
Cómo Crear una Base de Datos MongoDB: 6 Aspectos Críticos a Saber
Publicado: 2022-11-07Según los requisitos de su software, puede priorizar la flexibilidad, la escalabilidad, el rendimiento o la velocidad. Por lo tanto, los desarrolladores y las empresas a menudo se confunden al elegir una base de datos para sus necesidades. Si necesita una base de datos que brinde alta flexibilidad y escalabilidad, y agregación de datos para análisis de clientes, ¡MongoDB puede ser la opción adecuada para usted!
En este artículo, discutiremos la estructura de la base de datos MongoDB y cómo crear, monitorear y administrar su base de datos. Empecemos.
¿Cómo se estructura una base de datos MongoDB?
MongoDB es una base de datos NoSQL sin esquema. Esto significa que no especifica una estructura para las tablas/bases de datos como lo hace con las bases de datos SQL.
¿Sabía que las bases de datos NoSQL son en realidad más rápidas que las bases de datos relacionales? Esto se debe a características como canalizaciones de indexación, fragmentación y agregación. MongoDB también es conocido por su rápida ejecución de consultas. Es por eso que es preferido por compañías como Google, Toyota y Forbes.
A continuación, exploraremos algunas características clave de MongoDB.
Documentos
MongoDB tiene un modelo de datos de documentos que almacena datos como documentos JSON. Los documentos se asignan naturalmente a los objetos en el código de la aplicación, lo que facilita su uso para los desarrolladores.
En una tabla de base de datos relacional, debe agregar una columna para agregar un nuevo campo. Ese no es el caso con los campos en un documento JSON. Los campos de un documento JSON pueden diferir de un documento a otro, por lo que no se agregarán a todos los registros de la base de datos.
Los documentos pueden almacenar estructuras como matrices que se pueden anidar para expresar relaciones jerárquicas. Además, MongoDB convierte documentos en un tipo binario JSON (BSON). ¡Esto garantiza un acceso más rápido y una mayor compatibilidad con varios tipos de datos como cadenas, enteros, números booleanos y mucho más!
Conjuntos de réplicas
Cuando crea una nueva base de datos en MongoDB, el sistema crea automáticamente al menos 2 copias más de sus datos. Estas copias se conocen como "conjuntos de réplicas" y replican continuamente los datos entre ellos, lo que garantiza una mejor disponibilidad de sus datos. También ofrecen protección contra el tiempo de inactividad durante una falla del sistema o un mantenimiento planificado.
Colecciones
Una colección es un grupo de documentos asociados con una base de datos. Son similares a las tablas de las bases de datos relacionales.
Las colecciones, sin embargo, son mucho más flexibles. Por un lado, no se basan en un esquema. En segundo lugar, ¡los documentos no necesitan ser del mismo tipo de datos!
Para ver una lista de las colecciones que pertenecen a una base de datos, use el comando listCollections .
Tuberías de agregación
Puede usar este marco para asociar varios operadores y expresiones. Es flexible porque te permite procesar, transformar y analizar datos de cualquier estructura.
Debido a esto, MongoDB permite funciones y flujos de datos rápidos en 150 operadores y expresiones. También tiene varios escenarios, como el escenario Unión, que reúne de manera flexible los resultados de múltiples colecciones.
Índices
Puede indexar cualquier campo en un documento MongoDB para aumentar su eficiencia y mejorar la velocidad de consulta. La indexación ahorra tiempo al escanear el índice para limitar los documentos inspeccionados. ¿No es esto mucho mejor que leer todos los documentos de la colección?
Puede utilizar varias estrategias de indexación, incluidos índices compuestos en varios campos. Por ejemplo, suponga que tiene varios documentos que contienen el nombre y apellido del empleado en campos separados. Si desea que se devuelva el nombre y el apellido, puede crear un índice que incluya tanto el "Apellido" como el "Nombre". Esto sería mucho mejor que tener un índice en "Apellido" y otro en "Nombre".
Puede aprovechar herramientas como Performance Advisor para comprender mejor qué consulta podría beneficiarse de los índices.
fragmentación
Sharding distribuye un único conjunto de datos en varias bases de datos. Ese conjunto de datos se puede almacenar en varias máquinas para aumentar la capacidad de almacenamiento total de un sistema. Esto se debe a que divide conjuntos de datos más grandes en fragmentos más pequeños y los almacena en varios nodos de datos.
MongoDB fragmenta datos a nivel de colección, distribuyendo documentos en una colección a través de los fragmentos en un clúster. Esto asegura la escalabilidad al permitir que la arquitectura maneje las aplicaciones más grandes.
Cómo crear una base de datos MongoDB
Primero deberá instalar el paquete MongoDB adecuado para su sistema operativo. Vaya a la página 'Descargar MongoDB Community Server'. De las opciones disponibles, seleccione la última "versión", formato de "paquete" como archivo zip y "plataforma" como su sistema operativo y haga clic en "Descargar" como se muestra a continuación:
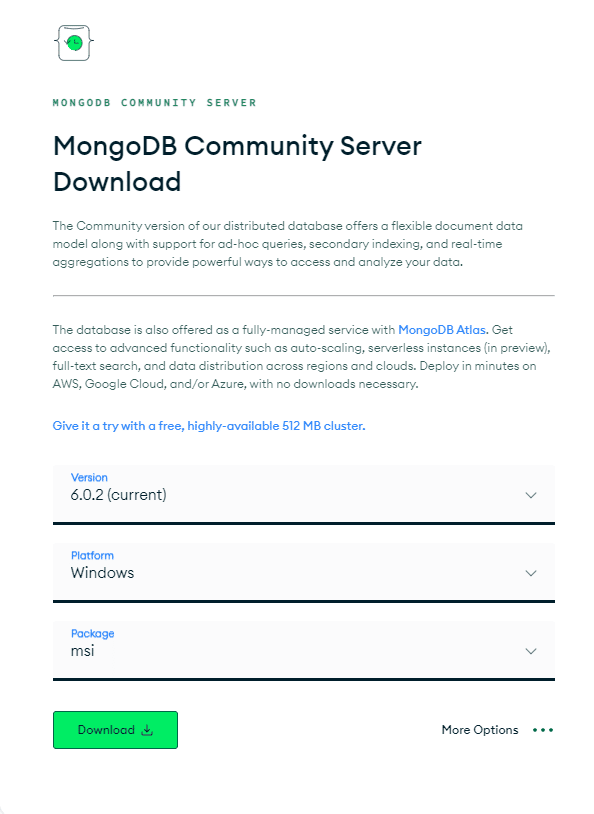
¡El proceso es bastante sencillo, por lo que tendrá MongoDB instalado en su sistema en muy poco tiempo!
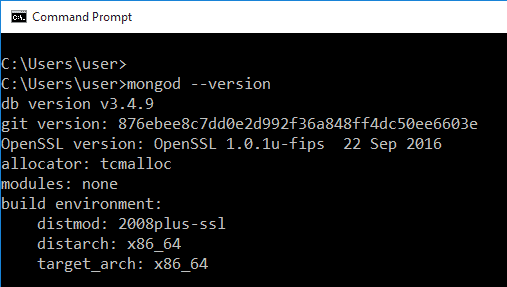
Una vez que haya realizado la instalación, abra su símbolo del sistema y escriba mongod -version para verificarlo. Si no obtiene el siguiente resultado y, en cambio, ve una serie de errores, es posible que deba volver a instalarlo:
Usando MongoDB Shell
Antes de comenzar, asegúrese de que:
- Su cliente tiene Seguridad de la capa de transporte y está en su lista de direcciones IP permitidas.
