
Robots.txt: Qué es y cómo crearlo (Guía completa)
Publicado: 2023-05-05Si posee un sitio web o administra su contenido, es probable que haya oído hablar de robots.txt. Es un archivo que instruye a los robots de los motores de búsqueda sobre cómo rastrear e indexar las páginas de su sitio web. A pesar de su importancia en la optimización de motores de búsqueda (SEO), muchos propietarios de sitios web pasan por alto la importancia de un archivo robots.txt bien diseñado.
En esta guía completa, exploraremos qué es robots.txt, por qué es importante para el SEO y cómo crear un archivo robots.txt para su sitio web.
¿Qué es el archivo Robots.txt?
Un archivo robots.txt es un archivo que le dice a los robots de los motores de búsqueda (también conocidos como rastreadores o arañas) qué páginas o secciones de un sitio web deben rastrearse o no. Es un archivo de texto sin formato ubicado en el directorio raíz de un sitio web y, por lo general, incluye una lista de directorios, archivos o URL que el webmaster desea bloquear de la indexación o el rastreo del motor de búsqueda.
Así es como se ve un archivo robots.txt:

¿Por qué es importante Robots.txt?
Hay tres razones principales por las que robots.txt es importante para su sitio web:
1. Maximice el presupuesto de rastreo
El "presupuesto de rastreo" representa la cantidad de páginas que Google rastreará en su sitio en un momento dado. El número depende del tamaño, la salud y la cantidad de vínculos de retroceso en su sitio.
El presupuesto de rastreo es importante porque si la cantidad de páginas de su sitio supera el presupuesto de rastreo, tendrá páginas que no estarán indexadas.
Además, las páginas que no están indexadas no se clasificarán para nada.
Al usar robots.txt para bloquear páginas inútiles, Googlebot (el rastreador web de Google) puede gastar más de su presupuesto de rastreo en páginas importantes.
2. Bloquear páginas no públicas
Tiene muchas páginas en su sitio que no desea indexar.
Por ejemplo, puede tener una página de resultados de búsqueda interna o una página de inicio de sesión. Estas páginas deben existir. Sin embargo, no querrás que personas al azar aterricen en ellos.
En este caso, usaría robots.txt para evitar que los rastreadores y bots de los motores de búsqueda accedan a ciertas páginas.
3. Evitar la indexación de recursos
A veces querrá que Google excluya recursos como archivos PDF, videos e imágenes de los resultados de búsqueda.
Posiblemente desee mantener esos recursos privados o desea que Google se concentre más en el contenido importante.
En tales casos, usar robots.txt es el mejor enfoque para evitar que se indexen.
¿Cómo funciona un archivo Robots.txt?
Los archivos Robots.txt indican a los robots de los motores de búsqueda qué páginas o directorios del sitio web deben o no rastrear o indexar.
Mientras rastrean, los robots de los motores de búsqueda encuentran y siguen enlaces. Este proceso los lleva del sitio X al sitio Y al sitio Z a través de miles de millones de enlaces y sitios web.
Cuando un bot visita un sitio, lo primero que hace es buscar un archivo robots.txt.
Si detecta uno, leerá el archivo antes de hacer cualquier otra cosa.
Por ejemplo, suponga que desea permitir que todos los bots, excepto DuckDuckGo, rastreen su sitio:
User-agent: DuckDuckBot Disallow: /
Nota: un archivo robots.txt solo puede dar instrucciones; no puede imponerlos. Es similar a un código de conducta. Los bots buenos (como los bots de los motores de búsqueda) seguirán las reglas, mientras que los bots malos (como los bots de spam) las ignorarán.
¿Cómo encontrar un archivo Robots.txt?
El archivo robots.txt, como cualquier otro archivo de su sitio web, está alojado en su servidor.
Puede acceder al archivo robots.txt de cualquier sitio web ingresando la URL completa de la página de inicio y luego agregando /robots.txt al final, como https://pickupwp.com/robots.txt.
