
Almacenamiento persistente: memoria a largo plazo en la era de los contenedores
Publicado: 2023-04-17El almacenamiento persistente se refiere a la retención de datos de manera no volátil para que permanezcan disponibles incluso después de que un dispositivo o aplicación se apague o reinicie. El almacenamiento y la recuperación de datos permiten que las aplicaciones web guarden la información y los estados del usuario y funcionen de manera confiable.
En las aplicaciones monolíticas, el acceso al almacenamiento es sencillo porque el servidor y el almacenamiento viven juntos. Sin embargo, los sistemas distribuidos geográficamente hacen que el acceso sea más complejo, ya que el sistema de almacenamiento debe permanecer disponible para todos los componentes en todo el mundo.
La contenedorización complica aún más el problema porque los contenedores son livianos, sin estado y efímeros, características inadecuadas para almacenar datos. Por lo tanto, cualquier solución de almacenamiento persistente debe poder funcionar sin problemas con los contenedores, lo que agrega otra capa de complejidad.
Este artículo profundiza en el almacenamiento persistente explorando sus tipos, arquitectura y casos de uso. También proporciona una demostración práctica que ilustra la diferencia entre el almacenamiento de volumen y el almacenamiento de volumen persistente en Docker.
Tipos de almacenamiento persistente
Hay varios tipos de almacenamiento no volátil, incluidos los discos giratorios tradicionales (unidades de disco duro o HDD), unidades de estado sólido (SSD), almacenamiento conectado a la red (NAS) y redes de área de almacenamiento (SAN).
- Los discos duros son dispositivos de almacenamiento de datos electromecánicos que almacenan y recuperan datos digitales utilizando discos giratorios de medios magnéticos. Los discos usan cabezales magnéticos en un brazo accionador móvil que lee y escribe datos.
- Los SSD , a veces llamados dispositivos de almacenamiento de semiconductores, dispositivos de estado sólido o discos de estado sólido, usan ensamblajes de circuitos integrados para almacenar datos de manera persistente, generalmente usando dispositivos flash interconectados que no contienen partes móviles. Su naturaleza estacionaria los hace más rápidos y confiables que los HDD.
- El almacenamiento conectado a la red es un grupo de HDD, SSD o ambos, conectados a través de una red local mediante un sistema de archivos como el Sistema de archivos de nueva tecnología (NTFS) o el cuarto sistema de archivos extendido (EXT4).
- Las SAN son dispositivos de almacenamiento de nivel de bloque de alta velocidad conectados en red, como bibliotecas de cintas o matrices de discos. Su conexión aparece en el sistema operativo como almacenamiento local y no es accesible a través de la red de área local (LAN).
Arquitectura de almacenamiento persistente
Hay tres enfoques para el almacenamiento persistente, cada uno con casos de uso y limitaciones únicos.
Arquitectura persistente de objetos
El enfoque de arquitectura persistente de objetos utiliza el mapeo relacional de objetos (ORM) para almacenar datos como objetos en una base de datos relacional o de valores clave. Este enfoque es útil cuando los datos no tienen un esquema definido, ya que el ORM maneja su almacenamiento y recuperación.
Arquitectura persistente de bloques
La arquitectura persistente en bloque utiliza dispositivos de almacenamiento a nivel de bloque, que son útiles cuando se almacenan archivos de gran tamaño. Este enfoque es beneficioso cuando se almacenan grandes cantidades de datos, ya que puede usar varios bloques para aumentar la capacidad de almacenamiento.
Arquitectura persistente de almacenamiento de archivos
Como sugiere el nombre, el enfoque de arquitectura persistente de almacenamiento de archivos utiliza un sistema de archivos para almacenar datos. Un método implica el uso de servidores de bases de datos, que proporcionan una forma centralizada de almacenar datos. Las soluciones de alojamiento en la nube, como los servidores de bases de datos de uso de Kinsta, se conectan fácilmente a las aplicaciones y ofrecen persistencia.
La arquitectura persistente de Filestore es útil en aplicaciones que requieren una recuperación frecuente de archivos y cuando necesita una interfaz para administrarlos.
Casos de uso de almacenamiento persistente
Esta sección analiza algunos de los casos de uso de cada tipo de almacenamiento.
Almacenamiento persistente de objetos
- Almacenamiento en la nube: el almacenamiento persistente de objetos se usa comúnmente en soluciones de almacenamiento en la nube para almacenar y recuperar grandes cantidades de datos no estructurados, como imágenes, videos y documentos. Los proveedores de la nube utilizan el almacenamiento de objetos para brindar a los clientes servicios de almacenamiento escalables, de alta disponibilidad y duraderos.
