
MongoDB データベースを作成する方法: 知っておくべき 6 つの重要な側面
公開: 2022-11-07ソフトウェアの要件に基づいて、柔軟性、スケーラビリティ、パフォーマンス、または速度を優先する場合があります。 したがって、開発者と企業は、ニーズに合わせてデータベースを選択する際に混乱することがよくあります. 高い柔軟性とスケーラビリティ、および顧客分析用のデータ集約を提供するデータベースが必要な場合は、MongoDB が最適です。
この記事では、MongoDB データベースの構造と、データベースを作成、監視、および管理する方法について説明します。 始めましょう。
MongoDB データベースはどのように構造化されていますか?
MongoDB は、スキーマのない NoSQL データベースです。 これは、SQL データベースの場合とは異なり、テーブル/データベースの構造を指定しないことを意味します。
NoSQL データベースは実際にはリレーショナル データベースよりも高速であることをご存知ですか? これは、インデックス作成、シャーディング、集約パイプラインなどの特性によるものです。 MongoDB は、高速なクエリ実行でも知られています。 これが、Google、Toyota、Forbes などの企業に好まれる理由です。
以下では、MongoDB のいくつかの重要な特徴について説明します。
ドキュメント
MongoDB には、データを JSON ドキュメントとして格納するドキュメント データ モデルがあります。 ドキュメントはアプリケーション コード内のオブジェクトに自然にマップされるため、開発者はより簡単に使用できます。
リレーショナル データベース テーブルでは、列を追加して新しいフィールドを追加する必要があります。 これは、JSON ドキュメントのフィールドには当てはまりません。 JSON ドキュメント内のフィールドはドキュメントごとに異なる可能性があるため、データベース内のすべてのレコードに追加されるわけではありません。
ドキュメントは、ネストして階層関係を表現できる配列などの構造を格納できます。 さらに、MongoDB はドキュメントをバイナリ JSON (BSON) 型に変換します。 これにより、アクセスが高速になり、文字列、整数、ブール値などのさまざまなデータ型のサポートが強化されます。
レプリカ セット
MongoDB で新しいデータベースを作成すると、システムはデータのコピーを少なくとも 2 つ追加で自動的に作成します。 これらのコピーは「レプリカ セット」と呼ばれ、それらの間でデータを継続的に複製し、データの可用性を向上させます。 また、システム障害や計画メンテナンス中のダウンタイムに対する保護も提供します。
コレクション
コレクションは、1 つのデータベースに関連付けられたドキュメントのグループです。 それらは、リレーショナル データベースのテーブルに似ています。
ただし、コレクションははるかに柔軟です。 1 つは、スキーマに依存しないことです。 第二に、ドキュメントは同じデータ型である必要はありません!
データベースに属するコレクションのリストを表示するには、コマンドlistCollectionsを使用します。
集約パイプライン
このフレームワークを使用して、いくつかの演算子と式をまとめることができます。 あらゆる構造のデータを処理、変換、および分析できるため、柔軟性があります。
このため、MongoDB は 150 の演算子と式にわたって高速なデータ フローと機能を可能にします。 また、複数のコレクションからの結果を柔軟にまとめるユニオン ステージなど、いくつかのステージがあります。
インデックス
MongoDB ドキュメント内の任意のフィールドにインデックスを付けて、効率を高め、クエリの速度を向上させることができます。 インデックス作成は、インデックスをスキャンして検査するドキュメントを制限することで時間を節約します。 これは、コレクション内のすべてのドキュメントを読むよりもはるかに優れていると思いませんか?
複数のフィールドに対する複合インデックスなど、さまざまなインデックス戦略を使用できます。 たとえば、従業員の名前と姓が別々のフィールドに含まれているドキュメントがいくつかあるとします。 姓と名を返したい場合は、「姓」と「名」の両方を含むインデックスを作成できます。 これは、「姓」に 1 つのインデックスを作成し、「名」に別のインデックスを作成するよりもはるかに優れています。
パフォーマンス アドバイザーなどのツールを活用して、どのクエリがインデックスの恩恵を受けるかをさらに理解することができます。
シャーディング
シャーディングは、単一のデータセットを複数のデータベースに分散します。 そのデータセットを複数のマシンに保存して、システムの総ストレージ容量を増やすことができます。 これは、大きなデータセットを小さなチャンクに分割し、さまざまなデータ ノードに保存するためです。
MongoDB は、コレクション レベルでデータをシャード化し、コレクション内のドキュメントをクラスター内のシャード全体に分散します。 これにより、アーキテクチャが最大のアプリケーションを処理できるようになるため、スケーラビリティが確保されます。
MongoDB データベースを作成する方法
最初に、OS に適した適切な MongoDB パッケージをインストールする必要があります。 「MongoDB Community Server のダウンロード」ページに移動します。 利用可能なオプションから、最新の「バージョン」、「パッケージ」形式を zip ファイル、「プラットフォーム」を OS として選択し、以下に示すように「ダウンロード」をクリックします。
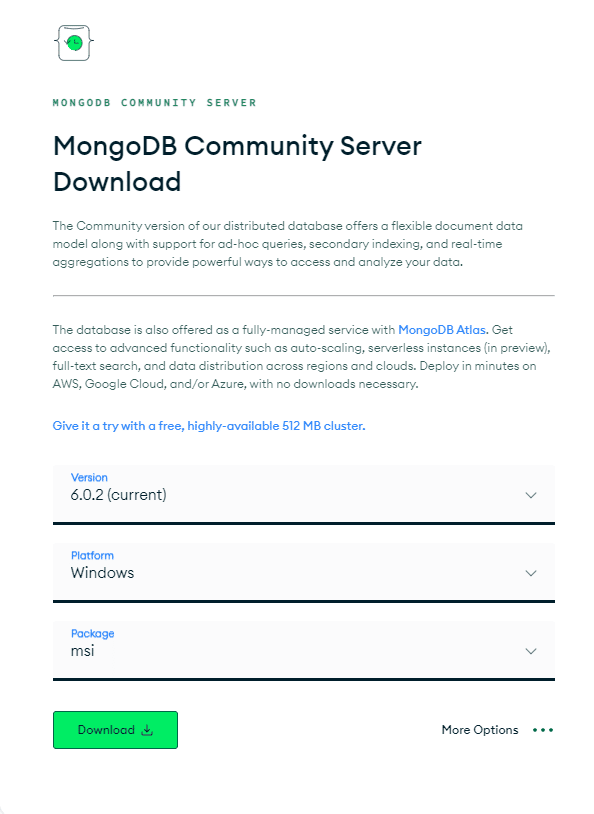
プロセスは非常に簡単なので、すぐにシステムに MongoDB をインストールできます。
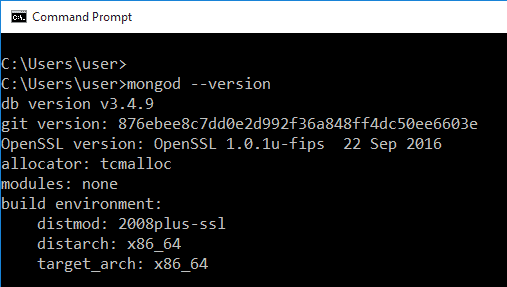
インストールが完了したら、コマンド プロンプトを開き、 mongod -versionと入力して確認します。 次の出力が得られず、代わりに一連のエラーが表示される場合は、再インストールする必要がある可能性があります。
MongoDB シェルの使用
始める前に、次のことを確認してください。
- クライアントはトランスポート レイヤー セキュリティを備えており、IP 許可リストに登録されています。
- 目的の MongoDB クラスターにユーザー アカウントとパスワードがある。
- デバイスに MongoDB をインストールしました。
ステップ 1: MongoDB シェルにアクセスする
MongoDB シェルにアクセスするには、次のコマンドを入力します。
net start MongoDBこれにより、次の出力が得られます。
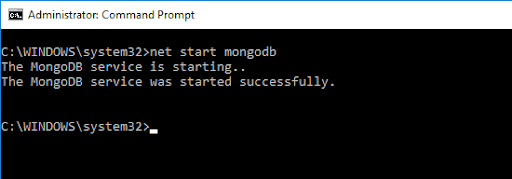
前のコマンドは、MongoDB サーバーを初期化しました。 これを実行するには、コマンド プロンプトでmongoと入力する必要があります。
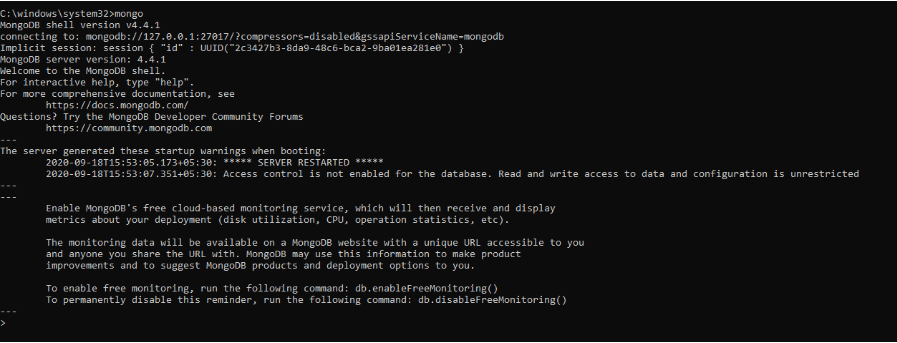
この MongoDB シェルでは、コマンドを実行して、データベースの作成、データの挿入、データの編集、管理コマンドの発行、およびデータの削除を行うことができます。
