
Cree un conjunto robusto de réplicas de MongoDB en un tiempo récord (4 métodos)
Publicado: 2023-03-11MongoDB es una base de datos NoSQL que utiliza documentos similares a JSON con esquemas dinámicos. Cuando se trabaja con bases de datos, siempre es bueno tener un plan de contingencia en caso de que falle uno de los servidores de la base de datos. Sidebar, puede reducir las posibilidades de que eso suceda aprovechando una ingeniosa herramienta de administración para su sitio de WordPress.
Por eso es útil tener muchas copias de sus datos. También reduce las latencias de lectura. Al mismo tiempo, puede mejorar la escalabilidad y disponibilidad de la base de datos. Aquí es donde entra en juego la replicación. Se define como la práctica de sincronizar datos en múltiples bases de datos.
En este artículo, nos sumergiremos en los diversos aspectos destacados de la replicación de MongoDB, como sus características y mecanismo, por nombrar algunos.
¿Qué es la replicación en MongoDB?
En MongoDB, los conjuntos de réplicas realizan la replicación. Este es un grupo de servidores que mantienen el mismo conjunto de datos a través de la replicación. Incluso puede usar la replicación de MongoDB como parte del equilibrio de carga. Aquí, puede distribuir las operaciones de escritura y lectura en todas las instancias, según el caso de uso.
¿Qué es un conjunto de réplicas de MongoDB?
Cada instancia de MongoDB que forma parte de un conjunto de réplicas determinado es un miembro. Cada conjunto de réplicas debe tener un miembro principal y al menos un miembro secundario.
El miembro principal es el punto de acceso principal para las transacciones con el conjunto de réplicas. También es el único miembro que puede aceptar operaciones de escritura. La replicación primero copia el registro de operaciones principal (registro de operaciones). A continuación, repite los cambios registrados en los conjuntos de datos respectivos de los secundarios. Por lo tanto, cada conjunto de réplicas solo puede tener un miembro principal a la vez. Varios primarios que reciben operaciones de escritura pueden causar conflictos de datos.
Por lo general, las aplicaciones solo consultan al miembro principal para operaciones de escritura y lectura. Puede diseñar su configuración para leer de uno o más de los miembros secundarios. La transferencia de datos asíncrona puede hacer que las lecturas de los nodos secundarios sirvan datos antiguos. Por lo tanto, dicho arreglo no es ideal para todos los casos de uso.
Características del conjunto de réplicas
El mecanismo automático de conmutación por error diferencia a los conjuntos de réplicas de MongoDB de su competencia. En ausencia de un primario, una elección automatizada entre los nodos secundarios elige un nuevo primario.
Conjunto de réplicas de MongoDB frente a clúster de MongoDB
Un conjunto de réplicas de MongoDB creará varias copias del mismo conjunto de datos en los nodos del conjunto de réplicas. El objetivo principal de un conjunto de réplicas es:
- Ofrezca una solución de copia de seguridad integrada
- Aumente la disponibilidad de datos
Un clúster de MongoDB es un juego de pelota completamente diferente. Distribuye los datos a través de muchos nodos a través de una clave de fragmento. Este proceso fragmentará los datos en muchas piezas llamadas fragmentos. A continuación, copia cada fragmento en un nodo diferente. Un clúster tiene como objetivo admitir grandes conjuntos de datos y operaciones de alto rendimiento. Lo logra escalando horizontalmente la carga de trabajo.
Esta es la diferencia entre un conjunto de réplicas y un clúster, en términos sencillos:
- Un clúster distribuye la carga de trabajo. También almacena fragmentos de datos (fragmentos) en muchos servidores.
- Un conjunto de réplicas duplica el conjunto de datos por completo.
MongoDB le permite combinar estas funcionalidades creando un clúster fragmentado. Aquí, puede replicar cada fragmento en un servidor secundario. Esto permite que un fragmento ofrezca alta redundancia y disponibilidad de datos.
El mantenimiento y la configuración de un conjunto de réplicas pueden ser técnicamente exigentes y llevar mucho tiempo. ¿Y encontrar el servicio de hosting adecuado? Ese es otro dolor de cabeza. Con tantas opciones disponibles, es fácil perder horas investigando, en lugar de construir su negocio.
Permíteme darte un resumen sobre una herramienta que hace todo esto y mucho más para que puedas volver a aplastarlo con tu servicio/producto.
La solución de hospedaje de aplicaciones de Kinsta, en la que confían más de 55 000 desarrolladores, puede comenzar a utilizarla en solo 3 simples pasos. Si eso suena demasiado bueno para ser verdad, aquí hay algunos beneficios más de usar Kinsta:
- Disfrute de un mejor rendimiento con las conexiones internas de Kinsta : Olvídese de sus problemas con las bases de datos compartidas. Cambie a bases de datos dedicadas con conexiones internas que no tengan límite de número de consultas ni de número de filas. Kinsta es más rápido, más seguro y no le cobrará por el ancho de banda/tráfico interno.
