
14 errores comunes de WordPress Robots.txt que se deben evitar
Publicado: 2025-01-14Robots.txt es un potente archivo de servidor que indica a los rastreadores de búsqueda y otros robots cómo comportarse en su sitio web de WordPress. Puede influir enormemente en la optimización del motor de búsqueda (SEO) de su sitio, tanto positiva como negativamente.
Por esa razón, debes saber qué es este archivo y cómo utilizarlo. De lo contrario, podrías dañar tu sitio web o, al menos, dejar parte de su potencial sobre la mesa.
Para ayudarle a evitar este escenario, en esta publicación cubriremos el archivo robots.txt en detalle. Definiremos qué es, su propósito, cómo encontrar y administrar su archivo y qué debe contener. Después de eso, repasaremos los errores más comunes que cometen las personas con su archivo robots.txt de WordPress, formas de evitarlos y cómo recuperarse si descubre que ha cometido un error.
¿Qué es el archivo robots.txt de WordPress?
Como se mencionó, robots.txt es un archivo de configuración del servidor. Normalmente lo encontrarás en la carpeta raíz de tu servidor.
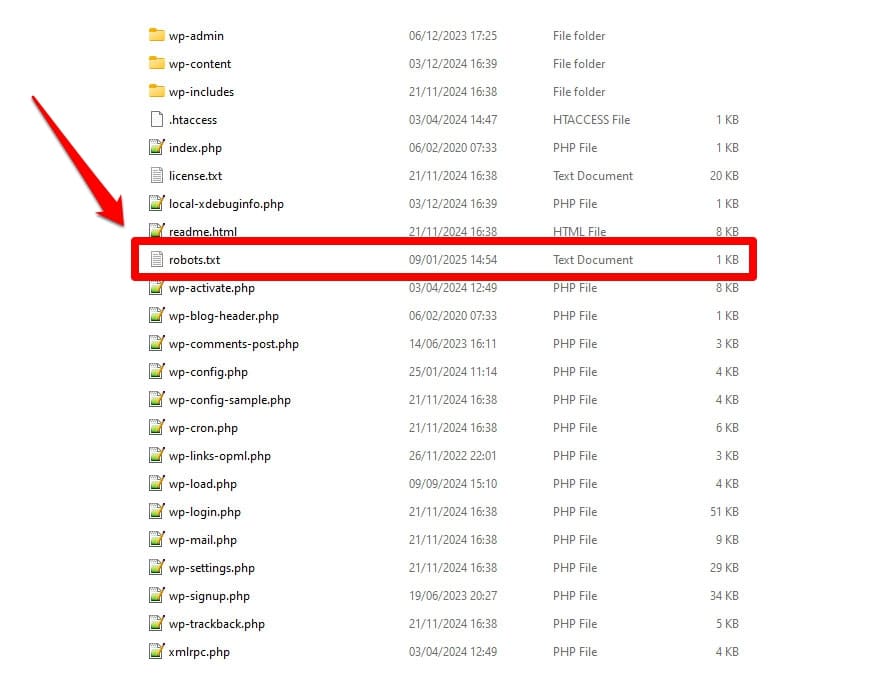
Cuando lo abres, el contenido se parece a esto:
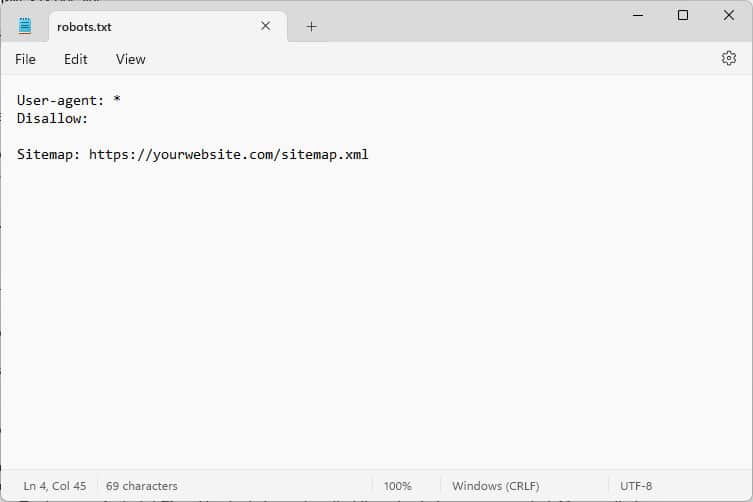
Estos fragmentos de código son instrucciones que le dicen a los robots que visitan su sitio web cómo comportarse mientras están allí; específicamente, a qué partes de su sitio web deben acceder y a cuáles no.
¿Qué robots, preguntas?
Los ejemplos más comunes son los rastreadores automáticos de motores de búsqueda que buscan páginas web para indexar o actualizar, pero también los bots de modelos de inteligencia artificial y otras herramientas automatizadas.
¿Qué directivas puedes dar con este archivo?
Robots.txt básicamente conoce cuatro directivas clave:
- Agente de usuario : define quién, es decir, para qué grupo o bots individuales son las reglas que siguen.
- No permitir : indica los directorios, archivos o recursos a los que el agente de usuario tiene prohibido acceder.
- Permitir : se puede utilizar para configurar excepciones, por ejemplo, para permitir el acceso a carpetas o recursos individuales en directorios que de otro modo estarían prohibidos.
- Mapa del sitio : dirige los robots a la ubicación URL del mapa del sitio de un sitio web.
Sólo User-agent y Disallow son obligatorios para que el archivo haga su trabajo; las otras dos directivas son opcionales. Por ejemplo, así es como bloqueas el acceso de cualquier bot a tu sitio:
User-agent: * Disallow: /El asterisco indica que la siguiente regla se aplica a todos los agentes de usuario. La barra diagonal después de Disallow indica que todos los directorios de este sitio están prohibidos. Este es el archivo robots.txt que normalmente se encuentra en los sitios de desarrollo, que se supone que no deben estar indexados por los motores de búsqueda.
Sin embargo, también puedes configurar reglas para bots individuales:
User-agent: Googlebot Allow: /private/resources/Es importante tener en cuenta que robots.txt no es vinculante. Sólo los bots de organizaciones que se adhieran al Protocolo de exclusión de robots obedecerán sus instrucciones. Los robots maliciosos, como los que buscan fallas de seguridad en su sitio, pueden ignorarlos y lo harán, y usted debe tomar medidas adicionales contra ellos.
Incluso las organizaciones que se adhieren al estándar ignorarán algunas directivas. Hablaremos de ejemplos de eso más adelante.
¿Por qué es importante el archivo robots.txt?
No es obligatorio que su sitio de WordPress tenga un archivo robots.txt. Su sitio funcionará sin uno y los motores de búsqueda no lo penalizarán por no tenerlo. Sin embargo, incluir uno le permite:
- Mantenga el contenido fuera de los resultados de búsqueda, como páginas de inicio de sesión o ciertos archivos multimedia.
- Evite que los rastreadores de búsqueda desperdicien su presupuesto de rastreo en partes sin importancia de su sitio, posiblemente ignorando las páginas que desea que indexen.
