
Comment créer une base de données MongoDB : 6 aspects critiques à connaître
Publié: 2022-11-07En fonction des exigences de votre logiciel, vous pouvez privilégier la flexibilité, l'évolutivité, les performances ou la vitesse. Par conséquent, les développeurs et les entreprises sont souvent confus lorsqu'ils choisissent une base de données pour leurs besoins. Si vous avez besoin d'une base de données offrant une grande flexibilité et évolutivité, ainsi qu'une agrégation de données pour l'analyse des clients, MongoDB peut être la bonne solution pour vous !
Dans cet article, nous discuterons de la structure de la base de données MongoDB et de la manière de créer, surveiller et gérer votre base de données ! Commençons.
Comment une base de données MongoDB est-elle structurée ?
MongoDB est une base de données NoSQL sans schéma. Cela signifie que vous ne spécifiez pas de structure pour les tables/bases de données comme vous le faites pour les bases de données SQL.
Saviez-vous que les bases de données NoSQL sont en fait plus rapides que les bases de données relationnelles ? Cela est dû à des caractéristiques telles que les pipelines d'indexation, de partitionnement et d'agrégation. MongoDB est également connu pour son exécution rapide des requêtes. C'est pourquoi il est préféré par des entreprises comme Google, Toyota et Forbes.
Ci-dessous, nous allons explorer certaines caractéristiques clés de MongoDB.
Documents
MongoDB possède un modèle de données de document qui stocke les données sous forme de documents JSON. Les documents correspondent naturellement aux objets du code de l'application, ce qui facilite leur utilisation par les développeurs.
Dans une table de base de données relationnelle, vous devez ajouter une colonne pour ajouter un nouveau champ. Ce n'est pas le cas avec les champs d'un document JSON. Les champs d'un document JSON peuvent différer d'un document à l'autre, ils ne seront donc pas ajoutés à chaque enregistrement de la base de données.
Les documents peuvent stocker des structures telles que des tableaux qui peuvent être imbriqués pour exprimer des relations hiérarchiques. De plus, MongoDB convertit les documents en un type binaire JSON (BSON). Cela garantit un accès plus rapide et une prise en charge accrue de divers types de données tels que les chaînes, les entiers, les nombres booléens et bien plus encore !
Ensembles de répliques
Lorsque vous créez une nouvelle base de données dans MongoDB, le système crée automatiquement au moins 2 copies supplémentaires de vos données. Ces copies sont appelées « ensembles de répliques » et elles répliquent en permanence les données entre elles, garantissant une meilleure disponibilité de vos données. Ils offrent également une protection contre les temps d'arrêt lors d'une panne du système ou d'une maintenance planifiée.
Collections
Une collection est un groupe de documents associés à une base de données. Ils sont similaires aux tables des bases de données relationnelles.
Les collections, cependant, sont beaucoup plus flexibles. D'une part, ils ne reposent pas sur un schéma. Deuxièmement, les documents n'ont pas besoin d'être du même type de données !
Pour afficher une liste des collections appartenant à une base de données, utilisez la commande listCollections .
Pipelines d'agrégation
Vous pouvez utiliser ce framework pour regrouper plusieurs opérateurs et expressions. Il est flexible car il vous permet de traiter, transformer et analyser des données de n'importe quelle structure.
Pour cette raison, MongoDB permet des flux de données rapides et des fonctionnalités sur 150 opérateurs et expressions. Il comporte également plusieurs étapes, comme l'étape Union, qui rassemble de manière flexible les résultats de plusieurs collections.
Index
Vous pouvez indexer n'importe quel champ dans un document MongoDB pour augmenter son efficacité et améliorer la vitesse des requêtes. L'indexation permet de gagner du temps en scannant l'index pour limiter les documents inspectés. N'est-ce pas bien mieux que de lire tous les documents de la collection ?
Vous pouvez utiliser diverses stratégies d'indexation, y compris des index composés sur plusieurs champs. Par exemple, supposons que vous ayez plusieurs documents contenant les noms et prénoms de l'employé dans des champs distincts. Si vous souhaitez que le prénom et le nom soient renvoyés, vous pouvez créer un index qui inclut à la fois "Nom" et "Prénom". Ce serait bien mieux que d'avoir un index sur "Nom" et un autre sur "Prénom".
Vous pouvez tirer parti d'outils tels que Performance Advisor pour mieux comprendre quelle requête pourrait bénéficier des index.
Partage
Le sharding distribue un seul ensemble de données sur plusieurs bases de données. Cet ensemble de données peut ensuite être stocké sur plusieurs machines pour augmenter la capacité de stockage totale d'un système. En effet, il divise les ensembles de données plus volumineux en plus petits morceaux et les stocke dans divers nœuds de données.
MongoDB fragmente les données au niveau de la collection, distribuant les documents d'une collection sur les fragments d'un cluster. Cela garantit l'évolutivité en permettant à l'architecture de gérer les applications les plus volumineuses.
Comment créer une base de données MongoDB
Vous devrez d'abord installer le bon package MongoDB adapté à votre système d'exploitation. Allez sur la page 'Télécharger MongoDB Community Server'. Parmi les options disponibles, sélectionnez la dernière "version", le format "package" en tant que fichier zip et la "plate-forme" comme système d'exploitation et cliquez sur "Télécharger" comme illustré ci-dessous :
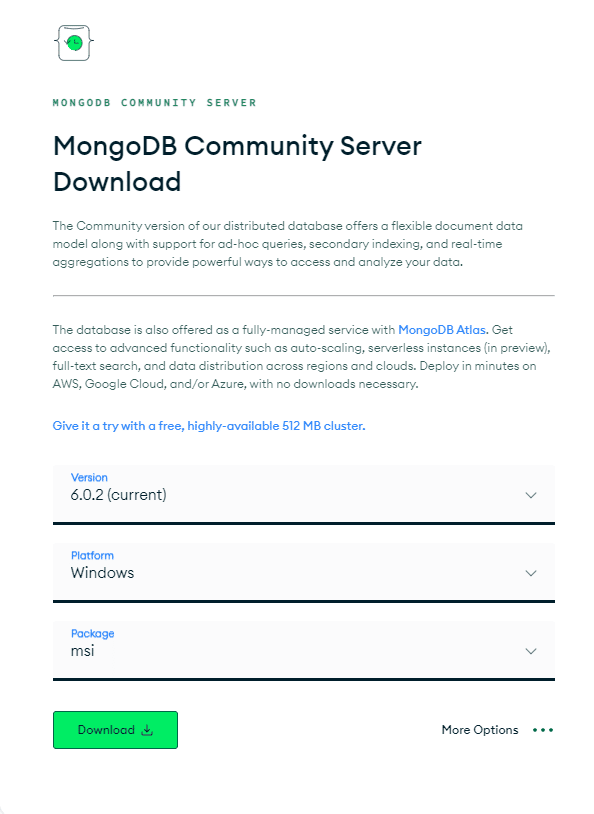
Le processus est assez simple, vous aurez donc MongoDB installé sur votre système en un rien de temps !
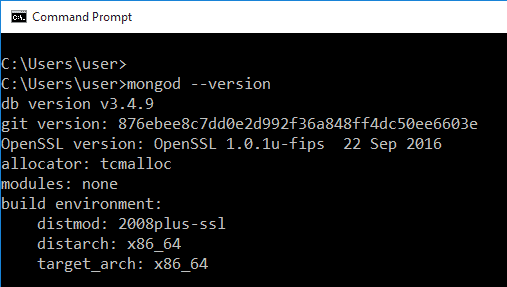
Une fois l'installation terminée, ouvrez votre invite de commande et tapez mongod -version pour le vérifier. Si vous n'obtenez pas le résultat suivant et voyez à la place une chaîne d'erreurs, vous devrez peut-être le réinstaller :
Utilisation du shell MongoDB
Avant de commencer, assurez-vous que :
- Votre client dispose de Transport Layer Security et figure sur votre liste d'adresses IP autorisées.