- Un conjunto de funciones diseñado para desarrolladores : Escale su aplicación en la sólida plataforma compatible con Gmail, YouTube y la Búsqueda de Google. Tenga la seguridad de que está en las manos más seguras aquí.
- Disfrute de velocidades incomparables con un centro de datos de su elección : elija la región que funcione mejor para usted y sus clientes. Con más de 25 centros de datos para elegir, los más de 275 PoP de Kinsta garantizan la máxima velocidad y una presencia global para su sitio web.
¡Pruebe la solución de hospedaje de aplicaciones de Kinsta gratis hoy!
¿Cómo funciona la replicación en MongoDB?
En MongoDB, envía operaciones de escritura al servidor principal (nodo). El primario asigna las operaciones a través de servidores secundarios, replicando los datos.
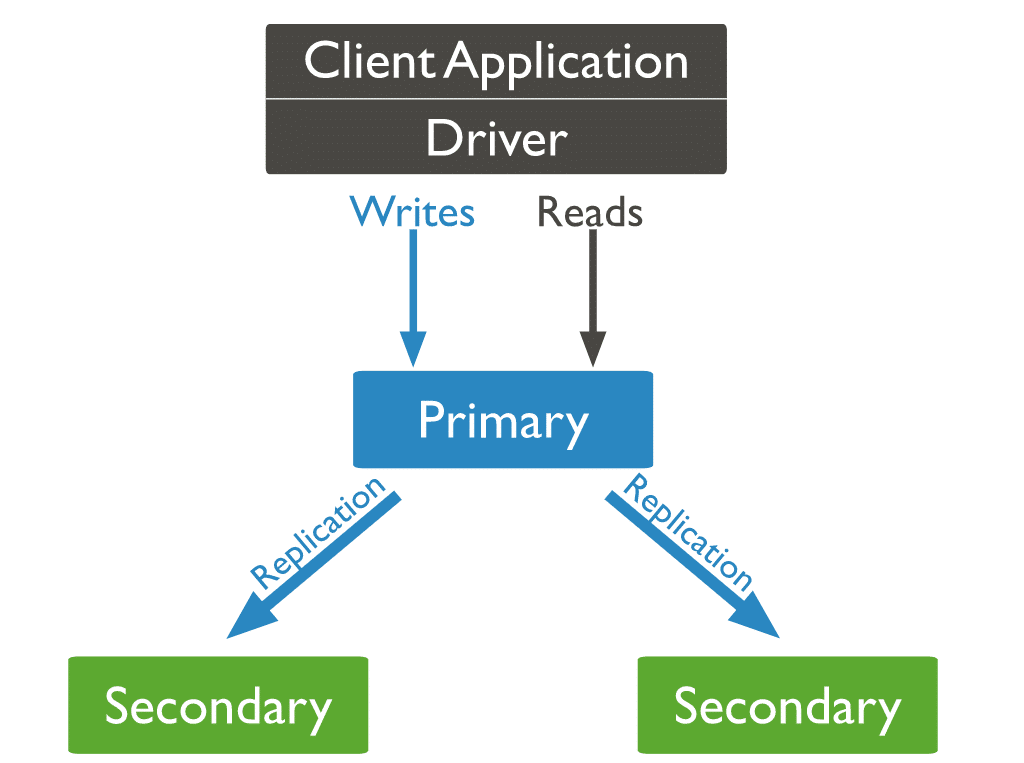
Tres tipos de nodos MongoDB
De los tres tipos de nodos de MongoDB, dos han surgido antes: nodos primarios y secundarios. El tercer tipo de nodo MongoDB que resulta útil durante la replicación es un árbitro. El nodo árbitro no tiene una copia del conjunto de datos y no puede convertirse en principal. Habiendo dicho eso, el árbitro sí participa en las elecciones para las primarias.
Anteriormente mencionamos lo que sucede cuando el nodo principal deja de funcionar, pero ¿qué pasa si los nodos secundarios muerden el polvo? En ese escenario, el nodo principal se vuelve secundario y la base de datos se vuelve inaccesible.
Elección de miembros
Las elecciones pueden ocurrir en los siguientes escenarios:
- Inicializar un conjunto de réplicas
- Pérdida de conectividad con el nodo principal (que se puede detectar mediante latidos)
- Mantenimiento de un conjunto de réplicas mediante métodos
rs.reconfigostepDown - Adición de un nuevo nodo a un conjunto de réplicas existente
Un conjunto de réplicas puede tener hasta 50 miembros, pero solo 7 o menos pueden votar en cualquier elección.