- Dirija los motores de búsqueda a su mapa del sitio para que puedan explorar más fácilmente el resto de su sitio web.
- Preserve los recursos del servidor manteniendo alejados a los robots derrochadores.
Todo esto ayuda a mejorar su sitio, particularmente su SEO, por lo que es importante que comprenda cómo utilizar robots.txt.
Cómo buscar, editar y crear su archivo robots.txt de WordPress
Como se mencionó, el archivo robots.txt generalmente se encuentra en la carpeta raíz de su sitio web en el servidor. Puedes acceder a él allí con un cliente FTP como FileZilla y editarlo con cualquier editor de texto.
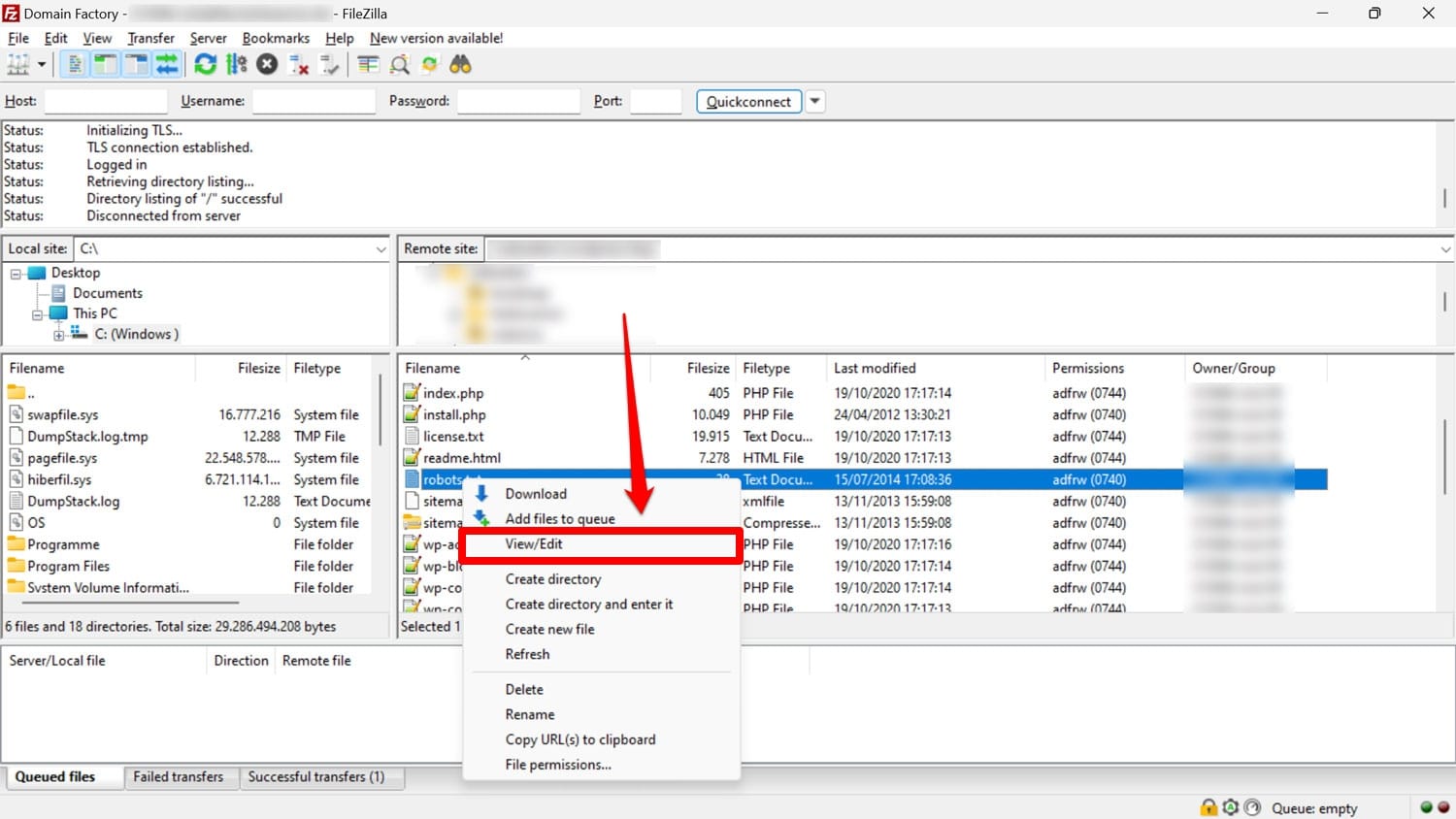
Si no tiene uno, es posible simplemente crear un archivo de texto vacío, llamarlo "robots.txt", llenarlo con directivas y cargarlo.
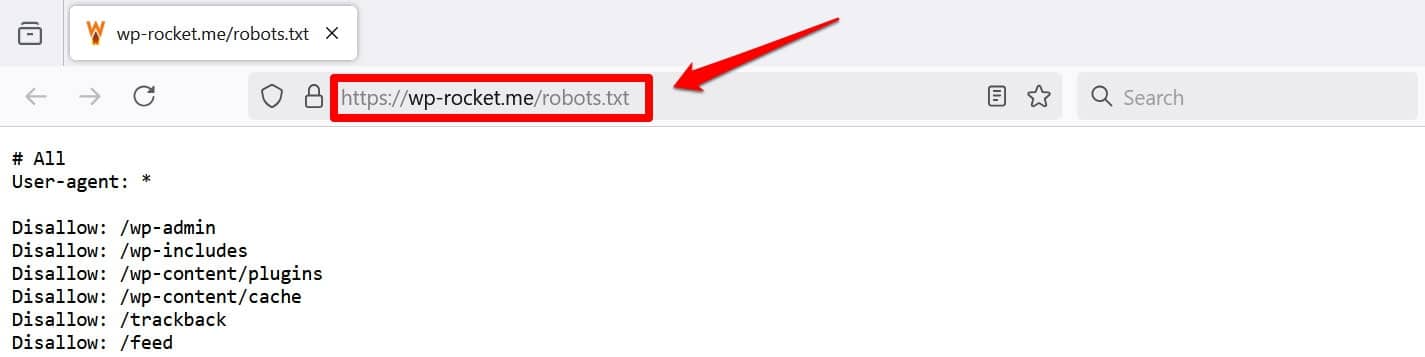
Otra forma de al menos ver su archivo es agregar /robots.txt a su dominio, por ejemplo, https://wp-rocket.me/robots.txt.
Además, hay formas de acceder al archivo desde el back-end de WordPress. Muchos complementos de SEO le permiten verlo y, a menudo, realizar cambios desde la interfaz de administración.
