
MongoDB 데이터베이스를 만드는 방법: 알아야 할 6가지 중요한 측면
게시 됨: 2022-11-07소프트웨어 요구 사항에 따라 유연성, 확장성, 성능 또는 속도의 우선 순위를 지정할 수 있습니다. 따라서 개발자와 기업은 필요에 따라 데이터베이스를 선택하는 동안 종종 혼동을 겪습니다. 높은 유연성과 확장성을 제공하는 데이터베이스와 고객 분석을 위한 데이터 집계가 필요한 경우 MongoDB가 적합할 수 있습니다!
이 유용한 가이드
이 기사에서는 MongoDB 데이터베이스의 구조와 데이터베이스를 생성, 모니터링 및 관리하는 방법에 대해 설명합니다! 시작하자.
MongoDB 데이터베이스는 어떻게 구성되어 있습니까?
MongoDB는 스키마가 없는 NoSQL 데이터베이스입니다. 즉, SQL 데이터베이스에 대해 수행하는 것처럼 테이블/데이터베이스에 대한 구조를 지정하지 않습니다.
NoSQL 데이터베이스가 실제로 관계형 데이터베이스보다 빠르다는 사실을 알고 계셨습니까? 이는 인덱싱, 샤딩 및 집계 파이프라인과 같은 특성 때문입니다. MongoDB는 빠른 쿼리 실행으로도 유명합니다. 이것이 Google, Toyota 및 Forbes와 같은 회사에서 선호하는 이유입니다.
아래에서는 MongoDB의 몇 가지 주요 특성을 살펴보겠습니다.
서류
MongoDB에는 데이터를 JSON 문서로 저장하는 문서 데이터 모델이 있습니다. 문서는 응용 프로그램 코드의 개체에 자연스럽게 매핑되므로 개발자가 더 쉽게 사용할 수 있습니다.
관계형 데이터베이스 테이블에서 새 필드를 추가하려면 열을 추가해야 합니다. JSON 문서의 필드는 그렇지 않습니다. JSON 문서의 필드는 문서마다 다를 수 있으므로 데이터베이스의 모든 레코드에 추가되지는 않습니다.
문서는 계층적 관계를 표현하기 위해 중첩될 수 있는 배열과 같은 구조를 저장할 수 있습니다. 또한 MongoDB는 문서를 BSON(바이너리 JSON) 유형으로 변환합니다. 이것은 문자열, 정수, 부울 숫자 등과 같은 다양한 데이터 유형에 대한 더 빠른 액세스와 향상된 지원을 보장합니다!
복제본 세트
MongoDB에서 새 데이터베이스를 생성하면 시스템이 자동으로 데이터 복사본을 2개 이상 생성합니다. 이러한 복사본을 "복제본 세트"라고 하며 이들 간에 데이터를 지속적으로 복제하여 데이터 가용성을 향상시킵니다. 또한 시스템 장애 또는 계획된 유지 관리 중 가동 중지 시간에 대한 보호 기능을 제공합니다.
컬렉션
컬렉션은 하나의 데이터베이스와 연결된 문서 그룹입니다. 관계형 데이터베이스의 테이블과 유사합니다.
그러나 컬렉션은 훨씬 더 유연합니다. 우선 스키마에 의존하지 않습니다. 둘째, 문서의 데이터 유형이 같을 필요는 없습니다!
데이터베이스에 속한 컬렉션 목록을 보려면 listCollections 명령을 사용합니다.
집계 파이프라인
이 프레임워크를 사용하여 여러 연산자와 표현식을 묶을 수 있습니다. 모든 구조의 데이터를 처리, 변환 및 분석할 수 있으므로 유연합니다.
이 때문에 MongoDB는 150개의 연산자와 표현식에서 빠른 데이터 흐름과 기능을 허용합니다. 또한 여러 컬렉션의 결과를 유연하게 조합하는 Union 단계와 같은 여러 단계가 있습니다.
인덱스
MongoDB 문서의 모든 필드를 인덱싱하여 효율성을 높이고 쿼리 속도를 개선할 수 있습니다. 인덱싱은 인덱스를 스캔하여 검사하는 문서를 제한함으로써 시간을 절약합니다. 컬렉션의 모든 문서를 읽는 것보다 훨씬 낫지 않습니까?
여러 필드에 대한 복합 인덱스를 포함하여 다양한 인덱싱 전략을 사용할 수 있습니다. 예를 들어, 직원의 이름과 성을 별도의 필드에 포함하는 문서가 여러 개 있다고 가정해 보겠습니다. 이름과 성을 반환하려면 "성"과 "이름"을 모두 포함하는 인덱스를 만들 수 있습니다. 이것은 "성"에 하나의 색인을 갖고 "이름"에 다른 색인을 갖는 것보다 훨씬 낫습니다.
Performance Advisor와 같은 도구를 활용하여 인덱스의 이점을 얻을 수 있는 쿼리를 더 자세히 이해할 수 있습니다.
샤딩
샤딩은 단일 데이터 세트를 여러 데이터베이스에 분산합니다. 그런 다음 해당 데이터 세트를 여러 시스템에 저장하여 시스템의 총 저장 용량을 늘릴 수 있습니다. 이는 더 큰 데이터 세트를 더 작은 청크로 분할하여 다양한 데이터 노드에 저장하기 때문입니다.
MongoDB는 컬렉션 수준에서 데이터를 샤드하여 클러스터의 샤드 전체에 컬렉션의 문서를 배포합니다. 이는 아키텍처가 가장 큰 애플리케이션을 처리할 수 있도록 하여 확장성을 보장합니다.
MongoDB 데이터베이스를 만드는 방법
먼저 자신의 OS에 적합한 MongoDB 패키지를 설치해야 합니다. 'MongoDB 커뮤니티 서버 다운로드' 페이지로 이동합니다. 사용 가능한 옵션에서 최신 "버전", "패키지" 형식을 zip 파일로, "플랫폼"을 OS로 선택하고 아래와 같이 "다운로드"를 클릭합니다.
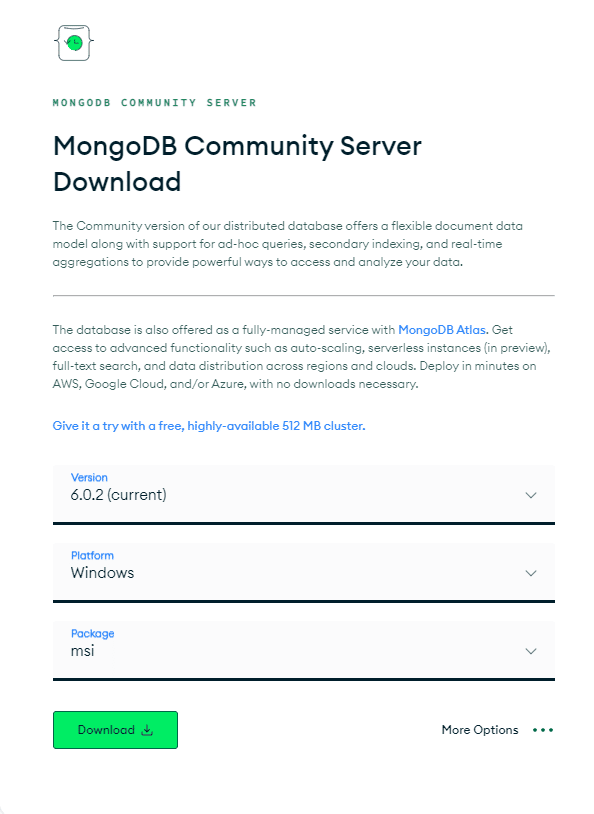
프로세스는 매우 간단하므로 즉시 시스템에 MongoDB를 설치할 수 있습니다!
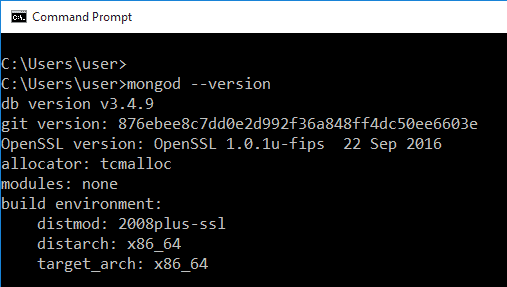
설치가 완료되면 명령 프롬프트를 열고 mongod -version 을 입력하여 확인합니다. 다음 출력이 표시되지 않고 대신 일련의 오류가 표시되면 다시 설치해야 할 수 있습니다.
