
Costruisci un robusto set di repliche MongoDB in tempi record (4 metodi)
Pubblicato: 2023-03-11MongoDB è un database NoSQL che utilizza documenti simili a JSON con schemi dinamici. Quando si lavora con i database, è sempre utile disporre di un piano di emergenza nel caso in cui uno dei server del database fallisca. Sidebar, puoi ridurre le possibilità che ciò accada sfruttando un ingegnoso strumento di gestione per il tuo sito WordPress.
Ecco perché è utile avere molte copie dei tuoi dati. Riduce anche le latenze di lettura. Allo stesso tempo, può migliorare la scalabilità e la disponibilità del database. È qui che entra in gioco la replica. È definita come la pratica di sincronizzare i dati su più database.
In questo articolo, ci immergeremo nei vari aspetti salienti della replica di MongoDB, come le sue caratteristiche e il suo meccanismo, solo per citarne alcuni.
Cos'è la replica in MongoDB?
In MongoDB, i set di repliche eseguono la replica. Questo è un gruppo di server che mantengono lo stesso set di dati tramite la replica. Puoi persino utilizzare la replica MongoDB come parte del bilanciamento del carico. Qui puoi distribuire le operazioni di scrittura e lettura su tutte le istanze, in base al caso d'uso.
Che cos'è un set di repliche MongoDB?
Ogni istanza di MongoDB che fa parte di un determinato set di repliche è un membro. Ogni set di repliche deve avere un membro primario e almeno un membro secondario.
Il membro primario è il punto di accesso primario per le transazioni con il set di repliche. È anche l'unico membro che può accettare operazioni di scrittura. La replica copia prima l'oplog del primario (log delle operazioni). Successivamente, ripete le modifiche registrate sui rispettivi set di dati dei secondari. Pertanto, ogni set di repliche può avere solo un membro primario alla volta. Vari primari che ricevono operazioni di scrittura possono causare conflitti di dati.
In genere, le applicazioni interrogano solo il membro primario per le operazioni di scrittura e lettura. Puoi progettare la tua configurazione per leggere da uno o più membri secondari. Il trasferimento di dati asincrono può far sì che le letture dei nodi secondari servano dati obsoleti. Pertanto, una tale disposizione non è l'ideale per ogni caso d'uso.
Funzionalità del set di repliche
Il meccanismo di failover automatico distingue i set di replica di MongoDB dalla concorrenza. In assenza di un primario, un'elezione automatizzata tra i nodi secondari sceglie un nuovo primario.
Set di repliche MongoDB rispetto al cluster MongoDB
Un set di repliche MongoDB creerà varie copie dello stesso set di dati attraverso i nodi del set di repliche. Lo scopo principale di un set di repliche è:
- Offri una soluzione di backup integrata
- Aumentare la disponibilità dei dati
Un cluster MongoDB è un gioco con la palla completamente diverso. Distribuisce i dati su molti nodi tramite una chiave di partizione. Questo processo frammenterà i dati in molti pezzi chiamati frammenti. Successivamente, copia ogni frammento su un nodo diverso. Un cluster mira a supportare set di dati di grandi dimensioni e operazioni a throughput elevato. Lo raggiunge ridimensionando orizzontalmente il carico di lavoro.
Ecco la differenza tra un set di repliche e un cluster, in parole povere:
- Un cluster distribuisce il carico di lavoro. Memorizza anche frammenti di dati (frammenti) su molti server.
- Un set di repliche duplica completamente il set di dati.
MongoDB ti consente di combinare queste funzionalità creando un cluster frammentato. Qui puoi replicare ogni frammento su un server secondario. Ciò consente a uno shard di offrire un'elevata ridondanza e disponibilità dei dati.
La manutenzione e l'impostazione di un set di repliche può essere tecnicamente impegnativa e richiedere molto tempo. E trovare il giusto servizio di hosting? Questo è tutto un altro mal di testa. Con così tante opzioni là fuori, è facile perdere ore a fare ricerche, invece di costruire la tua attività.
Lascia che ti dia una breve descrizione di uno strumento che fa tutto questo e molto altro in modo che tu possa tornare a schiacciarlo con il tuo servizio/prodotto.
La soluzione di hosting di applicazioni di Kinsta, che è considerata affidabile da oltre 55.000 sviluppatori, puoi metterla in funzione in soli 3 semplici passaggi. Se sembra troppo bello per essere vero, ecco alcuni altri vantaggi dell'utilizzo di Kinsta:
- Goditi prestazioni migliori con le connessioni interne di Kinsta : dimentica le tue lotte con i database condivisi. Passa a database dedicati con connessioni interne che non hanno limiti di numero di query o numero di righe. Kinsta è più veloce, più sicuro e non ti addebiterà la larghezza di banda/traffico interno.