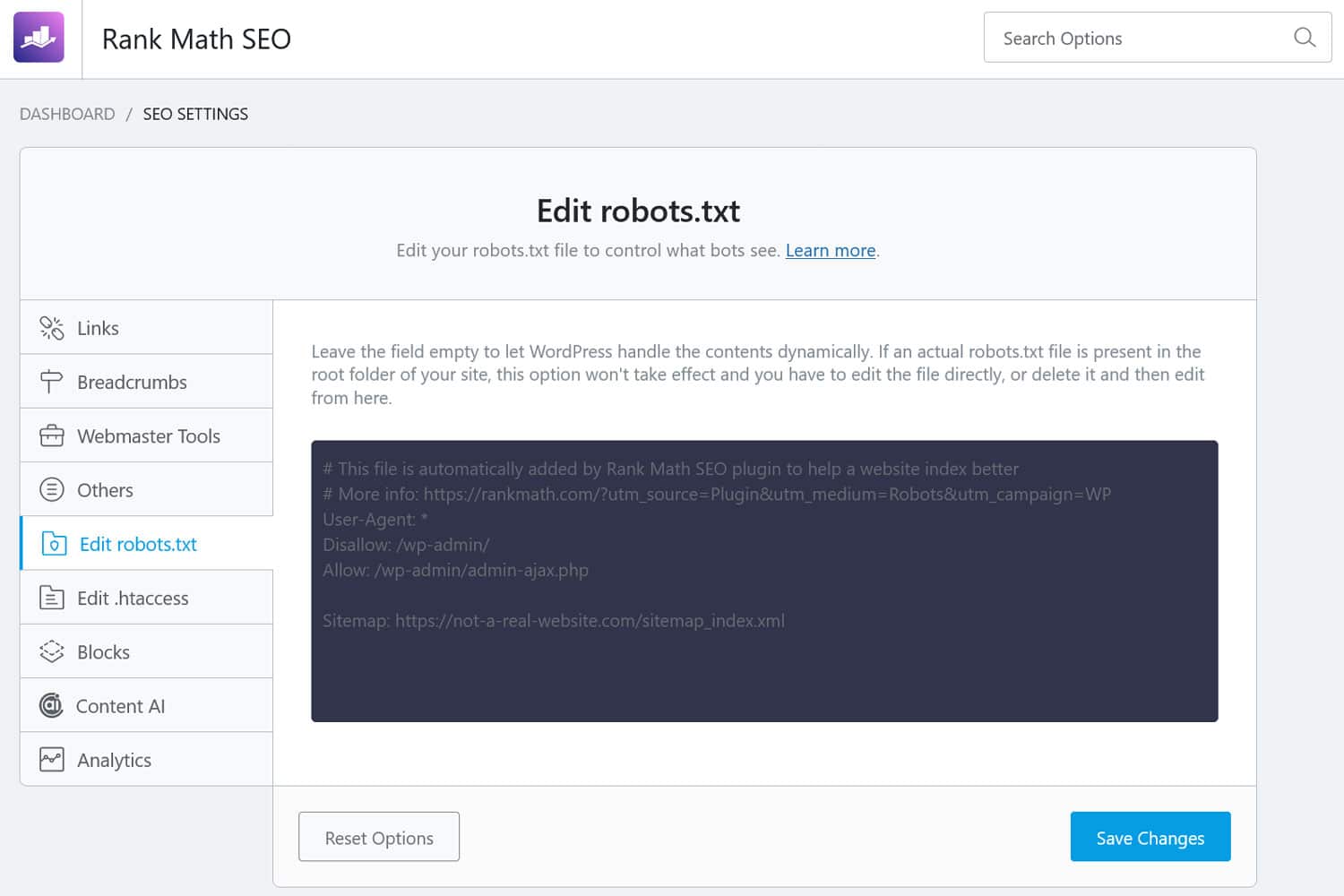
Alternativamente, también puedes usar un complemento como WPCode.
¿Cómo se ve un buen archivo robots.txt de WordPress?
No existe una respuesta única sobre qué directivas deberían estar en el archivo de su sitio web; Depende de tu configuración. Aquí hay un ejemplo que tiene sentido para muchos sitios web de WordPress:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://yourwebsite.com/sitemap.xmlEste ejemplo logra varios resultados:
- Bloquea el acceso al área de administración.
- Permite el acceso a funciones de administración esenciales
- Proporciona una ubicación en el mapa del sitio.
Esta configuración logra un equilibrio entre seguridad, rendimiento de SEO y rastreo eficiente.
No cometa estos 14 errores de robots.txt de WordPress
Si su objetivo es configurar y optimizar el archivo robots.txt para su propio sitio, asegúrese de evitar los siguientes errores.
1. Ignorar el archivo robots.txt interno de WordPress
Incluso si no tiene un archivo robots.txt “físico” en el directorio raíz de su sitio, WordPress viene con su propio archivo virtual. Es especialmente importante recordar esto si descubre que los motores de búsqueda no indexan su sitio web.
En ese caso, es muy probable que haya habilitado la opción para disuadirlos de hacerlo en Configuración > Lectura .
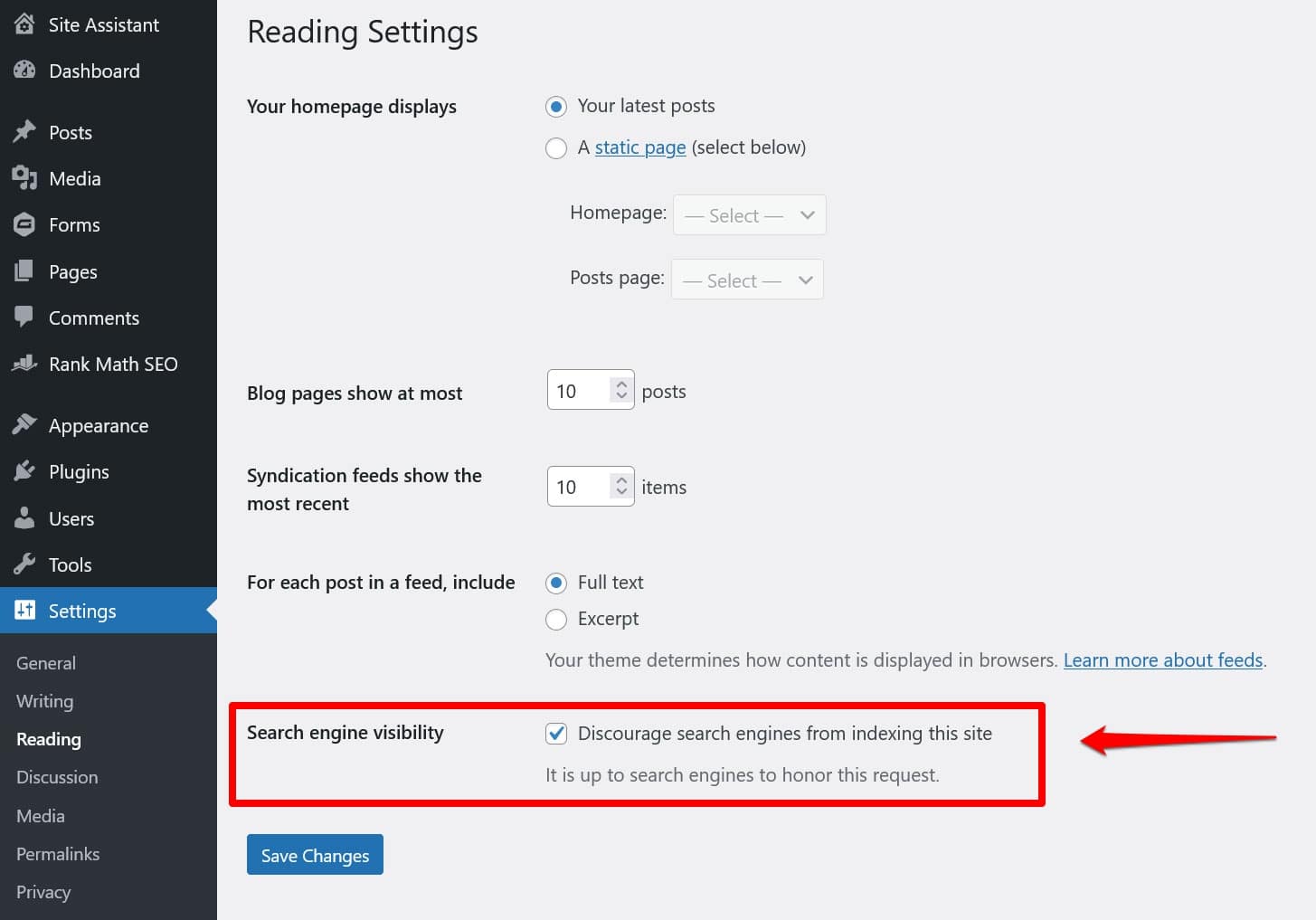
Esto establece una directiva para mantener todos los rastreadores de búsqueda fuera del archivo robots.txt virtual. Para desactivarlo, desmarca la casilla y guárdala en la parte inferior.
