
クローラー リスト: Web クローラー ボットとそれらを活用して成功させる方法
公開: 2022-12-03ほとんどのマーケティング担当者にとって、サイトを最新の状態に保ち、SEO ランキングを向上させるために、定期的な更新が必要です。
ただし、一部のサイトには数百または数千のページがあり、検索エンジンに更新を手動でプッシュするチームにとっては困難です. コンテンツが非常に頻繁に更新されている場合、これらの改善が SEO ランキングに影響を与えていることをチームはどのように確認できますか?
そこで登場するのがクローラーボットです。 Web クローラー ボットは、新しい更新のためにサイトマップをスクレイピングし、コンテンツを検索エンジンにインデックス付けします。
この投稿では、知っておく必要のあるすべての Web クローラー ボットをカバーする包括的なクローラー リストの概要を説明します。 詳細に入る前に、Web クローラー ボットを定義し、それらがどのように機能するかを示しましょう。
Web クローラーとは
Web クローラーは、Web ページを自動的にスキャンして体系的に読み取り、検索エンジンのページにインデックスを付けるコンピューター プログラムです。 Web クローラーは、スパイダーまたはボットとも呼ばれます。
検索エンジンが検索を開始するユーザーに関連する最新の Web ページを表示するには、Web クローラー ボットからのクロールが発生する必要があります。 このプロセスは、(クローラーとサイトの設定の両方に応じて) 自動的に行われることもあれば、直接開始されることもあります。
関連性、バックリンク、Web ホスティングなど、多くの要因がページの SEO ランキングに影響を与えます。 ただし、ページが検索エンジンによってクロールおよびインデックス登録されていない場合、これらはどれも問題になりません。 そのため、サイトが正しいクロールを実行できるようにし、邪魔になる障壁を取り除くことが非常に重要です。
ボットは継続的に Web をスキャンしてスクレイピングし、最も正確な情報が表示されるようにする必要があります。 Google は米国で最も訪問された Web サイトであり、検索の約 26.9% は米国のユーザーによるものです。