MongoDB 셸 사용
시작하기 전에 다음을 확인하세요.
- 클라이언트에 Transport Layer Security가 있고 IP 허용 목록에 있습니다.
- 원하는 MongoDB 클러스터에 사용자 계정과 암호가 있습니다.
- 기기에 MongoDB를 설치했습니다.
1단계: MongoDB 셸에 액세스
MongoDB 셸에 액세스하려면 다음 명령을 입력하십시오.
net start MongoDB이렇게 하면 다음과 같은 출력이 표시됩니다.
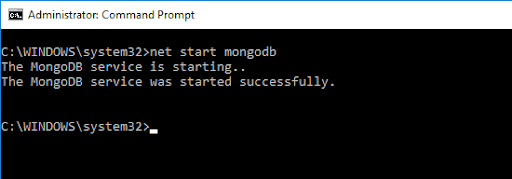
이전 명령은 MongoDB 서버를 초기화했습니다. 실행하려면 명령 프롬프트에 mongo 를 입력해야 합니다.
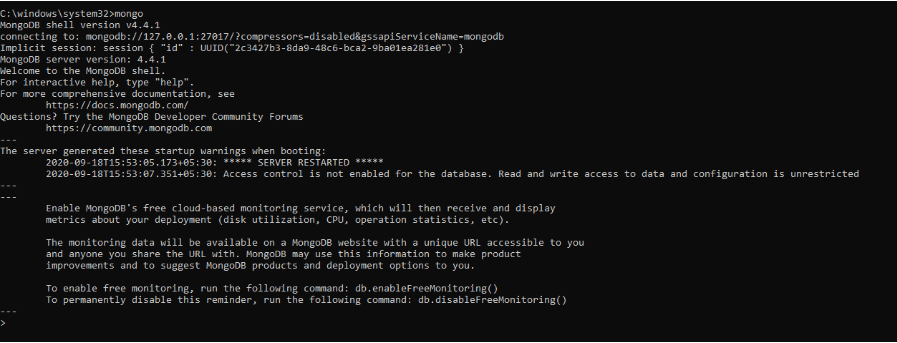
여기 MongoDB 셸에서 데이터베이스 생성, 데이터 삽입, 데이터 편집, 관리 명령 실행 및 데이터 삭제 명령을 실행할 수 있습니다.
2단계: 데이터베이스 생성
SQL과 달리 MongoDB에는 데이터베이스 생성 명령이 없습니다. 대신 지정된 데이터베이스로 전환하는 use 라는 키워드가 있습니다. 데이터베이스가 존재하지 않으면 새 데이터베이스를 만들고, 그렇지 않으면 기존 데이터베이스에 연결합니다.
예를 들어, "회사"라는 데이터베이스를 시작하려면 다음을 입력하십시오.
use Company 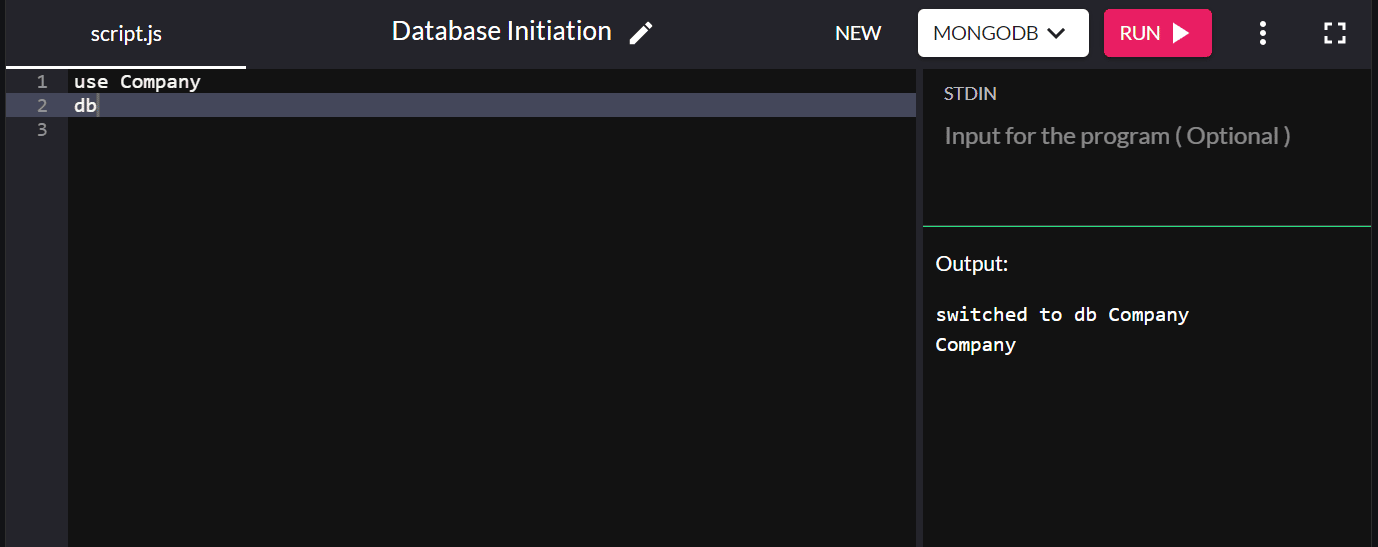
db 를 입력하여 시스템에서 방금 생성한 데이터베이스를 확인할 수 있습니다. 생성한 새 데이터베이스가 나타나면 성공적으로 연결된 것입니다.
기존 데이터베이스를 확인하려면 show dbs 를 입력하면 시스템의 모든 데이터베이스가 반환됩니다.
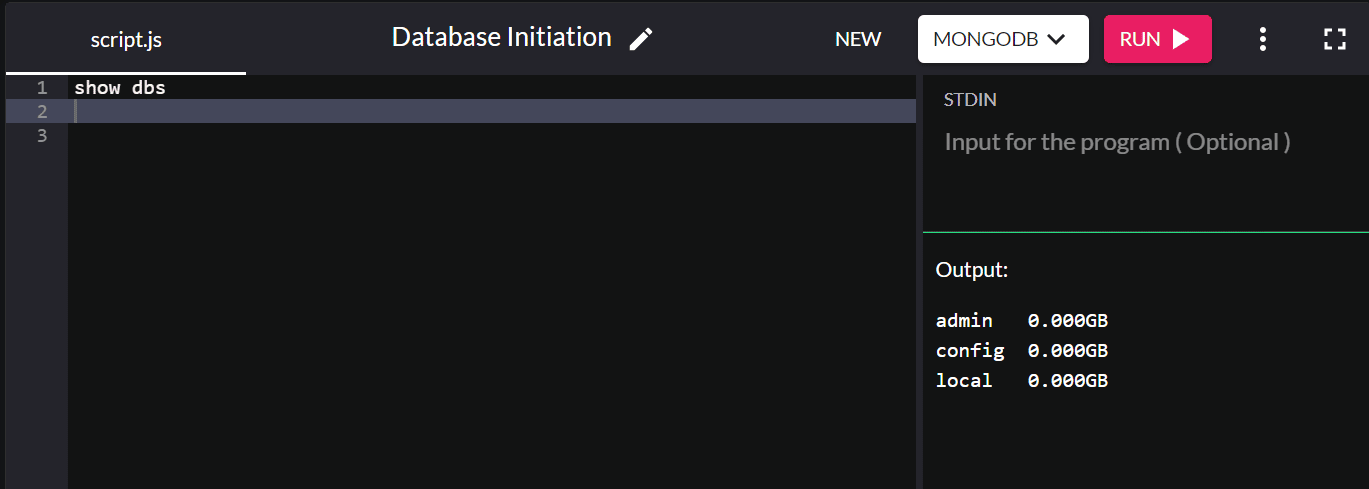
기본적으로 MongoDB를 설치하면 관리, 구성 및 로컬 데이터베이스가 생성됩니다.
우리가 만든 데이터베이스가 표시되지 않는 것을 눈치채셨나요? 아직 데이터베이스에 값을 저장하지 않았기 때문입니다! 데이터베이스 관리 섹션에서 삽입에 대해 논의할 것입니다.
