
Il file robots.txt di WordPress... Che cos'è e cosa fa
Pubblicato: 2020-11-25Ti sei mai chiesto cos'è il file robots.txt e cosa fa? Robots.txt viene utilizzato per comunicare con i web crawler (noti come bot) utilizzati da Google e altri motori di ricerca. Dice loro quali parti del tuo sito web indicizzare e quali ignorare. In quanto tale, il file robots.txt può aiutare a rendere (o potenzialmente distruggere!) i tuoi sforzi SEO. Se vuoi che il tuo sito web si classifichi bene, una buona conoscenza di robots.txt è essenziale!
Dove si trova Robots.txt?
WordPress in genere esegue un cosiddetto file robots.txt "virtuale", il che significa che non è accessibile tramite SFTP. Puoi comunque visualizzarne i contenuti di base andando su tuodominio.com/robots.txt. Probabilmente vedrai qualcosa del genere:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpLa prima riga specifica a quali bot si applicheranno le regole. Nel nostro esempio, l'asterisco significa che le regole verranno applicate a tutti i bot (es. quelli di Google, Bing e così via).
La seconda riga definisce una regola che impedisce l'accesso dei bot alla cartella /wp-admin e la terza riga afferma che i bot possono analizzare il file /wp-admin/admin-ajax.php.
Aggiungi le tue regole
Per un semplice sito Web WordPress, le regole predefinite applicate da WordPress al file robots.txt potrebbero essere più che adeguate. Se tuttavia desideri un maggiore controllo e la possibilità di aggiungere le tue regole per fornire istruzioni più specifiche ai bot dei motori di ricerca su come indicizzare il tuo sito web, dovrai creare il tuo file robots.txt fisico e metterlo sotto la radice directory della tua installazione.
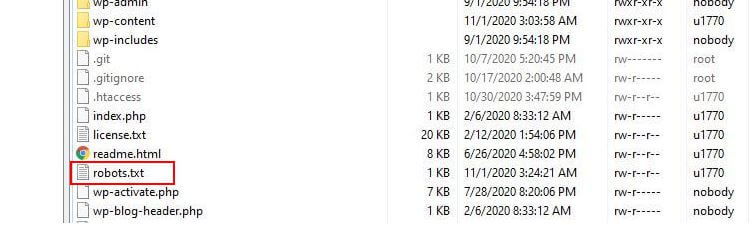
Ci sono diversi motivi per cui potresti voler riconfigurare il tuo file robots.txt e definire esattamente quali bot potranno scansionare esattamente. Uno dei motivi principali è a che fare con il tempo trascorso da un bot che esegue la scansione del tuo sito. Google (e altri) non consentono ai bot di trascorrere un tempo illimitato su ogni sito Web... con trilioni di pagine devono adottare un approccio più sfumato a ciò che i loro robot eseguiranno la scansione e ciò che ignoreranno nel tentativo di estrarre le informazioni più utili su un sito web.

Ospita il tuo sito web con Pressidium
GARANZIA DI RIMBORSO DI 60 GIORNI
Quando consenti ai bot di eseguire la scansione di tutte le pagine del tuo sito Web, una parte del tempo di scansione viene spesa su pagine che non sono importanti o addirittura pertinenti. Questo lascia loro meno tempo per farsi strada attraverso le aree più rilevanti del tuo sito. Non consentendo l'accesso del bot ad alcune parti del tuo sito web, aumenti il tempo a disposizione dei bot per estrarre informazioni dalle parti più rilevanti del tuo sito (che si spera finiranno per essere indicizzate). Poiché la scansione è più veloce, è più probabile che Google visiti nuovamente il tuo sito Web e mantenga aggiornato l'indice del tuo sito. Ciò significa che è probabile che i nuovi post del blog e altri nuovi contenuti vengano indicizzati più velocemente, il che è una buona notizia.
Esempi di modifica di Robots.txt
Il robots.txt offre molto spazio per la personalizzazione. Pertanto, abbiamo fornito una serie di esempi di regole che possono essere utilizzate per determinare il modo in cui i bot indicizzano il tuo sito.
