
Cosa fare in caso di infezione da SEO Spam su WordPress
Pubblicato: 2021-05-17In Jetpack, affrontare diversi tipi di minacce e attacchi Web fa parte della nostra routine. Nella maggior parte dei casi, si va dalla raccolta di un file dannoso e alla ricerca del vettore di attacco, alla fornitura di assistenza per il ripristino di un sito Web dall'ultimo backup. Ma a volte entriamo in una dimensione diversa di attacchi davvero creativi, una dimensione di reinfezioni inspiegabili — entriamo... nella zona crepuscolare.
Ok, probabilmente sarò troppo drammatico, ma abbi pazienza mentre preparo la scena per questo racconto misterioso. Pronto? Per favore, unisciti a me in questo viaggio nel regno dei fantasmi, dello spam e dei motori di ricerca.
Il comportamento dannoso
Abbiamo trovato un sito web che era oggetto di un tipo di attacco molto interessante. È emersa per la prima volta come un'e-mail inviata da Google Search Console: un URL non comune (e dall'aspetto molto sospetto, con un URL selezionabile all'interno) è stato elencato come una pagina in crescita.
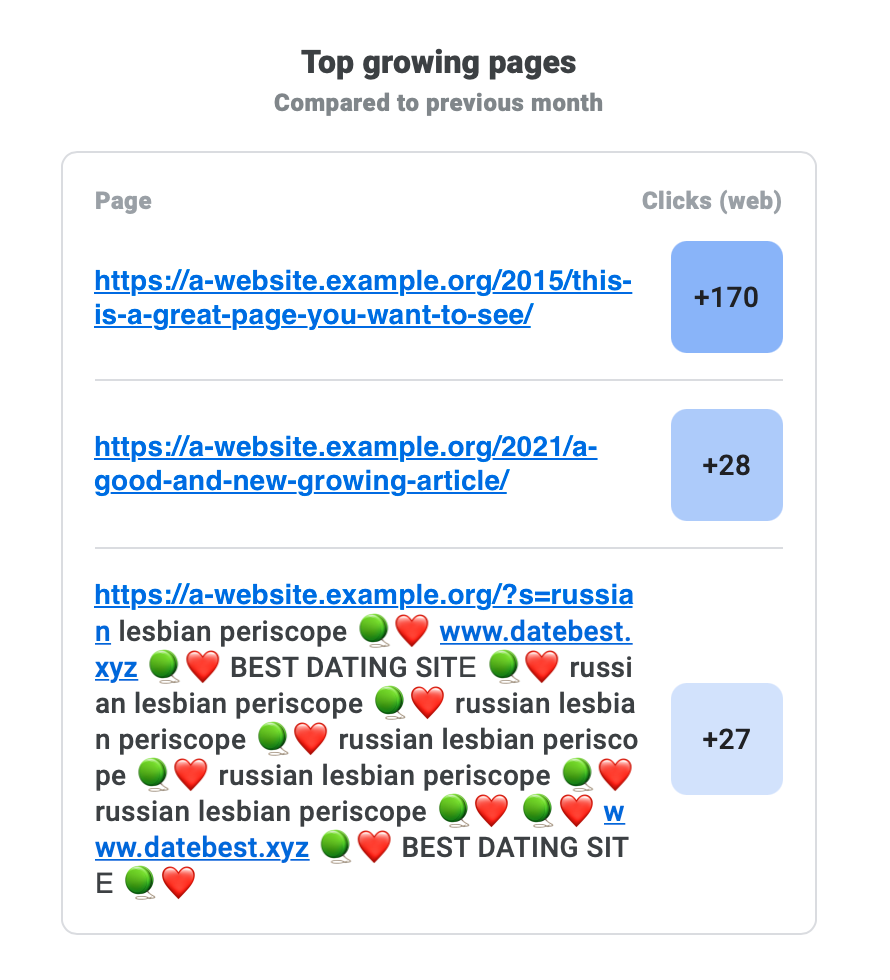
Il proprietario del sito web era un po' sconvolto poiché un comportamento come questo è spesso il risultato di un'infezione, ma Jetpack non li ha rilevati o avvertiti di nulla. Inoltre, queste pagine non esistevano nemmeno sul sito Web al momento del controllo, ma venivano comunque indicizzate da Google. La zona crepuscolare si intensifica .
