
WordPressrobots.txtファイル…それは何であり、それは何をするのか
公開: 2020-11-25robots.txtファイルとは何か、それが何をするのか疑問に思ったことはありませんか? Robots.txtは、Googleやその他の検索エンジンで使用されるウェブクローラー(ボットと呼ばれる)と通信するために使用されます。 Webサイトのどの部分をインデックスに登録し、どの部分を無視するかを指示します。 そのため、robots.txtファイルは、SEOの取り組みを成功させる(または失敗させる可能性がある)のに役立ちます。 あなたのウェブサイトをうまくランク付けしたいのなら、robots.txtをよく理解することが不可欠です!
Robots.txtはどこにありますか?
WordPressは通常、いわゆる「仮想」robots.txtファイルを実行します。これは、SFTP経由でアクセスできないことを意味します。 ただし、yourdomain.com / robots.txtにアクセスすると、その基本的な内容を表示できます。 おそらく次のようなものが表示されます。
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php最初の行は、ルールが適用されるボットを指定します。 この例では、アスタリスクは、ルールがすべてのボット(たとえば、Google、Bingなどのボット)に適用されることを意味します。
2行目は、ボットによる/ wp-adminフォルダーへのアクセスを防止するルールを定義し、3行目は、ボットが/wp-admin/admin-ajax.phpファイルを解析できることを示しています。
独自のルールを追加する
単純なWordPressWebサイトの場合、WordPressによってrobots.txtファイルに適用されるデフォルトのルールで十分な場合があります。 ただし、Webサイトのインデックス作成方法について検索エンジンボットに具体的な指示を与えるために、より詳細な制御と独自のルールを追加する機能が必要な場合は、独自の物理robots.txtファイルを作成し、ルートの下に配置する必要があります。インストールのディレクトリ。
robots.txtファイルを再構成し、それらのボットがクロールできるものを正確に定義する理由はいくつかあります。 主な理由の1つは、ボットがサイトをクロールするのに費やした時間に関係しています。 Google(およびその他)は、ボットがすべてのWebサイトで無制限の時間を費やすことを許可していません...何兆ものページがあるため、ボットがクロールする内容と無視する内容に対して、最も有用な情報を抽出するために、より微妙なアプローチをとる必要があります。ウェブサイトについて。