- Tiene una cuenta de usuario y una contraseña en el clúster MongoDB deseado.
- Ha instalado MongoDB en su dispositivo.
Paso 1: acceda al shell de MongoDB
Para obtener acceso al shell de MongoDB, escriba el siguiente comando:
net start MongoDBEsto debería dar el siguiente resultado:
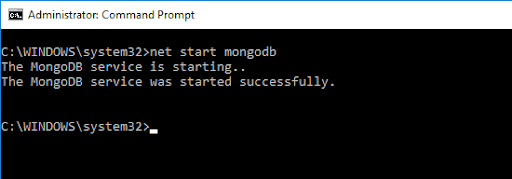
El comando anterior inicializó el servidor MongoDB. Para ejecutarlo, tendríamos que escribir mongo en el símbolo del sistema.
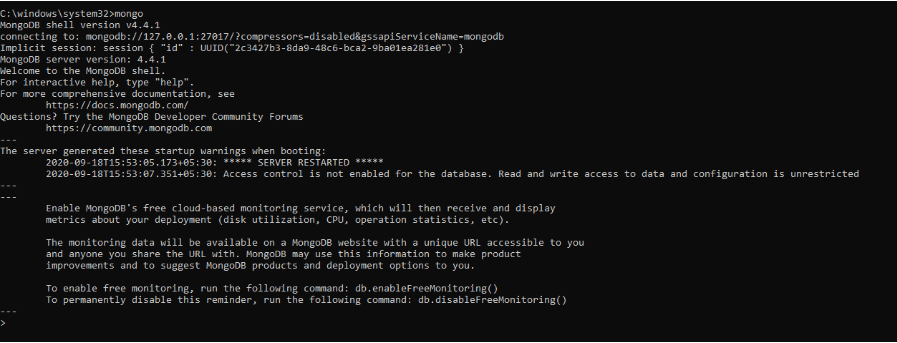
Aquí, en el shell de MongoDB, podemos ejecutar comandos para crear bases de datos, insertar datos, editar datos, emitir comandos administrativos y eliminar datos.
Paso 2: crea tu base de datos
A diferencia de SQL, MongoDB no tiene un comando de creación de base de datos. En cambio, hay una palabra clave llamada use que cambia a una base de datos específica. Si la base de datos no existe, creará una nueva base de datos; de lo contrario, se vinculará a la base de datos existente.
Por ejemplo, para iniciar una base de datos llamada "empresa", escriba:
use Company 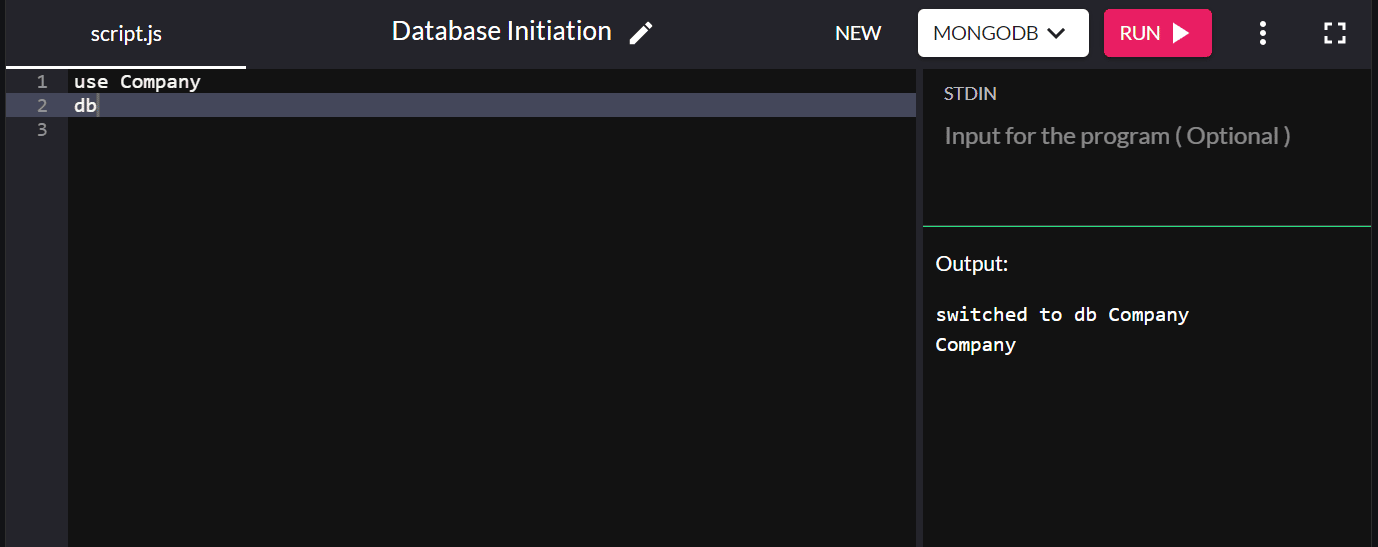
Puede escribir db para confirmar la base de datos que acaba de crear en su sistema. Si aparece la nueva base de datos que creó, se ha conectado correctamente a ella.
Si desea verificar las bases de datos existentes, escriba show dbs y devolverá todas las bases de datos en su sistema:
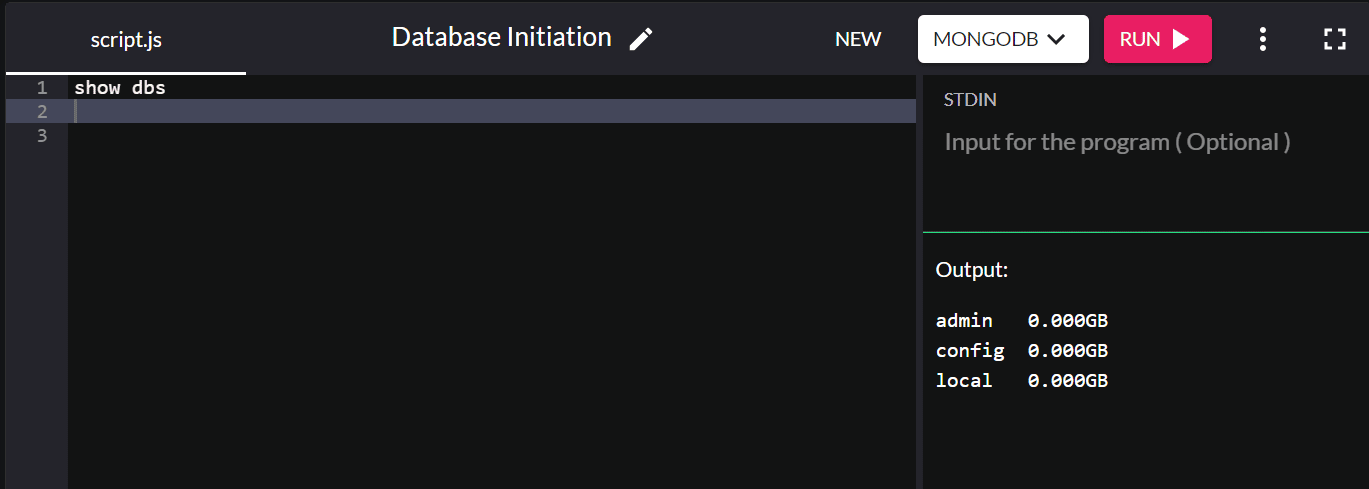
De forma predeterminada, la instalación de MongoDB crea las bases de datos de administración, configuración y locales.
