
Robots.txt : qu'est-ce que c'est et comment le créer (guide complet)
Publié: 2023-05-05Si vous possédez un site Web ou gérez son contenu, vous avez probablement entendu parler de robots.txt. Il s'agit d'un fichier qui indique aux robots des moteurs de recherche comment explorer et indexer les pages de votre site Web. Malgré son importance dans l'optimisation des moteurs de recherche (SEO), de nombreux propriétaires de sites Web négligent l'importance d'un fichier robots.txt bien conçu.
Dans ce guide complet, nous allons explorer ce qu'est le fichier robots.txt, pourquoi il est important pour le référencement et comment créer un fichier robots.txt pour votre site Web.
Qu'est-ce qu'un fichier Robots.txt ?
Un robots.txt est un fichier qui indique aux robots des moteurs de recherche (également appelés crawlers ou spiders) quelles pages ou sections d'un site Web doivent être explorées ou non. Il s'agit d'un fichier texte brut situé dans le répertoire racine d'un site Web, et il comprend généralement une liste de répertoires, de fichiers ou d'URL que le webmaster souhaite empêcher l'indexation ou l'exploration des moteurs de recherche.
Voici à quoi ressemble un fichier robots.txt :

Pourquoi Robots.txt est-il important ?
Robots.txt est important pour votre site Web pour trois raisons principales :
1. Maximiser le budget de crawl
Le "budget d'exploration" représente le nombre de pages que Google explorera sur votre site à un moment donné. Le nombre dépend de la taille, de la santé et de la quantité de backlinks sur votre site.
Le budget de crawl est important car si le nombre de pages de votre site dépasse le budget de crawl, vous aurez des pages non indexées.
De plus, les pages qui ne sont pas indexées ne seront classées pour rien.
En utilisant robots.txt pour bloquer les pages inutiles, Googlebot (le robot d'exploration de Google) peut dépenser une plus grande partie de votre budget d'exploration sur les pages qui comptent.
2. Bloquer les pages non publiques
Vous avez de nombreuses pages sur votre site que vous ne souhaitez pas indexer.
Par exemple, vous pouvez avoir une page de résultats de recherche interne ou une page de connexion. Ces pages doivent exister. Cependant, vous ne voulez pas que des personnes aléatoires atterrissent dessus.
Dans ce cas, vous utiliserez robots.txt pour empêcher les robots d'exploration et les robots des moteurs de recherche d'accéder à certaines pages.
3. Empêcher l'indexation des ressources
Parfois, vous souhaiterez que Google exclue des ressources telles que les fichiers PDF, les vidéos et les images des résultats de recherche.
Vous souhaitez peut-être que ces ressources restent privées ou que Google se concentre davantage sur le contenu important.
Dans de tels cas, l'utilisation de robots.txt est la meilleure approche pour empêcher leur indexation.
Comment fonctionne un fichier Robots.txt ?
Les fichiers Robots.txt indiquent aux robots des moteurs de recherche les pages ou les répertoires du site Web qu'ils doivent ou non explorer ou indexer.
Lors de l'exploration, les robots des moteurs de recherche trouvent et suivent des liens. Ce processus les conduit du site X au site Y puis au site Z via des milliards de liens et de sites Web.
Lorsqu'un bot visite un site, la première chose qu'il fait est de rechercher un fichier robots.txt.
S'il en détecte un, il lira le fichier avant de faire quoi que ce soit d'autre.
Par exemple, supposons que vous souhaitiez autoriser tous les bots, à l'exception de DuckDuckGo, à explorer votre site :
User-agent: DuckDuckBot Disallow: /
Remarque : Un fichier robots.txt ne peut donner que des instructions ; il ne peut pas les imposer. C'est comme un code de conduite. Les bons robots (tels que les robots des moteurs de recherche) suivront les règles, tandis que les mauvais robots (tels que les spambots) les ignoreront.
Comment trouver un fichier Robots.txt ?
Le fichier robots.txt, comme tout autre fichier de votre site Web, est hébergé sur votre serveur.
Vous pouvez accéder au fichier robots.txt de n'importe quel site Web en saisissant l'URL complète de la page d'accueil, puis en ajoutant /robots.txt à la fin, par exemple https://pickupwp.com/robots.txt.