- Vous disposez d'un compte utilisateur et d'un mot de passe sur le cluster MongoDB souhaité.
- Vous avez installé MongoDB sur votre appareil.
Étape 1 : Accéder au shell MongoDB
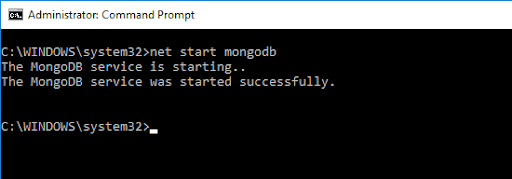
Pour accéder au shell MongoDB, saisissez la commande suivante :
net start MongoDBCela devrait donner la sortie suivante :
La commande précédente a initialisé le serveur MongoDB. Pour l'exécuter, nous devrons taper mongo dans l'invite de commande.
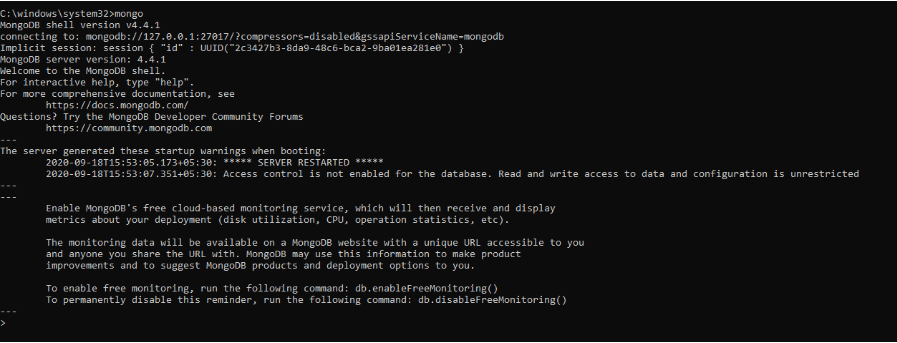
Ici, dans le shell MongoDB, nous pouvons exécuter des commandes pour créer des bases de données, insérer des données, modifier des données, émettre des commandes administratives et supprimer des données.
Étape 2 : Créez votre base de données
Contrairement à SQL, MongoDB n'a pas de commande de création de base de données. Au lieu de cela, il existe un mot-clé appelé use qui bascule vers une base de données spécifiée. Si la base de données n'existe pas, elle créera une nouvelle base de données, sinon, elle sera liée à la base de données existante.
Par exemple, pour initier une base de données appelée "société", saisissez :
use Company 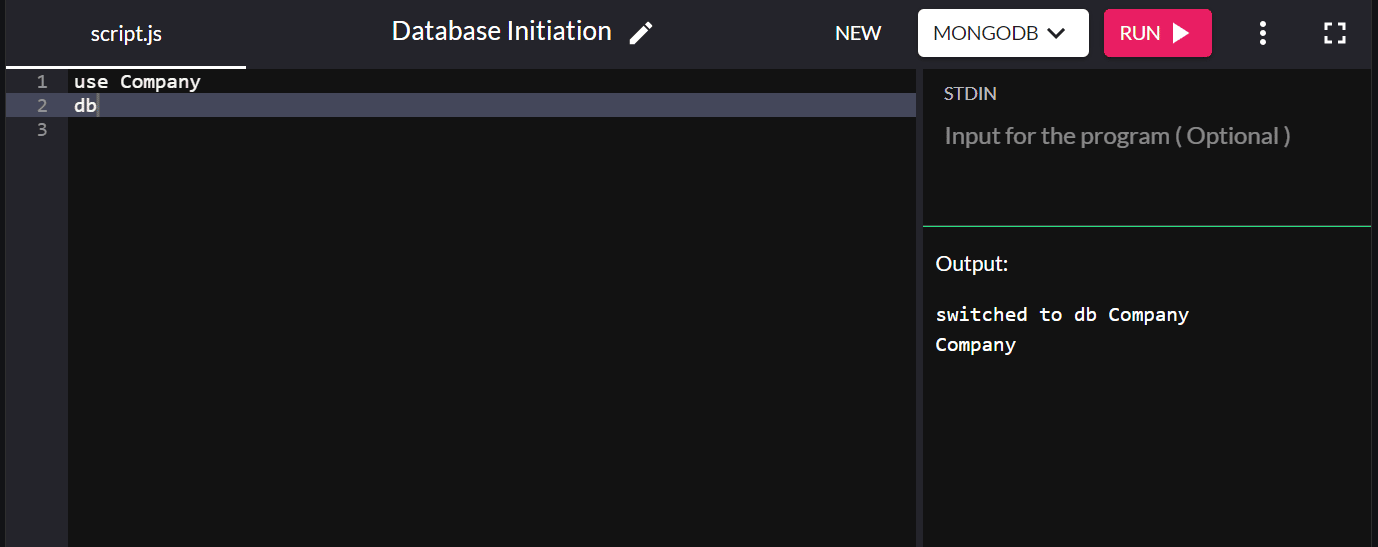
Vous pouvez taper db pour confirmer la base de données que vous venez de créer dans votre système. Si la nouvelle base de données que vous avez créée apparaît, vous vous y êtes connecté avec succès.
Si vous souhaitez vérifier les bases de données existantes, tapez show dbs et il renverra toutes les bases de données de votre système :
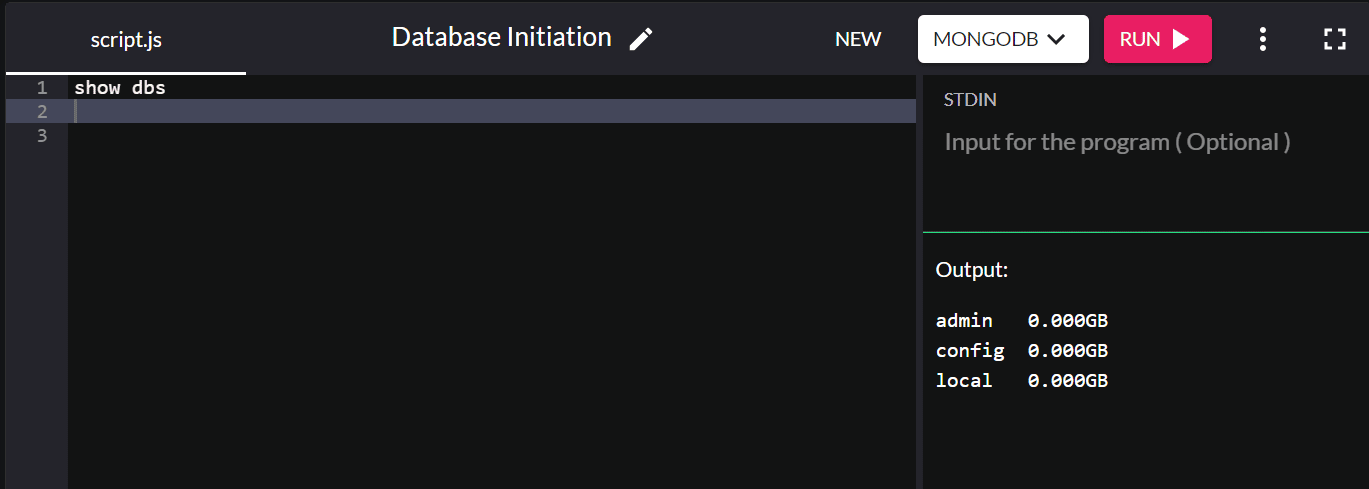
Par défaut, l'installation de MongoDB crée les bases de données d'administration, de configuration et locales.
Avez-vous remarqué que la base de données que nous avons créée ne s'affiche pas ? C'est parce que nous n'avons pas encore enregistré les valeurs dans la base de données ! Nous discuterons de l'insertion dans la section de gestion de la base de données.