El tiempo promedio antes de que un clúster elija una nueva primaria no debe exceder los 12 segundos. El algoritmo de elección intentará tener disponible el secundario de mayor prioridad. Al mismo tiempo, los miembros con un valor de prioridad de 0 no pueden convertirse en primarias y no participar en la elección.
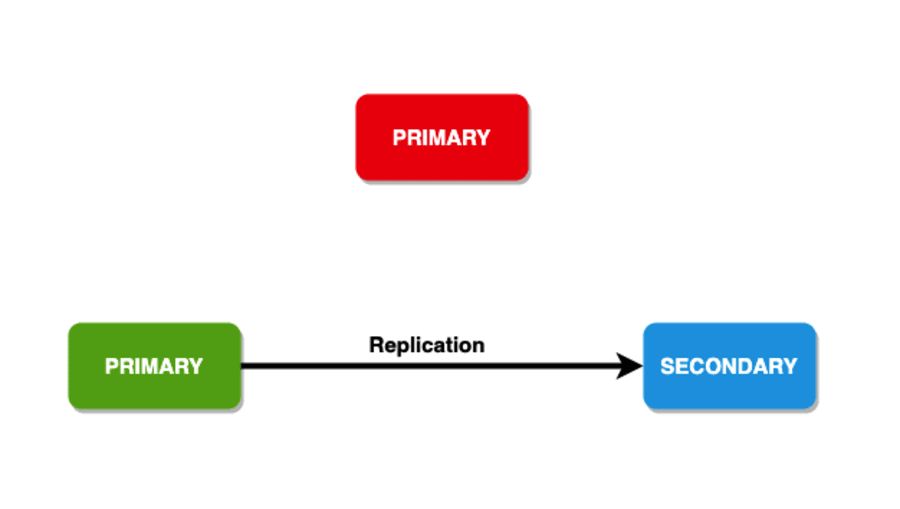
La preocupación por escribir
Para mayor durabilidad, las operaciones de escritura tienen un marco para copiar los datos en un número específico de nodos. Incluso puede ofrecer comentarios al cliente con esto. Este marco también se conoce como "preocupación de escritura". Tiene miembros portadores de datos que deben reconocer un problema de escritura antes de que la operación vuelva a ser exitosa. Generalmente, los conjuntos de réplicas tienen un valor de 1 como problema de escritura. Por lo tanto, solo el primario debe reconocer la escritura antes de devolver el reconocimiento de preocupación de escritura.
Incluso puede aumentar la cantidad de miembros necesarios para reconocer la operación de escritura. No hay límite para el número de miembros que puede tener. Pero, si los números son altos, debe lidiar con una latencia alta. Esto se debe a que el cliente debe esperar el reconocimiento de todos los miembros. Además, puede establecer la preocupación de escritura de la "mayoría". Esto calcula más de la mitad de los miembros después de recibir su reconocimiento.
Preferencia de lectura
Para las operaciones de lectura, puede mencionar la preferencia de lectura que describe cómo la base de datos dirige la consulta a los miembros del conjunto de réplicas. Generalmente, el nodo principal recibe la operación de lectura, pero el cliente puede mencionar una preferencia de lectura para enviar las operaciones de lectura a los nodos secundarios. Estas son las opciones para la preferencia de lectura:
- PrimaryPreferred : por lo general, las operaciones de lectura provienen del nodo principal, pero si no está disponible, los datos se extraen de los nodos secundarios.
- primario : todas las operaciones de lectura provienen del nodo primario.
- secundario : Todas las operaciones de lectura son ejecutadas por los nodos secundarios.
- más cercano : aquí, las solicitudes de lectura se enrutan al nodo accesible más cercano, que se puede detectar ejecutando el comando
ping. El resultado de las operaciones de lectura puede provenir de cualquier miembro del conjunto de réplicas, independientemente de si es el principal o el secundario. - secondPreferred : aquí, la mayoría de las operaciones de lectura provienen de los nodos secundarios, pero si ninguno de ellos está disponible, los datos se toman del nodo principal.
Sincronización de datos del conjunto de replicación
Para mantener copias actualizadas del conjunto de datos compartidos, los miembros secundarios de un conjunto de réplicas replican o sincronizan datos de otros miembros.
MongoDB aprovecha dos formas de sincronización de datos. Sincronización inicial para completar nuevos miembros con el conjunto de datos completo. Replicación para ejecutar cambios continuos en el conjunto de datos completo.
