
Construire un ensemble de répliques MongoDB robuste en un temps record (4 méthodes)
Publié: 2023-03-11MongoDB est une base de données NoSQL qui utilise des documents de type JSON avec des schémas dynamiques. Lorsque vous travaillez avec des bases de données, il est toujours bon d'avoir un plan d'urgence en cas de défaillance de l'un de vos serveurs de base de données. Sidebar, vous pouvez réduire les risques que cela se produise en tirant parti d'un outil de gestion astucieux pour votre site WordPress.
C'est pourquoi il est utile d'avoir plusieurs copies de vos données. Il réduit également les latences de lecture. En même temps, cela peut améliorer l'évolutivité et la disponibilité de la base de données. C'est là qu'intervient la réplication. Elle est définie comme la pratique consistant à synchroniser les données sur plusieurs bases de données.
Dans cet article, nous allons plonger dans les différents aspects saillants de la réplication MongoDB, comme ses fonctionnalités et son mécanisme, pour n'en nommer que quelques-uns.
Qu'est-ce que la réplication dans MongoDB ?
Dans MongoDB, les jeux de répliques effectuent la réplication. Il s'agit d'un groupe de serveurs conservant le même ensemble de données via la réplication. Vous pouvez même utiliser la réplication MongoDB dans le cadre de l'équilibrage de charge. Ici, vous pouvez répartir les opérations d'écriture et de lecture sur toutes les instances, en fonction du cas d'utilisation.
Qu'est-ce qu'un ensemble de répliques MongoDB ?
Chaque instance de MongoDB qui fait partie d'un jeu de répliques donné est un membre. Chaque jeu de répliques doit avoir un membre principal et au moins un membre secondaire.
Le membre principal est le point d'accès principal pour les transactions avec le jeu de répliques. C'est aussi le seul membre qui peut accepter les opérations d'écriture. La réplication copie d'abord l'oplog du primaire (journal des opérations). Ensuite, il répète les modifications enregistrées sur les ensembles de données respectifs des secondaires. Par conséquent, chaque jeu de répliques ne peut avoir qu'un seul membre principal à la fois. Diverses primaires recevant des opérations d'écriture peuvent provoquer des conflits de données.
Généralement, les applications interrogent uniquement le membre principal pour les opérations d'écriture et de lecture. Vous pouvez concevoir votre configuration pour lire à partir d'un ou plusieurs membres secondaires. Le transfert de données asynchrone peut amener les lectures des nœuds secondaires à servir d'anciennes données. Ainsi, un tel agencement n'est pas idéal pour tous les cas d'utilisation.
Caractéristiques de l'ensemble de répliques
Le mécanisme de basculement automatique distingue les ensembles de répliques de MongoDB de ses concurrents. En l'absence de primaire, une élection automatisée parmi les nœuds secondaires sélectionne un nouveau primaire.
Ensemble de répliques MongoDB vs cluster MongoDB
Un jeu de répliques MongoDB créera diverses copies du même jeu de données sur les nœuds du jeu de répliques. L'objectif principal d'un jeu de répliques est de :
- Offrir une solution de sauvegarde intégrée
- Accroître la disponibilité des données
Un cluster MongoDB est un tout autre jeu de balle. Il distribue les données sur de nombreux nœuds via une clé de partition. Ce processus fragmentera les données en plusieurs morceaux appelés fragments. Ensuite, il copie chaque fragment sur un nœud différent. Un cluster vise à prendre en charge de grands ensembles de données et des opérations à haut débit. Il y parvient en faisant évoluer horizontalement la charge de travail.
Voici la différence entre un jeu de répliques et un cluster, en termes simples :
- Un cluster distribue la charge de travail. Il stocke également des fragments de données (fragments) sur de nombreux serveurs.
- Un jeu de réplicas duplique complètement le jeu de données.
MongoDB vous permet de combiner ces fonctionnalités en créant un cluster fragmenté. Ici, vous pouvez répliquer chaque partition sur un serveur secondaire. Cela permet à une partition d'offrir une redondance et une disponibilité des données élevées.
La maintenance et la configuration d'un jeu de répliques peuvent être techniquement fastidieuses et chronophages. Et trouver le bon service d'hébergement ? C'est un tout autre casse-tête. Avec autant d'options disponibles, il est facile de perdre des heures à faire des recherches au lieu de développer votre entreprise.
Permettez-moi de vous donner un aperçu d'un outil qui fait tout cela et bien plus encore afin que vous puissiez recommencer à l'écraser avec votre service/produit.