ステップ 2: データベースを作成する
SQL とは異なり、MongoDB にはデータベース作成コマンドがありません。 代わりに、指定したデータベースに切り替えるuseというキーワードがあります。 データベースが存在しない場合は、新しいデータベースが作成されます。そうでない場合は、既存のデータベースにリンクされます。
たとえば、「company」というデータベースを開始するには、次のように入力します。
use Company 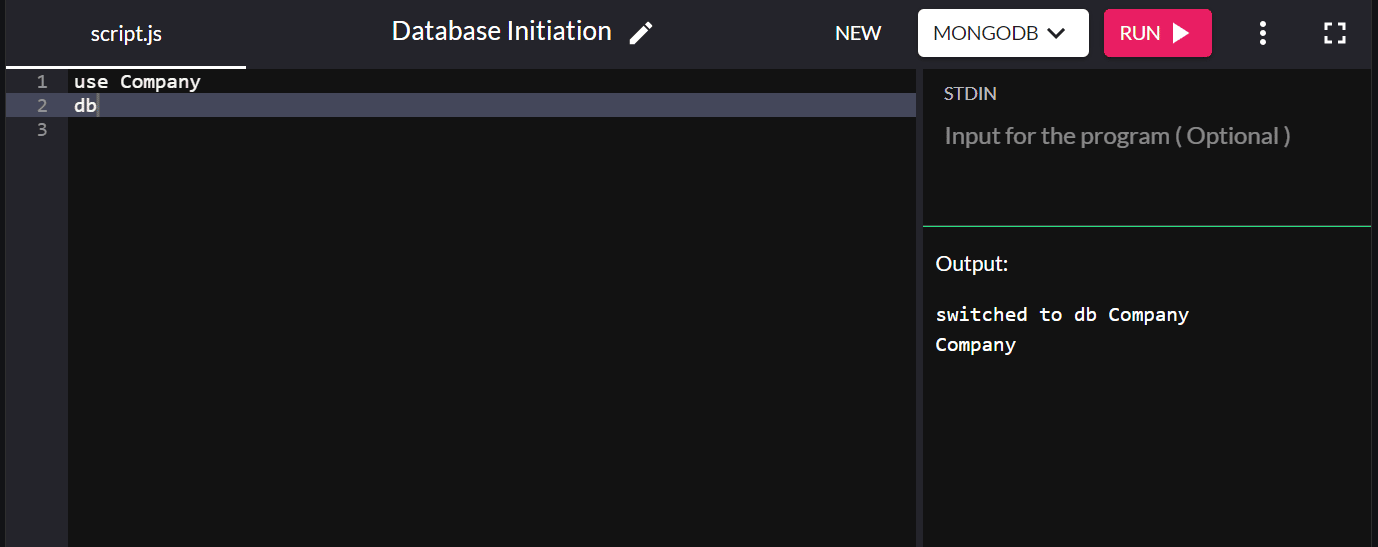
dbと入力して、システムで作成したばかりのデータベースを確認できます。 作成した新しいデータベースが表示されたら、正常に接続されています。
既存のデータベースを確認する場合は、 show dbsと入力すると、システム内のすべてのデータベースが返されます。
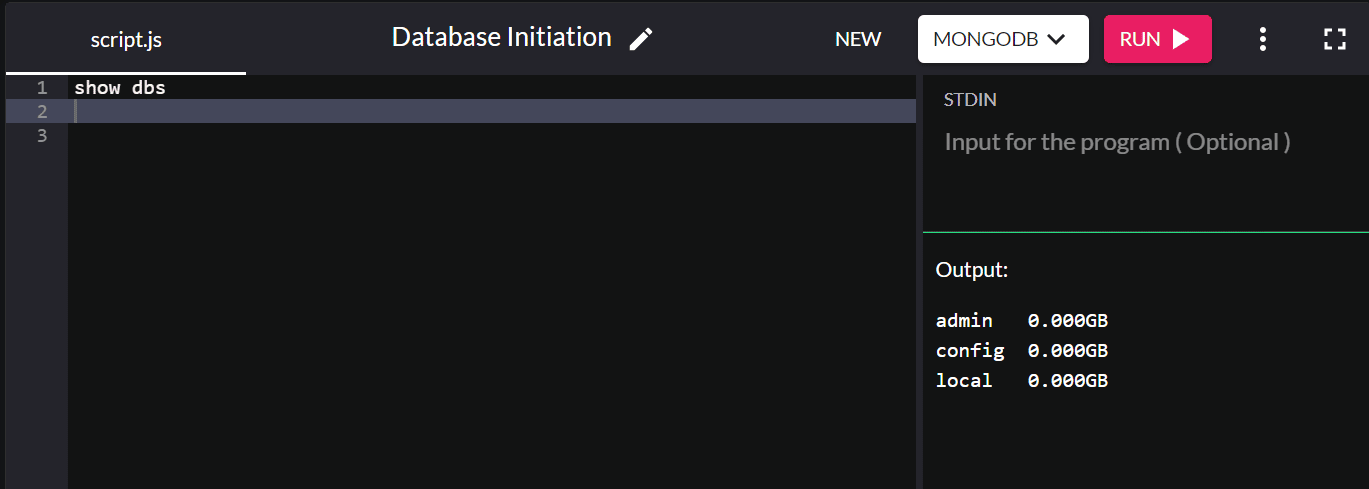
デフォルトでは、MongoDB をインストールすると、admin、config、および local データベースが作成されます。
作成したデータベースが表示されていないことに気付きましたか? これは、まだデータベースに値を保存していないためです! データベース管理セクションでの挿入について説明します。
アトラス UI の使用
MongoDB のデータベース サービスである Atlas を使い始めることもできます。 Atlas の一部の機能にアクセスするには料金が必要になる場合がありますが、ほとんどのデータベース機能は無料利用枠で利用できます。 無料利用枠の機能は、MongoDB データベースを作成するのに十分すぎる機能です。
始める前に、次のことを確認してください。
- あなたの IP はホワイトリストに登録されています。
- 使用する MongoDB クラスターのユーザー アカウントとパスワードを持っている。
AtlasUI で MongoDB データベースを作成するには、ブラウザ ウィンドウを開いて https://cloud.mongodb.com にログインします。 クラスター ページから、[ Browse Collections ] をクリックします。 クラスター内にデータベースがない場合は、[自分のデータを追加] ボタンをクリックしてデータベースを作成できます。
プロンプトで、データベースとコレクションの名前を指定するよう求められます。 名前を付けたら、[作成] をクリックして完了です。 新しいドキュメントを入力したり、ドライバーを使用してデータベースに接続したりできるようになりました。
MongoDB データベースの管理
このセクションでは、MongoDB データベースを効果的に管理するためのいくつかの気の利いた方法について説明します。 これは、MongoDB Compass を使用するか、コレクションを介して行うことができます。
コレクションの使用
リレーショナル データベースには、指定されたデータ型と列を持つ明確に定義されたテーブルがありますが、NoSQL にはテーブルの代わりにコレクションがあります。 これらのコレクションには構造がなく、ドキュメントは異なる場合があります。同じコレクション内の別のドキュメントの形式と一致する必要なく、さまざまなデータ型とフィールドを持つことができます。
実例として、「Employee」というコレクションを作成し、それにドキュメントを追加してみましょう。
db.Employee.insert( { "Employeename" : "Chris", "EmployeeDepartment" : "Sales" } ) 挿入が成功すると、 WriteResult({ "nInserted" : 1 })が返されます。
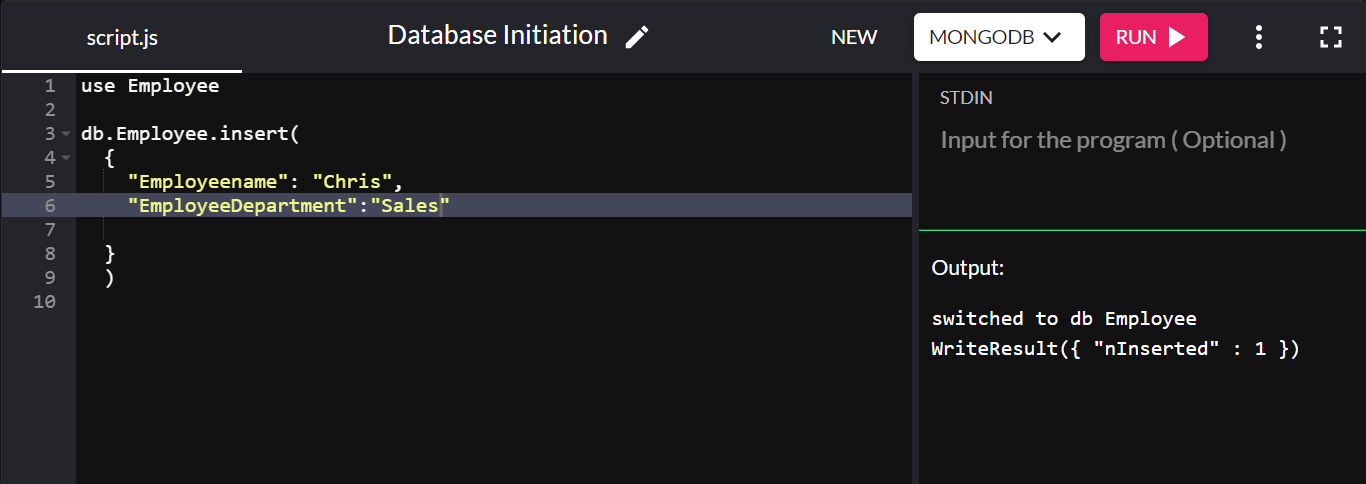
ここで、「db」は現在接続されているデータベースを指します。 「従業員」は、会社のデータベースで新しく作成されたコレクションです。
ここでは主キーを設定していません。これは、MongoDB が「_id」という主キー フィールドを自動的に作成し、それにデフォルト値を設定するためです。
以下のコマンドを実行して、コレクションを JSON 形式でチェックアウトします。
db.Employee.find().forEach(printjson)出力:
{ "_id" : ObjectId("63151427a4dd187757d135b8"), "Employeename" : "Chris", "EmployeeDepartment" : "Sales" }「_id」値は自動的に割り当てられますが、デフォルトの主キーの値を変更できます。 今回は、「_id」の値を「1」にして、「Employee」データベースに別のドキュメントを挿入します。
db.Employee.insert( { "_id" : 1, "EmployeeName" : "Ava", "EmployeeDepartment" : "Public Relations" } ) コマンドdb.Employee.find().forEach(printjson)を実行すると、次の出力が得られます。
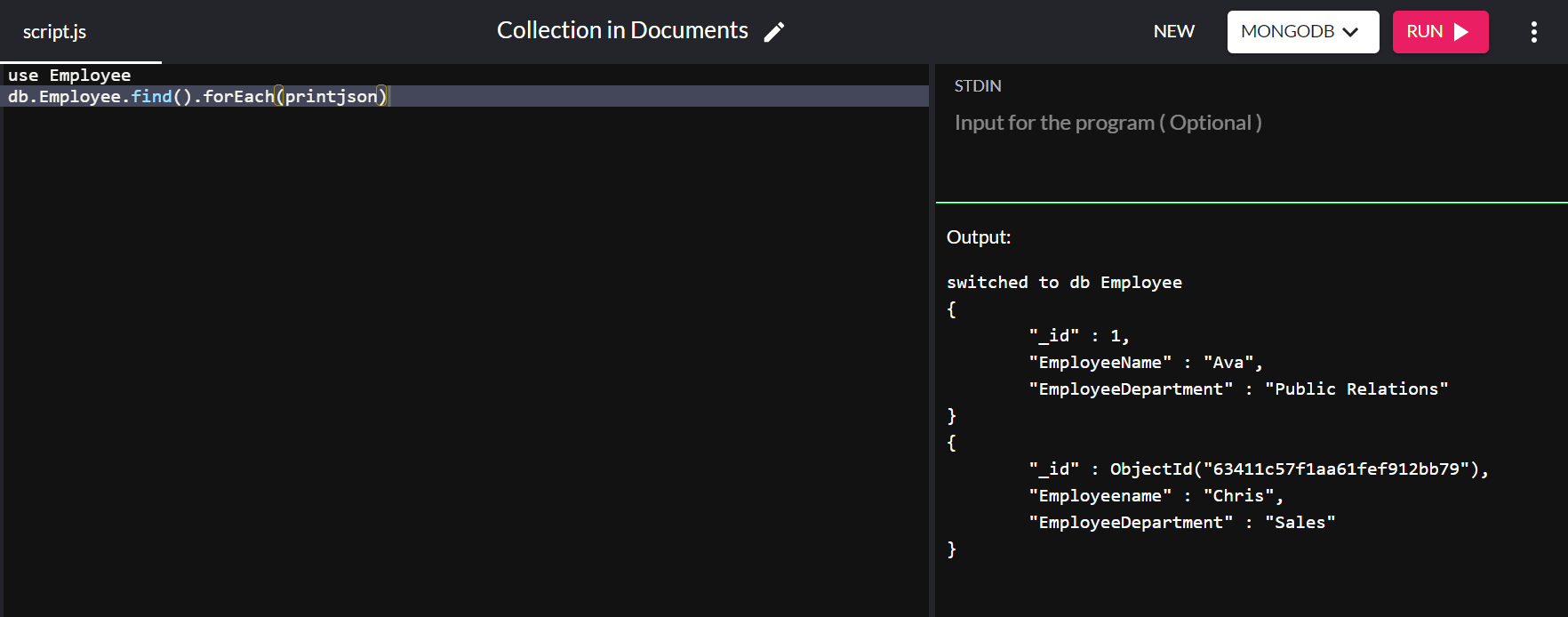
上記の出力では、「Ava」の「_id」値は、値が自動的に割り当てられる代わりに「1」に設定されています。
データベースに値を正常に追加したので、次のコマンドを使用して、システム内の既存のデータベースの下に値が表示されるかどうかを確認できます。
show dbs 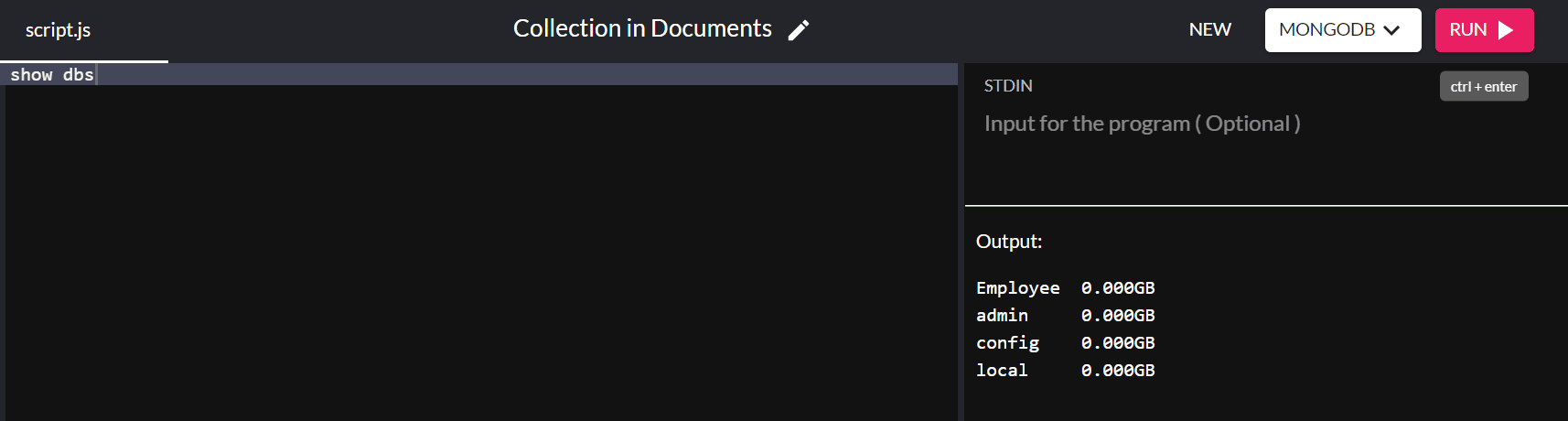
そして出来上がり! システムにデータベースが正常に作成されました!
MongoDB コンパスの使用
Mongo シェルから MongoDB サーバーを操作することはできますが、面倒な場合があります。 これは、実稼働環境で発生する可能性があります。
ただし、MongoDB によって作成されたコンパス ツール (適切な名前は Compass) があり、これを簡単に行うことができます。 GUI が改善され、データの視覚化、パフォーマンス プロファイリング、データ、データベース、コレクションへの CRUD (作成、読み取り、更新、削除) アクセスなどの機能が追加されました。
お使いの OS 用の Compass IDE をダウンロードして、簡単なプロセスでインストールできます。
次に、アプリケーションを開き、接続文字列を貼り付けてサーバーとの接続を作成します。 見つからない場合は、[接続フィールドに個別に入力する] をクリックできます。 MongoDB のインストール中にポート番号を変更しなかった場合は、接続ボタンをクリックするだけで完了です! それ以外の場合は、設定した値を入力して [接続] をクリックします。
![この画像は、接続 URL の貼り付けを選択できる [新しい接続] ウィンドウを示しています。](/uploads/article/43977/RRape2ira6ju2iYH.png)
次に、[新しい接続] ウィンドウでホスト名、ポート、および認証を指定します。
