
Die WordPress robots.txt-Datei… Was es ist und was es tut
Veröffentlicht: 2020-11-25Haben Sie sich jemals gefragt, was eine robots.txt-Datei ist und was sie tut? Robots.txt wird verwendet, um mit den Web-Crawlern (bekannt als Bots) zu kommunizieren, die von Google und anderen Suchmaschinen verwendet werden. Es teilt ihnen mit, welche Teile Ihrer Website indexiert und welche ignoriert werden sollen. Daher kann die robots.txt-Datei dazu beitragen, Ihre SEO-Bemühungen zu unterstützen (oder möglicherweise zu brechen!). Wenn Sie möchten, dass Ihre Website gut rankt, ist ein gutes Verständnis von robots.txt unerlässlich!
Wo befindet sich robots.txt?
WordPress führt normalerweise eine sogenannte „virtuelle“ robots.txt-Datei aus, was bedeutet, dass sie nicht über SFTP zugänglich ist. Sie können jedoch den grundlegenden Inhalt anzeigen, indem Sie zu yourdomain.com/robots.txt gehen. Sie werden wahrscheinlich so etwas sehen:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpDie erste Zeile gibt an, für welche Bots die Regeln gelten. In unserem Beispiel bedeutet das Sternchen, dass die Regeln auf alle Bots (z. B. von Google, Bing usw.) angewendet werden.
Die zweite Zeile definiert eine Regel, die den Zugriff von Bots auf den Ordner /wp-admin verhindert, und die dritte Zeile besagt, dass Bots die Datei /wp-admin/admin-ajax.php parsen dürfen.
Fügen Sie Ihre eigenen Regeln hinzu
Für eine einfache WordPress-Website können die von WordPress auf die robots.txt-Datei angewendeten Standardregeln mehr als ausreichend sein. Wenn Sie jedoch mehr Kontrolle und die Möglichkeit haben möchten, Ihre eigenen Regeln hinzuzufügen, um Suchmaschinen-Bots spezifischere Anweisungen zum Indexieren Ihrer Website zu geben, müssen Sie Ihre eigene physische robots.txt-Datei erstellen und sie unter das Stammverzeichnis legen Verzeichnis Ihrer Installation.
Es gibt mehrere Gründe, warum Sie Ihre robots.txt-Datei möglicherweise neu konfigurieren und definieren sollten, was genau diese Bots crawlen dürfen. Einer der Hauptgründe ist die Zeit, die ein Bot mit dem Crawlen Ihrer Website verbringt. Google (und andere) erlauben Bots nicht, unbegrenzt Zeit auf jeder Website zu verbringen… Bei Billionen von Seiten müssen sie einen nuancierteren Ansatz wählen, was ihre Bots crawlen und was sie ignorieren, um die nützlichsten Informationen zu extrahieren über eine Webseite.

Hosten Sie Ihre Website mit Pressidium
60- TÄGIGE GELD-ZURÜCK-GARANTIE
Wenn Sie Bots erlauben, alle Seiten Ihrer Website zu crawlen, wird ein Teil der Crawling-Zeit für Seiten aufgewendet, die nicht wichtig oder sogar relevant sind. Dadurch bleibt ihnen weniger Zeit, sich durch die relevanteren Bereiche Ihrer Website zu arbeiten. Indem Sie den Bot-Zugriff auf einige Teile Ihrer Website verbieten, erhöhen Sie die verfügbare Zeit für Bots, um Informationen aus den relevantesten Teilen Ihrer Website zu extrahieren (die hoffentlich indiziert werden). Da das Crawlen schneller ist, ist es wahrscheinlicher, dass Google Ihre Website erneut besucht und den Index Ihrer Website auf dem neuesten Stand hält. Das bedeutet, dass neue Blog-Posts und andere frische Inhalte wahrscheinlich schneller indiziert werden, was eine gute Nachricht ist.
Beispiele für die Bearbeitung von Robots.txt
Die robots.txt bietet viel Raum für Anpassungen. Daher haben wir eine Reihe von Beispielen für Regeln bereitgestellt, die verwendet werden können, um festzulegen, wie Bots Ihre Website indizieren.