La solution d'hébergement d'applications de Kinsta, à laquelle plus de 55 000 développeurs font confiance, vous pouvez vous lancer et l'utiliser en seulement 3 étapes simples. Si cela semble trop beau pour être vrai, voici quelques autres avantages de l'utilisation de Kinsta :
- Profitez de meilleures performances avec les connexions internes de Kinsta : Oubliez vos galères avec les bases de données partagées. Basculez vers des bases de données dédiées avec des connexions internes qui n'ont pas de limite de nombre de requêtes ou de nombre de lignes. Kinsta est plus rapide, plus sécurisé et ne vous facturera pas de bande passante/trafic interne.
- Un ensemble de fonctionnalités sur mesure pour les développeurs : faites évoluer votre application sur la plate-forme robuste qui prend en charge Gmail, YouTube et la recherche Google. Rassurez-vous, vous êtes entre de bonnes mains ici.
- Profitez de vitesses inégalées avec un centre de données de votre choix : Choisissez la région qui vous convient le mieux, à vous et à vos clients. Avec plus de 25 centres de données parmi lesquels choisir, les 275+ PoP de Kinsta garantissent une vitesse maximale et une présence mondiale pour votre site Web.
Essayez gratuitement la solution d'hébergement d'applications de Kinsta dès aujourd'hui !
Comment fonctionne la réplication dans MongoDB ?
Dans MongoDB, vous envoyez des opérations d'écriture au serveur principal (nœud). Le serveur principal affecte les opérations sur les serveurs secondaires, en répliquant les données.
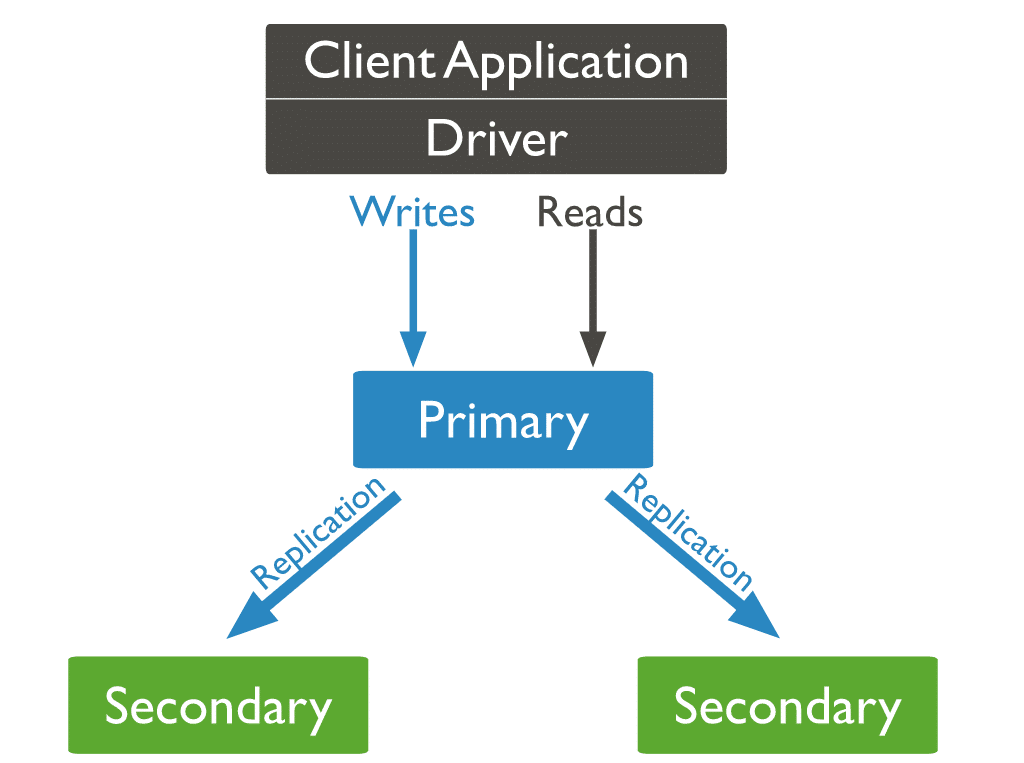
Trois types de nœuds MongoDB
Parmi les trois types de nœuds MongoDB, deux sont déjà apparus : les nœuds primaires et secondaires. Le troisième type de nœud MongoDB qui s'avère utile lors de la réplication est un arbitre. Le nœud arbitre n'a pas de copie de l'ensemble de données et ne peut pas devenir un nœud principal. Cela dit, l'arbitre participe aux élections pour la primaire.
Nous avons déjà mentionné ce qui se passe lorsque le nœud principal tombe en panne, mais que se passe-t-il si les nœuds secondaires mordent la poussière ? Dans ce scénario, le nœud principal devient secondaire et la base de données devient inaccessible.
Élection des membres
Les élections peuvent avoir lieu dans les scénarios suivants :
- Initialisation d'un jeu de répliques
- Perte de connectivité au nœud principal (qui peut être détectée par des battements de cœur)
- Maintenance d'un jeu de répliques à l'aide des méthodes
rs.reconfigoustepDown - Ajout d'un nouveau nœud à un jeu de répliques existant
Un ensemble de répliques peut posséder jusqu'à 50 membres, mais seulement 7 ou moins peuvent voter lors d'une élection.