2. Colocarlo en el lugar equivocado
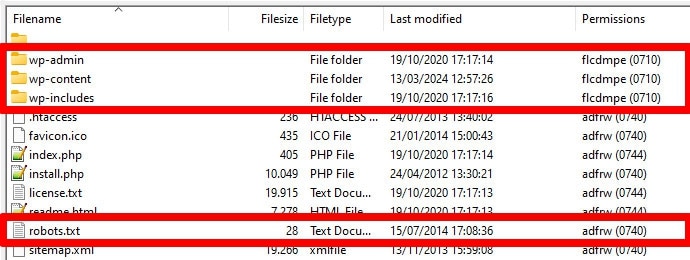
Los robots, en particular los rastreadores de búsqueda, buscan su archivo robots.txt solo en una ubicación: el directorio raíz de su sitio web. Si lo coloca en cualquier otro lugar, como en una carpeta, no lo encontrarán y lo ignorarán.
Su directorio raíz debe ser el lugar al que accede cuando accede a su servidor a través de FTP, a menos que haya colocado WordPress en un subdirectorio. Si ve las carpetas wp-admin , wp-content y wp-includes , está en el lugar correcto.
3. Incluir marcas obsoletas
Además de las directivas mencionadas anteriormente, hay dos más que aún puedes encontrar en los archivos robots.txt de sitios web más antiguos:
- Noindex : se utiliza para especificar URL que los motores de búsqueda no deben indexar en su sitio.
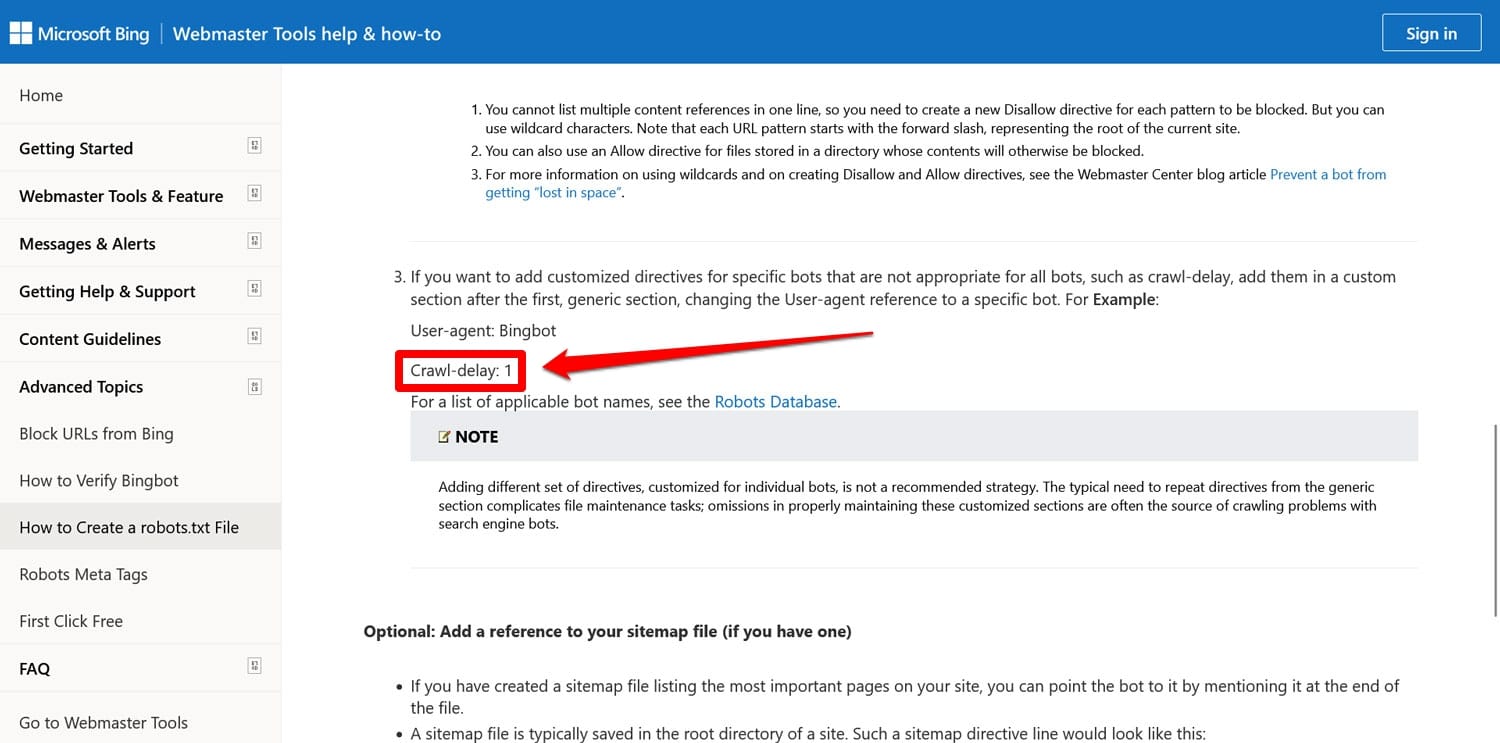
- Retraso de rastreo : directiva destinada a limitar los rastreadores para que no sobrecarguen los recursos del servidor web.
Ambas directivas ahora son ignoradas, al menos por Google. Bing, al menos, todavía respeta el retraso de rastreo.
En su mayor parte, es mejor no utilizar estas directivas. Esto ayuda a mantener su archivo optimizado y reduce el riesgo de errores.
