
Des statistiques trompeuses peuvent être dangereuses (quelques exemples)
Publié: 2022-12-06Les gens comptent sur les statistiques pour obtenir des informations importantes. Dans le monde des affaires, les statistiques peuvent être utiles pour suivre les tendances et maximiser la productivité. Mais parfois, les statistiques peuvent être présentées de manière trompeuse . Par exemple, en 2007, l'Advertising Standards Authority (ADA) au Royaume-Uni a reçu une plainte concernant une publicité de Colgate.
La publicité affirme que 80 % des dentistes recommandent d'utiliser le dentifrice Colgate. La plainte reçue par l'ADA a fait valoir qu'il s'agissait d'une violation des règles de publicité au Royaume-Uni. Après avoir examiné la question, l'ADA a découvert que l'annonce utilisait des statistiques trompeuses.
Il est vrai que de nombreux dentistes recommandent le dentifrice Colgate. Mais tous n'ont pas cité Colgate comme leur recommandation numéro un. La plupart des dentistes recommandaient également d'autres types de dentifrice, et Colgate arrivait généralement plus tard.
Ce n'est là qu'un exemple de la façon dont des statistiques trompeuses sont utilisées. Les gens rencontrent des exemples de statistiques trompeuses dans de nombreux domaines de la vie. Vous pouvez trouver des exemples dans les nouvelles, dans la publicité, dans la politique et même dans la science.
Cet article vous aidera à apprendre à reconnaître les statistiques trompeuses et autres données trompeuses . Il discutera de la façon dont ces données induisent les gens en erreur. Vous apprendrez également quand et comment utiliser les données lors de la prise de décisions critiques.
Que sont les statistiques trompeuses ?
Les statistiques sont le résultat de la collecte de données numériques, de leur analyse minutieuse, puis de leur interprétation . Il est particulièrement utile d'avoir des statistiques si vous traitez une grande quantité de données, mais tout ce qui peut être mesuré peut devenir une statistique. Les statistiques révèlent souvent beaucoup de choses sur le monde et son fonctionnement.
Cependant, lorsque cette information est utilisée à mauvais escient, même par accident, elle devient une statistique trompeuse. Les statistiques trompeuses donnent aux gens de fausses informations qui les trompent plutôt que de les informer .
Lorsque les gens sortent une statistique de son contexte, elle perd de sa valeur et peut amener les gens à tirer des conclusions erronées. Le terme « statistiques trompeuses » décrit toute méthode statistique qui représente les données de manière incorrecte. Que ce soit intentionnel ou non , cela compterait toujours comme des statistiques trompeuses.
Lors de la collecte de données pour une statistique, il y a trois points principaux à garder à l'esprit. Un problème avec l'analyse des données peut survenir à n'importe lequel de ces points.
- Collecte : Lors de la collecte des données
- Traitement : lors de l'analyse des données et de leurs implications
- Présentation : Lorsque vous partagez vos découvertes avec d'autres
Un petit échantillon
Les enquêtes sur la taille de l'échantillon sont un exemple de création de statistiques trompeuses. Les enquêtes ou études menées auprès d'un public de taille réduite produisent souvent des résultats tellement trompeurs qu'ils sont inutilisables.
Pour illustrer, un sondage demande à 20 personnes une question oui ou non. 19 des personnes répondent oui au sondage. Ainsi, les résultats montrent que 95% des personnes répondraient oui à cette question. Mais ce n'est pas une bonne enquête car les informations sont limitées.
Cette statistique n'a aucune valeur réelle. Maintenant, si vous posez la même question à 1 000 personnes et que 950 disent oui, alors c'est une statistique beaucoup plus fiable pour montrer que 95 % des gens diraient oui.
Pour mener une étude fiable sur la taille de l'échantillon, vous devez tenir compte de trois éléments :
- Un : Quel genre de question posez-vous ?
- Deux : Quelle est la signification de la statistique que vous essayez de trouver ?
