
Liste des robots d'exploration : robots d'indexation Web et comment les exploiter pour réussir
Publié: 2022-12-03Pour la plupart des spécialistes du marketing, des mises à jour constantes sont nécessaires pour maintenir la fraîcheur de leur site et améliorer leur classement SEO.
Cependant, certains sites ont des centaines voire des milliers de pages, ce qui en fait un défi pour les équipes qui envoient manuellement les mises à jour aux moteurs de recherche. Si le contenu est mis à jour si fréquemment, comment les équipes peuvent-elles s'assurer que ces améliorations ont un impact sur leur classement SEO ?
C'est là que les robots d'exploration entrent en jeu. Un robot d'exploration Web grattera votre sitemap pour de nouvelles mises à jour et indexera le contenu dans les moteurs de recherche.
Dans cet article, nous présenterons une liste complète des robots d'exploration qui couvre tous les robots d'exploration du Web que vous devez connaître. Avant de plonger, définissons les robots d'indexation Web et montrons comment ils fonctionnent.
Qu'est-ce qu'un robot d'indexation ?
Un robot d'exploration Web est un programme informatique qui analyse automatiquement et lit systématiquement les pages Web afin d'indexer les pages pour les moteurs de recherche. Les robots d'exploration Web sont également connus sous le nom d'araignées ou de bots.
Pour que les moteurs de recherche présentent des pages Web pertinentes et à jour aux utilisateurs lançant une recherche, une exploration à partir d'un robot d'exploration Web doit se produire. Ce processus peut parfois se produire automatiquement (selon les paramètres du robot d'exploration et de votre site), ou il peut être lancé directement.
De nombreux facteurs ont un impact sur le classement SEO de vos pages, notamment la pertinence, les backlinks, l'hébergement Web, etc. Cependant, rien de tout cela n'a d'importance si vos pages ne sont pas explorées et indexées par les moteurs de recherche. C'est pourquoi il est si vital de s'assurer que votre site permet aux explorations correctes d'avoir lieu et de supprimer tous les obstacles sur leur chemin.
Les robots doivent constamment scanner et gratter le Web pour s'assurer que les informations les plus précises sont présentées. Google est le site Web le plus visité aux États-Unis et environ 26,9 % des recherches proviennent d'utilisateurs américains :