¿Notaste que la base de datos que creamos no se muestra? ¡Esto se debe a que aún no hemos guardado valores en la base de datos! Discutiremos la inserción en la sección de administración de la base de datos.
Uso de la interfaz de usuario de Atlas
También puede comenzar con el servicio de base de datos de MongoDB, Atlas. Si bien es posible que deba pagar para acceder a algunas funciones de Atlas, la mayoría de las funciones de la base de datos están disponibles con el nivel gratuito. Las características del nivel gratuito son más que suficientes para crear una base de datos MongoDB.
Antes de comenzar, asegúrese de que:
- Su IP está en la lista de permitidos.
- Tiene una cuenta de usuario y una contraseña en el clúster de MongoDB que desea utilizar.
Para crear una base de datos MongoDB con AtlasUI, abra una ventana del navegador e inicie sesión en https://cloud.mongodb.com. Desde la página de su clúster, haga clic en Examinar colecciones . Si no hay bases de datos en el clúster, puede crear su base de datos haciendo clic en el botón Agregar mis propios datos .
El aviso le pedirá que proporcione una base de datos y un nombre de colección. Una vez que los hayas nombrado, haz clic en Crear y ¡listo! Ahora puede ingresar nuevos documentos o conectarse a la base de datos usando controladores.
Administrar su base de datos MongoDB
En esta sección, repasaremos algunas formas ingeniosas de administrar su base de datos MongoDB de manera efectiva. Puede hacerlo utilizando MongoDB Compass o mediante colecciones.
Uso de colecciones
Mientras que las bases de datos relacionales poseen tablas bien definidas con tipos de datos y columnas específicos, NoSQL tiene colecciones en lugar de tablas. Estas colecciones no tienen ninguna estructura y los documentos pueden variar; puede tener diferentes tipos de datos y campos sin tener que coincidir con el formato de otro documento en la misma colección.
Para demostrarlo, vamos a crear una colección llamada "Empleado" y agregarle un documento:
db.Employee.insert( { "Employeename" : "Chris", "EmployeeDepartment" : "Sales" } ) Si la inserción es exitosa, devolverá WriteResult({ "nInserted" : 1 }) :
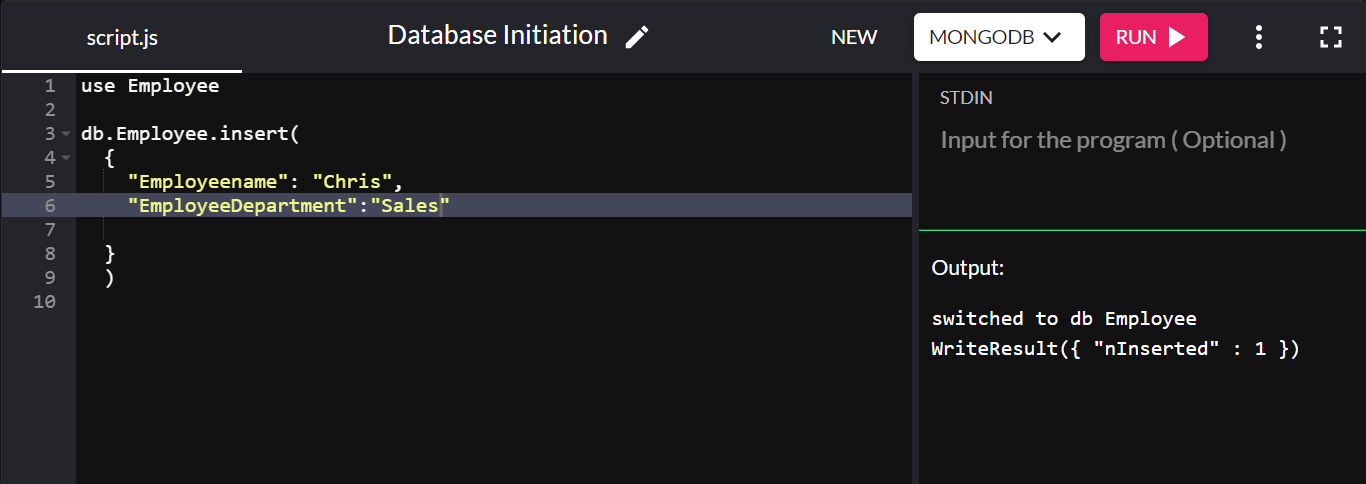
Aquí, "db" se refiere a la base de datos actualmente conectada. “Empleado” es la colección recién creada en la base de datos de la empresa.
No hemos establecido una clave principal aquí porque MongoDB crea automáticamente un campo de clave principal llamado "_id" y le establece un valor predeterminado.
Ejecute el siguiente comando para ver la colección en formato JSON:
db.Employee.find().forEach(printjson)Producción:
{ "_id" : ObjectId("63151427a4dd187757d135b8"), "Employeename" : "Chris", "EmployeeDepartment" : "Sales" }Si bien el valor "_id" se asigna automáticamente, puede cambiar el valor de la clave principal predeterminada. Esta vez, insertaremos otro documento en la base de datos "Empleado", con el valor "_id" como "1":
db.Employee.insert( { "_id" : 1, "EmployeeName" : "Ava", "EmployeeDepartment" : "Public Relations" } ) Al ejecutar el comando db.Employee.find().forEach(printjson) obtenemos el siguiente resultado:
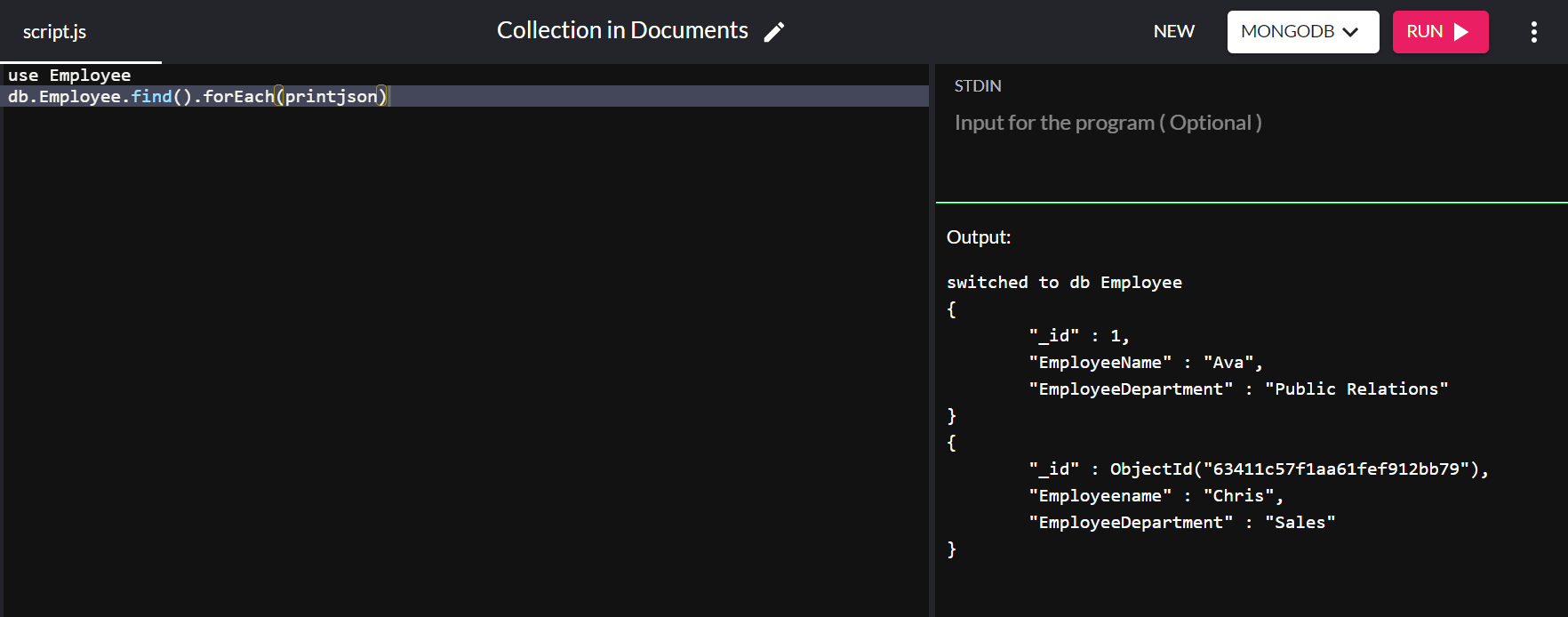
En el resultado anterior, el valor "_id" para "Ava" se establece en "1" en lugar de que se le asigne un valor automáticamente.