- Análisis de big data: el almacenamiento persistente de objetos se utiliza en el análisis de big data para almacenar y administrar grandes conjuntos de datos que a menudo se usan para el análisis de datos, el aprendizaje automático y la IA. El almacenamiento de objetos permite acceder a los datos de manera rápida y eficiente, lo que lo convierte en un componente clave de las arquitecturas de big data.
- Redes de entrega de contenido: el almacenamiento persistente de objetos se utiliza en redes de entrega de contenido (CDN) para almacenar y distribuir contenido, como imágenes, videos y archivos estáticos, a través de una red global de servidores. El almacenamiento de objetos permite que las CDN entreguen contenido de alta velocidad a usuarios de todo el mundo, independientemente de su ubicación.
Bloquear almacenamiento persistente
- Informática de alto rendimiento (HPC) : entornos HPC para el procesamiento rápido y eficiente de volúmenes de datos considerables. El almacenamiento persistente en bloques permite que los clústeres de HPC almacenen y recuperen grandes conjuntos de datos, como simulaciones científicas, modelos meteorológicos y análisis financieros. A menudo se prefiere el almacenamiento en bloque para HPC porque proporciona acceso a datos de alto rendimiento y baja latencia y permite operaciones de entrada/salida (E/S) paralelas, lo que puede mejorar significativamente los tiempos de procesamiento.
- Edición de video: las aplicaciones de edición de video requieren acceso de alto rendimiento y baja latencia a archivos de video de gran tamaño. También deben acomodar un número significativo de operaciones de E/S por segundo y baja latencia para renderizar y editar archivos de video en tiempo real. El almacenamiento en bloque brinda estas capacidades, lo que lo convierte en una solución ideal para los flujos de trabajo de edición de video.
- Juegos: las aplicaciones de juegos también exigen alto rendimiento y baja latencia para acceder a los activos del juego y los datos de los jugadores. El almacenamiento en bloque almacena y recupera rápidamente grandes cantidades de datos, lo que garantiza que los entornos de juego se carguen rápidamente y sigan respondiendo durante el juego.
Almacenamiento persistente de Filestore
- Medios y entretenimiento: las aplicaciones de edición, animación y representación de video suelen usar almacenamiento persistente. Estas aplicaciones requieren acceso de alto rendimiento y baja latencia a archivos multimedia grandes, como video, audio e imágenes. Filestore proporciona un sistema de archivos compartido al que pueden acceder varios clientes, lo que lo convierte en una solución de almacenamiento ideal para estas aplicaciones.
- Administración de contenido web: los sistemas de administración de contenido web (CMS) utilizan almacenamiento persistente de almacenamiento de archivos en sistemas de archivos compartidos para almacenar y administrar el contenido del sitio web, como texto, imágenes y archivos multimedia. Filestore proporciona una ubicación central para el contenido del sitio web, lo que facilita su administración y actualización. También permite que varios usuarios trabajen simultáneamente en el mismo contenido, lo que mejora la colaboración y la productividad.
Almacenamiento persistente en contenedores
Los contenedores son livianos, portátiles, seguros y sencillos, y ofrecen una fusión entre diferentes aplicaciones. Deben tener un mecanismo para conservar los datos entre los reinicios y la eliminación del contenedor. Los contenedores tienen almacenamiento de archivos o un sistema de archivos como las aplicaciones tradicionales, pero cada vez que los reconstruye con nuevos cambios, pierde todos los datos no persistentes.
Es por eso que los contenedores ofrecen la opción de incluir almacenamiento de volumen o montar un volumen de almacenamiento. Los contenedores tratan los volúmenes de almacenamiento como un directorio. Todos los datos escritos en el volumen van al sistema de archivos del host.
El almacenamiento persistente para contenedores debe funcionar de esta manera porque reiniciar un contenedor crea una nueva instancia y descarta la instancia anterior. Si un contenedor no tiene una vista coherente de los datos, los datos desaparecerán cuando se reinicie el contenedor. Un volumen de almacenamiento conserva los datos entre sesiones y reinicios del contenedor, lo que permite que el contenedor mantenga su estado incluso si se mueve o se reinicia.

Volumen vs Volumen Persistente
Los contenedores proporcionan 2 formas de almacenar datos persistentes: usando volúmenes y volúmenes persistentes. Hay una diferencia significativa entre ellos. Un contenedor gestiona los datos en el volumen de almacenamiento. Cuando detiene un contenedor, los datos permanecen y están disponibles cuando reinicia el contenedor. Sin embargo, cuando elimina o elimina un contenedor, los datos se pierden ya que también elimina el almacenamiento de volumen subyacente.
El almacenamiento de volumen persistente o los montajes de enlace son una forma de almacenar los datos fuera del sistema de archivos del contenedor. De esta manera, los datos no se perderán incluso cuando elimine el contenedor. Es persistente hasta que se elimina manualmente.