- Un set di funzionalità su misura per gli sviluppatori : ridimensiona la tua applicazione sulla solida piattaforma che supporta Gmail, YouTube e Ricerca Google. State tranquilli, qui siete nelle mani più sicure.
- Goditi velocità impareggiabili con un data center di tua scelta : scegli la regione che funziona meglio per te e per i tuoi clienti. Con oltre 25 data center tra cui scegliere, gli oltre 275 PoP di Kinsta assicurano la massima velocità e una presenza globale per il tuo sito web.
Prova oggi gratuitamente la soluzione di hosting delle applicazioni di Kinsta!
Come funziona la replica in MongoDB?
In MongoDB, invii operazioni di scrittura al server primario (nodo). Il primario assegna le operazioni sui server secondari, replicando i dati.
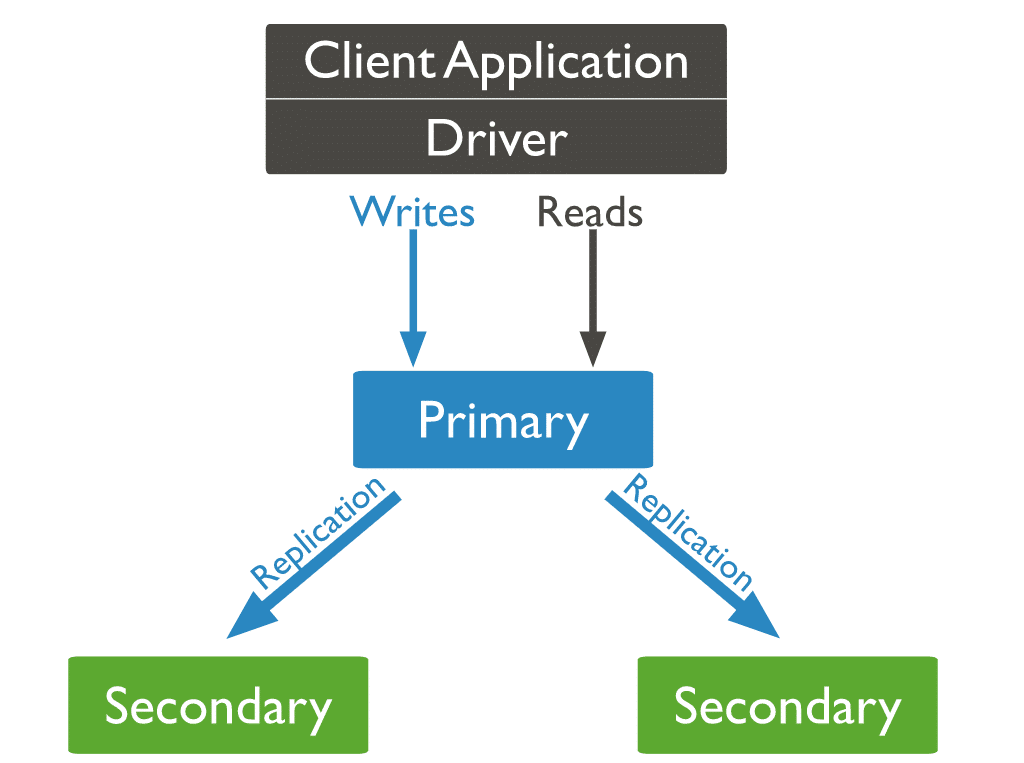
Tre tipi di nodi MongoDB
Dei tre tipi di nodi MongoDB, due sono già emersi: nodi primari e nodi secondari. Il terzo tipo di nodo MongoDB utile durante la replica è un arbitro. Il nodo arbitro non ha una copia del set di dati e non può diventare un nodo primario. Detto questo, l'arbitro partecipa alle elezioni per le primarie.
Abbiamo precedentemente menzionato cosa succede quando il nodo primario si interrompe, ma cosa succede se i nodi secondari mordono la polvere? In tale scenario, il nodo primario diventa secondario e il database diventa irraggiungibile.
Elezione dei membri
Le elezioni possono verificarsi nei seguenti scenari:
- Inizializzazione di un set di repliche
- Perdita di connettività al nodo primario (che può essere rilevata dagli heartbeat)
- Manutenzione di un set di repliche utilizzando i metodi
rs.reconfigostepDown - Aggiunta di un nuovo nodo a un set di repliche esistente
Un set di repliche può contenere fino a 50 membri, ma solo 7 o meno possono votare in qualsiasi elezione.
