
Come creare un database MongoDB: 6 aspetti critici da conoscere
Pubblicato: 2022-11-07In base ai requisiti del tuo software, potresti dare la priorità a flessibilità, scalabilità, prestazioni o velocità. Pertanto, gli sviluppatori e le aziende sono spesso confusi quando scelgono un database per le loro esigenze. Se hai bisogno di un database che offra elevata flessibilità e scalabilità e aggregazione dei dati per l'analisi dei clienti, MongoDB potrebbe essere la soluzione giusta per te!
In questo articolo, discuteremo della struttura del database MongoDB e di come creare, monitorare e gestire il tuo database! Iniziamo.
Come è strutturato un database MongoDB?
MongoDB è un database NoSQL senza schema. Ciò significa che non si specifica una struttura per le tabelle/database come si fa per i database SQL.
Sapevi che i database NoSQL sono in realtà più veloci dei database relazionali? Ciò è dovuto a caratteristiche come pipeline di indicizzazione, partizionamento orizzontale e aggregazione. MongoDB è anche noto per la sua rapida esecuzione delle query. Questo è il motivo per cui è preferito da aziende come Google, Toyota e Forbes.
Di seguito, esploreremo alcune caratteristiche chiave di MongoDB.
Documenti
MongoDB ha un modello di dati del documento che memorizza i dati come documenti JSON. I documenti si associano naturalmente agli oggetti nel codice dell'applicazione, rendendo più semplice l'utilizzo da parte degli sviluppatori.
In una tabella di database relazionale, è necessario aggiungere una colonna per aggiungere un nuovo campo. Questo non è il caso dei campi in un documento JSON. I campi in un documento JSON possono differire da documento a documento, quindi non verranno aggiunti a tutti i record nel database.
I documenti possono memorizzare strutture come array che possono essere nidificati per esprimere relazioni gerarchiche. Inoltre, MongoDB converte i documenti in un tipo binario JSON (BSON). Ciò garantisce un accesso più rapido e un maggiore supporto per vari tipi di dati come stringa, numero intero, numero booleano e molto altro!
Set di repliche
Quando crei un nuovo database in MongoDB, il sistema crea automaticamente almeno altre 2 copie dei tuoi dati. Queste copie sono note come "set di repliche" e replicano continuamente i dati tra di loro, garantendo una migliore disponibilità dei dati. Offrono inoltre protezione contro i tempi di inattività durante un guasto del sistema o una manutenzione programmata.
Collezioni
Una raccolta è un gruppo di documenti associati a un database. Sono simili alle tabelle nei database relazionali.
Le raccolte, tuttavia, sono molto più flessibili. Per uno, non si basano su uno schema. In secondo luogo, i documenti non devono necessariamente essere dello stesso tipo di dati!
Per visualizzare un elenco delle raccolte che appartengono a un database, utilizzare il comando listCollections .
Condutture di aggregazione
È possibile utilizzare questo framework per raggruppare diversi operatori ed espressioni. È flessibile perché consente di elaborare, trasformare e analizzare i dati di qualsiasi struttura.
Per questo motivo, MongoDB consente flussi di dati veloci e funzionalità su 150 operatori ed espressioni. Ha anche diverse fasi, come la fase dell'Unione, che mette insieme in modo flessibile i risultati di più raccolte.
Indici
Puoi indicizzare qualsiasi campo in un documento MongoDB per aumentarne l'efficienza e migliorare la velocità delle query. L'indicizzazione consente di risparmiare tempo scansionando l'indice per limitare i documenti ispezionati. Non è molto meglio che leggere tutti i documenti della collezione?
Puoi utilizzare varie strategie di indicizzazione, inclusi indici composti su più campi. Ad esempio, supponiamo di avere diversi documenti contenenti il nome e il cognome del dipendente in campi separati. Se desideri che il nome e il cognome vengano restituiti, puoi creare un indice che includa sia "Cognome" che "Nome". Sarebbe molto meglio che avere un indice su "Cognome" e un altro su "Nome".
Puoi sfruttare strumenti come Performance Advisor per comprendere ulteriormente quale query potrebbe trarre vantaggio dagli indici.
Frammentazione
Il partizionamento orizzontale distribuisce un singolo set di dati su più database. Tale set di dati può quindi essere archiviato su più macchine per aumentare la capacità di archiviazione totale di un sistema. Questo perché suddivide i set di dati più grandi in blocchi più piccoli e li archivia in vari nodi di dati.
MongoDB shards i dati a livello di raccolta, distribuendo i documenti in una raccolta tra gli shard in un cluster. Ciò garantisce la scalabilità consentendo all'architettura di gestire le applicazioni più grandi.
Come creare un database MongoDB
Dovrai prima installare il pacchetto MongoDB adatto al tuo sistema operativo. Vai alla pagina "Scarica MongoDB Community Server". Dalle opzioni disponibili, seleziona l'ultima "versione", il formato "pacchetto" come file zip e "piattaforma" come sistema operativo e fai clic su "Download" come illustrato di seguito:
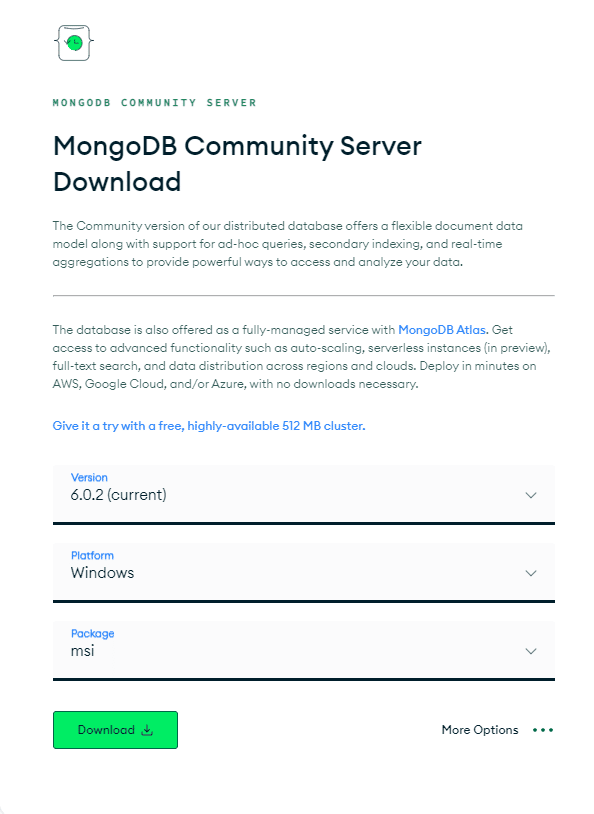
Il processo è abbastanza semplice, quindi avrai MongoDB installato nel tuo sistema in pochissimo tempo!
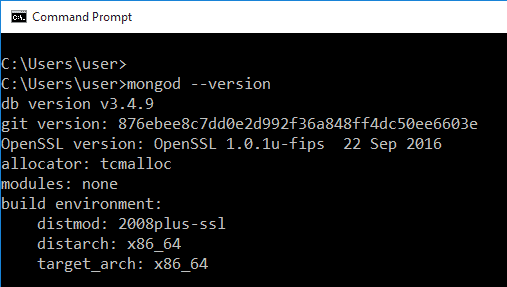
Una volta completata l'installazione, apri il prompt dei comandi e digita mongod -version per verificarlo. Se non si ottiene il seguente output e invece viene visualizzata una stringa di errori, potrebbe essere necessario reinstallarlo:
Utilizzando MongoDB Shell
Prima di iniziare, assicurati che:
- Il tuo client ha Transport Layer Security ed è nella tua lista IP consentita.