Quando abbiamo verificato la presenza di file sospetti che Jetpack Scan potrebbe aver perso (nessuno strumento di sicurezza rileva il 100% delle minacce), le cose sono diventate ancora più strane. Il core di WordPress e i plug-in erano intatti: nessun file o script iniettato nel database. Un paio di plug-in obsoleti non contenevano alcuna correzione di sicurezza, WordPress era una versione indietro (5.6) e l'ultimo aggiornamento non elencava grandi correzioni di sicurezza. Non c'era niente di sospetto. Nessun sospetto abituale, nessuna prova di attacchi; non ancora, comunque.
Il passaggio logico successivo consiste nel controllare i log di accesso. Forse potrebbe far luce su questo mistero. Scopriremmo che stiamo affrontando un attacco zero-day, o che abbiamo finalmente trovato una prova per la teoria del multiverso e questo sito Web è infetto solo nell'Universo #1337? Ai registri!


Come ti aspetteresti: niente di strano, a parte un mucchio di richieste a quelle pagine di spam come puoi vedere negli screenshot. E stavano tutti restituendo un "200 OK". Quindi, la pagina esisteva da qualche parte nel continuum spazio-temporale, oppure... aspetta un secondo... la vedi adesso?
Tutte quelle pagine puntavano alla stessa posizione: `/?s=`, il che significa che i motori di ricerca (il problema è stato notato da Google, ma le richieste provengono da Bing) stavano indicizzando le pagine dei risultati di ricerca. E perché? Il crawler non esegue ricerche sulla pagina, per quanto ne sappiamo, giusto?
Il paradosso dell'indicizzazione
Le basi di come funziona un motore di ricerca sono abbastanza semplici se sei nel business dei siti web. C'è un robot (o script automatizzato) che esegue la scansione delle pagine Web, ne indicizza il contenuto, esegue alcune magie e memorizza le risorse interrogabili da qualche parte nel cloud.
Con questo in mente, abbiamo scavato un po' di più i log per vedere se qualcuna di quelle richieste avesse qualche altro indizio, come un referrer, ma senza fortuna. Tutte le richieste registrate provenivano dai motori di ricerca. Fortunatamente, Google Search Console aveva una delle pagine di riferimento in uno dei registri.
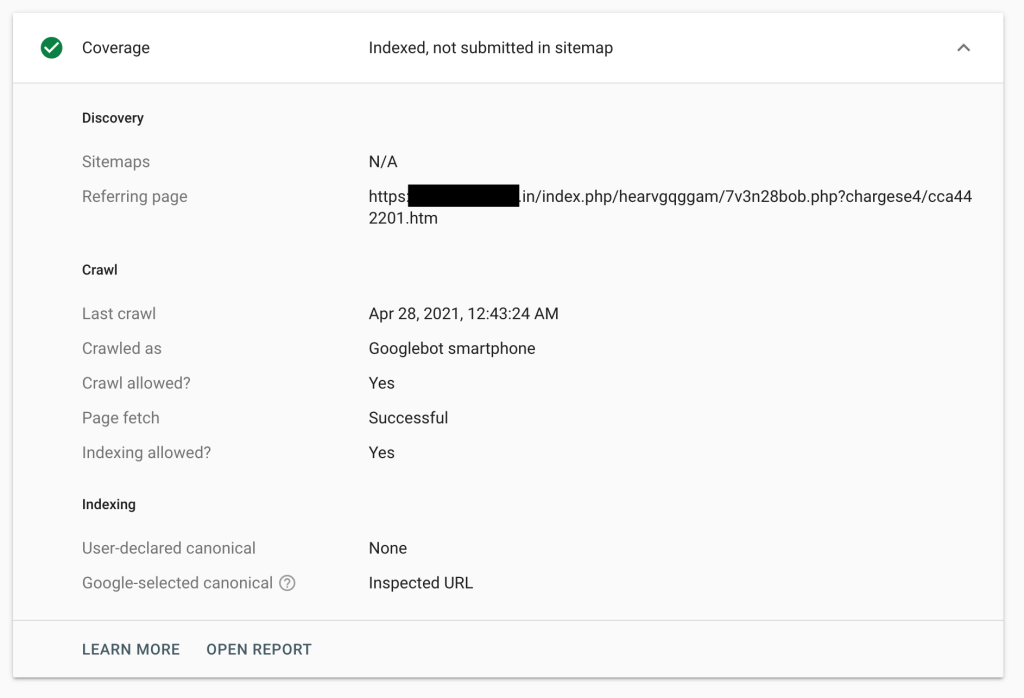
Ora penso che sia giunto il momento di cambiare il nostro cappello Twilight Zone con un cappello CSI e scavare alcune ossa di siti Web da mettere al microscopio.