Consejo: si su objetivo es evitar que los motores de búsqueda indexen determinadas páginas, utilice la metaetiqueta noindex . Puede implementarlo con un complemento de SEO por página.
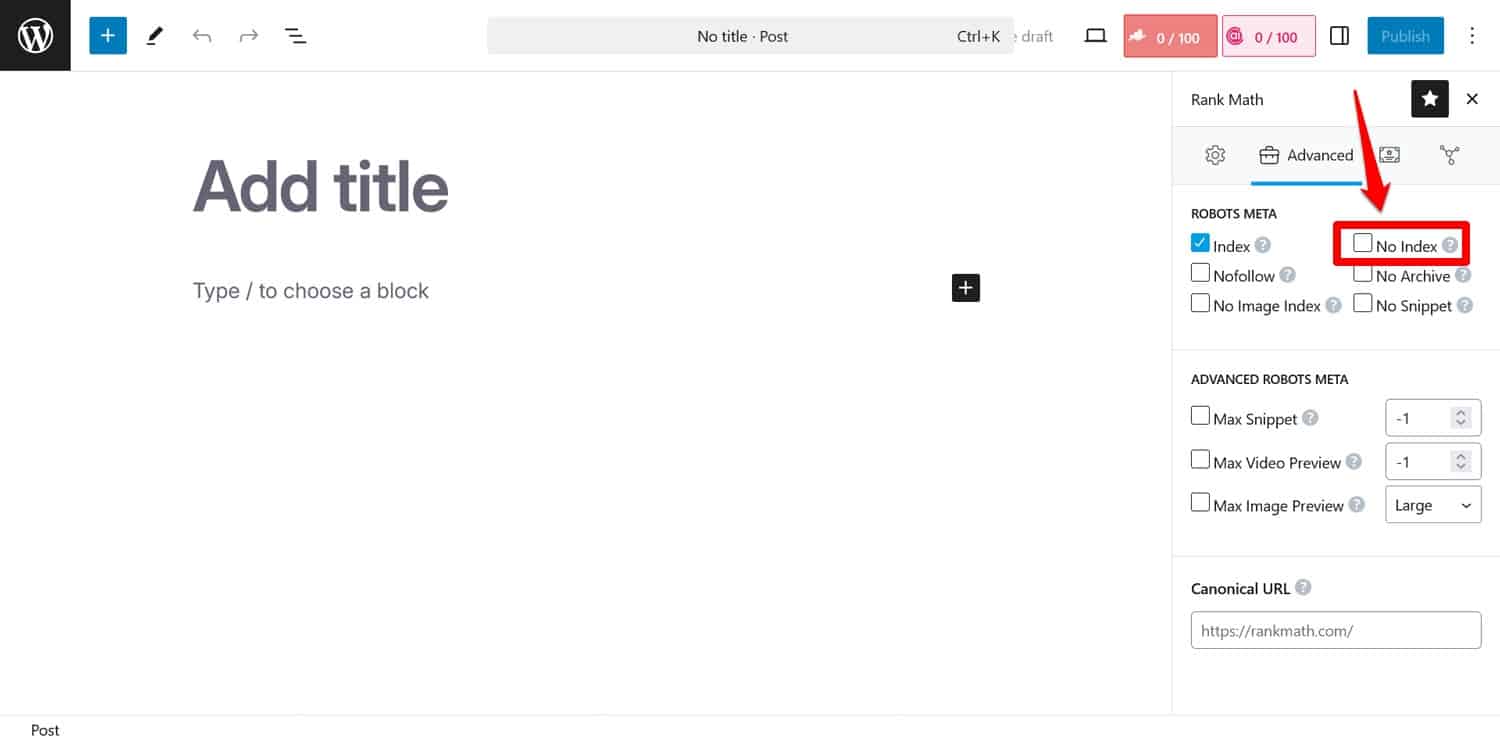
Si bloquea páginas mediante robots.txt, los rastreadores no llegarán a la parte donde ven la etiqueta noindex . De esa manera, es posible que aún indexen tu página pero sin su contenido, lo cual es peor.
4. Bloqueo de recursos esenciales
Uno de los errores que comete la gente es usar robots.txt para bloquear el acceso a todas las hojas de estilo (archivos CSS) y scripts (archivos JavaScript) en su sitio de WordPress para preservar el presupuesto de rastreo.
Sin embargo, esa no es una buena idea. Los robots de los motores de búsqueda muestran las páginas para "verlas" de la misma manera que lo hacen los visitantes. Esto les ayuda a comprender el contenido para poder indexarlo en consecuencia.
Al bloquear estos recursos, podría dar a los motores de búsqueda una impresión equivocada de sus páginas, lo que podría provocar que no se indexen correctamente o perjudicar su clasificación.
Si cree que los archivos CSS y JavaScript pueden afectar el rendimiento de su sitio, es una mejor idea optimizarlos para que se carguen rápidamente, tanto para los bots como para los visitantes habituales. Puede hacerlo minimizando el código y comprimiendo los archivos del sitio web para que se transmitan más rápido. Además, es posible optimizar su entrega eliminando el código no utilizado y aplazando los recursos que bloquean el procesamiento.

Consejo : puedes simplificar este proceso utilizando un complemento de rendimiento como WP Rocket. Su interfaz fácil de usar le permite optimizar la entrega de archivos marcando algunas casillas en el menú Optimización de archivos .