Cependant, il n'y a pas un seul robot d'exploration Web qui explore chaque moteur de recherche. Chaque moteur de recherche a des atouts uniques, de sorte que les développeurs et les spécialistes du marketing établissent parfois une « liste de robots ». Cette liste de robots les aide à identifier différents robots d'exploration dans leur journal de site à accepter ou à bloquer.
Les spécialistes du marketing doivent assembler une liste complète des différents robots d'exploration Web et comprendre comment ils évaluent leur site (contrairement aux grattoirs de contenu qui volent le contenu) pour s'assurer qu'ils optimisent correctement leurs pages de destination pour les moteurs de recherche.
Comment fonctionne un robot d'exploration Web ?
Un robot d'indexation analysera automatiquement votre page Web après sa publication et indexera vos données.
Les robots d'exploration Web recherchent des mots clés spécifiques associés à la page Web et indexent ces informations pour les moteurs de recherche pertinents tels que Google, Bing, etc.
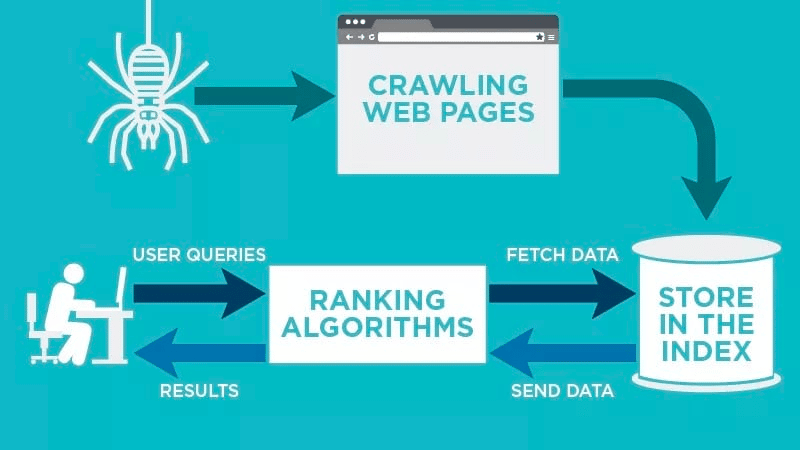
Les algorithmes des moteurs de recherche récupèrent ces données lorsqu'un utilisateur soumet une demande pour le mot-clé pertinent qui y est lié.
Les explorations commencent par des URL connues. Ce sont des pages Web établies avec divers signaux qui dirigent les robots d'exploration Web vers ces pages. Ces signaux pourraient être :
- Backlinks : Le nombre de fois qu'un site est lié à celui-ci
- Visiteurs : combien de trafic se dirige vers cette page
- Autorité de domaine : la qualité globale du domaine
Ensuite, ils stockent les données dans l'index du moteur de recherche. Lorsque l'utilisateur lance une requête de recherche, l'algorithme récupère les données de l'index et celles-ci apparaissent sur la page de résultats du moteur de recherche. Ce processus peut se produire en quelques millisecondes, c'est pourquoi les résultats apparaissent souvent rapidement.
En tant que webmaster, vous pouvez contrôler quels bots explorent votre site. C'est pourquoi il est important d'avoir une liste de robots. C'est le protocole robots.txt qui vit dans les serveurs de chaque site qui dirige les crawlers vers le nouveau contenu qui doit être indexé.
En fonction de ce que vous entrez dans votre protocole robots.txt sur chaque page Web, vous pouvez dire à un robot d'exploration d'analyser ou d'éviter d'indexer cette page à l'avenir.
En comprenant ce qu'un robot d'indexation recherche dans son analyse, vous pouvez comprendre comment mieux positionner votre contenu pour les moteurs de recherche.
Compilation de votre liste de robots : quels sont les différents types de robots d'exploration ?
Lorsque vous commencez à penser à compiler votre liste de robots, il existe trois principaux types de robots à rechercher. Ceux-ci inclus:
- Robots d'exploration internes : ce sont des robots d'exploration conçus par l'équipe de développement d'une entreprise pour analyser son site. Ils sont généralement utilisés pour l'audit et l'optimisation du site.
- Robots d'exploration commerciaux : il s'agit de robots d'exploration personnalisés tels que Screaming Frog que les entreprises peuvent utiliser pour explorer et évaluer efficacement leur contenu.
- Crawlers Open-Source : Ce sont des robots d'exploration gratuits qui sont construits par une variété de développeurs et de pirates du monde entier.
Il est important de comprendre les différents types de crawlers qui existent afin de savoir quel type vous devez exploiter pour vos propres objectifs commerciaux.
Les 11 robots d'exploration Web les plus courants à ajouter à votre liste de robots
Il n'y a pas un robot qui fait tout le travail pour chaque moteur de recherche.
Au lieu de cela, il existe une variété de robots d'exploration Web qui évaluent vos pages Web et analysent le contenu de tous les moteurs de recherche disponibles pour les utilisateurs du monde entier.
Examinons quelques-uns des robots d'exploration Web les plus courants aujourd'hui.
1. Googlebot
Googlebot est le robot d'exploration Web générique de Google qui est responsable de l'exploration des sites qui apparaîtront sur le moteur de recherche de Google.

