
14 erreurs WordPress Robots.txt courantes à éviter
Publié: 2025-01-14Robots.txt est un fichier serveur puissant qui indique aux robots de recherche et autres robots comment se comporter sur votre site Web WordPress. Cela peut grandement influencer l’optimisation des moteurs de recherche (SEO) de votre site, à la fois positivement et négativement.
Pour cette raison, vous devez savoir ce qu’est ce fichier et comment l’utiliser. Sinon, vous pourriez endommager votre site Web ou, du moins, laisser de côté une partie de son potentiel.
Pour vous aider à éviter ce scénario, dans cet article, nous aborderons en détail le fichier robots.txt. Nous définirons de quoi il s'agit, son objectif, comment retrouver et gérer votre dossier, et ce qu'il doit contenir. Après cela, nous passerons en revue les erreurs les plus courantes commises par les gens avec leur fichier robots.txt WordPress, les moyens de les éviter et comment récupérer si vous constatez que vous avez commis une erreur.
Qu'est-ce que le fichier robots.txt de WordPress ?
Comme mentionné, robots.txt est un fichier de configuration du serveur. Vous le trouvez généralement dans le dossier racine de votre serveur.
Lorsque vous l'ouvrez, le contenu ressemble à ceci :
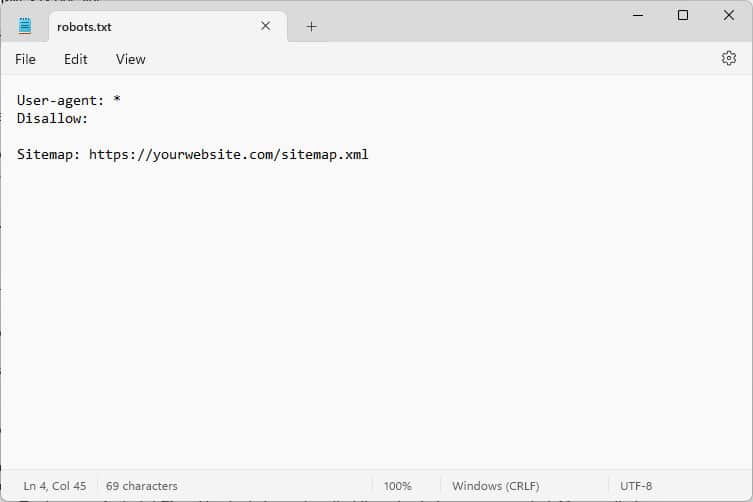
Ces morceaux de code sont des instructions qui indiquent aux robots qui accèdent à votre site Web comment se comporter lorsqu'ils y sont, en particulier, à quelles parties de votre site Web accéder et lesquelles non.
Quels robots, demandez-vous ?
Les exemples les plus courants sont les robots d’exploration automatiques des moteurs de recherche recherchant des pages Web à indexer ou à mettre à jour, mais aussi les robots issus de modèles d’IA et d’autres outils automatisés.
Quelles directives pouvez-vous donner avec ce fichier ?
Robots.txt connaît essentiellement quatre directives clés :
- Agent utilisateur – Définit à qui, c'est-à-dire à quel groupe de robots ou à quels robots individuels s'adressent les règles qui suivent.
- Interdire – Indique les répertoires, fichiers ou ressources auxquels l'agent utilisateur n'a pas le droit d'accéder.
- Autoriser – Peut être utilisé pour configurer des exceptions, par exemple pour autoriser l'accès à des dossiers ou des ressources individuels dans des répertoires autrement interdits.
- Plan du site – Dirige les robots vers l'emplacement URL du plan du site d'un site Web.
Seuls User-agent et Disallow sont obligatoires pour que le fichier fasse son travail ; les deux autres directives sont facultatives. Par exemple, voici comment empêcher les robots d'accéder à votre site :
User-agent: * Disallow: /L'astérisque indique que la règle suivante s'applique à tous les agents utilisateurs. La barre oblique après Disallow indique que tous les répertoires de ce site sont interdits. Il s’agit du fichier robots.txt que l’on retrouve habituellement sur les sites de développement, qui ne sont pas censés être indexés par les moteurs de recherche.
Cependant, vous pouvez également définir des règles pour des robots individuels :
User-agent: Googlebot Allow: /private/resources/Il est important de noter que le fichier robots.txt n'est pas contraignant. Seuls les robots des organisations qui adhèrent au protocole d’exclusion des robots obéiront à ses instructions. Les robots malveillants, tels que ceux qui recherchent des failles de sécurité sur votre site, peuvent les ignorer et vous devez prendre des mesures supplémentaires à leur encontre.
Même les organisations qui adhèrent à la norme ignoreront certaines directives. Nous en parlerons des exemples plus loin.
Pourquoi le fichier robots.txt est-il important ?
Il n'est pas obligatoire que votre site WordPress ait un fichier robots.txt. Votre site fonctionnera sans celui-ci et les moteurs de recherche ne vous pénaliseront pas pour ne pas l'avoir. Cependant, en inclure un vous permet de :
- Gardez le contenu hors des résultats de recherche, comme les pages de connexion ou certains fichiers multimédias.
- Empêchez les robots de recherche de gaspiller votre budget d'exploration sur des parties sans importance de votre site, en ignorant éventuellement les pages que vous souhaitez qu'ils indexent.
- Dirigez les moteurs de recherche vers votre plan de site afin qu’ils puissent explorer plus facilement le reste de votre site Web.
- Préservez les ressources du serveur en éloignant les robots inutiles.
Tout cela contribue à améliorer votre site, en particulier votre référencement, c'est pourquoi il est important que vous compreniez comment utiliser robots.txt.
Comment rechercher, modifier et créer votre robots.txt WordPress
Comme mentionné, le fichier robots.txt se trouve généralement dans le dossier racine de votre site Web sur le serveur. Vous pouvez y accéder avec un client FTP comme FileZilla et le modifier avec n'importe quel éditeur de texte.
Si vous n'en avez pas, il est possible de simplement créer un fichier texte vide, de le nommer « robots.txt », de le remplir de directives et de le télécharger.