MongoDB Compass では、データベースの作成と最初のコレクションの追加を同時に行うことができます。 方法は次のとおりです。
- [データベースの作成]をクリックして、プロンプトを開きます。
- データベースの名前とその最初のコレクションを入力します。
- [データベースの作成]をクリックします。
データベースの名前をクリックし、コレクションの名前をクリックして [ドキュメント] タブを表示すると、データベースにさらにドキュメントを挿入できます。 次に、[データの追加] ボタンをクリックして、1 つまたは複数のドキュメントをコレクションに挿入できます。
ドキュメントを追加するときは、一度に 1 つずつ入力することも、配列内の複数のドキュメントとして入力することもできます。 複数のドキュメントを追加する場合は、これらのカンマ区切りのドキュメントが角括弧で囲まれていることを確認してください。 例えば:
{ _id: 1, item: { name: "apple", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }, { _id: 2, item: { name: "banana", code: "123" }, qty: 20, tags: [ "B" ] }, { _id: 3, item: { name: "spinach", code: "456" }, qty: 25, tags: [ "A", "B" ] }, { _id: 4, item: { name: "lentils", code: "456" }, qty: 30, tags: [ "B", "A" ] }, { _id: 5, item: { name: "pears", code: "000" }, qty: 20, tags: [ [ "A", "B" ], "C" ] }, { _id: 6, item: { name: "strawberry", code: "123" }, tags: [ "B" ] }最後に、[挿入] をクリックしてドキュメントをコレクションに追加します。 ドキュメントの本文は次のようになります。
{ "StudentID" : 1 "StudentName" : "JohnDoe" }ここでは、フィールド名は「StudentID」と「StudentName」です。 フィールド値はそれぞれ「1」と「JohnDoe」です。
便利なコマンド
これらのコレクションは、ロール管理およびユーザー管理コマンドを使用して管理できます。
ユーザー管理コマンド
MongoDB ユーザー管理コマンドには、ユーザーに関連するコマンドが含まれています。 これらのコマンドを使用して、ユーザーを作成、更新、および削除できます。
ドロップユーザー
このコマンドは、指定されたデータベースから 1 人のユーザーを削除します。 以下は構文です。
db.dropUser(username, writeConcern) ここで、 usernameは、ユーザーに関する認証およびアクセス情報を含むドキュメントを含む必須フィールドです。 オプションのフィールドwriteConcernには、作成操作に対する書き込み懸念のレベルが含まれます。 書き込み懸念のレベルは、オプションのフィールドwriteConcernによって決定できます。
userAdminAnyDatabaseロールを持つユーザーを削除する前に、ユーザー管理権限を持つ他のユーザーが少なくとも 1 人存在することを確認してください。
この例では、ユーザー「user26」を test データベースにドロップします。
use test db.dropUser("user26", {w: "majority", wtimeout: 4000})出力:
> db.dropUser("user26", {w: "majority", wtimeout: 4000}); trueユーザーを作成
このコマンドは、次のように、指定されたデータベースの新しいユーザーを作成します。
db.createUser(user, writeConcern) ここで、 userは、作成するユーザーに関する認証およびアクセス情報を含むドキュメントを含む必須フィールドです。 オプションのフィールドwriteConcernには、作成操作に対する書き込み懸念のレベルが含まれます。 書き込み懸念のレベルは、オプションのフィールドwriteConcernによって決定できます。
ユーザーがデータベースに既に存在する場合、 createUserは重複ユーザー エラーを返します。
次のようにして、テスト データベースに新しいユーザーを作成できます。
use test db.createUser( { user: "user26", pwd: "myuser123", roles: [ "readWrite" ] } );出力は次のとおりです。
Successfully added user: { "user" : "user26", "roles" : [ "readWrite", "dbAdmin" ] }grantRolesToUser
このコマンドを利用して、追加のロールをユーザーに付与できます。 これを使用するには、次の構文に注意する必要があります。
db.runCommand( { grantRolesToUser: "<user>", roles: [ <roles> ], writeConcern: { <write concern> }, comment: <any> } ) 上記のロールでは、ユーザー定義ロールと組み込みロールの両方を指定できます。 grantRolesToUserが実行される同じデータベースに存在するロールを指定する場合は、以下に示すように、ドキュメントでロールを指定できます。
{ role: "<role>", db: "<database>" }または、ロールの名前でロールを指定することもできます。 例えば:
"readWrite"別のデータベースに存在するロールを指定する場合は、別のドキュメントでロールを指定する必要があります。
データベースでロールを付与するには、指定したデータベースでgrantRoleアクションが必要です。
ここでは、明確なイメージを与える例を示します。 たとえば、次のロールを持つ製品データベース内のユーザー productUser00 を考えてみましょう。
"roles" : [ { "role" : "assetsWriter", "db" : "assets" } ] grantRolesToUserオペレーションは、「productUser00」に、stock データベースに対するreadWriteロールと、products データベースに対する read ロールを提供します。
use products db.runCommand({ grantRolesToUser: "productUser00", roles: [ { role: "readWrite", db: "stock"}, "read" ], writeConcern: { w: "majority" , wtimeout: 2000 } })製品データベースのユーザー productUser00 は、次のロールを所有しています。