- Et trois : Quelle technique statistique allez-vous utiliser ?
Pour avoir des résultats fiables, toute analyse quantitative de la taille de l'échantillon doit inclure au moins 200 personnes.
Questions chargées

Il est important de chercher des données provenant d'une source neutre . Sinon, l'information est biaisée. Les questions chargées utilisent une hypothèse controversée ou injustifiée pour manipuler la réponse. Un exemple de ceci est de poser une question qui commence par « Qu'est-ce que vous aimez ? » Cette question fait un excellent travail de collecte de commentaires positifs, mais ne vous apprend rien d'utile. Cela ne donne aucune possibilité à la personne de donner ses pensées et ses opinions honnêtes.
Considérez la différence entre les deux questions suivantes :
- Êtes-vous favorable à une réforme fiscale qui impliquerait une hausse des impôts ?
- Soutenez-vous une réforme fiscale qui serait bénéfique pour la redistribution sociale ?
La question porte essentiellement sur le même sujet, mais les résultats de chacune de ces questions seraient assez différents. Les sondages doivent être menés de manière impartiale et impartiale. Vous voulez obtenir les opinions honnêtes des gens et une image complète de ce que les gens pensent. Pour y parvenir, vos questions ne doivent pas impliquer la réponse ni provoquer une réponse émotionnelle .
Citant des "moyennes" trompeuses
Certaines personnes utilisent le terme « moyen » pour masquer la vérité ou mentent pour améliorer l'apparence de l'information.
Cette technique est particulièrement utile si quelqu'un veut faire apparaître un nombre plus grand ou meilleur qu'il ne l'est. Par exemple, une université désireuse d'attirer de nouveaux étudiants peut verser un salaire annuel « moyen » aux diplômés de son école. Mais il n'y a peut-être qu'une poignée d'étudiants qui ont en fait des salaires élevés. Mais leurs salaires augmentent le revenu moyen de tous les étudiants. Cela semble mieux pour l'ensemble de la moyenne.
Les moyennes sont également utiles pour masquer les inégalités. Autre exemple, supposons qu'une entreprise verse 20 000 $ par année à ses 90 employés. Mais leur patron reçoit 200 000 $ par an. Si vous combinez le salaire du patron et celui des employés, le revenu moyen de chaque membre de l'entreprise est de 21 978 $.
Sur le papier, ça a l'air super. Mais ce chiffre ne raconte pas toute l'histoire car l'un des employés (le patron) gagne beaucoup plus que les autres travailleurs. Ces types de résultats sont donc considérés comme des statistiques trompeuses.
Données cumulées par rapport aux données annuelles
Les données cumulatives suivent les informations sur un graphique au fil du temps. Chaque fois que vous saisissez des données dans les graphiques, le graphique augmente.
Les données annuelles présentent toutes les données pour une année spécifique.
Les informations de suivi pour chaque année fournissent une image plus fidèle des tendances générales.
Un exemple de graphique cumulatif est le graphique Worldometer COVID-19. Pendant la pandémie de COVID-19, de nombreux exemples de graphiques cumulatifs ont surgi. Ils reflètent souvent le nombre cumulé de cas de COVID dans une zone spécifique.