Le temps moyen avant qu'un cluster élise un nouveau primaire ne doit pas dépasser 12 secondes. L'algorithme d'élection essaiera d'avoir le secondaire avec la priorité la plus élevée disponible. En même temps, les membres avec une valeur de priorité de 0 ne peuvent pas devenir primaires et ne participent pas à l'élection.
Le souci de l'écriture
Pour la durabilité, les opérations d'écriture ont un cadre pour copier les données dans un nombre spécifié de nœuds. Vous pouvez même offrir des commentaires au client avec cela. Ce cadre est également connu sous le nom de « problème d'écriture ». Il a des membres porteurs de données qui doivent accuser réception d'un problème d'écriture avant que l'opération ne soit réussie. Généralement, les jeux de répliques ont une valeur de 1 en tant que problème d'écriture. Ainsi, seul le primaire doit accuser réception de l'écriture avant de renvoyer l'accusé de réception concernant l'écriture.
Vous pouvez même augmenter le nombre de membres nécessaires pour accuser réception de l'opération d'écriture. Il n'y a pas de plafond au nombre de membres que vous pouvez avoir. Mais, si les chiffres sont élevés, vous devez faire face à une latence élevée. En effet, le client doit attendre l'accusé de réception de tous les membres. En outre, vous pouvez définir la préoccupation d'écriture de la «majorité». Cela calcule plus de la moitié des membres après avoir reçu leur accusé de réception.
Préférence de lecture
Pour les opérations de lecture, vous pouvez mentionner la préférence de lecture qui décrit comment la base de données dirige la requête vers les membres du jeu de répliques. Généralement, le nœud primaire reçoit l'opération de lecture mais le client peut mentionner une préférence de lecture pour envoyer les opérations de lecture aux nœuds secondaires. Voici les options pour la préférence de lecture :
- primaryPreferred : Habituellement, les opérations de lecture proviennent du nœud principal, mais si celui-ci n'est pas disponible, les données sont extraites des nœuds secondaires.
- primary : Toutes les opérations de lecture proviennent du nœud primaire.
- secondaire : Toutes les opérations de lecture sont exécutées par les nœuds secondaires.
- le plus proche : Ici, les requêtes de lecture sont acheminées vers le nœud accessible le plus proche, qui peut être détecté en exécutant la commande
ping. Le résultat des opérations de lecture peut provenir de n'importe quel membre du jeu de répliques, qu'il s'agisse du primaire ou du secondaire. - SecondaryPreferred : Ici, la plupart des opérations de lecture proviennent des nœuds secondaires, mais si aucun d'entre eux n'est disponible, les données sont extraites du nœud principal.
Synchronisation des données du jeu de réplication
Pour conserver des copies à jour de l'ensemble de données partagées, les membres secondaires d'un ensemble de répliques répliquent ou synchronisent les données des autres membres.
MongoDB exploite deux formes de synchronisation des données. Synchronisation initiale pour remplir les nouveaux membres avec l'ensemble de données complet. Réplication pour exécuter les modifications continues de l'ensemble de données complet.
Synchronisation initiale
Lors de la synchronisation initiale, un nœud secondaire exécute la commande init sync pour synchroniser toutes les données du nœud principal vers un autre nœud secondaire contenant les dernières données. Par conséquent, le nœud secondaire exploite systématiquement la fonction tailable cursor pour interroger les dernières entrées oplog dans la collection local.oplog.rs du nœud principal et applique ces opérations dans ces entrées oplog.
À partir de MongoDB 5.2, les synchronisations initiales peuvent être basées sur la copie de fichiers ou logiques.
Synchronisation logique
Lorsque vous exécutez une synchronisation logique, MongoDB :
- Développe tous les index de collection au fur et à mesure que les documents sont copiés pour chaque collection.
- Duplique toutes les bases de données à l'exception de la base de données locale.
mongodanalyse chaque collection dans toutes les bases de données source et insère toutes les données dans ses doublons de ces collections. - Exécute toutes les modifications sur l'ensemble de données. En tirant parti de l'oplog de la source, le
mongodmet à niveau son ensemble de données pour décrire l'état actuel de l'ensemble de répliques. - Extrait les enregistrements oplog nouvellement ajoutés lors de la copie des données. Assurez-vous que le membre cible dispose de suffisamment d'espace disque dans la base de données locale pour stocker provisoirement ces enregistrements oplog pendant la durée de cette étape de copie des données.
Lorsque la synchronisation initiale est terminée, le membre passe de STARTUP2 à SECONDARY .