아틀라스 UI 사용
MongoDB의 데이터베이스 서비스인 Atlas를 시작할 수도 있습니다. Atlas의 일부 기능에 액세스하려면 비용을 지불해야 할 수도 있지만 대부분의 데이터베이스 기능은 프리 티어로 사용할 수 있습니다. 프리 티어의 기능은 MongoDB 데이터베이스를 생성하기에 충분합니다.
시작하기 전에 다음을 확인하세요.
- 귀하의 IP가 허용 목록에 있습니다.
- 사용하려는 MongoDB 클러스터에 사용자 계정과 암호가 있습니다.
AtlasUI로 MongoDB 데이터베이스를 생성하려면 브라우저 창을 열고 https://cloud.mongodb.com에 로그인합니다. 클러스터 페이지에서 컬렉션 찾아보기 를 클릭합니다. 클러스터에 데이터베이스가 없으면 내 데이터 추가 버튼을 클릭하여 데이터베이스를 생성할 수 있습니다.
데이터베이스와 컬렉션 이름을 제공하라는 프롬프트가 표시됩니다. 이름을 지정한 후 만들기 를 클릭하면 완료됩니다! 이제 새 문서를 입력하거나 드라이버를 사용하여 데이터베이스에 연결할 수 있습니다.
MongoDB 데이터베이스 관리
이 섹션에서는 MongoDB 데이터베이스를 효과적으로 관리하는 몇 가지 유용한 방법을 살펴보겠습니다. MongoDB Compass를 사용하거나 컬렉션을 통해 이를 수행할 수 있습니다.
컬렉션 사용
관계형 데이터베이스에는 데이터 유형과 열이 지정된 잘 정의된 테이블이 있지만 NoSQL에는 테이블 대신 컬렉션이 있습니다. 이러한 컬렉션에는 구조가 없으며 문서는 다양할 수 있습니다. 동일한 컬렉션에서 다른 문서의 형식과 일치하지 않고도 다른 데이터 유형 및 필드를 가질 수 있습니다.
시연하기 위해 "Employee"라는 컬렉션을 만들고 여기에 문서를 추가해 보겠습니다.
db.Employee.insert( { "Employeename" : "Chris", "EmployeeDepartment" : "Sales" } ) 삽입이 성공하면 WriteResult({ "nInserted" : 1 }) 를 반환합니다.
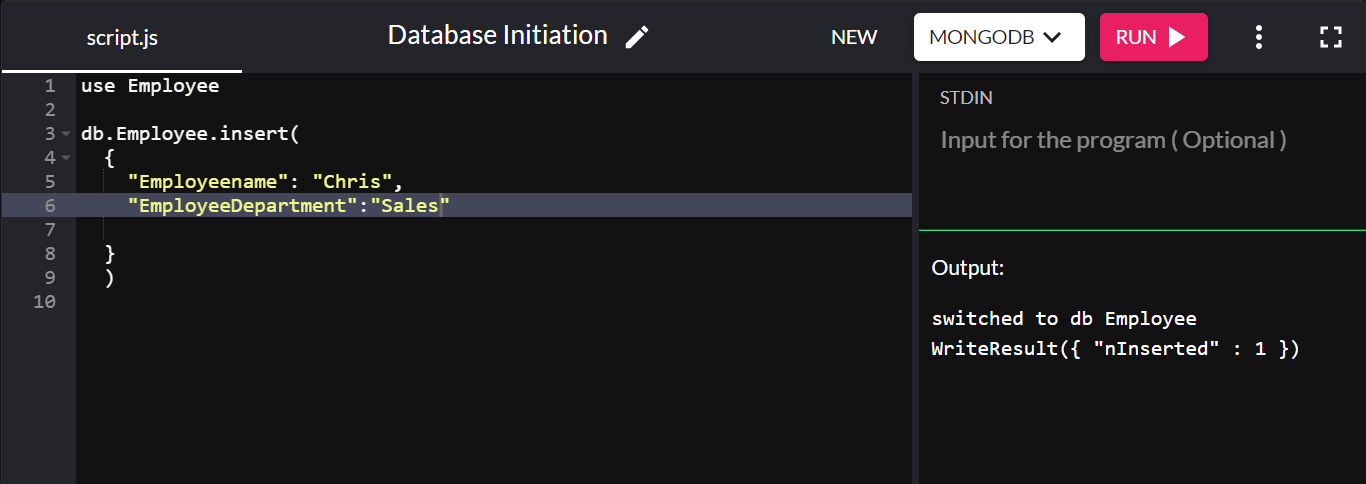
여기서 "db"는 현재 연결된 데이터베이스를 의미합니다. "Employee"는 회사 데이터베이스에서 새로 생성된 컬렉션입니다.
MongoDB는 "_id"라는 기본 키 필드를 자동으로 생성하고 기본값을 설정하기 때문에 여기서는 기본 키를 설정하지 않았습니다.
JSON 형식의 컬렉션을 확인하려면 아래 명령을 실행합니다.
db.Employee.find().forEach(printjson)산출:
{ "_id" : ObjectId("63151427a4dd187757d135b8"), "Employeename" : "Chris", "EmployeeDepartment" : "Sales" }"_id" 값이 자동으로 할당되는 동안 기본 기본 키의 값을 변경할 수 있습니다. 이번에는 "_id" 값이 "1"인 다른 문서를 "Employee" 데이터베이스에 삽입합니다.
db.Employee.insert( { "_id" : 1, "EmployeeName" : "Ava", "EmployeeDepartment" : "Public Relations" } ) db.Employee.find().forEach(printjson) 명령을 실행하면 다음 출력을 얻습니다.
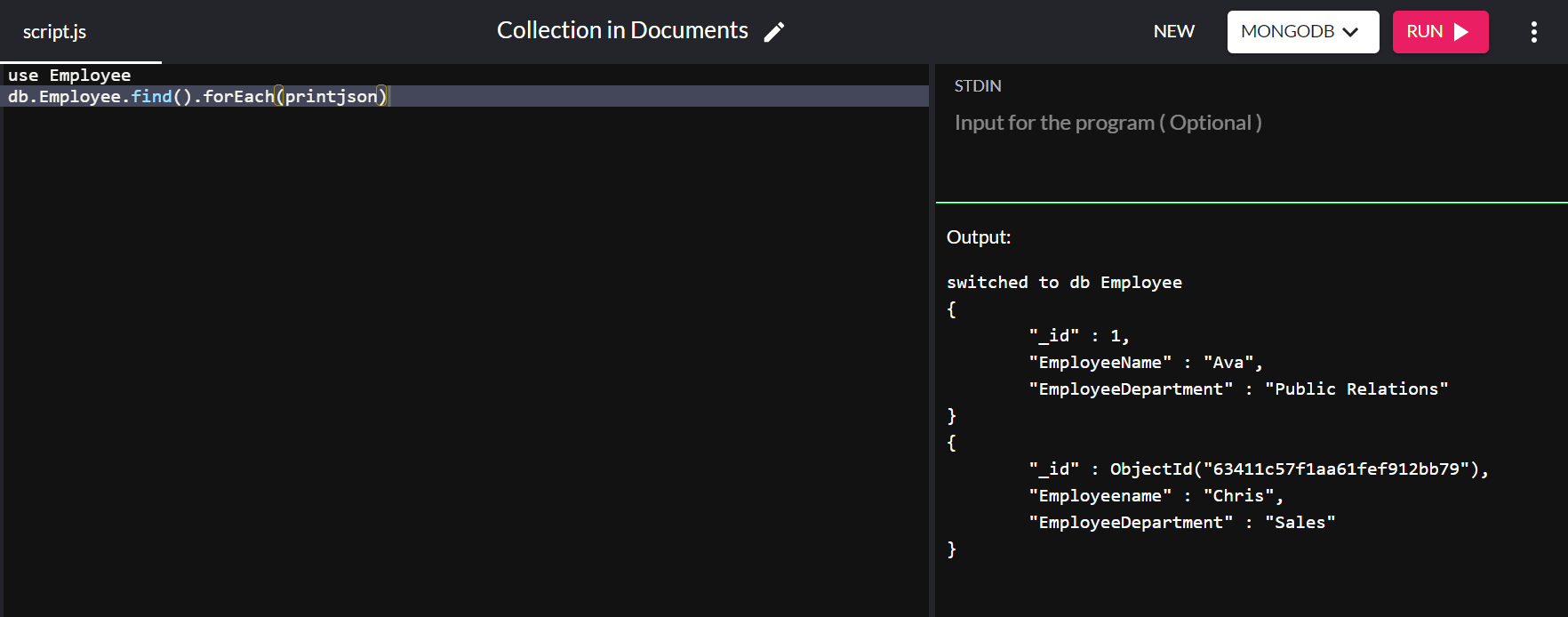
위의 출력에서 "Ava"에 대한 "_id" 값은 자동으로 값이 할당되는 대신 "1"로 설정됩니다.
