
記録的な速さで堅牢な MongoDB レプリカ セットを構築する (4 つの方法)
公開: 2023-03-11MongoDB は、動的なスキーマを持つ JSON のようなドキュメントを使用する NoSQL データベースです。 データベースを操作するときは、データベース サーバーの 1 つに障害が発生した場合に備えて、緊急時対応計画を用意しておくことをお勧めします。 サイドバー、WordPress サイトの気の利いた管理ツールを活用することで、その可能性を減らすことができます.
これが、データのコピーをたくさん持っていると便利な理由です。 また、読み取りレイテンシも短縮されます。 同時に、データベースのスケーラビリティと可用性を向上させることができます。 ここでレプリケーションの出番です。これは、複数のデータベース間でデータを同期する方法として定義されています。
この記事では、MongoDB レプリケーションのさまざまな顕著な側面 (機能やメカニズムなど) について詳しく説明します。
MongoDB のレプリケーションとは?
MongoDB では、レプリカ セットがレプリケーションを実行します。 これは、複製によって同じデータ セットを維持するサーバーのグループです。 負荷分散の一部として MongoDB レプリケーションを使用することもできます。 ここでは、ユースケースに基づいて、書き込み操作と読み取り操作をすべてのインスタンスに分散できます。
MongoDB レプリカ セットとは
特定のレプリカ セットの一部である MongoDB のすべてのインスタンスがメンバーです。 すべてのレプリカ セットには、プライマリ メンバーと少なくとも 1 つのセカンダリ メンバーが必要です。
プライマリ メンバーは、レプリカ セットとのトランザクションのプライマリ アクセス ポイントです。 また、書き込み操作を受け入れることができる唯一のメンバーでもあります。 レプリケーションは、最初にプライマリの oplog (操作ログ) をコピーします。 次に、ログに記録された変更をセカンダリのそれぞれのデータセットで繰り返します。 したがって、すべてのレプリカ セットは一度に 1 つのプライマリ メンバーしか持つことができません。 書き込み操作を受け取るさまざまなプライマリは、データの競合を引き起こす可能性があります。
通常、アプリケーションは、書き込み操作と読み取り操作についてプライマリ メンバーのみをクエリします。 1 つ以上のセカンダリ メンバーから読み取るようにセットアップを設計できます。 非同期データ転送により、セカンダリ ノードの読み取りで古いデータが提供される可能性があります。 したがって、このような配置はすべてのユースケースに適しているわけではありません。
レプリカセットの特徴
自動フェイルオーバー メカニズムにより、MongoDB のレプリカ セットは競合他社と一線を画しています。 プライマリがない場合、セカンダリ ノード間の自動選択によって新しいプライマリが選択されます。
MongoDB レプリカ セットと MongoDB クラスター
MongoDB レプリカ セットは、レプリカ セット ノード全体で同じデータ セットのさまざまなコピーを作成します。 レプリカ セットの主な目的は次のとおりです。
- 組み込みのバックアップ ソリューションを提供する
- データの可用性を向上
MongoDB クラスターはまったく別の球技です。 シャードキーを介して多くのノードにデータを分散します。 このプロセスは、データをシャードと呼ばれる多くの断片に断片化します。 次に、各シャードを別のノードにコピーします。 クラスターは、大規模なデータ セットと高スループットの操作をサポートすることを目的としています。 ワークロードを水平方向にスケーリングすることでそれを実現します。
簡単に言えば、レプリカ セットとクラスターの違いは次のとおりです。
- クラスターはワークロードを分散します。 また、データのフラグメント (シャード) を多数のサーバーに保存します。
- レプリカ セットは、データ セットを完全に複製します。
MongoDB では、シャード クラスターを作成することで、これらの機能を組み合わせることができます。 ここでは、すべてのシャードをセカンダリ サーバーに複製できます。 これにより、シャードは高い冗長性とデータの可用性を提供できます。
レプリカ セットの維持と設定は、技術的に負担が大きく、時間がかかる場合があります。 そして、適切なホスティング サービスを見つけますか? それはまったく別の頭痛の種です。 非常に多くのオプションがあるため、ビジネスを構築する代わりに、調査に何時間も費やすのは簡単です.