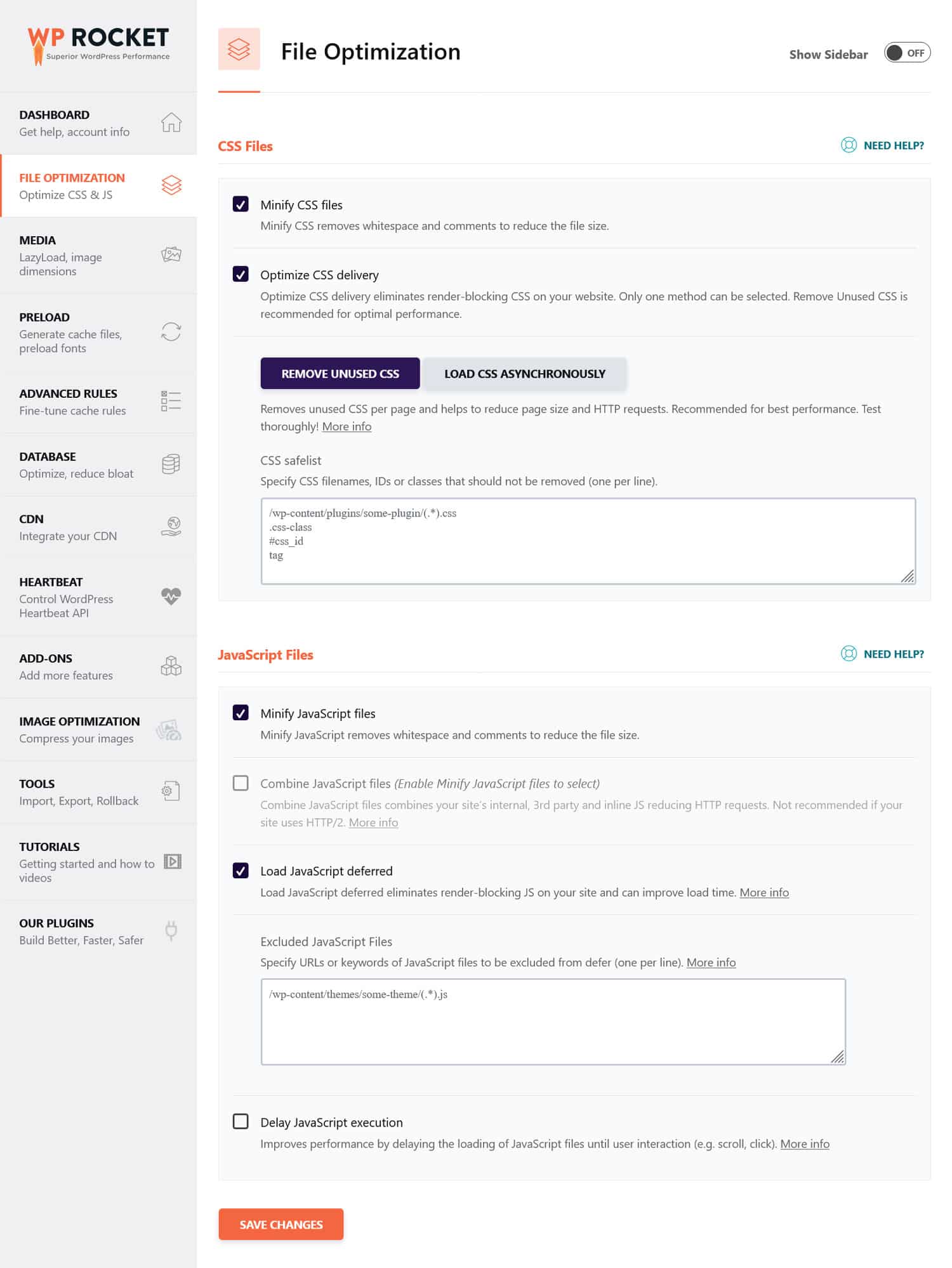
WP Rocket también viene con funciones adicionales para mejorar el rendimiento del sitio web, que incluyen:
- Almacenamiento en caché, con un caché móvil dedicado
- Carga diferida para imágenes y vídeos
- Precarga de caché, enlaces, archivos externos y fuentes
- Optimización de base de datos
Además, el complemento implementa muchos pasos de optimización automáticamente. Los ejemplos incluyen el almacenamiento en caché del navegador y del servidor, la compresión GZIP y la optimización de imágenes en la mitad superior de la página para mejorar LCP. De esa manera, su sitio será más rápido simplemente activando WP Rocket.
El complemento también ofrece una garantía de devolución de dinero de 14 días, para que puedas probarlo sin riesgos.
5. No actualizar el archivo robots.txt de desarrollo
Al crear un sitio web, los desarrolladores suelen incluir un archivo robots.txt que prohíbe que todos los bots accedan a él. Esto tiene sentido; Lo último que desea es que su sitio inacabado aparezca en los resultados de búsqueda.
Solo se produce un problema cuando transfiere accidentalmente este archivo a su servidor de producción y bloquea también a los motores de búsqueda para que no indexen su sitio web en vivo. Definitivamente verifique esto si su contenido se niega a aparecer en los resultados de búsqueda.
6. No incluir un enlace a su mapa del sitio
Al vincular su mapa del sitio desde robots.txt, los rastreadores de los motores de búsqueda obtienen una lista de todo su contenido. Esto aumenta sus posibilidades de que indexen algo más que la página actual a la que llegaron.
Todo lo que necesitas es una línea:
Sitemap: https://yourwebsite.com/sitemap.xmlSí, también puedes enviar tu mapa del sitio directamente en herramientas como Google Search Console.
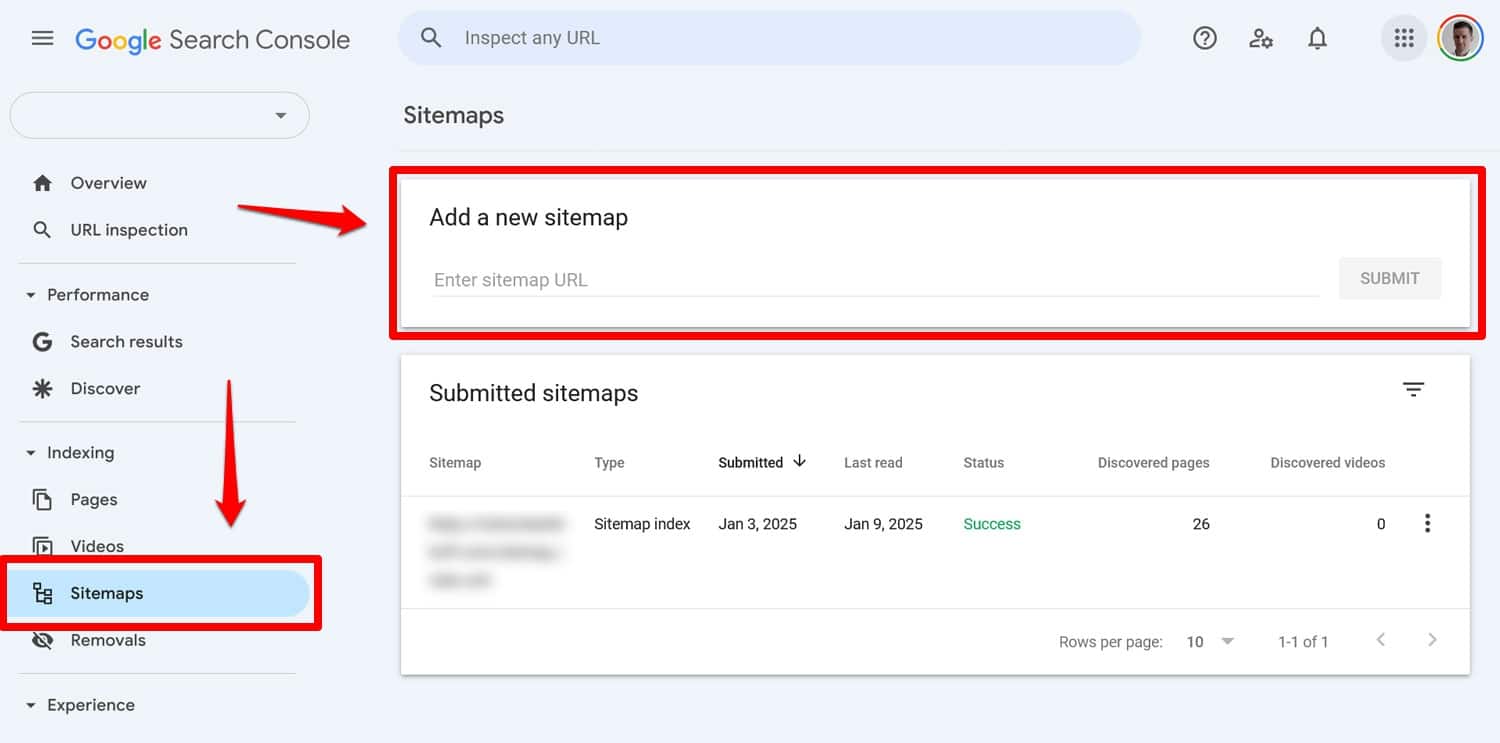
Sin embargo, incluirlo en su archivo robots.txt sigue siendo útil, especialmente para los motores de búsqueda cuyas herramientas para webmasters no está utilizando.