Utilisation de l'interface utilisateur d'Atlas
Vous pouvez également démarrer avec le service de base de données de MongoDB, Atlas. Bien que vous deviez peut-être payer pour accéder à certaines fonctionnalités d'Atlas, la plupart des fonctionnalités de base de données sont disponibles avec le niveau gratuit. Les fonctionnalités du niveau gratuit sont plus que suffisantes pour créer une base de données MongoDB.
Avant de commencer, assurez-vous que :
- Votre adresse IP est sur la liste d'autorisation.
- Vous disposez d'un compte utilisateur et d'un mot de passe sur le cluster MongoDB que vous souhaitez utiliser.
Pour créer une base de données MongoDB avec AtlasUI, ouvrez une fenêtre de navigateur et connectez-vous à https://cloud.mongodb.com. À partir de la page de votre cluster, cliquez sur Parcourir les collections . S'il n'y a pas de bases de données dans le cluster, vous pouvez créer votre base de données en cliquant sur le bouton Ajouter mes propres données .
L'invite vous demandera de fournir une base de données et un nom de collection. Une fois que vous les avez nommés, cliquez sur Créer , et le tour est joué ! Vous pouvez maintenant saisir de nouveaux documents ou vous connecter à la base de données à l'aide de pilotes.
Gestion de votre base de données MongoDB
Dans cette section, nous allons passer en revue quelques façons astucieuses de gérer efficacement votre base de données MongoDB. Vous pouvez le faire en utilisant MongoDB Compass ou via des collections.
Utilisation des collections
Alors que les bases de données relationnelles possèdent des tables bien définies avec des types de données et des colonnes spécifiés, NoSQL a des collections au lieu de tables. Ces collections n'ont aucune structure et les documents peuvent varier — vous pouvez avoir différents types de données et champs sans avoir à faire correspondre le format d'un autre document dans la même collection.
Pour illustrer, créons une collection appelée "Employé" et ajoutons-y un document :
db.Employee.insert( { "Employeename" : "Chris", "EmployeeDepartment" : "Sales" } ) Si l'insertion réussit, elle renverra WriteResult({ "nInserted" : 1 }) :
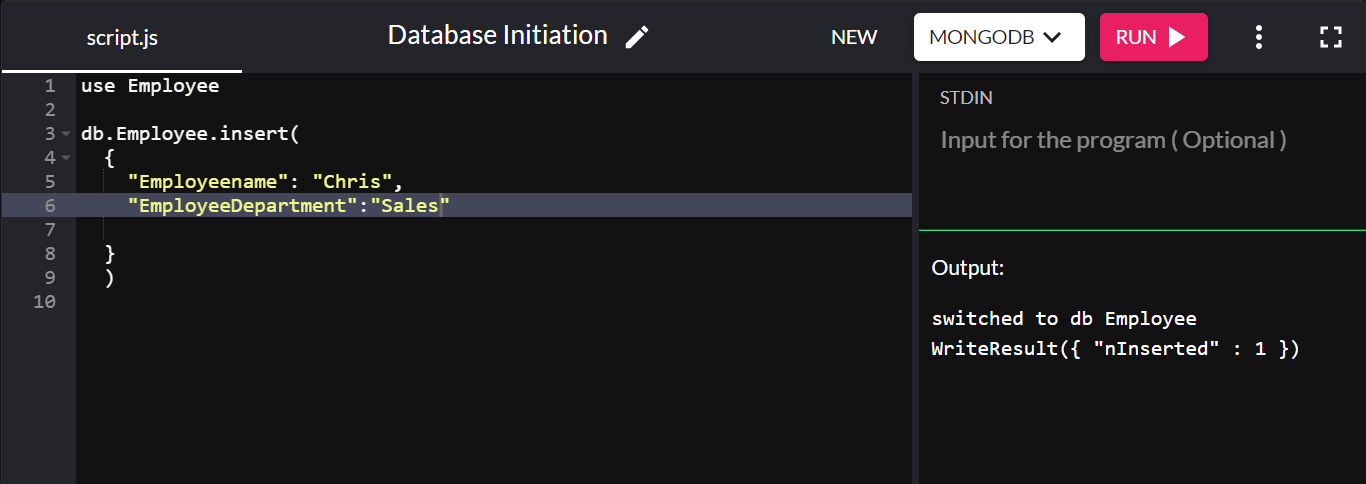
Ici, "db" fait référence à la base de données actuellement connectée. « Employé » est la collection nouvellement créée dans la base de données de l'entreprise.
Nous n'avons pas défini de clé primaire ici car MongoDB crée automatiquement un champ de clé primaire appelé "_id" et lui définit une valeur par défaut.
Exécutez la commande ci-dessous pour extraire la collection au format JSON :
db.Employee.find().forEach(printjson)Production:
{ "_id" : ObjectId("63151427a4dd187757d135b8"), "Employeename" : "Chris", "EmployeeDepartment" : "Sales" }Alors que la valeur "_id" est attribuée automatiquement, vous pouvez modifier la valeur de la clé primaire par défaut. Cette fois, nous allons insérer un autre document dans la base de données « Employé », avec la valeur « _id » comme « 1 » :
db.Employee.insert( { "_id" : 1, "EmployeeName" : "Ava", "EmployeeDepartment" : "Public Relations" } ) En exécutant la commande db.Employee.find().forEach(printjson) nous obtenons la sortie suivante :
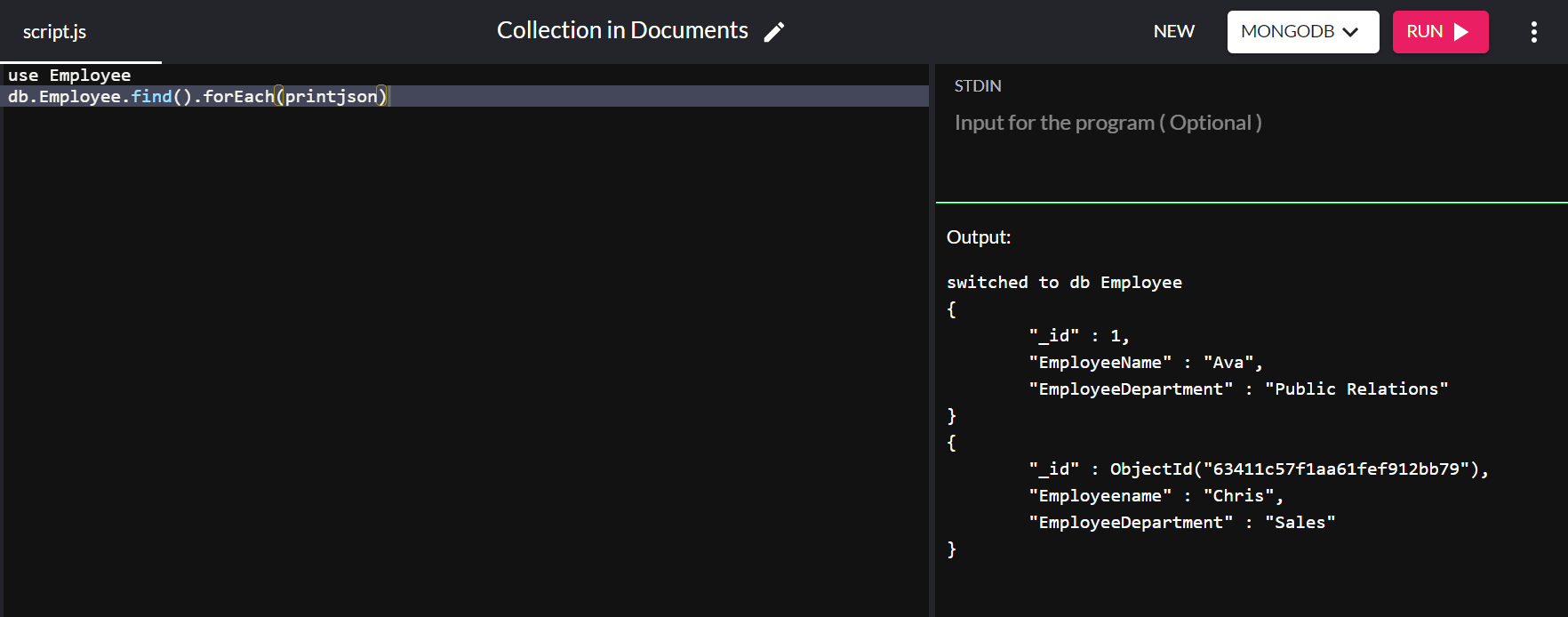
Dans la sortie ci-dessus, la valeur "_id" pour "Ava" est définie sur "1" au lieu de se voir attribuer une valeur automatiquement.