이제 데이터베이스에 값을 성공적으로 추가했으므로 다음 명령을 사용하여 시스템의 기존 데이터베이스 아래에 값이 표시되는지 확인할 수 있습니다.
show dbs 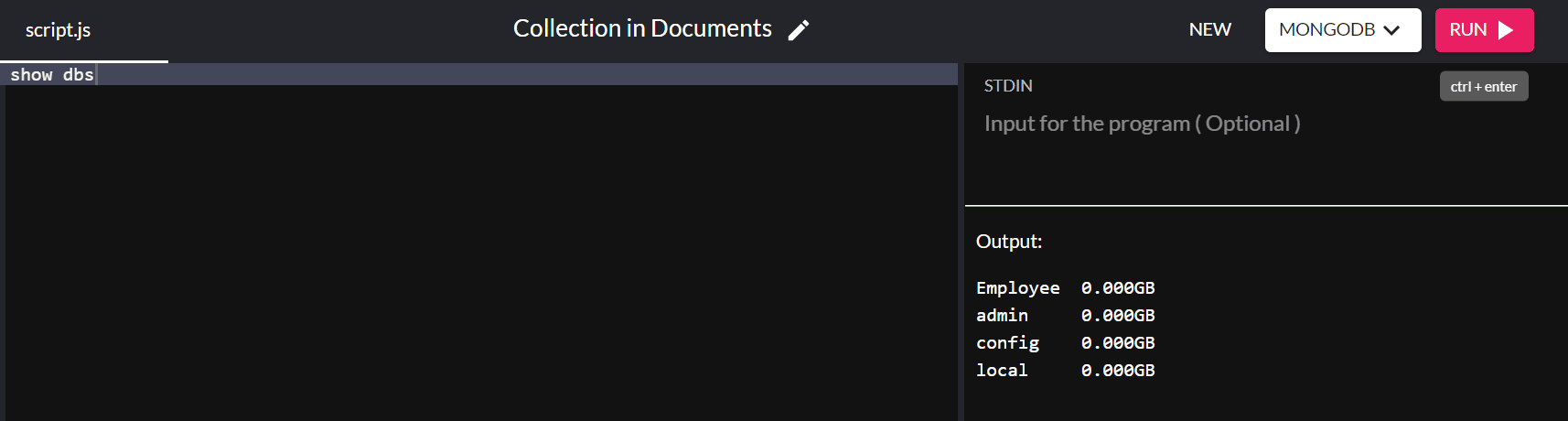
그리고 짜잔! 시스템에 데이터베이스를 성공적으로 생성했습니다!
MongoDB 나침반 사용
Mongo 셸에서 MongoDB 서버로 작업할 수 있지만 때로는 지루할 수 있습니다. 프로덕션 환경에서 이를 경험할 수 있습니다.
그러나 더 쉽게 만들 수 있는 MongoDB에서 만든 나침반 도구(적절하게 나침반이라는 이름이 지정됨)가 있습니다. 더 나은 GUI와 데이터 시각화, 성능 프로파일링 및 데이터, 데이터베이스 및 컬렉션에 대한 CRUD(생성, 읽기, 업데이트, 삭제) 액세스와 같은 기능이 추가되었습니다.
OS용 Compass IDE를 다운로드하고 간단한 프로세스로 설치할 수 있습니다.
그런 다음 응용 프로그램을 열고 연결 문자열을 붙여넣어 서버와의 연결을 만듭니다. 찾을 수 없으면 연결 필드를 개별적으로 채우기 를 클릭할 수 있습니다. MongoDB를 설치하는 동안 포트 번호를 변경하지 않았다면 연결 버튼을 클릭하기만 하면 됩니다! 그렇지 않으면 설정한 값을 입력하고 연결 을 클릭하기만 하면 됩니다.
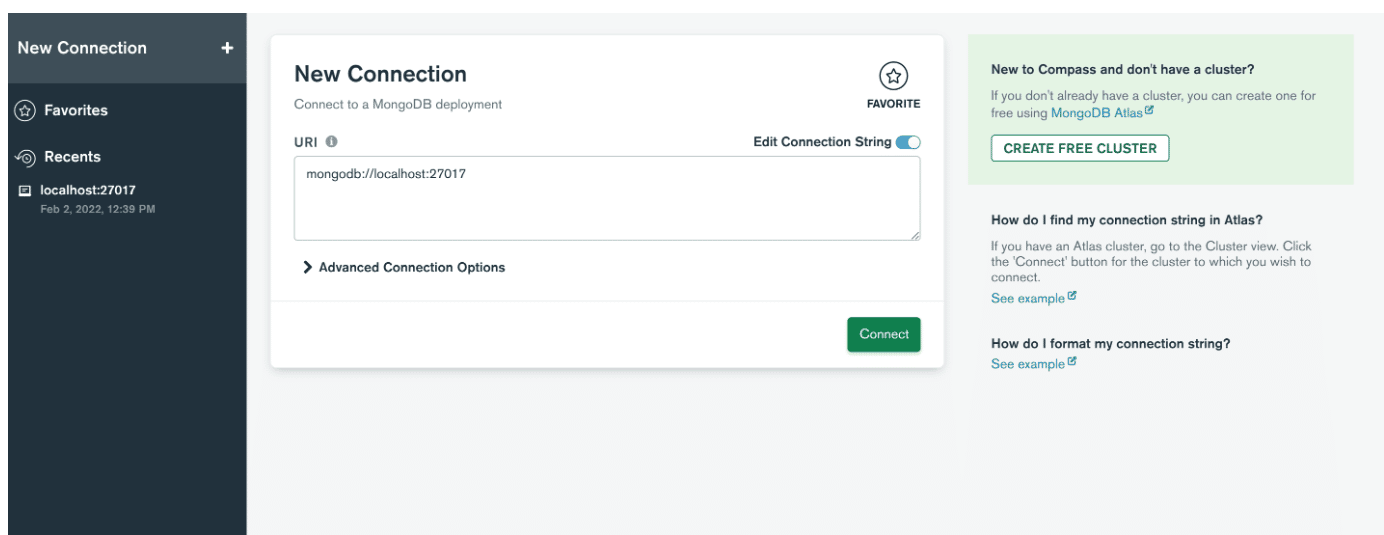
그런 다음 새 연결 창에서 호스트 이름, 포트 및 인증을 제공합니다.
MongoDB Compass에서는 데이터베이스를 생성하고 첫 번째 컬렉션을 동시에 추가할 수 있습니다. 방법은 다음과 같습니다.
- 데이터베이스 생성 을 클릭하여 프롬프트를 엽니다.
- 데이터베이스의 이름과 첫 번째 컬렉션을 입력합니다.
- 데이터베이스 만들기 를 클릭합니다.
데이터베이스 이름을 클릭한 다음 컬렉션 이름을 클릭하여 문서 탭을 표시하면 데이터베이스에 더 많은 문서를 삽입할 수 있습니다. 그런 다음 데이터 추가 버튼을 클릭하여 컬렉션에 하나 이상의 문서를 삽입할 수 있습니다.
문서를 추가하는 동안 한 번에 하나씩 입력하거나 배열에 여러 문서로 입력할 수 있습니다. 여러 문서를 추가하는 경우 이러한 쉼표로 구분된 문서를 대괄호로 묶어야 합니다. 예를 들어:
{ _id: 1, item: { name: "apple", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }, { _id: 2, item: { name: "banana", code: "123" }, qty: 20, tags: [ "B" ] }, { _id: 3, item: { name: "spinach", code: "456" }, qty: 25, tags: [ "A", "B" ] }, { _id: 4, item: { name: "lentils", code: "456" }, qty: 30, tags: [ "B", "A" ] }, { _id: 5, item: { name: "pears", code: "000" }, qty: 20, tags: [ [ "A", "B" ], "C" ] }, { _id: 6, item: { name: "strawberry", code: "123" }, tags: [ "B" ] }마지막으로 삽입 을 클릭하여 문서를 컬렉션에 추가합니다. 문서 본문은 다음과 같습니다.