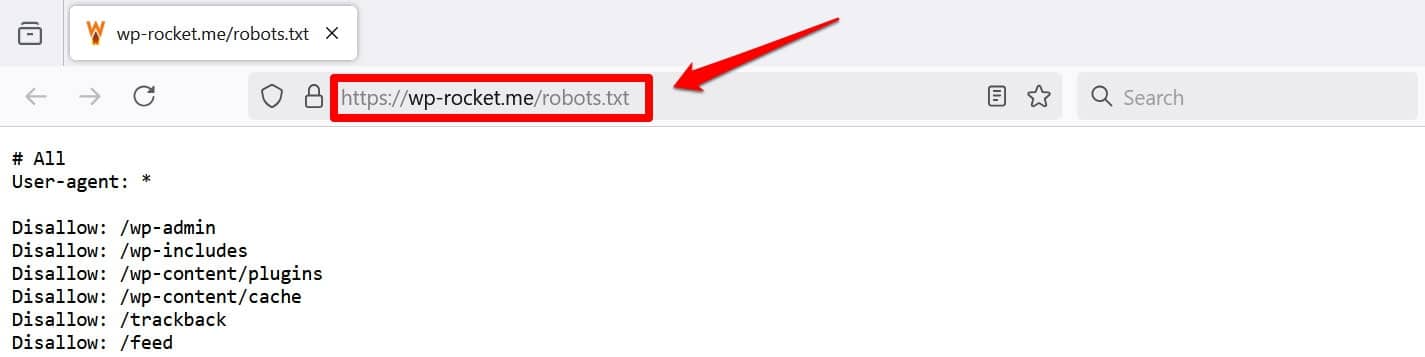
Une autre façon de visualiser au moins votre fichier consiste à ajouter /robots.txt à votre domaine, par exemple https://wp-rocket.me/robots.txt.
De plus, il existe des moyens d’accéder au fichier depuis le back-end WordPress. De nombreux plugins SEO permettent de le voir et souvent d’y apporter des modifications depuis l’interface d’administration.
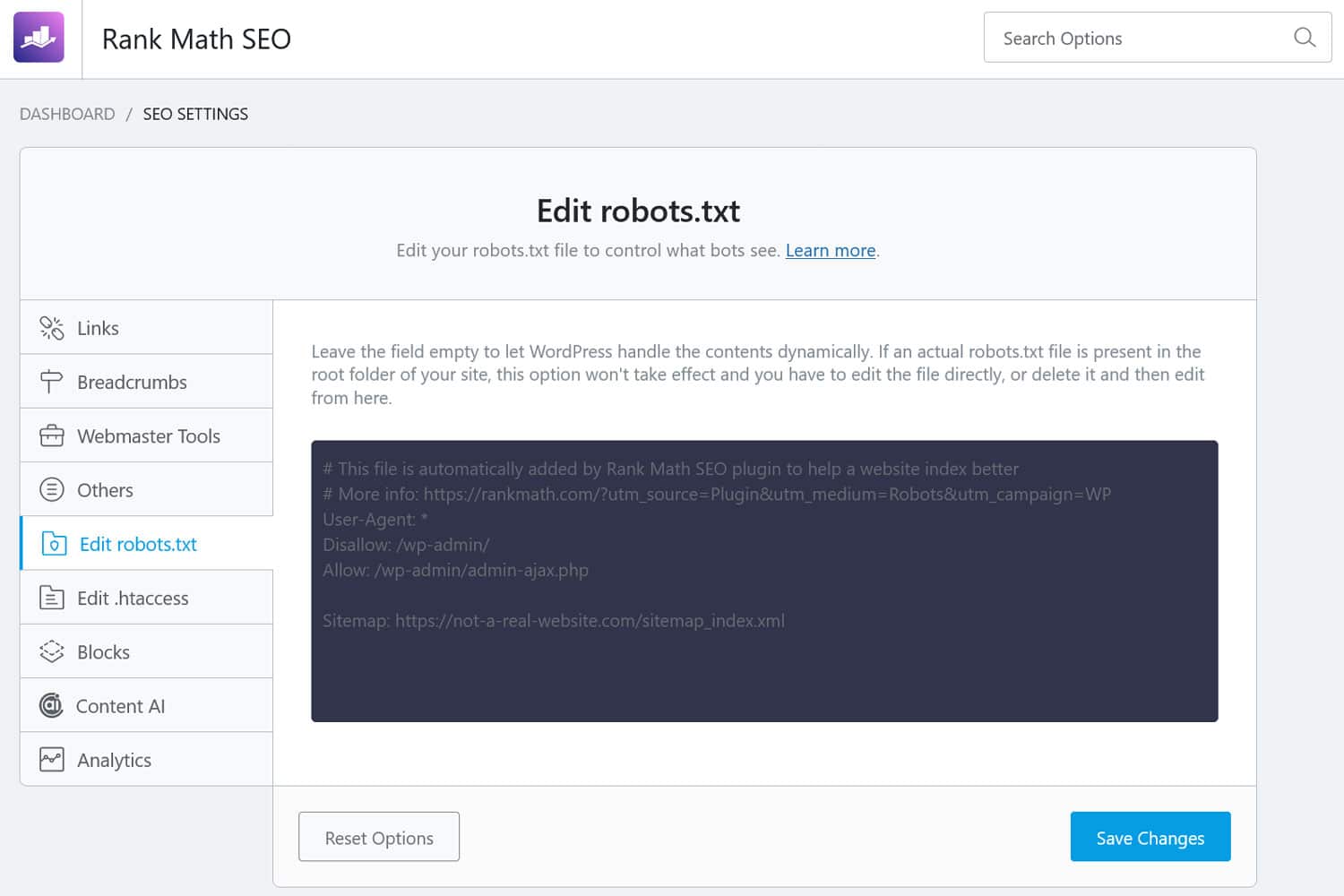
Alternativement, vous pouvez également utiliser un plugin comme WPCode.
À quoi ressemble un bon fichier robots.txt WordPress ?
Il n’existe pas de réponse unique quant aux directives qui doivent figurer dans le fichier de votre site Web ; cela dépend de votre configuration. Voici un exemple qui a du sens pour de nombreux sites WordPress :
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://yourwebsite.com/sitemap.xmlCet exemple permet d'obtenir plusieurs résultats :
- Il bloque l'accès à la zone d'administration
- Permet d'accéder aux fonctionnalités d'administration essentielles
- Fournit un emplacement sur le plan du site
Cette configuration établit un équilibre entre la sécurité, les performances de référencement et une exploration efficace.
Ne faites pas ces 14 erreurs WordPress robots.txt
Si votre objectif est de configurer et d'optimiser le fichier robots.txt pour votre propre site, veillez à éviter les erreurs suivantes.
1. Ignorer le fichier robots.txt interne de WordPress
Même si vous n'avez pas de fichier robots.txt « physique » dans le répertoire racine de votre site, WordPress est livré avec son propre fichier virtuel. Il est particulièrement important de s’en souvenir si vous constatez que les moteurs de recherche n’indexent pas votre site Web.
Dans ce cas, il y a de fortes chances que vous ayez activé l'option pour les décourager de le faire sous Paramètres > Lecture .