La siguiente sección muestra ambos tipos de volumen con ejemplos.
Demostración de almacenamiento persistente de contenedores
Hemos creado una pequeña aplicación web para demostrar el almacenamiento persistente con contenedores Docker. Puede seguir instalando Docker y tomando el código de este repositorio de GitHub.
La aplicación es un formulario elemental con 2 campos para la entrada del usuario:
- Título
- Texto del documento
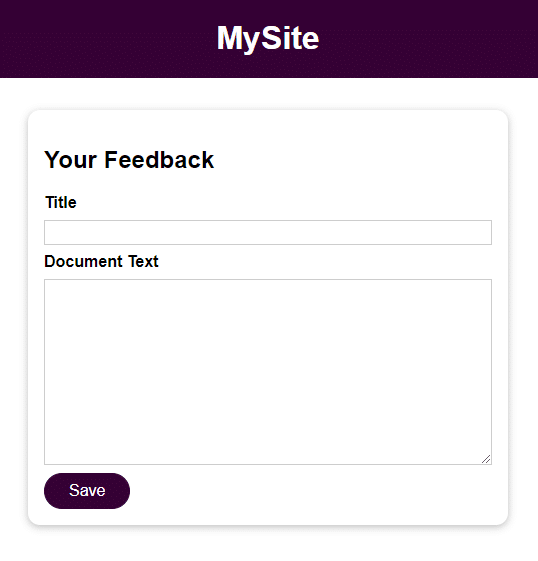
Una vez que guarde la entrada del usuario, puede acceder a ella abriendo el archivo en el directorio de comentarios con el nombre proporcionado en el campo Título . La entrada del campo Texto del documento es el contenido del archivo.
Cómo usar el almacenamiento de volumen
Una vez que haya instalado la aplicación en su propia máquina, puede usar almacenamiento de volumen como se muestra en el Dockerfile .
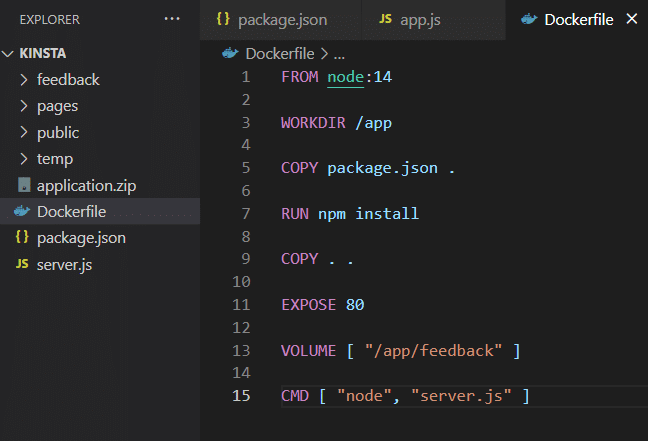
Ahora, crea la imagen y ejecuta el contenedor. Para hacerlo, ejecute los siguientes comandos.
docker build -t feedback-node:volumes . docker run -d -p 3000:80 --name feedback-app feedback-node:volumes 
Una vez que se ejecute la aplicación, vaya a localhost:3000 para enviar comentarios.
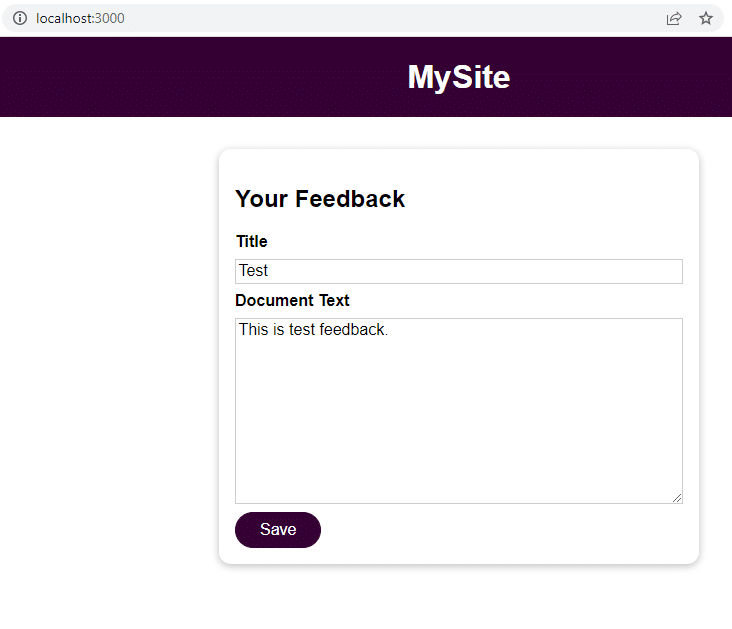
Haga clic en Guardar y navegue hasta localhost:3000/feedback/test.txt para ver si la entrada se almacenó correctamente o no.