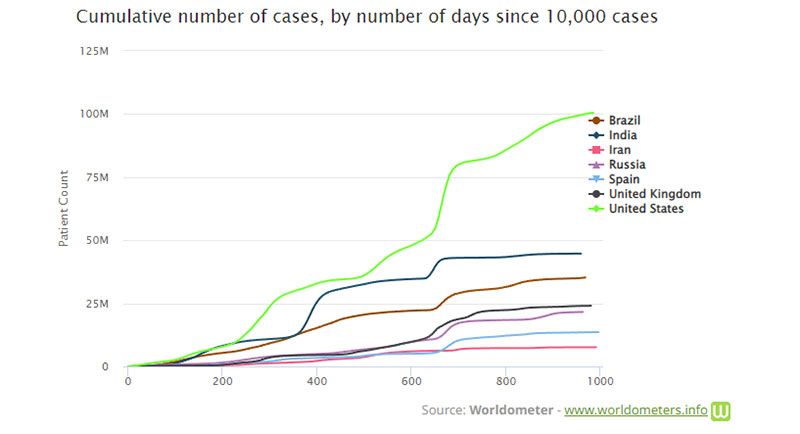
Certaines entreprises utilisent des graphiques comme celui-ci pour faire apparaître les ventes plus importantes qu'elles ne le sont. En 2013, le PDG d'Apple, Tim Cook, a été critiqué pour avoir utilisé une présentation ne montrant que le nombre cumulé de ventes d'iPhone. Beaucoup à l'époque estimaient qu'il avait fait cela intentionnellement pour cacher le fait que les ventes d'iPhone diminuaient.
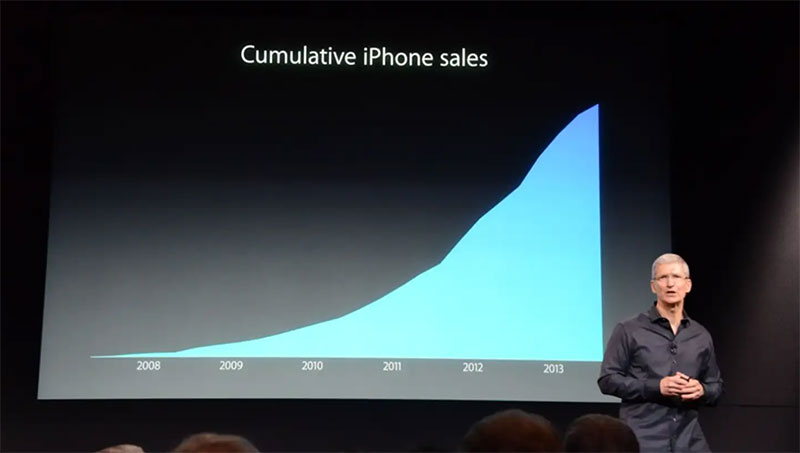
Cela ne veut pas dire que toutes les données cumulées sont mauvaises ou fausses. En fait, cela peut être utile pour suivre les changements ou la croissance et divers totaux. Mais l'important est de prêter attention aux changements dans les données. Ensuite, examinez plus en profondeur ce qui les a causés plutôt que de vous fier au tableau pour tout vous dire.
Surgénéralisation et échantillons biaisés
La généralisation excessive se produit lorsque quelqu'un suppose que ce qui est vrai pour une personne doit être vrai pour tout le monde. Habituellement, cette erreur se produit lorsque quelqu'un mène une étude avec un certain groupe de personnes. Ils supposent alors que les résultats seront vrais pour un autre groupe de personnes non apparentées.
Les échantillons non représentatifs, ou échantillons biaisés, sont des enquêtes qui ne représentent pas avec précision la population générale.
Un exemple d'échantillons biaisés s'est produit lors des élections présidentielles de 1936 aux États-Unis d'Amérique.
Le Literary Digest, un magazine populaire à l'époque, a mené une enquête pour prédire qui gagnerait les élections. Les résultats ont prédit qu'Alfred Landon gagnerait par un glissement de terrain.
Ce magazine était connu pour prédire avec précision le résultat des élections. Cette année, cependant, ils se sont complètement trompés. Franklin Roosevelt a gagné avec presque le double des voix de son adversaire.
Certaines recherches supplémentaires ont révélé que deux variables étaient entrées en jeu et faussaient les résultats.
Premièrement , la plupart des participants à l'enquête étaient des personnes trouvées dans l'annuaire téléphonique et sur les listes d'enregistrement automatique. L'enquête n'a donc été menée qu'auprès de personnes d'un certain statut socio-économique.