サービス/製品でそれを押しつぶすことができるように、これらすべてとそれ以上のことを行うツールについて簡単に説明しましょう。
55,000 人を超える開発者から信頼されている Kinsta のアプリケーション ホスティング ソリューションは、わずか 3 つの簡単な手順で起動して実行できます。 それがうますぎると思われる場合は、Kinsta を使用する利点をさらにいくつかご紹介します。
- Kinstaの内部接続でより良いパフォーマンスをお楽しみください: 共有データベースでの苦労は忘れてください。 クエリ数や行数の制限がない内部接続を備えた専用データベースに切り替えます。 Kinsta はより高速で安全であり、内部の帯域幅/トラフィックに対して請求することはありません。
- 開発者向けに調整された機能セット: Gmail、YouTube、Google 検索をサポートする堅牢なプラットフォームでアプリケーションをスケーリングします。 安心してください、あなたはここで最も安全です。
- 選択したデータセンターで比類のない速度をお楽しみください: あなたとあなたの顧客にとって最適なリージョンを選択してください。 25 以上のデータセンターから選択できる Kinsta の275 以上のPoP は、ウェブサイトの最大速度とグローバルな存在感を保証します。
Kinstaのアプリケーションホスティングソリューションを今すぐ無料でお試しください!
MongoDB でレプリケーションはどのように機能しますか?
MongoDB では、ライター操作をプライマリ サーバー (ノード) に送信します。 プライマリ サーバーは、セカンダリ サーバー全体に操作を割り当て、データを複製します。
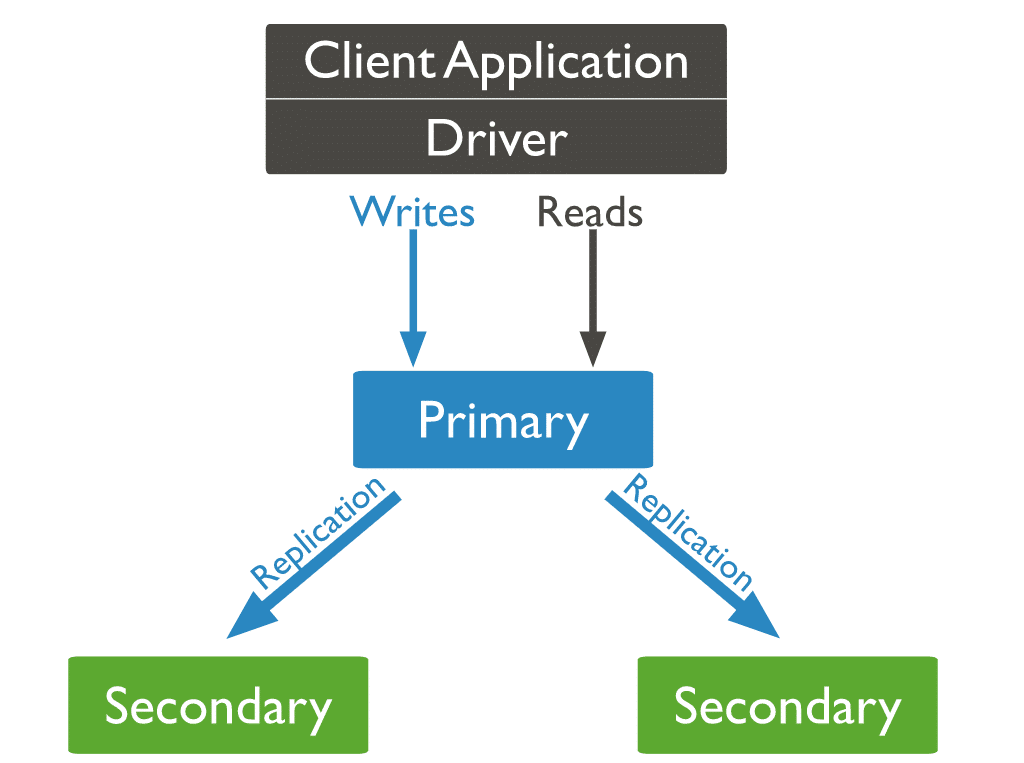
3 種類の MongoDB ノード
3 種類の MongoDB ノードのうち、プライマリ ノードとセカンダリ ノードの 2 種類が以前に登場しました。 レプリケーション中に役立つ 3 番目のタイプの MongoDB ノードはアービターです。 アービター ノードにはデータ セットのコピーがなく、プライマリになることはできません。 そうは言っても、アービターは予備選挙の選挙に参加します。
プライマリ ノードがダウンするとどうなるかについては以前に説明しましたが、セカンダリ ノードがダウンしたらどうなるでしょうか? そのシナリオでは、プライマリ ノードがセカンダリになり、データベースに到達できなくなります。
メンバー選挙
選挙は、次のシナリオで発生する可能性があります。
- レプリカ セットの初期化
- プライマリ ノードへの接続の喪失 (ハートビートで検出可能)
-
rs.reconfigまたはstepDownメソッドを使用したレプリカ セットのメンテナンス - 既存のレプリカ セットへの新しいノードの追加
レプリカ セットは最大 50 人のメンバーを持つことができますが、どの選挙でも 7 人以下しか投票できません。
クラスターが新しいプライマリを選択するまでの平均時間は、12 秒を超えてはなりません。 選択アルゴリズムは、優先度が最も高いセカンダリを使用できるようにします。 同時に、優先順位の値が 0 のメンバーは予備選挙になれず、選挙に参加しません。
書き込み懸念
耐久性のために、書き込み操作には、指定された数のノードにデータをコピーするためのフレームワークがあります。 これにより、クライアントにフィードバックを提供することもできます。 このフレームワークは、「書き込み懸念」としても知られています。 操作が成功として戻る前に、書き込みの懸念を確認する必要があるデータ保持メンバーがあります。 一般に、レプリカ セットは書き込み問題として値 1 を持ちます。 したがって、書き込み関連確認を返す前に、プライマリのみが書き込みを確認する必要があります。
書き込み操作を確認するために必要なメンバーの数を増やすこともできます。 メンバー数に上限はありません。 ただし、数値が高い場合は、高いレイテンシに対処する必要があります。 これは、クライアントがすべてのメンバーからの確認を待つ必要があるためです。 また、「過半数」の書き込み懸念を設定することもできます。これは、承認を受け取った後に半分以上のメンバーを計算します。
読み取り設定
読み取り操作については、データベースがクエリをレプリカ セットのメンバーに送信する方法を説明する読み取り設定を指定できます。 通常、プライマリ ノードは読み取り操作を受け取りますが、クライアントは読み取り操作をセカンダリ ノードに送信するように読み取り設定を指定できます。 読み取り設定のオプションは次のとおりです。
- primaryPreferred : 通常、読み取り操作はプライマリ ノードから行われますが、これが利用できない場合、データはセカンダリ ノードからプルされます。
- primary : すべての読み取り操作はプライマリ ノードから行われます。
- secondary : すべての読み取り操作はセカンダリ ノードによって実行されます。
- nearest : ここでは、読み取り要求は、