Synchronisation initiale basée sur la copie de fichiers
Dès le départ, vous ne pouvez l'exécuter que si vous utilisez MongoDB Enterprise. Ce processus exécute la synchronisation initiale en dupliquant et en déplaçant les fichiers sur le système de fichiers. Cette méthode de synchronisation peut être plus rapide que la synchronisation initiale logique dans certains cas. Gardez à l'esprit que la synchronisation initiale basée sur la copie de fichiers peut entraîner des décomptes inexacts si vous exécutez la méthode count() sans prédicat de requête.
Mais, cette méthode a aussi sa juste part de limites :
- Lors d'une synchronisation initiale basée sur la copie de fichiers, vous ne pouvez pas écrire dans la base de données locale du membre en cours de synchronisation. Vous ne pouvez pas non plus exécuter une sauvegarde sur le membre qui est synchronisé ou sur le membre à partir duquel la synchronisation est effectuée.
- Lors de l'utilisation du moteur de stockage chiffré, MongoDB utilise la clé source pour chiffrer la destination.
- Vous ne pouvez exécuter une synchronisation initiale qu'à partir d'un membre donné à la fois.
Réplication
Les membres secondaires répliquent les données de manière cohérente après la synchronisation initiale. Les membres secondaires dupliqueront l'oplog à partir de leur synchronisation à partir de la source et exécuteront ces opérations dans un processus asynchrone.
Les secondaires sont capables de modifier automatiquement leur synchronisation à partir de la source selon les besoins en fonction des modifications du temps de ping et de l'état de la réplication des autres membres.
Réplication en continu
À partir de MongoDB 4.4, la synchronisation à partir des sources envoie un flux continu d'entrées oplog à leurs secondaires de synchronisation. La réplication en continu réduit le décalage de réplication dans les réseaux à forte charge et à forte latence. Ça peut aussi:
- Réduisez le risque de perdre des opérations d'écriture avec
w:1en raison d'un basculement principal. - Diminue l'obsolescence des lectures à partir des secondaires.
- Réduisez la latence des opérations d'écriture avec
w:“majority”etw:>1. En bref, tout problème d'écriture qui doit attendre la réplication.
Réplication multithread
MongoDB écrivait des opérations par lots via plusieurs threads pour améliorer la simultanéité. MongoDB regroupe les lots par ID de document tout en appliquant chaque groupe d'opérations avec un thread différent.
MongoDB exécute toujours les opérations d'écriture sur un document donné dans son ordre d'écriture d'origine. Cela a changé dans MongoDB 4.0.
À partir de MongoDB 4.0, les opérations de lecture qui ciblaient les secondaires et sont configurées avec un niveau de préoccupation de lecture “majority” ou “local” liront désormais à partir d'un instantané WiredTiger des données si la lecture se produit sur un secondaire où les lots de réplication sont appliqués. La lecture à partir d'un instantané garantit une vue cohérente des données et permet à la lecture de se produire simultanément avec la réplication en cours sans avoir besoin d'un verrou.
Par conséquent, les lectures secondaires nécessitant ces niveaux de préoccupation de lecture n'ont plus besoin d'attendre que les lots de réplication soient appliqués et peuvent être traitées au fur et à mesure de leur réception.
Comment créer un ensemble de répliques MongoDB
Comme mentionné précédemment, MongoDB gère la réplication via des jeux de répliques. Dans les sections suivantes, nous mettrons en évidence quelques méthodes que vous pouvez utiliser pour créer des jeux de répliques pour votre cas d'utilisation.
Méthode 1 : Création d'un nouvel ensemble de répliques MongoDB sur Ubuntu
Avant de commencer, vous devez vous assurer que vous disposez d'au moins trois serveurs exécutant Ubuntu 20.04, avec MongoDB installé sur chaque serveur.
Pour configurer un jeu de répliques, il est essentiel de fournir une adresse à laquelle chaque membre du jeu de répliques peut être atteint par les autres membres du jeu. Dans ce cas, nous gardons trois membres dans l'ensemble. Bien que nous puissions utiliser des adresses IP, cela n'est pas recommandé car les adresses peuvent changer de manière inattendue. Une meilleure alternative peut être d'utiliser les noms d'hôte DNS logiques lors de la configuration des jeux de répliques.
Nous pouvons le faire en configurant le sous-domaine pour chaque membre de réplication. Bien que cela puisse être idéal pour un environnement de production, cette section explique comment configurer la résolution DNS en modifiant les fichiers hôtes respectifs de chaque serveur. Ce fichier nous permet d'attribuer des noms d'hôte lisibles aux adresses IP numériques. Ainsi, si de toute façon votre adresse IP change, il vous suffira de mettre à jour les fichiers des hosts sur les trois serveurs plutôt que de reconfigurer de toutes pièces le jeu de répliques !