Le deuxième facteur était que ceux qui ont voté pour Landon étaient plus disposés à répondre à l'enquête que ceux qui ont choisi de voter pour Roosevelt. Les résultats reflétaient donc ce biais.
Tronquer un axe
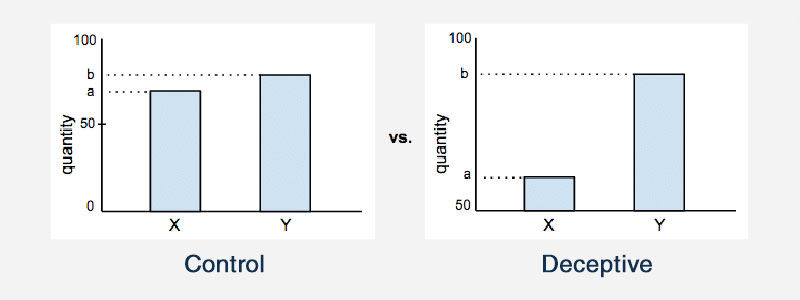
Tronquer l'axe d'un graphique est un autre exemple de statistiques trompeuses. Sur la plupart des graphiques statistiques, les axes x et y commencent vraisemblablement à partir de zéro. Mais tronquer l'axe signifie que le graphique commence en fait les axes à une autre valeur. Cela affecte l'apparence d'un graphique et affecte les conclusions qu'une personne en tirera.
Voici un exemple qui illustre cela :
Un autre exemple de cela s'est produit récemment en septembre 2021. Lors d'une émission de Fox News, le présentateur a utilisé un graphique montrant le nombre d'Américains qui prétendaient être chrétiens. Le graphique montre que le nombre d'Américains qui se sont identifiés comme chrétiens a chuté de façon drastique au cours des 10 dernières années.
Dans le graphique suivant, nous voyons qu'en 2009, 77 % des Américains se sont identifiés comme chrétiens.
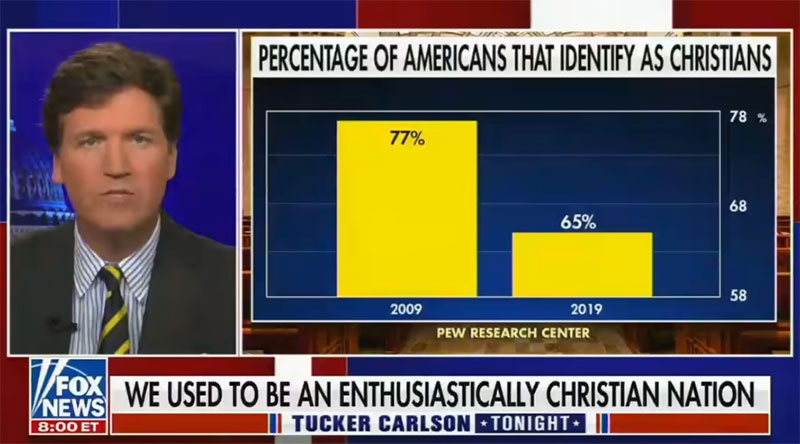
En 2019, ce nombre est tombé à 65 %. En réalité, ce n'est pas une énorme diminution. Mais l'axe de ce graphique commence à 58 % et s'arrête à 78 %. Ainsi, la baisse de 12 % de 2009 à 2019 semble bien plus drastique qu'elle ne l'est en réalité.

Causalité et corrélation
Il peut être facile de supposer une connexion entre deux points de données apparemment connectés. Pourtant, on dit que corrélation n'implique pas causalité . Pourquoi est-ce si?
Ce graphique illustre pourquoi la corrélation n'est pas la même chose que la causalité.