pingコマンドを実行することで検出できる、最も近い到達可能なノードにルーティングされます。 読み取り操作の結果は、プライマリかセカンダリかに関係なく、レプリカ セットの任意のメンバーから取得できます。 - secondaryPreferred : ここでは、ほとんどの読み取り操作はセカンダリ ノードから行われますが、いずれも使用できない場合、データはプライマリ ノードから取得されます。
レプリケーション セット データの同期
共有データ セットの最新のコピーを維持するために、レプリカ セットのセカンダリ メンバーは、他のメンバーからのデータをレプリケートまたは同期します。
MongoDB は、2 つの形式のデータ同期を利用します。 新しいメンバーに完全なデータセットを入力するための初期同期。 完全なデータ セットに対して進行中の変更を実行するためのレプリケーション。
初期同期
初期同期中に、セカンダリ ノードはinit syncコマンドを実行して、すべてのデータをプライマリ ノードから、最新のデータを含む別のセカンダリ ノードに同期します。 したがって、セカンダリ ノードは一貫してtailable cursor機能を活用して、プライマリ ノードの local.oplog.rs コレクション内の最新の oplog エントリをクエリし、これらの操作をこれらの oplog エントリ内に適用します。
MongoDB 5.2 から、初期同期はファイル コピー ベースまたは論理的に行うことができます。
論理同期
論理同期を実行すると、MongoDB は次のことを行います。
- ドキュメントがコレクションごとにコピーされるときに、すべてのコレクション インデックスを作成します。
- ローカル データベースを除くすべてのデータベースを複製します。
mongod、すべてのソース データベースのすべてのコレクションをスキャンし、すべてのデータをこれらのコレクションの複製に挿入します。 - データセットのすべての変更を実行します。 ソースからの oplog を活用することにより、
mongodそのデータ セットをアップグレードして、レプリカ セットの現在の状態を示します。 - データのコピー中に新しく追加された oplog レコードを抽出します。 このデータ コピー ステージの間、これらの oplog レコードを一時的に格納するために、ターゲット メンバーのローカル データベース内に十分なディスク領域があることを確認してください。
初期同期が完了すると、メンバーはSTARTUP2からSECONDARYに移行します。
ファイル コピー ベースの初期同期
すぐに実行できるのは、MongoDB Enterprise を使用している場合のみです。 このプロセスは、ファイル システム上でファイルを複製および移動することによって、初期同期を実行します。 この同期方法は、場合によっては、論理的な初期同期よりも高速になることがあります。 クエリ述語を指定せずに count() メソッドを実行すると、ファイル コピー ベースの初期同期でカウントが不正確になる可能性があることに注意してください。
ただし、この方法にもかなりの制限があります。
- ファイル コピー ベースの初期同期中は、同期中のメンバーのローカル データベースに書き込むことができません。 また、同期先のメンバーまたは同期元のメンバーでバックアップを実行することもできません。
- 暗号化されたストレージ エンジンを利用する場合、MongoDB はソース キーを使用して宛先を暗号化します。
- 一度に 1 つの特定のメンバーからのみ初期同期を実行できます。
レプリケーション
セカンダリ メンバーは、最初の同期後に一貫してデータをレプリケートします。 セカンダリ メンバーは、ソースからの同期から oplog を複製し、これらの操作を非同期プロセスで実行します。
セカンダリは、ping 時間の変化と他のメンバーのレプリケーションの状態に基づいて、必要に応じてソースからの同期を自動的に変更できます。
ストリーミング レプリケーション
MongoDB 4.4 以降、ソースからの同期は oplog エントリの継続的なストリームを同期セカンダリに送信します。 ストリーミング レプリケーションは、高負荷で高遅延のネットワークでのレプリケーション ラグを短縮します。 次のこともできます。
- プライマリ フェールオーバーが原因で
w:1書き込み操作が失われるリスクを減らします。 - セカンダリからの読み取りの古さを減らします。
-
w:“majority”およびw:>1を使用して、書き込み操作のレイテンシを短縮します。 つまり、レプリケーションを待機する必要がある書き込みの問題です。
マルチスレッド レプリケーション
MongoDB は、同時実行性を向上させるために、複数のスレッドを介してバッチで操作を書き込むために使用されていました。 MongoDB は、異なるスレッドで操作の各グループを適用しながら、ドキュメント ID によってバッチをグループ化します。