Consentire o disabilitare i bot
Per prima cosa, diamo un'occhiata a come possiamo limitare un bot specifico. Per fare ciò non dobbiamo far altro che sostituire l'asterisco (*) con il nome dello user-agent bot che vogliamo bloccare, ad esempio 'MSNBot'. Un elenco completo di agenti utente noti è disponibile qui.
User-agent: MSNBot Disallow: /Mettere un trattino nella seconda riga limiterà l'accesso del bot a tutte le directory.
Per consentire a un solo bot di eseguire la scansione del nostro sito, utilizzeremo un processo in 2 passaggi. Per prima cosa impostiamo questo bot come eccezione e quindi disabilitamo tutti i bot in questo modo:
User-agent: Google Disallow: User-agent: * Disallow: /Per consentire l'accesso a tutti i bot su tutti i contenuti aggiungiamo queste due righe:
User-agent: * Disallow:Lo stesso effetto si otterrebbe semplicemente creando un file robots.txt e poi lasciandolo vuoto.
Blocco dell'accesso a file specifici
Vuoi impedire ai bot di indicizzare determinati file sul tuo sito web? Questo è facile! Nell'esempio seguente abbiamo impedito ai motori di ricerca di accedere a tutti i file .pdf sul nostro sito web.
User-agent: * Disallow: /*.pdf$Il simbolo "$" viene utilizzato per definire la fine dell'URL. Poiché fa distinzione tra maiuscole e minuscole, un file con nome my.PDF verrà comunque sottoposto a scansione (notare le maiuscole).
Espressioni logiche complesse
Alcuni motori di ricerca, come Google, comprendono l'uso di espressioni regolari più complicate. È importante notare, tuttavia, che non tutti i motori di ricerca potrebbero essere in grado di comprendere le espressioni logiche in robots.txt.

Un esempio è l'utilizzo del simbolo $. Nei file robots.txt questo simbolo indica la fine di un URL. Quindi, nell'esempio seguente abbiamo bloccato i robot di ricerca dalla lettura e dall'indicizzazione dei file che terminano con .php
Disallow: /*.php$Ciò significa che /index.php non può essere indicizzato, ma /index.php?p=1 potrebbe esserlo. Questo è utile solo in circostanze molto specifiche e deve essere usato con cautela o corri il rischio di bloccare l'accesso del bot a file che non volevi!
Puoi anche impostare regole diverse per ciascun bot specificando le regole che si applicano a ciascuno di essi individualmente. Il codice di esempio seguente limiterà l'accesso alla cartella wp-admin per tutti i bot, bloccando allo stesso tempo l'accesso all'intero sito per il motore di ricerca Bing. Non vorresti necessariamente farlo, ma è un'utile dimostrazione di quanto possano essere flessibili le regole in un file robots.txt.
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /Sitemap XML
Le Sitemap XML aiutano davvero i robot di ricerca a comprendere il layout del tuo sito web. Ma per essere utile, il bot deve sapere dove si trova la mappa del sito. La "direttiva Sitemap" viene utilizzata per indicare specificamente ai motori di ricerca che a) esiste una mappa del sito del tuo sito eb) dove possono trovarla.
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:Puoi anche specificare più posizioni della mappa del sito:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* DisallowRitardi della scansione dei bot
Un'altra funzione che può essere ottenuta tramite il file robots.txt è dire ai bot di "rallentare" la scansione del tuo sito. Questo potrebbe essere necessario se scopri che il tuo server è sovraccaricato da alti livelli di traffico del bot. Per fare ciò, devi specificare l'agente utente che desideri rallentare e quindi aggiungere un ritardo.
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10Le virgolette numeriche (10) in questo esempio sono il ritardo che vuoi che si verifichi tra la scansione delle singole pagine del tuo sito. Quindi, nell'esempio sopra abbiamo chiesto al Bing Bot di fare una pausa di dieci secondi tra ogni pagina che esegue la scansione e, così facendo, dare al nostro server un po' di respiro.