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ]ユーザー情報
usersInfoコマンドを使用して、1 人以上のユーザーに関する情報を返すことができます。 構文は次のとおりです。
db.runCommand( { usersInfo: <various>, showCredentials: <Boolean>, showCustomData: <Boolean>, showPrivileges: <Boolean>, showAuthenticationRestrictions: <Boolean>, filter: <document>, comment: <any> } ) { usersInfo: <various> } アクセスに関しては、ユーザーはいつでも自分の情報を見ることができます。 別のユーザーの情報を表示するには、コマンドを実行するユーザーが、そのユーザーのデータベースに対するviewUserアクションを含む権限を持っている必要があります。
userInfoコマンドを実行すると、指定したオプションに応じて次の情報を取得できます。
{ "users" : [ { "_id" : "<db>.<username>", "userId" : <UUID>, // Starting in MongoDB 4.0.9 "user" : "<username>", "db" : "<db>", "mechanisms" : [ ... ], // Starting in MongoDB 4.0 "customData" : <document>, "roles" : [ ... ], "credentials": { ... }, // only if showCredentials: true "inheritedRoles" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedPrivileges" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedAuthenticationRestrictions" : [ ] // only if showPrivileges: true or showAuthenticationRestrictions: true "authenticationRestrictions" : [ ... ] // only if showAuthenticationRestrictions: true }, ], "ok" : 1 } usersInfoコマンドで何を達成できるかについての一般的なアイデアが得られたので、次の明らかな疑問は、特定のユーザーや複数のユーザーを調べるのにどのコマンドが便利かということです。
同じことを説明する便利な例を 2 つ示します。
「office」データベースで定義されたユーザー「Anthony」の資格情報ではなく、特定のユーザーの特定の特権と情報を確認するには、次のコマンドを実行します。
db.runCommand( { usersInfo: { user: "Anthony", db: "office" }, showPrivileges: true } )現在のデータベース内のユーザーを調べたい場合は、ユーザーを名前でのみ言及できます。 たとえば、ホーム データベースにいて、「Timothy」という名前のユーザーがホーム データベースに存在する場合、次のコマンドを実行できます。
db.getSiblingDB("home").runCommand( { usersInfo: "Timothy", showPrivileges: true } ) 次に、さまざまなユーザーの情報を見たい場合は、配列を使用できます。 オプションのフィールドshowCredentialsおよびshowPrivilegesを含めるか、除外することを選択できます。 コマンドは次のようになります。
db.runCommand({ usersInfo: [ { user: "Anthony", db: "office" }, { user: "Timothy", db: "home" } ], showPrivileges: true })revokeRolesFromUser
revokeRolesFromUserコマンドを利用して、ロールが存在するデータベース上のユーザーから 1 つ以上のロールを削除できます。 revokeRolesFromUserコマンドの構文は次のとおりです。
db.runCommand( { revokeRolesFromUser: "<user>", roles: [ { role: "<role>", db: "<database>" } | "<role>", ], writeConcern: { <write concern> }, comment: <any> } ) 上記の構文では、ユーザー定義の役割と組み込みの役割の両方rolesフィールドに指定できます。 grantRolesToUserコマンドと同様に、ドキュメントで取り消すロールを指定するか、その名前を使用できます。
revokeRolesFromUserコマンドを正常に実行するには、指定したデータベースでrevokeRoleアクションが必要です。
ポイントを家に持ち帰る例を次に示します。 製品データベースのproductUser00エンティティには、次の役割がありました。
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ] 次のrevokeRolesFromUserコマンドは、ユーザーの 2 つの役割を削除します。 productsからの「読み取り」役割と、「資産」データベースからのassetsWriter役割です。
use products db.runCommand( { revokeRolesFromUser: "productUser00", roles: [ { role: "AssetsWriter", db: "assets" }, "read" ], writeConcern: { w: "majority" } } )製品データベースのユーザー「productUser00」には、残りのロールが 1 つだけあります。
"roles" : [ { "role" : "readWrite", "db" : "stock" } ]役割管理コマンド
ロールは、ユーザーにリソースへのアクセスを許可します。 管理者はいくつかの組み込みロールを使用して、MongoDB システムへのアクセスを制御できます。 役割が必要な権限をカバーしていない場合は、さらに進んで特定のデータベースに新しい役割を作成することもできます。
ドロップロール
dropRoleコマンドを使用すると、コマンドを実行するデータベースからユーザー定義ロールを削除できます。 このコマンドを実行するには、次の構文を使用します。
db.runCommand( { dropRole: "<role>", writeConcern: { <write concern> }, comment: <any> } ) 正常に実行するには、指定されたデータベースでdropRoleアクションが必要です。 次の操作は、 writeTagsロールを「products」データベースから削除します。

