
WordPress Robots.txt で避けるべき 14 のよくある間違い
公開: 2025-01-14Robots.txt は、検索クローラーやその他のボットに WordPress Web サイト上での動作方法を指示する強力なサーバー ファイルです。これは、サイトの検索エンジン最適化 (SEO) にプラスとマイナスの両方で大きな影響を与える可能性があります。
そのため、このファイルが何であるか、またその使用方法を理解しておく必要があります。そうしないと、Web サイトに損害を与えたり、少なくともその可能性の一部を台無しにしてしまう可能性があります。
このシナリオを回避できるように、この投稿では robots.txt ファイルについて詳しく説明します。ファイルとは何か、その目的、ファイルを見つけて管理する方法、ファイルに何を含めるべきかを定義します。その後、WordPress の robots.txt でよくある間違い、それらを回避する方法、間違いを犯した場合の回復方法について説明します。
WordPress robots.txt とは何ですか?
前述したように、robots.txt はサーバー構成ファイルです。通常、これはサーバーのルート フォルダーにあります。
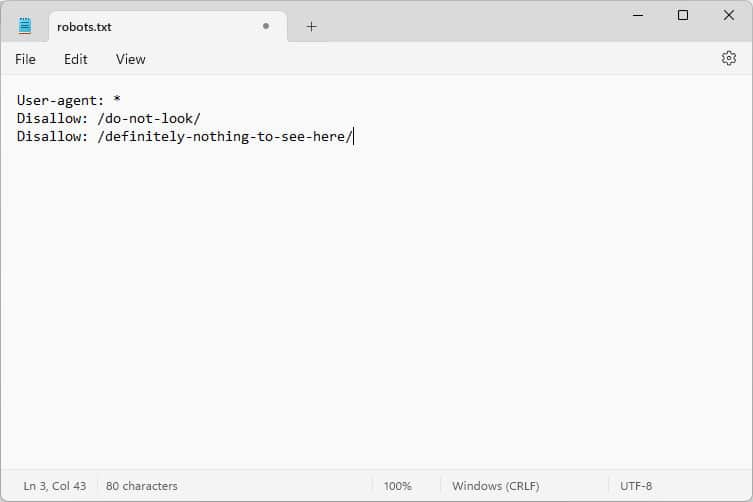
開くと中身はこんな感じです。
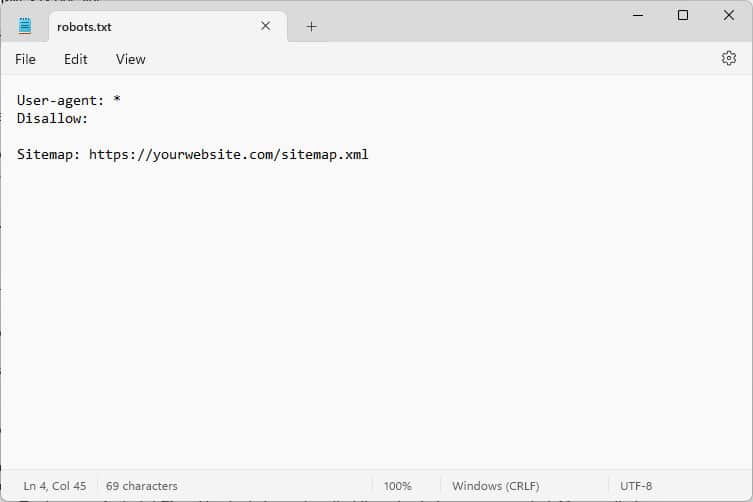
これらのコードは、Web サイトにアクセスするボットに、そこにいる間の行動方法、具体的には、Web サイトのどの部分にアクセスし、どの部分にアクセスしないかを指示する指示です。
どのようなボットですか?
最も一般的な例は、インデックス付けまたは更新する Web ページを探す検索エンジンからの自動クローラーですが、AI モデルやその他の自動化ツールからのボットも含まれます。
このファイルにはどのような指示を与えることができますか?
Robots.txt は基本的に 4 つの主要なディレクティブを認識します。
- ユーザー エージェント– 誰を定義します。つまり、従うルールがどのグループまたは個々のボットに適用されるかを定義します。
- 禁止– ユーザー エージェントがアクセスを禁止されているディレクトリ、ファイル、またはリソースを示します。
- 許可– 例外を設定するために使用できます。たとえば、他の方法では禁止されているディレクトリ内の個々のフォルダーやリソースへのアクセスを許可します。
- サイトマップ– ボットに Web サイトのサイトマップの URL の場所を指示します。
ファイルがそのジョブを実行するために必須なのは、 User-agentとDisallowだけです。他の 2 つのディレクティブはオプションです。たとえば、ボットによるサイトへのアクセスをブロックする方法は次のとおりです。