Il tempo medio prima che un cluster elegga un nuovo primario non dovrebbe superare i 12 secondi. L'algoritmo di elezione proverà ad avere il secondario con la massima priorità disponibile. Allo stesso tempo, i membri con un valore di priorità pari a 0 non possono diventare primari e non partecipano alle elezioni.
La preoccupazione per la scrittura
Per la durabilità, le operazioni di scrittura hanno un framework per copiare i dati in un numero specificato di nodi. Puoi persino offrire un feedback al cliente con questo. Questo framework è anche noto come "problema di scrittura". Dispone di membri portatori di dati che devono riconoscere un problema di scrittura prima che l'operazione abbia esito positivo. In genere, i set di repliche hanno un valore pari a 1 come problema di scrittura. Pertanto, solo il primario dovrebbe riconoscere la scrittura prima di restituire il riconoscimento del problema di scrittura.
È anche possibile aumentare il numero di membri necessari per riconoscere l'operazione di scrittura. Non c'è limite al numero di membri che puoi avere. Tuttavia, se i numeri sono elevati, è necessario gestire un'elevata latenza. Questo perché il client deve attendere il riconoscimento da parte di tutti i membri. Inoltre, puoi impostare la preoccupazione di scrittura della "maggioranza". Questo calcola più della metà dei membri dopo aver ricevuto il loro riconoscimento.
Leggi Preferenza
Per le operazioni di lettura, puoi menzionare la preferenza di lettura che descrive come il database indirizza la query ai membri del set di repliche. Generalmente, il nodo primario riceve l'operazione di lettura ma il client può menzionare una preferenza di lettura per inviare le operazioni di lettura ai nodi secondari. Ecco le opzioni per la preferenza di lettura:
- primaryPreferred : in genere, le operazioni di lettura provengono dal nodo primario ma se questo non è disponibile i dati vengono estratti dai nodi secondari.
- primary : tutte le operazioni di lettura provengono dal nodo primario.
- secondary : tutte le operazioni di lettura vengono eseguite dai nodi secondari.
- più vicino : Qui, le richieste di lettura vengono instradate al nodo raggiungibile più vicino, che può essere rilevato eseguendo il comando
ping. Il risultato delle operazioni di lettura può provenire da qualsiasi membro del set di repliche, indipendentemente dal fatto che sia primario o secondario. - secondaryPreferred : qui, la maggior parte delle operazioni di lettura proviene dai nodi secondari, ma se nessuno di essi è disponibile, i dati vengono prelevati dal nodo primario.
Sincronizzazione dei dati del set di replica
Per mantenere copie aggiornate del set di dati condiviso, i membri secondari di un set di repliche replicano o sincronizzano i dati di altri membri.
MongoDB sfrutta due forme di sincronizzazione dei dati. Sincronizzazione iniziale per popolare i nuovi membri con il set di dati completo. Replica per eseguire modifiche continue al set di dati completo.
Sincronizzazione iniziale
Durante la sincronizzazione iniziale, un nodo secondario esegue il comando init sync per sincronizzare tutti i dati dal nodo primario a un altro nodo secondario che contiene i dati più recenti. Pertanto, il nodo secondario sfrutta costantemente la funzione tailable cursor per interrogare le voci oplog più recenti all'interno della raccolta local.oplog.rs del nodo primario e applica queste operazioni all'interno di queste voci oplog.
Da MongoDB 5.2, le sincronizzazioni iniziali possono essere basate sulla copia di file o logiche.
Sincronizzazione logica
Quando esegui una sincronizzazione logica, MongoDB:
- Sviluppa tutti gli indici delle raccolte man mano che i documenti vengono copiati per ciascuna raccolta.
- Duplica tutti i database ad eccezione del database locale.
mongodesegue la scansione di ogni raccolta in tutti i database di origine e inserisce tutti i dati nei duplicati di queste raccolte. - Esegue tutte le modifiche sul set di dati. Sfruttando l'oplog dall'origine, il
mongodaggiorna il proprio set di dati per rappresentare lo stato corrente del set di repliche. - Estrae i record oplog appena aggiunti durante la copia dei dati. Assicurarsi che il membro di destinazione disponga di spazio su disco sufficiente all'interno del database locale per archiviare provvisoriamente questi record oplog per la durata di questa fase di copia dei dati.
Al termine della sincronizzazione iniziale, il membro passa da STARTUP2 a SECONDARY .