L'unica notizia leggermente negativa su questa particolare regola robots.txt è che il bot di Google non la rispetta. Puoi tuttavia istruire i loro bot a rallentare dall'interno di Google Search Console.
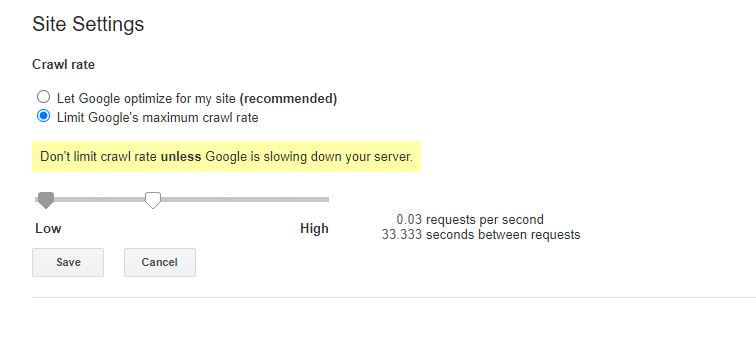
Note sulle regole robots.txt:
- Tutte le regole di robots.txt fanno distinzione tra maiuscole e minuscole. Digita con attenzione!
- Assicurati che non esistano spazi prima del comando all'inizio della riga.
- Le modifiche apportate in robots.txt possono richiedere 24-36 ore per essere annotate dai bot.
Come testare e inviare il tuo file robots.txt di WordPress
Dopo aver creato un nuovo file robots.txt vale la pena controllare che non ci siano errori. Puoi farlo utilizzando la Google Search Console.
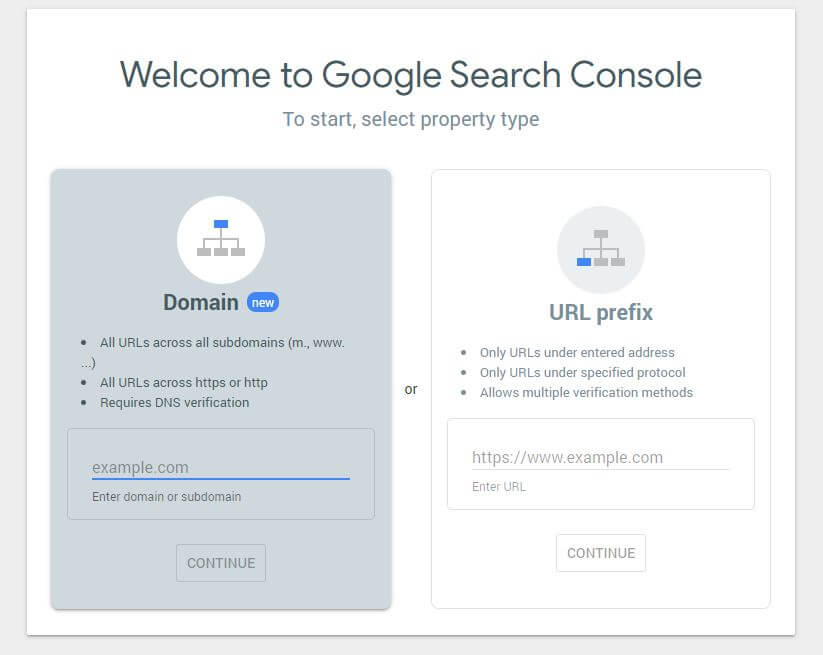
Innanzitutto, dovrai inviare il tuo dominio (se non hai già un account Search Console per la configurazione del tuo sito web). Google ti fornirà un record TXT che deve essere aggiunto al tuo DNS per verificare il tuo dominio.