ただし、すべての検索エンジンをクロールする Web クローラーは 1 つではありません。 各検索エンジンには独自の強みがあるため、開発者やマーケティング担当者は「クローラー リスト」を作成することがあります。 このクローラー リストは、サイト ログ内のさまざまなクローラーを識別して許可またはブロックするのに役立ちます。
マーケティング担当者は、さまざまな Web クローラーでいっぱいのクローラー リストを作成し、(コンテンツを盗むコンテンツ スクレーパーとは異なり) サイトをどのように評価するかを理解して、ランディング ページを検索エンジン向けに正しく最適化する必要があります。
Webクローラーはどのように機能しますか?
Web クローラーは、公開された Web ページを自動的にスキャンし、データをインデックスに登録します。
Web クローラーは、Web ページに関連付けられた特定のキーワードを探し、その情報を Google、Bing などの関連する検索エンジンにインデックス付けします。
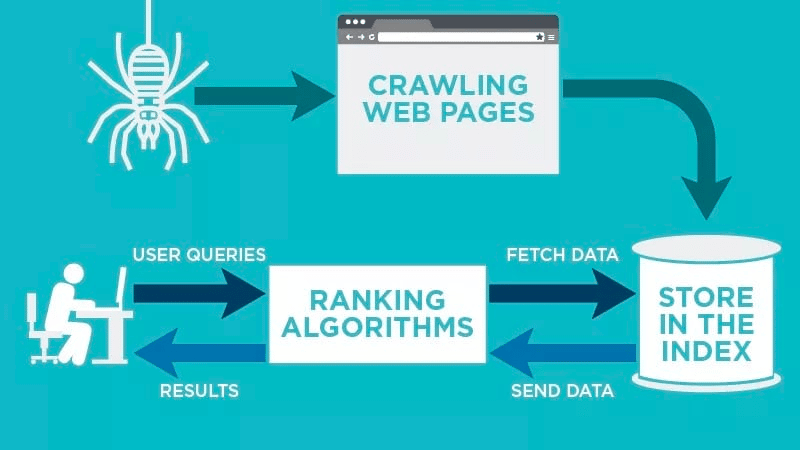
検索エンジンのアルゴリズムは、ユーザーが関連付けられた関連キーワードの問い合わせを送信すると、そのデータを取得します。
クロールは既知の URL から始まります。 これらは、Web クローラーをそれらのページに誘導するさまざまなシグナルを備えた確立された Web ページです。 これらの信号は次のとおりです。
- バックリンク:サイトがそのサイトにリンクする回数
- 訪問者:そのページに向かうトラフィックの量
- ドメイン権限: ドメインの全体的な品質
次に、検索エンジンのインデックスにデータを保存します。 ユーザーが検索クエリを開始すると、アルゴリズムがインデックスからデータを取得し、検索エンジンの結果ページに表示されます。 このプロセスは数ミリ秒以内に発生する可能性があるため、多くの場合、結果がすぐに表示されます。
ウェブマスターは、サイトをクロールするボットを制御できます。 そのため、クローラー リストを用意することが重要です。 これは、各サイトのサーバー内に存在するrobots.txt プロトコルであり、インデックスを作成する必要がある新しいコンテンツにクローラーを誘導します。
各 Web ページのrobots.txtプロトコルに何を入力するかによって、今後そのページをスキャンするか、インデックスに登録しないようにクローラーに指示できます。
Web クローラーがスキャンで何を探すかを理解することで、検索エンジンに対してコンテンツをより適切に配置する方法を理解できます。
クローラー リストの編集: Web クローラーのさまざまな種類とは?
クローラー リストの編集について考え始めると、探すべき主なタイプのクローラーが 3 つあります。 これらには以下が含まれます:
- 社内クローラー:企業の開発チームがサイトをスキャンするために設計したクローラーです。 通常、サイトの監査と最適化に使用されます。
- 商用クローラー:これらは、企業がコンテンツをクロールして効率的に評価するために使用できる、Screaming Frog のような特注のクローラーです。
- オープンソース クローラー: これらは、世界中のさまざまな開発者やハッカーによって構築された無料で使用できるクローラーです。
存在するさまざまなタイプのクローラーを理解して、独自のビジネス目標のためにどのタイプを活用する必要があるかを理解することが重要です。
クローラー リストに追加する最も一般的な 11 の Web クローラー
すべての検索エンジンに対してすべての作業を行う 1 つのクローラーはありません。
代わりに、Web ページを評価し、世界中のユーザーが利用できるすべての検索エンジンのコンテンツをスキャンするさまざまな Web クローラーがあります。
今日最も一般的な Web クローラーのいくつかを見てみましょう。
1.Googlebot
Googlebot は、Google の検索エンジンに表示されるサイトをクロールする Google の汎用 Web クローラーです。