Cependant, si le site Web ne contient pas de fichier robots.txt, vous recevrez un message d'erreur « 404 Not Found ».
Comment créer un fichier Robots.txt ?
Avant de montrer comment créer un fichier robots.txt, examinons d'abord la syntaxe robots.txt.
La syntaxe d'un fichier robots.txt peut être décomposée selon les composants suivants :
- User-agent : cela spécifie le robot ou le robot d'exploration auquel l'enregistrement s'applique. Par exemple, "User-agent : Googlebot" ne s'appliquerait qu'au robot d'exploration de Google, tandis que "User-agent : *" s'appliquerait à tous les robots d'exploration.
- Disallow : Cela spécifie les pages ou les répertoires que le robot ne doit pas explorer. Par exemple, "Disallow: /private/" empêcherait les robots d'explorer toutes les pages du répertoire "privé".
- Autoriser : Cela spécifie les pages ou les répertoires que le robot doit être autorisé à explorer, même si le répertoire parent n'est pas autorisé. Par exemple, « Autoriser : /public/ » permettrait aux robots d'explorer toutes les pages du répertoire « public », même si le répertoire parent n'est pas autorisé.
- Crawl-delay : Cela spécifie le temps en secondes que le robot doit attendre avant de crawler le site Web. Par exemple, "Crawl-delay : 10" demanderait au robot d'attendre 10 secondes avant d'explorer le site Web.
- Plan du site : indique l'emplacement du plan du site Web. Par exemple, "Sitemap: https://www.example.com/sitemap.xml" informera le robot de l'emplacement du sitemap du site Web.
Voici un exemple de fichier robots.txt :
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
Remarque : Il est important de noter que les fichiers robots.txt sont sensibles à la casse. Il est donc important d'utiliser la casse correcte lors de la spécification des URL.
Par exemple, /public/ n'est pas identique à /Public/.
D'autre part, les directives comme "Autoriser" et "Refuser" ne sont pas sensibles à la casse, c'est donc à vous de les mettre en majuscule ou non.
Après avoir appris la syntaxe robots.txt, vous pouvez créer un fichier robots.txt à l'aide d'un outil générateur de robots.txt ou en créer un vous-même.
Voici comment créer un fichier robots.txt en seulement quatre étapes :
1. Créez un nouveau fichier et nommez-le Robots.txt
Ouvrez simplement un document .txt avec n'importe quel éditeur de texte ou navigateur Web.
Ensuite, donnez au document le nom robots.txt. Pour fonctionner, il doit être nommé robots.txt.
Une fois cela fait, vous pouvez maintenant commencer à taper des directives.
2. Ajouter des directives au fichier Robots.txt
Un fichier robots.txt contient un ou plusieurs groupes de directives, chacun avec plusieurs lignes d'instructions.
Chaque groupe commence par un "User-agent" et contient les données suivantes :
- À qui le groupe s'applique (l'agent utilisateur)
- À quels répertoires (pages) ou fichiers l'agent peut-il accéder ?
- À quels répertoires (pages) ou fichiers l'agent n'a-t-il pas accès ?
- Un sitemap (facultatif) pour informer les moteurs de recherche des sites et des fichiers que vous jugez importants.
Les lignes qui ne correspondent à aucune de ces directives sont ignorées par les robots.

Par exemple, vous souhaitez empêcher Google d'explorer votre répertoire /privé/.
Cela ressemblerait à ceci :
User-agent: Googlebot Disallow: /private/
Si vous aviez d'autres instructions comme celle-ci pour Google, vous les placeriez dans une ligne séparée juste en dessous comme ceci :
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
De plus, si vous avez terminé avec les instructions spécifiques de Google et que vous souhaitez créer un nouveau groupe de directives.
Par exemple, si vous vouliez empêcher tous les moteurs de recherche d'explorer vos répertoires /archive/ et /support/.
Cela ressemblerait à ceci :
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
Lorsque vous avez terminé, vous pouvez ajouter votre sitemap.
