
Robots.txt: その内容と作成方法 (完全ガイド)
公開: 2023-05-05Web サイトを所有している、またはそのコンテンツを管理している場合、robots.txt について聞いたことがあるでしょう。 Web サイトのページをクロールしてインデックスに登録する方法を検索エンジン ロボットに指示するファイルです。 検索エンジン最適化 (SEO) における重要性にもかかわらず、多くの Web サイト所有者は、適切に設計された robots.txt ファイルの重要性を見落としています。
この完全なガイドでは、robots.txt とは何か、なぜ SEO にとって重要なのか、ウェブサイト用の robots.txt ファイルを作成する方法について説明します。
Robots.txt ファイルとは?
robots.txt は、検索エンジン ロボット (クローラーまたはスパイダーとも呼ばれます) に、Web サイトのどのページまたはセクションをクロールする必要があるかどうかを伝えるファイルです。 これは Web サイトのルート ディレクトリにあるプレーン テキスト ファイルであり、通常、Web マスターが検索エンジンのインデックス作成またはクロールからブロックしたいディレクトリ、ファイル、または URL のリストが含まれています。
robots.txt ファイルは次のようになります。

Robots.txt が重要な理由
ウェブサイトにとって robots.txt が重要である主な理由は 3 つあります。
1. クロール バジェットを最大化する
「クロール バジェット」とは、Google が特定の時点でサイト上でクロールするページの数を表します。 この数は、サイトのバックリンクのサイズ、健全性、および量によって異なります。
サイトのページ数がクロール バジェットを超えると、インデックスに登録されていないページが発生するため、クロール バジェットは重要です。
さらに、インデックスされていないページはランク付けされません。
robots.txt を使用して不要なページをブロックすると、Googlebot (Google のウェブ クローラー) が重要なページにより多くのクロール バジェットを費やす可能性があります。
2. 非公開ページをブロックする
あなたのサイトには、インデックスを作成したくないページがたくさんあります。
たとえば、内部検索結果ページやログイン ページがあるとします。 これらのページが存在する必要があります。 ただし、ランダムな人がそれらに着陸することは望ましくありません。
この場合、robots.txt を使用して、検索エンジンのクローラーやボットが特定のページにアクセスできないようにします。
3. リソースのインデックス作成を防止する
PDF、動画、画像などのリソースを Google に検索結果から除外してもらいたい場合があります。
これらのリソースを非公開にしたい場合や、Google を重要なコンテンツにより集中させたい場合があります。
このような場合、robots.txt を使用してインデックスに登録されないようにするのが最善の方法です。
Robots.txt ファイルはどのように機能しますか?
robots.txt ファイルは、検索エンジン ボットに、Web サイトのどのページまたはディレクトリをクロールまたはインデックス化すべきか、またはすべきでないかを指示します。
クロール中、検索エンジン ボットはリンクを見つけてたどります。 このプロセスは、サイト X からサイト Y、サイト Z へと、何十億ものリンクと Web サイトを介してユーザーを導きます。
ボットがサイトにアクセスすると、最初に robots.txt ファイルを探します。
ファイルを検出すると、他の処理を行う前にファイルを読み取ります。
たとえば、DuckDuckGo 以外のすべてのボットにサイトのクロールを許可するとします。
User-agent: DuckDuckBot Disallow: /
注: robots.txt ファイルは指示のみを提供できます。 それらを課すことはできません。 行動規範に似ています。 良いボット (検索エンジン ボットなど) はルールに従いますが、悪いボット (スパム ボットなど) はルールを無視します。
Robots.txt ファイルを見つける方法は?