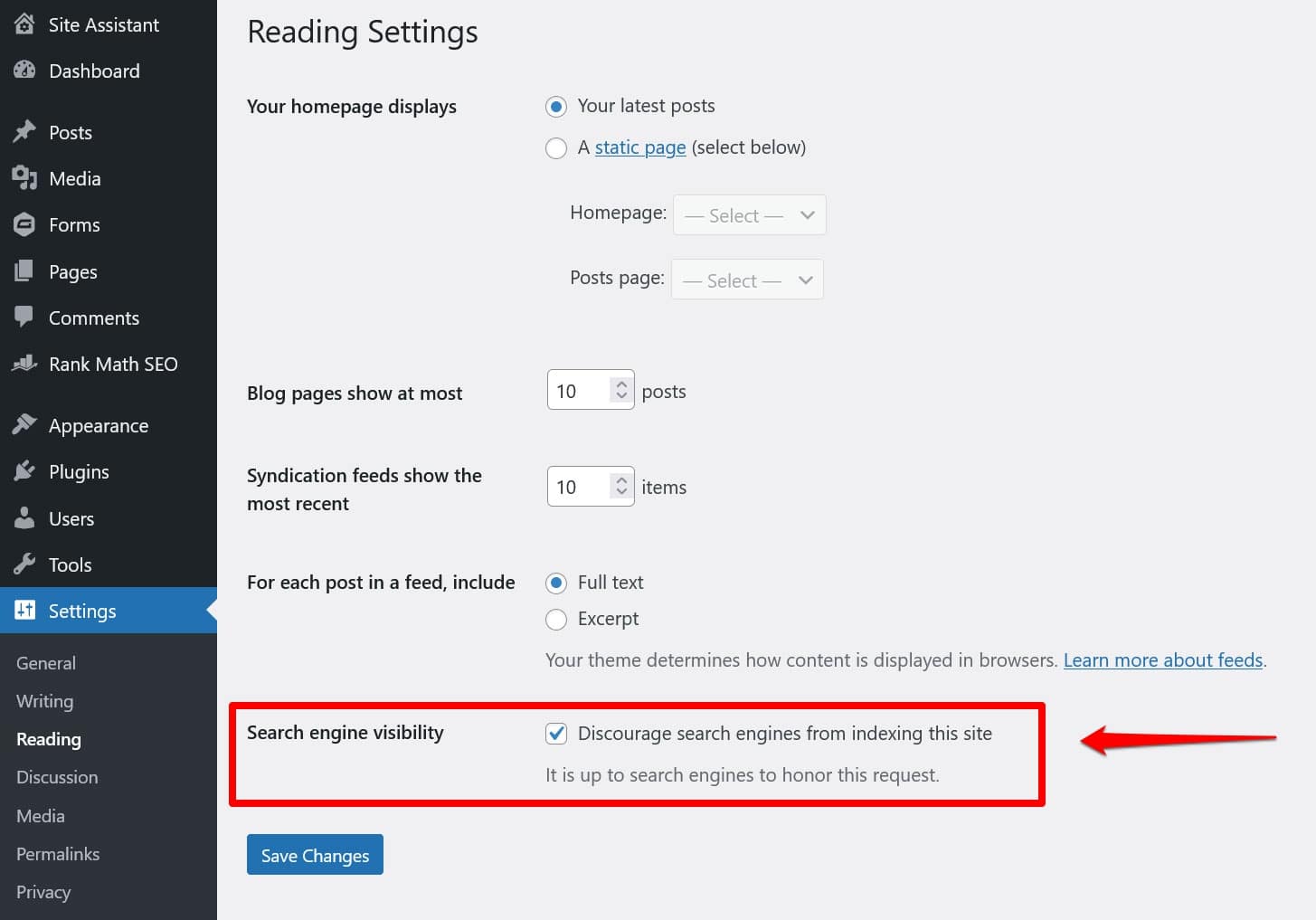
Cela met une directive pour garder tous les robots de recherche à l'écart dans le fichier robots.txt virtuel. Pour le désactiver, décochez la case et enregistrez-la en bas.
2. Le placer au mauvais endroit
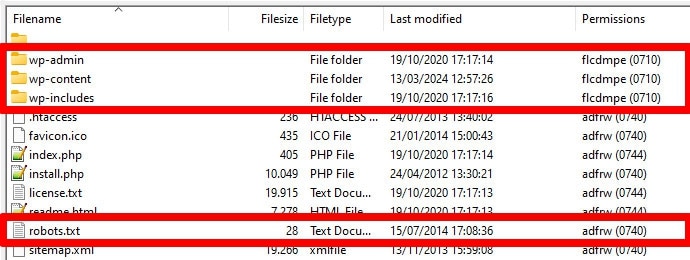
Les robots, en particulier les robots de recherche, recherchent votre fichier robots.txt uniquement à un seul emplacement : le répertoire racine de votre site Web. Si vous le placez ailleurs, par exemple dans un dossier, ils ne le trouveront pas et l'ignoreront.
Votre répertoire racine doit être celui où vous atterrissez lorsque vous accédez à votre serveur via FTP, sauf si vous avez placé WordPress dans un sous-répertoire. Si vous voyez les dossiers wp-admin , wp-content et wp-includes , vous êtes au bon endroit.
3. Y compris le balisage obsolète
Outre les directives mentionnées ci-dessus, il y en a deux autres que vous pouvez encore trouver dans les fichiers robots.txt des anciens sites Web :
- Noindex – Utilisé pour spécifier les URL que les moteurs de recherche ne sont pas censés indexer sur votre site.
