
Le fichier robots.txt de WordPress… Qu'est-ce que c'est et ce qu'il fait
Publié: 2020-11-25Vous êtes-vous déjà demandé ce qu'est le fichier robots.txt et ce qu'il fait ? Robots.txt est utilisé pour communiquer avec les robots d'indexation (appelés bots) utilisés par Google et d'autres moteurs de recherche. Il leur indique quelles parties de votre site Web indexer et lesquelles ignorer. En tant que tel, le fichier robots.txt peut aider à faire (ou potentiellement à casser !) vos efforts de référencement. Si vous voulez que votre site Web soit bien classé, une bonne compréhension de robots.txt est essentielle !
Où se trouve Robots.txt ?
WordPress exécute généralement un fichier robots.txt dit "virtuel", ce qui signifie qu'il n'est pas accessible via SFTP. Vous pouvez cependant consulter son contenu de base en vous rendant sur votredomaine.com/robots.txt. Vous verrez probablement quelque chose comme ceci :
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpLa première ligne spécifie à quels bots les règles s'appliqueront. Dans notre exemple, l'astérisque signifie que les règles seront appliquées à tous les robots (par exemple ceux de Google, Bing, etc.).
La deuxième ligne définit une règle qui empêche l'accès des bots au dossier /wp-admin et la troisième ligne indique que les bots sont autorisés à analyser le fichier /wp-admin/admin-ajax.php.
Ajoutez vos propres règles
Pour un site Web WordPress simple, les règles par défaut appliquées par WordPress au fichier robots.txt peuvent être plus que suffisantes. Si toutefois vous souhaitez plus de contrôle et la possibilité d'ajouter vos propres règles afin de donner des instructions plus spécifiques aux robots des moteurs de recherche sur la façon d'indexer votre site Web, vous devrez créer votre propre fichier physique robots.txt et le placer sous la racine. répertoire de votre installation.
Il y a plusieurs raisons qui peuvent vouloir reconfigurer votre fichier robots.txt et définir exactement ce que ces bots seront autorisés à explorer. L'une des principales raisons est liée au temps passé par un bot à explorer votre site. Google (et d'autres) n'autorisent pas les robots à passer un temps illimité sur chaque site Web… avec des milliards de pages, ils doivent adopter une approche plus nuancée de ce que leurs robots vont explorer et de ce qu'ils ignoreront pour tenter d'extraire les informations les plus utiles. sur un site Web.

Hébergez votre site web avec Pressidium
GARANTIE DE REMBOURSEMENT DE 60 JOURS
Lorsque vous autorisez les robots à explorer toutes les pages de votre site Web, une partie du temps d'exploration est consacrée à des pages qui ne sont pas importantes ou même pertinentes. Cela leur laisse moins de temps pour se frayer un chemin à travers les zones les plus pertinentes de votre site. En interdisant l'accès des robots à certaines parties de votre site Web, vous augmentez le temps dont disposent les robots pour extraire des informations des parties les plus pertinentes de votre site (qui, espérons-le, finiront par être indexées). Parce que l'exploration est plus rapide, Google est plus susceptible de revisiter votre site Web et de tenir à jour son index de votre site. Cela signifie que les nouveaux articles de blog et autres contenus frais seront probablement indexés plus rapidement, ce qui est une bonne nouvelle.
Exemples de modification de Robots.txt
Le robots.txt offre beaucoup de place pour la personnalisation. En tant que tel, nous avons fourni une série d'exemples de règles qui peuvent être utilisées pour dicter la façon dont les bots indexent votre site.
Autoriser ou interdire les robots
Voyons d'abord comment nous pouvons restreindre un bot spécifique. Pour ce faire, il nous suffit de remplacer l'astérisque (*) par le nom de l'agent utilisateur du bot que nous souhaitons bloquer, par exemple "MSNBot". Une liste complète des agents utilisateurs connus est disponible ici.