MongoDB は、特定のドキュメントに対して常に元の書き込み順序で書き込み操作を実行します。 これは MongoDB 4.0 で変更されました。
MongoDB 4.0 から、セカンダリを対象とし、 “majority”または“local”の読み取り懸念レベルで構成されている読み取り操作は、レプリケーション バッチが適用されているセカンダリで読み取りが発生した場合、データの WiredTiger スナップショットから読み取るようになりました。 スナップショットからの読み取りは、データの一貫したビューを保証し、ロックを必要とせずに進行中のレプリケーションと同時に読み取りを実行できます。
したがって、これらの読み取り懸念レベルを必要とするセカンダリ読み取りは、レプリケーション バッチが適用されるのを待つ必要がなくなり、受信時に処理できます。
MongoDB レプリカ セットを作成する方法
前述のように、MongoDB はレプリカ セットを介してレプリケーションを処理します。 次のいくつかのセクションでは、ユース ケースのレプリカ セットを作成するために使用できるいくつかの方法について説明します。
方法 1: Ubuntu で新しい MongoDB レプリカ セットを作成する
開始する前に、Ubuntu 20.04 を実行するサーバーが少なくとも 3 台あり、各サーバーに MongoDB がインストールされていることを確認する必要があります。
レプリカ セットをセットアップするには、セット内の他のメンバーが各レプリカ セット メンバーに到達できるアドレスを提供することが不可欠です。 この場合、セットに 3 つのメンバーを保持します。 IP アドレスを使用できますが、アドレスが予期せず変更される可能性があるため、お勧めしません。 より良い代替手段は、レプリカ セットを構成するときに論理 DNS ホスト名を使用することです。
これを行うには、レプリケーション メンバーごとにサブドメインを構成します。 これは実稼働環境には理想的ですが、このセクションでは、各サーバーのそれぞれのホストのファイルを編集して DNS 解決を構成する方法について概説します。 このファイルを使用すると、読み取り可能なホスト名を数値の IP アドレスに割り当てることができます。 したがって、いずれにせよ IP アドレスが変更された場合、レプリカ セットを最初から再構成するのではなく、3 台のサーバー上のホストのファイルを更新するだけで済みます。
ほとんどの場合、 hosts /etc/ディレクトリに保存されます。 3 つのサーバーのそれぞれについて、以下のコマンドを繰り返します。
sudo nano /etc/hosts上記のコマンドでは、nano をテキスト エディターとして使用していますが、任意のテキスト エディターを使用できます。 localhost を構成する最初の数行の後に、レプリカ セットの各メンバーのエントリを追加します。 これらのエントリは、IP アドレスの後に、選択した人が読める名前が続く形式をとります。 好きな名前を付けることができますが、各メンバーを区別できるようにわかりやすいものにしてください。 このチュートリアルでは、以下のホスト名を使用します。
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
これらのホスト名を使用すると、/etc/hosts ファイルは次の強調表示された行のようになります。

ファイルを保存して閉じます。
レプリカ セットの DNS 解決を構成したら、ファイアウォール ルールを更新して、相互に通信できるようにする必要があります。 mongo0 で次のufwコマンドを実行して、mongo0 のポート 27017 への mongo1 アクセスを提供します。
sudo ufw allow from mongo1_server_ip to any port 27017 mongo1_server_ipパラメータの代わりに、mongo1 サーバーの実際の IP アドレスを入力します。 また、このサーバーの Mongo インスタンスをデフォルト以外のポートを使用するように更新した場合は、MongoDB インスタンスが使用しているポートを反映するように 27017 を変更してください。
次に、別のファイアウォール ルールを追加して、mongo2 が同じポートにアクセスできるようにします。
sudo ufw allow from mongo2_server_ip to any port 27017 mongo2_server_ipパラメータの代わりに、mongo2 サーバーの実際の IP アドレスを入力します。 次に、他の 2 つのサーバーのファイアウォール ルールを更新します。 mongo1 サーバーで次のコマンドを実行し、server_ip パラメーターの代わりに IP アドレスを変更して、それぞれ mongo0 と mongo2 の IP アドレスを反映するようにします。
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017最後に、これら 2 つのコマンドを mongo2 で実行します。 ここでも、各サーバーに正しい IP アドレスを入力してください。