User-agent: * Disallow: /アスタリスクは、次のルールがすべてのユーザー エージェントに適用されることを示します。 Disallowの後のスラッシュは、このサイト上のすべてのディレクトリが立ち入り禁止であることを示します。これは開発サイトでよく見られる robots.txt ファイルで、検索エンジンによってインデックスが作成されることは想定されていません。
ただし、個々のボットにルールを設定することもできます。
User-agent: Googlebot Allow: /private/resources/robots.txt はバインドされていないことに注意することが重要です。ロボット排除プロトコルに準拠する組織のボットのみがその指示に従います。サイトのセキュリティ上の欠陥を探すような悪意のあるボットは無視する可能性があるため、追加の対策を講じる必要があります。
標準を遵守している組織であっても、一部の指令は無視されます。その例については後ほど説明します。
robots.txt が重要な理由
WordPress サイトに robots.txt ファイルが存在することは必須ではありません。サイトはそれがなくても機能し、検索エンジンがそれを持っていなくてもペナルティを課すことはありません。ただし、これを含めると次のことが可能になります。
- ログイン ページや特定のメディア ファイルなどのコンテンツを検索結果から除外します。
- 検索クローラーがサイトの重要でない部分にクロール予算を浪費し、インデックスを付けたいページを無視することを防ぎます。
- 検索エンジンがサイトマップを参照できるようにすることで、Web サイトの残りの部分をより簡単に探索できるようになります。
- 無駄なボットを排除してサーバー リソースを保護します。
これらすべてはサイト、特に SEO の改善に役立ちます。そのため、robots.txt の使用方法を理解することが重要です。
WordPress の robots.txt を検索、編集、作成する方法
前述したように、robots.txt は通常、サーバー上の Web サイトのルート フォルダーにあります。 FileZilla などの FTP クライアントを使用してそこにアクセスし、任意のテキスト エディターで編集できます。
ファイルがない場合は、空のテキスト ファイルを作成して「robots.txt」という名前を付け、ディレクティブを入力してアップロードすることができます。
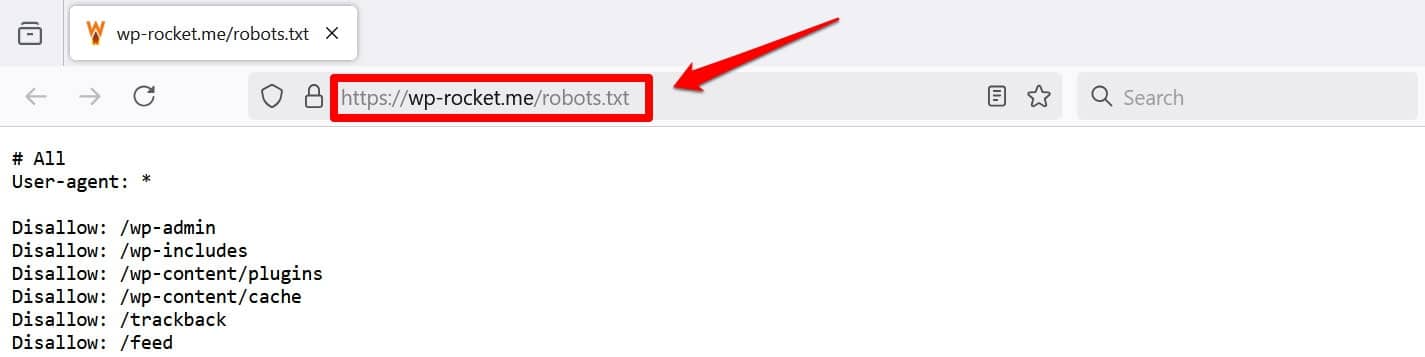
少なくともファイルを表示するもう 1 つの方法は、 /robots.txt をドメインに追加することです (例: https://wp-rocket.me/robots.txt)。
さらに、WordPress バックエンドからファイルにアクセスする方法もあります。多くの SEO プラグインでは、管理インターフェイスからプラグインを確認したり、変更を加えたりすることができます。
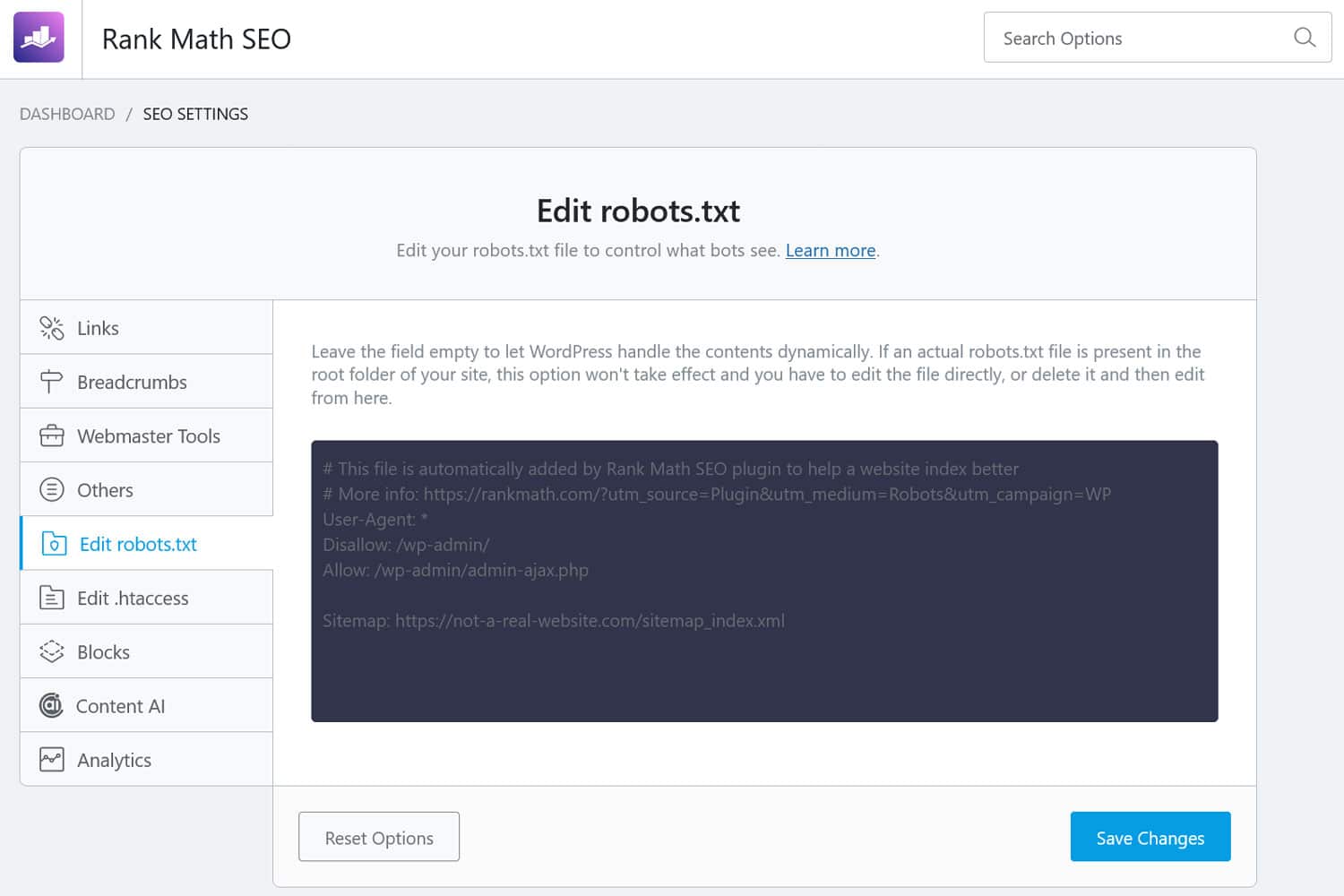
あるいは、WPCode などのプラグインを使用することもできます。
優れた WordPress robots.txt ファイルとはどのようなものですか?