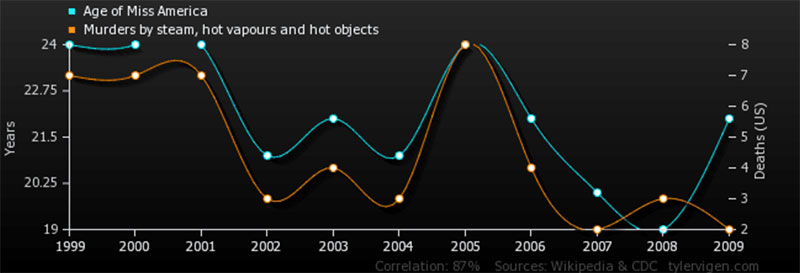
Les chercheurs sont souvent soumis à de fortes pressions pour découvrir de nouvelles données utiles. Ainsi, la tentation de sauter le pas et de tirer des conclusions prématurément est toujours présente. C'est pourquoi il est important, dans chaque situation, de rechercher la cause et l'effet réels .
Utiliser des pourcentages pour masquer des nombres et des calculs
Un pourcentage peut masquer des chiffres exacts et donner l'impression que les résultats sont plus fiables et plus fiables qu'ils ne le sont.
Par exemple, si deux personnes sur trois préfèrent un certain produit de nettoyage, on peut dire que 66,667 % des personnes préfèrent ce produit. Cela rend le nombre plus officiel, en particulier avec les nombres après la virgule inclus.
Voici quelques autres façons dont les décimales et les pourcentages peuvent masquer la vérité :
- Masquage des nombres bruts et des échantillons de petite taille . Les pourcentages masquent la valeur absolue des nombres bruts. Cela les rend utiles pour les personnes qui souhaitent masquer des chiffres peu flatteurs ou des résultats d'échantillons de petite taille.
- Utilisation de bases différentes. Étant donné que les pourcentages ne fournissent pas les chiffres d'origine sur lesquels ils sont basés, il peut être facile de fausser les résultats. Si quelqu'un voulait améliorer l'apparence d'un nombre, il pouvait calculer ce nombre à partir d'une base différente.
Cela s'est produit une fois dans un rapport publié par le New York Times sur les travailleurs syndiqués. Les travailleurs ont eu une réduction de salaire de 20% une année, et l'année suivante, le Times a rapporté que les travailleurs syndiqués avaient reçu une augmentation de 5%. On prétendait donc qu'ils recevaient un quart de leur réduction de salaire.
Cependant, les travailleurs ont reçu une augmentation de 5 % basée sur leur salaire actuel, et non sur le salaire qu'ils avaient avant la réduction de salaire. Ainsi, même si cela paraissait bien sur le papier, la réduction de salaire de 20 % et l'augmentation de 5 % ont été calculées à partir de chiffres de base différents. Les deux chiffres ne se comparent pas vraiment du tout.
Cueillette/rejet des données défavorables
Le terme «cueillette de cerises» est basé sur l'idée de ne cueillir que les meilleurs fruits d'un arbre. Quiconque voit ce fruit est obligé de penser que tous les fruits de l'arbre sont également sains. Évidemment, ce n'est pas forcément le cas.
Ce même principe entre en jeu dans le cas du changement climatique. De nombreux graphiques limitent leur cadre de données pour ne montrer que les changements climatiques des années 2000 à 2013.
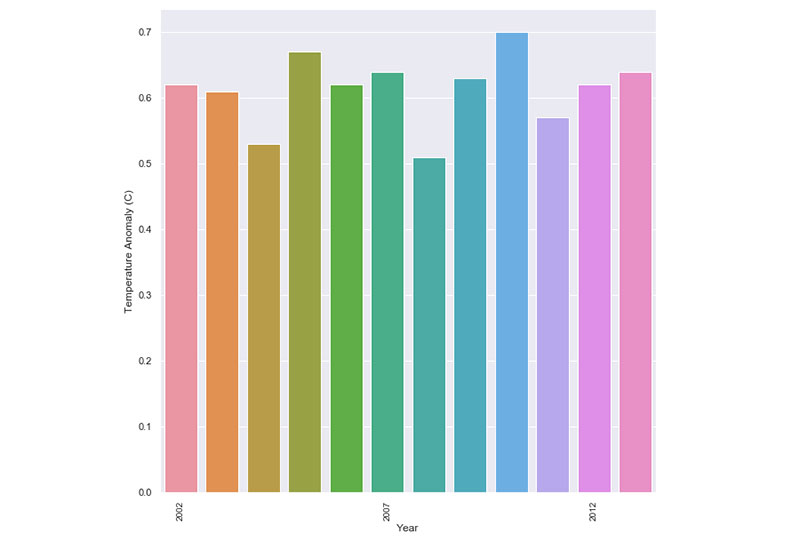
En conséquence, il semble que les changements de température et les anomalies sont cohérents et ne changent pas beaucoup. Cependant, lorsque vous prenez du recul et regardez la situation dans son ensemble, il devient clair où se trouvent les changements et les anomalies.