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017次のステップは、各 MongoDB インスタンスの構成ファイルを更新して、外部接続を許可することです。 これを可能にするには、各サーバーの構成ファイルを変更して、IP アドレスを反映し、レプリカ セットを示す必要があります。 任意のテキスト エディターを使用できますが、ここではもう一度 nano テキスト エディターを使用します。 各mongod.confファイルで次の変更を行いましょう。
mongo0 で:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"mongo1 で:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"mongo2 で:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodこれで、各サーバーの MongoDB インスタンスのレプリケーションが有効になりました。
rs.initiate()メソッドを使用してレプリカ セットを初期化できるようになりました。 このメソッドは、レプリカ セット内の単一の MongoDB インスタンスでのみ実行する必要があります。 レプリカ セットの名前とメンバーが、以前に各構成ファイルで行った構成と一致していることを確認してください。
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })メソッドが出力で「ok」: 1 を返す場合、レプリカ セットが正しく開始されたことを意味します。 以下は、出力がどのように見えるかの例です。
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }MongoDB サーバーをシャットダウンする
db.shutdownServer()メソッドを使用して、MongoDB サーバーをシャットダウンできます。 以下は、同じ構文です。 forceとtimeoutsecsどちらもオプションのパラメーターです。
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) mongod レプリカ セット メンバーが特定の操作をインデックス構築として実行する場合、このメソッドは失敗する可能性があります。 操作を中断してメンバーを強制的にシャットダウンするには、ブール値パラメーターforceを true に入力できます。
–replSet で MongoDB を再起動します
構成をリセットするには、レプリカ セット内のすべてのノードが停止していることを確認してください。 次に、すべてのノードのローカル データベースを削除します。 –replSetフラグを使用して再度開始し、レプリカ セットの 1 つの mongod インスタンスのみでrs.initiate()を実行します。
mongod --replSet "rs0" rs.initiate()オプションのレプリカ セット構成ドキュメントを取得できます。つまり、次のようになります。
-
Replication.replSetNameまたは—replSetオプションを使用して、_idフィールドにレプリカ セット名を指定します。 - 各レプリカ セット メンバーの 1 つのドキュメントを含むメンバーの配列。
rs.initiate()メソッドは選出をトリガーし、メンバーの 1 つをプライマリに選出します。
メンバーをレプリカ セットに追加する
セットにメンバーを追加するには、さまざまなマシンで mongod インスタンスを開始します。 次に、mongo クライアントを起動し、 rs.add()コマンドを使用します。
rs.add()コマンドの基本的な構文は次のとおりです。
rs.add(HOST_NAME:PORT)例えば、
mongo1 が mongod インスタンスであり、ポート 27017 でリッスンしているとします。Mongo クライアント コマンドrs.add()を使用して、このインスタンスをレプリカ セットに追加します。
rs.add("mongo1:27017") プライマリ ノードに接続した後でのみ、mongod インスタンスをレプリカ セットに追加できます。 プライマリに接続されているかどうかを確認するには、コマンドdb.isMaster()を使用します。
ユーザーを削除
メンバーを削除するには、 rs.remove()を使用できます。
これを行うには、まず、上記で説明したdb.shutdownServer()メソッドを使用して、削除する mongod インスタンスをシャットダウンします。

次に、レプリカ セットの現在のプライマリに接続します。 現在のプライマリを確認するには、レプリカ セットの任意のメンバーに接続しているときにdb.hello()を使用します。 プライマリを決定したら、次のいずれかのコマンドを実行します。