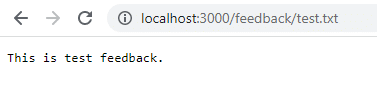
Retire y reinicie el contenedor para ver si la entrada persiste.
docker stop feedback-app docker start feedback-appSi ahora visita la misma URL, verá que los comentarios siguen ahí. Pero, ¿qué sucede si elimina el contenedor y lo reinicia?
docker stop feedback-app docker rm feedback-app docker run -d -p 3000:80 --name feedback-app feedback-node:volumesUna vez reiniciado, si regresa a esa URL, ya no existe porque los datos se perdieron cuando eliminó el contenedor. Los datos de volumen persisten solo cuando se detiene el contenedor, no cuando se retira.
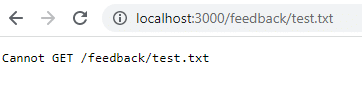
Para mitigar este problema y conservar los datos incluso cuando elimine el contenedor, debe usar almacenamiento de volumen persistente o almacenamiento con nombre. Primero, debe limpiar los contenedores y las imágenes.
docker stop feedback-app docker rm feedback-app docker rmi feedback-node:volumesCómo utilizar el almacenamiento de volumen persistente
Antes de probar esto, debe eliminar el atributo VOLUME del Dockerfile y reconstruir la imagen.
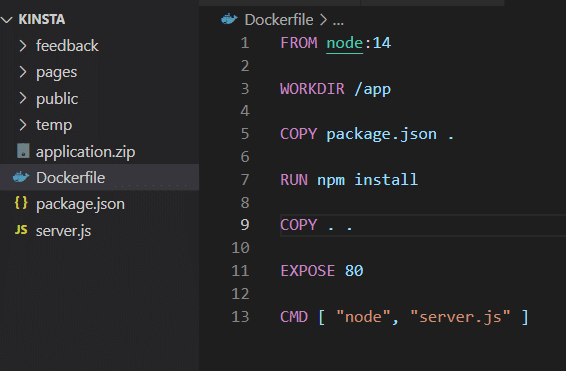
docker build -t feedback-node:volumes . docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumes Como puede ver, en el segundo comando, usa el indicador -v para definir el volumen persistente fuera del contenedor, que persiste incluso cuando elimina el contenedor.
Al igual que en el paso anterior, intente agregar comentarios y acceda a ellos una vez que detenga, elimine y reinicie el contenedor.
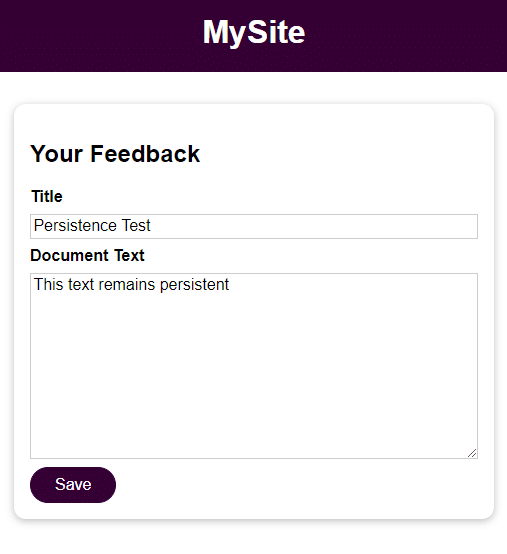
docker stop feedback-app docker rm feedback-app docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesComo puede ver, incluso después de detener y eliminar el contenedor, los datos son accesibles y permanecen.
Resumen
El almacenamiento persistente es vital para las aplicaciones en contenedores porque permite la persistencia de datos fuera del ciclo de vida de un contenedor. Los 2 tipos principales de almacenamiento persistente para aplicaciones en contenedores son volúmenes y montajes de enlace, cada uno con sus beneficios y casos de uso.
Los volúmenes se almacenan dentro del sistema de archivos del contenedor, mientras que los montajes de enlace son accesibles directamente en la máquina host.
El almacenamiento persistente permite que los datos se compartan entre contenedores, lo que hace posible crear aplicaciones complejas de varios niveles. El almacenamiento persistente es esencial para garantizar la estabilidad y la continuidad de las aplicaciones en contenedores, ya que brinda una forma confiable y flexible de almacenar datos cruciales.
Y si está utilizando Docker para desarrollar sus aplicaciones web, descubrirá que es muy fácil configurar las implementaciones de Dockerfile con el servicio de alojamiento de aplicaciones de Kinsta.