- Hai un account utente e una password sul cluster MongoDB desiderato.
- Hai installato MongoDB sul tuo dispositivo.
Passaggio 1: accedi alla shell MongoDB
Per ottenere l'accesso alla shell MongoDB, digita il seguente comando:
net start MongoDBQuesto dovrebbe dare il seguente output:
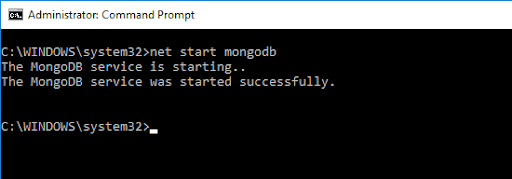
Il comando precedente ha inizializzato il server MongoDB. Per eseguirlo, dovremmo digitare mongo nel prompt dei comandi.
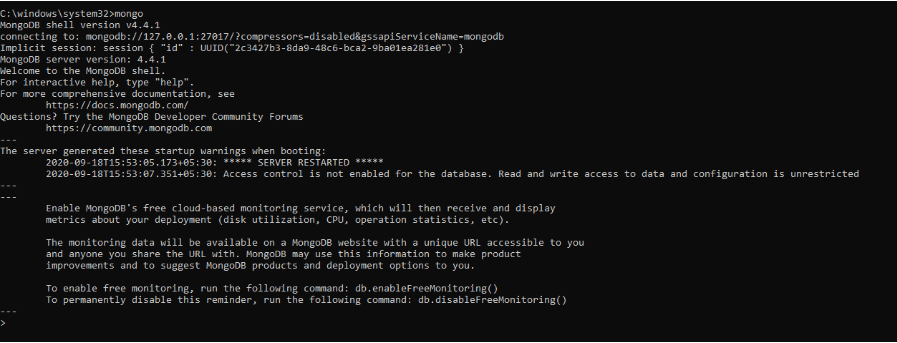
Qui nella shell MongoDB, possiamo eseguire comandi per creare database, inserire dati, modificare dati, emettere comandi amministrativi ed eliminare dati.
Passaggio 2: crea il tuo database
A differenza di SQL, MongoDB non ha un comando di creazione del database. Invece, esiste una parola chiave chiamata use che passa a un database specificato. Se il database non esiste, creerà un nuovo database, altrimenti si collegherà al database esistente.
Ad esempio, per avviare un database chiamato "azienda", digitare:
use Company 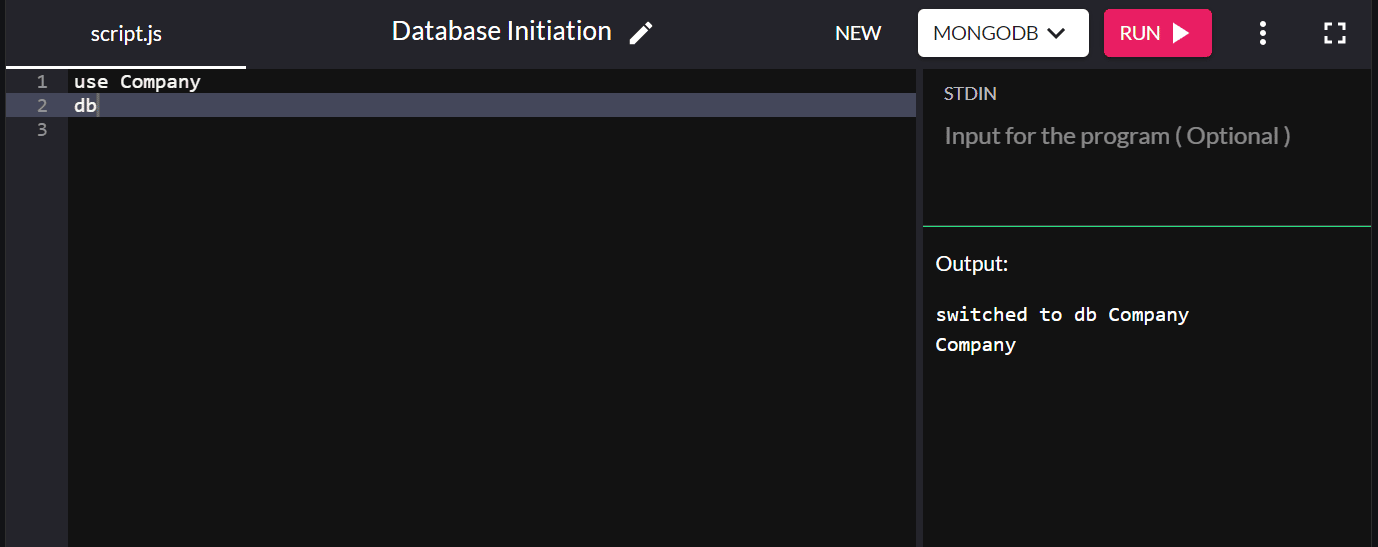
Puoi digitare db per confermare il database che hai appena creato nel tuo sistema. Se viene visualizzato il nuovo database che hai creato, ti sei connesso correttamente ad esso.
Se vuoi controllare i database esistenti, digita show dbs e restituirà tutti i database nel tuo sistema:
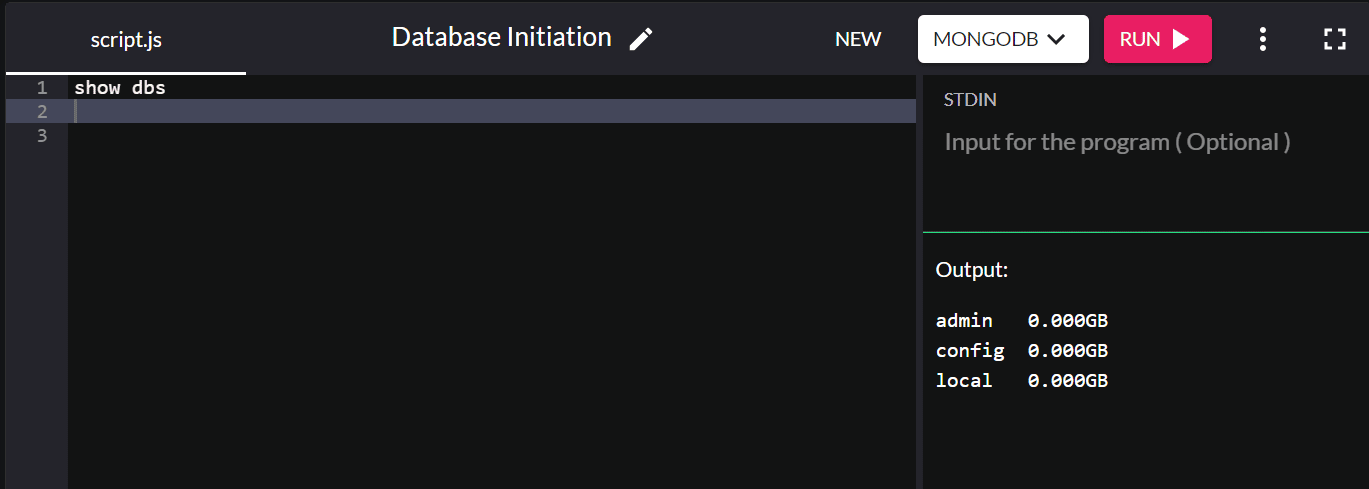
Per impostazione predefinita, l'installazione di MongoDB crea i database admin, config e locali.