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 
レプリカ セットが新しいプライマリを選択する必要がある場合、MongoDB はシェルを一時的に切断することがあります。 このシナリオでは、もう一度自動的に再接続します。 また、コマンドが成功してもDBClientCursor::init call() failed エラーが表示される場合があります。
方法 2: 展開とテスト用に MongoDB レプリカ セットを構成する
一般に、RBAC を有効または無効にして、テスト用のレプリカ セットを設定できます。 この方法では、テスト環境にデプロイするために、アクセス制御を無効にしてレプリカ セットをセットアップします。
まず、次のコマンドを使用して、レプリカ セットの一部であるすべてのインスタンスのディレクトリを作成します。
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2このコマンドは、3 つの MongoDB インスタンス、replicaset0-0、replicaset0-1、replicaset0-2 のディレクトリを作成します。 次に、次の一連のコマンドを使用して、それぞれの MongoDB インスタンスを開始します。
サーバー 1 の場合:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128サーバー 2 の場合:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128サーバー 3 の場合:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 –oplogSizeパラメーターは、テスト フェーズ中にマシンが過負荷になるのを防ぐために使用されます。 これにより、各ディスクが消費するディスク容量を削減できます。
次に、以下のポート番号を使用して接続することにより、Mongo シェルを使用してインスタンスの 1 つに接続します。
mongo --port 27017 rs.initiate()コマンドを使用して、レプリケーション プロセスを開始できます。 hostnameパラメーターをシステムの名前に置き換える必要があります。
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }構成オブジェクト ファイルを初期化コマンドのパラメーターとして渡し、次のように使用できます。
rs.initiate(rsconf)そして、あなたはそれを持っています! 開発およびテスト用の MongoDB レプリカ セットが正常に作成されました。
方法 3: スタンドアロン インスタンスを MongoDB レプリカ セットに変換する
MongoDB を使用すると、ユーザーはスタンドアロン インスタンスをレプリカ セットに変換できます。 スタンドアロン インスタンスは主にテストおよび開発段階で使用されますが、レプリカ セットは本番環境の一部です。
開始するには、次のコマンドを使用して mongod インスタンスをシャットダウンしましょう。
db.adminCommand({"shutdown":"1"}) コマンドで–repelSetパラメータを使用してインスタンスを再起動し、使用するレプリカ セットを指定します。
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>コマンドで一意のアドレスとともにサーバーの名前を指定する必要があります。
シェルを MongoDB インスタンスに接続し、initiate コマンドを使用してレプリケーション プロセスを開始し、インスタンスをレプリカ セットに正常に変換します。 次のコマンドを使用して、インスタンスの追加や削除などのすべての基本操作を実行できます。
rs.add(“<host_name:port>”) rs.remove(“host-name”) さらに、 rs.status()およびrs.conf()コマンドを使用して、MongoDB レプリカ セットのステータスを確認できます。
方法 4: MongoDB Atlas — よりシンプルな代替手段
レプリケーションとシャーディングは連携して、シャード クラスターと呼ばれるものを形成します。 セットアップと構成は簡単ですが、かなり時間がかかる場合がありますが、MongoDB Atlas は前述の方法よりも優れた代替手段です。
レプリカ セットを自動化し、プロセスの実装を容易にします。 数回クリックするだけでグローバルに分割されたレプリカ セットをデプロイできるため、災害復旧、管理の容易化、データの局所性、マルチリージョン デプロイが可能になります。
MongoDB Atlas では、クラスターを作成する必要があります。クラスターは、レプリカ セットまたはシャード クラスターのいずれかです。 特定のプロジェクトでは、他のリージョンのクラスター内のノード数は合計 40 に制限されています。