7. Usar reglas contradictorias
Un error común al crear un archivo robots.txt es agregar reglas que se contradicen entre sí, como por ejemplo:
User-agent: * Disallow: /blog/ Allow: /blog/Las directivas anteriores no dejan claro a los motores de búsqueda si deben rastrear el directorio /blog/ o no. Esto conduce a resultados impredecibles y puede dañar su SEO.
| ¿Tiene curiosidad por saber qué más puede ser perjudicial para el ranking de búsqueda de su sitio y cómo evitarlo? Aprenda sobre esto en nuestra guía de errores de SEO. |
Para evitar conflictos, siga estas mejores prácticas:
- Utilice primero reglas específicas : coloque reglas más específicas antes que otras más amplias.
- Evite la redundancia : no incluya directivas opuestas para el mismo camino.
- Pruebe su archivo robots.txt : utilice herramientas para confirmar que las reglas se comportan como se espera. Más sobre eso a continuación.
8. Intentar ocultar contenido confidencial con robots.txt
Como se mencionó anteriormente, robots.txt no es una herramienta para mantener el contenido fuera de los resultados de búsqueda. De hecho, debido a que el archivo es de acceso público, usarlo para bloquear contenido confidencial puede revelar sin querer exactamente dónde se encuentra ese contenido.
Consejo : utilice la metaetiqueta noindex para mantener el contenido fuera de los resultados de búsqueda. Además, proteja con contraseña las áreas confidenciales de su sitio para mantenerlas a salvo tanto de robots como de usuarios no autorizados.
9. Empleo inadecuado de comodines
Los comodines le permiten incluir grandes grupos de rutas o archivos en sus directivas. Ya conocimos uno antes, el símbolo *. Significa "cada instancia de" y se usa con mayor frecuencia para configurar reglas que se aplican a todos los agentes de usuario.
Otro símbolo comodín es $, que aplica reglas a la parte final de una URL. Puede usarlo, por ejemplo, si desea impedir que los rastreadores accedan a todos los archivos PDF de su sitio:
Disallow: /*.pdf$Si bien los comodines son útiles, pueden tener consecuencias de gran alcance. Úselos con cuidado y pruebe siempre su archivo robots.txt para asegurarse de no cometer ningún error.
10. URL absolutas y relativas confusas
Aquí está la diferencia entre URL absolutas y relativas:
- URL absoluta : https://yourwebsite.com/private/
- URL relativa – /privada/
Se recomienda utilizar URL relativas en sus directivas robots.txt, por ejemplo:
Disallow: /private/Las URL absolutas pueden causar problemas en los que los robots pueden ignorar o malinterpretar la directiva. La única excepción es la ruta a su mapa del sitio, que debe ser una URL absoluta.
11. Ignorar la distinción entre mayúsculas y minúsculas
Las directivas Robots.txt distinguen entre mayúsculas y minúsculas. Esto significa que las dos directivas siguientes no son intercambiables:
Disallow: /Private/ Disallow: /private/Si descubre que su archivo robots.txt no se comporta como se esperaba, verifique si el problema podría ser el uso de mayúsculas incorrectas.
12. Usar barras diagonales incorrectamente
Una barra diagonal es una barra al final de una URL:
- Sin barra diagonal : /directorio
- Con una barra al final : /directorio/
En robots.txt decide qué recursos del sitio están permitidos y no permitidos. He aquí un ejemplo:
Disallow: /private/La regla anterior impide que los rastreadores accedan al directorio "privado" de su sitio y a todo lo que contiene. Por otro lado, digamos que omites la barra diagonal, así:
Disallow: /privateEn este caso, la regla también bloquearía otras instancias que comiencen con "privado" en su sitio, como por ejemplo:
- https://tusitioweb.com/privado.html
- https://tusitioweb.com/privateer
Por tanto, es importante ser preciso. En caso de duda, pruebe su archivo.
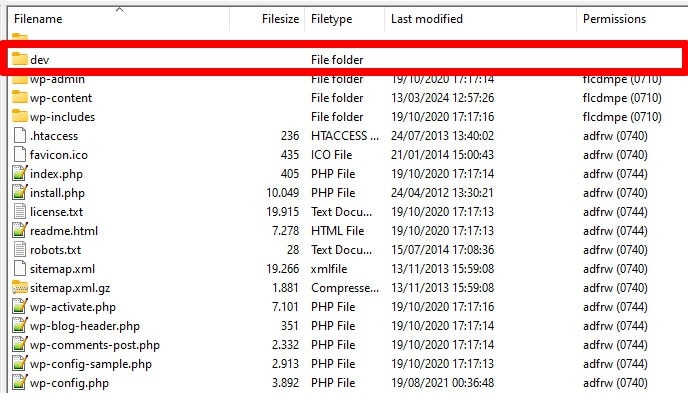
13. Falta robots.txt para subdominios
Cada subdominio de su sitio web (por ejemplo, dev.yourwebsite.com) necesita su propio archivo robots.txt porque los motores de búsqueda los tratan como entidades web independientes. Sin un archivo en su lugar, corre el riesgo de que los rastreadores indexen partes de su sitio que pretendía mantener ocultas.
Por ejemplo, si su versión de desarrollo está en una carpeta llamada "dev" y utiliza un subdominio, asegúrese de que tenga un archivo robots.txt dedicado para bloquear los rastreadores de búsqueda.
14. No probar su archivo robots.txt
Uno de los mayores errores al configurar su archivo robots.txt de WordPress es no probarlo, especialmente después de realizar cambios.
Como hemos visto, incluso pequeños errores de sintaxis o lógica pueden causar importantes problemas de SEO. Por lo tanto, pruebe siempre su archivo robots.txt.