Hai notato che il database che abbiamo creato non viene visualizzato? Questo perché non abbiamo ancora salvato i valori nel database! Discuteremo l'inserimento nella sezione di gestione del database.
Utilizzo dell'interfaccia utente di Atlas
Potresti anche iniziare con il servizio di database di MongoDB, Atlas. Anche se potrebbe essere necessario pagare per accedere ad alcune funzionalità di Atlas, la maggior parte delle funzionalità del database sono disponibili con il piano gratuito. Le funzionalità del livello gratuito sono più che sufficienti per creare un database MongoDB.
Prima di iniziare, assicurati che:
- Il tuo IP è nella lista consentita.
- Hai un account utente e una password sul cluster MongoDB che desideri utilizzare.
Per creare un database MongoDB con AtlasUI, apri una finestra del browser e accedi a https://cloud.mongodb.com. Dalla pagina del cluster, fai clic su Sfoglia raccolte . Se non ci sono database nel cluster, puoi creare il tuo database facendo clic sul pulsante Aggiungi i miei dati .
Il prompt ti chiederà di fornire un database e un nome di raccolta. Dopo averli nominati, fai clic su Crea e il gioco è fatto! Ora puoi inserire nuovi documenti o collegarti al database utilizzando i driver.
Gestire il tuo database MongoDB
In questa sezione, esamineremo alcuni modi ingegnosi per gestire in modo efficace il tuo database MongoDB. Puoi farlo utilizzando la bussola MongoDB o tramite le raccolte.
Utilizzo delle raccolte
Sebbene i database relazionali possiedano tabelle ben definite con tipi di dati e colonne specificati, NoSQL ha raccolte anziché tabelle. Queste raccolte non hanno alcuna struttura e i documenti possono variare: puoi avere tipi di dati e campi diversi senza dover corrispondere al formato di un altro documento nella stessa raccolta.
Per dimostrare, creiamo una raccolta chiamata "Employee" e aggiungiamo un documento ad essa:
db.Employee.insert( { "Employeename" : "Chris", "EmployeeDepartment" : "Sales" } ) Se l'inserimento ha esito positivo, restituirà WriteResult({ "nInserted" : 1 }) :
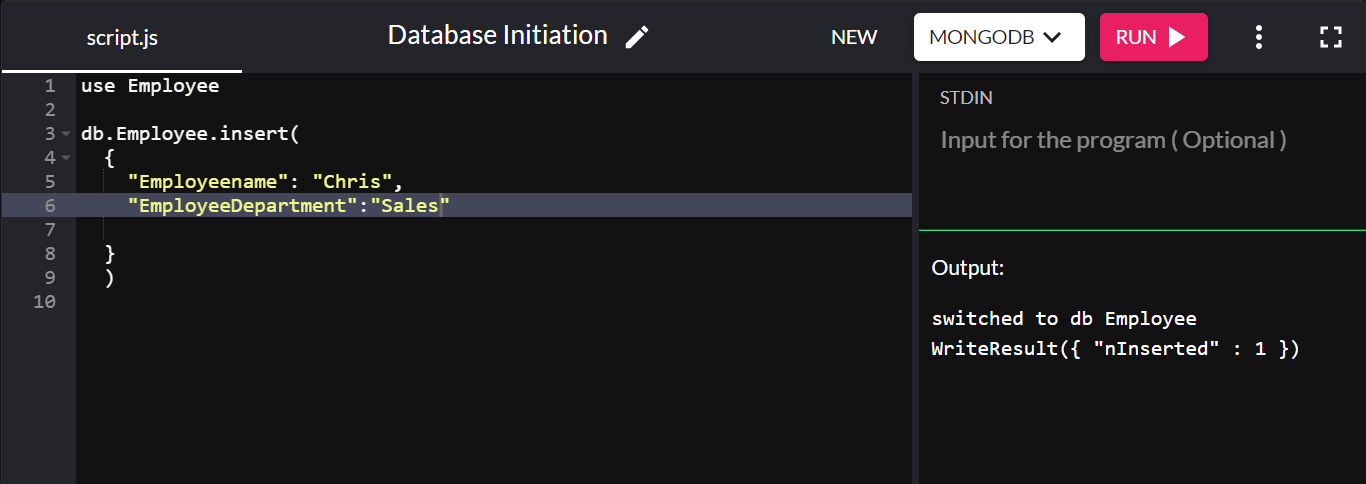
Qui, "db" si riferisce al database attualmente connesso. “Employee” è la nuova collezione creata nel database aziendale.
Non abbiamo impostato una chiave primaria qui perché MongoDB crea automaticamente un campo di chiave primaria chiamato "_id" e imposta un valore predefinito su di esso.
Esegui il comando seguente per controllare la raccolta in formato JSON:
db.Employee.find().forEach(printjson)Produzione:
{ "_id" : ObjectId("63151427a4dd187757d135b8"), "Employeename" : "Chris", "EmployeeDepartment" : "Sales" }Mentre il valore "_id" viene assegnato automaticamente, è possibile modificare il valore della chiave primaria predefinita. Questa volta, inseriremo un altro documento nel database "Employee", con il valore "_id" come "1":
db.Employee.insert( { "_id" : 1, "EmployeeName" : "Ava", "EmployeeDepartment" : "Public Relations" } ) Eseguendo il comando db.Employee.find().forEach(printjson) otteniamo il seguente output:
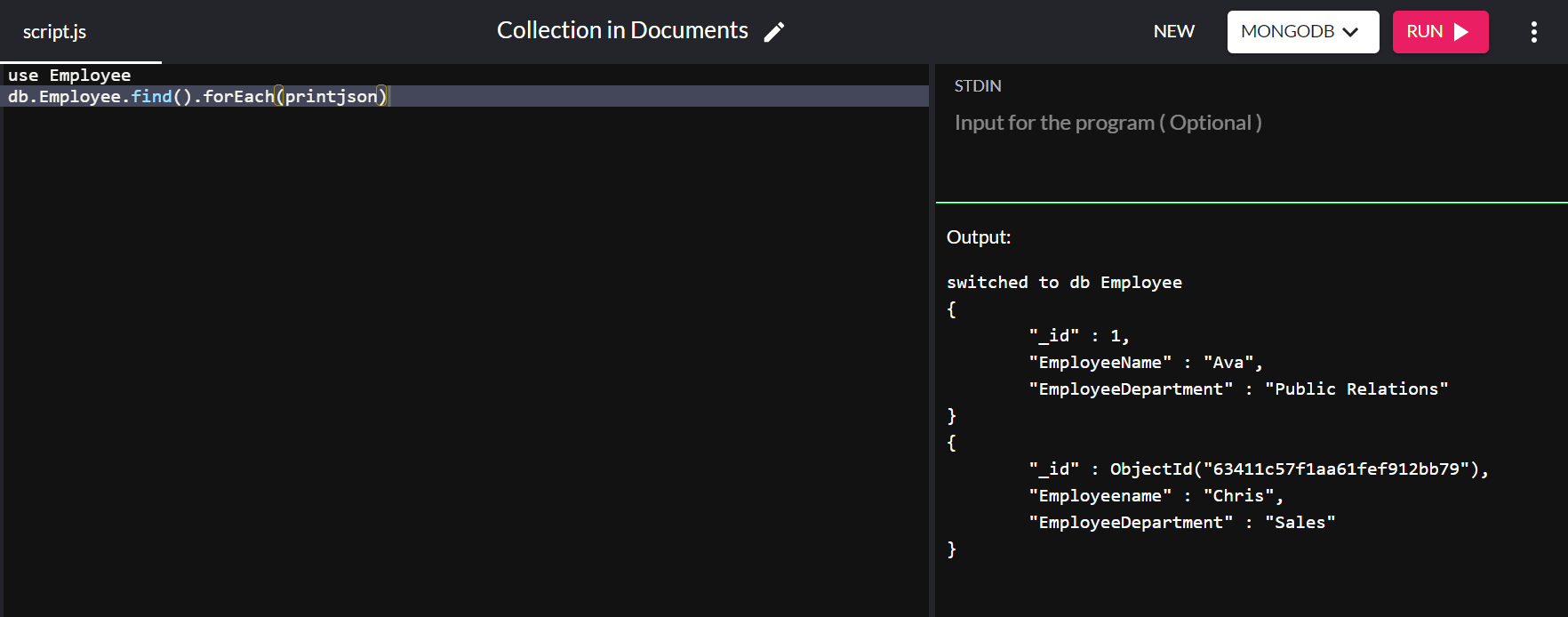
Nell'output sopra, il valore "_id" per "Ava" è impostato su "1" invece di essere assegnato automaticamente a un valore.