Sin embargo, si el sitio web no tiene un archivo robots.txt, recibirá un mensaje de error "404 Not Found".
¿Cómo crear un archivo Robots.txt?
Antes de mostrar cómo crear un archivo robots.txt, veamos primero la sintaxis de robots.txt.
La sintaxis de un archivo robots.txt se puede dividir en los siguientes componentes:
- Agente de usuario: Esto especifica el robot o rastreador al que se aplica el registro. Por ejemplo, "User-agent: Googlebot" se aplicaría solo al rastreador de búsqueda de Google, mientras que "User-agent: *" se aplicaría a todos los rastreadores.
- No permitir: Esto especifica las páginas o directorios que el robot no debe rastrear. Por ejemplo, "No permitir: /privado/" evitaría que los robots rastreen cualquier página dentro del directorio "privado".
- Permitir: Esto especifica las páginas o directorios que el robot debe poder rastrear, incluso si el directorio principal no está permitido. Por ejemplo, "Permitir: /público/" permitiría a los robots rastrear cualquier página dentro del directorio "público", incluso si el directorio principal no está permitido.
- Crawl-delay: Esto especifica la cantidad de tiempo en segundos que el robot debe esperar antes de rastrear el sitio web. Por ejemplo, "Crawl-delay: 10" indicaría al robot que esperara 10 segundos antes de rastrear el sitio web.
- Mapa del sitio: Esto especifica la ubicación del mapa del sitio del sitio web. Por ejemplo, "Sitemap: https://www.example.com/sitemap.xml" informaría al robot de la ubicación del sitemap del sitio web.
Este es un ejemplo de un archivo robots.txt:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
Nota: es importante tener en cuenta que los archivos robots.txt distinguen entre mayúsculas y minúsculas, por lo que es importante utilizar las mayúsculas y minúsculas correctas al especificar las URL.
Por ejemplo, /público/ no es lo mismo que /Público/.
Por otro lado, directivas como "Permitir" y "No permitir" no distinguen entre mayúsculas y minúsculas, por lo que depende de usted si las escribe con mayúscula o no.
Después de aprender sobre la sintaxis de robots.txt, puede crear un archivo robots.txt usando una herramienta generadora de robots.txt o crear uno usted mismo.
Aquí se explica cómo crear un archivo robots.txt en solo cuatro pasos:
1. Cree un nuevo archivo y asígnele el nombre Robots.txt
Simplemente abriendo un documento .txt con cualquier editor de texto o navegador web.
A continuación, asigne al documento el nombre robots.txt. Para que funcione, debe llamarse robots.txt.
Una vez hecho esto, ahora puede comenzar a escribir directivas.
2. Agregar directivas al archivo Robots.txt
Un archivo robots.txt contiene uno o más grupos de directivas, cada uno con varias líneas de instrucciones.
Cada grupo comienza con un “User-agent” y contiene los siguientes datos:
- A quién se aplica el grupo (el agente de usuario)
- ¿A qué directorios (páginas) o archivos puede acceder el agente?
- ¿A qué directorios (páginas) o archivos no puede acceder el agente?
- Un mapa del sitio (opcional) para informar a los motores de búsqueda sobre los sitios y archivos que cree que son importantes.
Los rastreadores ignoran las líneas que no coinciden con ninguna de estas directivas.

Por ejemplo, desea evitar que Google rastree su directorio /private/.
Se vería así:
User-agent: Googlebot Disallow: /private/
Si tuviera más instrucciones como esta para Google, las colocaría en una línea separada directamente debajo de esta manera:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
Además, si ha terminado con las instrucciones específicas de Google y desea crear un nuevo grupo de directivas.
Por ejemplo, si desea evitar que todos los motores de búsqueda rastreen sus directorios /archive/ y /support/.