技術的には、Googlebot デスクトップと Googlebot スマートフォン (モバイル) の 2 つのバージョンの Googlebot がありますが、ほとんどの専門家は Googlebot を 1 つのクローラーと見なしています。
これは、両方が各サイトのrobots.txtに記述された同じ一意の製品トークン (ユーザー エージェント トークンと呼ばれる) に従っているためです。 Googlebot ユーザー エージェントは単に「Googlebot」です。
Googlebot は動作を開始し、通常は数秒ごとにサイトにアクセスします (サイトのrobots.txtでブロックしていない場合)。 スキャンしたページのバックアップは、Google キャッシュと呼ばれる統合データベースに保存されます。 これにより、サイトの古いバージョンを見ることができます。
さらに、Google Search Console は、Googlebot がサイトをどのようにクロールしているかを理解し、検索用にページを最適化するためにウェブマスターが使用するもう 1 つのツールでもあります。
2. ビングボット
Bingbot は 2010 年に Microsoft によって作成され、URL をスキャンしてインデックスを作成し、Bing がプラットフォームのユーザーに関連する最新の検索エンジンの結果を確実に提供できるようにします。
Googlebot と同じように、開発者やマーケティング担当者は、自分のサイトをスキャンするエージェント識別子「bingbot」を承認または拒否するかどうかを、自分のサイトの robots.txt で定義できます。
さらに、Bingbot が最近新しいエージェント タイプに切り替わったため、モバイル ファースト インデックス クローラーとデスクトップ クローラーを区別する機能も備えています。 これは、Bing Webmaster Tools と共に、Web マスターに、自分のサイトがどのように発見され、検索結果に表示されるかを示す柔軟性を提供します。
3.ヤンデックスボット
Yandex Bot は、ロシアの検索エンジン Yandex 専用のクローラーです。 これは、ロシアで最大かつ最も人気のある検索エンジンの 1 つです。

Web マスターは、 robots.txtファイルを使用して、Yandex ボットがサイト ページにアクセスできるようにすることができます。
さらに、 Yandex.Metricaタグを特定のページに追加したり、Yandex Webmaster でページのインデックスを再作成したり、新しいページ、変更されたページ、または非アクティブ化されたページを指摘する独自のレポートである IndexNow プロトコルを発行したりすることもできます。
4.アップルボット
Apple は、Apple Bot に、Apple の Siri および Spotlight Suggestions の Web ページのクロールとインデックス作成を依頼しました。
Apple Bot は、Siri および Spotlight Suggestions でどのコンテンツを昇格させるかを決定する際に、複数の要因を考慮します。 これらの要素には、ユーザー エンゲージメント、検索用語の関連性、リンクの数/品質、位置情報に基づくシグナル、さらには Web ページのデザインが含まれます。
5.ダックダックボット
DuckDuckBot は DuckDuckGo の Web クローラーであり、「Web ブラウザーでのシームレスなプライバシー保護」を提供します。
ウェブマスターは、DuckDuckBot API を使用して、DuckDuck Bot がサイトをクロールしたかどうかを確認できます。 クロールすると、DuckDuckBot API データベースが最新の IP アドレスとユーザー エージェントで更新されます。
これにより、Web マスターは、DuckDuck Bot に関連付けられようとするなりすましや悪意のあるボットを特定できます。
6. 百度スパイダー
Baidu は中国の大手検索エンジンであり、Baidu Spider はサイトの唯一のクローラーです。

Google は中国では禁止されているため、中国市場に進出したい場合は、Baidu Spider がサイトをクロールできるようにすることが重要です。
サイトをクロールしている Baidu Spider を特定するには、次のユーザー エージェントを探します: baiduspider、baiduspider-image、baiduspider-video など。
中国でビジネスを行っていない場合は、robots.txt スクリプトで Baidu Spider をブロックすることをお勧めします。 これにより、Baidu Spider がサイトをクロールするのを防ぎ、Baidu の検索エンジンの結果ページ (SERP) にページが表示される可能性を排除します。
7. そごうスパイダー
Sogou は中国の検索エンジンであり、100 億の中国語ページがインデックス化された最初の検索エンジンであると伝えられています。

中国市場でビジネスを行っている場合、これは知っておく必要があるもう 1 つの人気のある検索エンジン クローラーです。 Sogou Spider は、ロボットの除外テキストとクロール遅延パラメーターに従います。

Baidu Spider と同様に、中国市場でビジネスを行いたくない場合は、このスパイダーを無効にして、サイトの読み込み時間が遅くなるのを防ぐ必要があります。
8. Facebook 外部ヒット
Facebook 外部ヒット (別名 Facebook クローラー) は、Facebook で共有されているアプリまたは Web サイトの HTML をクロールします。