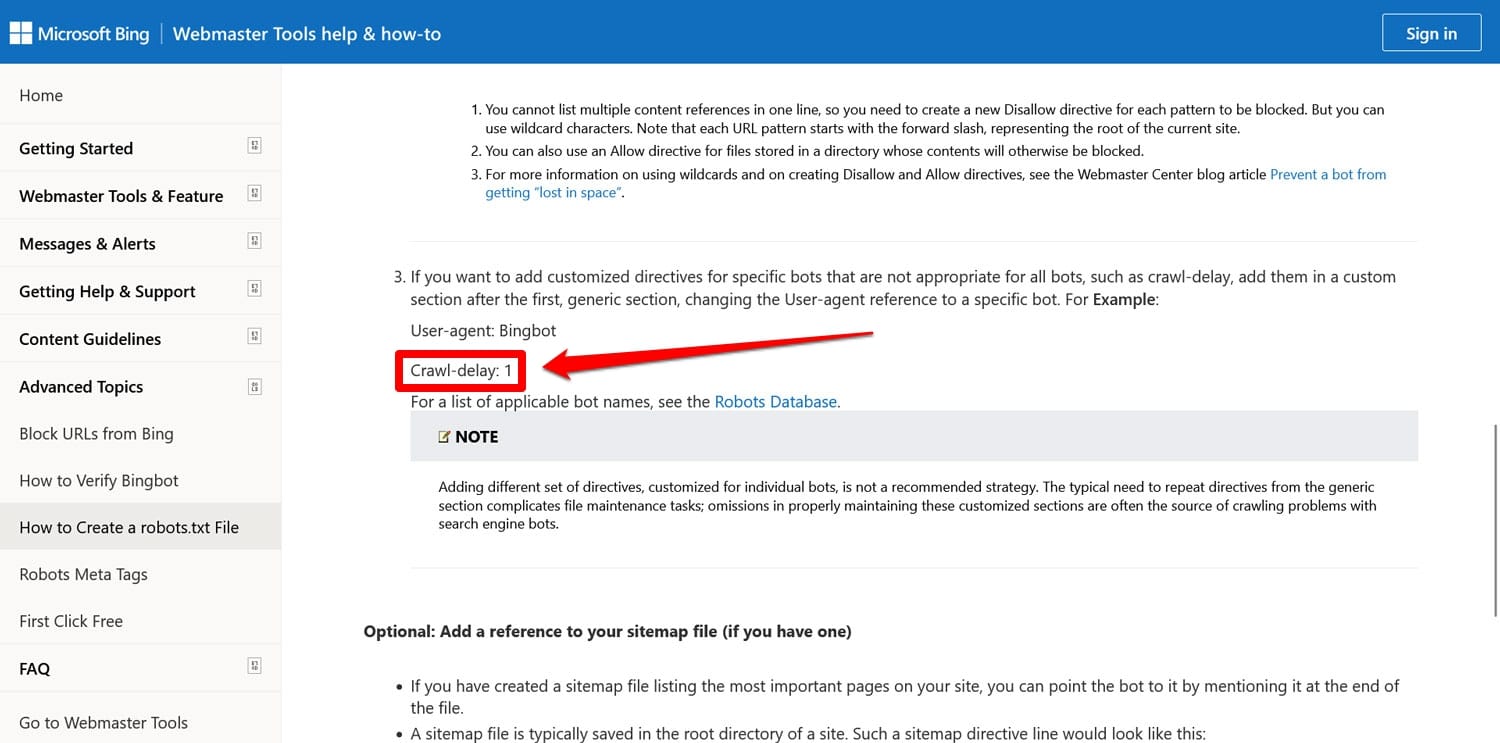
- Crawl-delay – Une directive destinée à limiter les robots d'exploration afin qu'ils ne surchargent pas les ressources du serveur Web.
Ces deux directives sont désormais ignorées, du moins par Google. Bing, au moins, respecte toujours le délai d'exploration.
Pour la plupart, il est préférable de ne pas utiliser ces directives. Cela permet de garder votre fichier léger et réduit le risque d’erreurs.
Astuce : Si votre objectif est d’empêcher les moteurs de recherche d’indexer certaines pages, utilisez plutôt la balise méta noindex . Vous pouvez l’implémenter avec un plugin SEO page par page.
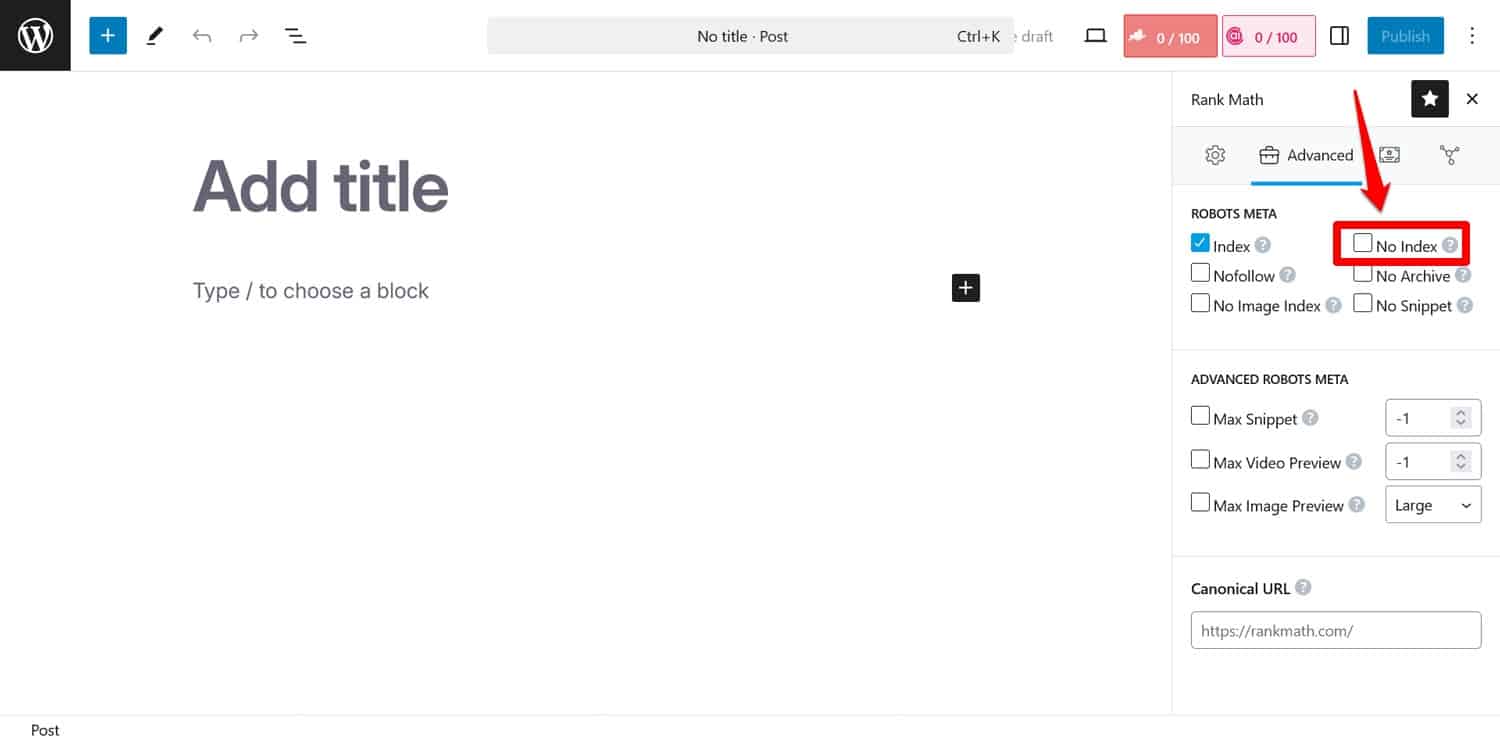
Si vous bloquez des pages via robots.txt, les robots d'exploration n'accéderont pas à la partie où ils voient la balise noindex . De cette façon, ils peuvent toujours indexer votre page mais sans son contenu, ce qui est pire.
