ist /public/ nicht dasselbe wie /Public/.
Andererseits wird bei Direktiven wie „Allow“ und „Disallow“ nicht zwischen Groß- und Kleinschreibung unterschieden, also liegt es an Ihnen, sie groß zu schreiben oder nicht.
Nachdem Sie sich mit der robots.txt-Syntax vertraut gemacht haben, können Sie eine robots.txt-Datei mit einem robots.txt-Generator-Tool erstellen oder selbst eine erstellen.
So erstellen Sie eine robots.txt-Datei in nur vier Schritten:
1. Erstellen Sie eine neue Datei und nennen Sie sie Robots.txt
Öffnen Sie einfach ein .txt-Dokument mit einem beliebigen Texteditor oder Webbrowser.
Geben Sie dem Dokument als Nächstes den Namen robots.txt. Damit es funktioniert, muss es robots.txt heißen.
Sobald Sie fertig sind, können Sie nun mit der Eingabe von Anweisungen beginnen.
2. Fügen Sie der Robots.txt-Datei Anweisungen hinzu
Eine robots.txt-Datei enthält eine oder mehrere Gruppen von Anweisungen mit jeweils mehreren Zeilen mit Anweisungen.
Jede Gruppe beginnt mit einem „User-Agent“ und enthält die folgenden Daten:
- Für wen die Gruppe gilt (der User-Agent)
- Auf welche Verzeichnisse (Seiten) oder Dateien kann der Agent zugreifen?
- Auf welche Verzeichnisse (Seiten) oder Dateien kann der Agent nicht zugreifen?
- Eine Sitemap (optional), um Suchmaschinen über die Websites und Dateien zu informieren, die Sie für wichtig halten.
Zeilen, die keiner dieser Anweisungen entsprechen, werden von Crawlern ignoriert.

Sie möchten beispielsweise verhindern, dass Google Ihr Verzeichnis /private/ durchsucht.
Es würde so aussehen:
User-agent: Googlebot Disallow: /private/
Wenn Sie weitere Anweisungen wie diese für Google hätten, würden Sie sie in einer separaten Zeile direkt darunter einfügen:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
Außerdem, wenn Sie mit den spezifischen Anweisungen von Google fertig sind und eine neue Gruppe von Richtlinien erstellen möchten.
Zum Beispiel, wenn Sie verhindern wollten, dass alle Suchmaschinen Ihre Verzeichnisse /archive/ und /support/ durchsuchen.
Es würde so aussehen:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
Wenn Sie fertig sind, können Sie Ihre Sitemap hinzufügen.
Ihre fertige robots.txt-Datei sollte so aussehen:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
Als nächstes speichern Sie Ihre robots.txt-Datei. Denken Sie daran, dass sie robots.txt heißen muss.
Weitere nützliche robots.txt-Regeln finden Sie in dieser hilfreichen Anleitung von Google.
3. Laden Sie die Robots.txt-Datei hoch
Nachdem Sie Ihre robots.txt-Datei auf Ihrem Computer gespeichert haben, laden Sie sie auf Ihre Website hoch und machen Sie sie für Suchmaschinen zum Crawlen verfügbar.
Leider gibt es kein Tool, das bei diesem Schritt helfen kann.
Das Hochladen der robots.txt-Datei hängt von der Dateistruktur und dem Webhosting Ihrer Website ab.
Um Anweisungen zum Hochladen Ihrer robots.txt-Datei zu erhalten, suchen Sie online oder wenden Sie sich an Ihren Hosting-Anbieter.
4. Testen Sie Ihre Robots.txt
Nachdem Sie die robots.txt-Datei hochgeladen haben, können Sie als Nächstes prüfen, ob jeder sie sehen und ob Google sie lesen kann.
Öffnen Sie einfach einen neuen Tab in Ihrem Browser und suchen Sie nach Ihrer robots.txt-Datei.
Zum Beispiel https://pickupwp.com/robots.txt.
Wenn Sie Ihre robots.txt-Datei sehen, können Sie das Markup (HTML-Code) testen.