Sincronización inicial
Durante la sincronización inicial, un nodo secundario ejecuta el comando init sync para sincronizar todos los datos del nodo principal con otro nodo secundario que contiene los datos más recientes. Por lo tanto, el nodo secundario aprovecha constantemente la función tailable cursor para consultar las últimas entradas de oplog dentro de la colección local.oplog.rs del nodo principal y aplica estas operaciones dentro de estas entradas de oplog.
A partir de MongoDB 5.2, las sincronizaciones iniciales pueden basarse en copias de archivos o ser lógicas.
sincronización lógica
Cuando ejecuta una sincronización lógica, MongoDB:
- Elabora todos los índices de colección a medida que se copian los documentos de cada colección.
- Duplica todas las bases de datos excepto la base de datos local.
mongodescanea cada colección en todas las bases de datos de origen e inserta todos los datos en sus duplicados de estas colecciones. - Ejecuta todos los cambios en el conjunto de datos. Al aprovechar el registro de operaciones de la fuente,
mongodactualiza su conjunto de datos para representar el estado actual del conjunto de réplicas. - Extrae registros de oplog recién agregados durante la copia de datos. Asegúrese de que el miembro de destino tenga suficiente espacio en disco dentro de la base de datos local para almacenar tentativamente estos registros de operación durante la duración de esta etapa de copia de datos.
Cuando se completa la sincronización inicial, el miembro pasa de STARTUP2 a SECONDARY .
Sincronización inicial basada en copia de archivos
Desde el principio, solo puede ejecutar esto si usa MongoDB Enterprise. Este proceso ejecuta la sincronización inicial al duplicar y mover los archivos en el sistema de archivos. Este método de sincronización puede ser más rápido que la sincronización inicial lógica en algunos casos. Tenga en cuenta que la sincronización inicial basada en la copia de archivos puede generar recuentos inexactos si ejecuta el método count() sin un predicado de consulta.
Pero, este método también tiene una buena cantidad de limitaciones:
- Durante una sincronización inicial basada en copia de archivos, no puede escribir en la base de datos local del miembro que se está sincronizando. Tampoco puede ejecutar una copia de seguridad en el miembro que se está sincronizando o el miembro desde el que se está sincronizando.
- Al aprovechar el motor de almacenamiento cifrado, MongoDB utiliza la clave de origen para cifrar el destino.
- Solo puede ejecutar una sincronización inicial de un miembro dado a la vez.
Replicación
Los miembros secundarios replican los datos de forma coherente después de la sincronización inicial. Los miembros secundarios duplicarán el registro de operaciones de su sincronización desde la fuente y ejecutarán estas operaciones en un proceso asíncrono.
Los secundarios pueden modificar automáticamente su sincronización desde la fuente según sea necesario en función de los cambios en el tiempo de ping y el estado de la replicación de otros miembros.
Replicación de transmisión
Desde MongoDB 4.4, la sincronización desde las fuentes envía un flujo continuo de entradas de oplog a sus secundarios de sincronización. La replicación de transmisión reduce el retraso de replicación en redes de alta carga y alta latencia. También puede:
- Disminuya el riesgo de perder operaciones de escritura con
w:1debido a una conmutación por error principal. - Disminuya la obsolescencia de las lecturas de los secundarios.
- Reduzca la latencia en las operaciones de escritura con
w:“majority”yw:>1. En resumen, cualquier problema de escritura que deba esperar para la replicación.
Replicación multiproceso
MongoDB solía escribir operaciones en lotes a través de múltiples subprocesos para mejorar la concurrencia. MongoDB agrupa los lotes por ID de documento mientras aplica cada grupo de operaciones con un hilo diferente.
MongoDB siempre ejecuta operaciones de escritura en un documento dado en su orden de escritura original. Esto cambió en MongoDB 4.0.
A partir de MongoDB 4.0, las operaciones de lectura dirigidas a los secundarios y que están configuradas con un nivel de preocupación de lectura de “majority” o “local” ahora se leerán desde una instantánea de WiredTiger de los datos si la lectura ocurre en un secundario donde se aplican los lotes de replicación. Leer desde una instantánea garantiza una vista consistente de los datos y permite que la lectura ocurra simultáneamente con la replicación en curso sin necesidad de un bloqueo.
Por lo tanto, las lecturas secundarias que necesitan estos niveles de preocupación de lectura ya no necesitan esperar a que se apliquen los lotes de replicación y se pueden manejar a medida que se reciben.
Cómo crear un conjunto de réplicas de MongoDB
Como se mencionó anteriormente, MongoDB maneja la replicación a través de conjuntos de réplicas. En las siguientes secciones, destacaremos algunos métodos que puede usar para crear conjuntos de réplicas para su caso de uso.