Maintenant que nous avons réussi à ajouter des valeurs dans la base de données, nous pouvons vérifier si elles apparaissent dans les bases de données existantes de notre système à l'aide de la commande suivante :
show dbs 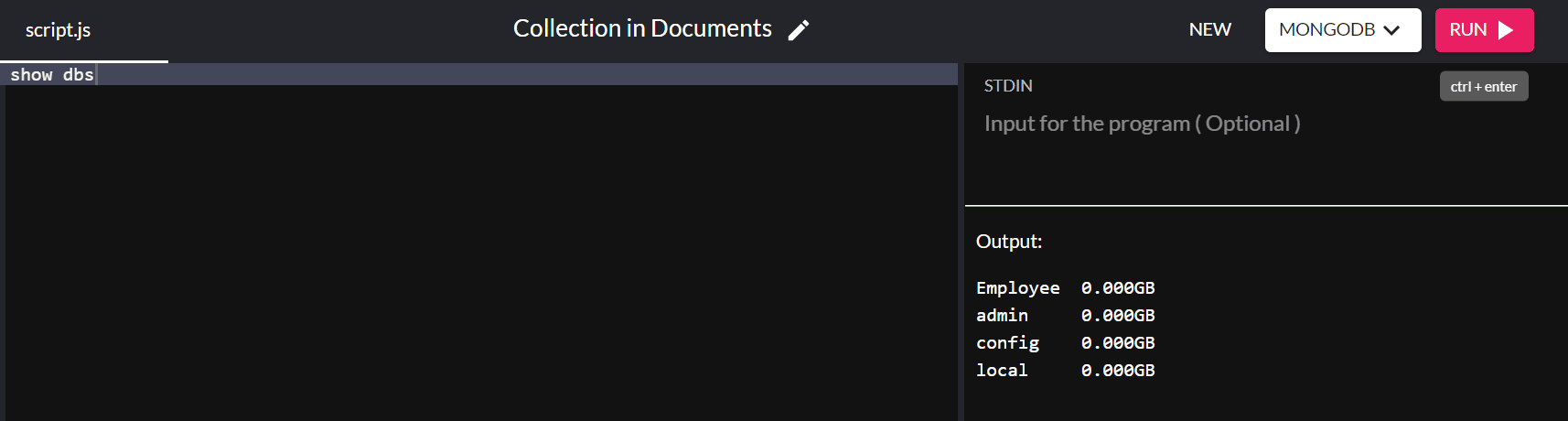
Et voila ! Vous avez créé avec succès une base de données dans votre système !
Utilisation de la boussole MongoDB
Bien que nous puissions travailler avec les serveurs MongoDB depuis le shell Mongo, cela peut parfois être fastidieux. Vous pouvez rencontrer cela dans un environnement de production.
Cependant, il existe un outil de boussole (nommé à juste titre Compass) créé par MongoDB qui peut le rendre plus facile. Il a une meilleure interface graphique et des fonctionnalités supplémentaires telles que la visualisation des données, le profilage des performances et l'accès CRUD (créer, lire, mettre à jour, supprimer) aux données, aux bases de données et aux collections.
Vous pouvez télécharger l'IDE Compass pour votre système d'exploitation et l'installer avec son processus simple.
Ensuite, ouvrez l'application et créez une connexion avec le serveur en collant la chaîne de connexion. Si vous ne le trouvez pas, vous pouvez cliquer sur Remplir les champs de connexion individuellement . Si vous n'avez pas changé le numéro de port lors de l'installation de MongoDB, cliquez simplement sur le bouton de connexion et vous êtes prêt ! Sinon, entrez simplement les valeurs que vous avez définies et cliquez sur Connecter .
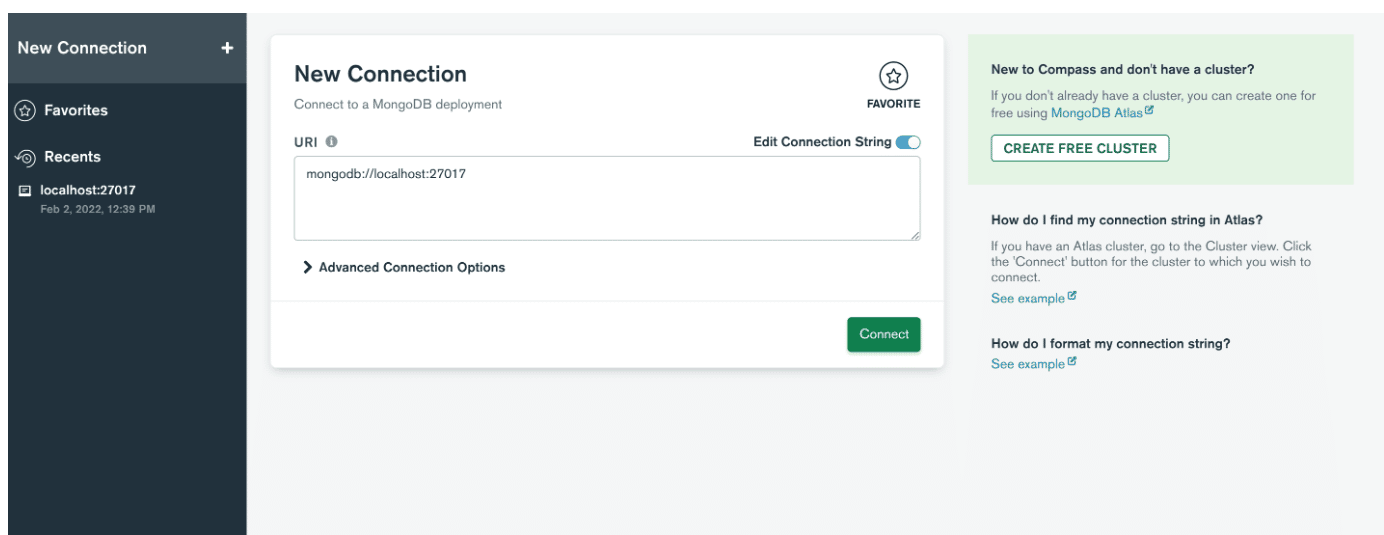
Ensuite, indiquez le nom d'hôte, le port et l'authentification dans la fenêtre Nouvelle connexion.
Dans MongoDB Compass, vous pouvez créer une base de données et ajouter sa première collection simultanément. Voici comment procéder :
- Cliquez sur Créer une base de données pour ouvrir l'invite.
- Entrez le nom de la base de données et sa première collection.
- Cliquez sur Créer une base de données .
Vous pouvez insérer plus de documents dans votre base de données en cliquant sur le nom de votre base de données, puis en cliquant sur le nom de la collection pour voir l'onglet Documents . Vous pouvez ensuite cliquer sur le bouton Ajouter des données pour insérer un ou plusieurs documents dans votre collection.