Ahora que hemos agregado con éxito valores a la base de datos, podemos verificar si aparece en las bases de datos existentes en nuestro sistema usando el siguiente comando:
show dbs 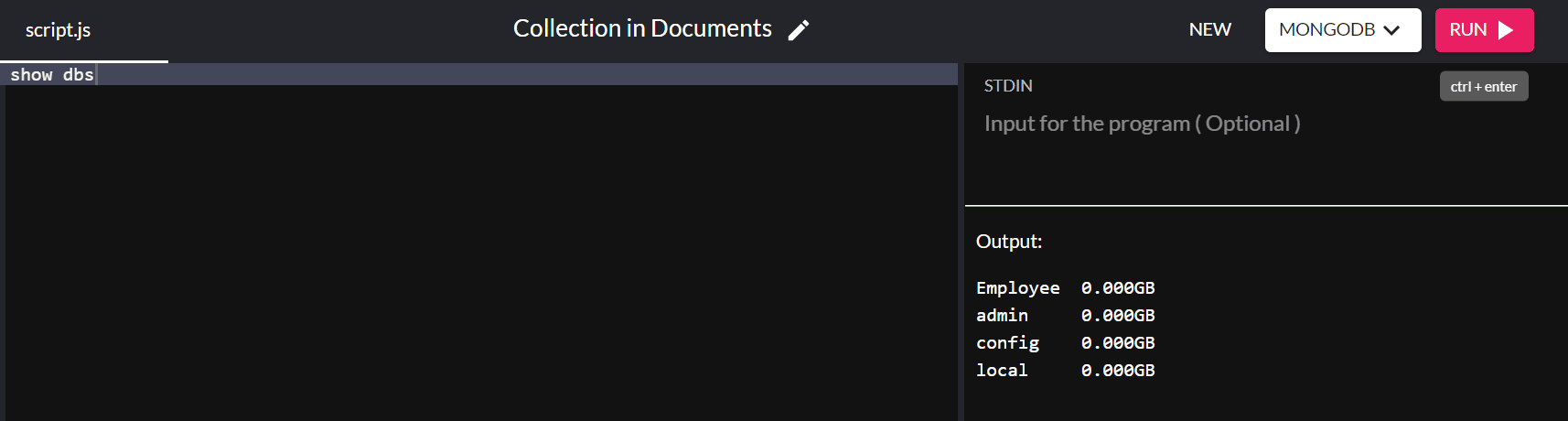
¡Y voilá! ¡Ha creado con éxito una base de datos en su sistema!
Uso de la brújula de MongoDB
Aunque podemos trabajar con servidores MongoDB desde el shell de Mongo, en ocasiones puede resultar tedioso. Puede experimentar esto en un entorno de producción.
Sin embargo, hay una herramienta de brújula (apropiadamente llamada Compass) creada por MongoDB que puede facilitarlo. Tiene una mejor GUI y funcionalidades adicionales como visualización de datos, creación de perfiles de rendimiento y acceso CRUD (crear, leer, actualizar, eliminar) a datos, bases de datos y colecciones.
Puede descargar el IDE de Compass para su sistema operativo e instalarlo con su sencillo proceso.
A continuación, abra la aplicación y cree una conexión con el servidor pegando la cadena de conexión. Si no lo encuentra, puede hacer clic en Rellenar los campos de conexión individualmente . Si no cambió el número de puerto al instalar MongoDB, simplemente haga clic en el botón de conexión y ya está. De lo contrario, simplemente ingrese los valores que estableció y haga clic en Conectar .
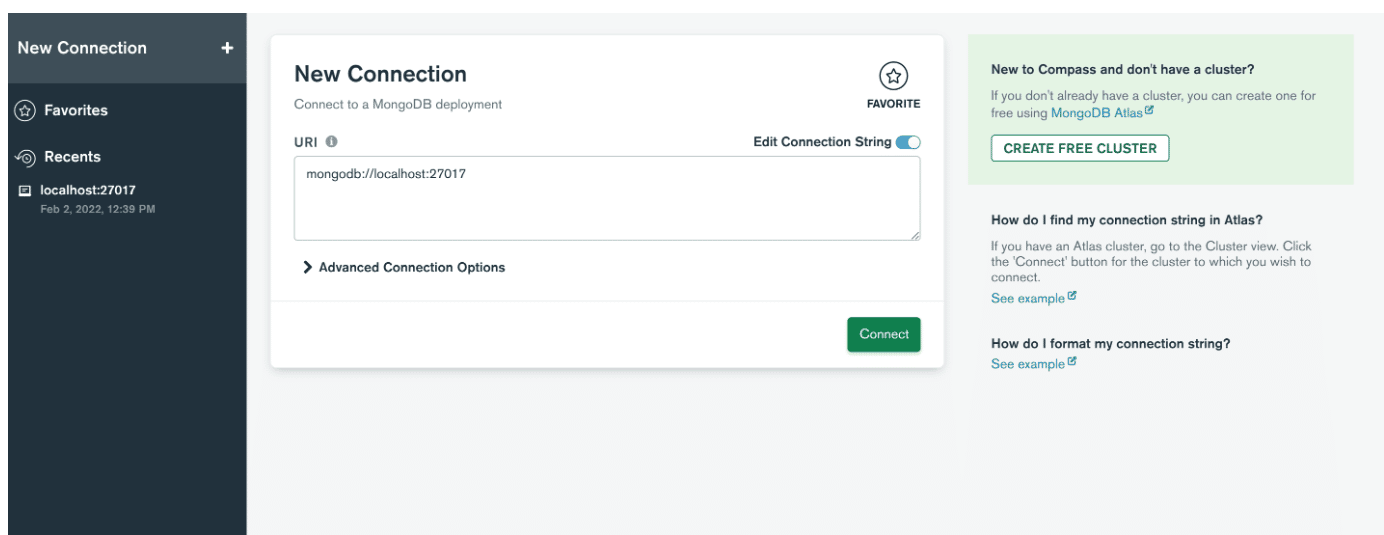
A continuación, proporcione el nombre de host, el puerto y la autenticación en la ventana Nueva conexión.
