
Robots.txt: Apa Itu Dan Cara Membuatnya (Panduan Lengkap)
Diterbitkan: 2023-05-05Jika Anda memiliki situs web atau mengelola kontennya, Anda mungkin pernah mendengar tentang robots.txt. Ini adalah file yang menginstruksikan robot mesin telusur tentang cara merayapi dan mengindeks laman situs web Anda. Meskipun penting dalam pengoptimalan mesin telusur (SEO), banyak pemilik situs web mengabaikan pentingnya file robots.txt yang dirancang dengan baik.
Dalam panduan lengkap ini, kita akan mempelajari apa itu robots.txt, mengapa itu penting untuk SEO, dan cara membuat file robots.txt untuk situs web Anda.
Apa itu File Robots.txt?
Robots.txt adalah file yang memberi tahu robot mesin telusur (juga dikenal sebagai perayap atau spider) halaman atau bagian situs web mana yang harus dirayapi atau tidak. Ini adalah file teks biasa yang terletak di direktori root situs web, dan biasanya berisi daftar direktori, file, atau URL yang ingin diblokir oleh webmaster dari pengindeksan atau perayapan mesin telusur.
Seperti inilah tampilan file robots.txt:

Mengapa Robots.txt Penting?
Ada tiga alasan utama mengapa robots.txt penting untuk situs web Anda:
1. Maksimalkan Anggaran Perayapan
“Anggaran perayapan” berarti jumlah halaman yang akan dirayapi Google di situs Anda pada waktu tertentu. Jumlahnya tergantung pada ukuran, kesehatan, dan jumlah backlink di situs Anda.
Anggaran perayapan penting karena jika jumlah halaman di situs Anda melebihi anggaran perayapan, Anda akan memiliki halaman yang tidak diindeks.
Selain itu, halaman yang tidak diindeks tidak akan diberi peringkat untuk apa pun.
Dengan menggunakan robots.txt untuk memblokir halaman yang tidak berguna, Googlebot (perayap web Google) mungkin membelanjakan lebih banyak anggaran perayapan Anda pada halaman yang penting.
2. Blokir Halaman Non-Publik
Anda memiliki banyak halaman di situs Anda yang tidak ingin Anda indeks.
Misalnya, Anda mungkin memiliki halaman hasil pencarian internal atau halaman login. Halaman-halaman ini harus ada. Namun, Anda tidak ingin orang sembarangan mendarat di atasnya.
Dalam hal ini, Anda akan menggunakan robots.txt untuk mencegah perayap mesin telusur dan bot mengakses laman tertentu.
3. Mencegah Pengindeksan Sumber Daya
Terkadang Anda ingin Google mengecualikan sumber daya seperti PDF, video, dan gambar dari hasil pencarian.
Mungkin Anda ingin merahasiakan sumber daya tersebut, atau Anda ingin Google lebih fokus pada konten penting.
Dalam kasus seperti itu, menggunakan robots.txt adalah pendekatan terbaik untuk mencegahnya diindeks.
Bagaimana Cara Kerja File Robots.txt?
File Robots.txt menginstruksikan bot mesin pencari halaman atau direktori situs web mana yang harus atau tidak boleh dirayapi atau diindeks.
Saat merayapi, bot mesin pencari menemukan dan mengikuti tautan. Proses ini mengarahkan mereka dari situs X ke situs Y ke situs Z melalui miliaran tautan dan situs web.
Saat bot mengunjungi sebuah situs, hal pertama yang dilakukannya adalah mencari file robots.txt.
Jika mendeteksi satu, itu akan membaca file sebelum melakukan hal lain.
Misalnya, Anda ingin mengizinkan semua bot kecuali DuckDuckGo merayapi situs Anda:
User-agent: DuckDuckBot Disallow: /
Catatan: File robots.txt hanya dapat memberikan instruksi; itu tidak bisa memaksakan mereka. Ini mirip dengan kode etik. Bot yang baik (seperti bot mesin pencari) akan mengikuti aturan, sedangkan bot yang buruk (seperti bot spam) akan mengabaikannya.
Bagaimana Cara Menemukan File Robots.txt?
File robots.txt, seperti file lainnya di situs web Anda, dihosting di server Anda.
