
기록적인 시간 내에 강력한 MongoDB 복제 세트 구축(4가지 방법)
게시 됨: 2023-03-11MongoDB는 동적 스키마와 함께 JSON과 유사한 문서를 사용하는 NoSQL 데이터베이스입니다. 데이터베이스로 작업할 때 데이터베이스 서버 중 하나가 실패할 경우에 대비한 비상 계획을 세우는 것이 항상 좋습니다. 사이드바에서 WordPress 사이트를 위한 멋진 관리 도구를 활용하여 이러한 일이 발생할 가능성을 줄일 수 있습니다.
이것이 데이터 사본을 많이 보유하는 것이 유용한 이유입니다. 또한 읽기 대기 시간도 줄어듭니다. 동시에 데이터베이스의 확장성과 가용성을 향상시킬 수 있습니다. 여기에서 복제가 시작됩니다. 복제는 여러 데이터베이스에서 데이터를 동기화하는 방식으로 정의됩니다.
이 기사에서는 몇 가지 예를 들면 기능 및 메커니즘과 같은 MongoDB 복제의 다양한 중요한 측면에 대해 자세히 살펴보겠습니다.
MongoDB에서 복제란 무엇입니까?
MongoDB에서 복제본 세트는 복제를 수행합니다. 복제를 통해 동일한 데이터 세트를 유지하는 서버 그룹입니다. 부하 분산의 일부로 MongoDB 복제를 사용할 수도 있습니다. 여기에서 사용 사례에 따라 쓰기 및 읽기 작업을 모든 인스턴스에 분산할 수 있습니다.
MongoDB 복제본 세트란?
주어진 복제 세트의 일부인 MongoDB의 모든 인스턴스는 구성원입니다. 모든 복제본 세트에는 기본 구성원과 하나 이상의 보조 구성원이 있어야 합니다.
기본 구성원은 복제 세트가 있는 트랜잭션의 기본 액세스 지점입니다. 쓰기 작업을 수락할 수 있는 유일한 구성원이기도 합니다. 복제는 먼저 기본의 oplog(작업 로그)를 복사합니다. 그런 다음 보조 서버의 각 데이터 세트에 기록된 변경 사항을 반복합니다. 따라서 모든 복제본 세트는 한 번에 하나의 기본 구성원만 가질 수 있습니다. 쓰기 작업을 수신하는 다양한 기본은 데이터 충돌을 일으킬 수 있습니다.
일반적으로 애플리케이션은 기본 구성원에게 쓰기 및 읽기 작업만 쿼리합니다. 하나 이상의 보조 구성원에서 읽도록 설정을 설계할 수 있습니다. 비동기 데이터 전송으로 인해 보조 노드의 읽기가 이전 데이터를 제공할 수 있습니다. 따라서 이러한 배열은 모든 사용 사례에 이상적이지 않습니다.
복제 세트 기능
자동 장애 조치 메커니즘은 MongoDB의 복제 세트를 경쟁 제품과 차별화합니다. 기본 노드가 없으면 보조 노드 간의 자동 선택이 새 기본 노드를 선택합니다.
MongoDB 복제 세트와 MongoDB 클러스터 비교
MongoDB 복제본 세트는 복제본 세트 노드에서 동일한 데이터 세트의 다양한 복사본을 생성합니다. 복제 세트의 주요 목표는 다음과 같습니다.
- 빌트인 백업 솔루션 제공
- 데이터 가용성 향상
MongoDB 클러스터는 완전히 다른 볼 게임입니다. 샤드 키를 통해 여러 노드에 데이터를 배포합니다. 이 프로세스는 데이터를 샤드라고 하는 여러 조각으로 분할합니다. 그런 다음 각 샤드를 다른 노드에 복사합니다. 클러스터는 대용량 데이터 세트와 높은 처리량 작업을 지원하는 것을 목표로 합니다. 워크로드를 수평으로 확장하여 이를 달성합니다.
평신도의 용어로 복제 세트와 클러스터의 차이점은 다음과 같습니다.
- 클러스터는 워크로드를 분산합니다. 또한 여러 서버에 데이터 조각(샤드)을 저장합니다.
- 복제 세트는 데이터 세트를 완전히 복제합니다.
MongoDB를 사용하면 샤드 클러스터를 만들어 이러한 기능을 결합할 수 있습니다. 여기에서 모든 샤드를 보조 서버에 복제할 수 있습니다. 이를 통해 샤드는 높은 중복성과 데이터 가용성을 제공할 수 있습니다.
복제본 세트를 유지하고 설정하는 것은 기술적으로 많은 부담과 시간이 소요될 수 있습니다. 적합한 호스팅 서비스를 찾으시나요? 그것은 완전히 다른 두통입니다. 너무 많은 옵션이 있기 때문에 비즈니스를 구축하는 대신 조사하는 데 시간을 낭비하기 쉽습니다.
이 모든 작업을 수행하는 도구에 대한 간략한 설명을 드리고 귀하의 서비스/제품으로 돌아가서 분쇄할 수 있도록 훨씬 더 많은 작업을 수행합니다.