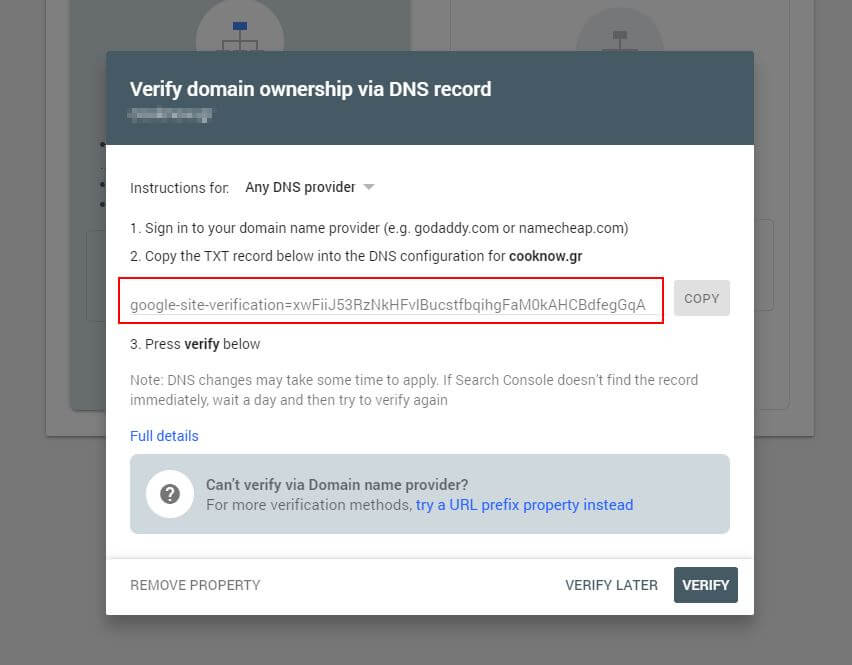
Una volta che questo aggiornamento DNS si è propagato (sensi di impazienza... prova a utilizzare Cloudflare per gestire il tuo DNS) puoi visitare il tester robots.txt e verificare se ci sono avvisi sul contenuto del tuo file robots.txt.
Un'altra cosa che puoi fare per testare le regole che hai in atto stanno avendo l'effetto desiderato è usare uno strumento di test robots.txt come Ryte.
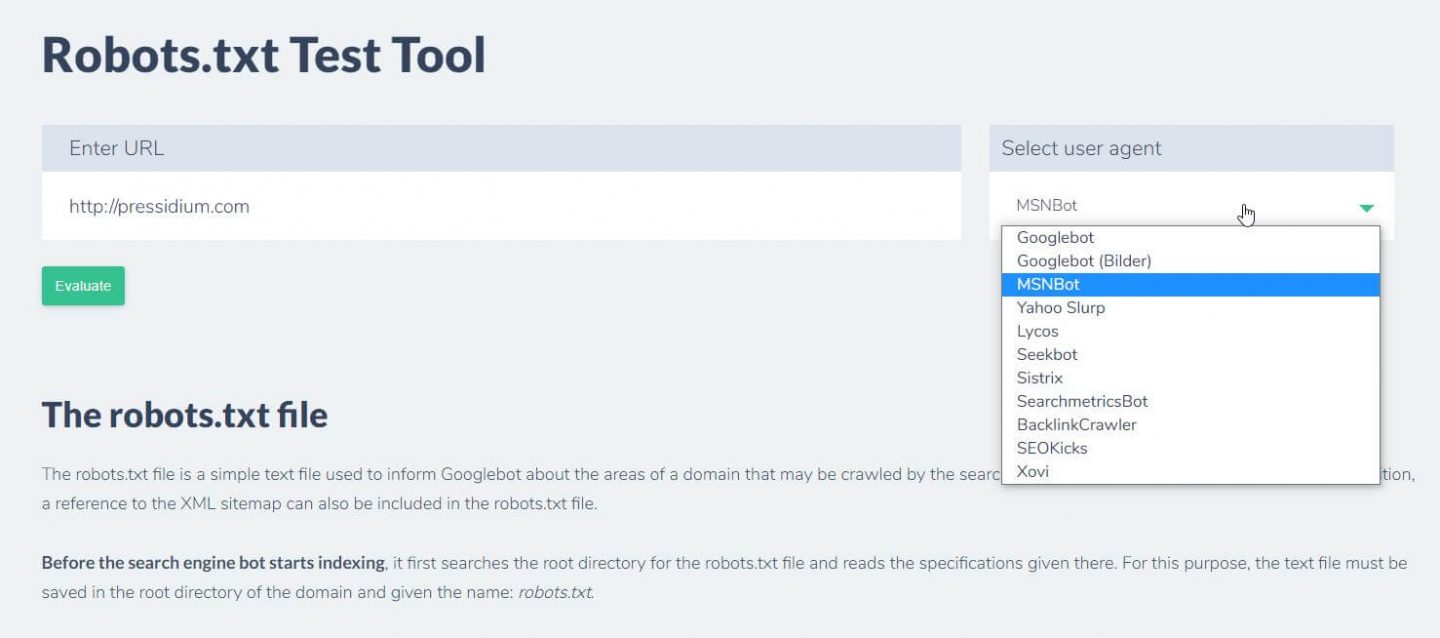
Devi solo inserire il tuo dominio e scegliere uno user agent dal pannello a destra. Dopo aver inviato questo vedrai i tuoi risultati.