4. Bloquer les ressources essentielles
L'une des erreurs commises par les gens est d'utiliser robots.txt pour bloquer l'accès à toutes les feuilles de style (fichiers CSS) et scripts (fichiers JavaScript) sur leur site WordPress afin de préserver le budget d'exploration.
Cependant, ce n'est pas une bonne idée. Les robots des moteurs de recherche affichent les pages pour les « voir » de la même manière que les visiteurs. Cela les aide à comprendre le contenu afin de pouvoir l'indexer en conséquence.
En bloquant ces ressources, vous pourriez donner aux moteurs de recherche une mauvaise impression de vos pages, ce qui pourrait les amener à ne pas être indexées correctement ou nuire à leur classement.
Si vous pensez que les fichiers CSS et JavaScript pourraient nuire aux performances de votre site, il est préférable de les optimiser pour qu'ils se chargent rapidement, à la fois pour les robots et les visiteurs réguliers. Vous pouvez le faire en réduisant le code et en compressant les fichiers du site Web afin qu'ils soient transmis plus rapidement. De plus, il est possible d'optimiser leur livraison en éliminant le code inutilisé et en différant les ressources bloquant le rendu.

Astuce : Vous pouvez simplifier ce processus en utilisant un plugin de performance comme WP Rocket. Son interface conviviale vous permet d'optimiser la livraison des fichiers en cochant quelques cases dans le menu Optimisation des fichiers .
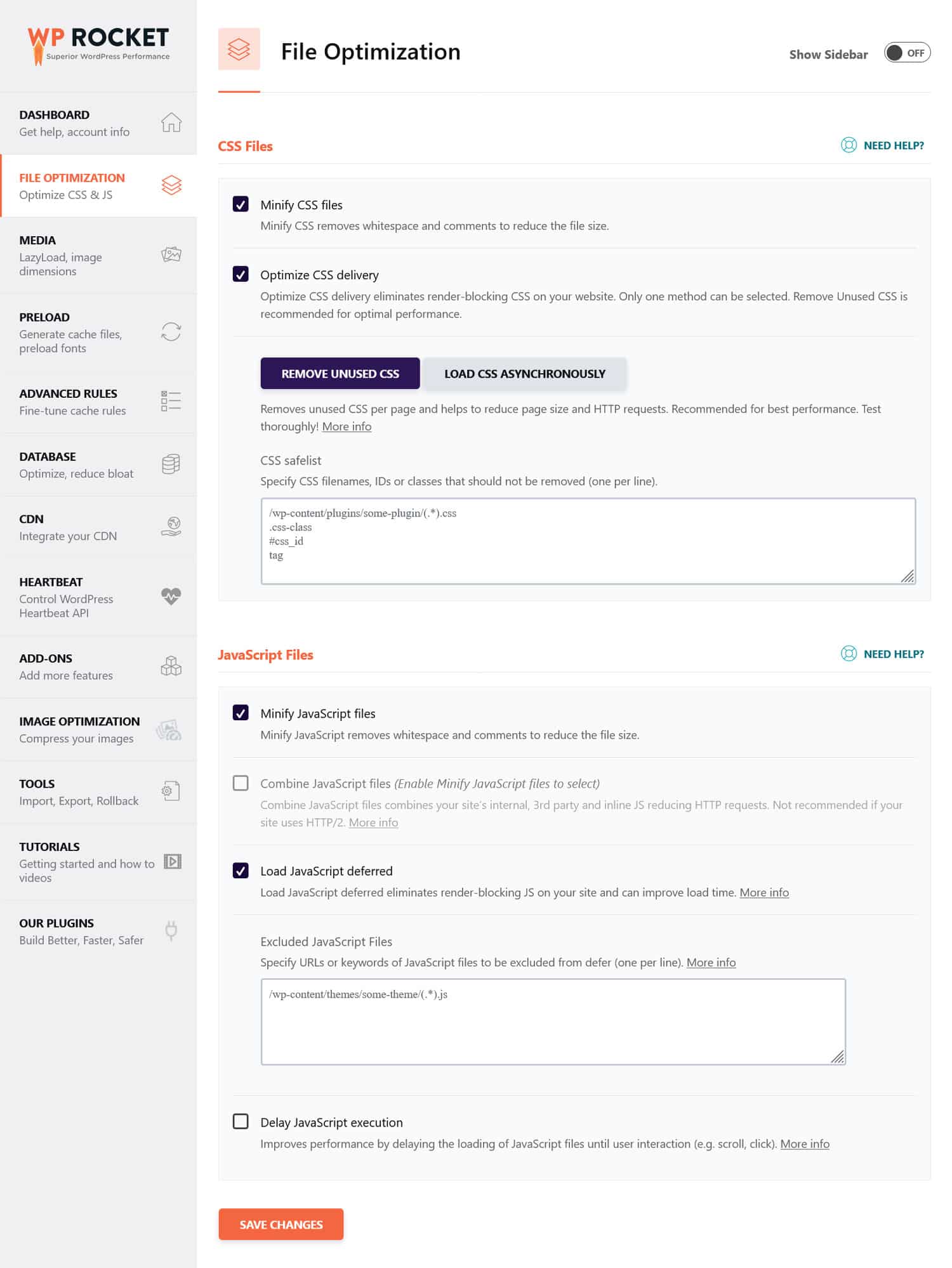
WP Rocket est également livré avec des fonctionnalités supplémentaires pour améliorer les performances du site Web, notamment :
- Mise en cache, avec un cache mobile dédié
- Chargement paresseux pour les images et les vidéos
- Préchargement du cache, des liens, des fichiers externes et des polices
- Optimisation de la base de données
De plus, le plugin implémente automatiquement de nombreuses étapes d’optimisation. Les exemples incluent la mise en cache du navigateur et du serveur, la compression GZIP et l'optimisation des images au-dessus de la ligne de flottaison pour améliorer le LCP. De cette façon, votre site deviendra plus rapide simplement en activant WP Rocket.
Le plugin offre également une garantie de remboursement de 14 jours, vous pouvez donc le tester sans risque.