Généralement, hosts sont stockés dans le répertoire /etc/ . Répétez les commandes ci-dessous pour chacun de vos trois serveurs :
sudo nano /etc/hostsDans la commande ci-dessus, nous utilisons nano comme éditeur de texte, cependant, vous pouvez utiliser n'importe quel éditeur de texte que vous préférez. Après les premières lignes qui configurent l'hôte local, ajoutez une entrée pour chaque membre du jeu de répliques. Ces entrées prennent la forme d'une adresse IP suivie du nom lisible par l'homme de votre choix. Bien que vous puissiez les nommer comme vous le souhaitez, assurez-vous d'être descriptif afin de savoir différencier chaque membre. Pour ce didacticiel, nous utiliserons les noms d'hôte ci-dessous :
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
En utilisant ces noms d'hôte, vos fichiers /etc/hosts ressembleraient aux lignes suivantes en surbrillance :

Enregistrez et fermez le fichier.
Après avoir configuré la résolution DNS pour le jeu de répliques, nous devons mettre à jour les règles de pare-feu pour leur permettre de communiquer entre elles. Exécutez la commande ufw suivante sur mongo0 pour fournir à mongo1 un accès au port 27017 sur mongo0 :
sudo ufw allow from mongo1_server_ip to any port 27017 À la place du paramètre mongo1_server_ip , entrez l'adresse IP réelle de votre serveur mongo1. De plus, si vous avez mis à jour l'instance Mongo sur ce serveur pour utiliser un port autre que celui par défaut, veillez à modifier 27017 pour refléter le port utilisé par votre instance MongoDB.
Ajoutez maintenant une autre règle de pare-feu pour permettre à mongo2 d'accéder au même port :
sudo ufw allow from mongo2_server_ip to any port 27017 À la place du paramètre mongo2_server_ip , entrez l'adresse IP réelle de votre serveur mongo2. Ensuite, mettez à jour les règles de pare-feu pour vos deux autres serveurs. Exécutez les commandes suivantes sur le serveur mongo1, en veillant à modifier les adresses IP à la place du paramètre server_ip pour refléter celles de mongo0 et mongo2, respectivement :
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017Enfin, exécutez ces deux commandes sur mongo2. Encore une fois, assurez-vous de saisir les adresses IP correctes pour chaque serveur :
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017Votre prochaine étape consiste à mettre à jour le fichier de configuration de chaque instance MongoDB pour autoriser les connexions externes. Pour permettre cela, vous devez modifier le fichier de configuration de chaque serveur pour refléter l'adresse IP et indiquer le jeu de répliques. Bien que vous puissiez utiliser n'importe quel éditeur de texte préféré, nous utilisons à nouveau l'éditeur de texte nano. Apportons les modifications suivantes dans chaque fichier mongod.conf.
Sur mongo0 :
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"Sur mongo1 :
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"Sur mongo2 :
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodAvec cela, vous avez activé la réplication pour l'instance MongoDB de chaque serveur.
Vous pouvez maintenant initialiser le jeu de réplicas en utilisant la méthode rs.initiate() . Cette méthode ne doit être exécutée que sur une seule instance MongoDB dans le jeu de répliques. Assurez-vous que le nom et le membre du jeu de répliques correspondent aux configurations que vous avez effectuées précédemment dans chaque fichier de configuration.
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })Si la méthode renvoie "ok": 1 dans la sortie, cela signifie que le jeu de répliques a été démarré correctement. Vous trouverez ci-dessous un exemple de ce à quoi la sortie devrait ressembler :
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }Arrêter le serveur MongoDB
Vous pouvez arrêter un serveur MongoDB en utilisant la méthode db.shutdownServer() . Vous trouverez ci-dessous la syntaxe de la même chose. force et timeoutsecs sont des paramètres facultatifs.
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) Cette méthode peut échouer si le membre du jeu de répliques mongod exécute certaines opérations lors de la construction d'index. Pour interrompre les opérations et forcer le membre à s'arrêter, vous pouvez saisir le paramètre booléen force sur true.

Redémarrez MongoDB avec –replSet
Pour réinitialiser la configuration, assurez-vous que chaque nœud de votre jeu de répliques est arrêté. Supprimez ensuite la base de données locale pour chaque nœud. Redémarrez-le à l'aide de l'indicateur –replSet et exécutez rs.initiate() sur une seule instance mongod pour le jeu de répliques.
mongod --replSet "rs0" rs.initiate() peut prendre un document de configuration de jeu de répliques facultatif, à savoir :
- L'option
Replication.replSetNameou—replSetpour spécifier le nom du jeu de répliques dans le champ_id. - Le tableau des membres, qui contient un document pour chaque membre du jeu de répliques.
La méthode rs.initiate() déclenche une élection et élit l'un des membres comme principal.
Ajouter des membres au jeu de répliques
Pour ajouter des membres à l'ensemble, démarrez des instances mongod sur différentes machines. Ensuite, démarrez un client mongo et utilisez la commande rs.add() .
