
Que faire si infecté par le spam SEO sur WordPress
Publié: 2021-05-17Chez Jetpack, faire face à différents types de menaces et d'attaques Web fait partie de notre routine. La plupart du temps, cela va de la collecte d'un fichier malveillant et de la recherche du vecteur d'attaque à l'assistance à la restauration d'un site Web à partir de la dernière sauvegarde. Mais parfois, nous entrons dans une dimension différente d'attaques vraiment créatives, une dimension de réinfections inexplicables – nous entrons… dans la zone crépusculaire.
D'accord, je suis probablement trop dramatique, mais restez avec moi alors que je prépare le terrain pour ce conte mystérieux. Prêt? S'il vous plaît, rejoignez-moi dans ce voyage au royaume des fantômes, du spam et des moteurs de recherche.
Le comportement malveillant
Nous avons trouvé un site Web qui faisait l'objet d'un type d'attaque très intéressant. Il a d'abord fait surface sous la forme d'un e-mail envoyé par la console de recherche Google : une URL peu commune (et une URL très suspecte, avec une URL cliquable à l'intérieur) a été répertoriée comme une page à la croissance la plus élevée.
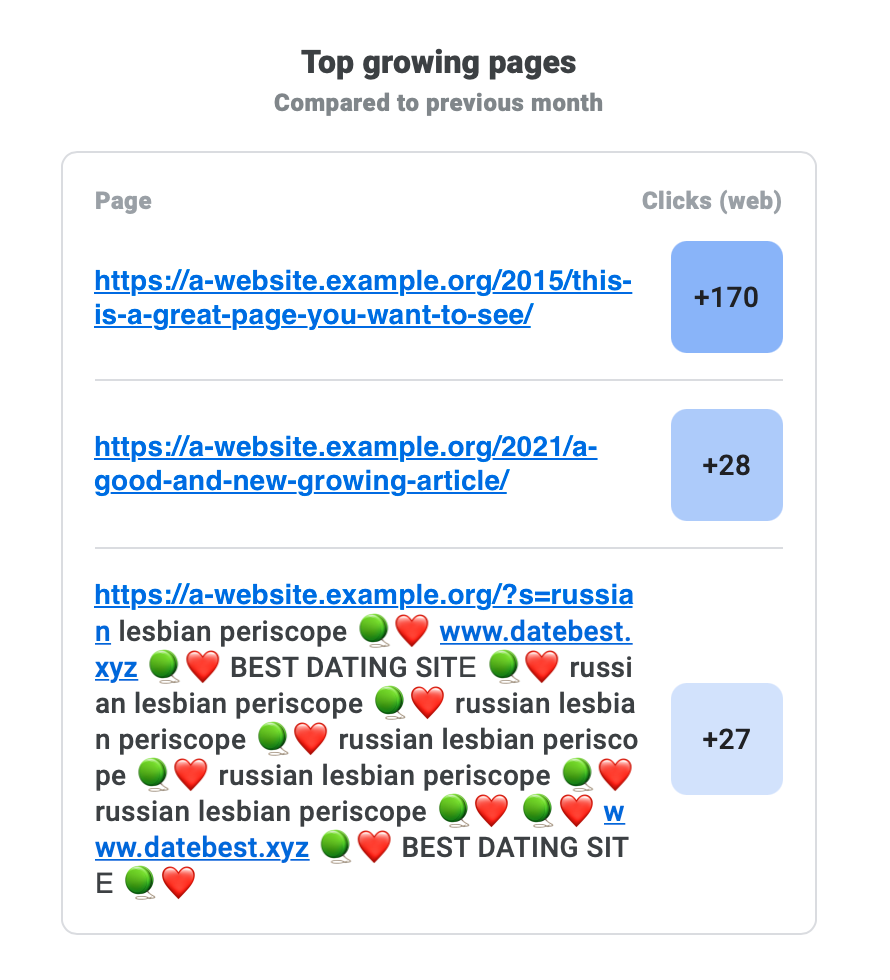
Le propriétaire du site Web était un peu contrarié car un tel comportement est souvent le résultat d'une infection, mais Jetpack ne l'avait pas détecté ni averti de quoi que ce soit. De plus, ces pages n'existaient même pas sur le site Web lors de leur vérification, mais étaient de toute façon indexées par Google. La zone crépusculaire s'intensifie .