55,000명 이상의 개발자가 신뢰하는 Kinsta의 애플리케이션 호스팅 솔루션을 사용하면 간단한 3단계로 시작하고 실행할 수 있습니다. 그것이 사실이 되기에는 너무 좋게 들리면 Kinsta 사용의 추가 이점이 있습니다.
- Kinsta의 내부 연결로 더 나은 성능을 즐기십시오 : 공유 데이터베이스와의 어려움을 잊으십시오. 쿼리 수 또는 행 수 제한이 없는 내부 연결이 있는 전용 데이터베이스로 전환합니다. Kinsta는 더 빠르고 안전하며 내부 대역폭/트래픽에 대해 비용을 청구하지 않습니다.
- 개발자를 위한 기능 세트 : Gmail, YouTube 및 Google 검색을 지원하는 강력한 플랫폼에서 애플리케이션을 확장하세요. 안심하십시오, 당신은 여기에서 가장 안전한 손에 있습니다.
- 선택한 데이터 센터로 비교할 수 없는 속도를 즐기십시오 : 귀하와 귀하의 고객에게 가장 적합한 지역을 선택하십시오. 선택할 수 있는 25개 이상의 데이터 센터가 있는 Kinsta의 275개 이상의 PoP는 웹사이트의 최대 속도와 글로벌 입지를 보장합니다.
오늘 Kinsta의 애플리케이션 호스팅 솔루션을 무료로 사용해 보세요!
복제는 MongoDB에서 어떻게 작동합니까?
MongoDB에서는 작성기 작업을 기본 서버(노드)로 보냅니다. 주 서버는 데이터를 복제하는 보조 서버 전체에 작업을 할당합니다.
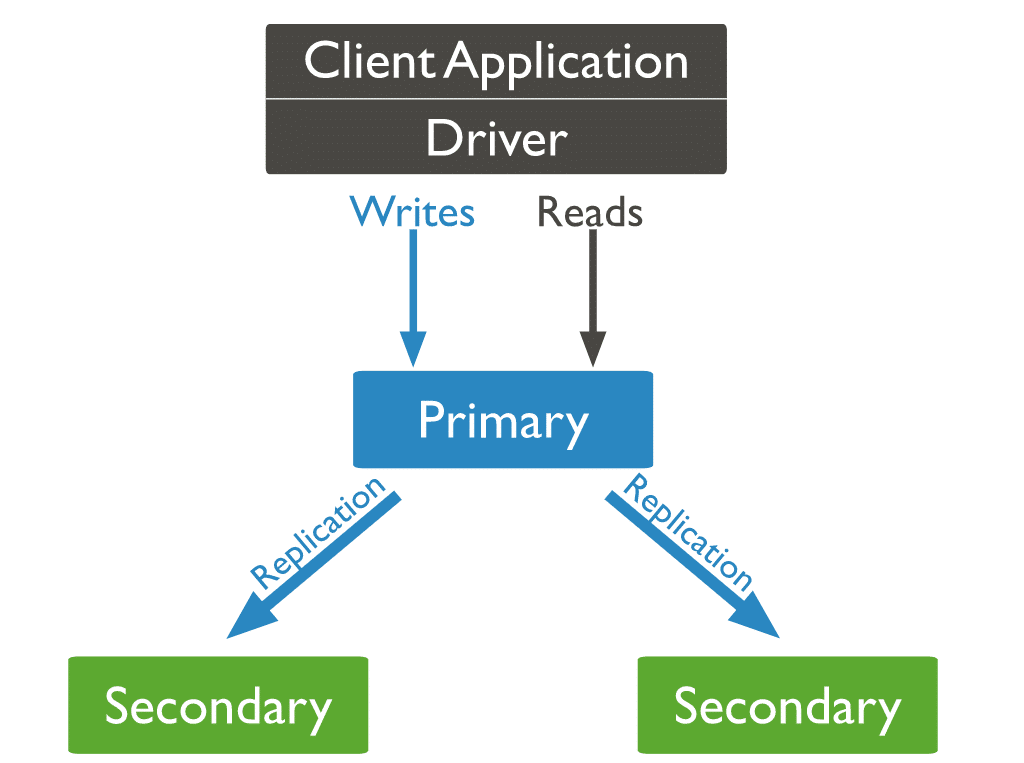
세 가지 유형의 MongoDB 노드
MongoDB 노드의 세 가지 유형 중 기본 및 보조 노드라는 두 가지 유형이 이전에 나타났습니다. 복제 중에 유용한 세 번째 유형의 MongoDB 노드는 중재자입니다. 중재자 노드에는 데이터 세트의 사본이 없으며 기본 노드가 될 수 없습니다. 그렇긴 하지만, 중재인은 예비 선거에 참여합니다.
이전에 기본 노드가 다운되면 어떻게 되는지 언급했지만 보조 노드가 먼지를 물어뜯으면 어떻게 될까요? 이 시나리오에서 기본 노드는 보조 노드가 되고 데이터베이스에 연결할 수 없게 됩니다.
회원 선출
선택은 다음 시나리오에서 발생할 수 있습니다.