En MongoDB Compass, puede crear una base de datos y agregar su primera colección simultáneamente. Así es como lo haces:
- Haga clic en Crear base de datos para abrir el aviso.
- Introduzca el nombre de la base de datos y su primera colección.
- Haga clic en Crear base de datos .
Puede insertar más documentos en su base de datos haciendo clic en el nombre de su base de datos y luego haciendo clic en el nombre de la colección para ver la pestaña Documentos . Luego puede hacer clic en el botón Agregar datos para insertar uno o más documentos en su colección.
Mientras agrega sus documentos, puede ingresarlos uno a la vez o como varios documentos en una matriz. Si está agregando varios documentos, asegúrese de que estos documentos separados por comas estén entre corchetes. Por ejemplo:
{ _id: 1, item: { name: "apple", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }, { _id: 2, item: { name: "banana", code: "123" }, qty: 20, tags: [ "B" ] }, { _id: 3, item: { name: "spinach", code: "456" }, qty: 25, tags: [ "A", "B" ] }, { _id: 4, item: { name: "lentils", code: "456" }, qty: 30, tags: [ "B", "A" ] }, { _id: 5, item: { name: "pears", code: "000" }, qty: 20, tags: [ [ "A", "B" ], "C" ] }, { _id: 6, item: { name: "strawberry", code: "123" }, tags: [ "B" ] }Finalmente, haga clic en Insertar para agregar los documentos a su colección. Así es como se vería el cuerpo de un documento:
{ "StudentID" : 1 "StudentName" : "JohnDoe" }Aquí, los nombres de campo son "StudentID" y "StudentName". Los valores de campo son "1" y "JohnDoe" respectivamente.
Comandos útiles
Puede administrar estas colecciones mediante la administración de roles y los comandos de administración de usuarios.
Comandos de administración de usuarios
Los comandos de administración de usuarios de MongoDB contienen comandos que pertenecen al usuario. Podemos crear, actualizar y eliminar los usuarios usando estos comandos.
soltarUsuario
Este comando elimina un solo usuario de la base de datos especificada. A continuación se muestra la sintaxis:
db.dropUser(username, writeConcern) Aquí, el nombre de username es un campo obligatorio que contiene el documento con información de autenticación y acceso sobre el usuario. El campo opcional writeConcern contiene el nivel de preocupación de escritura para la operación de creación. El nivel de preocupación de escritura se puede determinar mediante el campo opcional writeConcern .
Antes de descartar a un usuario que tiene el rol userAdminAnyDatabase , asegúrese de que haya al menos otro usuario con privilegios de administración de usuarios.
En este ejemplo, colocaremos al usuario "usuario26" en la base de datos de prueba:
use test db.dropUser("user26", {w: "majority", wtimeout: 4000})Producción:
> db.dropUser("user26", {w: "majority", wtimeout: 4000}); truecrear usuario
Este comando crea un nuevo usuario para la base de datos especificada de la siguiente manera:
db.createUser(user, writeConcern) Aquí, user es un campo obligatorio que contiene el documento con información de autenticación y acceso sobre el usuario a crear. El campo opcional writeConcern contiene el nivel de preocupación de escritura para la operación de creación. El nivel de preocupación de escritura se puede determinar mediante el campo opcional, writeConcern .
createUser devolverá un error de usuario duplicado si el usuario ya existe en la base de datos.
Puede crear un nuevo usuario en la base de datos de prueba de la siguiente manera:
use test db.createUser( { user: "user26", pwd: "myuser123", roles: [ "readWrite" ] } );La salida es la siguiente:
Successfully added user: { "user" : "user26", "roles" : [ "readWrite", "dbAdmin" ] }grantRolesToUser
Puede aprovechar este comando para otorgar funciones adicionales a un usuario. Para usarlo, debe tener en cuenta la siguiente sintaxis:
db.runCommand( { grantRolesToUser: "<user>", roles: [ <roles> ], writeConcern: { <write concern> }, comment: <any> } ) Puede especificar roles integrados y definidos por el usuario en los roles mencionados anteriormente. Si desea especificar un rol que existe en la misma base de datos donde se ejecuta grantRolesToUser , puede especificar el rol con un documento, como se menciona a continuación:
{ role: "<role>", db: "<database>" }O simplemente puede especificar el rol con el nombre del rol. Por ejemplo:
"readWrite"Si desea especificar el rol que está presente en una base de datos diferente, deberá especificar el rol con un documento diferente.
Para otorgar un rol en una base de datos, necesita la acción grantRole en la base de datos especificada.
Aquí hay un ejemplo para darle una imagen clara. Tomemos, por ejemplo, un usuario productUser00 en la base de datos de productos con los siguientes roles:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" } ] La operación grantRolesToUser proporciona a " readWrite " el rol de lectura y escritura en la base de datos de existencias y el rol de lectura en la base de datos de productos:
use products db.runCommand({ grantRolesToUser: "productUser00", roles: [ { role: "readWrite", db: "stock"}, "read" ], writeConcern: { w: "majority" , wtimeout: 2000 } })El usuario productUser00 en la base de datos de productos ahora posee los siguientes roles:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ]UserInfo
Puede usar el comando usersInfo para devolver información sobre uno o más usuarios. Aquí está la sintaxis:
db.runCommand( { usersInfo: <various>, showCredentials: <Boolean>, showCustomData: <Boolean>, showPrivileges: <Boolean>, showAuthenticationRestrictions: <Boolean>, filter: <document>, comment: <any> } ) { usersInfo: <various> } En términos de acceso, los usuarios siempre pueden consultar su propia información. Para ver la información de otro usuario, el usuario que ejecuta el comando debe tener privilegios que incluyan la acción viewUser en la base de datos del otro usuario.
Al ejecutar el comando userInfo , puede obtener la siguiente información según las opciones especificadas:
{ "users" : [ { "_id" : "<db>.<username>", "userId" : <UUID>, // Starting in MongoDB 4.0.9 "user" : "<username>", "db" : "<db>", "mechanisms" : [ ... ], // Starting in MongoDB 4.0 "customData" : <document>, "roles" : [ ... ], "credentials": { ... }, // only if showCredentials: true "inheritedRoles" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedPrivileges" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedAuthenticationRestrictions" : [ ] // only if showPrivileges: true or showAuthenticationRestrictions: true "authenticationRestrictions" : [ ... ] // only if showAuthenticationRestrictions: true }, ], "ok" : 1 } Ahora que tiene una idea general de lo que puede lograr con el comando usersInfo , la siguiente pregunta obvia que podría surgir es, ¿qué comandos serían útiles para observar usuarios específicos y múltiples usuarios?