{ "StudentID" : 1 "StudentName" : "JohnDoe" }여기에서 필드 이름은 "StudentID" 및 "StudentName"입니다. 필드 값은 각각 "1" 및 "JohnDoe"입니다.
유용한 명령
역할 관리 및 사용자 관리 명령을 통해 이러한 컬렉션을 관리할 수 있습니다.
사용자 관리 명령
MongoDB 사용자 관리 명령에는 사용자와 관련된 명령이 포함되어 있습니다. 이러한 명령을 사용하여 사용자를 생성, 업데이트 및 삭제할 수 있습니다.
dropUser
이 명령은 지정된 데이터베이스에서 단일 사용자를 제거합니다. 다음은 구문입니다.
db.dropUser(username, writeConcern) 여기서 username 은 사용자에 대한 인증 및 액세스 정보가 포함된 문서를 포함하는 필수 필드입니다. 선택적 필드 writeConcern 에는 생성 작업에 대한 쓰기 우려 수준이 포함됩니다. 쓰기 우려 수준은 선택적 필드 writeConcern 에 의해 결정될 수 있습니다.
userAdminAnyDatabase 역할이 있는 사용자를 삭제하기 전에 사용자 관리 권한이 있는 다른 사용자가 한 명 이상 있는지 확인하십시오.
이 예에서는 테스트 데이터베이스에 사용자 "user26"을 삭제합니다.
use test db.dropUser("user26", {w: "majority", wtimeout: 4000})산출:
> db.dropUser("user26", {w: "majority", wtimeout: 4000}); true사용자 생성
이 명령은 다음과 같이 지정된 데이터베이스에 대한 새 사용자를 생성합니다.
db.createUser(user, writeConcern) 여기서 user 는 생성하고자 하는 사용자에 대한 인증 및 접근 정보가 포함된 문서를 포함하는 필수 필드입니다. 선택적 필드 writeConcern 에는 생성 작업에 대한 쓰기 우려 수준이 포함됩니다. 쓰기 우려 수준은 선택적 필드인 writeConcern 으로 결정할 수 있습니다.
createUser 는 사용자가 데이터베이스에 이미 존재하는 경우 중복 사용자 오류를 반환합니다.
다음과 같이 테스트 데이터베이스에 새 사용자를 만들 수 있습니다.
use test db.createUser( { user: "user26", pwd: "myuser123", roles: [ "readWrite" ] } );출력은 다음과 같습니다.
Successfully added user: { "user" : "user26", "roles" : [ "readWrite", "dbAdmin" ] }권한 부여
이 명령을 활용하여 사용자에게 추가 역할을 부여할 수 있습니다. 이를 사용하려면 다음 구문을 염두에 두어야 합니다.
db.runCommand( { grantRolesToUser: "<user>", roles: [ <roles> ], writeConcern: { <write concern> }, comment: <any> } ) 위에서 언급한 역할에서 사용자 정의 역할과 기본 제공 역할을 모두 지정할 수 있습니다. grantRolesToUser 가 실행되는 동일한 데이터베이스에 존재하는 역할을 지정하려는 경우 아래에 언급된 대로 문서로 역할을 지정할 수 있습니다.
{ role: "<role>", db: "<database>" }또는 단순히 역할 이름으로 역할을 지정할 수 있습니다. 예를 들어:
"readWrite"다른 데이터베이스에 있는 역할을 지정하려면 다른 문서로 역할을 지정해야 합니다.
데이터베이스에 대한 역할을 부여하려면 지정된 데이터베이스에 대한 grantRole 작업이 필요합니다.
다음은 명확한 그림을 제공하는 예입니다. 예를 들어 다음 역할을 가진 제품 데이터베이스의 사용자 productUser00을 가정합니다.
"roles" : [ { "role" : "assetsWriter", "db" : "assets" } ] grantRolesToUser 작업은 재고 데이터베이스에 대한 readWrite 역할과 제품 데이터베이스에 대한 읽기 역할을 "productUser00"에 제공합니다.
use products db.runCommand({ grantRolesToUser: "productUser00", roles: [ { role: "readWrite", db: "stock"}, "read" ], writeConcern: { w: "majority" , wtimeout: 2000 } })제품 데이터베이스의 사용자 productUser00은 이제 다음 역할을 가집니다.
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ]사용자 정보
usersInfo 명령을 사용하여 한 명 이상의 사용자에 대한 정보를 반환할 수 있습니다. 구문은 다음과 같습니다.
db.runCommand( { usersInfo: <various>, showCredentials: <Boolean>, showCustomData: <Boolean>, showPrivileges: <Boolean>, showAuthenticationRestrictions: <Boolean>, filter: <document>, comment: <any> } ) { usersInfo: <various> } 접근 측면에서 사용자는 항상 자신의 정보를 볼 수 있습니다. 다른 사용자의 정보를 보려면 명령을 실행하는 사용자에게 다른 사용자의 데이터베이스에 대한 viewUser 작업을 포함하는 권한이 있어야 합니다.
userInfo 명령을 실행하면 지정된 옵션에 따라 다음 정보를 얻을 수 있습니다.
{ "users" : [ { "_id" : "<db>.<username>", "userId" : <UUID>, // Starting in MongoDB 4.0.9 "user" : "<username>", "db" : "<db>", "mechanisms" : [ ... ], // Starting in MongoDB 4.0 "customData" : <document>, "roles" : [ ... ], "credentials": { ... }, // only if showCredentials: true "inheritedRoles" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedPrivileges" : [ ... ], // only if showPrivileges: true or showAuthenticationRestrictions: true "inheritedAuthenticationRestrictions" : [ ] // only if showPrivileges: true or showAuthenticationRestrictions: true "authenticationRestrictions" : [ ... ] // only if showAuthenticationRestrictions: true }, ], "ok" : 1 } 이제 usersInfo 명령을 사용하여 수행할 수 있는 작업에 대한 일반적인 아이디어를 얻었으므로 다음 질문이 나타날 수 있습니다. 특정 사용자와 여러 사용자를 확인하는 데 어떤 명령이 유용할까요?
다음은 동일한 것을 설명하는 두 가지 편리한 예입니다.
"office" 데이터베이스에 정의된 "Anthony" 사용자에 대해 자격 증명이 아닌 특정 사용자에 대한 특정 권한 및 정보를 보려면 다음 명령을 실행합니다.
db.runCommand( { usersInfo: { user: "Anthony", db: "office" }, showPrivileges: true } )현재 데이터베이스에 있는 사용자를 보고 싶다면 이름으로만 사용자를 언급할 수 있습니다. 예를 들어 홈 데이터베이스에 있고 "Timothy"라는 사용자가 홈 데이터베이스에 있는 경우 다음 명령을 실행할 수 있습니다.
db.getSiblingDB("home").runCommand( { usersInfo: "Timothy", showPrivileges: true } ) 다음으로 다양한 사용자에 대한 정보를 보고 싶다면 배열을 사용할 수 있습니다. 옵션 필드인 showCredentials 및 showPrivileges 를 포함하거나 제외하도록 선택할 수 있습니다. 명령은 다음과 같습니다.
db.runCommand({ usersInfo: [ { user: "Anthony", db: "office" }, { user: "Timothy", db: "home" } ], showPrivileges: true })취소RolesFromUser
revokeRolesFromUser 명령을 활용하여 역할이 있는 데이터베이스의 사용자로부터 하나 이상의 역할을 제거할 수 있습니다. revokeRolesFromUser 명령의 구문은 다음과 같습니다.
db.runCommand( { revokeRolesFromUser: "<user>", roles: [ { role: "<role>", db: "<database>" } | "<role>", ], writeConcern: { <write concern> }, comment: <any> } ) 위에서 언급한 구문에서 사용자 정의 역할과 기본 역할을 모두 roles 필드에 지정할 수 있습니다. grantRolesToUser 명령과 유사하게 문서에서 취소하려는 역할을 지정하거나 해당 이름을 사용할 수 있습니다.
revokeRolesFromUser 명령을 성공적으로 실행하려면 지정된 데이터베이스에 대해 revokeRole 작업이 있어야 합니다.