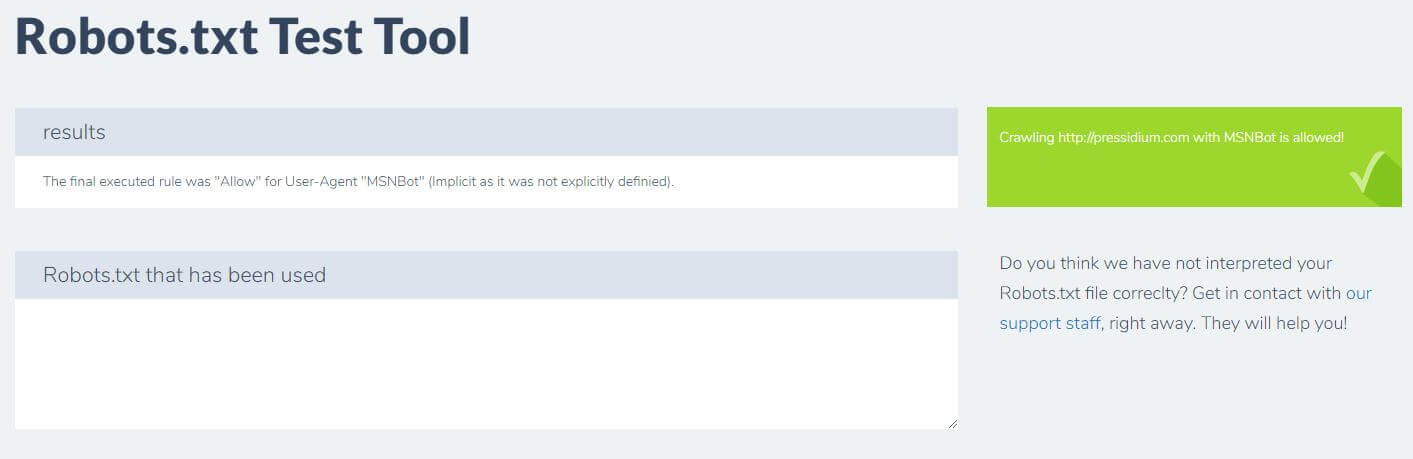
Conclusione
Sapere come utilizzare robots.txt è un altro strumento utile nel toolkit del tuo sviluppatore. Se l'unica cosa che porti via da questo tutorial è la possibilità di controllare che il tuo file robots.txt non stia bloccando bot come Google (cosa che è molto improbabile che tu voglia fare), allora non è una brutta cosa! Allo stesso modo, come puoi vedere, robots.txt offre tutta una serie di ulteriori controlli granulari sul tuo sito Web che potrebbero un giorno tornare utili.