use products db.runCommand( { dropRole: "writeTags", writeConcern: { w: "majority" } } )createRole
createRoleコマンドを利用して、ロールを作成し、その権限を指定できます。 ロールは、コマンドを実行するために選択したデータベースに適用されます。 ロールがデータベースにすでに存在する場合、 createRoleコマンドは重複ロール エラーを返します。
このコマンドを実行するには、次の構文に従います。
db.adminCommand( { createRole: "<new role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], roles: [ { role: "<role>", db: "<database>" } | "<role>", ], authenticationRestrictions: [ { clientSource: ["<IP>" | "<CIDR range>", ...], serverAddress: ["<IP>" | "<CIDR range>", ...] }, ], writeConcern: <write concern document>, comment: <any> } )ロールの権限は、ロールが作成されたデータベースに適用されます。 ロールは、そのデータベース内の他のロールから権限を継承できます。 たとえば、「admin」データベースで作成された役割には、クラスターまたはすべてのデータベースに適用される特権を含めることができます。 また、他のデータベースに存在するロールから特権を継承することもできます。
データベースにロールを作成するには、次の 2 つが必要です。
- そのデータベースの
grantRoleアクションで、新しいロールの権限を指定し、継承元のロールを指定します。 - そのデータベース リソースに対する
createRoleアクション。
次のcreateRoleコマンドは、ユーザー データベースにclusterAdminロールを作成します。
db.adminCommand({ createRole: "clusterAdmin", privileges: [ { resource: { cluster: true }, actions: [ "addShard" ] }, { resource: { db: "config", collection: "" }, actions: [ "find", "remove" ] }, { resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert" ] }, { resource: { db: "", collection: "" }, actions: [ "find" ] } ], roles: [ { role: "read", db: "user" } ], writeConcern: { w: "majority" , wtimeout: 5000 } })grantRolesToRole
grantRolesToRoleコマンドを使用すると、ロールをユーザー定義のロールに付与できます。 grantRolesToRoleコマンドは、コマンドが実行されるデータベースのロールに影響します。
このgrantRolesToRoleコマンドの構文は次のとおりです。
db.runCommand( { grantRolesToRole: "<role>", roles: [ { role: "<role>", db: "<database>" }, ], writeConcern: { <write concern> }, comment: <any> } ) アクセス権限はgrantRolesToUserコマンドに似ています。コマンドを適切に実行するには、データベースでgrantRoleアクションが必要です。
次の例では、 grantRolesToUserコマンドを使用して、「products」データベースのproductsReaderロールを更新し、 productsWriterロールの権限を継承できます。
use products db.runCommand( { grantRolesToRole: "productsReader", roles: [ "productsWriter" ], writeConcern: { w: "majority" , wtimeout: 5000 } } )revokePrivilegesFromRole
revokePrivilegesFromRoleを使用して、コマンドが実行されるデータベースのユーザー定義ロールから指定された権限を削除できます。 適切に実行するには、次の構文に注意する必要があります。
db.runCommand( { revokePrivilegesFromRole: "<role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], writeConcern: <write concern document>, comment: <any> } )特権を取り消すには、「リソース ドキュメント」パターンがその特権の「リソース」フィールドと一致する必要があります。 「actions」フィールドは、完全一致またはサブセットのいずれかです。
たとえば、「managers」データベースをリソースとして指定する次の権限を持つ製品データベースのロールmanageRoleについて考えてみます。
{ "resource" : { "db" : "managers", "collection" : "" }, "actions" : [ "insert", "remove" ] }manager データベース内の 1 つのコレクションだけから「挿入」または「削除」アクションを取り消すことはできません。 次の操作では、ロールは変更されません。
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert", "remove" ] } ] } ) db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert" ] } ] } ) ロールmanageRoleから「挿入」および/または「削除」アクションを取り消すには、リソース ドキュメントを正確に一致させる必要があります。 たとえば、次の操作は、既存の権限から「削除」アクションのみを取り消します。
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "" }, actions : [ "remove" ] } ] } )次の操作は、マネージャー データベースの「エグゼクティブ」ロールから複数の特権を削除します。