Per l'occhio allenato, è facile vedere che l'URL della pagina di riferimento apparteneva a un sito Web compromesso; fortunatamente, abbiamo occhi ben allenati! La directory `index.php` non ha senso e probabilmente è stata aggiunta per confondere il proprietario del sito web. Successivamente, è seguita da un'altra directory casuale e da un file PHP con un nome casuale, che è probabilmente un caricatore che sta ottenendo il payload finale: `cargese4/cca442201.htm`, anch'esso casuale. Tutte queste sono caratteristiche di un'infezione da malware link-farm.
Una rapida ricerca su Google per vedere cosa è stato indicizzato per il sito di riferimento ha confermato che era effettivamente infetto e che serviva spam SEO per un po'. Il sito è per un'azienda alimentare in India ma offre offerte sui SUV in Giappone — sì, è spam.
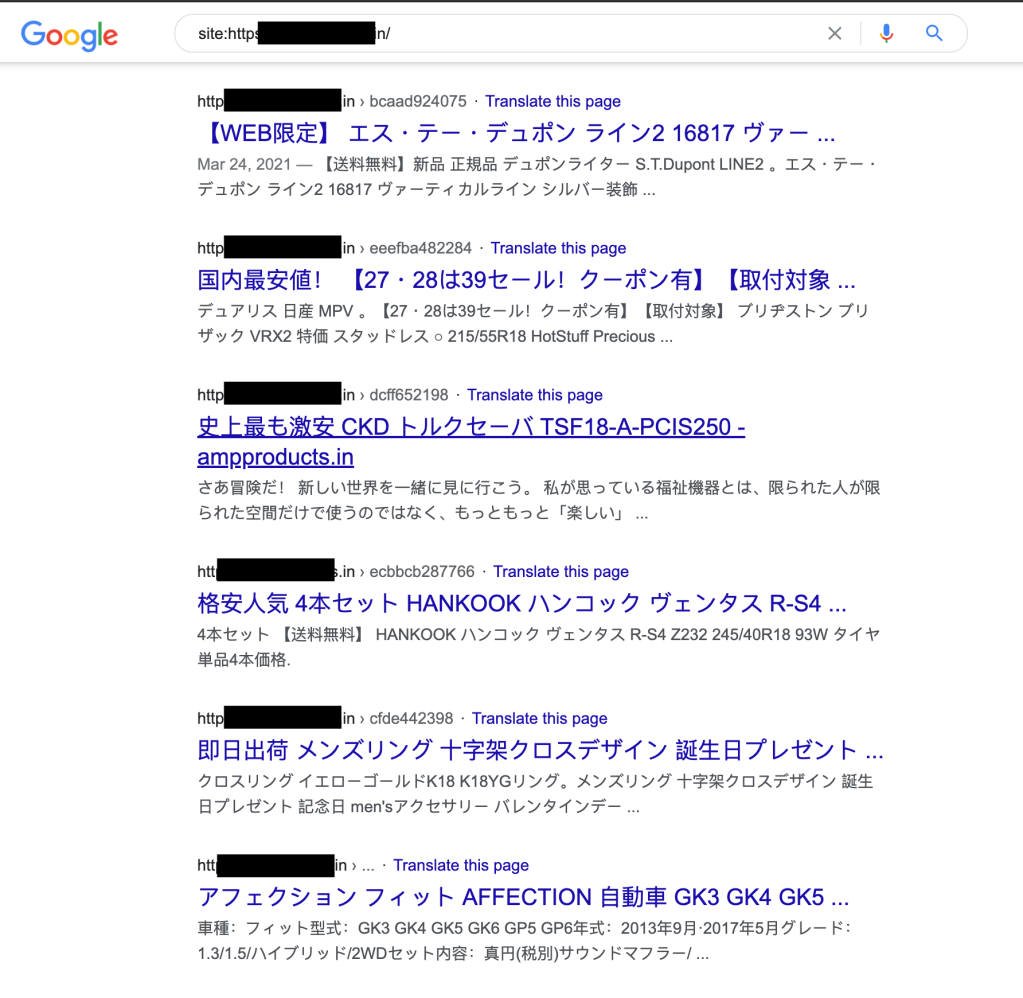
Ma nessuno dei risultati si collegava al sito Web del nostro amico, quindi ho deciso di scoprire se altri siti fossero interessati da questo stesso strano comportamento.