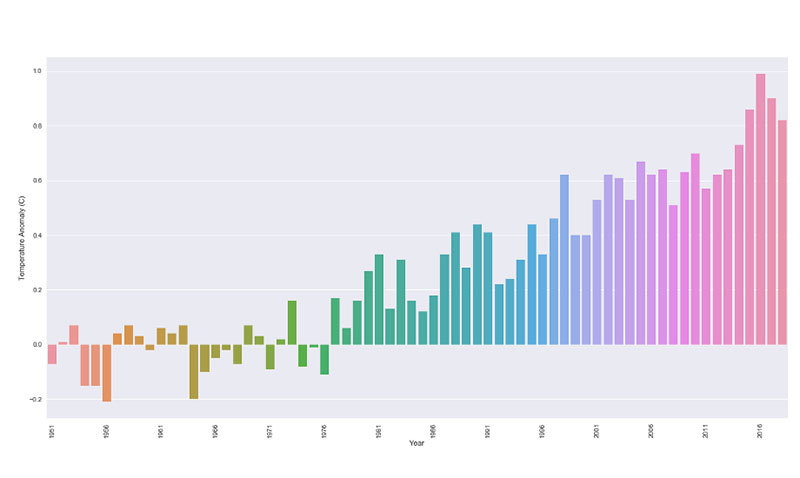
Cela se produit également dans le domaine de la médecine vétérinaire. Lorsqu'on demande aux vétérinaires de présenter les résultats d'un nouveau médicament à l'essai, ils ont tendance à présenter les meilleurs résultats. En particulier, si une société pharmaceutique soutient l'essai, elle ne souhaite voir que les meilleurs résultats.
Vos belles données méritent d'être en ligne
wpDataTables peut le faire de cette façon. Il y a une bonne raison pour laquelle c'est le plugin WordPress #1 pour créer des tableaux et des graphiques réactifs.
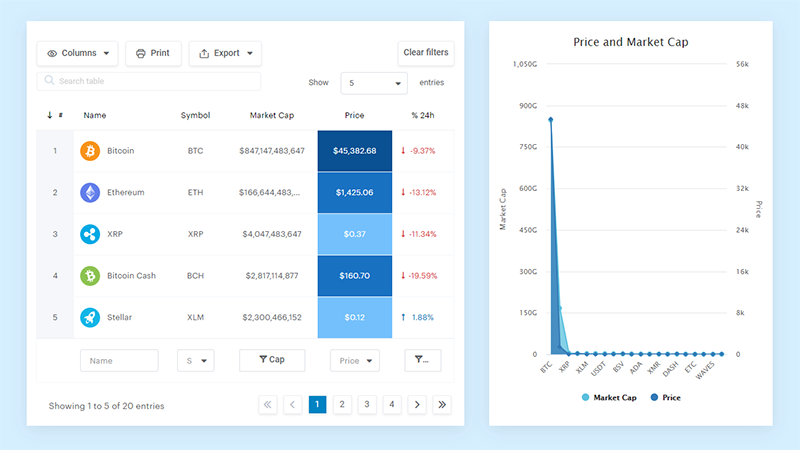
Et c'est vraiment facile de faire quelque chose comme ça :
- Vous fournissez les données du tableau
- Configurez-le et personnalisez-le
- Publiez-le dans un article ou une page
Et ce n'est pas seulement joli, mais aussi pratique. Vous pouvez créer de grands tableaux avec jusqu'à des millions de lignes, ou vous pouvez utiliser des filtres et une recherche avancés, ou vous pouvez vous déchaîner et le rendre modifiable.