Ora che abbiamo aggiunto correttamente i valori al database, possiamo verificare se viene visualizzato nei database esistenti nel nostro sistema utilizzando il seguente comando:
show dbs 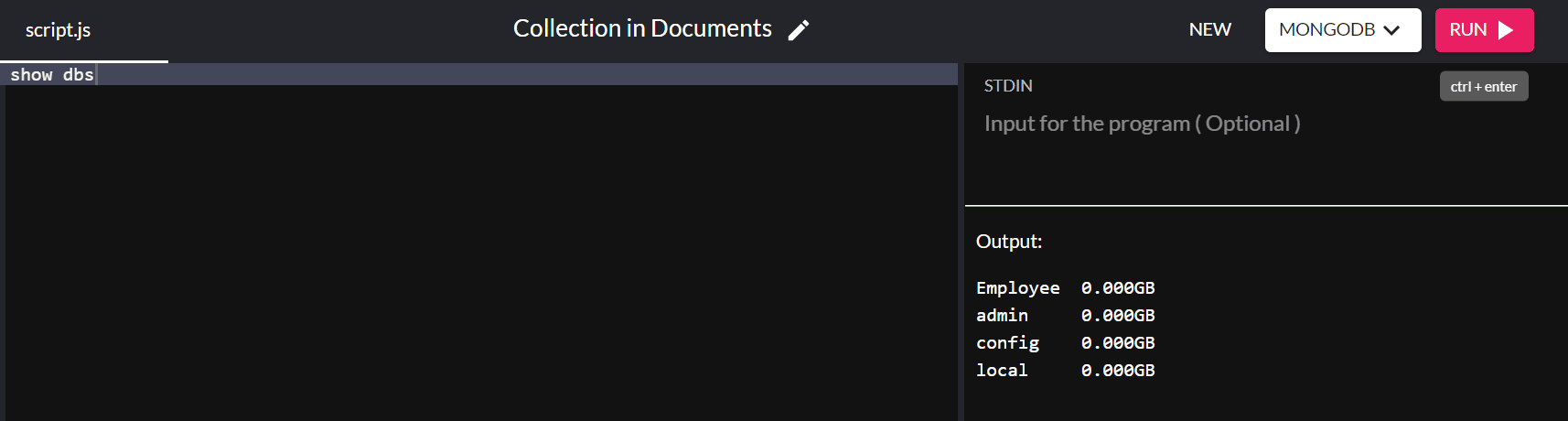
E voilà! Hai creato con successo un database nel tuo sistema!
Utilizzo della bussola MongoDB
Sebbene possiamo lavorare con i server MongoDB dalla shell Mongo, a volte può essere noioso. Potresti riscontrarlo in un ambiente di produzione.
Tuttavia, esiste uno strumento bussola (denominato in modo appropriato Compass) creato da MongoDB che può renderlo più semplice. Ha una GUI migliore e funzionalità aggiuntive come la visualizzazione dei dati, la profilazione delle prestazioni e l'accesso CRUD (crea, leggi, aggiorna, elimina) a dati, database e raccolte.
Puoi scaricare Compass IDE per il tuo sistema operativo e installarlo con il suo semplice processo.
Quindi, apri l'applicazione e crea una connessione con il server incollando la stringa di connessione. Se non riesci a trovarlo, puoi fare clic su Compila i campi di connessione singolarmente . Se non hai cambiato il numero di porta durante l'installazione di MongoDB, fai semplicemente clic sul pulsante di connessione e sei pronto! Altrimenti, inserisci i valori che hai impostato e fai clic su Connetti .
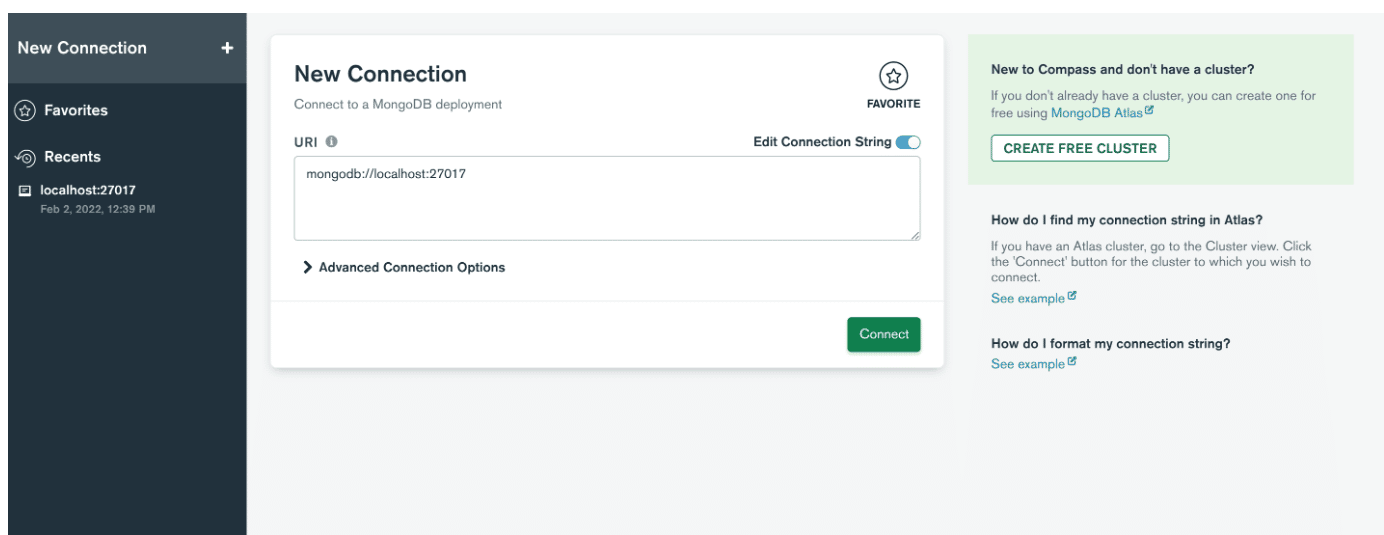
Quindi, fornisci il nome host, la porta e l'autenticazione nella finestra Nuova connessione.
In MongoDB Compass, puoi creare un database e aggiungere la sua prima raccolta contemporaneamente. Ecco come lo fai:
- Fare clic su Crea database per aprire il prompt.
- Immettere il nome del database e la sua prima raccolta.
- Fare clic su Crea database .