Votre fichier robots.txt terminé devrait ressembler à ceci :
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
Ensuite, enregistrez votre fichier robots.txt. N'oubliez pas qu'il doit être nommé robots.txt.
Pour des règles robots.txt plus utiles, consultez ce guide utile de Google.
3. Téléchargez le fichier Robots.txt
Après avoir enregistré votre fichier robots.txt sur votre ordinateur, téléchargez-le sur votre site Web et mettez-le à la disposition des moteurs de recherche.
Malheureusement, aucun outil ne peut vous aider dans cette étape.
Le téléchargement du fichier robots.txt dépend de la structure de fichiers et de l'hébergement Web de votre site.
Pour savoir comment télécharger votre fichier robots.txt, effectuez une recherche en ligne ou contactez votre fournisseur d'hébergement.
4. Testez votre fichier Robots.txt
Après avoir téléchargé le fichier robots.txt, vous pouvez ensuite vérifier si quelqu'un peut le voir et si Google peut le lire.
Ouvrez simplement un nouvel onglet dans votre navigateur et recherchez votre fichier robots.txt.
Par exemple, https://pickupwp.com/robots.txt.
Si vous voyez votre fichier robots.txt, vous êtes prêt à tester le balisage (code HTML).
Pour cela, vous pouvez utiliser un testeur Google robots.txt.
Remarque : Vous disposez d'un compte Search Console configuré pour tester votre fichier robots.txt à l'aide du testeur robots.txt.
Le testeur robots.txt trouvera les avertissements de syntaxe ou les erreurs de logique et les mettra en évidence.
De plus, il vous montre également les avertissements et les erreurs sous l'éditeur.
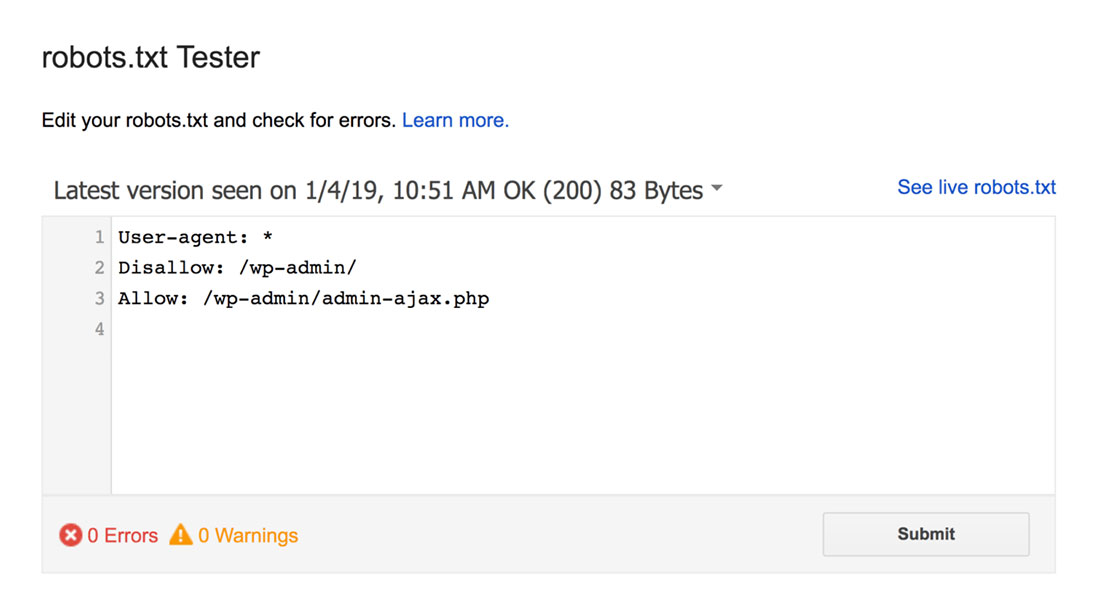
Vous pouvez modifier les erreurs ou les avertissements sur la page et retester aussi souvent que nécessaire.
N'oubliez pas que les modifications apportées à la page ne sont pas enregistrées sur votre site.
Pour apporter des modifications, copiez et collez ceci dans le fichier robots.txt de votre site.