これには、無料または共有クラスターと、相互に通信する Google クラウド リージョンは含まれません。 任意の 2 つのリージョン間のノードの総数は、この制約を満たす必要があります。 たとえば、次のようなプロジェクトがあるとします。
- リージョン A には 15 個のノードがあります。
- リージョン B には 25 個のノードがあります
- リージョン C には 10 個のノードがあります
リージョン C にはあと 5 つのノードしか割り当てることができません。
- 地域 A + 地域 B = 40; 許可されるノードの最大数である 40 の制約を満たします。
- リージョン B+ リージョン C = 25+10+5 (C に割り当てられた追加ノード) = 40; 許可されるノードの最大数である 40 の制約を満たします。
- リージョン A+ リージョン C =15+10+5 (C に割り当てられた追加ノード) = 30; 許可されるノードの最大数である 40 の制約を満たします。
リージョン C にさらに 10 個のノードを割り当てて、リージョン C に 20 個のノードを持たせると、リージョン B + リージョン C = 45 ノードになります。 これは指定された制約を超えるため、マルチリージョン クラスタを作成できない場合があります。
クラスターを作成すると、Atlas はクラウド プロバイダーのプロジェクトにネットワーク コンテナーを作成します (以前はネットワーク コンテナーが存在しなかった場合)。 MongoDB Atlas でレプリカ セット クラスターを作成するには、Atlas CLI で次のコマンドを実行します。
atlas clusters create [name] [options]クラスターの作成後に変更することはできないため、わかりやすいクラスター名を付けてください。 引数には、ASCII 文字、数字、およびハイフンを含めることができます。
要件に基づいて、MongoDB でクラスターを作成するために使用できるオプションがいくつかあります。 たとえば、クラスターの継続的なクラウド バックアップが必要な場合は、 --backupを true に設定します。
レプリケーションの遅延への対処
レプリケーションの遅延は、非常に不快な場合があります。 これは、プライマリでの操作と、oplog からセカンダリへのその操作の適用との間の遅延です。 ビジネスで大規模なデータ セットを扱う場合、特定のしきい値内での遅延が予想されます。 ただし、外部要因が原因で遅延が増加する場合もあります。 最新のレプリケーションを利用するには、次のことを確認してください。
- 安定した十分な帯域幅でネットワーク トラフィックをルーティングします。 ネットワークの待ち時間はレプリケーションに大きな影響を与えます。ネットワークがレプリケーション プロセスのニーズに対応するには不十分な場合、レプリカ セット全体でデータのレプリケーションに遅延が発生します。
- 十分なディスク スループットがあります。 セカンダリのファイル システムとディスク デバイスがプライマリほど速くデータをディスクにフラッシュできない場合、セカンダリは追いつくのが難しくなります。 したがって、セカンダリ ノードは、プライマリ ノードよりも低速で書き込みクエリを処理します。 これは、仮想化されたインスタンスや大規模な展開など、ほとんどのマルチテナント システムで共通の問題です。
- 特にプライマリへの大量の書き込みを必要とするバルク ロード操作またはデータ インジェストを実行する場合は、セカンダリがプライマリに追いつく機会を提供するために、間隔の後に書き込み確認書き込み懸念を要求します。 セカンダリは、変更に追いつくのに十分な速さで oplog を読み取ることができません。 特に未確認の書き込みに関する懸念がある場合。
- 実行中のバックグラウンド タスクを特定します。 cron ジョブ、サーバーの更新、セキュリティ チェックなどの特定のタスクは、ネットワークやディスクの使用に予期しない影響を与え、レプリケーション プロセスの遅延を引き起こす可能性があります。
アプリケーションにレプリケーション ラグがあるかどうかわからない場合でも、心配する必要はありません。次のセクションでは、トラブルシューティング戦略について説明します。
MongoDB レプリカ セットのトラブルシューティング
レプリカ セットを正常にセットアップしましたが、データがサーバー間で一貫していないことに気付きました。 これは大規模なビジネスにとって非常に憂慮すべきことですが、迅速なトラブルシューティング方法を使用すると、原因を特定したり、問題を修正したりすることができます! 以下に、レプリカ セットの展開のトラブルシューティングに役立ついくつかの一般的な戦略を示します。
レプリカのステータスを確認する
レプリカ セットのプライマリに接続されている mongosh セッションで次のコマンドを実行すると、レプリカ セットの現在の状態と各メンバーの状態を確認できます。
rs.status()レプリケーション ラグを確認する