La commande rs.add() a la syntaxe de base suivante :
rs.add(HOST_NAME:PORT)Par exemple,
Supposons que mongo1 est votre instance mongod et qu'elle écoute sur le port 27017. Utilisez la commande client Mongo rs.add() pour ajouter cette instance au jeu de répliques.
rs.add("mongo1:27017") Ce n'est qu'après vous être connecté au nœud principal que vous pouvez ajouter une instance mongod au jeu de répliques. Pour vérifier si vous êtes connecté au primaire, utilisez la commande db.isMaster() .
Supprimer des utilisateurs
Pour supprimer un membre, nous pouvons utiliser rs.remove()
Pour ce faire, arrêtez d'abord l'instance mongod que vous souhaitez supprimer en utilisant la méthode db.shutdownServer() dont nous avons parlé ci-dessus.
Ensuite, connectez-vous au primaire actuel du jeu de réplicas. Pour déterminer le primaire actuel, utilisez db.hello() lorsque vous êtes connecté à n'importe quel membre du jeu de réplicas. Une fois que vous avez déterminé le principal, exécutez l'une des commandes suivantes :
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 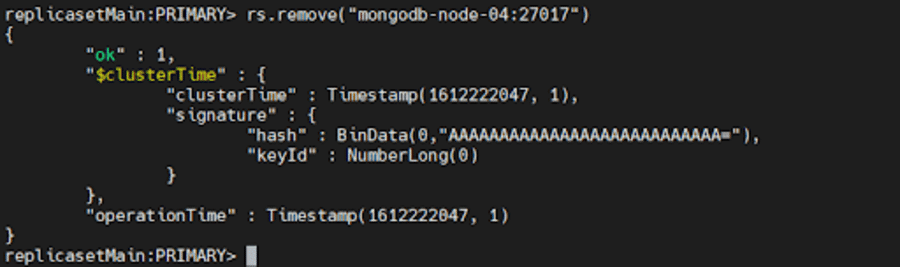
Si le jeu de réplicas doit élire un nouveau primaire, MongoDB peut déconnecter brièvement le shell. Dans ce scénario, il se reconnectera automatiquement une fois de plus. En outre, il peut afficher une erreur DBClientCursor::init call() failed même si la commande réussit.
Méthode 2 : Configuration d'un ensemble de répliques MongoDB pour le déploiement et les tests
En général, vous pouvez configurer des jeux de répliques pour les tests avec RBAC activé ou désactivé. Dans cette méthode, nous allons configurer des jeux de répliques avec le contrôle d'accès désactivé pour le déployer dans un environnement de test.
Commencez par créer des répertoires pour toutes les instances faisant partie du jeu de réplicas à l'aide de la commande suivante :
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2Cette commande créera des répertoires pour trois instances MongoDB replicaset0-0, replicaset0-1 et replicaset0-2. Maintenant, démarrez les instances MongoDB pour chacune d'entre elles à l'aide de l'ensemble de commandes suivant :
Pour le serveur 1 :
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Pour le serveur 2 :
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Pour le serveur 3 :
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 Le paramètre –oplogSize est utilisé pour éviter que la machine ne soit surchargée pendant la phase de test. Cela permet de réduire la quantité d'espace disque consommée par chaque disque.
Maintenant, connectez-vous à l'une des instances à l'aide du shell Mongo en vous connectant à l'aide du numéro de port ci-dessous.
mongo --port 27017 Nous pouvons utiliser la commande rs.initiate() pour démarrer le processus de réplication. Vous devrez remplacer le paramètre hostname par le nom de votre système.
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }Vous pouvez maintenant passer le fichier d'objet de configuration comme paramètre de la commande initiate et l'utiliser comme suit :
rs.initiate(rsconf)Et voila! Vous avez créé avec succès un jeu de répliques MongoDB à des fins de développement et de test.
Méthode 3 : Transformer une instance autonome en un ensemble de répliques MongoDB
MongoDB permet à ses utilisateurs de transformer leurs instances autonomes en jeux de répliques. Alors que les instances autonomes sont principalement utilisées pour la phase de test et de développement, les jeux de répliques font partie de l'environnement de production.
Pour commencer, fermons notre instance mongod à l'aide de la commande suivante :
db.adminCommand({"shutdown":"1"}) Redémarrez votre instance en utilisant le paramètre –repelSet dans votre commande pour spécifier le jeu de répliques que vous allez utiliser :
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>Vous devez spécifier le nom de votre serveur ainsi que l'adresse unique dans la commande.
Connectez le shell à votre instance MongoDB et utilisez la commande initiate pour démarrer le processus de réplication et convertir avec succès l'instance en un jeu de répliques. Vous pouvez effectuer toutes les opérations de base telles que l'ajout ou la suppression d'une instance à l'aide des commandes suivantes :
rs.add(“<host_name:port>”) rs.remove(“host-name”) De plus, vous pouvez vérifier l'état de votre jeu de répliques MongoDB à l'aide des commandes rs.status() et rs.conf() .