Método 1: crear un nuevo conjunto de réplicas de MongoDB en Ubuntu
Antes de comenzar, deberá asegurarse de tener al menos tres servidores con Ubuntu 20.04, con MongoDB instalado en cada servidor.
Para configurar un conjunto de réplicas, es esencial proporcionar una dirección donde cada miembro del conjunto de réplicas pueda ser contactado por otros en el conjunto. En este caso, mantenemos tres miembros en el conjunto. Si bien podemos usar direcciones IP, no se recomienda ya que las direcciones pueden cambiar inesperadamente. Una mejor alternativa puede ser usar los nombres de host DNS lógicos al configurar conjuntos de réplicas.
Podemos hacer esto configurando el subdominio para cada miembro de replicación. Si bien esto puede ser ideal para un entorno de producción, esta sección describirá cómo configurar la resolución de DNS mediante la edición de los archivos de los hosts respectivos de cada servidor. Este archivo nos permite asignar nombres de host legibles a direcciones IP numéricas. Por lo tanto, si en cualquier caso cambia su dirección IP, todo lo que tiene que hacer es actualizar los archivos de los hosts en los tres servidores en lugar de volver a configurar el conjunto de réplicas desde cero.
En su mayoría, hosts se almacenan en el directorio /etc/ . Repita los siguientes comandos para cada uno de sus tres servidores:
sudo nano /etc/hostsEn el comando anterior, estamos usando nano como nuestro editor de texto, sin embargo, puede usar cualquier editor de texto que prefiera. Después de las primeras líneas que configuran el host local, agregue una entrada para cada miembro del conjunto de réplicas. Estas entradas toman la forma de una dirección IP seguida del nombre legible por humanos de su elección. Si bien puede nombrarlos como desee, asegúrese de ser descriptivo para que sepa diferenciar entre cada miembro. Para este tutorial, usaremos los siguientes nombres de host:
- mongo0.replset.miembro
- mongo1.replset.miembro
- mongo2.replset.miembro
Usando estos nombres de host, sus archivos /etc/hosts se verían similares a las siguientes líneas resaltadas:

Guarde y cierre el archivo.
Después de configurar la resolución de DNS para el conjunto de réplicas, debemos actualizar las reglas del firewall para permitir que se comuniquen entre sí. Ejecute el siguiente comando ufw en mongo0 para proporcionar acceso mongo1 al puerto 27017 en mongo0:
sudo ufw allow from mongo1_server_ip to any port 27017 En lugar del parámetro mongo1_server_ip , ingrese la dirección IP real de su servidor mongo1. Además, si actualizó la instancia de Mongo en este servidor para usar un puerto no predeterminado, asegúrese de cambiar 27017 para reflejar el puerto que usa su instancia de MongoDB.
Ahora agregue otra regla de firewall para dar acceso a mongo2 al mismo puerto:
sudo ufw allow from mongo2_server_ip to any port 27017 En lugar del parámetro mongo2_server_ip , ingrese la dirección IP real de su servidor mongo2. Luego, actualice las reglas de firewall para sus otros dos servidores. Ejecute los siguientes comandos en el servidor mongo1, asegurándose de cambiar las direcciones IP en lugar del parámetro server_ip para reflejar las de mongo0 y mongo2, respectivamente:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017Por último, ejecute estos dos comandos en mongo2. Nuevamente, asegúrese de ingresar las direcciones IP correctas para cada servidor:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017Su siguiente paso es actualizar el archivo de configuración de cada instancia de MongoDB para permitir conexiones externas. Para permitir esto, debe modificar el archivo de configuración en cada servidor para reflejar la dirección IP e indicar el conjunto de réplicas. Si bien puede usar cualquier editor de texto preferido, estamos usando el editor de texto nano una vez más. Hagamos las siguientes modificaciones en cada archivo mongod.conf.
En mongo0:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"En mongo1:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"En mongo2:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodCon esto, ha habilitado la replicación para la instancia de MongoDB de cada servidor.
Ahora puede inicializar el conjunto de réplicas mediante el método rs.initiate() . Solo se requiere que este método se ejecute en una sola instancia de MongoDB en el conjunto de réplicas. Asegúrese de que el nombre y el miembro del conjunto de réplicas coincidan con las configuraciones que realizó en cada archivo de configuración anteriormente.
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })Si el método devuelve "ok": 1 en la salida, significa que el conjunto de réplicas se inició correctamente. A continuación se muestra un ejemplo de cómo debería verse la salida:
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }Apague el servidor MongoDB
Puede cerrar un servidor MongoDB utilizando el método db.shutdownServer() . A continuación se muestra la sintaxis para el mismo. Tanto force como timeoutsecs son parámetros opcionales.