Lors de l'ajout de vos documents, vous pouvez les saisir un par un ou sous forme de plusieurs documents dans un tableau. Si vous ajoutez plusieurs documents, assurez-vous que ces documents séparés par des virgules sont entre crochets. Par exemple:
{ _id: 1, item: { name: "apple", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }, { _id: 2, item: { name: "banana", code: "123" }, qty: 20, tags: [ "B" ] }, { _id: 3, item: { name: "spinach", code: "456" }, qty: 25, tags: [ "A", "B" ] }, { _id: 4, item: { name: "lentils", code: "456" }, qty: 30, tags: [ "B", "A" ] }, { _id: 5, item: { name: "pears", code: "000" }, qty: 20, tags: [ [ "A", "B" ], "C" ] }, { _id: 6, item: { name: "strawberry", code: "123" }, tags: [ "B" ] }Enfin, cliquez sur Insérer pour ajouter les documents à votre collection. Voici à quoi ressemblerait le corps d'un document :
{ "StudentID" : 1 "StudentName" : "JohnDoe" }Ici, les noms de champ sont "StudentID" et "StudentName". Les valeurs des champs sont respectivement "1" et "JohnDoe".
Commandes utiles
Vous pouvez gérer ces collections via des commandes de gestion des rôles et des utilisateurs.
Commandes de gestion des utilisateurs
Les commandes de gestion des utilisateurs MongoDB contiennent des commandes qui se rapportent à l'utilisateur. Nous pouvons créer, mettre à jour et supprimer les utilisateurs à l'aide de ces commandes.
dropUser
Cette commande supprime un seul utilisateur de la base de données spécifiée. Ci-dessous la syntaxe :
db.dropUser(username, writeConcern) Ici, le nom d' username est un champ obligatoire qui contient le document avec les informations d'authentification et d'accès de l'utilisateur. Le champ facultatif writeConcern contient le niveau de préoccupation en écriture pour l'opération de création. Le niveau de préoccupation en écriture peut être déterminé par le champ facultatif writeConcern .
Avant de supprimer un utilisateur doté du rôle userAdminAnyDatabase , assurez-vous qu'au moins un autre utilisateur dispose des privilèges d'administration des utilisateurs.
Dans cet exemple, nous allons supprimer l'utilisateur « user26 » dans la base de données de test :
use test db.dropUser("user26", {w: "majority", wtimeout: 4000})Production:
> db.dropUser("user26", {w: "majority", wtimeout: 4000}); trueCréer un utilisateur
Cette commande crée un nouvel utilisateur pour la base de données spécifiée comme suit :
db.createUser(user, writeConcern) Ici, user est un champ obligatoire qui contient le document avec les informations d'authentification et d'accès sur l'utilisateur à créer. Le champ facultatif writeConcern contient le niveau de préoccupation en écriture pour l'opération de création. Le niveau de préoccupation d'écriture peut être déterminé par le champ facultatif, writeConcern .
createUser renverra une erreur d'utilisateur en double si l'utilisateur existe déjà dans la base de données.
Vous pouvez créer un nouvel utilisateur dans la base de données de test comme suit :
use test db.createUser( { user: "user26", pwd: "myuser123", roles: [ "readWrite" ] } );La sortie est la suivante :
Successfully added user: { "user" : "user26", "roles" : [ "readWrite", "dbAdmin" ] }grantRolesToUser
Vous pouvez utiliser cette commande pour accorder des rôles supplémentaires à un utilisateur. Pour l'utiliser, vous devez garder à l'esprit la syntaxe suivante :
db.runCommand( { grantRolesToUser: "<user>", roles: [ <roles> ], writeConcern: { <write concern> }, comment: <any> } ) Vous pouvez spécifier à la fois des rôles définis par l'utilisateur et des rôles intégrés dans les rôles mentionnés ci-dessus. Si vous souhaitez spécifier un rôle qui existe dans la même base de données où s'exécute grantRolesToUser , vous pouvez soit spécifier le rôle avec un document, comme indiqué ci-dessous :
{ role: "<role>", db: "<database>" }Ou, vous pouvez simplement spécifier le rôle avec le nom du rôle. Par exemple:
"readWrite"Si vous souhaitez spécifier le rôle présent dans une base de données différente, vous devrez spécifier le rôle avec un document différent.
Pour accorder un rôle sur une base de données, vous avez besoin de l'action grantRole sur la base de données spécifiée.
Voici un exemple pour vous donner une image claire. Prenons, par exemple, un utilisateur productUser00 dans la base de données des produits avec les rôles suivants :
"roles" : [ { "role" : "assetsWriter", "db" : "assets" } ] L'opération grantRolesToUser fournit à "productUser00" le rôle readWrite sur la base de données stock et le rôle read sur la base de données produits :
use products db.runCommand({ grantRolesToUser: "productUser00", roles: [ { role: "readWrite", db: "stock"}, "read" ], writeConcern: { w: "majority" , wtimeout: 2000 } })L'utilisateur productUser00 dans la base de données des produits possède désormais les rôles suivants :
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ]utilisateursInfo
Vous pouvez utiliser la commande usersInfo pour renvoyer des informations sur un ou plusieurs utilisateurs. Voici la syntaxe :
db.runCommand( { usersInfo: <various>, showCredentials: <Boolean>, showCustomData: <Boolean>, showPrivileges: <Boolean>, showAuthenticationRestrictions: <Boolean>, filter: <document>, comment: <any> } ) { usersInfo: <various> } En termes d'accès, les utilisateurs peuvent toujours consulter leurs propres informations. Pour consulter les informations d'un autre utilisateur, l'utilisateur exécutant la commande doit disposer de privilèges incluant l'action viewUser sur la base de données de l'autre utilisateur.
Lors de l'exécution de la commande userInfo , vous pouvez obtenir les informations suivantes en fonction des options spécifiées :
{ "users" : [ { "_id" : "<db>.<username>", "userId" : <UUID>, // Starting in MongoDB 4.0.9 "user" : "<username>", "db" : "<db>", "mechanisms" : [ ... ], // Starting in MongoDB 4.0 "customData" : <document>, "roles" : [ ... ], "credentials": { ... }, // only if showCredentials: true "inheritedRoles" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedPrivileges" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedAuthenticationRestrictions" : [ ] // only if showPrivileges: true or showAuthenticationRestrictions: true "authenticationRestrictions" : [ ... ] // only if showAuthenticationRestrictions: true }, ], "ok" : 1 } Maintenant que vous avez une idée générale de ce que vous pouvez accomplir avec la commande usersInfo , la prochaine question évidente qui pourrait surgir est de savoir quelles commandes seraient utiles pour examiner des utilisateurs spécifiques et plusieurs utilisateurs ?
Voici deux exemples pratiques pour illustrer la même chose :
Pour consulter les privilèges et informations spécifiques d'utilisateurs spécifiques, mais pas les informations d'identification, pour un utilisateur "Anthony" défini dans la base de données "office", exécutez la commande suivante :
db.runCommand( { usersInfo: { user: "Anthony", db: "office" }, showPrivileges: true } )Si vous souhaitez consulter un utilisateur dans la base de données actuelle, vous ne pouvez mentionner l'utilisateur que par son nom. Par exemple, si vous êtes dans la base de données d'accueil et qu'un utilisateur nommé "Timothy" existe dans la base de données d'accueil, vous pouvez exécuter la commande suivante :
db.getSiblingDB("home").runCommand( { usersInfo: "Timothy", showPrivileges: true } ) Ensuite, vous pouvez utiliser un tableau si vous souhaitez consulter les informations pour différents utilisateurs. Vous pouvez soit inclure les champs facultatifs showCredentials et showPrivileges , soit choisir de les omettre. Voici à quoi ressemblerait la commande :
db.runCommand({ usersInfo: [ { user: "Anthony", db: "office" }, { user: "Timothy", db: "home" } ], showPrivileges: true })révoquerRolesFromUser
Vous pouvez utiliser la commande revokeRolesFromUser pour supprimer un ou plusieurs rôles d'un utilisateur sur la base de données où les rôles sont présents. La commande revokeRolesFromUser a la syntaxe suivante :
db.runCommand( { revokeRolesFromUser: "<user>", roles: [ { role: "<role>", db: "<database>" } | "<role>", ], writeConcern: { <write concern> }, comment: <any> } ) Dans la syntaxe mentionnée ci-dessus, vous pouvez spécifier à la fois des rôles définis par l'utilisateur et des rôles intégrés dans le champ roles . Semblable à la commande grantRolesToUser , vous pouvez spécifier le rôle que vous souhaitez révoquer dans un document ou utiliser son nom.