Anda dapat mengakses file robots.txt dari situs web mana pun dengan memasukkan URL lengkap beranda, lalu menambahkan /robots.txt di bagian akhir, seperti https://pickupwp.com/robots.txt.
Namun, jika situs web tidak memiliki file robots.txt, Anda akan menerima pesan kesalahan “404 Not Found”.
Bagaimana Cara Membuat File Robots.txt?
Sebelum menunjukkan cara membuat file robots.txt, mari kita lihat dulu sintaks robots.txt.
Sintaks file robots.txt dapat dipecah menjadi komponen berikut:
- Agen-pengguna: Ini menentukan robot atau perayap tempat rekaman diterapkan. Misalnya, “User-agent: Googlebot” hanya akan berlaku untuk perayap penelusuran Google, sedangkan “User-agent: *” akan berlaku untuk semua perayap.
- Larang: Ini menentukan halaman atau direktori yang tidak boleh dirayapi robot. Misalnya, “Larang: /private/” akan mencegah robot merayapi halaman mana pun di dalam direktori “pribadi”.
- Izinkan: Ini menentukan halaman atau direktori yang boleh dirayapi oleh robot, bahkan jika direktori induk tidak diizinkan. Misalnya, "Izinkan: /publik/" akan mengizinkan robot untuk merayapi laman apa pun di dalam direktori "publik", bahkan jika direktori induk tidak diizinkan.
- Penundaan perayapan: Ini menentukan jumlah waktu dalam detik yang harus ditunggu robot sebelum merayapi situs web. Misalnya, “Crawl-delay: 10” akan menginstruksikan robot untuk menunggu selama 10 detik sebelum merayapi situs web.
- Peta Situs: Ini menentukan lokasi peta situs situs web. Misalnya, “Sitemap: https://www.example.com/sitemap.xml” akan memberi tahu robot tentang lokasi peta situs situs web.
Berikut adalah contoh file robots.txt:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
Catatan: Perlu diperhatikan bahwa file robots.txt peka huruf besar/kecil, jadi penting untuk menggunakan huruf besar/kecil yang benar saat menentukan URL.
Misalnya, /publik/ tidak sama dengan /Publik/.
Di sisi lain, Arahan seperti "Izinkan" dan "Larang" tidak peka huruf besar-kecil, jadi terserah Anda untuk menggunakan huruf besar atau tidak.
Setelah mempelajari sintaks robots.txt, Anda dapat membuat file robots.txt menggunakan alat pembuat robots.txt atau membuatnya sendiri.
Berikut cara membuat file robots.txt hanya dalam empat langkah:
1. Buat File Baru dan Beri Nama Robots.txt
Cukup buka dokumen .txt dengan editor teks atau browser web apa pun.
Selanjutnya, beri nama dokumen robots.txt. Agar berfungsi, itu harus diberi nama robots.txt.
Setelah selesai, Anda sekarang dapat mulai mengetik arahan.
2. Tambahkan Arahan ke File Robots.txt
File robots.txt berisi satu atau beberapa grup direktif, masing-masing dengan beberapa baris instruksi.
Setiap grup dimulai dengan "User-agent" dan berisi data berikut:
- Kepada siapa grup berlaku (agen pengguna)
- Direktori (halaman) atau file mana yang dapat diakses oleh agen?
- Direktori (halaman) atau file mana yang tidak dapat diakses oleh agen?
- Peta situs (opsional) untuk memberi tahu mesin telusur tentang situs dan file yang menurut Anda penting.
Baris yang tidak cocok dengan arahan mana pun akan diabaikan oleh perayap.

Misalnya, Anda ingin mencegah Google meng-crawl direktori /private/ Anda.
Ini akan terlihat seperti ini:
User-agent: Googlebot Disallow: /private/
Jika Anda memiliki instruksi lebih lanjut seperti ini untuk Google, Anda akan meletakkannya di baris terpisah tepat di bawah seperti ini:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
Selanjutnya, jika Anda sudah selesai dengan instruksi khusus Google dan ingin membuat grup direktif baru.
Misalnya, jika Anda ingin mencegah semua mesin telusur merayapi direktori /archive/ dan /support/ Anda.
Ini akan terlihat seperti ini:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
Setelah selesai, Anda dapat menambahkan peta situs Anda.