다음은 포인트를 집으로 운전하는 예입니다. 제품 데이터베이스의 productUser00 엔터티에는 다음과 같은 역할이 있습니다.
"roles" : [ { "role" : "assetsWriter", "db" : "assets" }, { "role" : "readWrite", "db" : "stock" }, { "role" : "read", "db" : "products" } ] 다음 revokeRolesFromUser 명령은 두 가지 사용자 역할, 즉 products 에서 "읽기" 역할을 제거하고 "자산" 데이터베이스에서 assetsWriter 역할을 제거합니다.
use products db.runCommand( { revokeRolesFromUser: "productUser00", roles: [ { role: "AssetsWriter", db: "assets" }, "read" ], writeConcern: { w: "majority" } } )제품 데이터베이스의 사용자 "productUser00"은 이제 하나의 역할만 남습니다.
"roles" : [ { "role" : "readWrite", "db" : "stock" } ]역할 관리 명령
역할은 사용자에게 리소스에 대한 액세스 권한을 부여합니다. 관리자는 여러 기본 제공 역할을 사용하여 MongoDB 시스템에 대한 액세스를 제어할 수 있습니다. 역할이 원하는 권한을 포함하지 않는 경우 더 나아가 특정 데이터베이스에서 새 역할을 생성할 수도 있습니다.
dropRole
dropRole 명령을 사용하면 명령을 실행하는 데이터베이스에서 사용자 정의 역할을 삭제할 수 있습니다. 이 명령을 실행하려면 다음 구문을 사용하십시오.
db.runCommand( { dropRole: "<role>", writeConcern: { <write concern> }, comment: <any> } ) 성공적인 실행을 위해서는 지정된 데이터베이스에 대해 dropRole 작업이 있어야 합니다. 다음 작업은 "products" 데이터베이스에서 writeTags 역할을 제거합니다.

use products db.runCommand( { dropRole: "writeTags", writeConcern: { w: "majority" } } )역할 만들기
createRole 명령을 활용하여 역할을 생성하고 권한을 지정할 수 있습니다. 역할은 명령을 실행하도록 선택한 데이터베이스에 적용됩니다. 데이터베이스에 역할이 이미 있는 경우 createRole 명령은 중복 역할 오류를 반환합니다.
이 명령을 실행하려면 주어진 구문을 따르십시오:
db.adminCommand( { createRole: "<new role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], roles: [ { role: "<role>", db: "<database>" } | "<role>", ], authenticationRestrictions: [ { clientSource: ["<IP>" | "<CIDR range>", ...], serverAddress: ["<IP>" | "<CIDR range>", ...] }, ], writeConcern: <write concern document>, comment: <any> } )역할의 권한은 역할이 생성된 데이터베이스에 적용됩니다. 역할은 데이터베이스의 다른 역할에서 권한을 상속할 수 있습니다. 예를 들어, "admin" 데이터베이스에 대한 역할에는 클러스터 또는 모든 데이터베이스에 적용되는 권한이 포함될 수 있습니다. 또한 다른 데이터베이스에 있는 역할에서 권한을 상속할 수도 있습니다.
데이터베이스에서 역할을 생성하려면 다음 두 가지가 필요합니다.
- 해당 데이터베이스에 대한
grantRole작업은 새 역할에 대한 권한을 언급하고 상속할 역할을 언급합니다. - 해당 데이터베이스 리소스에 대한
createRole작업입니다.
다음 createRole 명령은 사용자 데이터베이스에 대해 clusterAdmin 역할을 생성합니다.
db.adminCommand({ createRole: "clusterAdmin", privileges: [ { resource: { cluster: true }, actions: [ "addShard" ] }, { resource: { db: "config", collection: "" }, actions: [ "find", "remove" ] }, { resource: { db: "users", collection: "usersCollection" }, actions: [ "update", "insert" ] }, { resource: { db: "", collection: "" }, actions: [ "find" ] } ], roles: [ { role: "read", db: "user" } ], writeConcern: { w: "majority" , wtimeout: 5000 } })권한 부여 역할
grantRolesToRole 명령을 사용하여 사용자 정의 역할에 역할을 부여할 수 있습니다. grantRolesToRole 명령은 명령이 실행되는 데이터베이스의 역할에 영향을 미칩니다.
이 grantRolesToRole 명령의 구문은 다음과 같습니다.
db.runCommand( { grantRolesToRole: "<role>", roles: [ { role: "<role>", db: "<database>" }, ], writeConcern: { <write concern> }, comment: <any> } ) 액세스 권한은 grantRolesToUser 명령과 유사합니다. 명령을 올바르게 실행하려면 데이터베이스에 대한 grantRole 작업이 필요합니다.
다음 예에서는 grantRolesToUser 명령을 사용하여 "products" 데이터베이스의 productsReader 역할을 업데이트하여 productsReader 역할의 권한을 상속할 수 productsWriter .
use products db.runCommand( { grantRolesToRole: "productsReader", roles: [ "productsWriter" ], writeConcern: { w: "majority" , wtimeout: 5000 } } )권한 취소
revokePrivilegesFromRole 을 사용하여 명령이 실행되는 데이터베이스의 사용자 정의 역할에서 지정된 권한을 제거할 수 있습니다. 적절한 실행을 위해서는 다음 구문을 염두에 두어야 합니다.
db.runCommand( { revokePrivilegesFromRole: "<role>", privileges: [ { resource: { <resource> }, actions: [ "<action>", ... ] }, ], writeConcern: <write concern document>, comment: <any> } )권한을 취소하려면 "리소스 문서" 패턴이 해당 권한의 "리소스" 필드와 일치해야 합니다. "actions" 필드는 정확히 일치하거나 하위 집합일 수 있습니다.
예를 들어, "managers" 데이터베이스를 리소스로 지정하는 다음 권한이 있는 제품 데이터베이스의 manageRole 역할을 고려하십시오.
{ "resource" : { "db" : "managers", "collection" : "" }, "actions" : [ "insert", "remove" ] }관리자 데이터베이스의 한 컬렉션에서만 "삽입" 또는 "제거" 작업을 취소할 수 없습니다. 다음 작업은 역할을 변경하지 않습니다.
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert", "remove" ] } ] } ) db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "kiosks" }, actions : [ "insert" ] } ] } ) manageRole 역할에서 "삽입" 및/또는 "제거" 작업을 취소하려면 리소스 문서를 정확히 일치시켜야 합니다. 예를 들어 다음 작업은 기존 권한에서 "제거" 작업만 취소합니다.
use managers db.runCommand( { revokePrivilegesFromRole: "manageRole", privileges: [ { resource : { db : "managers", collection : "" }, actions : [ "remove" ] } ] } )다음 작업은 관리자 데이터베이스의 "실행" 역할에서 여러 권한을 제거합니다.
use managers db.runCommand( { revokePrivilegesFromRole: "executive", privileges: [ { resource: { db: "managers", collection: "" }, actions: [ "insert", "remove", "find" ] }, { resource: { db: "managers", collection: "partners" }, actions: [ "update" ] } ], writeConcern: { w: "majority" } } )역할정보
rolesInfo 명령은 기본 제공 역할과 사용자 정의 역할을 모두 포함하여 지정된 역할에 대한 권한 및 상속 정보를 반환합니다. 또한 rolesInfo 명령을 활용하여 데이터베이스로 범위가 지정된 모든 역할을 검색할 수 있습니다.
적절한 실행을 위해 다음 구문을 따르십시오.
db.runCommand( { rolesInfo: { role: <name>, db: <db> }, showPrivileges: <Boolean>, showBuiltinRoles: <Boolean>, comment: <any> } )현재 데이터베이스에서 역할에 대한 정보를 반환하려면 다음과 같이 이름을 지정할 수 있습니다.
{ rolesInfo: "<rolename>" }다른 데이터베이스에서 역할에 대한 정보를 반환하려면 역할과 데이터베이스를 언급하는 문서와 함께 역할을 언급할 수 있습니다.