Bien qu'il existe techniquement deux versions de Googlebot (Googlebot Desktop et Googlebot Smartphone (Mobile)), la plupart des experts considèrent Googlebot comme un seul robot d'exploration.
En effet, les deux suivent le même jeton de produit unique (appelé jeton d'agent utilisateur) écrit dans le fichier robots.txt de chaque site. L'agent utilisateur Googlebot est simplement "Googlebot".
Googlebot se met au travail et accède généralement à votre site toutes les quelques secondes (sauf si vous l'avez bloqué dans le fichier robots.txt de votre site). Une sauvegarde des pages numérisées est enregistrée dans une base de données unifiée appelée Google Cache. Cela vous permet de consulter les anciennes versions de votre site.
En outre, Google Search Console est également un autre outil utilisé par les webmasters pour comprendre comment Googlebot explore leur site et pour optimiser leurs pages pour la recherche.
2. Bingbot
Bingbot a été créé en 2010 par Microsoft pour analyser et indexer les URL afin de s'assurer que Bing offre des résultats de moteur de recherche pertinents et à jour pour les utilisateurs de la plateforme.
Tout comme Googlebot, les développeurs ou les spécialistes du marketing peuvent définir dans leur fichier robots.txt sur leur site s'ils approuvent ou refusent l'identifiant d'agent "bingbot" pour scanner leur site.
De plus, ils ont la capacité de faire la distinction entre les robots d'indexation mobiles d'abord et les robots d'exploration de bureau depuis que Bingbot est récemment passé à un nouveau type d'agent. Ceci, avec Bing Webmaster Tools, offre aux webmasters une plus grande flexibilité pour montrer comment leur site est découvert et présenté dans les résultats de recherche.
3. Robot Yandex
Yandex Bot est un robot spécialement conçu pour le moteur de recherche russe Yandex. C'est l'un des moteurs de recherche les plus importants et les plus populaires de Russie.

Les webmasters peuvent rendre les pages de leur site accessibles à Yandex Bot via leur fichier robots.txt .
En outre, ils peuvent également ajouter une balise Yandex.Metrica à des pages spécifiques, réindexer des pages dans le Webmaster Yandex ou émettre un protocole IndexNow, un rapport unique qui signale les pages nouvelles, modifiées ou désactivées.
4. Bot Apple
Apple a chargé le bot Apple d'explorer et d'indexer les pages Web pour les suggestions Siri et Spotlight d'Apple.
Apple Bot prend en compte plusieurs facteurs lors du choix du contenu à élever dans Siri et les suggestions Spotlight. Ces facteurs incluent l'engagement des utilisateurs, la pertinence des termes de recherche, le nombre/la qualité des liens, les signaux basés sur la localisation et même la conception des pages Web.
5. Le robot canard canard
Le DuckDuckBot est le robot d'exploration Web de DuckDuckGo, qui offre une "protection transparente de la confidentialité sur votre navigateur Web".
Les webmasters peuvent utiliser l'API DuckDuckBot pour voir si le DuckDuck Bot a exploré leur site. Au fur et à mesure de son exploration, il met à jour la base de données de l'API DuckDuckBot avec les adresses IP et les agents utilisateurs récents.
Cela aide les webmasters à identifier les imposteurs ou les robots malveillants essayant d'être associés à DuckDuck Bot.
6. Araignée Baidu
Baidu est le principal moteur de recherche chinois et Baidu Spider est le seul moteur de recherche du site.

Google est interdit en Chine, il est donc important d'activer Baidu Spider pour explorer votre site si vous souhaitez atteindre le marché chinois.
Pour identifier l'araignée Baidu qui explore votre site, recherchez les agents utilisateurs suivants : baiduspider, baiduspider-image, baiduspider-video, etc.
Si vous ne faites pas d'affaires en Chine, il peut être judicieux de bloquer Baidu Spider dans votre script robots.txt. Cela empêchera l'araignée Baidu d'explorer votre site, supprimant ainsi toute chance que vos pages apparaissent sur les pages de résultats des moteurs de recherche (SERP) de Baidu.
7. Araignée Sogou
Sogou est un moteur de recherche chinois qui serait le premier moteur de recherche avec 10 milliards de pages chinoises indexées.


Si vous faites des affaires sur le marché chinois, il s'agit d'un autre moteur de recherche populaire que vous devez connaître. Le Sogou Spider suit les paramètres de texte d'exclusion et de délai d'exploration du robot.
Comme avec Baidu Spider, si vous ne voulez pas faire des affaires sur le marché chinois, vous devez désactiver cette araignée pour éviter les temps de chargement du site lents.
8. Coup externe Facebook
Facebook External Hit, autrement connu sous le nom de Facebook Crawler, explore le code HTML d'une application ou d'un site Web partagé sur Facebook.