User-agent: MSNBot Disallow: /Mettre un tiret dans la deuxième ligne restreindra l'accès du bot à tous les répertoires.
Pour permettre à un seul bot d'explorer notre site, nous utiliserons un processus en 2 étapes. Nous définirions d'abord ce bot comme une exception, puis nous interdireions tous les bots comme celui-ci :
User-agent: Google Disallow: User-agent: * Disallow: /Pour autoriser l'accès à tous les bots sur tout le contenu, nous ajoutons ces deux lignes :
User-agent: * Disallow:Le même effet serait obtenu en créant simplement un fichier robots.txt et en le laissant simplement vide.
Bloquer l'accès à des fichiers spécifiques
Vous voulez empêcher les bots d'indexer certains fichiers sur votre site Web ? C'est facile! Dans l'exemple ci-dessous, nous avons empêché les moteurs de recherche d'accéder à tous les fichiers .pdf de notre site Web.
User-agent: * Disallow: /*.pdf$Le symbole "$" est utilisé pour définir la fin de l'URL. Comme cela est sensible à la casse, un fichier portant le nom my.PDF sera toujours exploré (notez les MAJUSCULES).
Expressions logiques complexes
Certains moteurs de recherche, comme Google, comprennent l'utilisation d'expressions régulières plus compliquées. Il est important de noter cependant que tous les moteurs de recherche ne sont pas en mesure de comprendre les expressions logiques dans robots.txt.

Un exemple de ceci utilise le symbole $. Dans les fichiers robots.txt, ce symbole indique la fin d'une URL. Ainsi, dans l'exemple suivant, nous avons empêché les robots de recherche de lire et d'indexer les fichiers se terminant par .php
Disallow: /*.php$Cela signifie que /index.php ne peut pas être indexé, mais que /index.php?p=1 pourrait l'être. Ceci n'est utile que dans des circonstances très spécifiques et doit être utilisé avec prudence ou vous courez le risque de bloquer l'accès du bot à des fichiers que vous n'aviez pas l'intention de faire !
Vous pouvez également définir des règles différentes pour chaque bot en spécifiant les règles qui s'appliquent à eux individuellement. L'exemple de code ci-dessous limitera l'accès au dossier wp-admin pour tous les bots tout en bloquant l'accès à l'ensemble du site pour le moteur de recherche Bing. Vous ne voudriez pas nécessairement faire cela, mais c'est une démonstration utile de la flexibilité des règles dans un fichier robots.txt.
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /Plans de site XML
Les sitemaps XML aident vraiment les robots de recherche à comprendre la disposition de votre site Web. Mais pour être utile, le bot doit savoir où se trouve le sitemap. La « directive sitemap » est utilisée pour indiquer spécifiquement aux moteurs de recherche qu'a) un sitemap de votre site existe et b) où ils peuvent le trouver.
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:Vous pouvez également spécifier plusieurs emplacements de sitemap :
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* DisallowRetards d'exploration de robots
Une autre fonction qui peut être obtenue via le fichier robots.txt est de dire aux bots de "ralentir" leur exploration de votre site. Cela peut être nécessaire si vous constatez que votre serveur est surchargé par des niveaux élevés de trafic de robots. Pour ce faire, vous devez spécifier l'agent utilisateur que vous souhaitez ralentir, puis ajouter un délai.
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10Le nombre entre guillemets (10) dans cet exemple correspond au délai que vous souhaitez observer entre l'exploration de pages individuelles de votre site. Ainsi, dans l'exemple ci-dessus, nous avons demandé au Bing Bot de faire une pause de dix secondes entre chaque page qu'il explore et, ce faisant, de donner à notre serveur un peu de répit.
La seule petite mauvaise nouvelle à propos de cette règle robots.txt particulière est que le bot de Google ne la respecte pas. Vous pouvez cependant demander à leurs bots de ralentir depuis la Google Search Console.