これにより、ソーシャル プラットフォームは、プラットフォームに投稿された各リンクの共有可能なプレビューを生成できます。 クローラーのおかげで、タイトル、説明、およびサムネイル画像が表示されます。
クロールが数秒以内に実行されない場合、Facebook は共有前に生成されたカスタム スニペットのコンテンツを表示しません。
9.エグザボット
Exalead は 2000 年に設立され、フランスのパリに本社を置くソフトウェア会社です。 同社は、消費者および企業クライアント向けの検索プラットフォームを提供しています。
Exabot は、CloudView 製品上に構築されたコア検索エンジンのクローラーです。
ほとんどの検索エンジンと同様に、Exalead はランキングの際にバックリンクと Web ページのコンテンツの両方を考慮に入れます。 Exabot は、Exalead のロボットのユーザー エージェントです。 ロボットは、検索エンジンのユーザーに表示される結果をまとめた「メイン インデックス」を作成します。
10.スウィフトボット
Swiftype は、Web サイト用のカスタム検索エンジンです。 「最高の検索テクノロジー、アルゴリズム、コンテンツ取り込みフレームワーク、クライアント、および分析ツール」を組み合わせています。

多くのページを含む複雑なサイトがある場合、Swiftype は、すべてのページをカタログ化してインデックス化するための便利なインターフェイスを提供します。
Swiftbot は Swiftype の Web クローラーです。 ただし、他のボットとは異なり、Swiftbot は顧客が要求したサイトのみをクロールします。
11.スラープボット
Slurp Bot は、Yahoo のページをクロールしてインデックスに登録する Yahoo 検索ロボットです。
このクロールは、Yahoo.com だけでなく、Yahoo News、Yahoo Finance、Yahoo Sports などのパートナー サイトの両方に不可欠です。 これがないと、関連するサイトの一覧が表示されません。
インデックス化されたコンテンツは、ユーザーにとってよりパーソナライズされた Web エクスペリエンスに貢献し、より関連性の高い結果が得られます。
SEOの専門家が知っておくべき8つのコマーシャルクローラー
クローラー リストに最も人気のある 11 のボットが表示されたので、プロ向けの一般的な商用クローラーと SEO ツールのいくつかを見てみましょう。
1. Ahrefsボット
Ahrefs ボットは、人気のある SEO ソフトウェアである Ahrefs が提供する 12 兆のリンク データベースをコンパイルしてインデックスを作成する Web クローラーです。
Ahrefs ボットは毎日 60 億の Web サイトにアクセスしており、Googlebot に次いで「2 番目にアクティブなクローラー」と見なされています。
他のボットと同じように、Ahrefs ボットはrobots.txt関数に従い、各サイトのコードでルールを許可/禁止します。
2.セムラッシュボット
Semrush Bot により、主要な SEO ソフトウェアである Semrush は、プラットフォームで顧客が使用するサイト データを収集してインデックスを作成できます。

データは、Semrush のパブリック バックリンク検索エンジン、サイト監査ツール、バックリンク監査ツール、リンク構築ツール、ライティング アシスタントで使用されます。
Web ページの URL のリストをコンパイルしてサイトをクロールし、それらにアクセスして、今後のアクセスのために特定のハイパーリンクを保存します。
3. モズのキャンペーン クローラー ロジャーボット
Rogerbot は、主要な SEO サイトである Moz のクローラーです。 このクローラーは、特に Moz Pro キャンペーンのサイト監査用のコンテンツを収集しています。

Rogerbot はrobots.txtファイルに規定されているすべての規則に従うため、Rogerbot によるサイトのスキャンをブロック/許可するかどうかを決定できます。
Web マスターは、ロジャーボットが多面的なアプローチをとっているため、静的 IP アドレスを検索して、ロジャーボットがクロールしたページを確認することはできません。
4. カエルの叫び
Screaming Frog は、SEO の専門家が自分のサイトを監査し、検索エンジンのランキングに影響を与える改善領域を特定するために使用するクローラーです。