5. Échec de la mise à jour de votre robots.txt de développement
Lors de la création d'un site Web, les développeurs incluent généralement un fichier robots.txt qui interdit à tous les robots d'y accéder. Cela a du sens ; la dernière chose que vous souhaitez, c'est que votre site inachevé apparaisse dans les résultats de recherche.
Un problème ne se produit que lorsque vous transférez accidentellement ce fichier sur votre serveur de production et empêchez également les moteurs de recherche d'indexer votre site Web en direct. Vérifiez certainement ceci si votre contenu refuse d’apparaître dans les résultats de recherche.
6. Ne pas inclure de lien vers votre plan de site
Un lien vers votre plan de site à partir de robots.txt fournit aux robots des moteurs de recherche une liste de tout votre contenu. Cela augmente vos chances qu'ils indexent plus que la page actuelle sur laquelle ils ont atterri.
Il suffit d'une seule ligne :
Sitemap: https://yourwebsite.com/sitemap.xmlOui, vous pouvez également soumettre votre plan de site directement dans des outils comme Google Search Console.
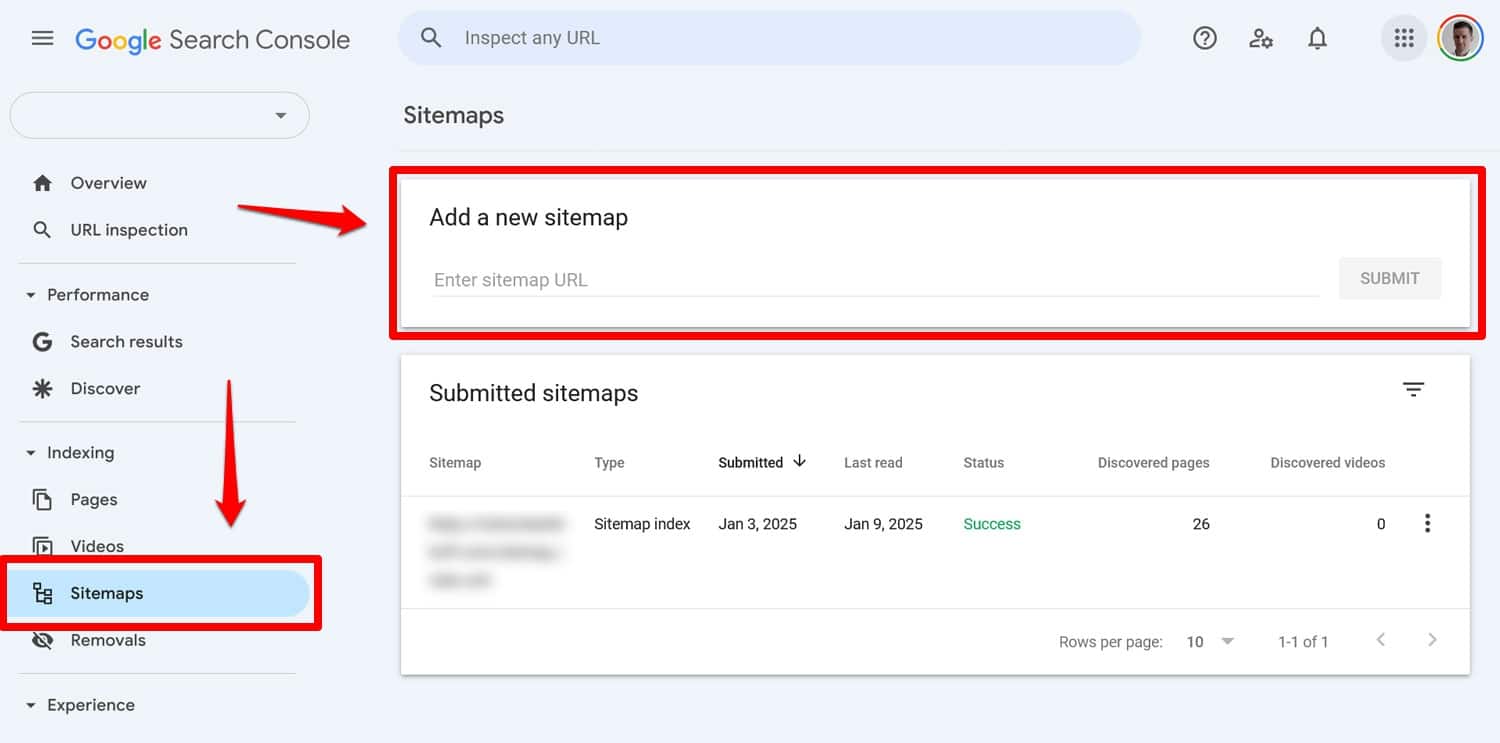
Cependant, l’inclure dans votre fichier robots.txt reste utile, notamment pour les moteurs de recherche dont vous n’utilisez pas les outils pour les webmasters.
7. Utiliser des règles contradictoires
Une erreur courante lors de la création d'un fichier robots.txt consiste à ajouter des règles qui se contredisent, telles que :
User-agent: * Disallow: /blog/ Allow: /blog/Les directives ci-dessus ne permettent pas aux moteurs de recherche de savoir s'ils doivent ou non explorer le répertoire /blog/ . Cela conduit à des résultats imprévisibles et peut nuire à votre référencement.
| Curieux de savoir quoi d'autre peut nuire au classement de recherche de votre site et comment l'éviter ? Découvrez-le dans notre guide des erreurs de référencement. |
Pour éviter les conflits, suivez ces bonnes pratiques :
- Utilisez d’abord des règles spécifiques – Placez les règles plus spécifiques avant les règles plus larges.
- Évitez la redondance – N'incluez pas de directives opposées pour le même chemin.
- Testez votre fichier robots.txt – Utilisez des outils pour confirmer que les règles se comportent comme prévu. Plus d’informations à ce sujet ci-dessous.
8. Essayer de masquer du contenu sensible avec robots.txt
Comme mentionné précédemment, robots.txt n'est pas un outil permettant d'exclure le contenu des résultats de recherche. En fait, comme le fichier est accessible au public, son utilisation pour bloquer un contenu sensible peut révéler par inadvertance exactement où se trouve ce contenu.