Pressidiumであなたのウェブサイトをホストする
60日間の返金保証
ボットがWebサイトのすべてのページをクロールできるようにすると、クロール時間の一部が重要ではない、または関連性のないページに費やされます。 これにより、サイトのより関連性の高い領域を処理する時間が少なくなります。 Webサイトの一部へのボットのアクセスを禁止することにより、ボットがサイトの最も関連性の高い部分から情報を抽出するために利用できる時間を増やします(これにより、インデックスが作成されることが期待されます)。 クロールが高速であるため、GoogleはWebサイトに再度アクセスし、サイトのインデックスを最新の状態に保つ可能性が高くなります。 これは、新しいブログ投稿やその他の新鮮なコンテンツがより早くインデックスに登録される可能性が高いことを意味します。これは朗報です。
Robots.txtの編集例
robots.txtには、カスタマイズの余地が十分にあります。 そのため、ボットがサイトにインデックスを付ける方法を指示するために使用できるルールのさまざまな例を提供しました。
ボットの許可または禁止
まず、特定のボットを制限する方法を見てみましょう。 これを行うには、アスタリスク(*)をブロックするボットユーザーエージェントの名前(たとえば、「MSNBot」)に置き換えるだけです。 既知のユーザーエージェントの包括的なリストは、こちらから入手できます。
User-agent: MSNBot Disallow: /2行目にダッシュを入れると、ボットのすべてのディレクトリへのアクセスが制限されます。
1つのボットのみがサイトをクロールできるようにするには、2ステップのプロセスを使用します。 まず、この1つのボットを例外として設定し、次に次のようなすべてのボットを禁止します。
User-agent: Google Disallow: User-agent: * Disallow: /すべてのコンテンツのすべてのボットへのアクセスを許可するために、次の2行を追加します。
User-agent: * Disallow:robots.txtファイルを作成し、それを空のままにしておくだけでも、同じ効果が得られます。
特定のファイルへのアクセスをブロックする
ボットがWebサイト上の特定のファイルのインデックスを作成するのを止めたいですか? 簡単だ! 以下の例では、検索エンジンがWebサイト上のすべての.pdfファイルにアクセスできないようにしています。
User-agent: * Disallow: /*.pdf$「$」記号は、URLの終わりを定義するために使用されます。 これは大文字と小文字が区別されるため、my.PDFという名前のファイルは引き続きクロールされます(CAPSに注意してください)。
複雑な論理式