Lorsque nous avons vérifié tous les fichiers suspects que Jetpack Scan aurait pu manquer (aucun outil de sécurité ne détecte 100 % des menaces), les choses sont devenues encore plus étranges. WordPress Core et les plugins étaient intacts : aucun fichier ou script injecté sur la base de données. Quelques plugins obsolètes n'avaient aucun correctif de sécurité, WordPress avait une version de retard (5.6) et la dernière mise à jour ne répertoriait aucun correctif de sécurité important. Il n'y avait rien de suspect du tout. Pas de suspects habituels, pas de preuves d'attaques ; pas encore en tout cas.
La prochaine étape logique consiste à vérifier les journaux d'accès. Cela pourrait peut-être éclaircir ce mystère. Découvririons-nous que nous sommes confrontés à une attaque zero-day, ou que nous avons enfin trouvé une preuve de la théorie du multivers, et que ce site Web n'est infecté que dans l'Univers #1337 ? Aux bûches !


Comme vous vous en doutez : rien d'étrange, à part un tas de requêtes vers ces pages de spam, comme vous pouvez le voir sur les captures d'écran. Et ils retournaient tous un "200 OK". Donc, la page existait quelque part dans le continuum de temps et d'espace, ou… attendez une seconde… la voyez-vous maintenant ?
Toutes ces pages pointaient vers le même emplacement : `/?s=`, ce qui signifie que les moteurs de recherche (le problème a été remarqué par Google, mais les requêtes proviennent de Bing) indexaient les pages de résultats de recherche. Et pourquoi est-ce que? Le robot d'exploration n'effectue pas de recherches sur la page, à notre connaissance, n'est-ce pas ?
Le paradoxe de l'indexation
Les bases du fonctionnement d'un moteur de recherche sont assez simples si vous êtes dans le domaine des sites Web. Il existe un robot (ou un script automatisé) qui parcourt les pages Web, indexe son contenu, effectue de la magie et stocke les ressources interrogeables quelque part dans le cloud.
Dans cet esprit, nous avons creusé un peu plus les journaux pour voir si l'une de ces demandes avait un autre indice, comme un référent, mais pas de chance du tout. Toutes les requêtes enregistrées provenaient de moteurs de recherche. Heureusement, Google Search Console avait l'une des pages de référence dans l'un des journaux.
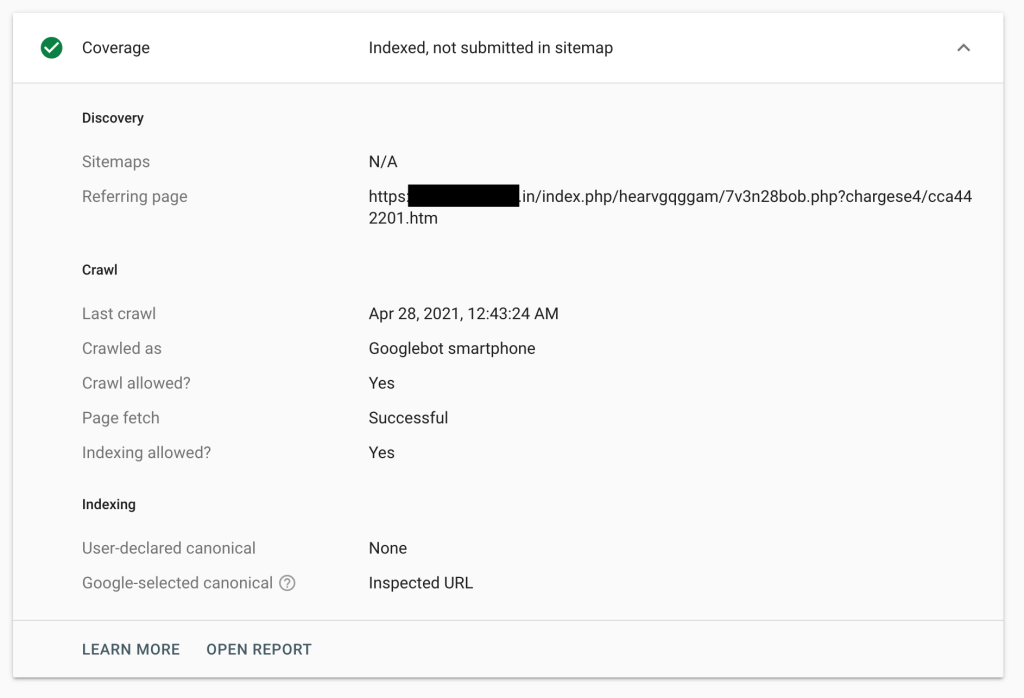
Maintenant, je pense qu'il est temps de changer notre chapeau Twilight Zone pour un chapeau CSI et de déterrer quelques os de site Web à mettre sous le microscope.