Pour exécuter avec succès la commande revokeRolesFromUser , vous devez disposer de l'action revokeRole sur la base de données spécifiée.
Voici un exemple pour enfoncer le clou. L'entité productUser00 dans la base de données des produits avait les rôles suivants :
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ] La commande revokeRolesFromUser suivante supprimera deux des rôles de l'utilisateur : le rôle "read" des products et le rôle assetsWriter de la base de données "assets" :

use products db.runCommand( { revokeRolesFromUser: "productUser00", roles: [ { role: "AssetsWriter", db: "assets" }, "read" ], writeConcern: { w: "majority" } } )L'utilisateur « productUser00 » dans la base de données des produits n'a plus qu'un seul rôle :
"roles" : [ { "role" : "readWrite", "db" : "stock" } ]Commandes de gestion des rôles
Les rôles accordent aux utilisateurs l'accès aux ressources. Plusieurs rôles intégrés peuvent être utilisés par les administrateurs pour contrôler l'accès à un système MongoDB. Si les rôles ne couvrent pas les privilèges souhaités, vous pouvez même aller plus loin pour créer de nouveaux rôles dans une base de données particulière.
dropRole
Avec la commande dropRole , vous pouvez supprimer un rôle défini par l'utilisateur de la base de données sur laquelle vous exécutez la commande. Pour exécuter cette commande, utilisez la syntaxe suivante :
db.runCommand( { dropRole: "<role>", writeConcern: { <write concern> }, comment: <any> } ) Pour une exécution réussie, vous devez disposer de l'action dropRole sur la base de données spécifiée. Les opérations suivantes supprimeraient le rôle writeTags de la base de données « produits » :
use products db.runCommand( { dropRole: "writeTags", writeConcern: { w: "majority" } } )créer un rôle
Vous pouvez utiliser la commande createRole pour créer un rôle et spécifier ses privilèges. Le rôle s'appliquera à la base de données sur laquelle vous choisissez d'exécuter la commande. La commande createRole renverrait une erreur de rôle en double si le rôle existe déjà dans la base de données.
Pour exécuter cette commande, suivez la syntaxe donnée :
db.adminCommand( { createRole: "<new role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], roles: [ { role: "<role>", db: "<database>" } | "<role>", ], authenticationRestrictions: [ { clientSource: ["<IP>" | "<CIDR range>", ...], serverAddress: ["<IP>" | "<CIDR range>", ...] }, ], writeConcern: <write concern document>, comment: <any> } )Les privilèges d'un rôle s'appliqueraient à la base de données dans laquelle le rôle a été créé. Le rôle peut hériter des privilèges d'autres rôles dans sa base de données. Par exemple, un rôle créé sur la base de données « admin » peut inclure des privilèges qui s'appliquent à un cluster ou à toutes les bases de données. Il peut également hériter des privilèges des rôles présents dans d'autres bases de données.
Pour créer un rôle dans une base de données, vous devez disposer de deux éléments :
- L'action
grantRolesur cette base de données pour mentionner les privilèges du nouveau rôle ainsi que pour mentionner les rôles dont hériter. - L'action
createRolesur cette ressource de base de données.
La commande createRole suivante créera un rôle clusterAdmin sur la base de données utilisateur :
db.adminCommand({ createRole: "clusterAdmin", privileges: [ { resource: { cluster: true }, actions: [ "addShard" ] }, { resource: { db: "config", collection: "" }, actions: [ "find", "remove" ] }, { resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert" ] }, { resource: { db: "", collection: "" }, actions: [ "find" ] } ], roles: [ { role: "read", db: "user" } ], writeConcern: { w: "majority" , wtimeout: 5000 } })grantRolesToRole
Avec la commande grantRolesToRole , vous pouvez attribuer des rôles à un rôle défini par l'utilisateur. La commande grantRolesToRole affecterait les rôles sur la base de données où la commande est exécutée.
Cette commande grantRolesToRole a la syntaxe suivante :
db.runCommand( { grantRolesToRole: "<role>", roles: [ { role: "<role>", db: "<database>" }, ], writeConcern: { <write concern> }, comment: <any> } ) Les privilèges d'accès sont similaires à la commande grantRolesToUser — vous avez besoin d'une action grantRole sur une base de données pour l'exécution correcte de la commande.
Dans l'exemple suivant, vous pouvez utiliser la commande grantRolesToUser pour mettre à jour le rôle productsReader dans la base de données "products" afin d'hériter des privilèges du rôle productsWriter :
use products db.runCommand( { grantRolesToRole: "productsReader", roles: [ "productsWriter" ], writeConcern: { w: "majority" , wtimeout: 5000 } } )revokePrivilegesFromRole
Vous pouvez utiliser revokePrivilegesFromRole pour supprimer les privilèges spécifiés du rôle défini par l'utilisateur sur la base de données où la commande est exécutée. Pour une exécution correcte, vous devez garder à l'esprit la syntaxe suivante :
db.runCommand( { revokePrivilegesFromRole: "<role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], writeConcern: <write concern document>, comment: <any> } )Pour révoquer un privilège, le modèle « document de ressource » doit correspondre au champ « ressource » de ce privilège. Le champ "actions" peut être soit une correspondance exacte, soit un sous-ensemble.
Par exemple, considérez le rôle manageRole dans la base de données produits avec les privilèges suivants qui spécifient la base de données « managers » comme ressource :
{ "resource" : { "db" : "managers", "collection" : "" }, "actions" : [ "insert", "remove" ] }Vous ne pouvez pas révoquer les actions « insérer » ou « supprimer » d'une seule collection dans la base de données des gestionnaires. Les opérations suivantes n'entraînent aucune modification du rôle :
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert", "remove" ] } ] } ) db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert" ] } ] } ) Pour révoquer les actions « insert » et/ou « remove » du rôle manageRole , vous devez faire correspondre exactement le document de ressource. Par exemple, l'opération suivante révoque uniquement l'action « supprimer » du privilège existant :
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "" }, actions : [ "remove" ] } ] } )L'opération suivante supprimera plusieurs privilèges du rôle "exécutif" dans la base de données des managers :
use managers db.runCommand( { revokePrivilegesFromRole: "executive", privileges: [ { resource: { db: "managers", collection: "" }, actions: [ "insert", "remove", "find" ] }, { resource: { db: "managers", collection: "partners" }, actions: [ "update" ] } ], writeConcern: { w: "majority" } } )rôlesInfo
La commande rolesInfo renverra les informations de privilège et d'héritage pour les rôles spécifiés, y compris les rôles intégrés et définis par l'utilisateur. Vous pouvez également tirer parti de la commande rolesInfo pour récupérer tous les rôles étendus à une base de données.