Se vería así:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
Cuando haya terminado, puede agregar su mapa del sitio.
Su archivo robots.txt completado debería verse así:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
A continuación, guarde su archivo robots.txt. Recuerde, debe llamarse robots.txt.
Para obtener reglas de robots.txt más útiles, consulte esta útil guía de Google.
3. Cargue el archivo Robots.txt
Después de guardar su archivo robots.txt en su computadora, cárguelo en su sitio web y póngalo a disposición de los motores de búsqueda para que lo rastreen.
Desafortunadamente, no existe ninguna herramienta que pueda ayudar con este paso.
La carga del archivo robots.txt depende de la estructura de archivos y el alojamiento web de su sitio.
Para obtener instrucciones sobre cómo cargar su archivo robots.txt, busque en línea o comuníquese con su proveedor de alojamiento.
4. Pruebe sus robots.txt
Después de cargar el archivo robots.txt, puede verificar si alguien puede verlo y si Google puede leerlo.
Simplemente abra una nueva pestaña en su navegador y busque su archivo robots.txt.
Por ejemplo, https://pickupwp.com/robots.txt.
Si ve su archivo robots.txt, está listo para probar el marcado (código HTML).
Para ello, puede utilizar un probador de robots.txt de Google.
Nota: Tienes una cuenta de Search Console configurada para probar tu archivo robots.txt usando robots.txt Tester.
El probador de robots.txt encontrará cualquier advertencia de sintaxis o errores lógicos y los resaltará.
Además, también te muestra las advertencias y errores debajo del editor.
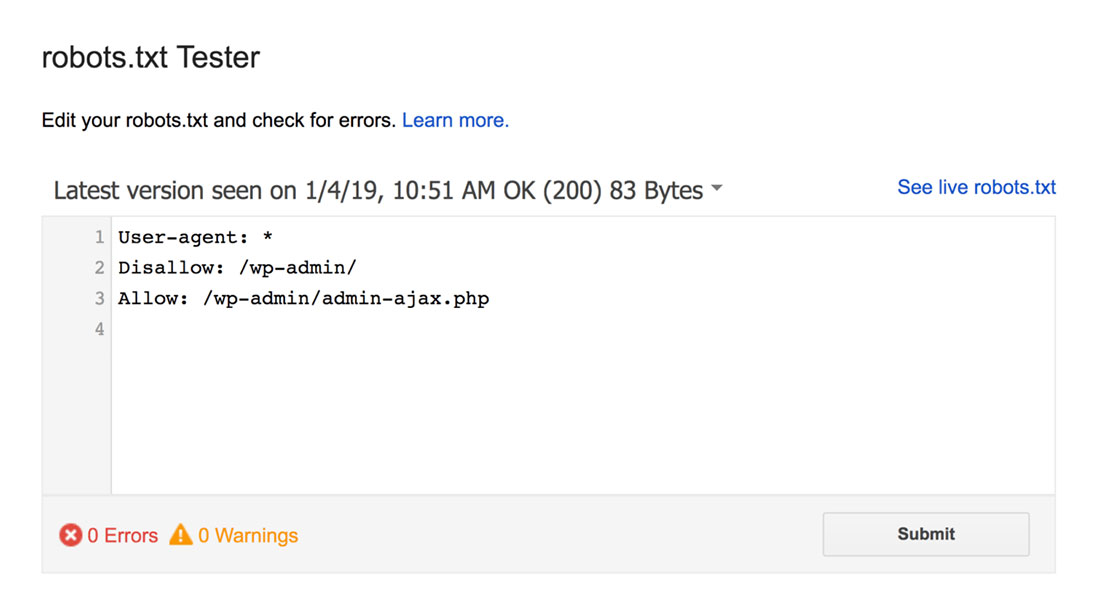
Puede editar errores o advertencias en la página y volver a realizar la prueba tantas veces como sea necesario.
Solo tenga en cuenta que los cambios realizados en la página no se guardan en su sitio.