Sincronizzazione iniziale basata su copia di file
Fin dall'inizio, puoi eseguirlo solo se usi MongoDB Enterprise. Questo processo esegue la sincronizzazione iniziale duplicando e spostando i file nel file system. Questo metodo di sincronizzazione potrebbe essere più veloce della sincronizzazione iniziale logica in alcuni casi. Tenere presente che la sincronizzazione iniziale basata sulla copia dei file potrebbe portare a conteggi imprecisi se si esegue il metodo count() senza un predicato di query.
Ma anche questo metodo ha la sua giusta dose di limitazioni:
- Durante una sincronizzazione iniziale basata sulla copia di file, non è possibile scrivere nel database locale del membro che viene sincronizzato. Inoltre, non è possibile eseguire un backup sul membro che viene sincronizzato o sul membro da cui viene sincronizzata.
- Quando si sfrutta il motore di archiviazione crittografato, MongoDB utilizza la chiave di origine per crittografare la destinazione.
- Puoi eseguire una sincronizzazione iniziale solo da un determinato membro alla volta.
Replica
I membri secondari replicano i dati in modo coerente dopo la sincronizzazione iniziale. I membri secondari duplicheranno l'oplog dalla loro sincronizzazione dall'origine ed eseguiranno queste operazioni in un processo asincrono.
I secondari sono in grado di modificare automaticamente la loro sincronizzazione dall'origine secondo necessità in base alle modifiche nel tempo di ping e nello stato della replica degli altri membri.
Replica in streaming
Da MongoDB 4.4, la sincronizzazione dalle fonti invia un flusso continuo di voci oplog ai loro secondari di sincronizzazione. La replica in streaming riduce il ritardo di replica nelle reti ad alto carico e ad alta latenza. Io posso anche:
- Riduci il rischio di perdere le operazioni di scrittura con
w:1a causa del failover primario. - Diminuire l'obsolescenza per le letture dai secondari.
- Riduci la latenza nelle operazioni di scrittura con
w:“majority”ew:>1. In breve, qualsiasi problema di scrittura che richiede l'attesa per la replica.
Replica multithread
MongoDB era solito scrivere operazioni in batch attraverso più thread per migliorare la concorrenza. MongoDB raggruppa i batch per ID documento applicando ogni gruppo di operazioni con un thread diverso.
MongoDB esegue sempre operazioni di scrittura su un determinato documento nel suo ordine di scrittura originale. Questo è cambiato in MongoDB 4.0.
Da MongoDB 4.0, le operazioni di lettura destinate ai secondari e configurate con un livello di preoccupazione per la lettura di “majority” o “local” ora leggeranno da uno snapshot WiredTiger dei dati se la lettura avviene su un secondario in cui vengono applicati i batch di replica. La lettura da uno snapshot garantisce una visualizzazione coerente dei dati e consente la lettura simultanea con la replica in corso senza la necessità di un blocco.
Pertanto, le letture secondarie che richiedono questi livelli di preoccupazione di lettura non devono più attendere l'applicazione dei batch di replica e possono essere gestite non appena vengono ricevute.
Come creare un set di repliche MongoDB
Come accennato in precedenza, MongoDB gestisce la replica tramite set di repliche. Nelle prossime sezioni, evidenzieremo alcuni metodi che puoi utilizzare per creare set di repliche per il tuo caso d'uso.
Metodo 1: creazione di un nuovo set di repliche MongoDB su Ubuntu
Prima di iniziare, devi assicurarti di avere almeno tre server che eseguono Ubuntu 20.04, con MongoDB installato su ciascun server.
Per configurare un set di repliche, è essenziale fornire un indirizzo in cui ogni membro del set di repliche possa essere raggiunto da altri membri del set. In questo caso, manteniamo tre membri nell'insieme. Anche se possiamo utilizzare gli indirizzi IP, non è consigliabile in quanto gli indirizzi potrebbero cambiare in modo imprevisto. Un'alternativa migliore può essere l'utilizzo dei nomi host DNS logici durante la configurazione dei set di repliche.
Possiamo farlo configurando il sottodominio per ogni membro di replica. Anche se questo può essere l'ideale per un ambiente di produzione, questa sezione illustrerà come configurare la risoluzione DNS modificando i file dei rispettivi host di ciascun server. Questo file ci consente di assegnare nomi host leggibili a indirizzi IP numerici. Pertanto, se in ogni caso il tuo indirizzo IP cambia, tutto ciò che devi fare è aggiornare i file degli host sui tre server piuttosto che riconfigurare la replica impostata da zero!