Web サイトのファイルにどのようなディレクティブを含めるべきかについて、万能の答えはありません。それは設定によって異なります。以下は、多くの WordPress Web サイトにとって意味のある例です。
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://yourwebsite.com/sitemap.xmlこの例では、いくつかの結果が得られます。
- 管理領域へのアクセスをブロックします
- 重要な管理機能へのアクセスを許可します
- サイトマップの場所を提供します
この設定では、セキュリティ、SEO パフォーマンス、効率的なクロールのバランスが取れています。
WordPress robots.txt での 14 の間違いを犯さないでください
自分のサイト用に robots.txt を設定して最適化することが目的の場合は、次のエラーを必ず回避してください。
1. 内部WordPressのrobots.txtを無視する
サイトのルート ディレクトリに「物理的な」robots.txt ファイルがない場合でも、WordPress には独自の仮想ファイルが付属しています。検索エンジンが Web サイトのインデックスを作成していないことに気付いた場合は、これを覚えておくことが特に重要です。
その場合は、 [設定] > [読書]で、ユーザーがそうすることを妨げるオプションを有効にしている可能性が高くなります。
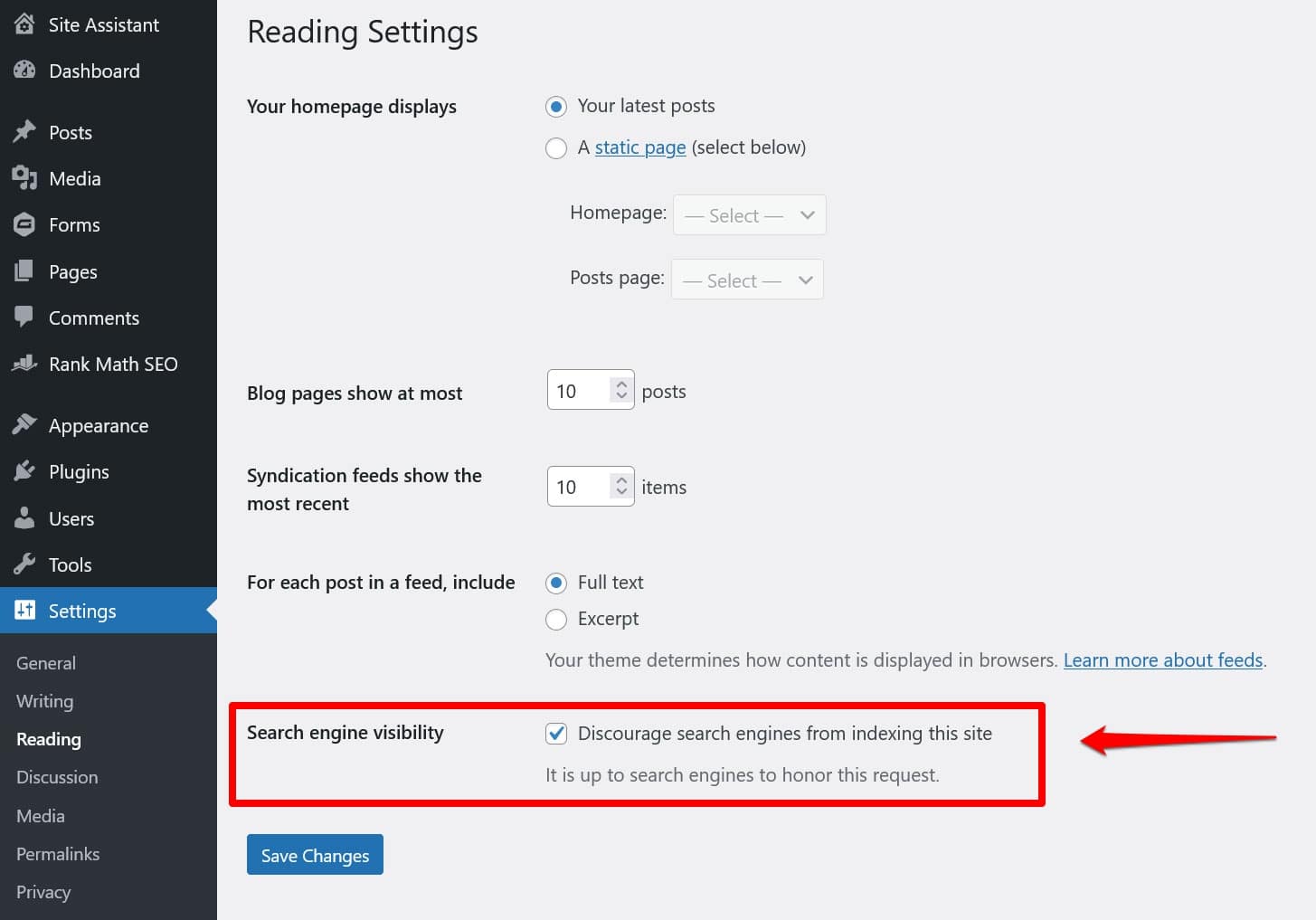
これにより、すべての検索クローラーを仮想 robots.txt に含めないようにするディレクティブが設定されます。無効にするには、ボックスのチェックを外して下部に保存します。
2. 間違った場所に置く
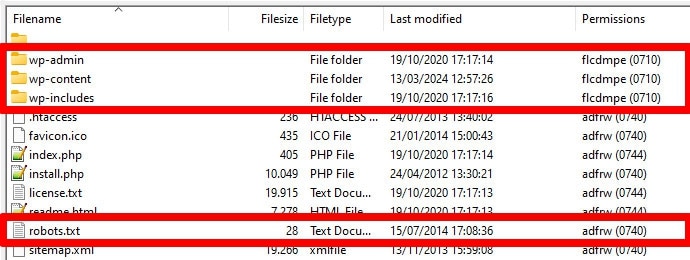
ボット、特に検索クローラーは、robots.txt ファイルを 1 つの場所 (Web サイトのルート ディレクトリ) でのみ検索します。フォルダーなど、他の場所に置いた場合、検索者はそれを見つけることができず、無視します。
WordPress をサブディレクトリに配置していない限り、ルート ディレクトリは、FTP 経由でサーバーにアクセスするときに到達する場所でなければなりません。 wp-admin 、 wp-content 、およびwp-includesフォルダーが表示されていれば、正しい場所にいます。
3. 古いマークアップを含む
上記のディレクティブの他に、古い Web サイトの robots.txt ファイルでまだ見つかる可能性のあるディレクティブがさらに 2 つあります。