{ rolesInfo: { role: "<rolename>", db: "<database>" } }예를 들어 다음 명령은 관리자 데이터베이스에 정의된 역할 집행자에 대한 역할 상속 정보를 반환합니다.
db.runCommand( { rolesInfo: { role: "executive", db: "managers" } } ) 다음 명령은 명령이 실행되는 데이터베이스의 accountManager 역할 상속 정보를 반환합니다.
db.runCommand( { rolesInfo: "accountManager" } )다음 명령은 관리자 데이터베이스에 정의된 "임원" 역할에 대한 권한과 역할 상속을 모두 반환합니다.
db.runCommand( { rolesInfo: { role: "executive", db: "managers" }, showPrivileges: true } )여러 역할을 언급하기 위해 배열을 사용할 수 있습니다. 배열의 각 역할을 문자열이나 문서로 언급할 수도 있습니다.
명령이 실행되는 데이터베이스에 역할이 있는 경우에만 문자열을 사용해야 합니다.
{ rolesInfo: [ "<rolename>", { role: "<rolename>", db: "<database>" }, ] }예를 들어 다음 명령은 세 개의 서로 다른 데이터베이스에 대한 세 가지 역할에 대한 정보를 반환합니다.
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ] } )다음과 같이 권한과 역할 상속을 모두 얻을 수 있습니다.
db.runCommand( { rolesInfo: [ { role: "executive", db: "managers" }, { role: "accounts", db: "departments" }, { role: "administrator", db: "products" } ], showPrivileges: true } )성능 향상을 위한 MongoDB 문서 포함
MongoDB와 같은 문서 데이터베이스를 사용하면 필요에 따라 스키마를 정의할 수 있습니다. MongoDB에서 최적의 스키마를 생성하기 위해 문서를 중첩할 수 있습니다. 따라서 애플리케이션을 데이터 모델과 일치시키는 대신 사용 사례와 일치하는 데이터 모델을 구축할 수 있습니다.
포함된 문서를 사용하면 함께 액세스하는 관련 데이터를 저장할 수 있습니다. MongoDB용 스키마를 설계하는 동안 기본적으로 문서를 포함하는 것이 좋습니다. 가치가 있을 때만 데이터베이스 측 또는 애플리케이션 측 조인 및 참조를 사용하십시오.
워크로드가 필요한 만큼 자주 문서를 검색할 수 있는지 확인하십시오. 동시에 문서에는 필요한 모든 데이터도 있어야 합니다. 이는 애플리케이션의 탁월한 성능에 매우 중요합니다.
아래에서 문서를 포함하는 몇 가지 다른 패턴을 찾을 수 있습니다.
포함된 문서 패턴
이를 사용하여 사용되는 문서에 복잡한 하위 구조도 포함할 수 있습니다. 연결된 데이터를 단일 문서에 포함하면 데이터를 가져오는 데 필요한 읽기 작업 수를 줄일 수 있습니다. 일반적으로 애플리케이션이 단일 읽기 작업으로 필요한 모든 정보를 받도록 스키마를 구조화해야 합니다. 따라서 여기에서 염두에 두어야 할 규칙은 함께 사용되는 것은 함께 저장해야 한다는 것 입니다.
임베디드 서브세트 패턴
임베디드 서브세트 패턴은 하이브리드 케이스입니다. 관련 항목의 긴 목록을 별도로 수집하는 데 사용하면 표시할 항목 중 일부를 가까이에 둘 수 있습니다.
다음은 영화 리뷰를 나열하는 예입니다.
> db.movie.findOne() { _id: 321475, title: "The Dark Knight" } > db.review.find({movie_id: 321475}) { _id: 264579, movie_id: 321475, stars: 4 text: "Amazing" } { _id: 375684, movie_id: 321475, stars:5, text: "Mindblowing" }이제 수천 개의 유사한 리뷰를 상상해 보세요. 하지만 영화를 상영할 때 가장 최근의 리뷰 두 개만 표시할 계획입니다. 이 시나리오에서는 해당 하위 집합을 영화 문서 내에서 목록으로 저장하는 것이 좋습니다.
> db.movie.findOne({_id: 321475}) { _id: 321475, title: "The Dark Knight", recent_reviews: [ {_id: 264579, stars: 4, text: "Amazing"}, {_id: 375684, stars: 5, text: "Mindblowing"} ] }</code간단히 말해서, 관련 항목의 하위 집합에 일상적으로 액세스하는 경우 포함해야 합니다.
독립적인 접근
하위 문서를 해당 컬렉션에 저장하여 상위 컬렉션과 분리할 수 있습니다.
예를 들어 회사의 제품 라인을 살펴보겠습니다. 회사에서 소량의 제품을 판매하는 경우 회사 문서에 해당 제품을 저장할 수 있습니다. 그러나 회사에서 재사용하거나 SKU(재고 보관 단위)에서 직접 액세스하려는 경우 컬렉션에 저장하는 것도 좋습니다.
엔티티를 독립적으로 조작하거나 액세스하는 경우 모범 사례를 위해 별도로 저장하도록 컬렉션을 만드십시오.
무제한 목록
문서에 관련 정보의 짧은 목록을 저장하는 것은 단점이 있습니다. 목록이 확인되지 않은 상태로 계속 늘어나면 단일 문서에 넣지 않아야 합니다. 오랫동안 지원하지 못하기 때문입니다.
여기에는 두 가지 이유가 있습니다. 첫째, MongoDB는 단일 문서의 크기에 제한이 있습니다. 둘째, 문서에 너무 많은 빈도로 액세스하면 제어되지 않은 메모리 사용으로 인해 부정적인 결과가 나타납니다.
간단히 말해서 목록이 무한정 늘어나기 시작하면 컬렉션을 만들어 별도로 저장하는 것입니다.
확장 참조 패턴
확장 참조 패턴은 하위 집합 패턴과 같습니다. 또한 문서에 저장하기 위해 정기적으로 액세스하는 정보를 최적화합니다.
여기에서는 목록 대신 문서가 동일한 컬렉션에 있는 다른 문서를 참조할 때 활용됩니다. 동시에 액세스 준비를 위해 해당 문서의 일부 필드도 저장합니다.
예를 들어:
> db.movie.findOne({_id: 245434}) { _id: 245434, title: "Mission Impossible 4 - Ghost Protocol", studio_id: 924935, studio_name: "Paramount Pictures" }As you can see, “the studio_id” is stored so that you can look up more information on the studio that created the film. But the studio's name is also copied to this document for simplicity.
To embed information from modified documents regularly, remember to update documents where you've copied that information when it is modified. In other words, if you routinely access some fields from a referenced document, embed them.
How To Monitor MongoDB
You can use monitoring tools like Kinsta APM to debug long API calls, slow database queries, long external URL requests, to name a few. You can even leverage commands to improve database performance. You can also use them to inspect the ase/” data-mce-href=”https://kinsta.com/knowledgebase/wordpress-repair-database/”>health of your database instances.
Why Should You Monitor MongoDB Databases?
A key aspect of database administration planning is monitoring your cluster's performance and health. MongoDB Atlas handles the majority of administration efforts through its fault-tolerance/scaling abilities.
Despite that, users need to know how to track clusters. They should also know how to scale or tweak whatever they need before hitting a crisis.
By monitoring MongoDB databases, you can:
- Observe the utilization of resources.
- Understand the current capacity of your database.
- React and detect real-time issues to enhance your application stack.
- Observe the presence of performance issues and abnormal behavior.
- Align with your governance/data protection and service-level agreement (SLA) requirements.
Key Metrics To Monitor
While monitoring MongoDB, there are four key aspects you need to keep in mind:
1. MongoDB Hardware Metrics
Here are the primary metrics for monitoring hardware:
Normalized Process CPU
It's defined as the percentage of time spent by the CPU on application software maintaining the MongoDB process.
You can scale this to a range of 0-100% by dividing it by the number of CPU cores. It includes CPU leveraged by modules such as kernel and user.
High kernel CPU might show exhaustion of CPU via the operating system operations. But the user linked with MongoDB operations might be the root cause of CPU exhaustion.
정규화된 시스템 CPU
It's the percentage of time the CPU spent on system calls servicing this MongoDB process. You can scale it to a range of 0-100% by dividing it by the number of CPU cores. It also covers the CPU used by modules such as iowait, user, kernel, steal, etc.
