
El archivo robots.txt de WordPress... Qué es y qué hace
Publicado: 2020-11-25¿Alguna vez te has preguntado qué es el archivo robots.txt y qué hace? Robots.txt se utiliza para comunicarse con los rastreadores web (conocidos como bots) utilizados por Google y otros motores de búsqueda. Les dice qué partes de su sitio web indexar y cuáles ignorar. Como tal, el archivo robots.txt puede ayudar a hacer (¡o potencialmente arruinar!) sus esfuerzos de SEO. Si desea que su sitio web se clasifique bien, ¡es esencial una buena comprensión de robots.txt!
¿Dónde se encuentra Robots.txt?
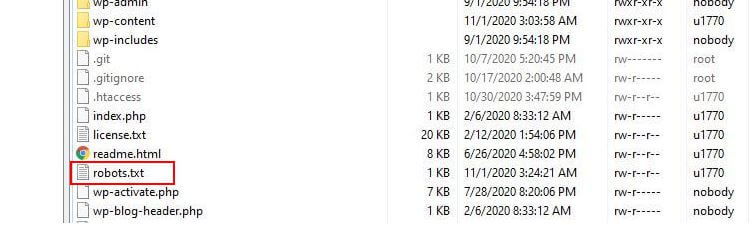
WordPress normalmente ejecuta un archivo llamado robots.txt 'virtual', lo que significa que no se puede acceder a él a través de SFTP. Sin embargo, puede ver su contenido básico yendo a yourdomain.com/robots.txt. Probablemente verás algo como esto:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpLa primera línea especifica a qué bots se aplicarán las reglas. En nuestro ejemplo, el asterisco significa que las reglas se aplicarán a todos los bots (por ejemplo, los de Google, Bing, etc.).
La segunda línea define una regla que impide el acceso de los bots a la carpeta /wp-admin y la tercera línea establece que los bots pueden analizar el archivo /wp-admin/admin-ajax.php.
Agregue sus propias reglas
Para un sitio web simple de WordPress, las reglas predeterminadas aplicadas por WordPress al archivo robots.txt pueden ser más que adecuadas. Sin embargo, si desea más control y la capacidad de agregar sus propias reglas para dar instrucciones más específicas a los robots de los motores de búsqueda sobre cómo indexar su sitio web, deberá crear su propio archivo físico robots.txt y colocarlo bajo la raíz. directorio de su instalación.
Hay varias razones por las que es posible que desee volver a configurar su archivo robots.txt y definir qué se les permitirá rastrear exactamente a esos bots. Una de las razones clave tiene que ver con el tiempo que dedica un bot a rastrear su sitio. Google (y otros) no permiten que los bots pasen tiempo ilimitado en cada sitio web... con billones de páginas, tienen que adoptar un enfoque más matizado sobre lo que sus bots rastrearán y lo que ignorarán en un intento de extraer la información más útil. sobre un sitio web.

Aloje su sitio web con Pressidium
GARANTÍA DE DEVOLUCIÓN DE DINERO DE 60 DÍAS
Cuando permite que los bots rastreen todas las páginas de su sitio web, una parte del tiempo de rastreo se dedica a páginas que no son importantes o incluso relevantes. Esto les deja menos tiempo para trabajar en las áreas más relevantes de su sitio. Al prohibir el acceso de bots a algunas partes de su sitio web, aumenta el tiempo disponible para que los bots extraigan información de las partes más relevantes de su sitio (que, con suerte, terminarán indexadas). Debido a que el rastreo es más rápido, es más probable que Google vuelva a visitar su sitio web y mantenga actualizado el índice de su sitio. Esto significa que es probable que las nuevas publicaciones de blog y otro contenido nuevo se indexen más rápido, lo cual es una buena noticia.
Ejemplos de edición de Robots.txt
El archivo robots.txt ofrece mucho espacio para la personalización. Como tal, proporcionamos una variedad de ejemplos de reglas que se pueden usar para dictar cómo los bots indexan su sitio.
Permitir o rechazar bots
Primero, veamos cómo podemos restringir un bot específico. Para ello solo tenemos que sustituir el asterisco (*) por el nombre del bot user-agent que queremos bloquear, por ejemplo 'MSNBot'. Una lista completa de agentes de usuario conocidos está disponible aquí.
User-agent: MSNBot Disallow: /Poner un guión en la segunda línea restringirá el acceso del bot a todos los directorios.