クロールが開始されると、リアルタイム データを確認し、ページ タイトル、メタデータ、ロボット、重複コンテンツなどに必要なリンク切れや改善を特定できます。
クロール パラメーターを構成するには、Screaming Frog ライセンスを購入する必要があります。
5. ルマー (以前のディープクロール)
Lumar は、「サイトの技術的な健全性を維持するための集中型コマンド センター」です。 このプラットフォームを使用すると、サイトのクロールを開始して、サイト アーキテクチャの計画に役立てることができます。
Lumar は「市場で最速の Web サイト クローラー」であると自負しており、1 秒あたり最大 450 個の URL をクロールできることを誇っています。
6.マジェスティック
Majestic は主に、URL のバックリンクの追跡と識別に重点を置いています。
同社は「インターネット上で最も包括的なバックリンク データのソースの 1 つ」を持っていることを誇りに思っており、2021 年にはリンクの 5 年から 15 年に増加した履歴インデックスを強調しています。
サイトのクローラーは、このすべてのデータを会社の顧客が利用できるようにします。
7.コグニティブSEO
コグニティブSEOは、多くの専門家が使用するもう1つの重要なSEOソフトウェアです。
コグニティブSEOクローラーを使用すると、ユーザーはサイトのアーキテクチャと包括的なSEO戦略を知らせる包括的なサイト監査を実行できます。
ボットはすべてのページをクロールし、エンド ユーザーに固有の「完全にカスタマイズされたデータ セット」を提供します。 このデータセットには、ランキングに影響を与え、不要なクローラーをブロックするために、他のクローラーのためにサイトを改善する方法に関するユーザーへの推奨事項も含まれます。
8.オンクロール
Oncrawl は、エンタープライズ レベルのクライアント向けの「業界をリードする SEO クローラーおよびログ アナライザー」です。

ユーザーは「クロール プロファイル」を設定して、クロール用の特定のパラメーターを作成できます。 これらの設定 (開始 URL、クロール制限、最大クロール速度などを含む) を保存して、確立された同じパラメーターで簡単にクロールを再実行できます。
悪意のある Web クローラーからサイトを保護する必要がありますか?
すべてのクローラーが優れているわけではありません。 ページ速度に悪影響を与えるものもあれば、サイトをハッキングしようとしたり悪意を持ったりするものもあります.
そのため、クローラーがサイトに侵入するのをブロックする方法を理解することが重要です。
クローラー リストを作成することで、どのクローラーを探すのが適切かがわかります。 次に、怪しいものを取り除き、ブロック リストに追加します。
悪意のある Web クローラーをブロックする方法
クローラー リストがあれば、承認したいボットとブロックする必要のあるボットを特定できます。
最初のステップは、クローラー リストを調べて、各クローラーに関連付けられているユーザー エージェントと完全なエージェント文字列、およびその特定の IP アドレスを定義することです。 これらは、各ボットに関連付けられている重要な識別要素です。
ユーザー エージェントと IP アドレスを使用すると、DNS ルックアップまたは IP 一致を通じて、サイト レコードでそれらを照合できます。 正確に一致しない場合は、悪意のあるボットが実際のボットになりすまそうとしている可能性があります。
次に、 robots.txtサイト タグを使用して権限を調整することで、なりすましをブロックできます。
概要
Web クローラーは検索エンジンにとって有用であり、マーケティング担当者が理解することが重要です。
サイトが適切なクローラーによって正しくクロールされるようにすることは、ビジネスの成功にとって重要です。 クローラー リストを保持することで、サイト ログに表示されたときに注意すべきクローラーを知ることができます。
商用クローラーの推奨事項に従い、サイトのコンテンツと速度を改善すると、クローラーがサイトにアクセスしやすくなり、検索エンジンやそれを求める消費者のために適切な情報をインデックスに登録しやすくなります。