Principalmente, hosts è memorizzato nella directory /etc/ . Ripeti i comandi seguenti per ciascuno dei tuoi tre server:
sudo nano /etc/hostsNel comando precedente, stiamo usando nano come editor di testo, tuttavia puoi utilizzare qualsiasi editor di testo che preferisci. Dopo le prime righe che configurano il localhost, aggiungi una voce per ogni membro del set di repliche. Queste voci assumono la forma di un indirizzo IP seguito dal nome leggibile dall'uomo di tua scelta. Mentre puoi nominarli come preferisci, assicurati di essere descrittivo in modo da sapere distinguere tra ogni membro. Per questo tutorial, utilizzeremo i seguenti nomi host:
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
Usando questi nomi host, i tuoi file /etc/hosts sarebbero simili alle seguenti righe evidenziate:

Salva e chiudi il file.
Dopo aver configurato la risoluzione DNS per il set di repliche, è necessario aggiornare le regole del firewall per consentire loro di comunicare tra loro. Esegui il seguente comando ufw su mongo0 per fornire l'accesso mongo1 alla porta 27017 su mongo0:
sudo ufw allow from mongo1_server_ip to any port 27017 Al posto del parametro mongo1_server_ip , inserisci l'effettivo indirizzo IP del tuo server mongo1. Inoltre, se hai aggiornato l'istanza Mongo su questo server per utilizzare una porta non predefinita, assicurati di modificare 27017 per riflettere la porta utilizzata dall'istanza MongoDB.
Ora aggiungi un'altra regola del firewall per dare a mongo2 l'accesso alla stessa porta:
sudo ufw allow from mongo2_server_ip to any port 27017 Al posto del parametro mongo2_server_ip , inserisci l'effettivo indirizzo IP del tuo server mongo2. Quindi, aggiorna le regole del firewall per gli altri due server. Esegui i seguenti comandi sul server mongo1, assicurandoti di modificare gli indirizzi IP al posto del parametro server_ip per riflettere rispettivamente quelli di mongo0 e mongo2:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017Infine, esegui questi due comandi su mongo2. Ancora una volta, assicurati di inserire gli indirizzi IP corretti per ciascun server:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017Il passaggio successivo consiste nell'aggiornare il file di configurazione di ogni istanza MongoDB per consentire le connessioni esterne. Per consentire ciò, è necessario modificare il file di configurazione in ogni server per riflettere l'indirizzo IP e indicare il set di repliche. Sebbene sia possibile utilizzare qualsiasi editor di testo preferito, stiamo utilizzando ancora una volta l'editor di testo nano. Apportiamo le seguenti modifiche in ciascun file mongod.conf.
Su mongo0:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"Su mongo1:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"Su mongo2:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodCon questo, hai abilitato la replica per l'istanza MongoDB di ogni server.
È ora possibile inizializzare il set di repliche utilizzando il metodo rs.initiate() . Questo metodo deve essere eseguito solo su una singola istanza MongoDB nel set di repliche. Assicurarsi che il nome e il membro del set di repliche corrispondano alle configurazioni effettuate in precedenza in ciascun file di configurazione.
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })Se il metodo restituisce "ok": 1 nell'output, significa che il set di repliche è stato avviato correttamente. Di seguito è riportato un esempio di come dovrebbe apparire l'output:
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }Spegni il server MongoDB
Puoi arrestare un server MongoDB utilizzando il metodo db.shutdownServer() . Di seguito è riportata la sintassi per lo stesso. Sia force che timeoutsecs sono parametri facoltativi.
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) Questo metodo potrebbe non riuscire se il membro del set di repliche mongod esegue determinate operazioni durante la compilazione dell'indice. Per interrompere le operazioni e forzare l'arresto del membro, è possibile inserire il parametro booleano force su true.
Riavvia MongoDB con –replSet
Per reimpostare la configurazione, assicurati che ogni nodo nel set di repliche sia arrestato. Quindi eliminare il database locale per ogni nodo. Avvialo di nuovo utilizzando il flag –replSet ed esegui rs.initiate() su una sola istanza mongod per il set di repliche.
mongod --replSet "rs0" rs.initiate() può accettare un documento di configurazione del set di repliche facoltativo, vale a dire:

- L'opzione
Replication.replSetNameo—replSetper specificare il nome della serie di repliche nel campo_id. - La matrice dei membri, che contiene un documento per ogni membro del set di repliche.
Il metodo rs.initiate() attiva un'elezione ed elegge uno dei membri come primario.
Aggiungi membri al set di repliche
Per aggiungere membri all'insieme, avvia le istanze mongod su varie macchine. Successivamente, avvia un client mongo e usa il comando rs.add() .