Para permitir que un solo bot rastree nuestro sitio, usaríamos un proceso de 2 pasos. Primero configuraríamos este bot como una excepción y luego rechazaríamos todos los bots como este:
User-agent: Google Disallow: User-agent: * Disallow: /Para permitir el acceso a todos los bots en todo el contenido, agregamos estas dos líneas:
User-agent: * Disallow:El mismo efecto se lograría simplemente creando un archivo robots.txt y luego dejándolo vacío.
Bloqueo del acceso a archivos específicos
¿Quiere evitar que los bots indexen ciertos archivos en su sitio web? ¡Eso es fácil! En el siguiente ejemplo, hemos impedido que los motores de búsqueda accedan a todos los archivos .pdf de nuestro sitio web.
User-agent: * Disallow: /*.pdf$El símbolo “$” se utiliza para definir el final de la URL. Dado que esto distingue entre mayúsculas y minúsculas, se seguirá rastreando un archivo con el nombre my.PDF (tenga en cuenta las MAYÚSCULAS).
Expresiones lógicas complejas
Algunos motores de búsqueda, como Google, entienden el uso de expresiones regulares más complicadas. Sin embargo, es importante tener en cuenta que no todos los motores de búsqueda pueden comprender las expresiones lógicas en robots.txt.

Un ejemplo de esto es usar el símbolo $. En archivos robots.txt este símbolo indica el final de una url. Entonces, en el siguiente ejemplo, hemos bloqueado los robots de búsqueda para que no lean e indexen archivos que terminan en .php.
Disallow: /*.php$Esto significa que /index.php no se puede indexar, pero /index.php?p=1 podría serlo. ¡Esto solo es útil en circunstancias muy específicas y debe usarse con precaución o corre el riesgo de bloquear el acceso de bots a archivos que no tenía la intención de bloquear!
También puede establecer diferentes reglas para cada bot especificando las reglas que se aplican a ellos individualmente. El código de ejemplo a continuación restringirá el acceso a la carpeta wp-admin para todos los bots y, al mismo tiempo, bloqueará el acceso a todo el sitio para el motor de búsqueda Bing. No necesariamente querrá hacer esto, pero es una demostración útil de cuán flexibles pueden ser las reglas en un archivo robots.txt.
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /Mapas de sitio XML
Los sitemaps XML realmente ayudan a los robots de búsqueda a comprender el diseño de su sitio web. Pero para ser útil, el bot necesita saber dónde se encuentra el mapa del sitio. La 'directiva del mapa del sitio' se usa para decirle específicamente a los motores de búsqueda que a) existe un mapa del sitio de su sitio yb) dónde pueden encontrarlo.
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:También puede especificar varias ubicaciones del mapa del sitio:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* DisallowRetrasos en el rastreo de bots
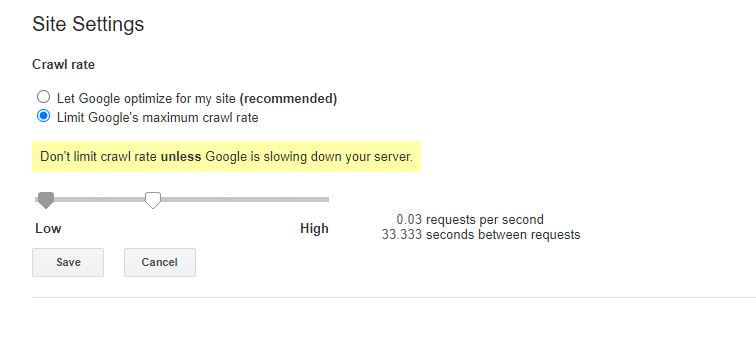
Otra función que se puede lograr a través del archivo robots.txt es decirles a los bots que 'reduzcan la velocidad' en el rastreo de su sitio. Esto podría ser necesario si descubre que su servidor está sobrecargado por altos niveles de tráfico de bots. Para hacer esto, debe especificar el agente de usuario que desea ralentizar y luego agregar un retraso.
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10El número de comillas (10) en este ejemplo es el retraso que desea que ocurra entre el rastreo de páginas individuales en su sitio. Entonces, en el ejemplo anterior, le pedimos al Bing Bot que haga una pausa de diez segundos entre cada página que rastrea y, al hacerlo, le damos a nuestro servidor un poco de espacio para respirar.
La única mala noticia sobre esta regla de robots.txt en particular es que el bot de Google no la respeta. Sin embargo, puede indicar a sus bots que reduzcan la velocidad desde Google Search Console.