Bots zulassen oder verbieten
Schauen wir uns zunächst an, wie wir einen bestimmten Bot einschränken können. Dazu müssen wir lediglich das Sternchen (*) durch den Namen des Bot-Benutzeragenten ersetzen, den wir blockieren möchten, zum Beispiel „MSNBot“. Eine umfassende Liste bekannter User-Agents finden Sie hier.
User-agent: MSNBot Disallow: /Durch einen Bindestrich in der zweiten Zeile wird der Zugriff des Bots auf alle Verzeichnisse eingeschränkt.
Damit nur ein einziger Bot unsere Website crawlen kann, verwenden wir einen zweistufigen Prozess. Zuerst würden wir diesen einen Bot als Ausnahme festlegen und dann alle Bots wie folgt verbieten:
User-agent: Google Disallow: User-agent: * Disallow: /Um allen Bots Zugriff auf alle Inhalte zu gewähren, fügen wir diese beiden Zeilen hinzu:
User-agent: * Disallow:Den gleichen Effekt würde man erzielen, indem man einfach eine robots.txt-Datei erstellt und diese dann einfach leer lässt.
Sperren des Zugriffs auf bestimmte Dateien
Möchten Sie verhindern, dass Bots bestimmte Dateien auf Ihrer Website indizieren? Das ist leicht! Im folgenden Beispiel haben wir Suchmaschinen daran gehindert, auf alle .pdf-Dateien auf unserer Website zuzugreifen.
User-agent: * Disallow: /*.pdf$Das „$“-Symbol wird verwendet, um das Ende der URL zu definieren. Da hier zwischen Groß- und Kleinschreibung unterschieden wird, wird eine Datei mit dem Namen my.PDF trotzdem gecrawlt (beachten Sie die GROSSBUCHSTABEN).
Komplexe logische Ausdrücke
Einige Suchmaschinen, wie Google, verstehen die Verwendung komplizierterer regulärer Ausdrücke. Es ist jedoch wichtig zu beachten, dass möglicherweise nicht alle Suchmaschinen in der Lage sind, logische Ausdrücke in robots.txt zu verstehen.

Ein Beispiel hierfür ist die Verwendung des $-Symbols. In robots.txt-Dateien zeigt dieses Symbol das Ende einer URL an. Im folgenden Beispiel haben wir also Such-Bots daran gehindert, Dateien zu lesen und zu indizieren, die auf .php enden
Disallow: /*.php$Das bedeutet, dass /index.php nicht indiziert werden kann, aber /index.php?p=1 könnte es sein. Dies ist nur unter ganz bestimmten Umständen nützlich und muss mit Vorsicht verwendet werden, da Sie sonst Gefahr laufen, den Bot-Zugriff auf Dateien zu blockieren, die Sie nicht beabsichtigt haben!
Sie können auch unterschiedliche Regeln für jeden Bot festlegen, indem Sie die Regeln angeben, die für sie einzeln gelten. Der folgende Beispielcode beschränkt den Zugriff auf den wp-admin-Ordner für alle Bots und blockiert gleichzeitig den Zugriff auf die gesamte Website für die Bing-Suchmaschine. Sie würden das nicht unbedingt wollen, aber es ist eine nützliche Demonstration dafür, wie flexibel die Regeln in einer robots.txt-Datei sein können.
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /XML-Sitemaps
XML-Sitemaps helfen Suchbots wirklich, das Layout Ihrer Website zu verstehen. Aber um nützlich zu sein, muss der Bot wissen, wo sich die Sitemap befindet. Die „Sitemap-Direktive“ wird verwendet, um Suchmaschinen ausdrücklich mitzuteilen, dass a) eine Sitemap Ihrer Website existiert und b) wo sie sie finden können.
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:Sie können auch mehrere Sitemap-Speicherorte angeben:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* DisallowBot-Crawling-Verzögerungen
Eine weitere Funktion, die über die robots.txt-Datei erreicht werden kann, besteht darin, Bots anzuweisen, das Crawlen Ihrer Website zu „verlangsamen“. Dies kann erforderlich sein, wenn Sie feststellen, dass Ihr Server durch hohen Bot-Datenverkehr überlastet ist. Dazu geben Sie den User-Agent an, den Sie verlangsamen möchten, und fügen dann eine Verzögerung hinzu.