Pour un œil averti, il est facile de voir que l'URL de la page de référence appartenait à un site Web compromis ; heureusement, nous avons des yeux bien entraînés ! Le répertoire `index.php` n'a aucun sens et il a probablement été ajouté pour confondre le propriétaire du site Web. Ensuite, il est suivi d'un autre répertoire aléatoire et d'un fichier PHP avec un nom aléatoire, qui est probablement un chargeur qui reçoit la charge utile finale : le `cargese4/cca442201.htm`, qui est également aléatoire. Tous ces éléments sont des caractéristiques d'une infection par un logiciel malveillant de ferme de liens.
Une recherche rapide sur Google pour voir ce qui était indexé pour le site référent a confirmé qu'il était effectivement infecté et qu'il servait du spam SEO pendant un certain temps. Le site est destiné à une entreprise alimentaire en Inde mais propose des offres sur les SUV au Japon - oui, c'est du spam.
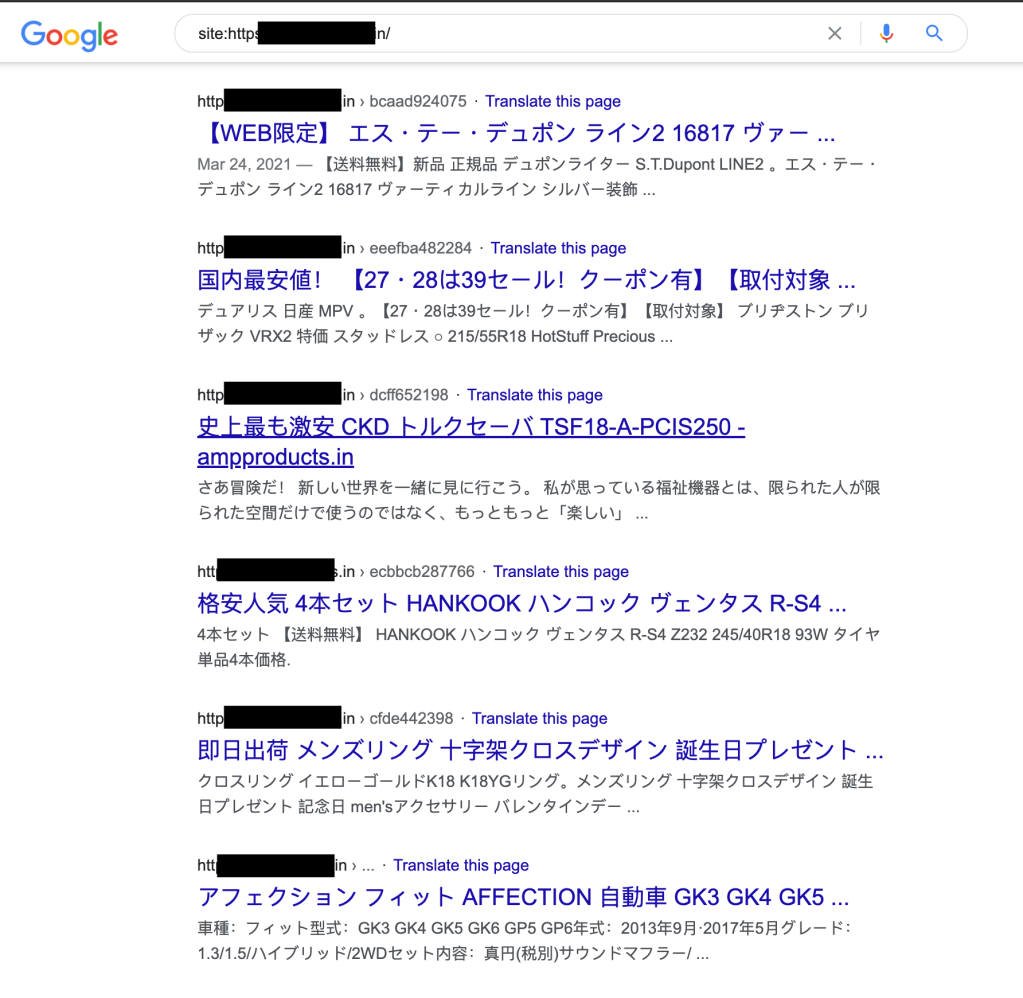
Mais, aucun des résultats n'était lié au site Web de notre ami, j'ai donc décidé de rechercher si d'autres sites étaient affectés par ce même comportement étrange.