robots.txt ファイルは、ウェブサイトの他のファイルと同様に、サーバーでホストされています。
ホームページの完全な URL を入力し、末尾に /robots.txt を追加すると、任意の Web サイトの robots.txt ファイルにアクセスできます (例: https://pickupwp.com/robots.txt)。
ただし、ウェブサイトに robots.txt ファイルがない場合は、「404 Not Found」というエラー メッセージが表示されます。
Robots.txt ファイルの作成方法
robots.txt ファイルの作成方法を説明する前に、まず robots.txt の構文を見てみましょう。
robots.txt ファイルの構文は、次のコンポーネントに分けることができます。
- ユーザーエージェント:これは、レコードが適用されるロボットまたはクローラーを指定します。 たとえば、「User-agent: Googlebot」は Google の検索クローラーにのみ適用され、「User-agent: *」はすべてのクローラーに適用されます。
- Disallow:ロボットがクロールしないページまたはディレクトリを指定します。 たとえば、「Disallow: /private/」は、ロボットが「private」ディレクトリ内のページをクロールするのを防ぎます。
- 許可:親ディレクトリが許可されていない場合でも、ロボットがクロールできるページまたはディレクトリを指定します。 たとえば、「Allow: /public/」を指定すると、親ディレクトリが許可されていない場合でも、ロボットは「public」ディレクトリ内のすべてのページをクロールできます。
- クロール遅延:これは、ロボットが Web サイトをクロールする前に待機する時間を秒単位で指定します。 たとえば、「Crawl-delay: 10」は、ロボットが Web サイトをクロールする前に 10 秒間待機するように指示します。
- サイトマップ:これは、Web サイトのサイトマップの場所を指定します。 たとえば、「サイトマップ: https://www.example.com/sitemap.xml」は、ウェブサイトのサイトマップの場所をロボットに通知します。
robots.txt ファイルの例を次に示します。
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
注: robots.txt ファイルでは大文字と小文字が区別されることに注意してください。URL を指定するときは、大文字と小文字を正しく使用することが重要です。
たとえば、/public/ は /Public/ と同じではありません。
一方、「Allow」や「Disallow」などのディレクティブは大文字と小文字が区別されないため、大文字にするかどうかはユーザー次第です。
robots.txt の構文について学習したら、robots.txt 生成ツールを使用して robots.txt ファイルを作成するか、自分で作成できます。
わずか 4 つのステップで robots.txt ファイルを作成する方法は次のとおりです。
1. 新しいファイルを作成し、Robots.txt という名前を付けます。
任意のテキスト エディターまたは Web ブラウザーで .txt ドキュメントを開くだけです。
次に、ドキュメントに robots.txt という名前を付けます。 動作させるには、robots.txt という名前にする必要があります。
完了したら、ディレクティブの入力を開始できます。
2. Robots.txt ファイルにディレクティブを追加する
robots.txt ファイルには、1 つまたは複数のディレクティブ グループが含まれており、それぞれに複数行の命令が含まれています。
各グループは「User-agent」で始まり、次のデータが含まれています。
- グループの適用先 (ユーザーエージェント)
- エージェントがアクセスできるディレクトリ (ページ) またはファイルは?
- エージェントがアクセスできないディレクトリ (ページ) またはファイルは?
- 重要だと思われるサイトやファイルを検索エンジンに知らせるためのサイトマップ (オプション)。
これらのディレクティブのいずれとも一致しない行は、クローラーによって無視されます。

たとえば、Google が /private/ ディレクトリをクロールしないようにしたいとします。
次のようになります。
User-agent: Googlebot Disallow: /private/
Google に対してこのような追加の指示がある場合は、次のようにすぐ下の別の行に入力します。
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
さらに、Google の特定の手順が完了し、新しいディレクティブのグループを作成したい場合。
たとえば、すべての検索エンジンが /archive/ および /support/ ディレクトリをクロールしないようにしたい場合。
次のようになります。
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
完了したら、サイトマップを追加できます。
完成した robots.txt ファイルは次のようになります。
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
次に、robots.txt ファイルを保存します。 robots.txt という名前にする必要があります。
より便利な robots.txt ルールについては、Google のこの役立つガイドをご覧ください。
3. Robots.txt ファイルをアップロードする
robots.txt ファイルをコンピュータに保存したら、それをウェブサイトにアップロードして、検索エンジンがクロールできるようにします。