Puoi inserire più documenti nel tuo database facendo clic sul nome del tuo database, quindi facendo clic sul nome della raccolta per visualizzare la scheda Documenti . Puoi quindi fare clic sul pulsante Aggiungi dati per inserire uno o più documenti nella tua raccolta.
Durante l'aggiunta dei documenti, è possibile inserirli uno alla volta o come più documenti in un array. Se stai aggiungendo più documenti, assicurati che questi documenti separati da virgole siano racchiusi tra parentesi quadre. Per esempio:
{ _id: 1, item: { name: "apple", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }, { _id: 2, item: { name: "banana", code: "123" }, qty: 20, tags: [ "B" ] }, { _id: 3, item: { name: "spinach", code: "456" }, qty: 25, tags: [ "A", "B" ] }, { _id: 4, item: { name: "lentils", code: "456" }, qty: 30, tags: [ "B", "A" ] }, { _id: 5, item: { name: "pears", code: "000" }, qty: 20, tags: [ [ "A", "B" ], "C" ] }, { _id: 6, item: { name: "strawberry", code: "123" }, tags: [ "B" ] }Infine, fai clic su Inserisci per aggiungere i documenti alla tua raccolta. Ecco come sarebbe il corpo di un documento:
{ "StudentID" : 1 "StudentName" : "JohnDoe" }Qui, i nomi dei campi sono "StudentID" e "StudentName". I valori del campo sono rispettivamente "1" e "JohnDoe".
Comandi utili
È possibile gestire queste raccolte tramite la gestione dei ruoli e i comandi di gestione degli utenti.
Comandi di gestione degli utenti
I comandi di gestione degli utenti di MongoDB contengono comandi che riguardano l'utente. Possiamo creare, aggiornare ed eliminare gli utenti utilizzando questi comandi.
dropUser
Questo comando rimuove un singolo utente dal database specificato. Di seguito è riportata la sintassi:
db.dropUser(username, writeConcern) Qui, username è un campo obbligatorio che contiene il documento con l'autenticazione e le informazioni di accesso sull'utente. Il campo facoltativo writeConcern contiene il livello di attenzione alla scrittura per l'operazione di creazione. Il livello di preoccupazione per la scrittura può essere determinato dal campo facoltativo writeConcern .
Prima di eliminare un utente che ha il ruolo userAdminAnyDatabase , assicurarsi che sia presente almeno un altro utente con privilegi di amministrazione utente.
In questo esempio, rilasceremo l'utente "user26" nel database di test:
use test db.dropUser("user26", {w: "majority", wtimeout: 4000})Produzione:
> db.dropUser("user26", {w: "majority", wtimeout: 4000}); truecreare un utente
Questo comando crea un nuovo utente per il database specificato come segue:
db.createUser(user, writeConcern) Qui, user è un campo obbligatorio che contiene il documento con l'autenticazione e le informazioni di accesso sull'utente da creare. Il campo facoltativo writeConcern contiene il livello di attenzione alla scrittura per l'operazione di creazione. Il livello di preoccupazione per la scrittura può essere determinato dal campo facoltativo, writeConcern .
createUser restituirà un errore utente duplicato se l'utente esiste già nel database.
È possibile creare un nuovo utente nel database di test come segue:
use test db.createUser( { user: "user26", pwd: "myuser123", roles: [ "readWrite" ] } );L'uscita è la seguente:
Successfully added user: { "user" : "user26", "roles" : [ "readWrite", "dbAdmin" ] }grantRolesToUser
Puoi sfruttare questo comando per concedere ruoli aggiuntivi a un utente. Per usarlo, devi tenere a mente la seguente sintassi:
db.runCommand( { grantRolesToUser: "<user>", roles: [ <roles> ], writeConcern: { <write concern> }, comment: <any> } ) È possibile specificare sia i ruoli definiti dall'utente che quelli incorporati nei ruoli sopra menzionati. Se si desidera specificare un ruolo che esiste nello stesso database in cui viene eseguito grantRolesToUser , è possibile specificare il ruolo con un documento, come indicato di seguito:
{ role: "<role>", db: "<database>" }Oppure puoi semplicemente specificare il ruolo con il nome del ruolo. Per esempio:
"readWrite"Se vuoi specificare il ruolo che è presente in un database diverso, dovrai specificare il ruolo con un documento diverso.
Per concedere un ruolo su un database, è necessaria l'azione grantRole sul database specificato.
Ecco un esempio per darti un quadro chiaro. Prendi, ad esempio, un utente productUser00 nel database dei prodotti con i seguenti ruoli:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" } ] L'operazione grantRolesToUser fornisce a "productUser00" il ruolo readWrite nel database stock e il ruolo read nel database prodotti:
use products db.runCommand({ grantRolesToUser: "productUser00", roles: [ { role: "readWrite", db: "stock"}, "read" ], writeConcern: { w: "majority" , wtimeout: 2000 } })L'utente productUser00 nel database dei prodotti ora possiede i seguenti ruoli:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ]utentiInfo
È possibile utilizzare il comando usersInfo per restituire informazioni su uno o più utenti. Ecco la sintassi:
db.runCommand( { usersInfo: <various>, showCredentials: <Boolean>, showCustomData: <Boolean>, showPrivileges: <Boolean>, showAuthenticationRestrictions: <Boolean>, filter: <document>, comment: <any> } ) { usersInfo: <various> } In termini di accesso, gli utenti possono sempre guardare le proprie informazioni. Per esaminare le informazioni di un altro utente, l'utente che esegue il comando deve disporre dei privilegi che includono l'azione viewUser sul database dell'altro utente.
Eseguendo il comando userInfo , è possibile ottenere le seguenti informazioni a seconda delle opzioni specificate:
{ "users" : [ { "_id" : "<db>.<username>", "userId" : <UUID>, // Starting in MongoDB 4.0.9 "user" : "<username>", "db" : "<db>", "mechanisms" : [ ... ], // Starting in MongoDB 4.0 "customData" : <document>, "roles" : [ ... ], "credentials": { ... }, // only if showCredentials: true "inheritedRoles" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedPrivileges" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedAuthenticationRestrictions" : [ ] // only if showPrivileges: true or showAuthenticationRestrictions: true "authenticationRestrictions" : [ ... ] // only if showAuthenticationRestrictions: true }, ], "ok" : 1 } Ora che hai un'idea generale di cosa puoi ottenere con il comando usersInfo , la prossima domanda ovvia che potrebbe apparire è: quali comandi sarebbero utili per guardare utenti specifici e più utenti?
Ecco due esempi pratici per illustrare lo stesso:
Per visualizzare i privilegi e le informazioni specifici per utenti specifici, ma non le credenziali, per un utente "Anthony" definito nel database "office", eseguire il comando seguente:
db.runCommand( { usersInfo: { user: "Anthony", db: "office" }, showPrivileges: true } )Se vuoi guardare un utente nel database corrente, puoi menzionare l'utente solo per nome. Ad esempio, se sei nel database principale e un utente chiamato "Timothy" esiste nel database principale, puoi eseguire il comando seguente:
db.getSiblingDB("home").runCommand( { usersInfo: "Timothy", showPrivileges: true } ) Successivamente, puoi utilizzare un array se desideri esaminare le informazioni per vari utenti. Puoi includere i campi facoltativi showCredentials e showPrivileges oppure puoi scegliere di lasciarli fuori. Ecco come sarebbe il comando:
db.runCommand({ usersInfo: [ { user: "Anthony", db: "office" }, { user: "Timothy", db: "home" } ], showPrivileges: true })revokeRolesFromUser
È possibile sfruttare il comando revokeRolesFromUser per rimuovere uno o più ruoli da un utente nel database in cui sono presenti i ruoli. Il comando revokeRolesFromUser ha la seguente sintassi:
db.runCommand( { revokeRolesFromUser: "<user>", roles: [ { role: "<role>", db: "<database>" } | "<role>", ], writeConcern: { <write concern> }, comment: <any> } ) Nella sintassi sopra menzionata, puoi specificare sia i ruoli definiti dall'utente che quelli integrati nel campo dei roles . Simile al comando grantRolesToUser , puoi specificare il ruolo che vuoi revocare in un documento o usarne il nome.