Pour une exécution correcte, suivez cette syntaxe :
db.runCommand( { rolesInfo: { role: <name>, db: <db> }, showPrivileges: <Boolean>, showBuiltinRoles: <Boolean>, comment: <any> } )Pour renvoyer des informations sur un rôle à partir de la base de données actuelle, vous pouvez spécifier son nom comme suit :
{ rolesInfo: "<rolename>" }Pour renvoyer des informations pour un rôle depuis une autre base de données, vous pouvez mentionner le rôle avec un document mentionnant le rôle et la base de données :
{ rolesInfo: { role: "<rolename>", db: "<database>" } }Par exemple, la commande suivante renvoie les informations d'héritage de rôle pour le rôle cadre défini dans la base de données managers :
db.runCommand( { rolesInfo: { role: "executive", db: "managers" } } ) Cette commande suivante renverra les informations d'héritage de rôle : accountManager sur la base de données sur laquelle la commande est exécutée :
db.runCommand( { rolesInfo: "accountManager" } )La commande suivante renverra à la fois les privilèges et l'héritage de rôle pour le rôle "exécutif" tel que défini dans la base de données des gestionnaires :
db.runCommand( { rolesInfo: { role: "executive", db: "managers" }, showPrivileges: true } )Pour mentionner plusieurs rôles, vous pouvez utiliser un tableau. Vous pouvez également mentionner chaque rôle dans le tableau sous forme de chaîne ou de document.
Vous ne devez utiliser une chaîne que si le rôle existe sur la base de données sur laquelle la commande est exécutée :
{ rolesInfo: [ "<rolename>", { role: "<rolename>", db: "<database>" }, ] }Par exemple, la commande suivante renverra des informations pour trois rôles sur trois bases de données différentes :
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ] } )Vous pouvez obtenir à la fois les privilèges et l'héritage de rôle comme suit :
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ], showPrivileges: true } )Intégrer des documents MongoDB pour de meilleures performances
Les bases de données documentaires comme MongoDB vous permettent de définir votre schéma selon vos besoins. Pour créer des schémas optimaux dans MongoDB, vous pouvez imbriquer les documents. Ainsi, au lieu de faire correspondre votre application à un modèle de données, vous pouvez créer un modèle de données qui correspond à votre cas d'utilisation.
Les documents intégrés vous permettent de stocker des données associées auxquelles vous accédez ensemble. Lors de la conception de schémas pour MongoDB, il est recommandé d'intégrer des documents par défaut. N'utilisez les jointures et les références côté base de données ou côté application que lorsqu'elles en valent la peine.
Assurez-vous que la charge de travail peut récupérer un document aussi souvent que nécessaire. Dans le même temps, le document doit également contenir toutes les données dont il a besoin. Ceci est essentiel pour les performances exceptionnelles de votre application.
Ci-dessous, vous trouverez quelques modèles différents pour intégrer des documents :
Modèle de document intégré
Vous pouvez l'utiliser pour intégrer même des sous-structures complexes dans les documents avec lesquels elles sont utilisées. L'intégration de données connectées dans un seul document peut réduire le nombre d'opérations de lecture nécessaires pour obtenir des données. En règle générale, vous devez structurer votre schéma de manière à ce que votre application reçoive toutes les informations requises en une seule opération de lecture. Par conséquent, la règle à garder à l'esprit ici est que ce qui est utilisé ensemble doit être stocké ensemble .
Modèle de sous-ensemble intégré
Le modèle de sous-ensemble intégré est un cas hybride. Vous l'utiliserez pour une collection séparée d'une longue liste d'éléments connexes, où vous pourrez conserver certains de ces éléments à portée de main pour les afficher.
Voici un exemple qui répertorie les critiques de films :
> db.movie.findOne() { _id: 321475, title: "The Dark Knight" } > db.review.find({movie_id: 321475}) { _id: 264579, movie_id: 321475, stars: 4 text: "Amazing" } { _id: 375684, movie_id: 321475, stars:5, text: "Mindblowing" }Maintenant, imaginez un millier de critiques similaires, mais vous ne prévoyez d'afficher que les deux plus récentes lorsque vous montrez un film. Dans ce scénario, il est logique de stocker ce sous-ensemble sous forme de liste dans le document de film :
> db.movie.findOne({_id: 321475}) { _id: 321475, title: "The Dark Knight", recent_reviews: [ {_id: 264579, stars: 4, text: "Amazing"}, {_id: 375684, stars: 5, text: "Mindblowing"} ] }</codeEn termes simples, si vous accédez régulièrement à un sous-ensemble d'éléments connexes, assurez-vous de l'intégrer.
Accès indépendant
Vous souhaiterez peut-être stocker des sous-documents dans leur collection pour les séparer de leur collection parent.
Prenons par exemple la gamme de produits d'une entreprise. Si l'entreprise vend un petit ensemble de produits, vous souhaiterez peut-être les stocker dans le document de l'entreprise. Mais si vous souhaitez les réutiliser dans toutes les entreprises ou y accéder directement via leur unité de gestion des stocks (SKU), vous souhaitez également les stocker dans leur collection.
Si vous manipulez ou accédez à une entité indépendamment, créez une collection pour la stocker séparément pour les meilleures pratiques.
Listes illimitées
Le stockage de courtes listes d'informations connexes dans leur document présente un inconvénient. Si votre liste continue de s'allonger sans contrôle, vous ne devriez pas la mettre dans un seul document. C'est parce que vous ne pourriez pas le supporter très longtemps.
Il y a deux raisons à cela. Premièrement, MongoDB a une limite sur la taille d'un seul document. Deuxièmement, si vous accédez au document à trop de fréquences, vous verrez des résultats négatifs en raison d'une utilisation incontrôlée de la mémoire.
Pour le dire simplement, si une liste commence à croître sans limite, créez une collection pour la stocker séparément.
Motif de référence étendu
Le modèle de référence étendu est comme le modèle de sous-ensemble. It also optimizes information that you regularly access to store on the document.
Here, instead of a list, it's leveraged when a document refers to another that is present in the same collection. At the same time, it also stores some fields from that other document for ready access.
Par exemple:
> db.movie.findOne({_id: 245434}) { _id: 245434, title: "Mission Impossible 4 - Ghost Protocol", studio_id: 924935, studio_name: "Paramount Pictures" }As you can see, “the studio_id” is stored so that you can look up more information on the studio that created the film. But the studio's name is also copied to this document for simplicity.
To embed information from modified documents regularly, remember to update documents where you've copied that information when it is modified. In other words, if you routinely access some fields from a referenced document, embed them.
How To Monitor MongoDB
You can use monitoring tools like Kinsta APM to debug long API calls, slow database queries, long external URL requests, to name a few. You can even leverage commands to improve database performance. You can also use them to inspect the ase/” data-mce-href=”https://kinsta.com/knowledgebase/wordpress-repair-database/”>health of your database instances.
Why Should You Monitor MongoDB Databases?
A key aspect of database administration planning is monitoring your cluster's performance and health. MongoDB Atlas handles the majority of administration efforts through its fault-tolerance/scaling abilities.
Despite that, users need to know how to track clusters. They should also know how to scale or tweak whatever they need before hitting a crisis.
By monitoring MongoDB databases, you can:
- Observe the utilization of resources.
- Understand the current capacity of your database.
- React and detect real-time issues to enhance your application stack.
- Observe the presence of performance issues and abnormal behavior.
- Align with your governance/data protection and service-level agreement (SLA) requirements.
Key Metrics To Monitor
While monitoring MongoDB, there are four key aspects you need to keep in mind:
1. MongoDB Hardware Metrics
Here are the primary metrics for monitoring hardware:
Normalized Process CPU
It's defined as the percentage of time spent by the CPU on application software maintaining the MongoDB process.
You can scale this to a range of 0-100% by dividing it by the number of CPU cores. It includes CPU leveraged by modules such as kernel and user.
High kernel CPU might show exhaustion of CPU via the operating system operations. But the user linked with MongoDB operations might be the root cause of CPU exhaustion.
Normalized System CPU
It's the percentage of time the CPU spent on system calls servicing this MongoDB process. You can scale it to a range of 0-100% by dividing it by the number of CPU cores. It also covers the CPU used by modules such as iowait, user, kernel, steal, etc.