Al fine di cercare più vittime di questo attacco di spam, solo a scopo didattico, abbiamo utilizzato la nostra conoscenza di Google-fu per creare una query di ricerca che restituisse siti che terminano con .edu, che aveva `/?s=` nell'URL, e la parola "acquista" nel titolo. E abbiamo ottenuto 22 risultati. Che è abbastanza per la nostra caccia.

Questa è la prova che il sito segnalato non è stato l'unico colpito; sembra essere un problema più diffuso. Abbiamo riflettuto su cosa avrebbe potuto fare in modo che Google indicizzasse quelle pagine. In che modo Googlebot li ha raggiunti? Passaggio successivo: verifica dei backlink.
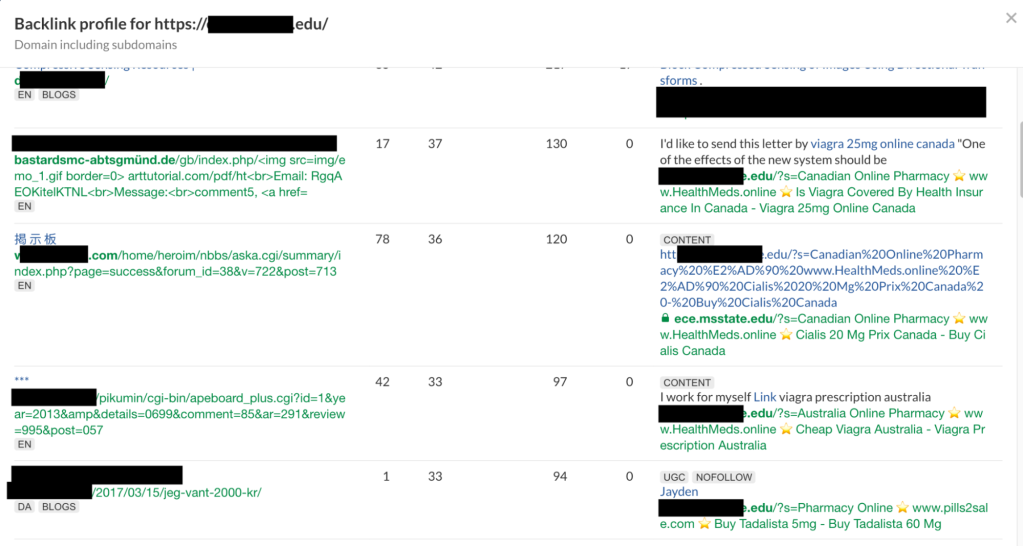
Esistono diversi strumenti online che forniscono report sui backlink a siti Web; quello che abbiamo usato in questa ricerca era Ahrefs, ma altri strumenti potrebbero raggiungere gli stessi risultati. Alcune delle pagine di ricerca dannose sono elencate nei risultati, a conferma che eravamo sulla strada giusta.