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) Este método puede fallar si el miembro del conjunto de réplicas mongod ejecuta ciertas operaciones como compilaciones de índice. Para interrumpir las operaciones y forzar el cierre del miembro, puede ingresar el parámetro booleano force en verdadero.
Reinicie MongoDB con –replSet
Para restablecer la configuración, asegúrese de que todos los nodos de su conjunto de réplicas estén detenidos. Luego elimine la base de datos local para cada nodo. Vuelva a iniciarlo con el indicador –replSet y ejecute rs.initiate() en una sola instancia de mongod para el conjunto de réplicas.

mongod --replSet "rs0" rs.initiate() puede tomar un documento de configuración de conjunto de réplicas opcional, a saber:
- La opción
Replication.replSetNameo—replSetpara especificar el nombre del conjunto de réplicas en el campo_id. - La matriz de miembros, que contiene un documento para cada miembro del conjunto de réplicas.
El método rs.initiate() desencadena una elección y elige a uno de los miembros para que sea el principal.
Agregar miembros al conjunto de réplicas
Para agregar miembros al conjunto, inicie instancias de mongod en varias máquinas. A continuación, inicie un cliente mongo y use el comando rs.add() .
El comando rs.add() tiene la siguiente sintaxis básica:
rs.add(HOST_NAME:PORT)Por ejemplo,
Suponga que mongo1 es su instancia de mongod y está escuchando en el puerto 27017. Utilice el comando de cliente Mongo rs.add() para agregar esta instancia al conjunto de réplicas.
rs.add("mongo1:27017") Solo después de estar conectado al nodo principal, puede agregar una instancia de mongod al conjunto de réplicas. Para verificar si está conectado al principal, use el comando db.isMaster() .
Eliminar usuarios
Para eliminar un miembro, podemos usar rs.remove()
Para hacerlo, en primer lugar, apague la instancia de mongod que desea eliminar utilizando el método db.shutdownServer() que discutimos anteriormente.
A continuación, conéctese al principal actual del conjunto de réplicas. Para determinar el principal actual, use db.hello() mientras está conectado a cualquier miembro del conjunto de réplicas. Una vez que haya determinado el principal, ejecute cualquiera de los siguientes comandos:
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 
Si el conjunto de réplicas necesita elegir un nuevo primario, MongoDB podría desconectar el shell brevemente. En este escenario, se volverá a conectar automáticamente una vez más. Además, puede mostrar un error de DBClientCursor::init call() aunque el comando se ejecute correctamente.
Método 2: Configuración de un conjunto de réplicas de MongoDB para implementación y pruebas
En general, puede configurar conjuntos de réplicas para realizar pruebas con RBAC habilitado o deshabilitado. En este método, configuraremos conjuntos de réplicas con el control de acceso deshabilitado para implementarlo en un entorno de prueba.
Primero, cree directorios para todas las instancias que forman parte del conjunto de réplicas con el siguiente comando:
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2Este comando creará directorios para tres instancias de MongoDB replicaset0-0, replicaset0-1 y replicaset0-2. Ahora, inicie las instancias de MongoDB para cada una de ellas usando el siguiente conjunto de comandos:
Para el servidor 1:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Para el servidor 2:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Para el servidor 3:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 El parámetro –oplogSize se utiliza para evitar que la máquina se sobrecargue durante la fase de prueba. Ayuda a reducir la cantidad de espacio en disco que consume cada disco.
Ahora, conéctese a una de las instancias usando el shell de Mongo conectándose usando el número de puerto a continuación.
mongo --port 27017 Podemos usar el comando rs.initiate() para iniciar el proceso de replicación. Deberá reemplazar el parámetro de hostname con el nombre de su sistema.
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }Ahora puede pasar el archivo de objeto de configuración como parámetro para el comando de inicio y usarlo de la siguiente manera:
rs.initiate(rsconf)¡Y ahí lo tienes! Ha creado correctamente un conjunto de réplicas de MongoDB con fines de desarrollo y prueba.
Método 3: Transformar una instancia independiente en un conjunto de réplicas de MongoDB
MongoDB permite a sus usuarios transformar sus instancias independientes en conjuntos de réplicas. Si bien las instancias independientes se utilizan principalmente para la fase de prueba y desarrollo, los conjuntos de réplicas forman parte del entorno de producción.
Para comenzar, apaguemos nuestra instancia de mongod usando el siguiente comando:
db.adminCommand({"shutdown":"1"}) Reinicie su instancia usando el parámetro –repelSet en su comando para especificar el conjunto de réplicas que va a usar:
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>Debe especificar el nombre de su servidor junto con la dirección única en el comando.