Cela permet à la plateforme sociale de générer un aperçu partageable de chaque lien publié sur la plateforme. Le titre, la description et la vignette apparaissent grâce au crawler.
Si l'exploration n'est pas exécutée en quelques secondes, Facebook n'affichera pas le contenu dans l'extrait personnalisé généré avant le partage.
9. Exabot
Exalead est une société de logiciels créée en 2000 et basée à Paris, France. La société fournit des plates-formes de recherche pour les consommateurs et les entreprises.
Exabot est le crawler de leur moteur de recherche principal basé sur leur produit CloudView.
Comme la plupart des moteurs de recherche, Exalead tient compte à la fois du backlinking et du contenu des pages Web lors du classement. Exabot est l'agent utilisateur du robot d'Exalead. Le robot crée un « index principal » qui compile les résultats que les utilisateurs du moteur de recherche verront.
10. Swiftbot
Swiftype est un moteur de recherche personnalisé pour votre site Web. Il combine "la meilleure technologie de recherche, les meilleurs algorithmes, le cadre d'ingestion de contenu, les clients et les outils d'analyse".

Si vous avez un site complexe avec de nombreuses pages, Swiftype offre une interface utile pour cataloguer et indexer toutes vos pages pour vous.
Swiftbot est le robot d'exploration Web de Swiftype. Cependant, contrairement aux autres bots, Swiftbot n'explore que les sites demandés par leurs clients.
11. Robot slurp
Slurp Bot est le robot de recherche Yahoo qui parcourt et indexe les pages de Yahoo.
Cette analyse est essentielle pour Yahoo.com ainsi que pour ses sites partenaires, notamment Yahoo News, Yahoo Finance et Yahoo Sports. Sans cela, les listes de sites pertinentes n'apparaîtraient pas.
Le contenu indexé contribue à une expérience Web plus personnalisée pour les utilisateurs avec des résultats plus pertinents.
Les 8 robots d'exploration commerciaux que les professionnels du référencement doivent connaître
Maintenant que vous avez 11 des bots les plus populaires sur votre liste de robots, examinons quelques-uns des robots commerciaux courants et des outils de référencement pour les professionnels.
1. Bot Ahrefs
Ahrefs Bot est un robot d'exploration Web qui compile et indexe la base de données de 12 000 milliards de liens proposée par le logiciel de référencement populaire Ahrefs.
Le Bot Ahrefs visite 6 milliards de sites Web chaque jour et est considéré comme "le deuxième robot d'exploration le plus actif" derrière Googlebot.
Tout comme les autres bots, le bot Ahrefs suit les fonctions robots.txt , ainsi que les règles d'autorisation/d'interdiction dans le code de chaque site.
2. Robot Semrush
Le bot Semrush permet à Semrush, un logiciel de référencement leader, de collecter et d'indexer les données du site pour l'utilisation de ses clients sur sa plateforme.

Les données sont utilisées dans le moteur de recherche de backlink public de Semrush, l'outil d'audit de site, l'outil d'audit de backlink, l'outil de création de liens et l'assistant d'écriture.
Il explore votre site en compilant une liste d'URL de pages Web, en les visitant et en sauvegardant certains hyperliens pour de futures visites.
3. Rogerbot, robot d'exploration de campagne de Moz
Rogerbot est le crawler du principal site SEO, Moz. Ce robot d'exploration collecte spécifiquement du contenu pour les audits de site Moz Pro Campaign.

Rogerbot suit toutes les règles énoncées dans les fichiers robots.txt , vous pouvez donc décider si vous souhaitez bloquer/autoriser Rogerbot à analyser votre site.
Les webmasters ne pourront pas rechercher une adresse IP statique pour voir quelles pages Rogerbot a explorées en raison de son approche à multiples facettes.
4. Grenouille hurlante
Screaming Frog est un crawler que les professionnels du référencement utilisent pour auditer leur propre site et identifier les domaines d'amélioration qui auront un impact sur leur classement dans les moteurs de recherche.