Googleなどの一部の検索エンジンは、より複雑な正規表現の使用を理解しています。 ただし、すべての検索エンジンがrobots.txtの論理式を理解できるとは限らないことに注意してください。
この一例は、$記号の使用です。 robots.txtファイルでは、この記号はURLの終わりを示します。 したがって、次の例では、検索ボットが.phpで終わるファイルを読み取ってインデックスを作成することをブロックしています。

Disallow: /*.php$つまり、/ index.phpはインデックスに登録できませんが、/ index.php?p=1はインデックスに登録できます。 これは非常に特定の状況でのみ有用であり、注意して使用する必要があります。そうしないと、意図しないファイルへのボットアクセスをブロックするリスクがあります。
ボットに個別に適用されるルールを指定することで、ボットごとに異なるルールを設定することもできます。 以下のサンプルコードは、すべてのボットのwp-adminフォルダーへのアクセスを制限すると同時に、Bing検索エンジンのサイト全体へのアクセスをブロックします。 必ずしもこれを実行する必要はありませんが、robots.txtファイルのルールがいかに柔軟であるかを示す便利なデモンストレーションです。
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /XMLサイトマップ
XMLサイトマップは、検索ボットがWebサイトのレイアウトを理解するのに役立ちます。 しかし、有用であるためには、ボットはサイトマップがどこにあるかを知る必要があります。 'sitemapディレクティブ'は、検索エンジンにa)サイトのサイトマップが存在し、b)サイトがどこにあるかを具体的に伝えるために使用されます。
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:複数のサイトマップの場所を指定することもできます。
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* Disallowボットクロールの遅延
robots.txtファイルを介して実行できるもう1つの機能は、ボットにサイトのクロールを「遅くする」ように指示することです。 これは、サーバーが高いボットトラフィックレベルによって過負荷になっていることがわかった場合に必要になることがあります。 これを行うには、速度を落とすユーザーエージェントを指定してから、遅延を追加します。
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10この例の引用符(10)は、サイトの個々のページをクロールする間に発生する遅延です。 したがって、上記の例では、Bing Botに、クロールする各ページの間に10秒間一時停止するように依頼しました。そうすることで、サーバーに少し余裕を持たせます。