Afin de rechercher d'autres victimes de cette attaque de spam, nous avons utilisé, à des fins éducatives uniquement, nos connaissances Google-fu pour créer une requête de recherche qui renverrait les sites se terminant par .edu, qui avaient `/?s=` dans l'URL, et le mot "acheter" dans le titre. Et nous avons obtenu 22 résultats. Ce qui est suffisant pour notre chasse.

C'est la preuve que le site signalé n'était pas le seul touché; il semble que ce soit un problème plus répandu. Nous avons réfléchi à ce qui aurait pu amener Google à indexer ces pages. Comment le Googlebot les a-t-il contactés ? Prochaine étape : les vérificateurs de backlinks.
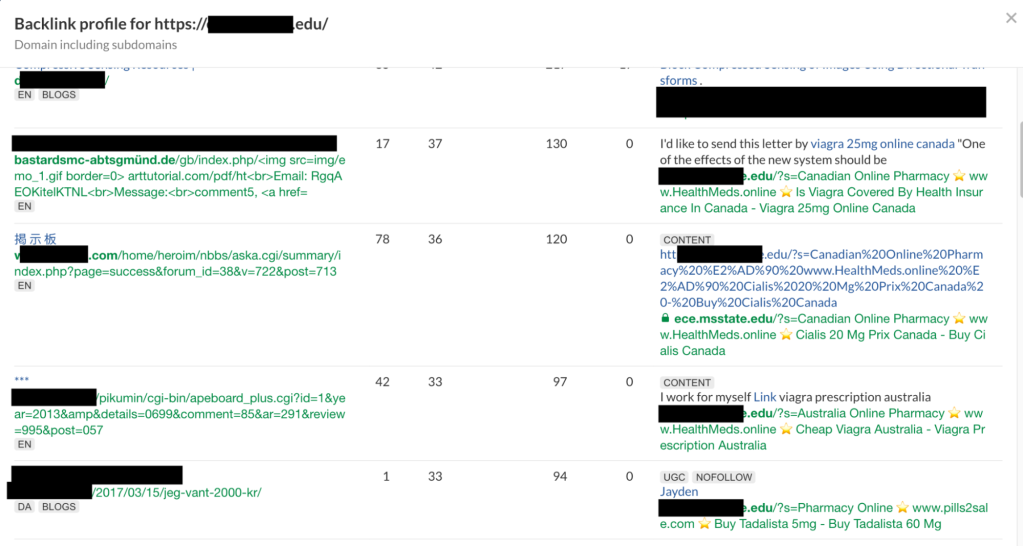
Il existe plusieurs outils en ligne qui fournissent des rapports sur les backlinks vers des sites Web ; celui que nous avons utilisé dans cette recherche était Ahrefs, mais d'autres outils peuvent atteindre les mêmes résultats. Certaines des pages de recherche malveillantes sont répertoriées dans les résultats, confirmant que nous étions sur la bonne voie.