Dazu können Sie einen Google robots.txt-Tester verwenden.
Hinweis: Sie haben ein Search Console-Konto eingerichtet, um Ihre robots.txt-Datei mit dem robots.txt-Tester zu testen.
Der robots.txt-Tester findet alle Syntaxwarnungen oder Logikfehler und hebt sie hervor.
Außerdem zeigt es Ihnen auch die Warnungen und Fehler unterhalb des Editors.
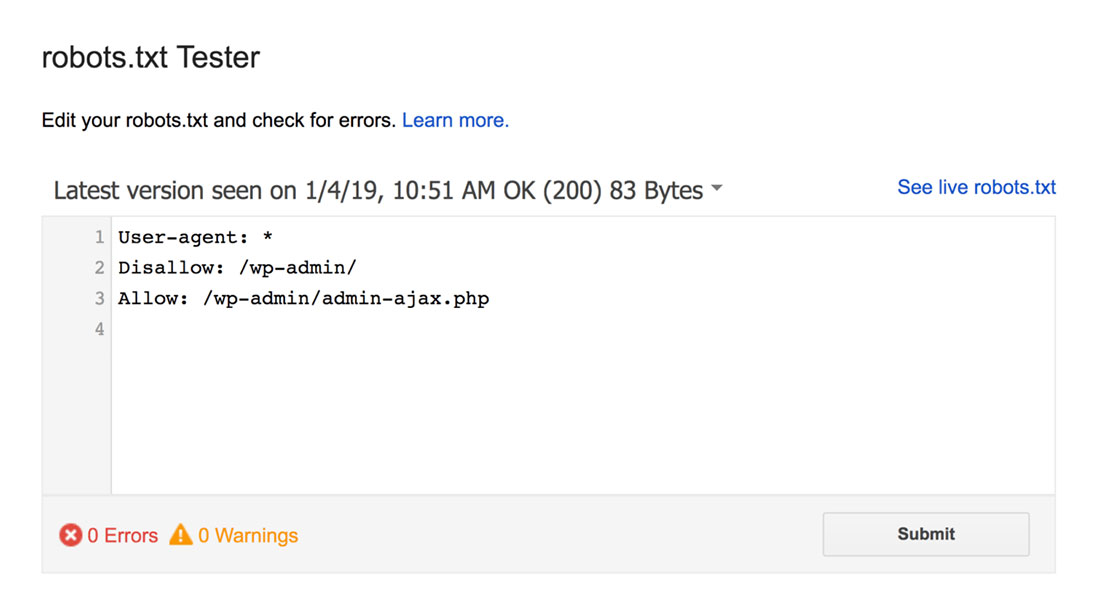
Sie können Fehler oder Warnungen auf der Seite bearbeiten und so oft wie nötig erneut testen.
Denken Sie nur daran, dass auf der Seite vorgenommene Änderungen nicht auf Ihrer Website gespeichert werden.
Um Änderungen vorzunehmen, kopieren Sie diese und fügen Sie sie in die robots.txt-Datei Ihrer Website ein.
Robots.txt Best Practices
Beachten Sie beim Erstellen Ihrer robots.txt-Datei diese Best Practices, um einige häufige Fehler zu vermeiden.
1. Verwenden Sie neue Zeilen für jede Richtlinie
Um Verwirrung für Suchmaschinen-Crawler zu vermeiden, fügen Sie jede Anweisung in eine neue Zeile in Ihrer robots.txt-Datei ein. Dies gilt sowohl für Allow- als auch für Disallow-Regeln.
Wenn Sie beispielsweise nicht möchten, dass ein Webcrawler Ihren Blog oder Ihre Kontaktseite durchsucht, fügen Sie die folgenden Regeln hinzu:
Disallow: /blog/ Disallow: /contact/
2. Verwenden Sie jeden Benutzeragenten nur einmal
Bots haben kein Problem damit, wenn Sie denselben User Agent immer wieder verwenden.