Il comando rs.add() ha la seguente sintassi di base:
rs.add(HOST_NAME:PORT)Per esempio,
Supponiamo che mongo1 sia la tua istanza mongod e sia in ascolto sulla porta 27017. Usa il comando client Mongo rs.add() per aggiungere questa istanza al set di repliche.
rs.add("mongo1:27017") Solo dopo esserti connesso al nodo primario puoi aggiungere un'istanza mongod al set di repliche. Per verificare se sei connesso al primario, usa il comando db.isMaster() .
Rimuovi utenti
Per rimuovere un membro, possiamo usare rs.remove()
Per fare ciò, in primo luogo, chiudi l'istanza mongod che desideri rimuovere utilizzando il metodo db.shutdownServer() di cui abbiamo discusso in precedenza.
Successivamente, connettiti al primario corrente del set di repliche. Per determinare il primario corrente, utilizzare db.hello() durante la connessione a qualsiasi membro del set di repliche. Dopo aver determinato il primario, esegui uno dei seguenti comandi:
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 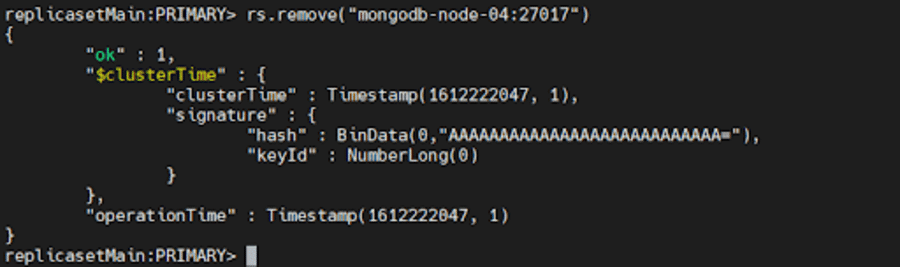
Se il set di repliche deve eleggere un nuovo primario, MongoDB potrebbe disconnettere brevemente la shell. In questo scenario, si ricollegherà automaticamente ancora una volta. Inoltre, potrebbe visualizzare un errore DBClientCursor::init call() non riuscito anche se il comando ha esito positivo.
Metodo 2: configurazione di un set di repliche MongoDB per la distribuzione e il test
In generale, puoi configurare set di repliche per il test con RBAC abilitato o disabilitato. In questo metodo, configureremo i set di repliche con il controllo di accesso disabilitato per la distribuzione in un ambiente di test.
Innanzitutto, crea le directory per tutte le istanze che fanno parte del set di repliche utilizzando il seguente comando:
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2Questo comando creerà directory per tre istanze MongoDB replicaset0-0, replicaset0-1 e replicaset0-2. Ora, avvia le istanze MongoDB per ciascuna di esse utilizzando il seguente set di comandi:
Per Server 1:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Per Server 2:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Per server 3:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 Il parametro –oplogSize viene utilizzato per evitare che la macchina venga sovraccaricata durante la fase di test. Aiuta a ridurre la quantità di spazio su disco consumato da ciascun disco.
Ora, connettiti a una delle istanze utilizzando la shell Mongo connettendoti utilizzando il numero di porta di seguito.
mongo --port 27017 Possiamo usare il comando rs.initiate() per avviare il processo di replica. Dovrai sostituire il parametro hostname con il nome del tuo sistema.
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }È ora possibile passare il file dell'oggetto di configurazione come parametro per il comando di inizializzazione e utilizzarlo come segue:
rs.initiate(rsconf)E il gioco è fatto! Hai creato correttamente un set di repliche MongoDB per scopi di sviluppo e test.
Metodo 3: trasformazione di un'istanza autonoma in un set di repliche MongoDB
MongoDB consente ai suoi utenti di trasformare le loro istanze autonome in set di repliche. Mentre le istanze autonome vengono utilizzate principalmente per la fase di test e sviluppo, i set di repliche fanno parte dell'ambiente di produzione.
Per iniziare, chiudiamo la nostra istanza mongod utilizzando il seguente comando:
db.adminCommand({"shutdown":"1"}) Riavvia l'istanza utilizzando il parametro –repelSet nel comando per specificare il set di repliche che intendi utilizzare:
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>È necessario specificare il nome del server insieme all'indirizzo univoco nel comando.
Connetti la shell con la tua istanza MongoDB e usa il comando initial per avviare il processo di replica e convertire correttamente l'istanza in un set di repliche. Puoi eseguire tutte le operazioni di base come l'aggiunta o la rimozione di un'istanza utilizzando i seguenti comandi:
rs.add(“<host_name:port>”) rs.remove(“host-name”) Inoltre, puoi controllare lo stato del set di repliche MongoDB utilizzando i comandi rs.status() e rs.conf() .