Aquí hay dos ejemplos prácticos para ilustrar lo mismo:
Para ver los privilegios e información específicos para usuarios específicos, pero no las credenciales, para un usuario "Anthony" definido en la base de datos "oficina", ejecute el siguiente comando:
db.runCommand( { usersInfo: { user: "Anthony", db: "office" }, showPrivileges: true } )Si desea ver a un usuario en la base de datos actual, solo puede mencionar al usuario por su nombre. Por ejemplo, si está en la base de datos de inicio y existe un usuario llamado "Timothy" en la base de datos de inicio, puede ejecutar el siguiente comando:
db.getSiblingDB("home").runCommand( { usersInfo: "Timothy", showPrivileges: true } ) A continuación, puede usar una matriz si desea ver la información de varios usuarios. Puede incluir los campos opcionales showCredentials y showPrivileges , o puede optar por omitirlos. Así es como se vería el comando:
db.runCommand({ usersInfo: [ { user: "Anthony", db: "office" }, { user: "Timothy", db: "home" } ], showPrivileges: true })revocarRolesFromUser
Puede aprovechar el comando revokeRolesFromUser para eliminar uno o más roles de un usuario en la base de datos donde están presentes los roles. El comando revokeRolesFromUser tiene la siguiente sintaxis:
db.runCommand( { revokeRolesFromUser: "<user>", roles: [ { role: "<role>", db: "<database>" } | "<role>", ], writeConcern: { <write concern> }, comment: <any> } ) En la sintaxis mencionada anteriormente, puede especificar roles integrados y definidos por el usuario en el campo de roles . De forma similar al comando grantRolesToUser , puede especificar la función que desea revocar en un documento o usar su nombre.
Para ejecutar con éxito el comando revokeRolesFromUser , debe tener la acción revokeRole en la base de datos especificada.
Aquí hay un ejemplo para llevar el punto a casa. La entidad productUser00 en la base de datos de productos tenía los siguientes roles:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ] El siguiente comando revokeRolesFromUser eliminará dos de los roles del usuario: el rol de "lectura" de los products y el rol de assetsWriter de la base de datos de "activos":
use products db.runCommand( { revokeRolesFromUser: "productUser00", roles: [ { role: "AssetsWriter", db: "assets" }, "read" ], writeConcern: { w: "majority" } } )El usuario "productUser00" en la base de datos de productos ahora solo tiene un rol restante:

"roles" : [ { "role" : "readWrite", "db" : "stock" } ]Comandos de gestión de funciones
Los roles otorgan a los usuarios acceso a los recursos. Los administradores pueden utilizar varias funciones integradas para controlar el acceso a un sistema MongoDB. Si los roles no cubren los privilegios deseados, incluso puede ir más allá y crear nuevos roles en una base de datos en particular.
dropRole
Con el comando dropRole , puede eliminar un rol definido por el usuario de la base de datos en la que ejecuta el comando. Para ejecutar este comando, utilice la siguiente sintaxis:
db.runCommand( { dropRole: "<role>", writeConcern: { <write concern> }, comment: <any> } ) Para una ejecución exitosa, debe tener la acción dropRole en la base de datos especificada. Las siguientes operaciones eliminarían el rol writeTags de la base de datos de "productos":
use products db.runCommand( { dropRole: "writeTags", writeConcern: { w: "majority" } } )crear Rol
Puede aprovechar el comando createRole para crear un rol y especificar sus privilegios. El rol se aplicará a la base de datos en la que elija ejecutar el comando. El comando createRole devolvería un error de rol duplicado si el rol ya existe en la base de datos.
Para ejecutar este comando, siga la sintaxis dada:
db.adminCommand( { createRole: "<new role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], roles: [ { role: "<role>", db: "<database>" } | "<role>", ], authenticationRestrictions: [ { clientSource: ["<IP>" | "<CIDR range>", ...], serverAddress: ["<IP>" | "<CIDR range>", ...] }, ], writeConcern: <write concern document>, comment: <any> } )Los privilegios de un rol se aplicarían a la base de datos donde se creó el rol. El rol puede heredar privilegios de otros roles en su base de datos. Por ejemplo, un rol creado en la base de datos "admin" puede incluir privilegios que se aplican a un clúster o a todas las bases de datos. También puede heredar privilegios de roles presentes en otras bases de datos.
Para crear un rol en una base de datos, debe tener dos cosas:
- La acción
grantRoleen esa base de datos para mencionar privilegios para el nuevo rol, así como para mencionar roles de los que heredar. - La acción
createRoleen ese recurso de base de datos.
El siguiente comando createRole creará un rol clusterAdmin en la base de datos del usuario:
db.adminCommand({ createRole: "clusterAdmin", privileges: [ { resource: { cluster: true }, actions: [ "addShard" ] }, { resource: { db: "config", collection: "" }, actions: [ "find", "remove" ] }, { resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert" ] }, { resource: { db: "", collection: "" }, actions: [ "find" ] } ], roles: [ { role: "read", db: "user" } ], writeConcern: { w: "majority" , wtimeout: 5000 } })grantRolesToRole
Con el comando grantRolesToRole , puede otorgar roles a un rol definido por el usuario. El comando grantRolesToRole afectaría los roles en la base de datos donde se ejecuta el comando.
Este comando grantRolesToRole tiene la siguiente sintaxis:
db.runCommand( { grantRolesToRole: "<role>", roles: [ { role: "<role>", db: "<database>" }, ], writeConcern: { <write concern> }, comment: <any> } ) Los privilegios de acceso son similares al comando grantRolesToUser : necesita una acción grantRole en una base de datos para la correcta ejecución del comando.
En el siguiente ejemplo, puede utilizar el comando grantRolesToUser para actualizar la función de lector de productsReader en la base de datos de "productos" para heredar los privilegios de la función de escritor de productsWriter :
use products db.runCommand( { grantRolesToRole: "productsReader", roles: [ "productsWriter" ], writeConcern: { w: "majority" , wtimeout: 5000 } } )revocar privilegios de rol
Puede usar revokePrivilegesFromRole para eliminar los privilegios especificados del rol definido por el usuario en la base de datos donde se ejecuta el comando. Para una ejecución adecuada, debe tener en cuenta la siguiente sintaxis:
db.runCommand( { revokePrivilegesFromRole: "<role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], writeConcern: <write concern document>, comment: <any> } )Para revocar un privilegio, el patrón de "documento de recurso" debe coincidir con el campo de "recurso" de ese privilegio. El campo "acciones" puede ser una coincidencia exacta o un subconjunto.
Por ejemplo, considere el rol manageRole en la base de datos de productos con los siguientes privilegios que especifican la base de datos de "administradores" como el recurso:
{ "resource" : { "db" : "managers", "collection" : "" }, "actions" : [ "insert", "remove" ] }No puede revocar las acciones de "insertar" o "eliminar" de una sola colección en la base de datos de administradores. Las siguientes operaciones no provocan ningún cambio en el rol:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert", "remove" ] } ] } ) db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert" ] } ] } ) Para revocar las acciones "insertar" y/o "eliminar" del rol manageRole , debe hacer coincidir exactamente el documento de recursos. Por ejemplo, la siguiente operación revoca solo la acción "eliminar" del privilegio existente:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "" }, actions : [ "remove" ] } ] } )La siguiente operación eliminará varios privilegios del rol "ejecutivo" en la base de datos de administradores:
use managers db.runCommand( { revokePrivilegesFromRole: "executive", privileges: [ { resource: { db: "managers", collection: "" }, actions: [ "insert", "remove", "find" ] }, { resource: { db: "managers", collection: "partners" }, actions: [ "update" ] } ], writeConcern: { w: "majority" } } )rolesInfo
El comando rolesInfo devolverá información de privilegios y herencia para roles específicos, incluidos los roles integrados y definidos por el usuario. También puede aprovechar el comando rolesInfo para recuperar todos los roles en el ámbito de una base de datos.