Per eseguire correttamente il comando revokeRolesFromUser , è necessario disporre dell'azione revokeRole sul database specificato.
Ecco un esempio per portare a casa il punto. L'entità productUser00 nel database dei prodotti aveva i ruoli seguenti:
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ] Il seguente comando revokeRolesFromUser rimuoverà due dei ruoli dell'utente: il ruolo "lettura" dai products e il ruolo assetsWriter dal database "assets":
use products db.runCommand( { revokeRolesFromUser: "productUser00", roles: [ { role: "AssetsWriter", db: "assets" }, "read" ], writeConcern: { w: "majority" } } )L'utente "productUser00" nel database dei prodotti ora ha solo un ruolo rimanente:

"roles" : [ { "role" : "readWrite", "db" : "stock" } ]Comandi di gestione dei ruoli
I ruoli concedono agli utenti l'accesso alle risorse. Diversi ruoli integrati possono essere utilizzati dagli amministratori per controllare l'accesso a un sistema MongoDB. Se i ruoli non coprono i privilegi desiderati, puoi anche andare oltre per creare nuovi ruoli in un determinato database.
dropRole
Con il comando dropRole , puoi eliminare un ruolo definito dall'utente dal database su cui esegui il comando. Per eseguire questo comando, utilizzare la seguente sintassi:
db.runCommand( { dropRole: "<role>", writeConcern: { <write concern> }, comment: <any> } ) Per un'esecuzione corretta, è necessario disporre dell'azione dropRole nel database specificato. Le seguenti operazioni rimuoverebbero il ruolo writeTags dal database "prodotti":
use products db.runCommand( { dropRole: "writeTags", writeConcern: { w: "majority" } } )createRole
Puoi sfruttare il comando createRole per creare un ruolo e specificarne i privilegi. Il ruolo verrà applicato al database su cui scegli di eseguire il comando. Il comando createRole restituirebbe un errore di ruolo duplicato se il ruolo esiste già nel database.
Per eseguire questo comando, segui la sintassi indicata:
db.adminCommand( { createRole: "<new role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], roles: [ { role: "<role>", db: "<database>" } | "<role>", ], authenticationRestrictions: [ { clientSource: ["<IP>" | "<CIDR range>", ...], serverAddress: ["<IP>" | "<CIDR range>", ...] }, ], writeConcern: <write concern document>, comment: <any> } )I privilegi di un ruolo si applicherebbero al database in cui è stato creato il ruolo. Il ruolo può ereditare i privilegi da altri ruoli nel proprio database. Ad esempio, un ruolo creato nel database "admin" può includere privilegi che si applicano a un cluster oa tutti i database. Può anche ereditare privilegi da ruoli presenti in altri database.
Per creare un ruolo in un database, devi avere due cose:
- L'azione
grantRolesu quel database per menzionare i privilegi per il nuovo ruolo e per menzionare i ruoli da cui ereditare. - L'azione
createRolesu quella risorsa di database.
Il seguente comando createRole creerà un ruolo clusterAdmin nel database utente:
db.adminCommand({ createRole: "clusterAdmin", privileges: [ { resource: { cluster: true }, actions: [ "addShard" ] }, { resource: { db: "config", collection: "" }, actions: [ "find", "remove" ] }, { resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert" ] }, { resource: { db: "", collection: "" }, actions: [ "find" ] } ], roles: [ { role: "read", db: "user" } ], writeConcern: { w: "majority" , wtimeout: 5000 } })grantRolesToRole
Con il comando grantRolesToRole , puoi concedere ruoli a un ruolo definito dall'utente. Il comando grantRolesToRole influirà sui ruoli nel database in cui viene eseguito il comando.
Questo comando grantRolesToRole ha la seguente sintassi:
db.runCommand( { grantRolesToRole: "<role>", roles: [ { role: "<role>", db: "<database>" }, ], writeConcern: { <write concern> }, comment: <any> } ) I privilegi di accesso sono simili al comando grantRolesToUser : è necessaria un'azione grantRole su un database per la corretta esecuzione del comando.
Nell'esempio seguente, puoi utilizzare il comando grantRolesToUser per aggiornare il ruolo productsReader nel database "products" per ereditare i privilegi del ruolo productsWriter :
use products db.runCommand( { grantRolesToRole: "productsReader", roles: [ "productsWriter" ], writeConcern: { w: "majority" , wtimeout: 5000 } } )revokePrivilegesFromRole
È possibile utilizzare revokePrivilegesFromRole per rimuovere i privilegi specificati dal ruolo definito dall'utente nel database in cui viene eseguito il comando. Per una corretta esecuzione, è necessario tenere a mente la seguente sintassi:
db.runCommand( { revokePrivilegesFromRole: "<role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], writeConcern: <write concern document>, comment: <any> } )Per revocare un privilegio, il modello "documento risorsa" deve corrispondere al campo "risorsa" di quel privilegio. Il campo "azioni" può essere una corrispondenza esatta o un sottoinsieme.
Si consideri, ad esempio, il ruolo manageRole nel database dei prodotti con i seguenti privilegi che specificano il database "manager" come risorsa:
{ "resource" : { "db" : "managers", "collection" : "" }, "actions" : [ "insert", "remove" ] }Non è possibile revocare le azioni "inserisci" o "rimuovi" da una sola raccolta nel database dei gestori. Le seguenti operazioni non comportano alcun cambiamento nel ruolo:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert", "remove" ] } ] } ) db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert" ] } ] } ) Per revocare le azioni "inserisci" e/o "rimuovi" dal ruolo manageRole ruolo , devi abbinare esattamente il documento risorsa. Ad esempio, la seguente operazione revoca solo l'azione "rimuovi" dal privilegio esistente:
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "" }, actions : [ "remove" ] } ] } )La seguente operazione rimuoverà più privilegi dal ruolo "esecutivo" nel database dei gestori:
use managers db.runCommand( { revokePrivilegesFromRole: "executive", privileges: [ { resource: { db: "managers", collection: "" }, actions: [ "insert", "remove", "find" ] }, { resource: { db: "managers", collection: "partners" }, actions: [ "update" ] } ], writeConcern: { w: "majority" } } )ruoliInfo
Il comando rolesInfo restituirà informazioni sui privilegi e sull'ereditarietà per i ruoli specificati, inclusi i ruoli predefiniti e definiti dall'utente. Puoi anche sfruttare il comando rolesInfo per recuperare tutti i ruoli con ambito in un database.