En sélectionnant l'un de ces sites Web pour vérifier ce qui se passait, nous avons vu près de 5 000 commentaires de spam, comme vous pouvez le voir dans la capture d'écran suivante (ils devraient consulter Jetpack Anti-spam). Chaque commentaire renvoyait à une page de recherche de site Web avec du spam dans la requête.
Attraper le lapin blanc
Comme je l'ai déjà mentionné, les robots des moteurs de recherche n'effectuent pas de requêtes sur les pages des sites Web. Mais, s'il trouve un lien vers celui-ci, il sera suivi. Et si la page n'indique pas au script automatisé qu'une page particulière n'est pas indexable, il l'ajoutera.

Il s'agit d'une méthode intelligente pour "injecter" du spam sur un site Web afin de spammer les résultats des moteurs de recherche et d'augmenter le classement des pages du site grâce à une ferme de liens à faible effort.
Maintenant que nous comprenons le problème, comment dire aux robots des moteurs de recherche d'éviter de suivre les liens vers les pages de recherche (ou simplement de refuser de les indexer) ? La meilleure façon serait de modifier WordPress Core, ce qui aiderait à protéger l'ensemble de la communauté (si vous souhaitez signaler un bogue ou contribuer au code, veuillez nous rejoindre).
Afin d'éviter des retouches inutiles, nous avons vérifié le trac de WordPress Core et trouvé ce problème qui a été résolu sur la version 5.7 mais qui n'a malheureusement pas été ajouté au journal des modifications en tant que problème de sécurité.
Je vais citer l'auteur, qui a décrit le problème mieux que moi (merci abagtcs pour le rapport):
Les spammeurs Web ont commencé à abuser des fonctionnalités de recherche de ces sites en transmettant des termes de spam et des noms d'hôte dans l'espoir d'améliorer le classement de recherche des sites des spammeurs.
Les spammeurs placent ces liens dans des wikis ouverts, des commentaires de blogs, des forums et d'autres fermes de liens, en s'appuyant sur les moteurs de recherche qui explorent leurs liens, puis visitent et indexent les pages de résultats de recherche résultantes avec du contenu spam.
Cette attaque est étonnamment assez répandue, affectant de nombreux sites Web à travers le monde. Bien que certains CMS et sites alimentés par un code écrit sur mesure puissent être vulnérables à cette technique, sur la base d'une enquête préliminaire, il semble que - du moins dans l'espace .edu - la plate-forme Web la plus ciblée soit de loin WordPress.
Ce n'est pas surprenant quand plus de 41% des plus gros sites du web sont des sites WordPress.
Clôture du dossier
Il y a quelques bonnes leçons à tirer de cet incident :
- L'URL présentée sur Top Growing Pages n'est pas bien filtrée, donc les URL de spam que vous voyez séparées par des emojis sont en fait directement cliquables (salut amis Google, c'est sur vous) ; les utilisateurs ignorants pourraient cliquer dessus et accéder à du contenu indésirable.
- Certains ajustements sont nécessaires à Google pour éviter d'indexer des pages clairement spammées. Sur la base du rapport de l'outil, certaines pages claires ont été explorées et non indexées, tandis que du spam a été ajouté.
- Les attaquants exploiteront même la plus petite ouverture de votre système et nous devons être vigilants à tout moment.
- Toujours écouter les gens et comprendre leurs problèmes. Si nous vérifiions uniquement les journaux de nos propres outils, nous ne serions pas au courant de ce problème ou ne pourrions pas aider à réparer leur site.
- Gardez votre logiciel à jour. Toujours.
Chez Jetpack, nous travaillons dur pour nous assurer que vos sites Web sont protégés contre ces types de vulnérabilités. Pour garder une longueur d'avance sur toute nouvelle menace, consultez Jetpack Scan, qui comprend l'analyse de sécurité et la suppression automatisée des logiciels malveillants.
Et un coup de chapeau à Erin Casali pour avoir mis en évidence ce problème et aidé à l'enquête.