Para una ejecución adecuada, siga esta sintaxis:
db.runCommand( { rolesInfo: { role: <name>, db: <db> }, showPrivileges: <Boolean>, showBuiltinRoles: <Boolean>, comment: <any> } )Para devolver información para un rol de la base de datos actual, puede especificar su nombre de la siguiente manera:
{ rolesInfo: "<rolename>" }Para devolver información para un rol desde otra base de datos, puede mencionar el rol con un documento que mencione el rol y la base de datos:
{ rolesInfo: { role: "<rolename>", db: "<database>" } }Por ejemplo, el siguiente comando devuelve la información de herencia de roles para el rol ejecutivo definido en la base de datos de administradores:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" } } ) Este siguiente comando devolverá la información de herencia de roles: accountManager en la base de datos en la que se ejecuta el comando:
db.runCommand( { rolesInfo: "accountManager" } )El siguiente comando devolverá tanto los privilegios como la herencia de roles para el rol "ejecutivo" como se define en la base de datos de administradores:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" }, showPrivileges: true } )Para mencionar varios roles, puede usar una matriz. También puede mencionar cada rol en la matriz como una cadena o documento.
Debe usar una cadena solo si el rol existe en la base de datos en la que se ejecuta el comando:
{ rolesInfo: [ "<rolename>", { role: "<rolename>", db: "<database>" }, ] }Por ejemplo, el siguiente comando devolverá información para tres roles en tres bases de datos diferentes:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ] } )Puede obtener tanto los privilegios como la herencia de roles de la siguiente manera:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ], showPrivileges: true } )Incorporación de documentos de MongoDB para un mejor rendimiento
Las bases de datos de documentos como MongoDB le permiten definir su esquema de acuerdo con sus necesidades. Para crear esquemas óptimos en MongoDB, puede anidar los documentos. Entonces, en lugar de hacer coincidir su aplicación con un modelo de datos, puede crear un modelo de datos que coincida con su caso de uso.
Los documentos incrustados le permiten almacenar datos relacionados a los que acceden juntos. Al diseñar esquemas para MongoDB, se recomienda incrustar documentos de forma predeterminada. Use uniones y referencias del lado de la base de datos o del lado de la aplicación solo cuando valgan la pena.
Asegúrese de que la carga de trabajo pueda recuperar un documento con la frecuencia necesaria. Al mismo tiempo, el documento también debe tener todos los datos que necesita. Esto es fundamental para el rendimiento excepcional de su aplicación.
A continuación, encontrará algunos patrones diferentes para incrustar documentos:
Patrón de documento incrustado
Puede usar esto para incrustar incluso subestructuras complicadas en los documentos con los que se usan. Incrustar datos conectados en un solo documento puede disminuir la cantidad de operaciones de lectura necesarias para obtener datos. En general, debe estructurar su esquema para que su aplicación reciba toda la información requerida en una sola operación de lectura. Por lo tanto, la regla a tener en cuenta aquí es que lo que se usa en conjunto debe almacenarse en conjunto .
Patrón de subconjunto incrustado
El patrón de subconjunto incrustado es un caso híbrido. Lo usaría para una colección separada de una larga lista de elementos relacionados, donde puede tener algunos de esos elementos a mano para mostrarlos.
Aquí hay un ejemplo que enumera reseñas de películas:
> db.movie.findOne() { _id: 321475, title: "The Dark Knight" } > db.review.find({movie_id: 321475}) { _id: 264579, movie_id: 321475, stars: 4 text: "Amazing" } { _id: 375684, movie_id: 321475, stars:5, text: "Mindblowing" }Ahora, imagina miles de reseñas similares, pero solo planeas mostrar las dos más recientes cuando muestres una película. En este escenario, tiene sentido almacenar ese subconjunto como una lista dentro del documento de la película:
> db.movie.findOne({_id: 321475}) { _id: 321475, title: "The Dark Knight", recent_reviews: [ {_id: 264579, stars: 4, text: "Amazing"}, {_id: 375684, stars: 5, text: "Mindblowing"} ] }</codeEn pocas palabras, si accede habitualmente a un subconjunto de elementos relacionados, asegúrese de insertarlo.
Acceso Independiente
Es posible que desee almacenar subdocumentos en su colección para separarlos de su colección principal.
Por ejemplo, tome la línea de productos de una empresa. Si la empresa vende un pequeño conjunto de productos, es posible que desee almacenarlos en el documento de la empresa. Pero si desea reutilizarlos en todas las empresas o acceder a ellos directamente por su unidad de mantenimiento de existencias (SKU), también querrá almacenarlos en su colección.
Si manipula o accede a una entidad de forma independiente, cree una colección para almacenarla por separado como práctica recomendada.
Listas ilimitadas
El almacenamiento de listas cortas de información relacionada en su documento tiene un inconveniente. Si su lista continúa creciendo sin control, no debería ponerla en un solo documento. Esto se debe a que no podría soportarlo por mucho tiempo.
Hay dos razones para esto. Primero, MongoDB tiene un límite en el tamaño de un solo documento. En segundo lugar, si accede al documento con demasiada frecuencia, verá resultados negativos debido al uso descontrolado de la memoria.
En pocas palabras, si una lista comienza a crecer sin límites, haga una colección para almacenarla por separado.
Patrón de referencia extendido
El patrón de referencia extendido es como el patrón de subconjunto. It also optimizes information that you regularly access to store on the document.
Here, instead of a list, it's leveraged when a document refers to another that is present in the same collection. At the same time, it also stores some fields from that other document for ready access.
Por ejemplo:
> db.movie.findOne({_id: 245434}) { _id: 245434, title: "Mission Impossible 4 - Ghost Protocol", studio_id: 924935, studio_name: "Paramount Pictures" }As you can see, “the studio_id” is stored so that you can look up more information on the studio that created the film. But the studio's name is also copied to this document for simplicity.
To embed information from modified documents regularly, remember to update documents where you've copied that information when it is modified. In other words, if you routinely access some fields from a referenced document, embed them.
How To Monitor MongoDB
You can use monitoring tools like Kinsta APM to debug long API calls, slow database queries, long external URL requests, to name a few. You can even leverage commands to improve database performance. You can also use them to inspect the ase/” data-mce-href=”https://kinsta.com/knowledgebase/wordpress-repair-database/”>health of your database instances.
Why Should You Monitor MongoDB Databases?
A key aspect of database administration planning is monitoring your cluster's performance and health. MongoDB Atlas handles the majority of administration efforts through its fault-tolerance/scaling abilities.
Despite that, users need to know how to track clusters. They should also know how to scale or tweak whatever they need before hitting a crisis.
By monitoring MongoDB databases, you can:
- Observe the utilization of resources.
- Understand the current capacity of your database.
- React and detect real-time issues to enhance your application stack.
- Observe the presence of performance issues and abnormal behavior.
- Align with your governance/data protection and service-level agreement (SLA) requirements.
Key Metrics To Monitor
While monitoring MongoDB, there are four key aspects you need to keep in mind:
1. MongoDB Hardware Metrics
Here are the primary metrics for monitoring hardware:
Normalized Process CPU
It's defined as the percentage of time spent by the CPU on application software maintaining the MongoDB process.
You can scale this to a range of 0-100% by dividing it by the number of CPU cores. It includes CPU leveraged by modules such as kernel and user.
High kernel CPU might show exhaustion of CPU via the operating system operations. But the user linked with MongoDB operations might be the root cause of CPU exhaustion.
Normalized System CPU
It's the percentage of time the CPU spent on system calls servicing this MongoDB process. You can scale it to a range of 0-100% by dividing it by the number of CPU cores. It also covers the CPU used by modules such as iowait, user, kernel, steal, etc.
User CPU or high kernel might show CPU exhaustion through MongoDB operations (software). High iowait might be linked to storage exhaustion causing CPU exhaustion.