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10Die Zahl in Anführungszeichen (10) in diesem Beispiel ist die Verzögerung, die zwischen dem Crawlen einzelner Seiten auf Ihrer Website auftreten soll. Im obigen Beispiel haben wir also den Bing-Bot gebeten, zwischen jeder Seite, die er durchsucht, zehn Sekunden lang anzuhalten und damit unserem Server etwas Luft zum Atmen zu geben.
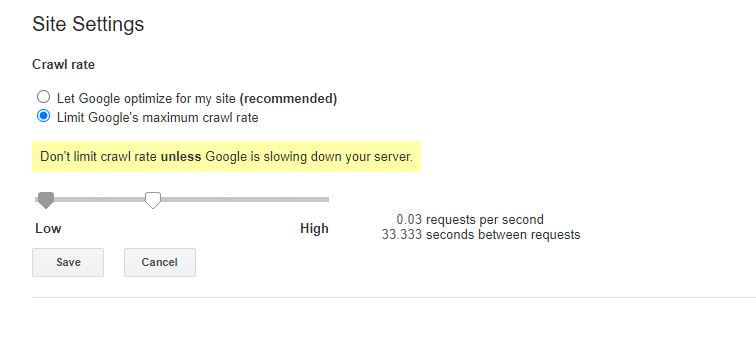
Die einzige etwas schlechte Nachricht zu dieser speziellen robots.txt-Regel ist, dass der Bot von Google sie nicht respektiert. Sie können ihre Bots jedoch über die Google Search Console anweisen, langsamer zu werden.
Hinweise zu robots.txt-Regeln:
- Bei allen robots.txt-Regeln wird zwischen Groß- und Kleinschreibung unterschieden. Tippen Sie sorgfältig!
- Achten Sie darauf, dass vor dem Befehl am Zeilenanfang keine Leerzeichen stehen.
- Es kann 24–36 Stunden dauern, bis Änderungen in robots.txt von Bots bemerkt werden.
So testen und übermitteln Sie Ihre WordPress robots.txt-Datei
Wenn Sie eine neue robots.txt-Datei erstellt haben, sollten Sie überprüfen, ob sie keine Fehler enthält. Sie können dies tun, indem Sie die Google Search Console verwenden.
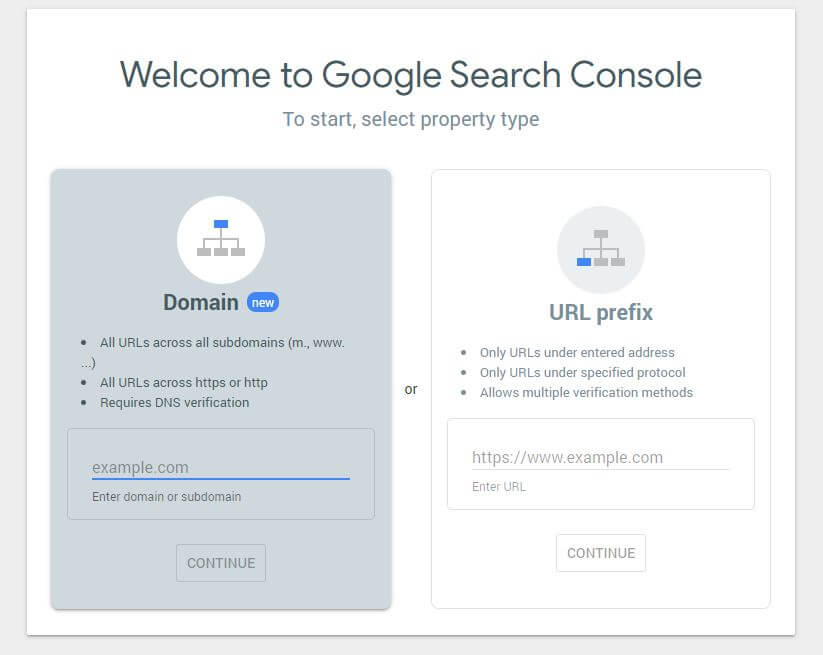
Zuerst müssen Sie Ihre Domain einreichen (falls Sie noch kein Search Console-Konto für die Einrichtung Ihrer Website haben). Google stellt Ihnen einen TXT-Eintrag zur Verfügung, der Ihrem DNS hinzugefügt werden muss, um Ihre Domain zu verifizieren.