- Noindex – 検索エンジンがサイトのインデックスを作成しない URL を指定するために使用されます。
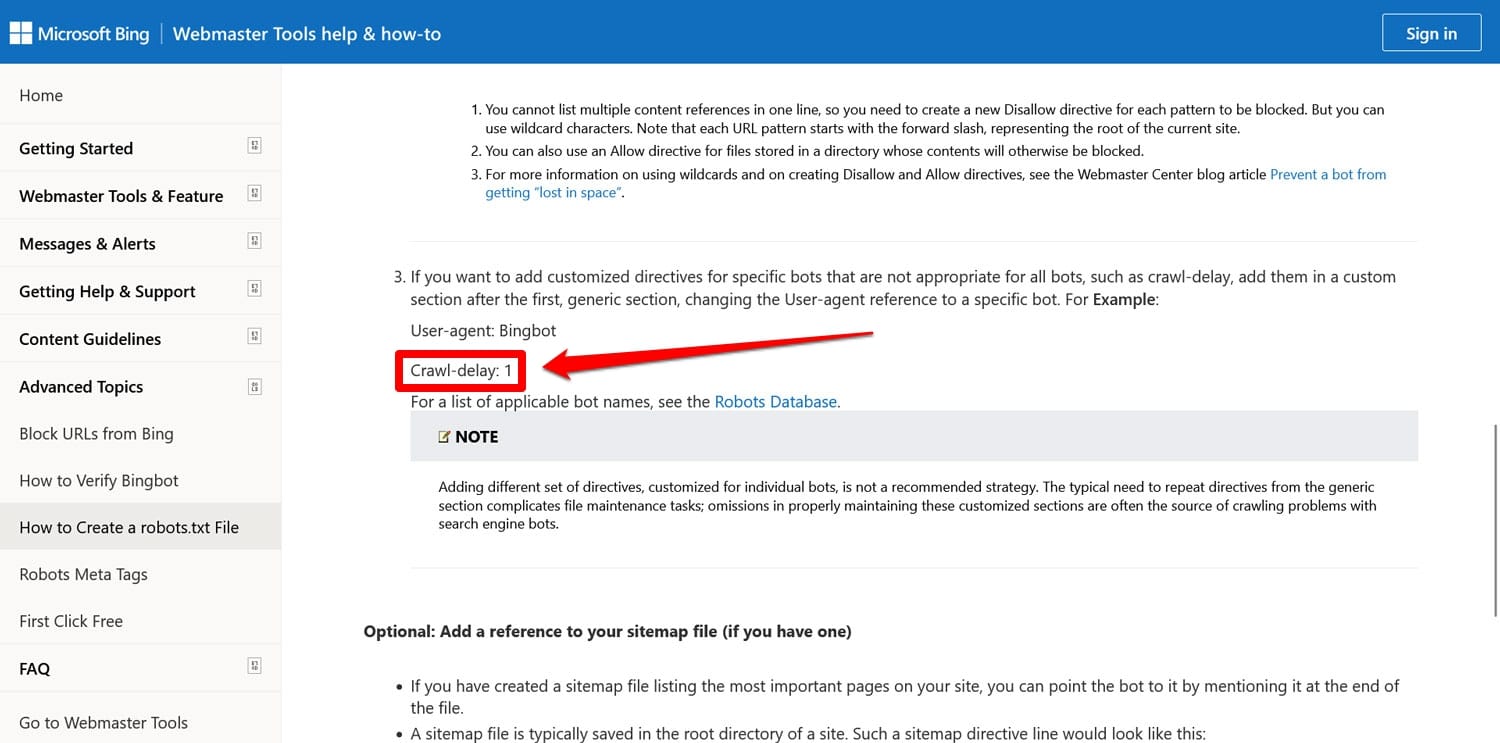
- クロール遅延– クローラーが Web サーバーのリソースに過負荷をかけないように、クローラーを調整することを目的としたディレクティブ。
これらのディレクティブは両方とも、少なくとも Google では現在無視されています。少なくとも、Bing は依然としてクロール遅延を尊重しています。
ほとんどの場合、これらのディレクティブは使用しないことが最善です。これにより、ファイルを無駄のない状態に保ち、エラーのリスクを軽減できます。
ヒント:検索エンジンが特定のページのインデックスを作成しないようにすることが目標の場合は、代わりにnoindexメタ タグを使用します。 SEO プラグインを使用してページごとに実装できます。
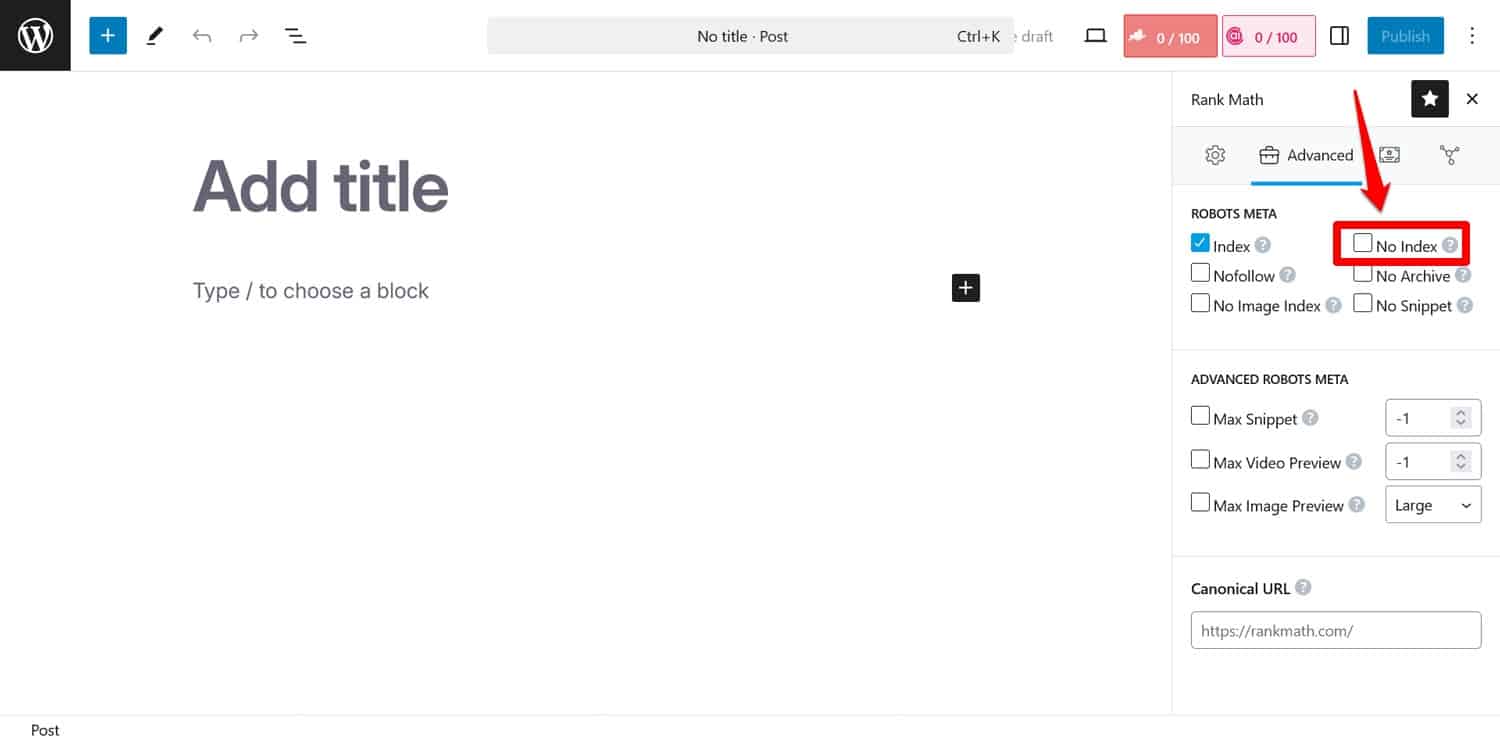
robots.txt 経由でページをブロックすると、クローラーはnoindexタグが表示される部分に到達できなくなります。そうすれば、ページのインデックスが作成されてもコンテンツが削除される可能性があり、これはさらに悪いことです。
4. 重要なリソースのブロック
人々が犯す間違いの 1 つは、クロール バジェットを維持するために、robots.txt を使用して WordPress サイト上のすべてのスタイル シート (CSS ファイル) とスクリプト (JavaScript ファイル) へのアクセスをブロックすることです。
しかし、それは良い考えではありません。検索エンジンのボットは、訪問者と同じようにページをレンダリングして「見る」ことができます。これはコンテンツを理解し、それに応じてインデックスを付けるのに役立ちます。
これらのリソースをブロックすると、検索エンジンにページに対して誤った印象を与え、ページが適切にインデックスされなかったり、ランキングが低下したりする可能性があります。
CSS および JavaScript ファイルがサイトのパフォーマンスを妨げている可能性があると思われる場合は、ボットと通常の訪問者の両方にとって、CSS および JavaScript ファイルが迅速に読み込まれるように最適化することをお勧めします。これを行うには、コードを縮小し、Web サイトのファイルを圧縮して、より高速に送信できるようにします。さらに、未使用のコードを削除し、レンダリングをブロックするリソースを延期することで、配信を最適化することができます。