User CPU or high kernel might show CPU exhaustion through MongoDB operations (software). High iowait might be linked to storage exhaustion causing CPU exhaustion.
Disk IOPS
Disk IOPS is the average consumed IO operations per second on MongoDB's disk partition.
Disk Latency
This is the disk partition's read and write disk latency in milliseconds in MongoDB. High values (>500ms) show that the storage layer might affect MongoDB's performance.
System Memory
Use the system memory to describe physical memory bytes used versus available free space.
The available metric approximates the number of bytes of system memory available. You can use this to execute new applications, without swapping.
Disk Space Free
This is defined as the total bytes of free disk space on MongoDB's disk partition. MongoDB Atlas provides auto-scaling capabilities based on this metric.
Swap Usage
You can leverage a swap usage graph to describe how much memory is being placed on the swap device. A high used metric in this graph shows that swap is being utilized. This shows that the memory is under-provisioned for the current workload.
MongoDB Cluster's Connection and Operation Metrics
Here are the main metrics for Operation and Connection Metrics:
Operation Execution Times
The average operation time (write and read operations) performed over the selected sample period.
Opcounters
It is the average rate of operations executed per second over the selected sample period. Opcounters graph/metric shows the operations breakdown of operation types and velocity for the instance.
Connexions
This metric refers to the number of open connections to the instance. High spikes or numbers might point to a suboptimal connection strategy either from the unresponsive server or the client side.
Query Targeting and Query Executors
This is the average rate per second over the selected sample period of scanned documents. For query executors, this is during query-plan evaluation and queries. Query targeting shows the ratio between the number of documents scanned and the number of documents returned.
Un rapport de nombre élevé indique des opérations sous-optimales. Ces opérations numérisent un grand nombre de documents pour en restituer une plus petite partie.
Scannez et commandez
Il décrit le taux moyen par seconde sur la période d'échantillonnage choisie des requêtes. Il renvoie des résultats triés qui ne peuvent pas exécuter l'opération de tri à l'aide d'un index.
Files d'attente
Les files d'attente peuvent décrire le nombre d'opérations en attente d'un verrou, en écriture ou en lecture. Les files d'attente élevées peuvent indiquer l'existence d'une conception de schéma moins qu'optimale. Cela pourrait également indiquer des chemins d'écriture conflictuels, poussant à une forte concurrence sur les ressources de base de données.
Métriques de réplication MongoDB
Voici les principales métriques pour la surveillance de la réplication :
Fenêtre Oplog de réplication
Cette métrique répertorie le nombre approximatif d'heures disponibles dans l'oplog de réplication du primaire. Si un secondaire est plus en retard que ce montant, il ne peut pas suivre et aura besoin d'une resynchronisation complète.
Délai de réplication
Le décalage de réplication est défini comme le nombre approximatif de secondes pendant lesquelles un nœud secondaire est derrière le nœud principal dans les opérations d'écriture. Un décalage de réplication élevé indiquerait un secondaire qui a des difficultés à se répliquer. Cela peut avoir un impact sur la latence de votre opération, compte tenu du problème de lecture/écriture des connexions.
Marge de réplication
Cette métrique fait référence à la différence entre la fenêtre oplog de la réplication primaire et le décalage de réplication de la secondaire. Si cette valeur passe à zéro, cela pourrait faire passer un secondaire en mode RECOVERING.
Opcounters -repl
Opcounters -repl est défini comme le taux moyen d'opérations de réplication exécutées par seconde pour la période d'échantillonnage choisie. Avec opcounters -graph/metric, vous pouvez consulter la vitesse des opérations et la répartition des types d'opérations pour l'instance spécifiée.
Oplog Go/heure
Ceci est défini comme le taux moyen de gigaoctets d'oplog que le primaire génère par heure. Des volumes élevés et inattendus d'oplog peuvent indiquer une charge de travail d'écriture très insuffisante ou un problème de conception de schéma.
Outils de surveillance des performances MongoDB
MongoDB dispose d'outils d'interface utilisateur intégrés dans Cloud Manager, Atlas et Ops Manager pour le suivi des performances. Il fournit également des commandes et des outils indépendants pour examiner davantage de données brutes. Nous parlerons de certains outils que vous pouvez exécuter à partir d'un hôte disposant d'un accès et des rôles appropriés pour vérifier votre environnement :
mongotop
Vous pouvez tirer parti de cette commande pour suivre le temps qu'une instance MongoDB passe à écrire et à lire des données par collection. Utilisez la syntaxe suivante :
mongotop <options> <connection-string> <polling-interval in seconds>rs.status()
Cette commande renvoie l'état du jeu de répliques. Il est exécuté du point de vue du membre où la méthode est exécutée.
mongostat
Vous pouvez utiliser la commande mongostat pour obtenir un aperçu rapide de l'état de votre instance de serveur MongoDB. Pour une sortie optimale, vous pouvez l'utiliser pour regarder une seule instance d'un événement spécifique car il offre une vue en temps réel.
Tirez parti de cette commande pour surveiller les statistiques de base du serveur telles que les files d'attente de verrouillage, la panne des opérations, les statistiques de la mémoire MongoDB et les connexions/réseau :
mongostat <options> <connection-string> <polling interval in seconds>dbStats
Cette commande renvoie des statistiques de stockage pour une base de données spécifique, telles que le nombre d'index et leur taille, le total des données de collection par rapport à la taille de stockage et les statistiques liées à la collection (nombre de collections et de documents).
db.serverStatus()
Vous pouvez utiliser la commande db.serverStatus() pour avoir un aperçu de l'état de la base de données. Il vous donne un document représentant les compteurs de métriques de l'instance actuelle. Exécutez cette commande à intervalles réguliers pour rassembler des statistiques sur l'instance.
collStats
La commande collStats collecte des statistiques similaires à celles proposées par dbStats au niveau de la collecte. Sa sortie consiste en un nombre d'objets dans la collection, la quantité d'espace disque consommée par la collection, la taille de la collection et des informations concernant ses index pour une collection donnée.
Vous pouvez utiliser toutes ces commandes pour offrir des rapports et une surveillance en temps réel du serveur de base de données qui vous permettent de surveiller les performances et les erreurs de la base de données et d'aider à la prise de décision éclairée pour affiner une base de données.
Comment supprimer une base de données MongoDB
Pour supprimer une base de données que vous avez créée dans MongoDB, vous devez vous y connecter via le mot-clé use.
Supposons que vous ayez créé une base de données nommée "Engineers". Pour vous connecter à la base de données, vous utiliserez la commande suivante :
use Engineers Ensuite, tapez db.dropDatabase() pour vous débarrasser de cette base de données. Après exécution, voici le résultat auquel vous pouvez vous attendre :
{ "dropped" : "Engineers", "ok" : 1 } Vous pouvez exécuter la commande showdbs pour vérifier si la base de données existe toujours.
Sommaire
Pour extraire chaque dernière goutte de valeur de MongoDB, vous devez avoir une solide compréhension des fondamentaux. Par conséquent, il est essentiel de connaître les bases de données MongoDB comme le dos de votre main. Cela nécessite de vous familiariser avec les méthodes de création d'une base de données en premier.
Dans cet article, nous mettons en lumière les différentes méthodes que vous pouvez utiliser pour créer une base de données dans MongoDB, suivi d'une description détaillée de quelques commandes astucieuses de MongoDB pour vous garder au top de vos bases de données. Enfin, nous avons terminé la discussion en expliquant comment vous pouvez tirer parti des documents intégrés et des outils de surveillance des performances dans MongoDB pour garantir que votre flux de travail fonctionne avec une efficacité maximale.
Que pensez-vous de ces commandes MongoDB ? Avons-nous oublié un aspect ou une méthode que vous auriez aimé voir ici ? Faites le nous savoir dans les commentaires!