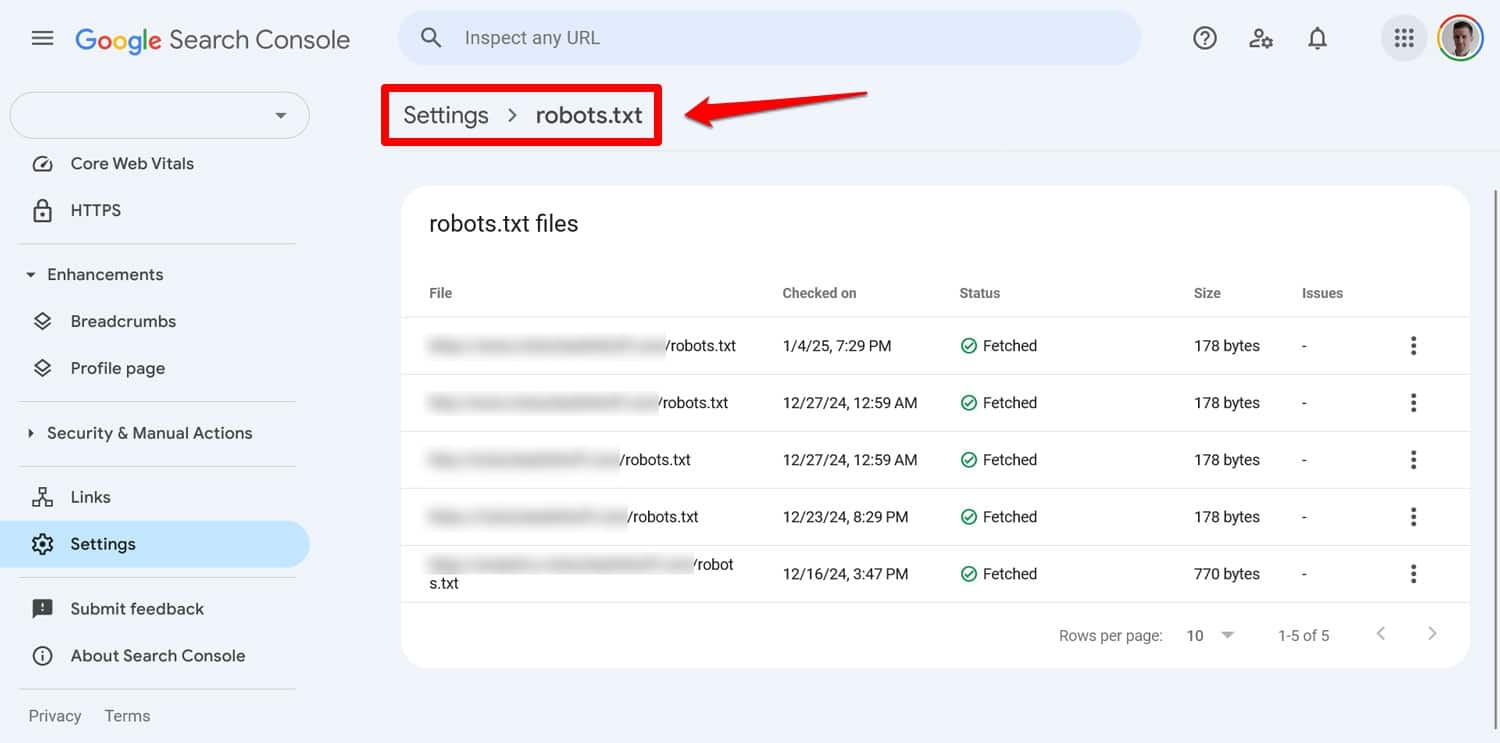
Puedes ver cualquier problema con tu archivo en Google Search Console en Configuración > robots.txt .
Otra forma es simular el comportamiento de rastreo con una herramienta como Screaming Frog. Además, utilice un entorno de prueba para verificar el impacto de las nuevas reglas antes de aplicarlas a su sitio en vivo.
Cómo recuperarse de un error de robots.txt
Los errores en su archivo robots.txt son fáciles de cometer, pero afortunadamente también suelen ser fáciles de corregir una vez que los descubre.
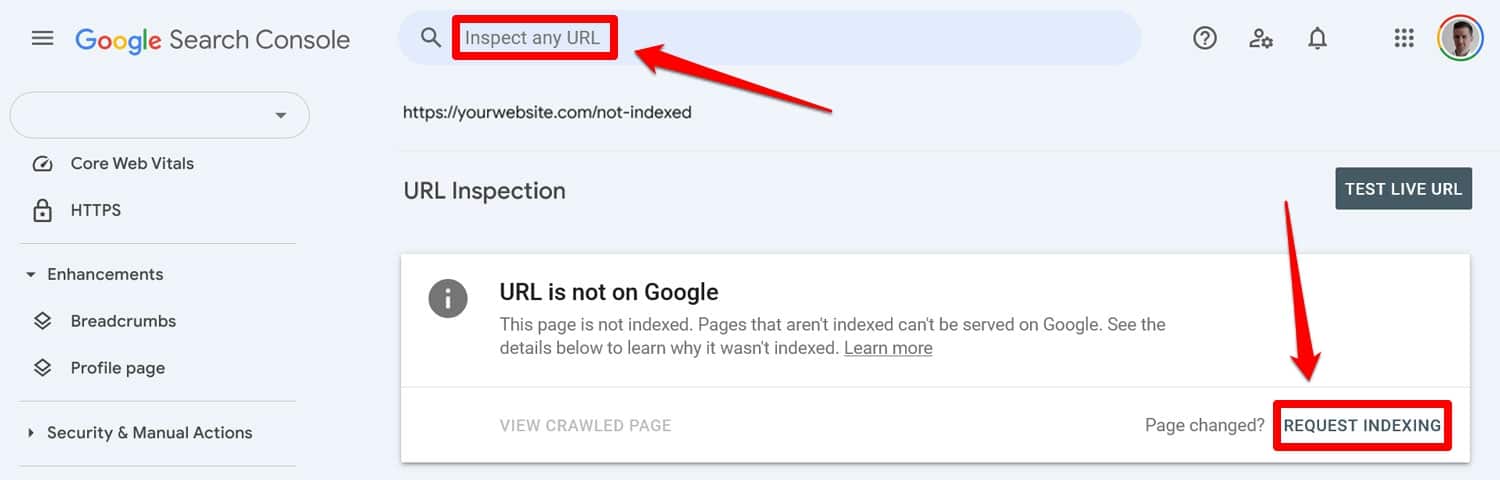
Comience ejecutando su archivo robots.txt actualizado a través de una herramienta de prueba. Luego, si las páginas fueron previamente bloqueadas por directivas robots.txt, ingréselas manualmente en Google Search Console o Bing Webmaster Tools para solicitar la indexación.
Además, vuelva a enviar una versión actualizada de su mapa del sitio.
Después de eso, es sólo un juego de espera. Los motores de búsqueda volverán a visitar su sitio y, con suerte, restaurarán su lugar en las clasificaciones rápidamente.
Tome el control de su archivo robots.txt de WordPress
Con los archivos robots.txt, más vale prevenir que curar. Especialmente en sitios web más grandes, un archivo defectuoso puede causar estragos en las clasificaciones, el tráfico y los ingresos.
Por ese motivo, cualquier cambio en el archivo robots.txt de su sitio debe realizarse con cuidado y tras pruebas exhaustivas. Ser consciente de los errores que puedes cometer es un primer paso para prevenirlos.
Cuando cometa un error, trate de no entrar en pánico. Diagnostique lo que está mal, corrija los errores y vuelva a enviar su mapa del sitio para que se vuelva a rastrear su sitio.
Finalmente, asegúrese de que el rendimiento no sea la razón por la que los motores de búsqueda no rastrean adecuadamente su sitio. ¡Pruebe WP Rocket ahora para hacer que su sitio sea más rápido al instante!