ヒント: WP Rocket などのパフォーマンス プラグインを使用すると、このプロセスを簡素化できます。ユーザーフレンドリーなインターフェイスにより、 [ファイル最適化]メニューのいくつかのボックスをチェックすることでファイル配信を最適化できます。
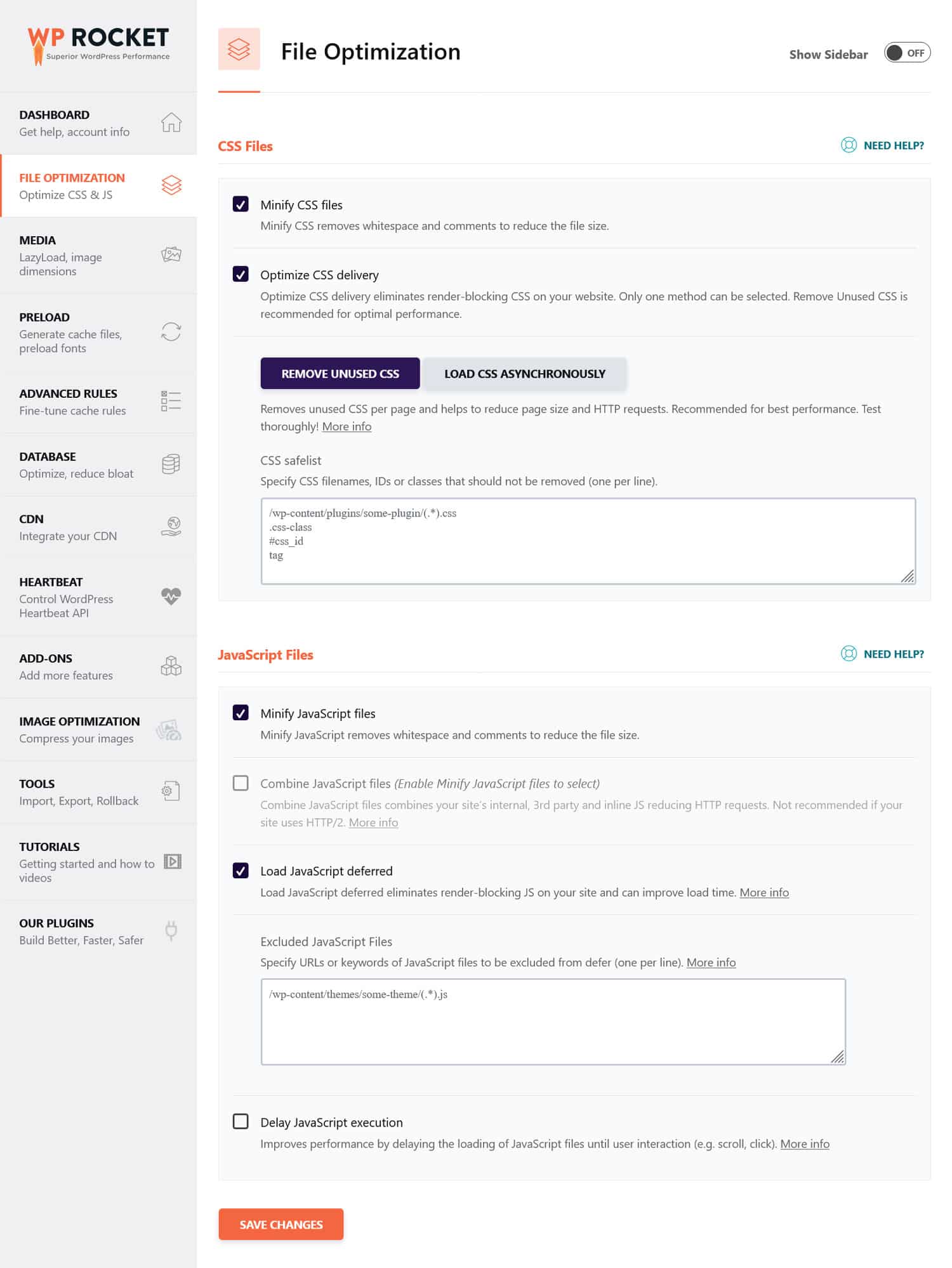
WP Rocket には、Web サイトのパフォーマンスを向上させるための次のような追加機能も付属しています。
- 専用のモバイルキャッシュを使用したキャッシング
- 画像やビデオの遅延読み込み
- キャッシュ、リンク、外部ファイル、フォントのプリロード
- データベースの最適化
さらに、プラグインは多くの最適化ステップを自動的に実装します。例には、ブラウザとサーバーのキャッシュ、GZIP 圧縮、LCP を改善するためのスクロールせずに見える画像の最適化などが含まれます。そうすれば、WP Rocket をオンにするだけでサイトが高速化されます。
このプラグインには 14 日間の返金保証も提供されているため、リスクなくテストできます。
5. 開発 robots.txt の更新に失敗する
Web サイトを構築するとき、開発者は通常、すべてのボットによるアクセスを禁止する robots.txt ファイルを含めます。これは理にかなっています。未完成のサイトが検索結果に表示されることは最も避けたいことです。
問題が発生するのは、このファイルを誤って運用サーバーに転送し、検索エンジンがライブ Web サイトのインデックス作成をブロックした場合のみです。コンテンツが検索結果に表示されない場合は、必ずこれを確認してください。
6. サイトマップへのリンクを含めない
robots.txt からサイトマップにリンクすると、検索エンジン クローラーにすべてのコンテンツのリストが提供されます。これにより、アクセスした現在のページ以外にもインデックスが作成される可能性が高まります。
必要なのは 1 行だけです。
Sitemap: https://yourwebsite.com/sitemap.xmlはい、Google Search Console などのツールでサイトマップを直接送信することもできます。
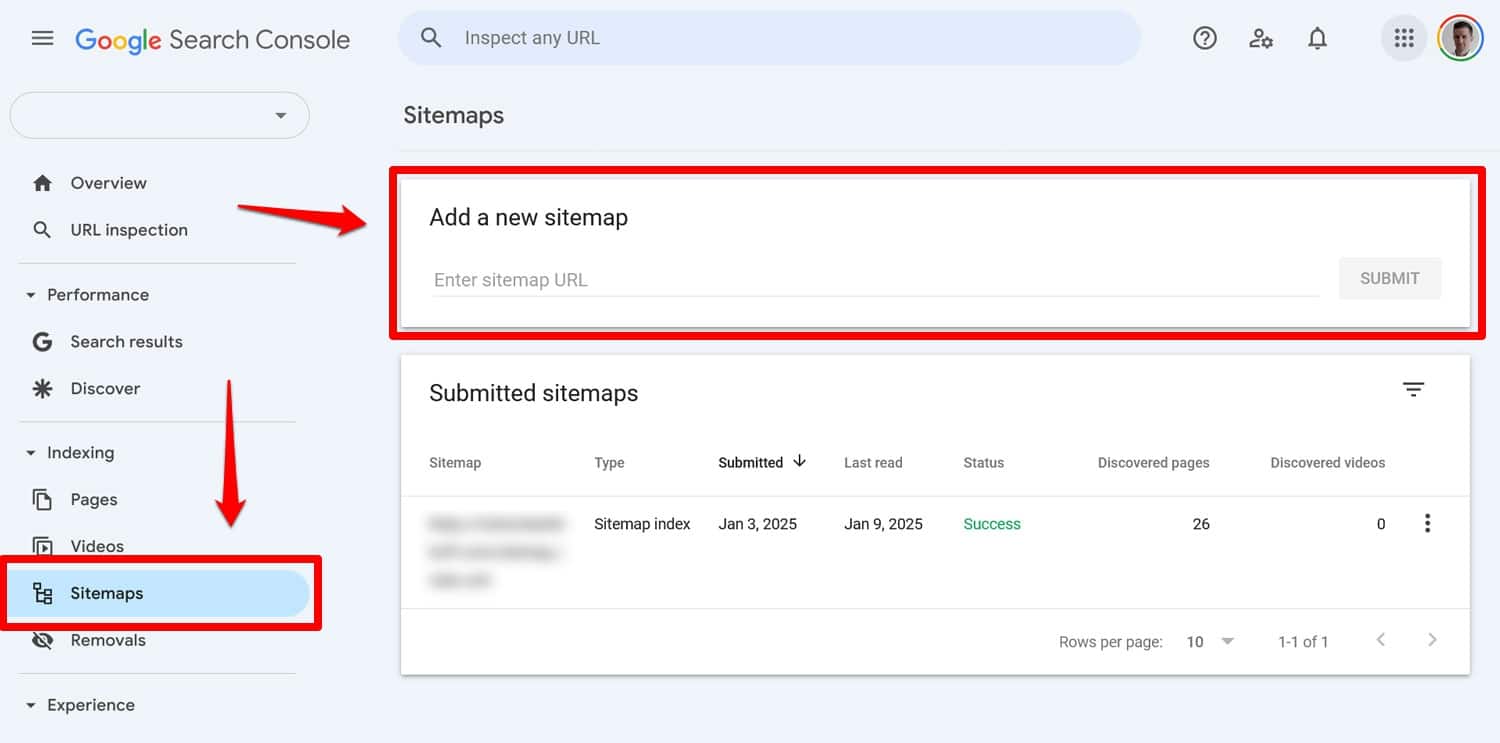
ただし、これを robots.txt ファイルに含めることは、特にウェブマスター ツールを使用していない検索エンジンにとっては役立ちます。
7. 矛盾するルールの使用
robots.txt ファイルの作成時によくある間違いの 1 つは、次のような相互に矛盾するルールを追加することです。