Conecte el shell con su instancia de MongoDB y use el comando de inicio para iniciar el proceso de replicación y convertir con éxito la instancia en un conjunto de réplicas. Puede realizar todas las operaciones básicas, como agregar o eliminar una instancia, utilizando los siguientes comandos:
rs.add(“<host_name:port>”) rs.remove(“host-name”) Además, puede comprobar el estado de su conjunto de réplicas de MongoDB mediante los comandos rs.status() y rs.conf() .
Método 4: MongoDB Atlas: una alternativa más simple
La replicación y la fragmentación pueden trabajar juntas para formar algo llamado clúster fragmentado. Si bien la instalación y la configuración pueden llevar bastante tiempo, aunque son sencillas, MongoDB Atlas es una mejor alternativa que los métodos mencionados anteriormente.
Automatiza sus conjuntos de réplicas, lo que facilita la implementación del proceso. Puede implementar conjuntos de réplicas fragmentadas globalmente con unos pocos clics, lo que permite la recuperación ante desastres, una administración más sencilla, localidad de datos e implementaciones en varias regiones.
En MongoDB Atlas, necesitamos crear clústeres; pueden ser un conjunto de réplicas o un clúster fragmentado. Para un proyecto en particular, la cantidad de nodos en un clúster en otras regiones está limitada a un total de 40.
Esto excluye los clústeres gratuitos o compartidos y las regiones de la nube de Google que se comunican entre sí. El número total de nodos entre dos regiones debe cumplir con esta restricción. Por ejemplo, si hay un proyecto en el que:
- La región A tiene 15 nodos.
- La región B tiene 25 nodos
- La región C tiene 10 nodos
Solo podemos asignar 5 nodos más a la región C como,
- Región A+ Región B = 40; cumple con la restricción de 40 siendo el número máximo de nodos permitidos.
- Región B+ Región C = 25+10+5 (Nodos adicionales asignados a C) = 40; cumple con la restricción de 40 siendo el número máximo de nodos permitidos.
- Región A+ Región C =15+10+5 (Nodos adicionales asignados a C) = 30; cumple con la restricción de 40 siendo el número máximo de nodos permitidos.
Si asignamos 10 nodos más a la región C, haciendo que la región C tenga 20 nodos, entonces Región B + Región C = 45 nodos. Esto excedería la restricción dada, por lo que es posible que no pueda crear un clúster de varias regiones.
Cuando crea un clúster, Atlas crea un contenedor de red en el proyecto para el proveedor de la nube si no estaba allí anteriormente. Para crear un clúster de conjunto de réplicas en MongoDB Atlas, ejecute el siguiente comando en Atlas CLI:
atlas clusters create [name] [options]Asegúrese de proporcionar un nombre de clúster descriptivo, ya que no se puede cambiar después de crear el clúster. El argumento puede contener letras ASCII, números y guiones.
Hay varias opciones disponibles para la creación de clústeres en MongoDB según sus requisitos. Por ejemplo, si desea una copia de seguridad continua en la nube para su clúster, establezca --backup en verdadero.
Lidiando con el retraso de la replicación
El retraso en la replicación puede ser bastante desagradable. Es un retraso entre una operación en el primario y la aplicación de esa operación desde el oplog al secundario. Si su negocio maneja grandes conjuntos de datos, se espera un retraso dentro de cierto umbral. Sin embargo, a veces los factores externos también pueden contribuir y aumentar la demora. Para beneficiarse de una replicación actualizada, asegúrese de que:
- Enruta el tráfico de su red en un ancho de banda estable y suficiente. La latencia de la red juega un papel muy importante al afectar su replicación, y si la red es insuficiente para satisfacer las necesidades del proceso de replicación, habrá demoras en la replicación de datos en todo el conjunto de réplicas.
- Tiene un rendimiento de disco suficiente. Si el sistema de archivos y el dispositivo de disco en el secundario no pueden vaciar los datos en el disco tan rápido como el principal, entonces el secundario tendrá dificultades para mantenerse al día. Por lo tanto, los nodos secundarios procesan las consultas de escritura más lentamente que el nodo principal. Este es un problema común en la mayoría de los sistemas multiusuario, incluidas las instancias virtualizadas y las implementaciones a gran escala.
- Solicita una solicitud de confirmación de escritura después de un intervalo para brindar la oportunidad de que los secundarios se pongan al día con el principal, especialmente cuando desea realizar una operación de carga masiva o ingesta de datos que requiere una gran cantidad de escrituras en el principal. Los secundarios no podrán leer el registro de operaciones lo suficientemente rápido como para mantenerse al día con los cambios; particularmente con preocupaciones de escritura no reconocidas.
- Usted identifica las tareas en segundo plano en ejecución. Ciertas tareas, como los trabajos cron, las actualizaciones del servidor y las comprobaciones de seguridad, pueden tener efectos inesperados en la red o el uso del disco, lo que provoca retrasos en el proceso de replicación.