Metodo 4: MongoDB Atlas: un'alternativa più semplice
La replica e lo sharding possono lavorare insieme per formare qualcosa chiamato cluster sharded. Sebbene l'installazione e la configurazione possano richiedere molto tempo, anche se semplici, MongoDB Atlas è un'alternativa migliore rispetto ai metodi menzionati in precedenza.
Automatizza i set di repliche, semplificando l'implementazione del processo. Può distribuire set di repliche partizionate a livello globale con pochi clic, consentendo il ripristino di emergenza, una gestione più semplice, la località dei dati e le distribuzioni in più regioni.
In MongoDB Atlas, dobbiamo creare cluster: possono essere un set di repliche o un cluster frammentato. Per un particolare progetto, il numero di nodi in un cluster in altre regioni è limitato a un totale di 40.
Ciò esclude i cluster gratuiti o condivisi e le regioni cloud di Google che comunicano tra loro. Il numero totale di nodi tra due regioni qualsiasi deve soddisfare questo vincolo. Ad esempio, se c'è un progetto in cui:
- La regione A ha 15 nodi.
- La regione B ha 25 nodi
- La regione C ha 10 nodi
Possiamo allocare solo altri 5 nodi alla regione C come,
- Regione A+ Regione B = 40; soddisfa il vincolo di 40 che è il numero massimo di nodi consentiti.
- Regione B+ Regione C = 25+10+5 (nodi aggiuntivi assegnati a C) = 40; soddisfa il vincolo di 40 che è il numero massimo di nodi consentiti.
- Regione A+ Regione C =15+10+5 (nodi aggiuntivi assegnati a C) = 30; soddisfa il vincolo di 40 che è il numero massimo di nodi consentiti.
Se abbiamo assegnato altri 10 nodi alla regione C, facendo in modo che la regione C abbia 20 nodi, allora Regione B + Regione C = 45 nodi. Ciò supererebbe il vincolo specificato, quindi potresti non essere in grado di creare un cluster multi-regione.
Quando crei un cluster, Atlas crea un contenitore di rete nel progetto per il provider cloud se non era presente in precedenza. Per creare un cluster di serie di repliche in MongoDB Atlas, esegui il seguente comando in Atlas CLI:
atlas clusters create [name] [options]Assicurati di fornire un nome di cluster descrittivo, poiché non può essere modificato dopo la creazione del cluster. L'argomento può contenere lettere ASCII, numeri e trattini.
Sono disponibili diverse opzioni per la creazione di cluster in MongoDB in base alle tue esigenze. Ad esempio, se desideri un backup cloud continuo per il tuo cluster, imposta --backup su true.
Gestione del ritardo di replica
Il ritardo della replica può essere piuttosto scoraggiante. È un ritardo tra un'operazione sul primario e l'applicazione di tale operazione dall'oplog al secondario. Se la tua azienda si occupa di set di dati di grandi dimensioni, è previsto un ritardo entro una certa soglia. Tuttavia, a volte anche fattori esterni potrebbero contribuire e aumentare il ritardo. Per beneficiare di una replica aggiornata, assicurati che:
- Instradi il tuo traffico di rete in una larghezza di banda stabile e sufficiente. La latenza di rete svolge un ruolo enorme nell'influenzare la replica e, se la rete non è sufficiente per soddisfare le esigenze del processo di replica, si verificheranno ritardi nella replica dei dati in tutto il set di repliche.
- Si dispone di una velocità effettiva del disco sufficiente. Se il file system e il dispositivo disco sul secondario non sono in grado di scaricare i dati sul disco con la stessa rapidità del primario, il secondario avrà difficoltà a tenere il passo. Pertanto, i nodi secondari elaborano le query di scrittura più lentamente del nodo primario. Questo è un problema comune nella maggior parte dei sistemi multi-tenant, incluse le istanze virtualizzate e le distribuzioni su larga scala.
- Si richiede un problema di scrittura di riconoscimento della scrittura dopo un intervallo per fornire l'opportunità ai secondari di raggiungere il primario, in particolare quando si desidera eseguire un'operazione di caricamento in blocco o l'inserimento di dati che richiede un numero elevato di scritture sul primario. I secondari non saranno in grado di leggere l'oplog abbastanza velocemente da tenere il passo con i cambiamenti; in particolare con problemi di scrittura non riconosciuti.
- Identifichi le attività in background in esecuzione. Alcune attività come cron job, aggiornamenti del server e controlli di sicurezza potrebbero avere effetti imprevisti sulla rete o sull'utilizzo del disco, causando ritardi nel processo di replica.