User-agent: * Disallow: /blog/ Allow: /blog/上記のディレクティブにより、検索エンジンは/blog/ディレクトリをクロールする必要があるかどうかが不明瞭になります。これにより、予期しない結果が生じ、SEO に損害を与える可能性があります。
| サイトの検索ランキングに悪影響を及ぼす可能性のあるものと、それを回避する方法について知りたいですか?これについては、SEO の間違いに関するガイドで学びましょう。 |
競合を回避するには、次のベスト プラクティスに従ってください。
- 特定のルールを最初に使用する– より具体的なルールをより広範なルールよりも前に配置します。
- 冗長性を避ける– 同じパスに反対のディレクティブを含めないでください。
- robots.txt ファイルをテストする– ツールを使用して、ルールが期待どおりに動作することを確認します。詳細については以下をご覧ください。
8. robots.txt を使用して機密コンテンツを隠そうとする
前述したように、robots.txt はコンテンツを検索結果から除外するツールではありません。実際、このファイルは公的にアクセスできるため、機密コンテンツをブロックするためにこのファイルを使用すると、そのコンテンツがどこにあるかを誤って明らかにしてしまう可能性があります。
ヒント: noindexメタ タグを使用して、コンテンツを検索結果から除外します。さらに、サイトの機密領域をパスワードで保護し、ロボットや権限のないユーザーの両方から安全に保ちます。
9. ワイルドカードの不適切な使用
ワイルドカードを使用すると、パスまたはファイルの大規模なグループをディレクティブに含めることができます。 * 記号については、すでに前に説明しました。これは「~のすべてのインスタンス」を意味し、すべてのユーザー エージェントに適用されるルールを設定するために最もよく使用されます。
もう 1 つのワイルドカード記号は $ で、これは URL の末尾部分にルールを適用します。たとえば、サイト上のすべての PDF ファイルにクローラーがアクセスするのをブロックしたい場合に使用できます。
Disallow: /*.pdf$ワイルドカードは便利ですが、広範囲にわたる影響を与える可能性があります。これらは慎重に使用し、常に robots.txt ファイルをテストして、間違いがないかどうかを確認してください。
10. 絶対 URL と相対 URL の混同
絶対 URL と相対 URL の違いは次のとおりです。
- 絶対 URL – https://yourwebsite.com/private/
- 相対 URL – /private/