Para realizar cambios, copie y pegue esto en el archivo robots.txt de su sitio.
Prácticas recomendadas de Robots.txt
Tenga en cuenta estas mejores prácticas al crear su archivo robots.txt para evitar algunos errores comunes.
1. Use nuevas líneas para cada directiva
Para evitar confusiones con los rastreadores de los motores de búsqueda, agregue cada directiva a una nueva línea en su archivo robots.txt. Esto se aplica a las reglas Permitir y No permitir.
Por ejemplo, si no desea que un rastreador web rastree su blog o página de contacto, agregue las siguientes reglas:
Disallow: /blog/ Disallow: /contact/
2. Use cada agente de usuario solo una vez
Los bots no tienen ningún problema si usa el mismo agente de usuario una y otra vez.
Sin embargo, usarlo solo una vez mantiene las cosas organizadas y reduce la posibilidad de error humano.
3. Use comodines para simplificar las instrucciones
Si tiene una gran cantidad de páginas para bloquear, agregar una regla para cada una puede llevar mucho tiempo. Afortunadamente, puede usar comodines para simplificar sus instrucciones.
Un comodín es un carácter que puede representar uno o más caracteres. El comodín más utilizado es el asterisco (*).
Por ejemplo, si desea bloquear todos los archivos que terminan en .jpg, agregaría la siguiente regla:
Disallow: /*.jpg
4. Use "$" para especificar el final de una URL
El signo de dólar ($) es otro comodín que se puede usar para identificar el final de una URL. Esto es útil si desea restringir una página específica pero no las siguientes.
Supongamos que desea bloquear la página de contacto pero no la página de éxito del contacto, agregaría la siguiente regla:
Disallow: /contact$
5. Use el hash (#) para agregar comentarios
Los rastreadores ignoran todo lo que comienza con un hash (#).
Como resultado, los desarrolladores a menudo usan el hash para agregar comentarios al archivo robots.txt. Mantiene el documento organizado y legible.
Por ejemplo, si desea evitar que todos los archivos terminen en .jpg, puede agregar el siguiente comentario:
# Block all files that end in .jpg Disallow: /*.jpg
Esto ayuda a cualquiera a entender para qué sirve la regla y por qué está ahí.
6. Use archivos Robots.txt separados para cada subdominio
Si tiene un sitio web que tiene varios subdominios, se recomienda crear un archivo robots.txt individual para cada uno. Esto mantiene las cosas organizadas y ayuda a los rastreadores de los motores de búsqueda a comprender sus reglas más fácilmente.
¡Terminando!
El archivo robots.txt es una herramienta útil de SEO, ya que instruye a los robots de los motores de búsqueda sobre qué indexar y qué no.
Sin embargo, es importante usarlo con precaución. Dado que una configuración incorrecta puede resultar en la desindexación completa de su sitio web (por ejemplo, usando Disallow: /).
En general, la buena manera es permitir que los motores de búsqueda escaneen la mayor cantidad posible de su sitio mientras mantienen la información confidencial y evitan el contenido duplicado. Por ejemplo, puede usar la directiva Disallow para evitar páginas o directorios específicos o la directiva Allow para anular una regla Disallow para una página en particular.
También vale la pena mencionar que no todos los bots siguen las reglas proporcionadas en el archivo robots.txt, por lo que no es un método perfecto para controlar lo que se indexa. Pero sigue siendo una herramienta valiosa para tener en su estrategia de SEO.
Esperamos que esta guía lo ayude a aprender qué es un archivo robots.txt y cómo crear uno.
Para obtener más información, puede consultar estos otros recursos útiles:
- 15 consejos prácticos de blogs para nuevos blogueros
- Desbloquear el poder de las palabras clave de cola larga (Guía para principiantes)
Por último, síganos en Twitter para obtener actualizaciones periódicas sobre nuevos artículos.