前述のように、レプリケーション ラグは深刻な問題になる可能性があります。これは、「ラグのある」メンバーをすぐにプライマリにする資格がなく、分散読み取り操作の一貫性が失われる可能性を高めるためです。 次のコマンドを使用して、レプリケーション ログの現在の長さを確認できます。
rs.printSecondaryReplicationInfo() これは、最後の oplog エントリが各メンバーのセカンダリに書き込まれた時刻であるsyncedTo値を返します。 同じことを示す例を次に示します。
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary プライマリの非アクティブ期間がmembers[n].secondaryDelaySecs値よりも長い場合、遅延メンバーはプライマリより 0 秒遅れて表示される場合があります。
すべてのメンバー間の接続をテストする
レプリカ セットの各メンバーは、他のすべてのメンバーと接続できる必要があります。 必ず両方向の接続を確認してください。 ほとんどの場合、ファイアウォール構成またはネットワーク トポロジによって、通常の必要な接続が妨げられ、レプリケーションがブロックされる可能性があります。
たとえば、mongod インスタンスが localhost と、IP アドレス 198.41.110.1 に関連付けられているホスト名「ExampleHostname」の両方にバインドされているとします。
mongod --bind_ip localhost, ExampleHostnameこのインスタンスに接続するには、リモート クライアントはホスト名または IP アドレスを指定する必要があります。
mongosh --host ExampleHostname mongosh --host 198.41.110.1レプリカ セットが m1、m2、および m3 の 3 つのメンバーで構成され、既定のポート 27017 を使用している場合は、次のように接続をテストする必要があります。
m1:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017m2:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017m3 の場合:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 いずれかの方向の接続が失敗した場合は、ファイアウォールの構成を確認し、接続を許可するように再構成する必要があります。
キーファイル認証による安全な通信の確保
デフォルトでは、MongoDB のキーファイル認証はソルト チャレンジ レスポンス認証メカニズム (SCRAM) に依存しています。 これを行うために、MongoDB は、特定の MongoDB インスタンスが認識しているユーザー名、パスワード、および認証データベースの組み合わせを含む、ユーザーが提供した資格情報を読み取って検証する必要があります。 これは、データベースへの接続時にパスワードを入力するユーザーを認証するために使用される正確なメカニズムです。
MongoDB で認証を有効にすると、ロールベースのアクセス制御 (RBAC) がレプリカ セットに対して自動的に有効になり、データベース リソースへのアクセスを決定する 1 つ以上のロールがユーザーに付与されます。 RBAC が有効になっている場合、適切な権限を持つ有効な認証済み Mongo ユーザーのみがシステム上のリソースにアクセスできることを意味します。
キーファイルは、クラスター内の各メンバーの共有パスワードのように機能します。 これにより、レプリカ セット内の各 mongod インスタンスは、デプロイ内の他のメンバーを認証するための共有パスワードとしてキーファイルの内容を使用できます。
正しいキーファイルを持つ mongod インスタンスのみがレプリカ セットに参加できます。 キーの長さは 6 ~ 1024 文字である必要があり、base64 セットの文字のみを含めることができます。 MongoDB は、キーを読み取るときに空白文字を削除することに注意してください。
さまざまな方法を使用してキーファイルを生成できます。 このチュートリアルでは、 opensslを使用して複雑な 1024 文字のランダム文字列を生成し、共有パスワードとして使用します。 次に、 chmodを使用してファイルのアクセス許可を変更し、ファイル所有者のみに読み取りアクセス許可を付与します。 Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. 例えば:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
そして出来上がり! You have successfully enabled keyfile authentication!
まとめ
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!