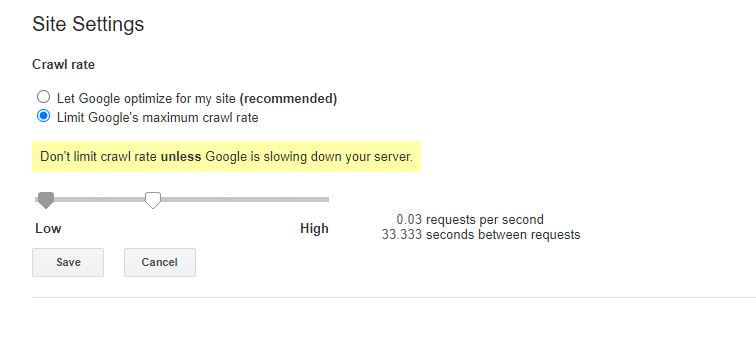
この特定のrobots.txtルールに関するわずかに悪いニュースは、Googleのボットがそれを尊重していないことです。 ただし、Google検索コンソール内からボットに速度を落とすように指示することはできます。
robots.txtルールに関する注意:
- すべてのrobots.txtルールでは大文字と小文字が区別されます。 慎重に入力してください。
- 行頭のコマンドの前にスペースがないことを確認してください。
- robots.txtに加えられた変更は、ボットによって認識されるまでに24〜36時間かかる場合があります。
WordPressrobots.txtファイルをテストして送信する方法
新しいrobots.txtファイルを作成したら、エラーがないことを確認する価値があります。 これは、Google検索コンソールを使用して行うことができます。
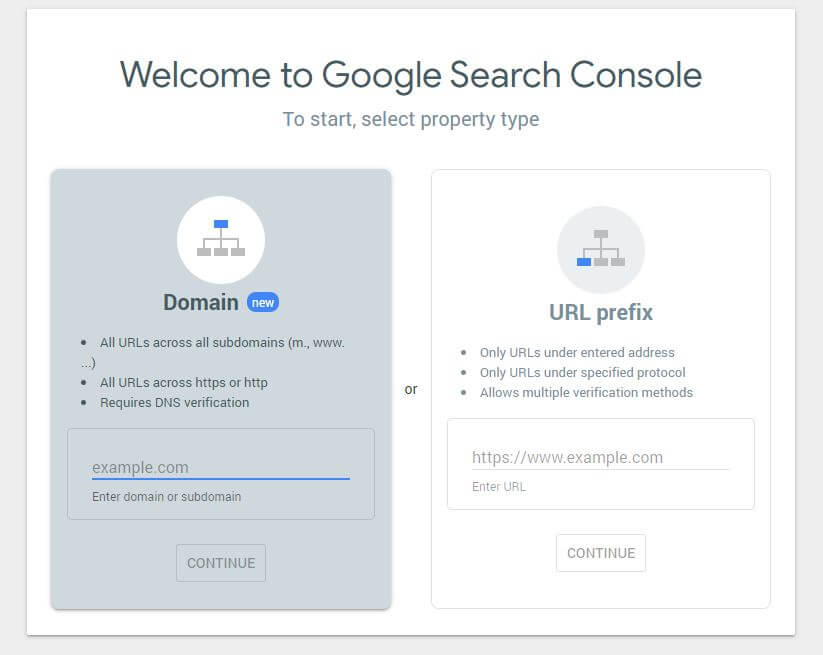
まず、ドメインを送信する必要があります(Webサイト設定用の検索コンソールアカウントをまだ取得していない場合)。 Googleは、ドメインを確認するためにDNSに追加する必要があるTXTレコードを提供します。
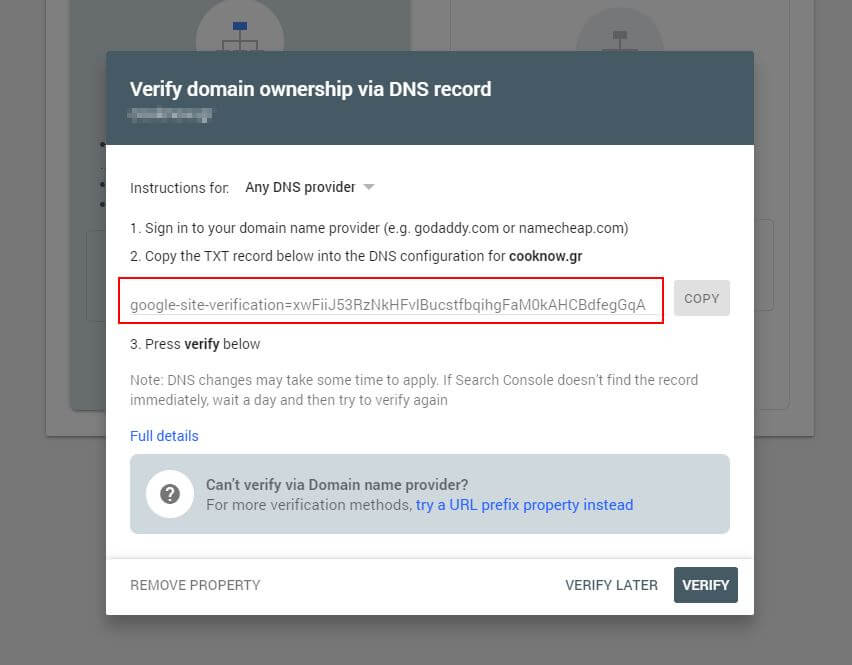
このDNS更新が伝播されたら(焦りを感じます…Cloudflareを使用してDNSを管理してみてください)、robots.txtテスターにアクセスして、robots.txtファイルの内容に関する警告があるかどうかを確認できます。
設定したルールをテストするためにできるもう1つのことは、Ryteのようなrobots.txtテストツールを使用することです。
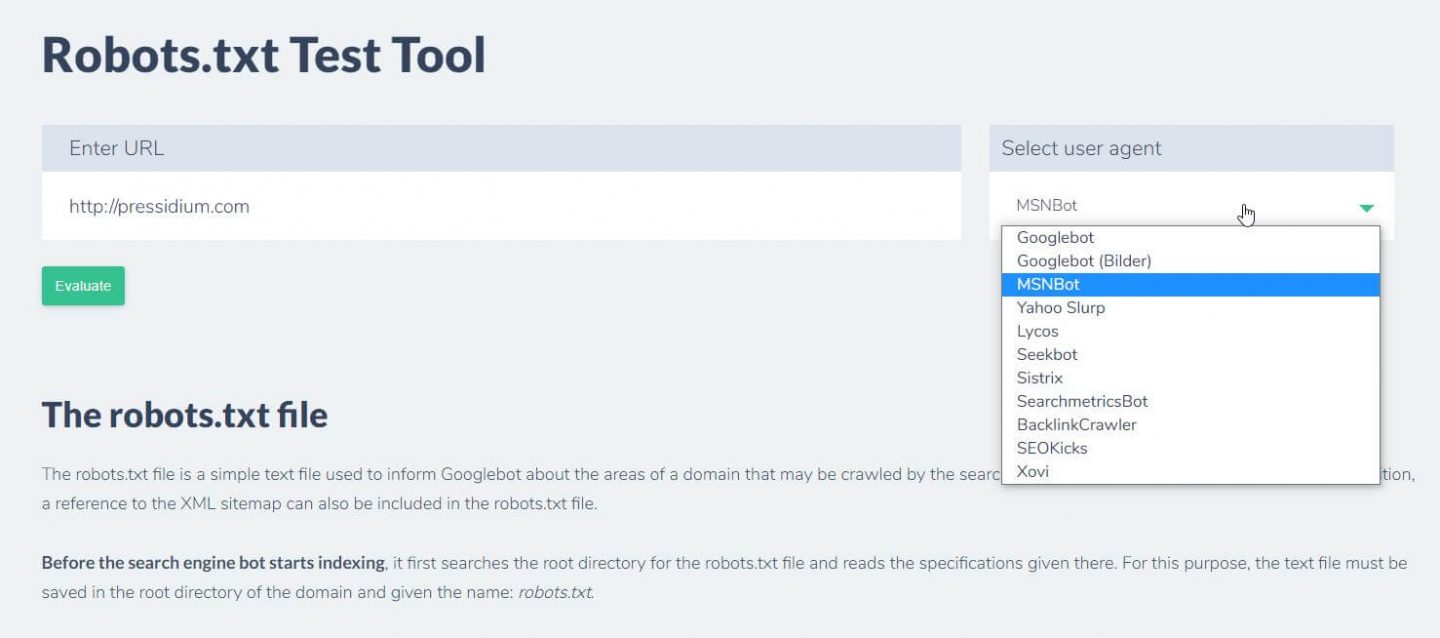
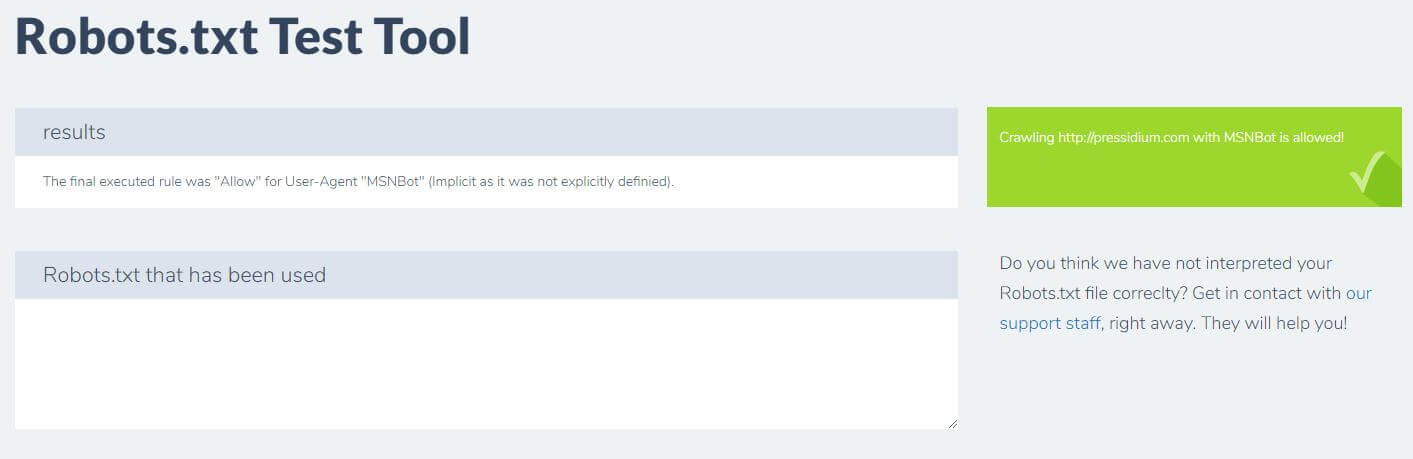
ドメインを入力し、右側のパネルからユーザーエージェントを選択するだけです。 これを送信すると、結果が表示されます。
結論
robots.txtの使用方法を知ることは、開発者向けツールキットのもう1つの便利なツールです。 このチュートリアルから得られる唯一のことは、robots.txtファイルがGoogleのようなボットをブロックしていないことを確認する機能である場合(これは、実行したくない可能性が非常に高いです)、それは悪いことではありません! 同様に、ご覧のとおり、robots.txtを使用すると、Webサイトをさらに細かく制御でき、いつか役立つ可能性があります。