Per una corretta esecuzione, segui questa sintassi:
db.runCommand( { rolesInfo: { role: <name>, db: <db> }, showPrivileges: <Boolean>, showBuiltinRoles: <Boolean>, comment: <any> } )Per restituire informazioni per un ruolo dal database corrente, è possibile specificarne il nome come segue:
{ rolesInfo: "<rolename>" }Per restituire informazioni per un ruolo da un altro database, puoi menzionare il ruolo con un documento che menziona il ruolo e il database:
{ rolesInfo: { role: "<rolename>", db: "<database>" } }Ad esempio, il comando seguente restituisce le informazioni sull'ereditarietà del ruolo per l'esecutivo del ruolo definito nel database dei gestori:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" } } ) Il prossimo comando restituirà le informazioni sull'ereditarietà del ruolo: accountManager sul database su cui viene eseguito il comando:
db.runCommand( { rolesInfo: "accountManager" } )Il comando seguente restituirà sia i privilegi che l'ereditarietà del ruolo per il ruolo "esecutivo" come definito nel database dei gestori:
db.runCommand( { rolesInfo: { role: "executive", db: "managers" }, showPrivileges: true } )Per citare più ruoli, puoi usare un array. Puoi anche menzionare ogni ruolo nell'array come una stringa o un documento.
È necessario utilizzare una stringa solo se il ruolo esiste nel database su cui viene eseguito il comando:
{ rolesInfo: [ "<rolename>", { role: "<rolename>", db: "<database>" }, ] }Ad esempio, il comando seguente restituirà informazioni per tre ruoli su tre database diversi:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ] } )Puoi ottenere sia i privilegi che l'ereditarietà del ruolo come segue:
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ], showPrivileges: true } )Incorporamento di documenti MongoDB per prestazioni migliori
I database di documenti come MongoDB ti consentono di definire il tuo schema in base alle tue esigenze. Per creare schemi ottimali in MongoDB, puoi annidare i documenti. Quindi, invece di abbinare la tua applicazione a un modello di dati, puoi creare un modello di dati che corrisponda al tuo caso d'uso.
I documenti incorporati ti consentono di archiviare i dati correlati a cui accedi insieme. Durante la progettazione di schemi per MongoDB, si consiglia di incorporare i documenti per impostazione predefinita. Utilizzare join e riferimenti lato database o lato applicazione solo quando ne vale la pena.
Assicurati che il carico di lavoro possa recuperare un documento tutte le volte che è necessario. Allo stesso tempo, il documento dovrebbe contenere anche tutti i dati di cui ha bisogno. Questo è fondamentale per le prestazioni eccezionali della tua applicazione.
Di seguito, troverai alcuni modelli diversi per incorporare i documenti:
Modello di documento incorporato
Puoi usarlo per incorporare sottostrutture anche complicate nei documenti con cui vengono utilizzate. L'incorporamento di dati connessi in un unico documento può ridurre il numero di operazioni di lettura necessarie per ottenere i dati. In genere, dovresti strutturare lo schema in modo che l'applicazione riceva tutte le informazioni richieste in un'unica operazione di lettura. Quindi, la regola da tenere a mente qui è che cosa viene usato insieme dovrebbe essere memorizzato insieme .
Modello di sottoinsieme incorporato
Il modello di sottoinsieme incorporato è un caso ibrido. Lo useresti per una raccolta separata di un lungo elenco di elementi correlati, in cui puoi tenere alcuni di quegli elementi a portata di mano per la visualizzazione.
Ecco un esempio che elenca le recensioni di film:
> db.movie.findOne() { _id: 321475, title: "The Dark Knight" } > db.review.find({movie_id: 321475}) { _id: 264579, movie_id: 321475, stars: 4 text: "Amazing" } { _id: 375684, movie_id: 321475, stars:5, text: "Mindblowing" }Ora, immagina un migliaio di recensioni simili, ma prevedi di visualizzare solo le due più recenti quando mostri un film. In questo scenario, ha senso memorizzare quel sottoinsieme come un elenco all'interno del documento del film:
> db.movie.findOne({_id: 321475}) { _id: 321475, title: "The Dark Knight", recent_reviews: [ {_id: 264579, stars: 4, text: "Amazing"}, {_id: 375684, stars: 5, text: "Mindblowing"} ] }</codeIn poche parole, se accedi regolarmente a un sottoinsieme di elementi correlati, assicurati di incorporarlo.
Accesso indipendente
Potresti voler archiviare i documenti secondari nella loro raccolta per separarli dalla loro raccolta principale.
Ad esempio, prendi la linea di prodotti di un'azienda. Se l'azienda vende una piccola serie di prodotti, potresti volerli archiviare all'interno del documento aziendale. Ma se desideri riutilizzarli in tutte le aziende o accedervi direttamente tramite la loro unità di conservazione delle scorte (SKU), vorresti anche archiviarli nella loro collezione.
Se modifichi o accedi a un'entità in modo indipendente, crea una raccolta per archiviarla separatamente per le migliori pratiche.
Liste illimitate
La memorizzazione di brevi elenchi di informazioni correlate nel proprio documento presenta uno svantaggio. Se la tua lista continua a crescere senza controllo, non dovresti inserirla in un unico documento. Questo perché non saresti in grado di supportarlo a lungo.
Ci sono due ragioni per questo. Innanzitutto, MongoDB ha un limite alla dimensione di un singolo documento. In secondo luogo, se accedi al documento a troppe frequenze, vedrai risultati negativi dall'utilizzo incontrollato della memoria.
Per dirla semplicemente, se un elenco inizia a crescere illimitatamente, crea una raccolta per archiviarlo separatamente.
Schema di riferimento esteso
Il modello di riferimento esteso è come il modello di sottoinsieme. It also optimizes information that you regularly access to store on the document.
Here, instead of a list, it's leveraged when a document refers to another that is present in the same collection. At the same time, it also stores some fields from that other document for ready access.
Per esempio:
> db.movie.findOne({_id: 245434}) { _id: 245434, title: "Mission Impossible 4 - Ghost Protocol", studio_id: 924935, studio_name: "Paramount Pictures" }As you can see, “the studio_id” is stored so that you can look up more information on the studio that created the film. But the studio's name is also copied to this document for simplicity.
To embed information from modified documents regularly, remember to update documents where you've copied that information when it is modified. In other words, if you routinely access some fields from a referenced document, embed them.
How To Monitor MongoDB
You can use monitoring tools like Kinsta APM to debug long API calls, slow database queries, long external URL requests, to name a few. You can even leverage commands to improve database performance. You can also use them to inspect the ase/” data-mce-href=”https://kinsta.com/knowledgebase/wordpress-repair-database/”>health of your database instances.
Why Should You Monitor MongoDB Databases?
A key aspect of database administration planning is monitoring your cluster's performance and health. MongoDB Atlas handles the majority of administration efforts through its fault-tolerance/scaling abilities.
Despite that, users need to know how to track clusters. They should also know how to scale or tweak whatever they need before hitting a crisis.
By monitoring MongoDB databases, you can:
- Observe the utilization of resources.
- Understand the current capacity of your database.
- React and detect real-time issues to enhance your application stack.
- Observe the presence of performance issues and abnormal behavior.
- Align with your governance/data protection and service-level agreement (SLA) requirements.
Key Metrics To Monitor
While monitoring MongoDB, there are four key aspects you need to keep in mind:
1. MongoDB Hardware Metrics
Here are the primary metrics for monitoring hardware:
Normalized Process CPU
It's defined as the percentage of time spent by the CPU on application software maintaining the MongoDB process.
You can scale this to a range of 0-100% by dividing it by the number of CPU cores. It includes CPU leveraged by modules such as kernel and user.
High kernel CPU might show exhaustion of CPU via the operating system operations. But the user linked with MongoDB operations might be the root cause of CPU exhaustion.
Normalized System CPU
It's the percentage of time the CPU spent on system calls servicing this MongoDB process. You can scale it to a range of 0-100% by dividing it by the number of CPU cores. It also covers the CPU used by modules such as iowait, user, kernel, steal, etc.
User CPU or high kernel might show CPU exhaustion through MongoDB operations (software). High iowait might be linked to storage exhaustion causing CPU exhaustion.