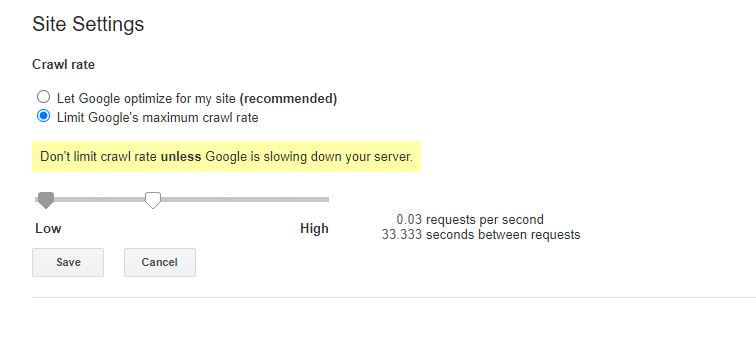
Remarques sur les règles robots.txt :
- Toutes les règles robots.txt sont sensibles à la casse. Tapez soigneusement!
- Assurez-vous qu'aucun espace n'existe avant la commande au début de la ligne.
- Les modifications apportées dans robots.txt peuvent prendre 24 à 36 heures pour être notées par les bots.
Comment tester et soumettre votre fichier WordPress robots.txt
Lorsque vous avez créé un nouveau fichier robots.txt, il vaut la peine de vérifier qu'il ne contient pas d'erreurs. Vous pouvez le faire en utilisant la console de recherche Google.
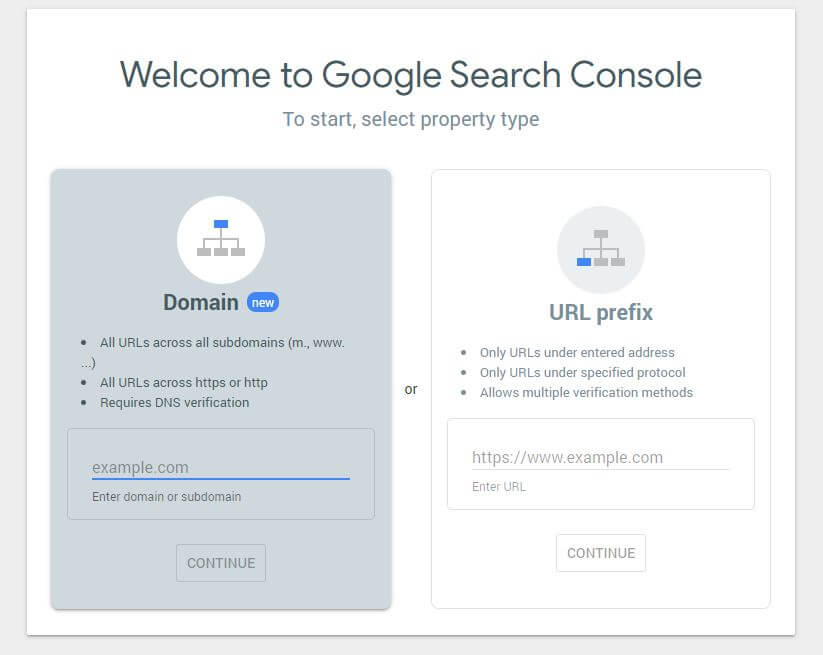
Tout d'abord, vous devrez soumettre votre domaine (si vous n'avez pas encore de compte Search Console pour la configuration de votre site Web). Google vous fournira un enregistrement TXT qui doit être ajouté à votre DNS afin de vérifier votre domaine.