Méthode 4 : MongoDB Atlas — Une alternative plus simple
La réplication et le partitionnement peuvent fonctionner ensemble pour former ce qu'on appelle un cluster fragmenté. Bien que l'installation et la configuration puissent prendre beaucoup de temps, bien que simples, MongoDB Atlas est une meilleure alternative que les méthodes mentionnées précédemment.
Il automatise vos jeux de répliques, ce qui facilite la mise en œuvre du processus. Il peut déployer en quelques clics des ensembles de réplicas partagés à l'échelle mondiale, permettant une reprise après sinistre, une gestion simplifiée, la localisation des données et des déploiements multirégionaux.
Dans MongoDB Atlas, nous devons créer des clusters. Il peut s'agir soit d'un jeu de répliques, soit d'un cluster fragmenté. Pour un projet particulier, le nombre de nœuds dans un cluster dans d'autres régions est limité à un total de 40.
Cela exclut les clusters gratuits ou partagés et les régions cloud de Google communiquant entre elles. Le nombre total de nœuds entre deux régions doit respecter cette contrainte. Par exemple, s'il existe un projet dans lequel :
- La région A compte 15 nœuds.
- La région B a 25 nœuds
- La région C a 10 nœuds
Nous ne pouvons allouer que 5 nœuds supplémentaires à la région C car,
- Région A+ Région B = 40 ; répond à la contrainte de 40 étant le nombre maximum de nœuds autorisés.
- Région B+ Région C = 25+10+5 (nœuds supplémentaires alloués à C) = 40 ; répond à la contrainte de 40 étant le nombre maximum de nœuds autorisés.
- Région A+ Région C =15+10+5 (nœuds supplémentaires alloués à C) = 30 ; répond à la contrainte de 40 étant le nombre maximum de nœuds autorisés.
Si nous allouons 10 nœuds supplémentaires à la région C, ce qui fait que la région C a 20 nœuds, alors la région B + la région C = 45 nœuds. Cela dépasserait la contrainte donnée, de sorte que vous ne pourrez peut-être pas créer de cluster multirégional.
Lorsque vous créez un cluster, Atlas crée un conteneur réseau dans le projet pour le fournisseur de cloud s'il n'y était pas auparavant. Pour créer un cluster de jeu de répliques dans MongoDB Atlas, exécutez la commande suivante dans Atlas CLI :
atlas clusters create [name] [options]Assurez-vous de donner un nom de cluster descriptif, car il ne peut pas être modifié une fois le cluster créé. L'argument peut contenir des lettres ASCII, des chiffres et des traits d'union.
Plusieurs options sont disponibles pour la création de clusters dans MongoDB en fonction de vos besoins. Par exemple, si vous souhaitez une sauvegarde cloud continue pour votre cluster, définissez --backup sur true.
Gérer le retard de réplication
Le délai de réplication peut être assez rebutant. C'est un délai entre une opération sur le primaire et l'application de cette opération de l'oplog au secondaire. Si votre entreprise traite de grands ensembles de données, un retard est attendu dans un certain seuil. Cependant, parfois, des facteurs externes peuvent également contribuer et augmenter le retard. Pour bénéficier d'une réplication à jour, assurez-vous que :
- Vous acheminez votre trafic réseau dans une bande passante stable et suffisante. La latence du réseau joue un rôle énorme dans l'incidence de votre réplication, et si le réseau est insuffisant pour répondre aux besoins du processus de réplication, il y aura des retards dans la réplication des données dans l'ensemble du réplica.
- Vous disposez d'un débit disque suffisant. Si le système de fichiers et le périphérique de disque du secondaire sont incapables de vider les données sur le disque aussi rapidement que le principal, le secondaire aura du mal à suivre. Par conséquent, les nœuds secondaires traitent les requêtes d'écriture plus lentement que le nœud principal. Il s'agit d'un problème courant dans la plupart des systèmes mutualisés, y compris les instances virtualisées et les déploiements à grande échelle.
- Vous demandez un problème d'écriture d'accusé de réception d'écriture après un intervalle pour permettre aux serveurs secondaires de rattraper le serveur principal, en particulier lorsque vous souhaitez effectuer une opération de chargement en bloc ou une ingestion de données qui nécessite un grand nombre d'écritures sur le serveur principal. Les secondaires ne pourront pas lire l'oplog assez rapidement pour suivre les changements ; en particulier avec des problèmes d'écriture non reconnus.
- Vous identifiez les tâches en arrière-plan en cours d'exécution. Certaines tâches telles que les tâches cron, les mises à jour de serveur et les vérifications de sécurité peuvent avoir des effets inattendus sur l'utilisation du réseau ou du disque, entraînant des retards dans le processus de réplication.