"Ouais, mais j'aime trop Excel et il n'y a rien de tel sur les sites Web". Oui, il y en a. Vous pouvez utiliser une mise en forme conditionnelle comme dans Excel ou Google Sheets.
Vous ai-je dit que vous pouviez également créer des graphiques avec vos données ? Et ce n'est qu'une petite partie. Il y a beaucoup d'autres fonctionnalités pour vous.
Pêche aux données
La pêche aux données, également connue sous le nom de dragage de données, est l'analyse de grandes quantités de données dans le but de trouver une corrélation. Cependant, comme indiqué précédemment dans cet article, la corrélation n'implique pas la causalité. Insistant sur le fait que cela n'aboutit qu'à des statistiques trompeuses.
Vous pouvez voir des exemples de pêche aux données dans les domaines de l'industrie tous les jours. Une semaine, un scandale est publié sur l'exploration de données, et une semaine plus tard, il est réfuté par un rapport encore plus scandaleux.
Un autre problème avec ce type d'analyse de données est que les gens ne choisissent que les données qui soutiennent leur point de vue et ignorent le reste. En omettant des informations contradictoires, ils rendent les résultats plus convaincants .
Graphique confus et étiquettes de graphique
Lorsque la pandémie de COVID-19 a commencé, plus de personnes que jamais se sont tournées vers les visualisations de données de la propagation du virus. Les personnes qui n'avaient jamais eu à travailler avec une représentation visuelle des statistiques ont été soudainement éjectées de l'extrémité profonde des données statistiques.
En outre, les organisations essayaient souvent d'obtenir rapidement des informations sur les personnes. Parfois, cela signifiait sacrifier des statistiques précises. Cela a provoqué une augmentation des statistiques trompeuses et une mauvaise interprétation des données.
Environ cinq mois après que le COVID-19 a commencé à se propager, le département américain de la santé publique de Géorgie a publié ce tableau :
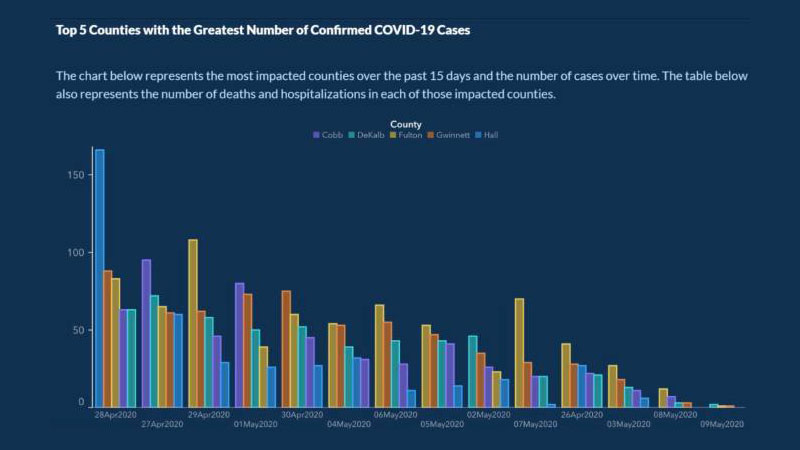
Le but du graphique était de montrer les 5 pays avec les cas de COVID les plus élevés au cours des 15 jours précédents, et le nombre de cas sur une période de temps.
Ce tableau contient quelques erreurs qui le rendent facile à mal comprendre. L'axe des x, par exemple, n'a pas d'étiquette expliquant qu'il représente la progression des cas dans le temps.