Disk IOPS
Disk IOPS is the average consumed IO operations per second on MongoDB's disk partition.
Disk Latency
This is the disk partition's read and write disk latency in milliseconds in MongoDB. High values (>500ms) show that the storage layer might affect MongoDB's performance.
System Memory
Use the system memory to describe physical memory bytes used versus available free space.
The available metric approximates the number of bytes of system memory available. You can use this to execute new applications, without swapping.
Disk Space Free
This is defined as the total bytes of free disk space on MongoDB's disk partition. MongoDB Atlas provides auto-scaling capabilities based on this metric.
Swap Usage
You can leverage a swap usage graph to describe how much memory is being placed on the swap device. A high used metric in this graph shows that swap is being utilized. This shows that the memory is under-provisioned for the current workload.
MongoDB Cluster's Connection and Operation Metrics
Here are the main metrics for Operation and Connection Metrics:
Operation Execution Times
The average operation time (write and read operations) performed over the selected sample period.
Opcounters
It is the average rate of operations executed per second over the selected sample period. Opcounters graph/metric shows the operations breakdown of operation types and velocity for the instance.
Connections
This metric refers to the number of open connections to the instance. High spikes or numbers might point to a suboptimal connection strategy either from the unresponsive server or the client side.
Query Targeting and Query Executors
This is the average rate per second over the selected sample period of scanned documents. For query executors, this is during query-plan evaluation and queries. Query targeting shows the ratio between the number of documents scanned and the number of documents returned.
Una relación numérica alta apunta a operaciones subóptimas. Estas operaciones escanean muchos documentos para devolver una parte más pequeña.
Escanea y Ordena
Describe la tasa promedio por segundo durante el período de muestra elegido de consultas. Devuelve resultados ordenados que no pueden ejecutar la operación de ordenación mediante un índice.
Colas
Las colas pueden describir la cantidad de operaciones que esperan un bloqueo, ya sea de escritura o de lectura. Las colas altas pueden representar la existencia de un diseño de esquema menos que óptimo. También podría indicar rutas de escritura en conflicto, lo que impulsaría una gran competencia por los recursos de la base de datos.
Métricas de replicación de MongoDB
Estas son las métricas principales para el monitoreo de la replicación:
Ventana Oplog de replicación
Esta métrica enumera el número aproximado de horas disponibles en el registro de operaciones de replicación principal. Si un secundario se retrasa más de esta cantidad, no puede seguir el ritmo y necesitará una resincronización completa.
Retraso de replicación
El retraso de la replicación se define como el número aproximado de segundos que un nodo secundario está detrás del principal en las operaciones de escritura. Un alto retraso en la replicación apuntaría a una secundaria que enfrenta dificultades para replicarse. Podría afectar la latencia de su operación, dada la preocupación de lectura/escritura de las conexiones.
Espacio libre de replicación
Esta métrica hace referencia a la diferencia entre la ventana de registro de operaciones de la replicación principal y el retraso de replicación de la secundaria. Si este valor llega a cero, podría causar que un secundario entre en modo RECUPERACIÓN.
Contadores de oportunidades -reemplazo
Opcounters -repl se define como la tasa promedio de operaciones de replicación ejecutadas por segundo durante el período de muestra elegido. Con opcounters -graph/metric, puede echar un vistazo a la velocidad de las operaciones y el desglose de los tipos de operaciones para la instancia especificada.
Oplog GB/Hora
Esto se define como la tasa promedio de gigabytes de oplog que genera el principal por hora. Los altos volúmenes inesperados de oplog pueden indicar una carga de trabajo de escritura muy insuficiente o un problema de diseño del esquema.
Herramientas de monitoreo de rendimiento de MongoDB
MongoDB tiene herramientas de interfaz de usuario integradas en Cloud Manager, Atlas y Ops Manager para el seguimiento del rendimiento. También proporciona algunos comandos y herramientas independientes para ver más datos sin procesar. Hablaremos sobre algunas herramientas que puede ejecutar desde un host que tiene acceso y roles apropiados para verificar su entorno:
mongotop
Puede aprovechar este comando para realizar un seguimiento de la cantidad de tiempo que una instancia de MongoDB dedica a escribir y leer datos por colección. Utilice la siguiente sintaxis:
mongotop <options> <connection-string> <polling-interval in seconds>rs.estado()
Este comando devuelve el estado del conjunto de réplicas. Se ejecuta desde el punto de vista del miembro donde se ejecuta el método.
mongostato
Puede usar el comando mongostat para obtener una descripción general rápida del estado de su instancia del servidor MongoDB. Para un resultado óptimo, puede usarlo para ver una sola instancia de un evento específico, ya que ofrece una vista en tiempo real.
Aproveche este comando para monitorear estadísticas básicas del servidor, como colas de bloqueo, desglose de operaciones, estadísticas de memoria MongoDB y conexiones/red:
mongostat <options> <connection-string> <polling interval in seconds>Estadísticas de base de datos
Este comando devuelve estadísticas de almacenamiento para una base de datos específica, como la cantidad de índices y su tamaño, los datos totales de la colección frente al tamaño del almacenamiento y las estadísticas relacionadas con la colección (cantidad de colecciones y documentos).
db.estadodelservidor()
Puede aprovechar el db.serverStatus() para tener una visión general del estado de la base de datos. Le proporciona un documento que representa los contadores de métricas de la instancia actual. Ejecute este comando a intervalos regulares para recopilar estadísticas sobre la instancia.
collStats
El comando collStats recopila estadísticas similares a las que ofrece dbStats en el nivel de recopilación. Su salida consiste en un recuento de objetos en la colección, la cantidad de espacio en disco consumido por la colección, el tamaño de la colección e información sobre sus índices para una colección determinada.
Puede usar todos estos comandos para ofrecer informes y monitoreo en tiempo real del servidor de la base de datos que le permite monitorear el rendimiento y los errores de la base de datos y ayudar en la toma de decisiones informadas para refinar una base de datos.
Cómo eliminar una base de datos MongoDB
Para eliminar una base de datos que creó en MongoDB, debe conectarse a ella mediante la palabra clave use.
Digamos que creó una base de datos llamada "Ingenieros". Para conectarse a la base de datos, utilizará el siguiente comando:
use Engineers A continuación, escriba db.dropDatabase() para deshacerse de esta base de datos. Después de la ejecución, este es el resultado que puede esperar:
{ "dropped" : "Engineers", "ok" : 1 } Puede ejecutar el comando showdbs para verificar si la base de datos aún existe.
Resumen
Para exprimir hasta la última gota de valor de MongoDB, debe tener una sólida comprensión de los fundamentos. Por lo tanto, es fundamental conocer las bases de datos de MongoDB como la palma de su mano. Esto requiere familiarizarse primero con los métodos para crear una base de datos.
En este artículo, arrojamos luz sobre los diferentes métodos que puede usar para crear una base de datos en MongoDB, seguido de una descripción detallada de algunos comandos ingeniosos de MongoDB para mantenerlo al tanto de sus bases de datos. Finalmente, redondeamos la discusión analizando cómo puede aprovechar los documentos integrados y las herramientas de monitoreo de rendimiento en MongoDB para garantizar que su flujo de trabajo funcione con la máxima eficiencia.
¿Cuál es su opinión sobre estos comandos de MongoDB? ¿Nos perdimos algún aspecto o método que le hubiera gustado ver aquí? ¡Cuéntanos en los comentarios!