File robots.txt Anda yang telah selesai akan terlihat seperti ini:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
Selanjutnya, simpan file robots.txt Anda. Ingat, itu harus diberi nama robots.txt.
Untuk aturan robots.txt yang lebih bermanfaat, lihat panduan bermanfaat ini dari Google.
3. Unggah File Robots.txt
Setelah menyimpan file robots.txt ke komputer Anda, unggah ke situs web Anda dan sediakan untuk dirayapi oleh mesin telusur.
Sayangnya, tidak ada alat yang dapat membantu langkah ini.
Pengunggahan file robots.txt bergantung pada struktur file dan hosting web situs Anda.
Untuk petunjuk tentang cara mengunggah file robots.txt, cari secara online atau hubungi penyedia hosting Anda.
4. Uji Robots.txt Anda
Setelah Anda mengunggah file robots.txt, selanjutnya Anda dapat memeriksa apakah ada yang dapat melihatnya dan apakah Google dapat membacanya.
Cukup buka tab baru di browser Anda dan cari file robots.txt Anda.
Misalnya, https://pickupwp.com/robots.txt.
Jika Anda melihat file robots.txt, Anda siap menguji markup (kode HTML).
Untuk ini, Anda dapat menggunakan Penguji robots.txt Google.
Catatan: Anda memiliki akun Search Console yang disiapkan untuk menguji file robots.txt menggunakan Penguji robots.txt.
Penguji robots.txt akan menemukan peringatan sintaksis atau kesalahan logika dan menyorotnya.
Plus, itu juga menunjukkan peringatan dan kesalahan di bawah editor.
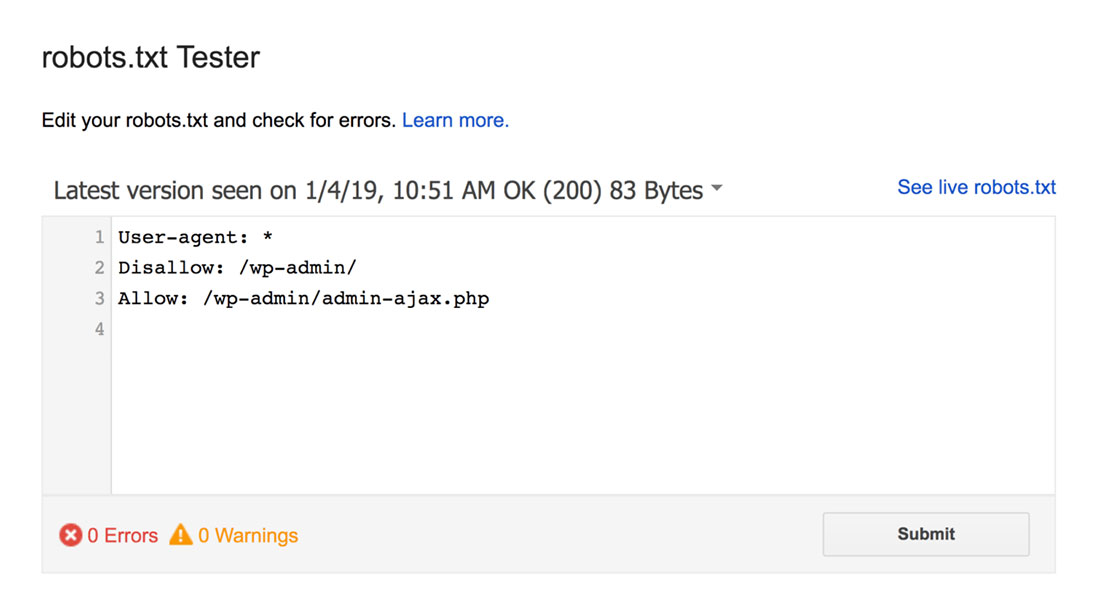
Anda dapat mengedit kesalahan atau peringatan pada halaman dan menguji ulang sesering yang diperlukan.
Perlu diingat bahwa perubahan yang dilakukan pada halaman tidak disimpan ke situs Anda.
Untuk melakukan perubahan, salin dan tempel ini ke file robots.txt di situs Anda.
Praktik Terbaik Robots.txt
Ingatlah praktik terbaik ini saat membuat file robots.txt untuk menghindari beberapa kesalahan umum.