Notas sobre las reglas de robots.txt:
- Todas las reglas de robots.txt distinguen entre mayúsculas y minúsculas. ¡Escriba con cuidado!
- Asegúrese de que no haya espacios antes del comando al comienzo de la línea.
- Los cambios realizados en robots.txt pueden tardar entre 24 y 36 horas en ser detectados por los bots.
Cómo probar y enviar su archivo robots.txt de WordPress
Cuando haya creado un nuevo archivo robots.txt, vale la pena comprobar que no contiene errores. Puede hacerlo utilizando la Consola de búsqueda de Google.
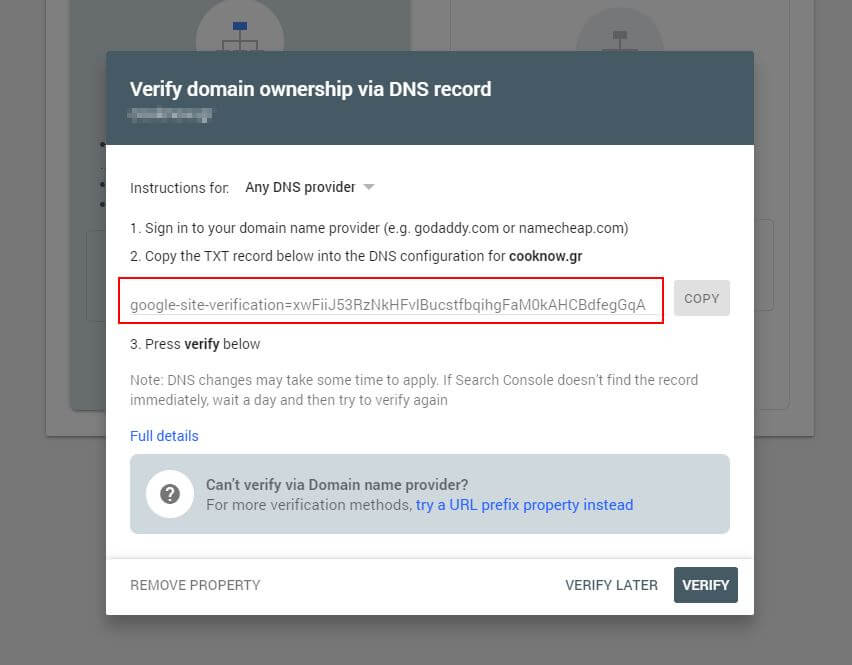
Primero, deberá enviar su dominio (si aún no tiene una cuenta de Search Console para la configuración de su sitio web). Google le proporcionará un registro TXT que debe agregarse a su DNS para verificar su dominio.
Una vez que esta actualización de DNS se haya propagado (te sientes impaciente… intenta usar Cloudflare para administrar tu DNS), puedes visitar el probador de robots.txt y comprobar si hay alguna advertencia sobre el contenido de tu archivo robots.txt.