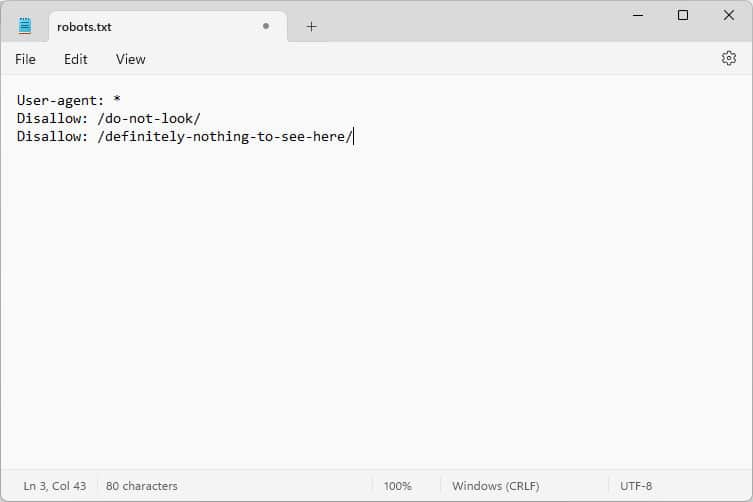
Astuce : utilisez la balise méta noindex pour garder le contenu hors des résultats de recherche. De plus, protégez par mot de passe les zones sensibles de votre site pour les protéger des robots et des utilisateurs non autorisés.
9. Utilisation inappropriée de caractères génériques
Les caractères génériques vous permettent d'inclure de grands groupes de chemins ou de fichiers dans vos directives. Nous en avons déjà rencontré un plus tôt, le symbole *. Cela signifie « chaque instance de » et il est le plus fréquemment utilisé pour définir des règles qui s'appliquent à tous les agents utilisateurs.
Un autre symbole générique est $, qui applique des règles à la fin d'une URL. Vous pouvez l'utiliser, par exemple, si vous souhaitez empêcher les robots d'exploration d'accéder à tous les fichiers PDF de votre site :
Disallow: /*.pdf$Même si les caractères génériques sont utiles, ils peuvent avoir des conséquences considérables. Utilisez-les avec précaution et testez toujours votre fichier robots.txt pour vous assurer que vous n'avez commis aucune erreur.
10. Confondre les URL absolues et relatives
Voici la différence entre les URL absolues et relatives :
- URL absolue – https://yourwebsite.com/private/
- URL relative – /privée/
Il est recommandé d'utiliser des URL relatives dans vos directives robots.txt, par exemple :
Disallow: /private/Les URL absolues peuvent provoquer des problèmes où les robots peuvent ignorer ou mal interpréter la directive. La seule exception est le chemin d'accès à votre plan de site, qui doit être une URL absolue.
11. Ignorer la sensibilité à la casse
Les directives Robots.txt sont sensibles à la casse. Cela signifie que les deux directives suivantes ne sont pas interchangeables :
Disallow: /Private/ Disallow: /private/Si vous constatez que votre fichier robots.txt ne se comporte pas comme prévu, vérifiez si une majuscule incorrecte pourrait être à l'origine du problème.
12. Utilisation incorrecte des barres obliques finales
Une barre oblique finale est une barre oblique à la fin d'une URL :
- Sans barre oblique finale : /répertoire
- Avec une barre oblique finale : /répertoire/
Dans robots.txt, il décide quelles ressources du site sont autorisées et interdites. Voici un exemple :
Disallow: /private/La règle ci-dessus empêche les robots d'accéder au répertoire « privé » de votre site et à tout ce qu'il contient. D'un autre côté, disons que vous laissez de côté la barre oblique finale, comme ceci :
Disallow: /privateDans ce cas, la règle bloquerait également d'autres instances commençant par « privé » sur votre site, telles que :
- https://votresiteweb.com/private.html
- https://votresiteweb.com/privateer
Il est donc important d'être précis. En cas de doute, testez votre fichier.
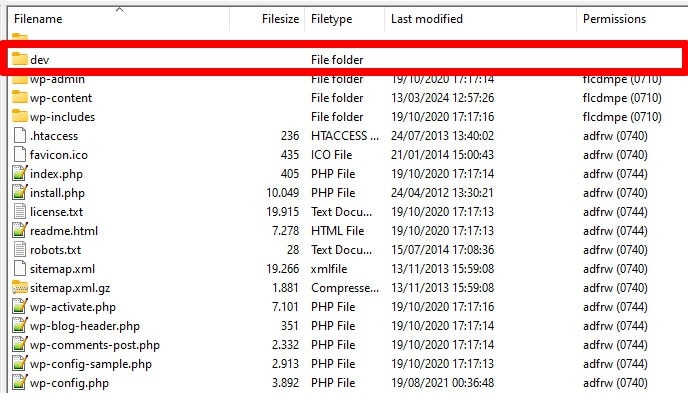
13. Robots.txt manquant pour les sous-domaines
Chaque sous-domaine de votre site Web (par exemple, dev.votresiteweb.com) a besoin de son propre fichier robots.txt, car les moteurs de recherche les traitent comme des entités Web distinctes. Sans fichier en place, vous risquez que les robots indexent les parties de votre site que vous aviez l’intention de garder cachées.
Par exemple, si votre version de développement se trouve dans un dossier appelé « dev » et utilise un sous-domaine, assurez-vous qu'elle dispose d'un fichier robots.txt dédié pour bloquer les robots de recherche.
14. Ne pas tester votre fichier robots.txt
L’une des plus grosses erreurs lors de la configuration de votre fichier robots.txt WordPress est de ne pas le tester, surtout après avoir apporté des modifications.
Comme nous l’avons vu, même de petites erreurs de syntaxe ou de logique peuvent entraîner d’importants problèmes de référencement. Par conséquent, testez toujours votre fichier robots.txt.