1. Gunakan Baris Baru untuk Setiap Direktif
Untuk mencegah kebingungan bagi perayap mesin telusur, tambahkan setiap arahan ke baris baru di file robots.txt Anda. Ini berlaku untuk aturan Allow dan Disallow.
Misalnya, jika Anda tidak ingin perayap web merayapi blog atau halaman kontak Anda, tambahkan aturan berikut:
Disallow: /blog/ Disallow: /contact/
2. Gunakan Setiap Agen Pengguna Hanya Sekali
Bot tidak bermasalah jika Anda menggunakan agen pengguna yang sama berulang kali.
Namun, menggunakannya sekali saja membuat segalanya teratur dan mengurangi kemungkinan kesalahan manusia.
3. Gunakan Wildcard Untuk Menyederhanakan Instruksi
Jika Anda memiliki banyak halaman untuk diblokir, menambahkan aturan untuk masing-masing halaman mungkin akan memakan waktu. Untungnya, Anda dapat menggunakan wildcard untuk menyederhanakan instruksi Anda.
Wildcard adalah karakter yang dapat mewakili satu atau lebih karakter. Wildcard yang paling umum digunakan adalah tanda bintang (*).
Misalnya, jika Anda ingin memblokir semua file yang diakhiri dengan .jpg, Anda akan menambahkan aturan berikut:
Disallow: /*.jpg
4. Gunakan "$" Untuk Menentukan Akhir URL
Tanda dolar ($) adalah wildcard lain yang dapat digunakan untuk mengidentifikasi akhir URL. Ini berguna jika Anda ingin membatasi halaman tertentu tetapi bukan halaman setelahnya.
Misalkan Anda ingin memblokir halaman kontak tetapi bukan halaman kontak-sukses, Anda akan menambahkan aturan berikut:
Disallow: /contact$
5. Gunakan Hash (#) Untuk Menambahkan Komentar
Segala sesuatu yang dimulai dengan hash (#) akan diabaikan oleh perayap.
Akibatnya, pengembang sering menggunakan hash untuk menambahkan komentar ke file robots.txt. Itu membuat dokumen tetap teratur dan mudah dibaca.
Misalnya, jika Anda ingin mencegah semua file diakhiri dengan .jpg, Anda dapat menambahkan komentar berikut:
# Block all files that end in .jpg Disallow: /*.jpg
Ini membantu siapa pun memahami untuk apa aturan itu dan mengapa aturan itu ada.
6. Gunakan File Robots.txt Terpisah untuk Setiap Subdomain
Jika Anda memiliki situs web yang memiliki beberapa subdomain, disarankan untuk membuat file robots.txt individual untuk masing-masing subdomain. Ini membuat semuanya teratur dan membantu perayap mesin telusur memahami aturan Anda dengan lebih mudah.
Membungkus!
File robots.txt adalah alat SEO yang berguna karena menginstruksikan bot mesin pencari tentang apa yang harus diindeks dan apa yang tidak.
Namun, penting untuk menggunakannya dengan hati-hati. Karena kesalahan konfigurasi dapat mengakibatkan deindeksasi lengkap situs web Anda (misalnya, menggunakan Disallow: /).
Secara umum, cara yang baik adalah membiarkan mesin telusur memindai situs Anda sebanyak mungkin sembari menyimpan informasi sensitif dan menghindari konten duplikat. Misalnya, Anda dapat menggunakan direktif Disallow untuk mencegah halaman atau direktori tertentu atau direktif Allow untuk mengesampingkan aturan Disallow untuk halaman tertentu.
Perlu juga disebutkan bahwa tidak semua bot mengikuti aturan yang disediakan di file robots.txt, jadi ini bukan metode yang sempurna untuk mengontrol apa yang diindeks. Tapi itu masih merupakan alat yang berharga untuk dimiliki dalam strategi SEO Anda.
Kami harap panduan ini membantu Anda mempelajari apa itu file robots.txt dan cara membuatnya.
Untuk lebih lanjut, Anda dapat melihat sumber daya bermanfaat lainnya ini:
- 15 Tips Blogging yang Dapat Ditindaklanjuti untuk Blogger Baru
- Membuka Kekuatan Kata Kunci Ekor Panjang (Panduan Pemula)
Terakhir, ikuti kami di Twitter untuk pembaruan rutin tentang artikel baru.