Une fois qu'une analyse est lancée, vous pouvez examiner les données en temps réel et identifier les liens rompus ou les améliorations nécessaires pour les titres de vos pages, les métadonnées, les robots, le contenu dupliqué, etc.
Afin de configurer les paramètres de crawl, vous devez acheter une licence Screaming Frog.
5. Lumar (anciennement Deep Crawl)
Lumar est un "centre de commande centralisé pour maintenir la santé technique de votre site". Avec cette plateforme, vous pouvez initier une exploration de votre site pour vous aider à planifier l'architecture de votre site.
Lumar se targue d'être le "crawler de site Web le plus rapide du marché" et se vante de pouvoir explorer jusqu'à 450 URL par seconde.
6. Majestueux
Majestic se concentre principalement sur le suivi et l'identification des backlinks sur les URL.
L'entreprise se targue d'avoir "l'une des sources les plus complètes de données de backlinks sur Internet", mettant en avant son index historique qui est passé de 5 à 15 ans de liens en 2021.
Le crawler du site met toutes ces données à la disposition des clients de l'entreprise.
7. SEO cognitif
cognitiveSEO est un autre logiciel de référencement important utilisé par de nombreux professionnels.
Le robot d'exploration cognitiveSEO permet aux utilisateurs d'effectuer des audits de site complets qui éclaireront l'architecture de leur site et leur stratégie globale de référencement.
Le bot explorera toutes les pages et fournira "un ensemble de données entièrement personnalisé" qui est unique pour l'utilisateur final. Cet ensemble de données contiendra également des recommandations pour l'utilisateur sur la façon dont il peut améliorer son site pour d'autres robots d'exploration, à la fois pour avoir un impact sur les classements et pour bloquer les robots d'exploration inutiles.
8. En exploration
Oncrawl est un "robot d'exploration et analyseur de journaux SEO leader de l'industrie" pour les clients au niveau de l'entreprise.

Les utilisateurs peuvent configurer des "profils de crawl" pour créer des paramètres spécifiques pour le crawl. Vous pouvez enregistrer ces paramètres (y compris l'URL de départ, les limites d'exploration, la vitesse d'exploration maximale, etc.) pour réexécuter facilement l'exploration avec les mêmes paramètres établis.
Dois-je protéger mon site contre les robots d'exploration Web malveillants ?
Tous les robots ne sont pas bons. Certains peuvent avoir un impact négatif sur la vitesse de votre page, tandis que d'autres peuvent essayer de pirater votre site ou avoir des intentions malveillantes.
C'est pourquoi il est important de comprendre comment empêcher les robots d'exploration d'accéder à votre site.
En établissant une liste de robots, vous saurez quels robots sont les bons à surveiller. Ensuite, vous pouvez éliminer les poissons et les ajouter à votre liste de blocage.
Comment bloquer les robots d'exploration Web malveillants
Avec votre liste de robots en main, vous pourrez identifier les bots que vous souhaitez approuver et ceux que vous devez bloquer.
La première étape consiste à parcourir votre liste de robots et à définir l'agent utilisateur et la chaîne d'agent complète associée à chaque robot ainsi que son adresse IP spécifique. Ce sont des facteurs d'identification clés associés à chaque bot.
Avec l'agent utilisateur et l'adresse IP, vous pouvez les faire correspondre dans les enregistrements de votre site via une recherche DNS ou une correspondance IP. S'ils ne correspondent pas exactement, vous pourriez avoir un bot malveillant essayant de se faire passer pour le vrai.
Ensuite, vous pouvez bloquer l'imposteur en ajustant les autorisations à l'aide de votre site tag robots.txt .
Sommaire
Les robots d'exploration Web sont utiles pour les moteurs de recherche et importants à comprendre pour les spécialistes du marketing.
S'assurer que votre site est exploré correctement par les bons crawlers est important pour le succès de votre entreprise. En conservant une liste de robots d'exploration, vous pouvez savoir lesquels surveiller lorsqu'ils apparaissent dans le journal de votre site.
En suivant les recommandations des robots commerciaux et en améliorant le contenu et la vitesse de votre site, vous faciliterez l'accès des robots à votre site et indexerez les bonnes informations pour les moteurs de recherche et les consommateurs qui les recherchent.