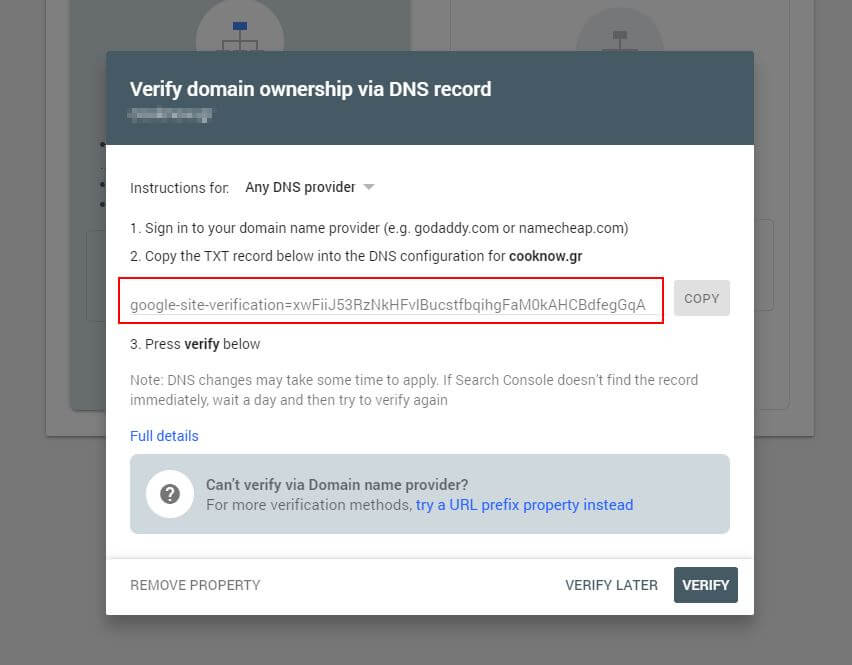
Sobald sich dieses DNS-Update verbreitet hat (Sie sind ungeduldig … versuchen Sie es mit Cloudflare, um Ihr DNS zu verwalten), können Sie den robots.txt-Tester besuchen und prüfen, ob es Warnungen zum Inhalt Ihrer robots.txt-Datei gibt.
Eine andere Möglichkeit, um zu testen, ob die von Ihnen eingerichteten Regeln den gewünschten Effekt haben, ist die Verwendung eines robots.txt-Testtools wie Ryte.
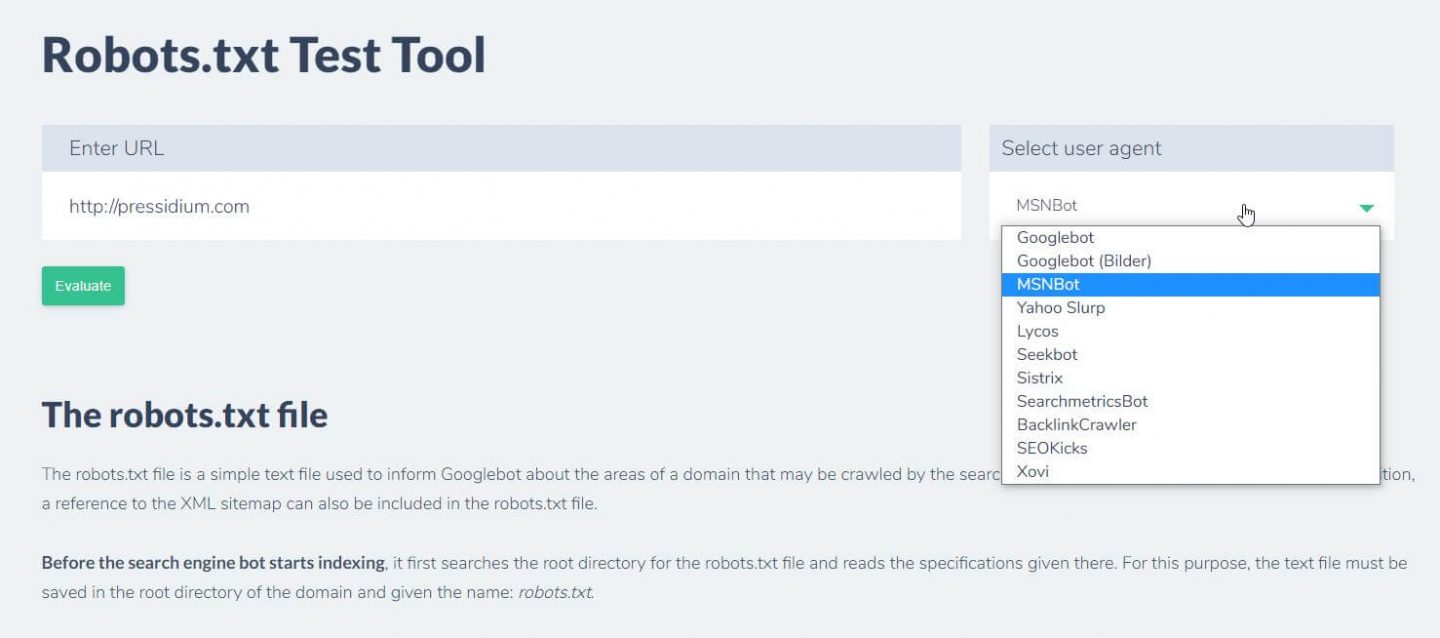
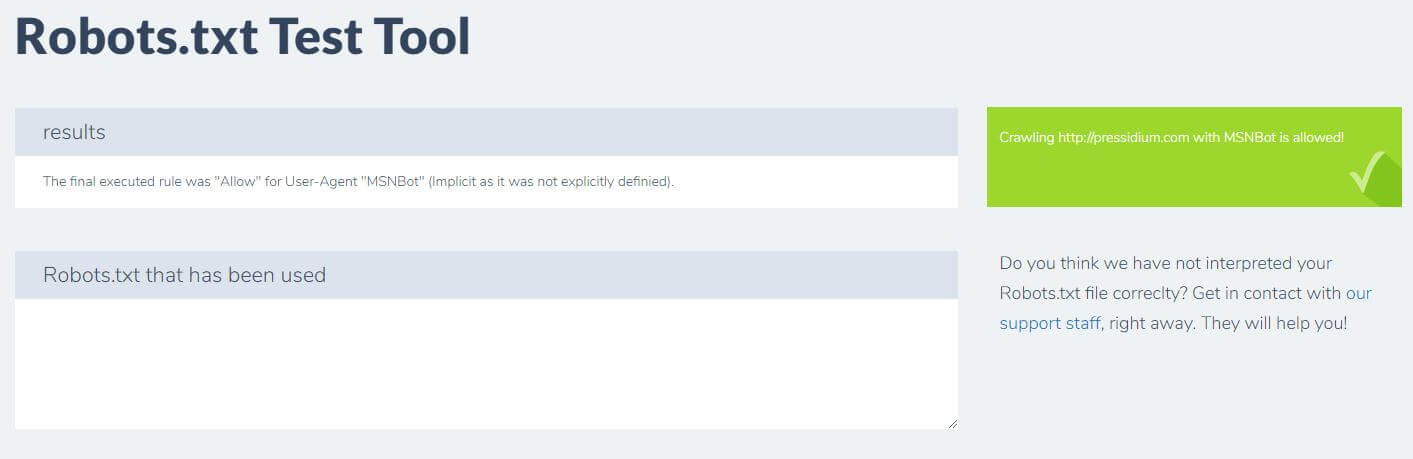
Geben Sie einfach Ihre Domain ein und wählen Sie einen Benutzeragenten aus dem Panel auf der rechten Seite. Nach dem Absenden sehen Sie Ihre Ergebnisse.
Fazit
Zu wissen, wie robots.txt verwendet wird, ist ein weiteres nützliches Tool in Ihrem Entwickler-Toolkit. Wenn das einzige, was Sie aus diesem Tutorial mitnehmen, die Möglichkeit ist, zu überprüfen, ob Ihre robots.txt-Datei keine Bots wie Google blockiert (was Sie wahrscheinlich nicht tun möchten), dann ist das keine schlechte Sache! Ebenso bietet robots.txt, wie Sie sehen können, eine ganze Reihe weiterer feinkörniger Kontrollmöglichkeiten über Ihre Website, die sich eines Tages als nützlich erweisen könnten.