User CPU or high kernel might show CPU exhaustion through MongoDB operations (software). High iowait might be linked to storage exhaustion causing CPU exhaustion.
디스크 IOPS
Disk IOPS is the average consumed IO operations per second on MongoDB's disk partition.
Disk Latency
This is the disk partition's read and write disk latency in milliseconds in MongoDB. High values (>500ms) show that the storage layer might affect MongoDB's performance.
시스템 메모리
Use the system memory to describe physical memory bytes used versus available free space.
The available metric approximates the number of bytes of system memory available. You can use this to execute new applications, without swapping.
Disk Space Free
This is defined as the total bytes of free disk space on MongoDB's disk partition. MongoDB Atlas provides auto-scaling capabilities based on this metric.
Swap Usage
You can leverage a swap usage graph to describe how much memory is being placed on the swap device. A high used metric in this graph shows that swap is being utilized. This shows that the memory is under-provisioned for the current workload.
MongoDB Cluster's Connection and Operation Metrics
Here are the main metrics for Operation and Connection Metrics:
Operation Execution Times
The average operation time (write and read operations) performed over the selected sample period.
옵카운터
It is the average rate of operations executed per second over the selected sample period. Opcounters graph/metric shows the operations breakdown of operation types and velocity for the instance.
사이
This metric refers to the number of open connections to the instance. High spikes or numbers might point to a suboptimal connection strategy either from the unresponsive server or the client side.
Query Targeting and Query Executors
This is the average rate per second over the selected sample period of scanned documents. For query executors, this is during query-plan evaluation and queries. Query targeting shows the ratio between the number of documents scanned and the number of documents returned.
높은 숫자 비율은 차선의 작업을 나타냅니다. 이러한 작업은 많은 문서를 스캔하여 더 작은 부품을 반환합니다.
스캔 및 주문
선택한 쿼리 샘플 기간 동안의 초당 평균 속도를 설명합니다. 인덱스를 사용하여 정렬 작업을 실행할 수 없는 정렬된 결과를 반환합니다.
대기열
큐는 쓰기 또는 읽기 중 잠금을 기다리는 작업 수를 설명할 수 있습니다. 높은 대기열은 최적이 아닌 스키마 디자인의 존재를 나타낼 수 있습니다. 또한 쓰기 경로가 충돌하여 데이터베이스 리소스에 대한 경쟁이 치열함을 나타낼 수도 있습니다.
MongoDB 복제 지표
다음은 복제 모니터링을 위한 기본 메트릭입니다.
복제 Oplog 창
이 측정 단위는 기본 복제 oplog에서 사용 가능한 대략적인 시간을 나열합니다. 보조 장치가 이 양보다 더 지연되면 따라갈 수 없으며 전체 재동기화가 필요합니다.
복제 지연
복제 지연은 쓰기 작업에서 보조 노드가 기본 노드보다 뒤처지는 대략적인 시간(초)으로 정의됩니다. 높은 복제 지연은 복제에 어려움을 겪는 2차 서버를 가리킵니다. 연결에 대한 읽기/쓰기 문제를 고려할 때 작업 대기 시간에 영향을 줄 수 있습니다.
복제 여유 공간
이 메트릭은 기본 복제의 oplog 창과 보조 복제 지연 간의 차이를 나타냅니다. 이 값이 0이 되면 보조 장치가 복구 모드로 들어갈 수 있습니다.
상대 -repl
Opcounters -repl은 선택한 샘플 기간 동안 초당 실행되는 복제 작업의 평균 비율로 정의됩니다. opcounters -graph/metric을 사용하여 지정된 인스턴스에 대한 작업 속도 및 작업 유형 분석을 살펴볼 수 있습니다.
Oplog GB/시간
이는 기본이 시간당 생성하는 oplog의 기가바이트 평균 비율로 정의됩니다. 예기치 않은 볼륨의 oplog는 쓰기 워크로드가 매우 부족하거나 스키마 설계 문제를 나타낼 수 있습니다.
MongoDB 성능 모니터링 도구
MongoDB에는 성능 추적을 위해 Cloud Manager, Atlas 및 Ops Manager에 사용자 인터페이스 도구가 내장되어 있습니다. 또한 원시 기반 데이터를 더 많이 볼 수 있는 몇 가지 독립적인 명령과 도구를 제공합니다. 환경을 확인하기 위한 액세스 권한과 적절한 역할이 있는 호스트에서 실행할 수 있는 몇 가지 도구에 대해 설명합니다.
몽고톱
이 명령을 활용하여 MongoDB 인스턴스가 컬렉션당 데이터를 쓰고 읽는 데 소비하는 시간을 추적할 수 있습니다. 다음 구문을 사용합니다.
mongotop <options> <connection-string> <polling-interval in seconds>rs.status()
이 명령은 복제본 세트 상태를 반환합니다. 메소드가 실행되는 멤버의 관점에서 실행됩니다.
몽고스타트
mongostat 명령을 사용하여 MongoDB 서버 인스턴스의 상태에 대한 빠른 개요를 얻을 수 있습니다. 실시간 보기를 제공하므로 최적의 출력을 위해 특정 이벤트에 대한 단일 인스턴스를 관찰하는 데 사용할 수 있습니다.
이 명령을 활용하여 잠금 대기열, 작업 분석, MongoDB 메모리 통계 및 연결/네트워크와 같은 기본 서버 통계를 모니터링합니다.
mongostat <options> <connection-string> <polling interval in seconds>데이터베이스 통계
이 명령은 인덱스 수 및 크기, 총 컬렉션 데이터 대 스토리지 크기, 컬렉션 관련 통계(컬렉션 및 문서 수)와 같은 특정 데이터베이스에 대한 스토리지 통계를 반환합니다.
db.serverStatus()
db.serverStatus() 명령을 활용하여 데이터베이스 상태의 개요를 볼 수 있습니다. 현재 인스턴스 메트릭 카운터를 나타내는 문서를 제공합니다. 정기적으로 이 명령을 실행하여 인스턴스에 대한 통계를 수집합니다.
collStats
collStats 명령은 수집 수준에서 dbStats 가 제공하는 것과 유사한 통계를 수집합니다. 그 출력은 컬렉션의 개체 수, 컬렉션에서 사용하는 디스크 공간의 양, 컬렉션의 크기, 지정된 컬렉션에 대한 인덱스 관련 정보로 구성됩니다.
이러한 모든 명령을 사용하여 데이터베이스 성능 및 오류를 모니터링하고 정보에 입각한 의사 결정을 지원하여 데이터베이스를 구체화할 수 있도록 데이터베이스 서버에 대한 실시간 보고 및 모니터링을 제공할 수 있습니다.
MongoDB 데이터베이스를 삭제하는 방법
MongoDB에서 생성한 데이터베이스를 삭제하려면 use 키워드를 통해 연결해야 합니다.
"Engineers"라는 데이터베이스를 생성했다고 가정해 보겠습니다. 데이터베이스에 연결하려면 다음 명령을 사용합니다.
use Engineers 다음으로 db.dropDatabase() 를 입력하여 이 데이터베이스를 제거합니다. 실행 후 예상할 수 있는 결과는 다음과 같습니다.
{ "dropped" : "Engineers", "ok" : 1 } showdbs 명령을 실행하여 데이터베이스가 아직 존재하는지 확인할 수 있습니다.
요약
MongoDB에서 가치의 모든 마지막 한 방울을 짜내려면 기본 사항을 잘 이해하고 있어야 합니다. 따라서 MongoDB 데이터베이스를 손등처럼 아는 것이 중요합니다. 이를 위해서는 먼저 데이터베이스를 생성하는 방법에 익숙해져야 합니다.
이 기사에서는 MongoDB에서 데이터베이스를 생성하는 데 사용할 수 있는 다양한 방법에 대해 설명하고, 이어서 데이터베이스를 최신 상태로 유지하는 몇 가지 멋진 MongoDB 명령에 대한 자세한 설명을 제공합니다. 마지막으로 MongoDB에 포함된 문서와 성능 모니터링 도구를 활용하여 워크플로 기능을 최대 효율로 보장하는 방법에 대해 논의하여 토론을 마무리했습니다.
이 MongoDB 명령에 대해 어떻게 생각하십니까? 여기에서 보고 싶었던 측면이나 방법을 놓쳤습니까? 댓글로 알려주세요!