Pire encore, les dates sur le graphique ne sont pas organisées chronologiquement. Les dates d'avril et de mai sont dispersées dans le graphique pour donner l'impression que le nombre de cas diminuait régulièrement. Chaque pays est également répertorié de manière à donner l'impression que les cas diminuaient.
Plus tard, ils ont republié le graphique avec des dates et des comtés mieux organisés :
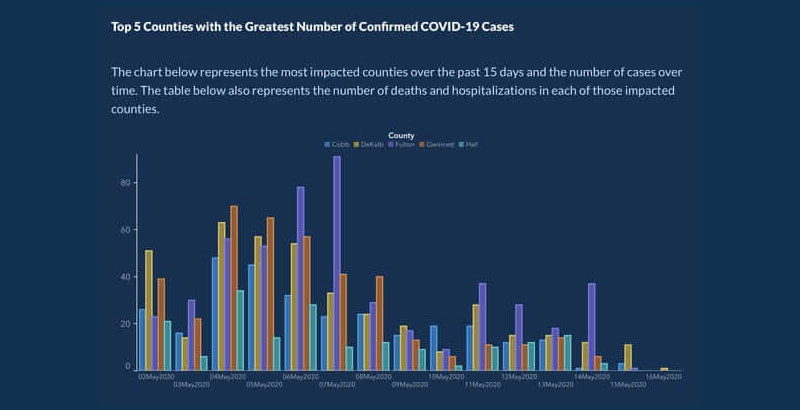
Chiffres inexacts
Un autre exemple de statistiques trompeuses se présente sous la forme de chiffres inexacts. Remarquez cette déclaration d'une ancienne campagne Reebok.
La publicité affirme que la chaussure fait travailler les ischio- jambiers et les mollets d'une personne 11% plus fort et peut tonifier les fesses d'une personne jusqu'à 28% de plus que les autres baskets . Tout ce que la personne a à faire est de marcher dans les baskets.
Ces chiffres donnent à penser que Reebok a effectué des recherches approfondies sur les avantages de la chaussure.
La réalité était que ces chiffres étaient complètement inventés. La marque a reçu une pénalité pour avoir utilisé de telles statistiques trompeuses. Ils ont également dû modifier la déclaration et supprimer les faux numéros.
Comment éviter et identifier l'utilisation abusive des statistiques
Les statistiques peuvent être extrêmement utiles. Mais les statistiques trompeuses ont également le potentiel de semer la confusion et de tromper les gens. Les statistiques donnent autorité à une déclaration et convainquent les gens de faire confiance à un certain argument.
Des statistiques solides et vraies aident à donner aux gens un aperçu et les aident à prendre des décisions. Mais les statistiques trompeuses sont dangereuses . Au lieu d'aider les gens à éviter les pièges et les nids-de-poule, ils conduisent les gens directement dans les situations qu'ils voulaient éviter.
Mais il est possible d'identifier des statistiques et des données trompeuses. Lorsque vous rencontrez une statistique, arrêtez-vous et posez les questions suivantes :
- D'où viennent ces données ?
- La source est-elle contrôlée ? Ou est-ce une expérience de taille d'échantillon ?
- Quels autres facteurs pourraient jouer dans ce résultat ?
- L'information essaie-t-elle de m'informer ou me dirige-t-elle vers une conclusion prédéterminée ?
Que vous collectiez des données ou que vous consultiez les résultats des recherches d'autres personnes, assurez-vous que les données sont exactes. De cette façon, vous n'ajoutez pas à la diffusion de statistiques trompeuses .
Si vous avez aimé lire cet article sur les statistiques trompeuses, vous devriez également lire ceux-ci :
- La visualisation de données interactive la plus impressionnante que vous trouverez en ligne
- Les meilleurs outils de visualisation de données WordPress que vous pouvez trouver
- Les meilleurs outils et plateformes de visualisation de données pour vous