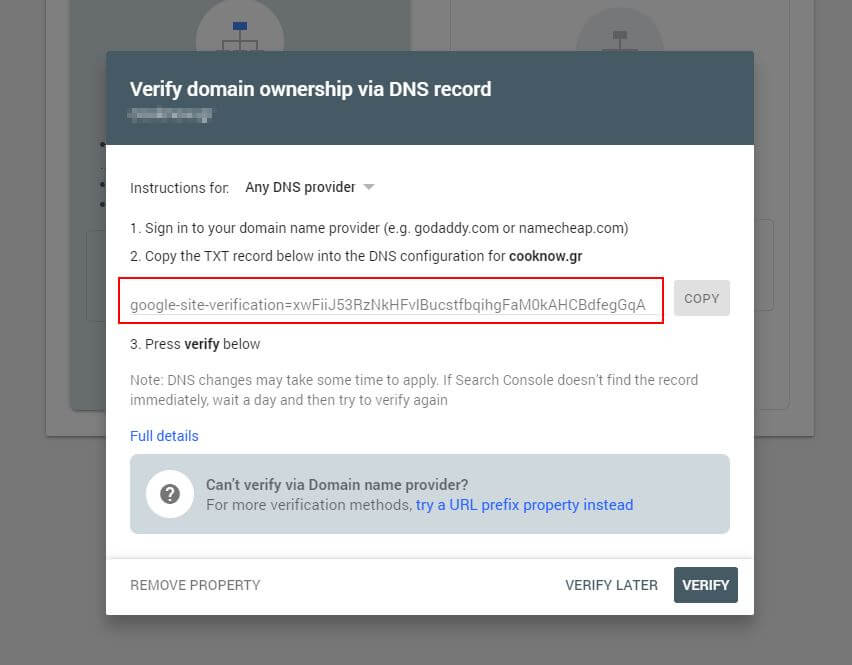
Une fois que cette mise à jour DNS s'est propagée (vous vous sentez impatient... essayez d'utiliser Cloudflare pour gérer votre DNS), vous pouvez visiter le testeur robots.txt et vérifier s'il y a des avertissements concernant le contenu de votre fichier robots.txt.
Une autre chose que vous pouvez faire pour tester les règles que vous avez en place ont l'effet souhaité est d'utiliser un outil de test robots.txt comme Ryte.
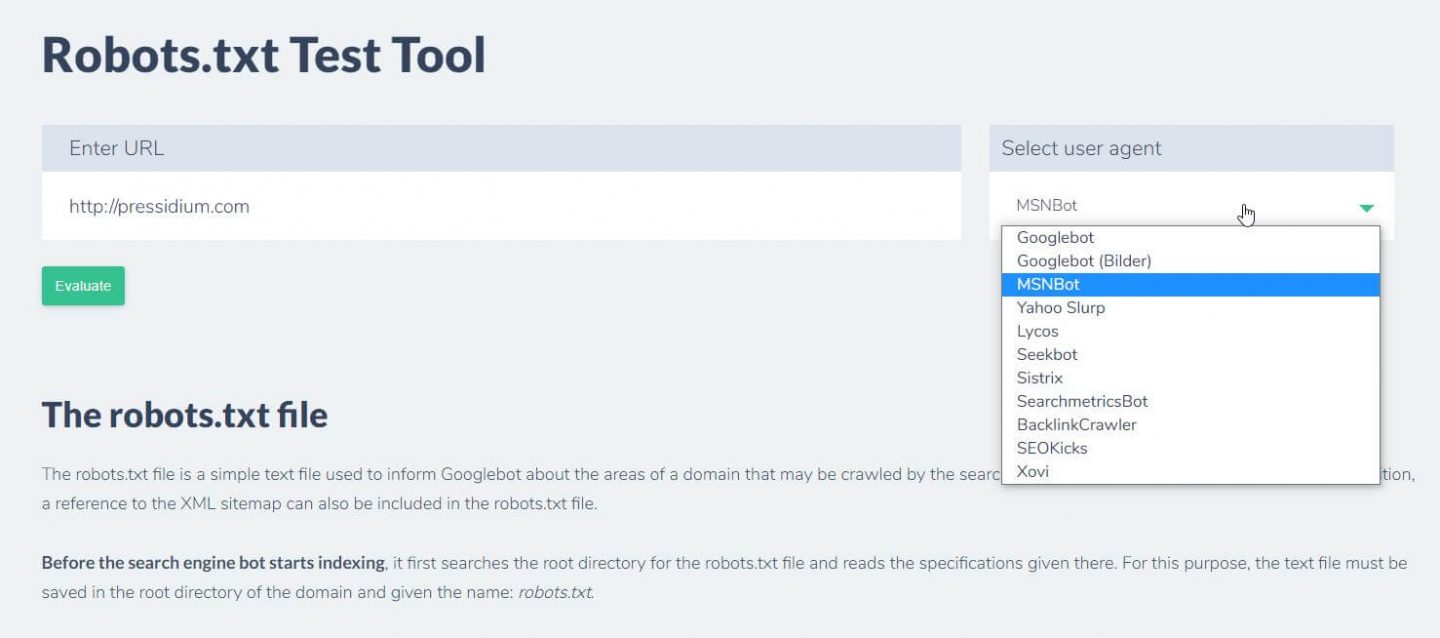
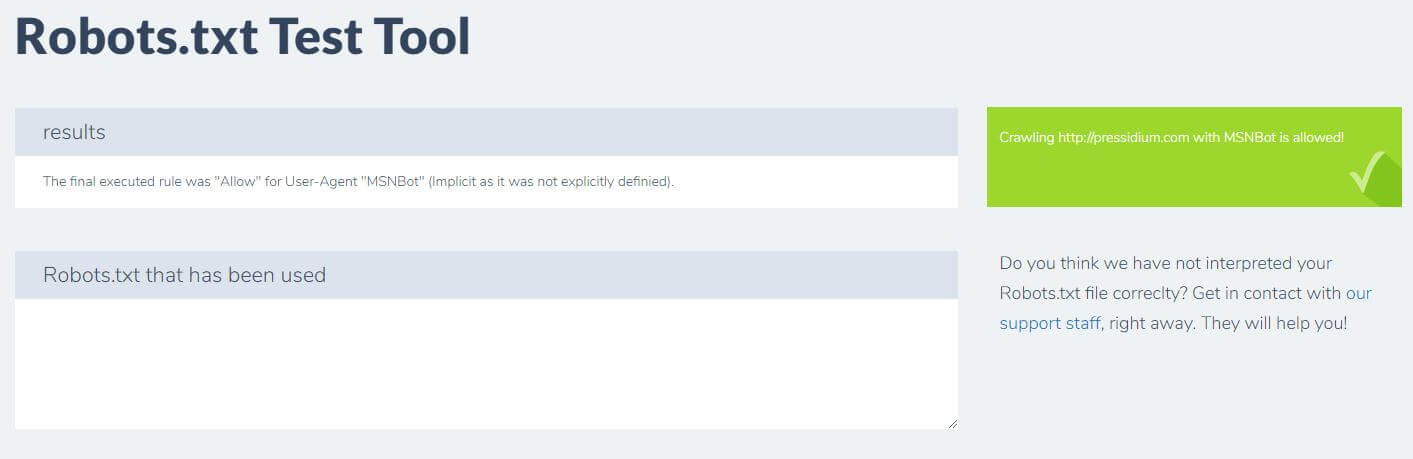
Vous entrez simplement votre domaine et choisissez un agent utilisateur dans le panneau de droite. Après avoir soumis ceci, vous verrez vos résultats.
Conclusion
Savoir utiliser robots.txt est un autre outil utile dans la boîte à outils de votre développeur. Si la seule chose que vous retenez de ce tutoriel est la possibilité de vérifier que votre fichier robots.txt ne bloque pas les bots comme Google (ce que vous ne voudriez probablement pas faire), alors ce n'est pas une mauvaise chose ! De même, comme vous pouvez le constater, robots.txt offre toute une série de contrôles plus précis sur votre site Web, ce qui pourrait un jour s'avérer utile.