Selezionando uno di quei siti Web per controllare cosa stava succedendo, abbiamo visto quasi 5.000 commenti di spam, come puoi vedere nella schermata successiva (dovrebbero controllare Jetpack Anti-spam). Ogni commento si collegava a una pagina di ricerca del sito Web con spam nella query.
Catturare il coniglio bianco
Come accennato in precedenza, i robot dei motori di ricerca non eseguono query sulle pagine dei siti Web. Ma, se trova un collegamento ad esso, verrà seguito. E se la pagina non dice allo script automatico che una particolare pagina non è indicizzabile, la aggiungerà.

Questo è un metodo intelligente per "iniettare" spam in un sito Web per spammare i risultati dei motori di ricerca e aumentare il page rank del sito attraverso l'agricoltura di link a basso sforzo.
Ora che abbiamo capito il problema, come possiamo dire ai bot dei motori di ricerca di evitare di seguire i link alle pagine di ricerca (o semplicemente di rifiutarsi di indicizzarli)? Il modo migliore sarebbe apportare una modifica a WordPress Core, che aiuterebbe a proteggere l'intera comunità (se vuoi segnalare un bug o vuoi contribuire con il codice, unisciti a noi).
Per evitare rielaborazioni non necessarie, abbiamo controllato la traccia Core di WordPress e abbiamo riscontrato questo problema che è stato risolto nella versione 5.7 ma sfortunatamente non è arrivato al registro delle modifiche come problema di sicurezza.
Citerò l'autore, che ha descritto il problema meglio di me (grazie abagtcs per il rapporto):
Gli spammer web hanno iniziato ad abusare delle funzionalità di ricerca di quei siti passando in termini di spam e nomi host nella speranza di aumentare le classifiche di ricerca dei siti degli spammer.
Gli spammer inseriscono questi collegamenti in wiki aperti, commenti di blog, forum e altre link farm, basandosi sui motori di ricerca che scansionano i loro collegamenti e quindi visitano e indicizzano le pagine dei risultati di ricerca risultanti con contenuto di spam.
Questo attacco è sorprendentemente abbastanza diffuso, colpendo molti siti web in tutto il mondo. Sebbene alcuni CMS e siti basati su codice personalizzato possano essere vulnerabili a questa tecnica, sulla base di un'indagine preliminare, sembra che, almeno nello spazio .edu, la piattaforma web più mirata in assoluto sia WordPress.
Ciò non sorprende quando oltre il 41% dei più grandi siti sul Web sono siti WordPress.
Chiusura del caso
Ci sono alcune buone lezioni da trarre da questo incidente:
- L'URL presentato sulle pagine in crescita più frequenti non è ben disinfettato, quindi gli URL di spam che vedi separati da emoji sono in realtà selezionabili direttamente (ciao amici di Google, questo è su di voi); gli utenti ignari potrebbero fare clic su di essi e accedere a contenuti indesiderati.
- Alcuni ritocchi sono necessari da parte di Google per evitare l'indicizzazione di pagine chiaramente spam. Sulla base del rapporto dello strumento, alcune pagine chiare sono state scansionate e non indicizzate, mentre è stato aggiunto lo spam.
- Gli aggressori sfrutteranno anche la più piccola apertura sul tuo sistema e dobbiamo essere sempre vigili.
- Ascolta sempre le persone e capisci i loro problemi. Se controllassimo i log solo dai nostri strumenti, non saremmo a conoscenza di questo problema o non saremmo in grado di aiutare a riparare il loro sito.
- Mantieni aggiornato il tuo software. Sempre.
In Jetpack, lavoriamo sodo per assicurarci che i tuoi siti Web siano protetti da questo tipo di vulnerabilità. Per essere un passo avanti a qualsiasi nuova minaccia, dai un'occhiata a Jetpack Scan, che include la scansione della sicurezza e la rimozione automatizzata del malware.
E una punta di cappello a Erin Casali per aver evidenziato questo problema e aver aiutato con le indagini.