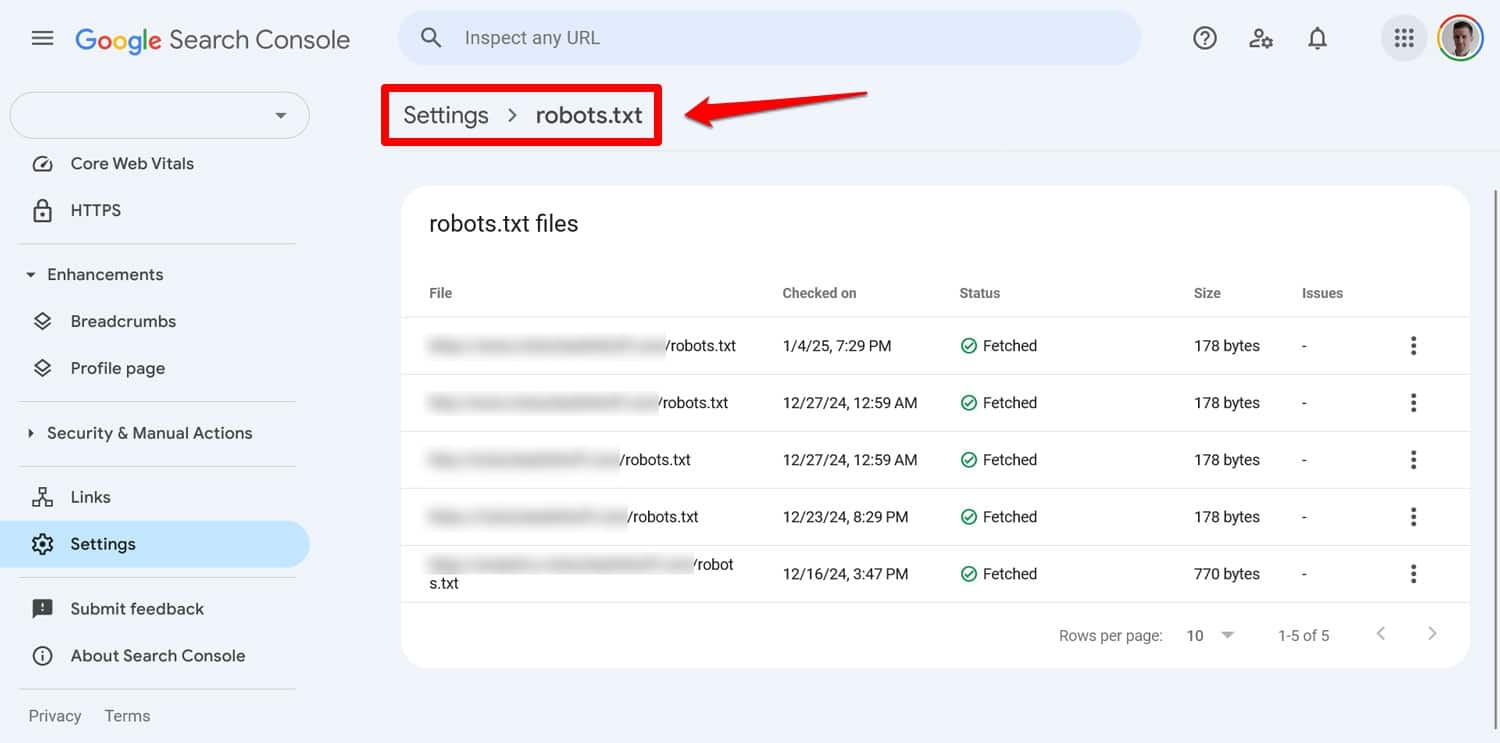
Vous pouvez voir tout problème avec votre fichier dans Google Search Console sous Paramètres > robots.txt .
Une autre façon consiste à simuler le comportement d'exploration avec un outil comme Screaming Frog. De plus, utilisez un environnement de test pour vérifier l’impact des nouvelles règles avant de les appliquer à votre site en ligne.
Comment récupérer d'une erreur robots.txt
Les erreurs dans votre fichier robots.txt sont faciles à commettre, mais heureusement, elles sont aussi généralement simples à corriger une fois que vous les avez découvertes.
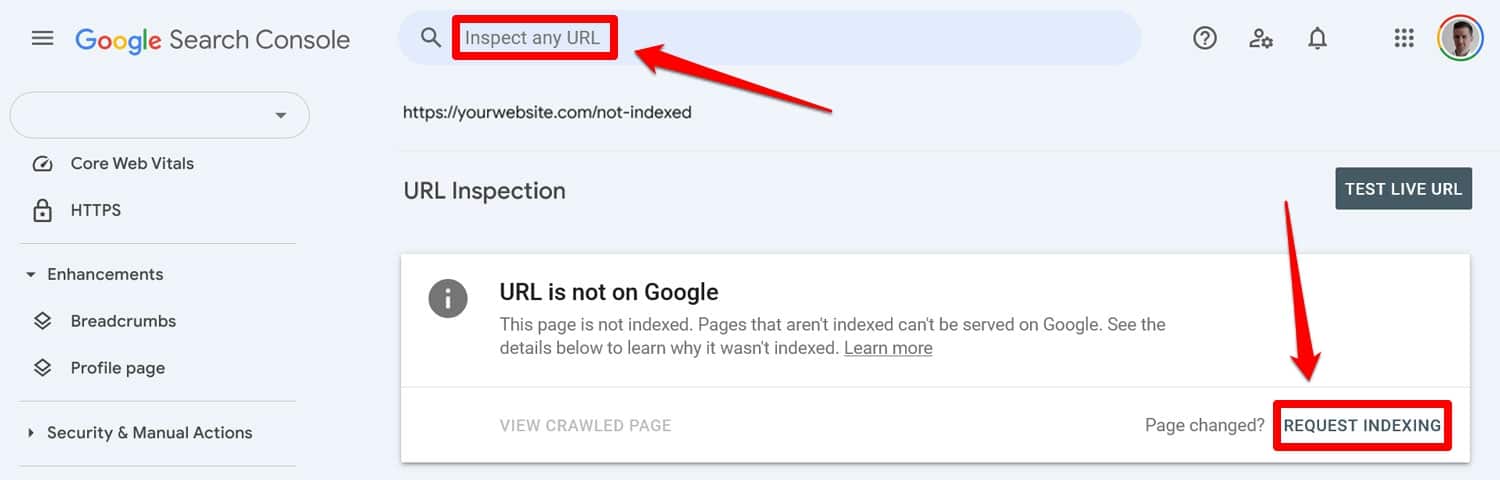
Commencez par exécuter votre fichier robots.txt mis à jour via un outil de test. Ensuite, si les pages étaient auparavant bloquées par les directives robots.txt, saisissez-les manuellement dans Google Search Console ou Bing Webmaster Tools pour demander l'indexation.
De plus, soumettez à nouveau une version à jour de votre plan de site.
Après cela, ce n'est plus qu'un jeu d'attente. Les moteurs de recherche revisiteront votre site et, espérons-le, rétabliront rapidement votre place dans le classement.
Prenez le contrôle de votre robots.txt WordPress
Avec les fichiers robots.txt, mieux vaut prévenir que guérir. Surtout sur les sites Web plus importants, un fichier défectueux peut avoir des conséquences désastreuses sur les classements, le trafic et les revenus.
Pour cette raison, toute modification apportée au fichier robots.txt de votre site doit être effectuée avec soin et avec des tests approfondis. Prendre conscience des erreurs que vous pouvez commettre est une première étape pour les prévenir.
Lorsque vous faites une erreur, essayez de ne pas paniquer. Diagnostiquez ce qui ne va pas, corrigez les erreurs et soumettez à nouveau votre plan de site pour que votre site soit réexploré.
Enfin, assurez-vous que les performances ne sont pas la raison pour laquelle les moteurs de recherche n'explorent pas correctement votre site. Essayez WP Rocket maintenant pour rendre votre site plus rapide instantanément !