robots.txt ディレクティブでは、次のような相対 URL を使用することをお勧めします。
Disallow: /private/絶対 URL は、ボットがディレクティブを無視または誤って解釈する可能性がある問題を引き起こす可能性があります。唯一の例外はサイトマップへのパスであり、絶対 URL である必要があります。
11. 大文字と小文字の区別を無視する
Robots.txt ディレクティブでは大文字と小文字が区別されます。これは、次の 2 つのディレクティブは互換性がないことを意味します。
Disallow: /Private/ Disallow: /private/robots.txt ファイルが期待どおりに動作していないことがわかった場合は、大文字と小文字の区別が間違っていることが問題であるかどうかを確認してください。
12. 末尾のスラッシュの誤った使用
末尾のスラッシュは、URL の末尾にあるスラッシュです。
- 末尾のスラッシュなし: /directory
- 末尾にスラッシュを付ける場合: /directory/
robots.txt では、どのサイト リソースを許可するか禁止するかを決定します。以下に例を示します。
Disallow: /private/上記のルールは、クローラーがサイト上の「プライベート」ディレクトリとその中のすべてのものにアクセスすることをブロックします。一方、次のように末尾のスラッシュを省略したとします。
Disallow: /privateこの場合、ルールはサイト上の「private」で始まる次のような他のインスタンスもブロックします。
- https://yourwebsite.com/private.html
- https://yourwebsite.com/privateer
したがって、正確であることが重要です。疑わしい場合は、ファイルをテストしてください。
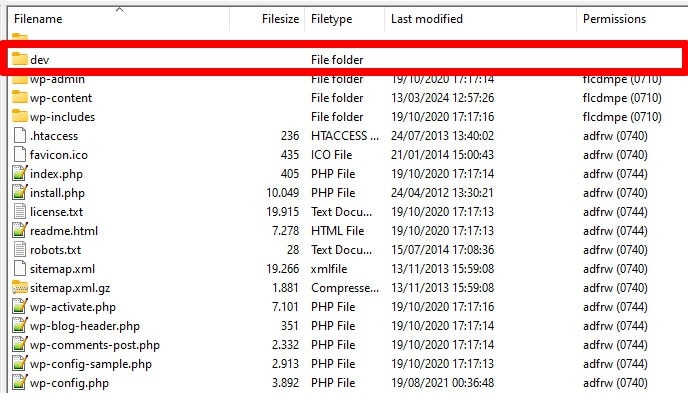
13. サブドメインの robots.txt が見つからない
Web サイト上の各サブドメイン (dev.yourwebsite.com など) には、検索エンジンがサブドメインを別個の Web エンティティとして扱うため、独自の robots.txt ファイルが必要です。ファイルを適切に配置しないと、サイトの非表示にするつもりだった部分がクローラーによってインデックス付けされる危険があります。
たとえば、開発バージョンが「dev」というフォルダーにあり、サブドメインを使用している場合は、検索クローラーをブロックする専用の robots.txt ファイルがあることを確認してください。