Meilleures pratiques pour Robots.txt
Gardez ces bonnes pratiques à l'esprit lors de la création de votre fichier robots.txt pour éviter certaines erreurs courantes.
1. Utilisez de nouvelles lignes pour chaque directive
Pour éviter toute confusion pour les robots des moteurs de recherche, ajoutez chaque directive à une nouvelle ligne dans votre fichier robots.txt. Cela s'applique aux règles Autoriser et Interdire.
Par exemple, si vous ne souhaitez pas qu'un robot d'exploration Web explore votre blog ou votre page de contact, ajoutez les règles suivantes :
Disallow: /blog/ Disallow: /contact/
2. Utilisez chaque agent utilisateur une seule fois
Les robots n'ont aucun problème si vous utilisez le même agent utilisateur encore et encore.
Cependant, l'utiliser une seule fois maintient les choses organisées et réduit les risques d'erreur humaine.
3. Utilisez des caractères génériques pour simplifier les instructions
Si vous avez un grand nombre de pages à bloquer, l'ajout d'une règle pour chacune peut prendre du temps. Heureusement, vous pouvez utiliser des caractères génériques pour simplifier vos instructions.
Un joker est un caractère qui peut représenter un ou plusieurs caractères. Le caractère générique le plus couramment utilisé est l'astérisque (*).
Par exemple, si vous souhaitez bloquer tous les fichiers qui se terminent par .jpg, vous ajouterez la règle suivante :
Disallow: /*.jpg
4. Utilisez "$" pour spécifier la fin d'une URL
Le signe dollar ($) est un autre caractère générique qui peut être utilisé pour identifier la fin d'une URL. Ceci est utile si vous souhaitez restreindre une page spécifique mais pas celles qui la suivent.
Supposons que vous souhaitiez bloquer la page de contact mais pas la page de réussite du contact, vous ajouteriez la règle suivante :
Disallow: /contact$
5. Utilisez le dièse (#) pour ajouter des commentaires
Tout ce qui commence par un dièse (#) est ignoré par les robots.
Par conséquent, les développeurs utilisent souvent le hachage pour ajouter des commentaires au fichier robots.txt. Il maintient le document organisé et lisible.
Par exemple, si vous souhaitez empêcher tous les fichiers se terminant par .jpg, vous pouvez ajouter le commentaire suivant :
# Block all files that end in .jpg Disallow: /*.jpg
Cela aide tout le monde à comprendre à quoi sert la règle et pourquoi elle est là.
6. Utilisez des fichiers Robots.txt distincts pour chaque sous-domaine
Si votre site Web comporte plusieurs sous-domaines, il est recommandé de créer un fichier robots.txt individuel pour chacun. Cela permet de garder les choses organisées et aide les robots des moteurs de recherche à saisir vos règles plus facilement.
Emballer!
Le fichier robots.txt est un outil de référencement utile car il indique aux robots des moteurs de recherche ce qu'il faut indexer et ce qu'il ne faut pas.
Cependant, il est important de l'utiliser avec prudence. Étant donné qu'une mauvaise configuration peut entraîner une désindexation complète de votre site Web (par exemple, en utilisant Disallow: /).
Généralement, le bon moyen est de permettre aux moteurs de recherche d'analyser autant que possible votre site tout en conservant les informations sensibles et en évitant le contenu en double. Par exemple, vous pouvez utiliser la directive Disallow pour empêcher des pages ou des répertoires spécifiques ou la directive Allow pour remplacer une règle Disallow pour une page particulière.
Il convient également de mentionner que tous les bots ne suivent pas les règles fournies dans le fichier robots.txt, ce n'est donc pas une méthode parfaite pour contrôler ce qui est indexé. Mais cela reste un outil précieux à avoir dans votre stratégie de référencement.
Nous espérons que ce guide vous aidera à comprendre ce qu'est un fichier robots.txt et comment en créer un.
Pour en savoir plus, vous pouvez consulter ces autres ressources utiles :
- 15 conseils de blogs exploitables pour les nouveaux blogueurs
- Libérer la puissance des mots-clés à longue traîne (Guide du débutant)
Enfin, suivez-nous sur Twitter pour des mises à jour régulières sur les nouveaux articles.