Si vous ne savez pas s'il y a un décalage de réplication dans votre application, ne vous inquiétez pas - la section suivante traite des stratégies de dépannage !
Dépannage des ensembles de répliques MongoDB
Vous avez correctement configuré vos jeux de répliques, mais vous remarquez que vos données sont incohérentes sur les serveurs. Ceci est très alarmant pour les grandes entreprises, cependant, avec des méthodes de dépannage rapides, vous pouvez trouver la cause ou même corriger le problème ! Vous trouverez ci-dessous quelques stratégies courantes de dépannage des déploiements de jeux de répliques qui pourraient s'avérer utiles :
Vérifier l'état de la réplique
Nous pouvons vérifier l'état actuel du jeu de répliques et le statut de chaque membre en exécutant la commande suivante dans une session mongosh connectée au primaire d'un jeu de répliques.
rs.status()Vérifier le décalage de réplication
Comme indiqué précédemment, le décalage de réplication peut être un problème sérieux car il rend les membres « retardés » inéligibles pour devenir rapidement principaux et augmente la possibilité que les opérations de lecture distribuées soient incohérentes. Nous pouvons vérifier la longueur actuelle du journal de réplication en utilisant la commande suivante :
rs.printSecondaryReplicationInfo() Cela renvoie la valeur syncedTo qui est l'heure à laquelle la dernière entrée oplog a été écrite dans le secondaire pour chaque membre. Voici un exemple pour démontrer la même chose :
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary Un membre retardé peut s'afficher avec 0 seconde de retard sur le primaire lorsque la période d'inactivité sur le primaire est supérieure à la valeur members[n].secondaryDelaySecs .
Tester les connexions entre tous les membres
Chaque membre d'un jeu de réplicas doit pouvoir se connecter à tous les autres membres. Assurez-vous toujours de vérifier les connexions dans les deux sens. Généralement, les configurations de pare-feu ou les topologies de réseau empêchent la connectivité normale et requise, ce qui peut bloquer la réplication.
Par exemple, supposons que l'instance mongod se lie à la fois à localhost et au nom d'hôte 'ExampleHostname' qui est associé à l'adresse IP 198.41.110.1 :
mongod --bind_ip localhost, ExampleHostnamePour se connecter à cette instance, les clients distants doivent spécifier le nom d'hôte ou l'adresse IP :
mongosh --host ExampleHostname mongosh --host 198.41.110.1Si un jeu de réplicas se compose de trois membres, m1, m2 et m3, utilisant le port par défaut 27017, vous devez tester la connexion comme ci-dessous :
Sur m1 :
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017Au m2 :
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017Sur m3 :
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 Si une connexion dans n'importe quelle direction échoue, vous devrez vérifier la configuration de votre pare-feu et le reconfigurer pour autoriser les connexions.
Garantir des communications sécurisées avec l'authentification par fichier clé
Par défaut, l'authentification du fichier de clés dans MongoDB repose sur le mécanisme d'authentification par défi-réponse salé (SCRAM). Pour ce faire, MongoDB doit lire et valider les informations d'identification fournies par l'utilisateur qui incluent une combinaison du nom d'utilisateur, du mot de passe et de la base de données d'authentification dont l'instance MongoDB spécifique est consciente. C'est le mécanisme exact utilisé pour authentifier les utilisateurs qui fournissent un mot de passe lors de la connexion à la base de données.
Lorsque vous activez l'authentification dans MongoDB, le contrôle d'accès basé sur les rôles (RBAC) est automatiquement activé pour le jeu de répliques et l'utilisateur se voit attribuer un ou plusieurs rôles qui déterminent son accès aux ressources de la base de données. Lorsque RBAC est activé, cela signifie que seul l'utilisateur Mongo authentifié valide avec les privilèges appropriés pourra accéder aux ressources du système.
Le fichier clé agit comme un mot de passe partagé pour chaque membre du cluster. Cela permet à chaque instance mongod du jeu de répliques d'utiliser le contenu du fichier de clés comme mot de passe partagé pour authentifier les autres membres du déploiement.
Seules les instances mongod avec le fichier de clés correct peuvent rejoindre le jeu de réplicas. La longueur d'une clé doit être comprise entre 6 et 1024 caractères et ne peut contenir que des caractères de l'ensemble base64. Veuillez noter que MongoDB supprime les caractères d'espacement lors de la lecture des clés.
Vous pouvez générer un fichier clé en utilisant diverses méthodes. Dans ce tutoriel, nous utilisons openssl pour générer une chaîne complexe de 1024 caractères aléatoires à utiliser comme mot de passe partagé. It then uses chmod to change file permissions to provide read permissions for the file owner only. Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. Par exemple:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
And voila! You have successfully enabled keyfile authentication!
Résumé
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!