Wenn Sie es jedoch nur einmal verwenden, bleiben die Dinge organisiert und die Wahrscheinlichkeit menschlicher Fehler wird verringert.
3. Verwenden Sie Platzhalter, um Anweisungen zu vereinfachen
Wenn Sie eine große Anzahl von Seiten blockieren müssen, kann das Hinzufügen einer Regel für jede Seite zeitaufwändig sein. Glücklicherweise können Sie Platzhalter verwenden, um Ihre Anweisungen zu vereinfachen.
Ein Platzhalter ist ein Zeichen, das ein oder mehrere Zeichen darstellen kann. Der am häufigsten verwendete Platzhalter ist das Sternchen (*).
Wenn Sie beispielsweise alle Dateien blockieren möchten, die auf .jpg enden, würden Sie die folgende Regel hinzufügen:
Disallow: /*.jpg
4. Verwenden Sie „$“, um das Ende einer URL anzugeben
Das Dollarzeichen ($) ist ein weiterer Platzhalter, der verwendet werden kann, um das Ende einer URL zu kennzeichnen. Dies ist nützlich, wenn Sie eine bestimmte Seite einschränken möchten, aber nicht die darauffolgenden.
Angenommen, Sie möchten die Kontaktseite, aber nicht die Kontakterfolgsseite blockieren, würden Sie die folgende Regel hinzufügen:
Disallow: /contact$
5. Verwenden Sie die Raute (#), um Kommentare hinzuzufügen
Alles, was mit einem Hash (#) beginnt, wird von Crawlern ignoriert.
Daher verwenden Entwickler häufig den Hash, um Kommentare zur robots.txt-Datei hinzuzufügen. Es hält das Dokument organisiert und lesbar.
Wenn Sie beispielsweise verhindern möchten, dass alle Dateien auf .jpg enden, können Sie den folgenden Kommentar hinzufügen:
# Block all files that end in .jpg Disallow: /*.jpg
Dies hilft jedem zu verstehen, wofür die Regel ist und warum sie da ist.
6. Verwenden Sie separate Robots.txt-Dateien für jede Subdomain
Wenn Sie eine Website mit mehreren Subdomains haben, wird empfohlen, für jede einzelne eine eigene robots.txt-Datei zu erstellen. Dies hält die Dinge organisiert und hilft Suchmaschinen-Crawlern, Ihre Regeln leichter zu verstehen.
Abschluss!
Die robots.txt-Datei ist ein nützliches SEO-Tool, da sie Suchmaschinen-Bots anweist, was zu indizieren ist und was nicht.
Es ist jedoch wichtig, es mit Vorsicht zu verwenden. Denn eine Fehlkonfiguration kann dazu führen, dass Ihre Website komplett deindexiert wird (zB mit Disallow: /).
Im Allgemeinen besteht der gute Weg darin, Suchmaschinen zu erlauben, so viel wie möglich von Ihrer Website zu scannen, während vertrauliche Informationen aufbewahrt und doppelte Inhalte vermieden werden. Beispielsweise können Sie die Disallow-Direktive verwenden, um bestimmte Seiten oder Verzeichnisse zu verhindern, oder die Allow-Direktive, um eine Disallow-Regel für eine bestimmte Seite außer Kraft zu setzen.
Es ist auch erwähnenswert, dass nicht alle Bots die in der robots.txt-Datei bereitgestellten Regeln befolgen, daher ist dies keine perfekte Methode, um zu steuern, was indiziert wird. Aber es ist immer noch ein wertvolles Werkzeug für Ihre SEO-Strategie.
Wir hoffen, dass dieser Leitfaden Ihnen dabei hilft, zu erfahren, was eine robots.txt-Datei ist und wie man sie erstellt.
Weitere Informationen finden Sie in diesen anderen hilfreichen Ressourcen:
- 15 umsetzbare Blogging-Tipps für neue Blogger
- Die Kraft von Long-Tail-Keywords freisetzen (Leitfaden für Anfänger)
Folgen Sie uns zu guter Letzt auf Twitter, um regelmäßig über neue Artikel informiert zu werden.