Disk IOPS
Disk IOPS is the average consumed IO operations per second on MongoDB's disk partition.
Disk Latency
This is the disk partition's read and write disk latency in milliseconds in MongoDB. High values (>500ms) show that the storage layer might affect MongoDB's performance.
System Memory
Use the system memory to describe physical memory bytes used versus available free space.
The available metric approximates the number of bytes of system memory available. You can use this to execute new applications, without swapping.
Disk Space Free
This is defined as the total bytes of free disk space on MongoDB's disk partition. MongoDB Atlas provides auto-scaling capabilities based on this metric.
Swap Usage
You can leverage a swap usage graph to describe how much memory is being placed on the swap device. A high used metric in this graph shows that swap is being utilized. This shows that the memory is under-provisioned for the current workload.
MongoDB Cluster's Connection and Operation Metrics
Here are the main metrics for Operation and Connection Metrics:
Operation Execution Times
The average operation time (write and read operations) performed over the selected sample period.
Opcounters
It is the average rate of operations executed per second over the selected sample period. Opcounters graph/metric shows the operations breakdown of operation types and velocity for the instance.
Connections
This metric refers to the number of open connections to the instance. High spikes or numbers might point to a suboptimal connection strategy either from the unresponsive server or the client side.
Query Targeting and Query Executors
This is the average rate per second over the selected sample period of scanned documents. For query executors, this is during query-plan evaluation and queries. Query targeting shows the ratio between the number of documents scanned and the number of documents returned.
Un rapporto numerico elevato indica operazioni non ottimali. Queste operazioni scansionano molti documenti per restituire una parte più piccola.
Scansiona e ordina
Descrive la frequenza media al secondo nel periodo di campionamento scelto per le query. Restituisce risultati ordinati che non possono eseguire l'operazione di ordinamento utilizzando un indice.
Code
Le code possono descrivere il numero di operazioni in attesa di un blocco, in scrittura o in lettura. Code elevate potrebbero rappresentare l'esistenza di una progettazione dello schema non ottimale. Potrebbe anche indicare percorsi di scrittura in conflitto, spingendo un'elevata concorrenza sulle risorse del database.
Metriche di replica MongoDB
Di seguito sono riportate le metriche principali per il monitoraggio della replica:
Finestra Oplog di replica
Questa metrica elenca il numero approssimativo di ore disponibili nell'oplog di replica del primario. Se un secondario è in ritardo di più di questo importo, non può tenere il passo e avrà bisogno di una risincronizzazione completa.
Ritardo di replica
Il ritardo di replica è definito come il numero approssimativo di secondi di ritardo di un nodo secondario rispetto al primario nelle operazioni di scrittura. Un ritardo di replica elevato indicherebbe un secondario che incontra difficoltà nella replica. Potrebbe influire sulla latenza dell'operazione, data la preoccupazione di lettura/scrittura delle connessioni.
Headroom di replica
Questa metrica si riferisce alla differenza tra la finestra dell'oplog della replica primaria e il ritardo di replica della replica secondaria. Se questo valore va a zero, potrebbe portare un secondario in modalità RECUPERO.
Opcounters - repl
Opcounters -repl è definito come la velocità media delle operazioni di replica eseguite al secondo per il periodo di campionamento scelto. Con opcounters -graph/metric, puoi dare un'occhiata alla velocità delle operazioni e alla suddivisione dei tipi di operazioni per l'istanza specificata.
Oplog GB/ora
Questo è definito come il tasso medio di gigabyte di oplog che il primario genera all'ora. Elevati volumi imprevisti di oplog potrebbero indicare un carico di lavoro di scrittura altamente insufficiente o un problema di progettazione dello schema.
Strumenti di monitoraggio delle prestazioni di MongoDB
MongoDB dispone di strumenti di interfaccia utente integrati in Cloud Manager, Atlas e Ops Manager per il monitoraggio delle prestazioni. Fornisce inoltre alcuni comandi e strumenti indipendenti per esaminare più dati grezzi. Parleremo di alcuni strumenti che puoi eseguire da un host che ha accesso e ruoli appropriati per controllare il tuo ambiente:
mongotopo
Puoi sfruttare questo comando per tenere traccia della quantità di tempo che un'istanza MongoDB dedica alla scrittura e alla lettura dei dati per raccolta. Usa la seguente sintassi:
mongotop <options> <connection-string> <polling-interval in seconds>rs.status()
Questo comando restituisce lo stato del set di repliche. Viene eseguito dal punto di vista del membro in cui viene eseguito il metodo.
mongostato
È possibile utilizzare il comando mongostat per ottenere una rapida panoramica dello stato dell'istanza del server MongoDB. Per un output ottimale, puoi usarlo per guardare una singola istanza per un evento specifico poiché offre una vista in tempo reale.
Sfrutta questo comando per monitorare le statistiche di base del server come code di blocco, interruzione delle operazioni, statistiche sulla memoria MongoDB e connessioni/rete:
mongostat <options> <connection-string> <polling interval in seconds>dbStats
Questo comando restituisce le statistiche di archiviazione per un database specifico, come il numero di indici e la relativa dimensione, i dati di raccolta totali rispetto alle dimensioni di archiviazione e le statistiche relative alla raccolta (numero di raccolte e documenti).
db.serverStatus()
È possibile sfruttare il comando db.serverStatus() per avere una panoramica dello stato del database. Fornisce un documento che rappresenta i contatori delle metriche dell'istanza corrente. Esegui questo comando a intervalli regolari per raccogliere le statistiche sull'istanza.
collStats
Il comando collStats raccoglie statistiche simili a quelle offerte da dbStats a livello di raccolta. Il suo output consiste in un conteggio di oggetti nella raccolta, la quantità di spazio su disco consumato dalla raccolta, le dimensioni della raccolta e le informazioni relative ai suoi indici per una determinata raccolta.
È possibile utilizzare tutti questi comandi per offrire report e monitoraggio in tempo reale del server di database che consentono di monitorare le prestazioni e gli errori del database e assistere nel processo decisionale informato per perfezionare un database.
Come eliminare un database MongoDB
Per eliminare un database che hai creato in MongoDB, devi connetterti ad esso tramite la parola chiave use.
Supponiamo che tu abbia creato un database chiamato "Ingegneri". Per connetterti al database, utilizzerai il seguente comando:
use Engineers Quindi, digita db.dropDatabase() per eliminare questo database. Dopo l'esecuzione, questo è il risultato che puoi aspettarti:
{ "dropped" : "Engineers", "ok" : 1 } È possibile eseguire il comando showdbs per verificare se il database esiste ancora.
Riepilogo
Per spremere fino all'ultima goccia di valore da MongoDB, devi avere una forte comprensione dei fondamenti. Quindi, è fondamentale conoscere i database MongoDB come il palmo della tua mano. Ciò richiede prima di tutto di familiarizzare con i metodi per creare un database.
In questo articolo, facciamo luce sui diversi metodi che puoi utilizzare per creare un database in MongoDB, seguiti da una descrizione dettagliata di alcuni eleganti comandi MongoDB per tenerti aggiornato sui tuoi database. Infine, abbiamo completato la discussione discutendo su come sfruttare i documenti incorporati e gli strumenti di monitoraggio delle prestazioni in MongoDB per garantire che il flusso di lavoro funzioni alla massima efficienza.
Qual è la tua opinione su questi comandi MongoDB? Ci siamo persi un aspetto o un metodo che ti sarebbe piaciuto vedere qui? Fateci sapere nei commenti!