Se non sei sicuro che ci sia un ritardo di replica nella tua applicazione, non preoccuparti: la sezione successiva discute le strategie di risoluzione dei problemi!
Risoluzione dei problemi relativi ai set di repliche di MongoDB
Hai configurato correttamente i tuoi set di repliche, ma noti che i tuoi dati non sono coerenti tra i server. Questo è molto allarmante per le aziende su larga scala, tuttavia, con metodi rapidi di risoluzione dei problemi, potresti trovare la causa o addirittura correggere il problema! Di seguito sono riportate alcune strategie comuni per la risoluzione dei problemi relativi alle distribuzioni di set di repliche che potrebbero rivelarsi utili:
Controlla lo stato della replica
Possiamo controllare lo stato corrente del set di repliche e lo stato di ciascun membro eseguendo il seguente comando in una sessione mongosh connessa al primario di un set di repliche.
rs.status()Controlla il ritardo di replica
Come discusso in precedenza, il ritardo di replica può essere un problema serio in quanto rende i membri "ritardati" non idonei a diventare rapidamente primari e aumenta la possibilità che le operazioni di lettura distribuite siano incoerenti. Possiamo verificare la lunghezza corrente del registro di replica utilizzando il seguente comando:
rs.printSecondaryReplicationInfo() Questo restituisce il valore syncedTo che è l'ora in cui l'ultima voce oplog è stata scritta nel secondario per ogni membro. Ecco un esempio per dimostrare lo stesso:
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary Un membro ritardato può essere visualizzato come 0 secondi indietro rispetto al primario quando il periodo di inattività sul primario è maggiore del valore members[n].secondaryDelaySecs .
Testare le connessioni tra tutti i membri
Ogni membro di un set di repliche deve essere in grado di connettersi con ogni altro membro. Assicurarsi sempre di verificare i collegamenti in entrambe le direzioni. Principalmente, le configurazioni del firewall o le topologie di rete impediscono la connettività normale e richiesta che può bloccare la replica.
Ad esempio, supponiamo che l'istanza mongod si colleghi sia a localhost che a hostname 'ExampleHostname' che è associato all'indirizzo IP 198.41.110.1:
mongod --bind_ip localhost, ExampleHostnamePer connettersi a questa istanza, i client remoti devono specificare il nome host o l'indirizzo IP:
mongosh --host ExampleHostname mongosh --host 198.41.110.1Se un set di repliche è composto da tre membri, m1, m2 e m3, utilizzando la porta predefinita 27017, è necessario testare la connessione come di seguito:
Su m1:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017Su m2:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017Su m3:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 Se una qualsiasi connessione in qualsiasi direzione fallisce, dovresti controllare la configurazione del tuo firewall e riconfigurarla per consentire le connessioni.
Garantire comunicazioni sicure con l'autenticazione del file di chiavi
Per impostazione predefinita, l'autenticazione del file di chiavi in MongoDB si basa sul meccanismo di autenticazione della risposta alla sfida salata (SCRAM). Per fare ciò, MongoDB deve leggere e convalidare le credenziali fornite dall'utente che includono una combinazione di nome utente, password e database di autenticazione di cui l'istanza MongoDB specifica è a conoscenza. Questo è l'esatto meccanismo utilizzato per autenticare gli utenti che forniscono una password durante la connessione al database.
Quando abiliti l'autenticazione in MongoDB, il controllo degli accessi in base al ruolo (RBAC) viene abilitato automaticamente per il set di repliche e all'utente vengono concessi uno o più ruoli che ne determinano l'accesso alle risorse del database. Quando RBAC è abilitato, significa che solo l'utente Mongo autenticato valido con i privilegi appropriati sarà in grado di accedere alle risorse sul sistema.
Il file di chiavi agisce come una password condivisa per ogni membro del cluster. Ciò consente a ogni istanza mongod nel set di repliche di utilizzare il contenuto del file di chiavi come password condivisa per l'autenticazione di altri membri nella distribuzione.
Solo le istanze mongod con il file di chiavi corretto possono unirsi al set di repliche. La lunghezza di una chiave deve essere compresa tra 6 e 1024 caratteri e può contenere solo caratteri nel set base64. Tieni presente che MongoDB rimuove i caratteri degli spazi bianchi durante la lettura delle chiavi.
È possibile generare un file di chiavi utilizzando vari metodi. In questo tutorial, utilizziamo openssl per generare una stringa complessa di 1024 caratteri casuali da utilizzare come password condivisa. It then uses chmod to change file permissions to provide read permissions for the file owner only. Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. Per esempio:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
And voila! You have successfully enabled keyfile authentication!
Riepilogo
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!