use managers db.runCommand( { revokePrivilegesFromRole: "executive", privileges: [ { resource: { db: "managers", collection: "" }, actions: [ "insert", "remove", "find" ] }, { resource: { db: "managers", collection: "partners" }, actions: [ "update" ] } ], writeConcern: { w: "majority" } } )ロール情報
rolesInfoコマンドは、組み込みの役割とユーザー定義の役割の両方を含む、指定された役割の特権と継承の情報を返します。 また、 rolesInfoコマンドを利用して、データベースをスコープとするすべてのロールを取得することもできます。
適切に実行するには、次の構文に従います。
db.runCommand( { rolesInfo: { role: <name>, db: <db> }, showPrivileges: <Boolean>, showBuiltinRoles: <Boolean>, comment: <any> } )現在のデータベースからロールの情報を返すには、その名前を次のように指定できます。
{ rolesInfo: "<rolename>" }別のデータベースからロールの情報を返すには、ロールとデータベースについて言及しているドキュメントでロールを言及できます。
{ rolesInfo: { role: "<rolename>", db: "<database>" } }たとえば、次のコマンドは、managers データベースで定義されたロール Executive のロール継承情報を返します。
db.runCommand( { rolesInfo: { role: "executive", db: "managers" } } ) 次のコマンドは、ロール継承情報を返します。コマンドが実行されたデータベースのaccountManager :
db.runCommand( { rolesInfo: "accountManager" } )次のコマンドは、managers データベースで定義されているロール「executive」の特権とロール継承の両方を返します。
db.runCommand( { rolesInfo: { role: "executive", db: "managers" }, showPrivileges: true } )複数のロールについて言及するには、配列を使用できます。 配列内の各ロールを文字列またはドキュメントとして指定することもできます。
コマンドが実行されるデータベースにロールが存在する場合にのみ、文字列を使用する必要があります。
{ rolesInfo: [ "<rolename>", { role: "<rolename>", db: "<database>" }, ] }たとえば、次のコマンドは、3 つの異なるデータベースの 3 つのロールに関する情報を返します。
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ] } )次のように、特権とロールの継承の両方を取得できます。
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ], showPrivileges: true } )パフォーマンス向上のための MongoDB ドキュメントの埋め込み
MongoDB のようなドキュメント データベースでは、必要に応じてスキーマを定義できます。 MongoDB で最適なスキーマを作成するために、ドキュメントをネストできます。 したがって、アプリケーションをデータ モデルに一致させる代わりに、ユース ケースに一致するデータ モデルを構築できます。
埋め込みドキュメントを使用すると、一緒にアクセスする関連データを保存できます。 MongoDB のスキーマを設計するときは、既定でドキュメントを埋め込むことをお勧めします。 データベース側またはアプリケーション側の結合と参照は、価値がある場合にのみ使用してください。
ワークロードが必要に応じてドキュメントを取得できることを確認してください。 同時に、ドキュメントには必要なすべてのデータも含まれている必要があります。 これは、アプリケーションの優れたパフォーマンスにとって極めて重要です。
以下に、ドキュメントを埋め込むためのいくつかの異なるパターンを示します。
埋め込みドキュメント パターン
これを使用して、使用されているドキュメントに複雑なサブ構造を埋め込むこともできます。 接続されたデータを 1 つのドキュメントに埋め込むと、データを取得するために必要な読み取り操作の回数を減らすことができます。 一般に、アプリケーションが必要なすべての情報を 1 回の読み取り操作で受け取るように、スキーマを構築する必要があります。 したがって、ここで覚えておくべき規則は、一緒に使用されるものは一緒に保管する必要があるということです。
埋め込みサブセット パターン
埋め込みサブセット パターンはハイブリッド ケースです。 関連項目の長いリストの個別のコレクションとして使用し、それらの項目の一部を表示用に手元に置いておくことができます。
映画のレビューを一覧表示する例を次に示します。
> db.movie.findOne() { _id: 321475, title: "The Dark Knight" } > db.review.find({movie_id: 321475}) { _id: 264579, movie_id: 321475, stars: 4 text: "Amazing" } { _id: 375684, movie_id: 321475, stars:5, text: "Mindblowing" }ここで、同様のレビューが 1,000 件あるとしますが、映画を上映するときに最新の 2 つだけを表示する予定です。 このシナリオでは、そのサブセットをムービー ドキュメント内のリストとして保存するのが理にかなっています。
> db.movie.findOne({_id: 321475}) { _id: 321475, title: "The Dark Knight", recent_reviews: [ {_id: 264579, stars: 4, text: "Amazing"}, {_id: 375684, stars: 5, text: "Mindblowing"} ] }</code簡単に言えば、関連するアイテムのサブセットに定期的にアクセスする場合は、それを埋め込むようにしてください。
独立したアクセス
サブドキュメントをコレクションに格納して、親コレクションから分離したい場合があります。
たとえば、会社の製品ラインを考えてみましょう。 会社が少数の製品セットを販売している場合、それらを会社のドキュメント内に保存することができます。 しかし、それらを企業間で再利用したり、在庫管理単位 (SKU) で直接アクセスしたりしたい場合は、それらをコレクションに保存することもできます。
エンティティを個別に操作またはアクセスする場合は、ベスト プラクティスとしてコレクションを作成して個別に格納します。
無制限のリスト
関連情報の短いリストをドキュメントに保存することには欠点があります。 あなたのリストが野放しに増え続けるなら、それを 1 つの文書にまとめるべきではありません。 これは、非常に長い間サポートすることができないためです。