Otra cosa que puede hacer para probar que las reglas que tiene implementadas tienen el efecto deseado es usar una herramienta de prueba de robots.txt como Ryte.
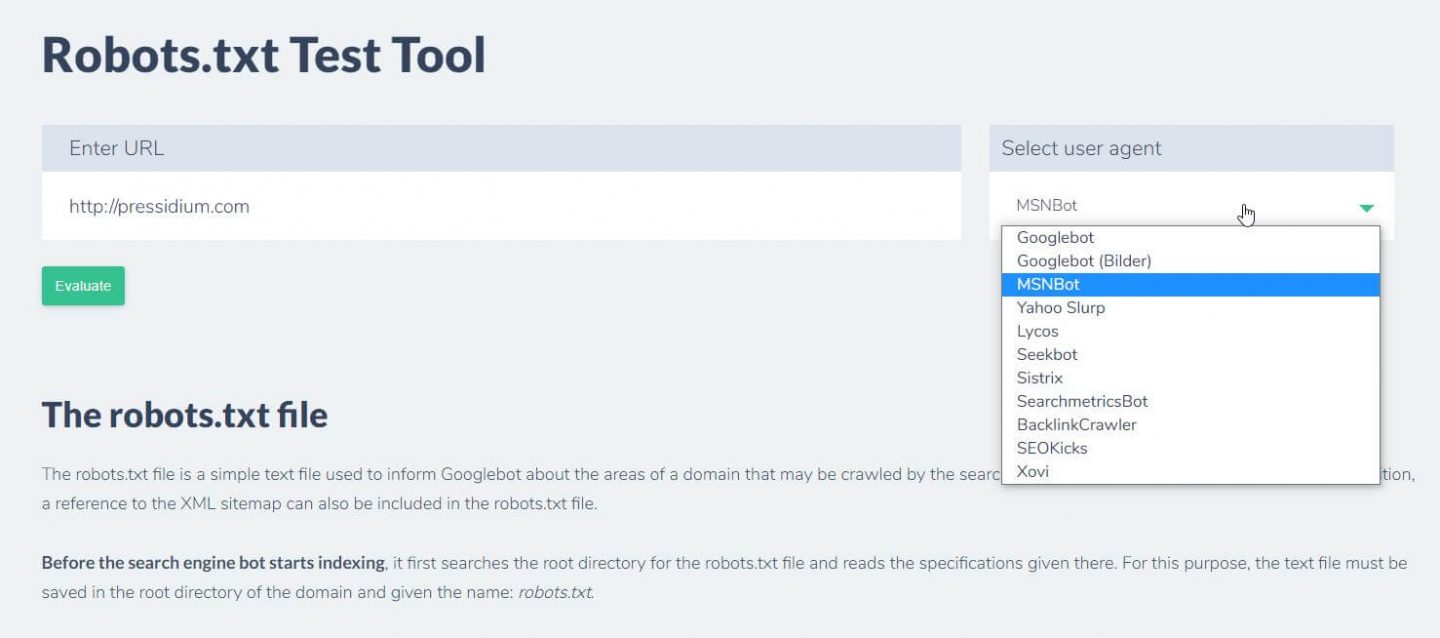
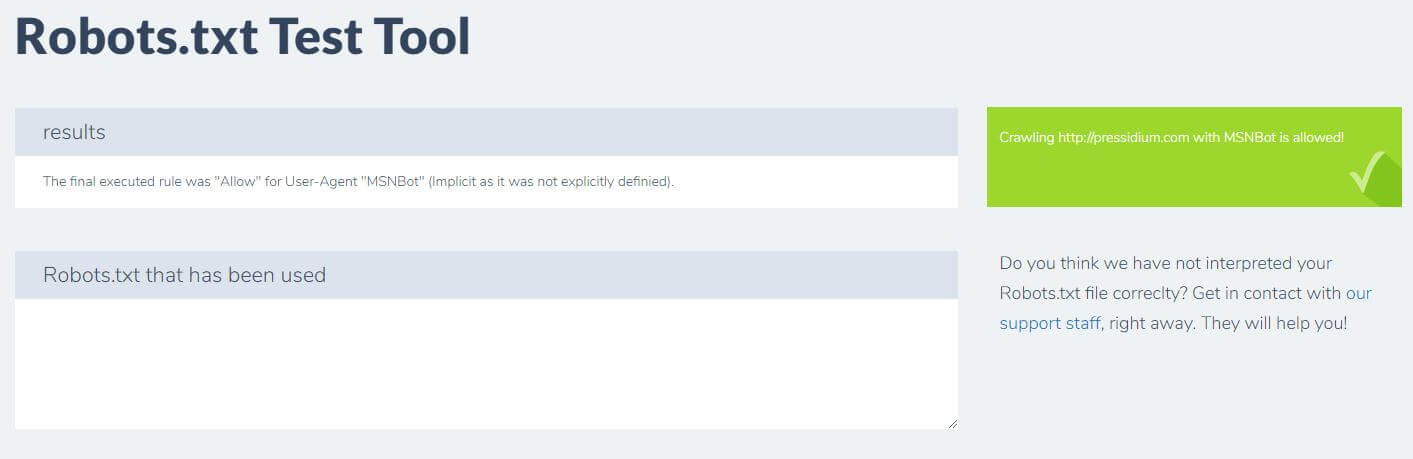
Simplemente ingrese su dominio y elija un agente de usuario del panel de la derecha. Después de enviar esto, verá los resultados.
Conclusión
Saber cómo usar robots.txt es otra herramienta útil en el kit de herramientas de su desarrollador. Si lo único que te llevas de este tutorial es la capacidad de verificar que tu archivo robots.txt no esté bloqueando bots como Google (lo que es muy poco probable que quieras hacer), ¡entonces eso no es malo! Del mismo modo, como puede ver, robots.txt ofrece una gran cantidad de control detallado adicional sobre su sitio web que algún día puede ser útil.