14. robots.txt ファイルをテストしていない
WordPress の robots.txt ファイルを設定する際の最大の間違いの 1 つは、特に変更を加えた後にテストに失敗することです。
これまで見てきたように、構文やロジックの小さなエラーでも、SEO に重大な問題を引き起こす可能性があります。したがって、robots.txt ファイルを常にテストしてください。
ファイルの問題は、Google Search Console の[設定] > [robots.txt]で確認できます。
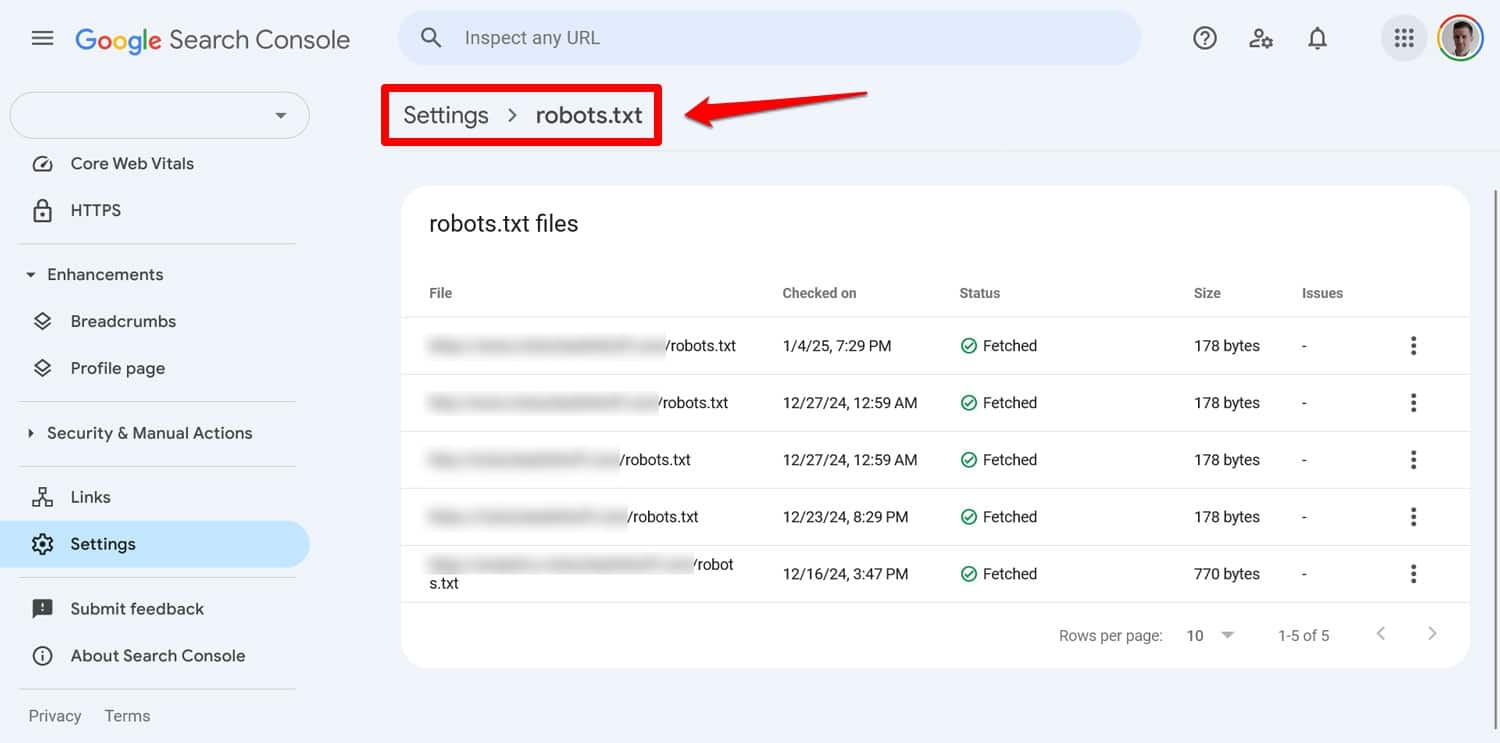
もう 1 つの方法は、Screaming Frog などのツールを使用して這う動作をシミュレートすることです。さらに、ステージング環境を使用して、新しいルールをライブ サイトに適用する前にその影響を検証します。
robots.txt エラーから回復する方法
robots.txt ファイル内の間違いは簡単に犯されますが、幸いなことに、発見したら修正するのも簡単です。
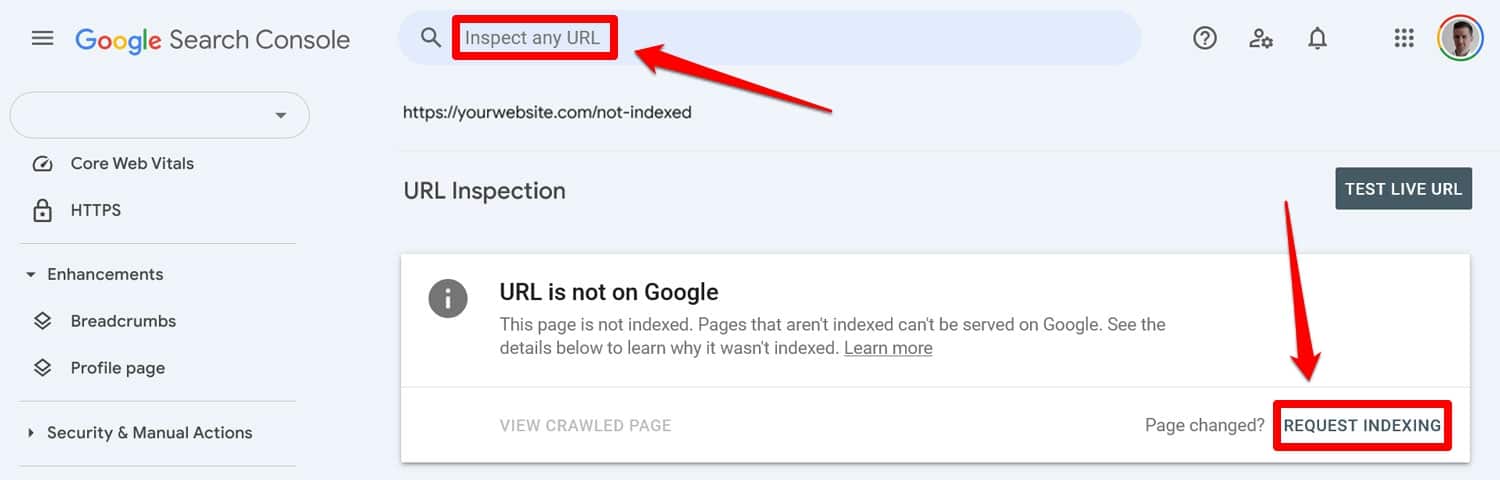
まず、更新された robots.txt ファイルをテスト ツールで実行します。次に、ページが以前に robots.txt ディレクティブによってブロックされていた場合は、そのページを Google Search Console または Bing ウェブマスター ツールに手動で入力してインデックス作成をリクエストします。
さらに、サイトマップの最新バージョンを再送信してください。
後はただ待つだけのゲームです。検索エンジンはあなたのサイトを再訪問し、できればすぐにランキングでの地位を回復するでしょう。
WordPress の robots.txt を管理する
robots.txt ファイルを使用すると、1 オンスの予防は 1 ポンドの治療よりも優れています。特に大規模な Web サイトでは、欠陥のあるファイルがランキング、トラフィック、収益に大打撃を与える可能性があります。
そのため、サイトの robots.txt に変更を加える場合は、広範なテストを行って慎重に行う必要があります。自分が犯す可能性のある間違いを認識することが、間違いを防ぐ第一歩です。
間違いを犯した場合でも、パニックにならないようにしてください。何が問題なのかを診断し、エラーがあれば修正し、サイトマップを再送信してサイトを再クロールしてください。
最後に、検索エンジンがサイトを適切にクロールしない理由がパフォーマンスではないことを確認してください。今すぐ WP Rocket を試して、サイトを即座に高速化してください。