これには 2 つの理由があります。 まず、MongoDB には 1 つのドキュメントのサイズに制限があります。 第 2 に、ドキュメントにアクセスする頻度が多すぎると、制御されていないメモリ使用による悪影響が見られます。
簡単に言えば、リストが無限に大きくなり始めたら、コレクションを作成して個別に保存します。
拡張参照パターン
拡張参照パターンは、サブセット パターンに似ています。 また、定期的にアクセスしてドキュメントに保存する情報を最適化します。
ここでは、リストの代わりに、ドキュメントが同じコレクションに存在する別のドキュメントを参照するときに利用されます。 同時に、すぐにアクセスできるように、他のドキュメントのいくつかのフィールドも保存します。
例えば:
> db.movie.findOne({_id: 245434}) { _id: 245434, title: "Mission Impossible 4 - Ghost Protocol", studio_id: 924935, studio_name: "Paramount Pictures" }As you can see, “the studio_id” is stored so that you can look up more information on the studio that created the film. But the studio's name is also copied to this document for simplicity.
To embed information from modified documents regularly, remember to update documents where you've copied that information when it is modified. In other words, if you routinely access some fields from a referenced document, embed them.
How To Monitor MongoDB
You can use monitoring tools like Kinsta APM to debug long API calls, slow database queries, long external URL requests, to name a few. You can even leverage commands to improve database performance. You can also use them to inspect the ase/” data-mce-href=”https://kinsta.com/knowledgebase/wordpress-repair-database/”>health of your database instances.
Why Should You Monitor MongoDB Databases?
A key aspect of database administration planning is monitoring your cluster's performance and health. MongoDB Atlas handles the majority of administration efforts through its fault-tolerance/scaling abilities.
Despite that, users need to know how to track clusters. They should also know how to scale or tweak whatever they need before hitting a crisis.
By monitoring MongoDB databases, you can:
- Observe the utilization of resources.
- Understand the current capacity of your database.
- React and detect real-time issues to enhance your application stack.
- Observe the presence of performance issues and abnormal behavior.
- Align with your governance/data protection and service-level agreement (SLA) requirements.
Key Metrics To Monitor
While monitoring MongoDB, there are four key aspects you need to keep in mind:
1. MongoDB Hardware Metrics
Here are the primary metrics for monitoring hardware:
Normalized Process CPU
It's defined as the percentage of time spent by the CPU on application software maintaining the MongoDB process.
You can scale this to a range of 0-100% by dividing it by the number of CPU cores. It includes CPU leveraged by modules such as kernel and user.
High kernel CPU might show exhaustion of CPU via the operating system operations. But the user linked with MongoDB operations might be the root cause of CPU exhaustion.
Normalized System CPU
It's the percentage of time the CPU spent on system calls servicing this MongoDB process. You can scale it to a range of 0-100% by dividing it by the number of CPU cores. It also covers the CPU used by modules such as iowait, user, kernel, steal, etc.
User CPU or high kernel might show CPU exhaustion through MongoDB operations (software). High iowait might be linked to storage exhaustion causing CPU exhaustion.