残念ながら、このステップに役立つツールはありません。
robots.txt ファイルのアップロードは、サイトのファイル構造と Web ホスティングによって異なります。
robots.txt ファイルのアップロード方法については、オンラインで検索するか、ホスティング プロバイダにお問い合わせください。
4. Robots.txt をテストする
robots.txt ファイルをアップロードしたら、誰でも閲覧できるかどうか、Google が読み取れるかどうかを確認できます。
ブラウザで新しいタブを開き、robots.txt ファイルを検索するだけです。
たとえば、https://pickupwp.com/robots.txt です。
robots.txt ファイルが表示されたら、マークアップ (HTML コード) をテストする準備ができています。
これには、Google robots.txt テスターを使用できます。
注: robots.txt Tester を使用して robots.txt ファイルをテストするための Search Console アカウントが設定されています。
robots.txt テスターは、構文の警告や論理エラーを見つけて強調表示します。
さらに、エディターの下に警告とエラーも表示されます。
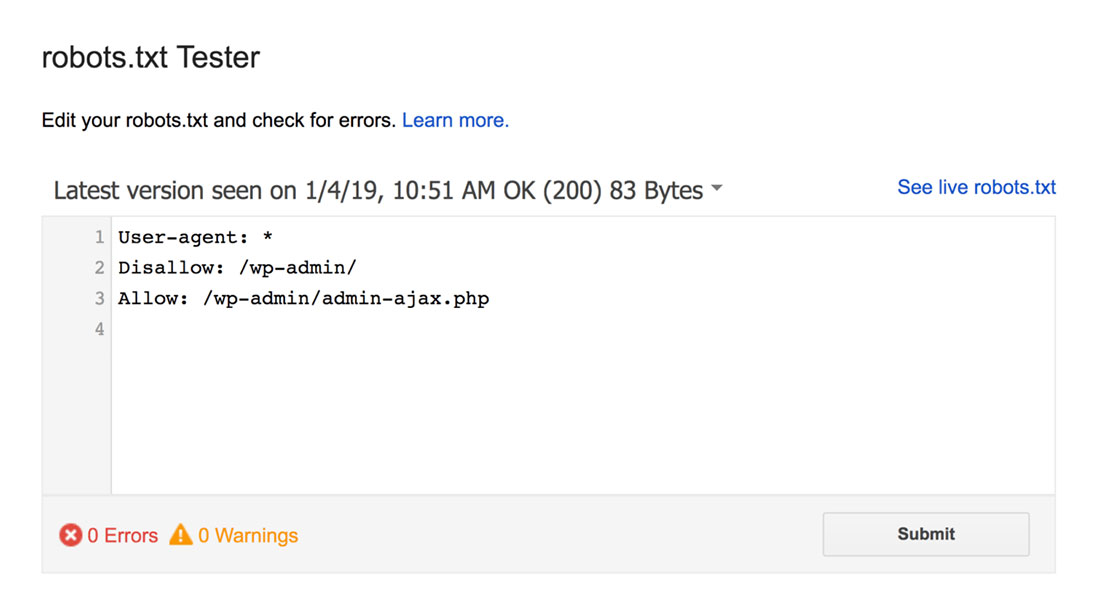
ページ上のエラーまたは警告を編集し、必要に応じて何度でも再テストできます。
ページで行った変更はサイトに保存されないことに注意してください。
変更を加えるには、これをコピーしてサイトの robots.txt ファイルに貼り付けます。
Robots.txt のベスト プラクティス
よくある間違いを避けるために、robots.txt ファイルを作成する際は、次のベスト プラクティスを念頭に置いてください。
1.ディレクティブごとに改行を使用する
検索エンジンのクローラーが混乱しないように、各ディレクティブを robots.txt ファイルの新しい行に追加してください。 これは、許可ルールと禁止ルールの両方に適用されます。
たとえば、Web クローラーにブログや連絡先ページをクロールさせたくない場合は、次のルールを追加します。
Disallow: /blog/ Disallow: /contact/
2. 各ユーザー エージェントを 1 回だけ使用する
ボットは、同じユーザー エージェントを何度も使用しても問題ありません。
ただし、一度使用するだけで物事が整理され、人的ミスの可能性が減少します。
3.ワイルドカードを使用して命令を簡素化する
ブロックするページが多数ある場合、ページごとにルールを追加すると時間がかかる場合があります。 幸いなことに、ワイルドカードを使用して指示を簡素化できます。
ワイルドカードは、1 つ以上の文字を表すことができる文字です。 最も一般的に使用されるワイルドカードはアスタリスク (*) です。
たとえば、.jpg で終わるすべてのファイルをブロックする場合は、次のルールを追加します。
Disallow: /*.jpg
4.「$」を使用して URL の末尾を指定する
ドル記号 ($) は、URL の末尾を識別するために使用できるもう 1 つのワイルドカードです。 これは、特定のページを制限したいが、それ以降のページは制限したくない場合に便利です。
コンタクト ページをブロックし、コンタクト成功ページはブロックしない場合、次のルールを追加します。
Disallow: /contact$
5. ハッシュ (#) を使用してコメントを追加する
ハッシュ (#) で始まるものはすべて、クローラーによって無視されます。
その結果、開発者はハッシュを使用して robots.txt ファイルにコメントを追加することがよくあります。 ドキュメントを整理して読みやすくします。
たとえば、.jpg で終わるすべてのファイルを防止する場合は、次のコメントを追加できます。
# Block all files that end in .jpg Disallow: /*.jpg
これは、ルールの目的とその理由を誰もが理解するのに役立ちます。
6. サブドメインごとに個別の Robots.txt ファイルを使用する
複数のサブドメインを持つ Web サイトがある場合は、サブドメインごとに個別の robots.txt ファイルを作成することをお勧めします。 これにより、物事が整理され、検索エンジンのクローラーがルールをより簡単に把握できるようになります。
まとめ!
robots.txt ファイルは、検索エンジン ボットに何をインデックスに登録し、何をインデックスに登録しないかを指示するため、便利な SEO ツールです。
ただし、注意して使用することが重要です。 構成を誤ると、Web サイトのインデックスが完全に削除される可能性があるため (たとえば、Disallow: / を使用)。
一般に、機密情報を保持し、コンテンツの重複を避けながら、検索エンジンができるだけ多くのサイトをスキャンできるようにすることをお勧めします。 たとえば、Disallow ディレクティブを使用して特定のページまたはディレクトリを禁止したり、Allow ディレクティブを使用して特定のページの Disallow ルールをオーバーライドしたりできます。
また、すべてのボットが robots.txt ファイルで提供されているルールに従っているわけではないことにも注意してください。そのため、インデックスを作成する対象を制御するための完全な方法ではありません。 それでも、SEO 戦略においては価値のあるツールです。
このガイドが、robots.txt ファイルの概要と作成方法を理解するのに役立つことを願っています。
詳細については、次の他の役立つリソースをご覧ください。
- 新しいブロガーのための 15 の実用的なブログのヒント
- ロングテールキーワードの力を解き放つ(初心者向けガイド)
最後に、新しい記事に関する定期的な更新については、Twitter をフォローしてください。