Si no está seguro de si hay un retraso en la replicación en su aplicación, no se preocupe: ¡la siguiente sección trata las estrategias de solución de problemas!
Solución de problemas de conjuntos de réplicas de MongoDB
Configuró correctamente sus conjuntos de réplicas, pero observa que sus datos son inconsistentes entre los servidores. Esto es muy alarmante para las empresas a gran escala, sin embargo, con métodos rápidos de solución de problemas, ¡puede encontrar la causa o incluso corregir el problema! A continuación se presentan algunas estrategias comunes para solucionar problemas de implementaciones de conjuntos de réplicas que podrían resultar útiles:
Comprobar el estado de la réplica
Podemos verificar el estado actual del conjunto de réplicas y el estado de cada miembro ejecutando el siguiente comando en una sesión mongosh que está conectada a la principal de un conjunto de réplicas.
rs.status()Comprobar el retraso de la replicación
Como se discutió anteriormente, el retraso de la replicación puede ser un problema grave, ya que hace que los miembros "retrasados" no sean elegibles para convertirse rápidamente en primarios y aumenta la posibilidad de que las operaciones de lectura distribuidas sean inconsistentes. Podemos verificar la longitud actual del registro de replicación usando el siguiente comando:
rs.printSecondaryReplicationInfo() Esto devuelve el valor syncedTo , que es el momento en que se escribió la última entrada de registro de operaciones en el secundario para cada miembro. Aquí hay un ejemplo para demostrar lo mismo:
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary Un miembro retrasado puede mostrarse 0 segundos detrás del principal cuando el período de inactividad en el principal es mayor que el valor members[n].secondaryDelaySecs .
Probar conexiones entre todos los miembros
Cada miembro de un conjunto de réplicas debe poder conectarse con todos los demás miembros. Siempre asegúrese de verificar las conexiones en ambas direcciones. En su mayoría, las configuraciones de firewall o las topologías de red impiden la conectividad normal y requerida, lo que puede bloquear la replicación.
Por ejemplo, supongamos que la instancia de mongod se vincula tanto con el host local como con el nombre de host 'ExampleHostname', que está asociado con la dirección IP 198.41.110.1:
mongod --bind_ip localhost, ExampleHostnamePara conectarse a esta instancia, los clientes remotos deben especificar el nombre de host o la dirección IP:
mongosh --host ExampleHostname mongosh --host 198.41.110.1Si un conjunto de réplica consta de tres miembros, m1, m2 y m3, utilizando el puerto predeterminado 27017, debe probar la conexión de la siguiente manera:
en m1:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017en m2:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017en m3:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 Si alguna conexión en cualquier dirección falla, deberá verificar la configuración de su firewall y reconfigurarlo para permitir las conexiones.
Garantía de comunicaciones seguras con la autenticación de archivos de claves
De forma predeterminada, la autenticación de archivos de claves en MongoDB se basa en el mecanismo de autenticación de respuesta de desafío salado (SCRAM). Para hacer esto, MongoDB debe leer y validar las credenciales proporcionadas por el usuario que incluyen una combinación del nombre de usuario, la contraseña y la base de datos de autenticación que conoce la instancia específica de MongoDB. Este es el mecanismo exacto que se utiliza para autenticar a los usuarios que proporcionan una contraseña al conectarse a la base de datos.
Cuando habilita la autenticación en MongoDB, el control de acceso basado en roles (RBAC) se habilita automáticamente para el conjunto de réplicas y al usuario se le otorgan uno o más roles que determinan su acceso a los recursos de la base de datos. Cuando RBAC está habilitado, significa que solo el usuario de Mongo autenticado válido con los privilegios apropiados podrá acceder a los recursos del sistema.
El archivo de claves actúa como una contraseña compartida para cada miembro del clúster. Esto permite que cada instancia de mongod en el conjunto de réplicas use el contenido del archivo de claves como la contraseña compartida para autenticar a otros miembros en la implementación.
Solo aquellas instancias de mongod con el archivo de claves correcto pueden unirse al conjunto de réplicas. La longitud de una clave debe tener entre 6 y 1024 caracteres y solo puede contener caracteres en el conjunto base64. Tenga en cuenta que MongoDB elimina los espacios en blanco al leer las claves.
Puede generar un archivo de claves utilizando varios métodos. En este tutorial, usamos openssl para generar una cadena compleja de 1024 caracteres aleatorios para usar como contraseña compartida. Luego usa chmod para cambiar los permisos de archivo para proporcionar permisos de lectura solo para el propietario del archivo. Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. Por ejemplo:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
And voila! You have successfully enabled keyfile authentication!
Resumen
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!