ディスク IOPS
Disk IOPS is the average consumed IO operations per second on MongoDB's disk partition.
Disk Latency
This is the disk partition's read and write disk latency in milliseconds in MongoDB. High values (>500ms) show that the storage layer might affect MongoDB's performance.
システムメモリ
Use the system memory to describe physical memory bytes used versus available free space.
The available metric approximates the number of bytes of system memory available. You can use this to execute new applications, without swapping.
Disk Space Free
This is defined as the total bytes of free disk space on MongoDB's disk partition. MongoDB Atlas provides auto-scaling capabilities based on this metric.
Swap Usage
You can leverage a swap usage graph to describe how much memory is being placed on the swap device. A high used metric in this graph shows that swap is being utilized. This shows that the memory is under-provisioned for the current workload.
MongoDB Cluster's Connection and Operation Metrics
Here are the main metrics for Operation and Connection Metrics:
Operation Execution Times
The average operation time (write and read operations) performed over the selected sample period.
Opcounters
It is the average rate of operations executed per second over the selected sample period. Opcounters graph/metric shows the operations breakdown of operation types and velocity for the instance.
接続
This metric refers to the number of open connections to the instance. High spikes or numbers might point to a suboptimal connection strategy either from the unresponsive server or the client side.
Query Targeting and Query Executors
This is the average rate per second over the selected sample period of scanned documents. For query executors, this is during query-plan evaluation and queries. Query targeting shows the ratio between the number of documents scanned and the number of documents returned.
数値比率が高い場合は、運用が最適化されていないことを示しています。 これらの操作は、多くのドキュメントをスキャンして、より小さな部分を返します。
スキャンして注文する
これは、クエリの選択されたサンプル期間における 1 秒あたりの平均レートを表します。 インデックスを使用してソート操作を実行できないソート結果を返します。
キュー
キューは、書き込みまたは読み取りのいずれかで、ロックを待機している操作の数を表すことができます。 高いキューは、スキーマ設計が最適ではないことを示している可能性があります。 また、競合する書き込みパスを示している可能性もあり、データベース リソースをめぐる競争が激化している可能性があります。
MongoDB レプリケーション メトリック
レプリケーション監視の主要なメトリックは次のとおりです。
レプリケーション Oplog ウィンドウ
このメトリクスは、プライマリのレプリケーション oplog で使用可能なおおよその時間を示します。 セカンダリがこの量よりも遅れている場合、追いつくことができず、完全な再同期が必要になります。
レプリケーション ラグ
レプリケーション ラグは、書き込み操作でセカンダリ ノードがプライマリよりも遅れているおおよその秒数として定義されます。 レプリケーション ラグが大きい場合は、セカンダリでレプリケーションが困難になっていることを示しています。 接続の読み取り/書き込みの問題を考えると、操作の待ち時間に影響を与える可能性があります。
レプリケーション ヘッドルーム
このメトリックは、プライマリ レプリケーションの oplog ウィンドウとセカンダリのレプリケーション ラグの差を表します。 この値がゼロになると、セカンダリが RECOVERING モードになる可能性があります。
Opcounters -repl
Opcounters -repl は、選択したサンプル期間に 1 秒あたりに実行されるレプリケーション操作の平均レートとして定義されます。 opcounters -graph/metric を使用すると、指定したインスタンスの操作速度と操作タイプの内訳を確認できます。
Oplog GB/時間
これは、1 時間あたりにプライマリが生成する oplog のギガバイトの平均レートとして定義されます。 予期しない大量の oplog は、非常に不十分な書き込みワークロードまたはスキーマ設計の問題を示している可能性があります。
MongoDB パフォーマンス監視ツール
MongoDB には、Cloud Manager、Atlas、および Ops Manager にパフォーマンス追跡用のユーザー インターフェイス ツールが組み込まれています。 また、より生ベースのデータを調べるためのいくつかの独立したコマンドとツールも提供します。 環境をチェックするためのアクセス権と適切なロールを持つホストから実行できるいくつかのツールについて説明します。
モンゴトップ
このコマンドを利用して、MongoDB インスタンスがコレクションごとのデータの書き込みと読み取りに費やした時間を追跡できます。 次の構文を使用します。
mongotop <options> <connection-string> <polling-interval in seconds>rs.status()
このコマンドは、レプリカ セットのステータスを返します。 メソッドが実行されるメンバーの観点から実行されます。
モンゴスタット
mongostatコマンドを使用して、MongoDB サーバー インスタンスのステータスの概要をすばやく取得できます。 最適な出力を得るために、リアルタイム ビューを提供するため、特定のイベントの 1 つのインスタンスを監視するために使用できます。
このコマンドを活用して、ロック キュー、操作の内訳、MongoDB メモリ統計、および接続/ネットワークなどの基本的なサーバー統計を監視します。
mongostat <options> <connection-string> <polling interval in seconds>dbStats
このコマンドは、特定のデータベースのストレージ統計を返します。たとえば、インデックスの数とそのサイズ、コレクション データの合計とストレージ サイズ、およびコレクション関連の統計 (コレクションとドキュメントの数) などです。
デシベル.serverStatus()
db.serverStatus()コマンドを利用して、データベースの状態の概要を把握できます。 これにより、現在のインスタンス メトリック カウンターを表すドキュメントが提供されます。 このコマンドを定期的に実行して、インスタンスに関する統計を照合します。
collStats
collStatsコマンドは、収集レベルでdbStatsによって提供されるものと同様の統計を収集します。 その出力は、コレクション内のオブジェクトの数、コレクションによって消費されるディスク容量、コレクションのサイズ、および特定のコレクションのインデックスに関する情報で構成されます。
これらすべてのコマンドを使用して、データベース サーバーのリアルタイム レポートと監視を提供できます。これにより、データベースのパフォーマンスとエラーを監視し、情報に基づいた意思決定を支援してデータベースを改良できます。
MongoDB データベースを削除する方法
MongoDB で作成したデータベースを削除するには、use キーワードを使用して接続する必要があります。
「Engineers」という名前のデータベースを作成したとします。 データベースに接続するには、次のコマンドを使用します。
use Engineers 次に、 db.dropDatabase()と入力して、このデータベースを削除します。 実行後、期待できる結果は次のとおりです。
{ "dropped" : "Engineers", "ok" : 1 } showdbsコマンドを実行して、データベースがまだ存在するかどうかを確認できます。
概要
MongoDB の価値を最後の一滴まで搾り取るには、基礎を深く理解している必要があります。 したがって、MongoDB データベースを手の甲のように理解することは非常に重要です。 これには、最初にデータベースを作成する方法に慣れる必要があります。
ます
この記事では、MongoDB でデータベースを作成するために使用できるさまざまな方法を明らかにした後、データベースの管理に役立ついくつかの気の利いた MongoDB コマンドについて詳しく説明します。 最後に、MongoDB に埋め込まれたドキュメントとパフォーマンス監視ツールを活用して、ワークフローが最高の効率で機能するようにする方法を説明して、議論を締めくくりました。
これらの MongoDB コマンドについてどう思いますか? ここで見たいと思っていた側面や方法を見逃していませんか? コメントでお知らせください!