- 복제 세트 초기화
- 기본 노드에 대한 연결 끊김(하트비트로 감지할 수 있음)
-
rs.reconfig또는stepDown방법을 사용한 복제 세트 유지 관리 - 기존 복제 세트에 새 노드 추가
레플리카 세트는 최대 50명의 구성원을 보유할 수 있지만 모든 선거에서 7명 이하만 투표할 수 있습니다.
클러스터가 새로운 기본 클러스터를 선택하기까지의 평균 시간은 12초를 초과해서는 안 됩니다. 선택 알고리즘은 사용 가능한 우선순위가 가장 높은 보조를 가지려고 시도합니다. 동시에 우선 순위 값이 0인 구성원은 예비 후보가 될 수 없으며 선거에 참여하지 않습니다.
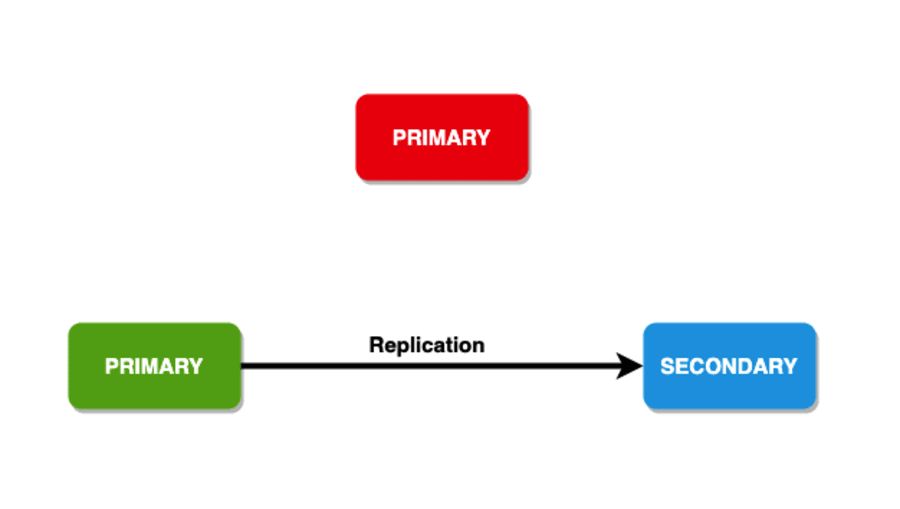
쓰기 문제
내구성을 위해 쓰기 작업에는 지정된 수의 노드에 데이터를 복사하는 프레임워크가 있습니다. 이를 통해 고객에게 피드백을 제공할 수도 있습니다. 이 프레임워크는 "쓰기 문제"라고도 합니다. 작업이 성공한 것으로 반환되기 전에 쓰기 문제를 승인해야 하는 데이터 보유 멤버가 있습니다. 일반적으로 복제본 세트는 쓰기 문제로 1의 값을 갖습니다. 따라서 쓰기 문제 확인을 반환하기 전에 기본만 쓰기를 확인해야 합니다.
쓰기 작업을 승인하는 데 필요한 구성원 수를 늘릴 수도 있습니다. 보유할 수 있는 회원 수에는 제한이 없습니다. 그러나 숫자가 높으면 긴 대기 시간을 처리해야 합니다. 이는 클라이언트가 모든 구성원의 승인을 기다려야 하기 때문입니다. 또한 "다수"의 쓰기 관심사를 설정할 수 있습니다. 이는 승인을 받은 구성원의 절반 이상을 계산합니다.
읽기 기본 설정
읽기 작업의 경우 데이터베이스가 쿼리를 복제 세트의 구성원으로 보내는 방법을 설명하는 읽기 기본 설정을 언급할 수 있습니다. 일반적으로 기본 노드는 읽기 작업을 받지만 클라이언트는 읽기 기본 설정을 언급하여 읽기 작업을 보조 노드로 보낼 수 있습니다. 다음은 읽기 기본 설정에 대한 옵션입니다.
- primaryPreferred : 일반적으로 읽기 작업은 기본 노드에서 발생하지만 이를 사용할 수 없는 경우 보조 노드에서 데이터를 가져옵니다.
- primary : 모든 읽기 작업은 기본 노드에서 발생합니다.
- secondary : 모든 읽기 작업은 보조 노드에서 실행됩니다.
- 가장 가까운 : 여기에서 읽기 요청은
ping명령을 실행하여 감지할 수 있는 가장 가까운 도달 가능한 노드로 라우팅됩니다. 읽기 작업의 결과는 그것이 기본인지 보조인지에 관계없이 복제 세트의 모든 구성원에서 나올 수 있습니다. - secondaryPreferred : 여기에서 대부분의 읽기 작업은 보조 노드에서 오지만 사용 가능한 것이 없으면 기본 노드에서 데이터를 가져옵니다.
복제 세트 데이터 동기화
공유 데이터 세트의 최신 사본을 유지하기 위해 복제본 세트의 보조 구성원은 다른 구성원의 데이터를 복제하거나 동기화합니다.
MongoDB는 두 가지 형태의 데이터 동기화를 활용합니다. 새 구성원을 전체 데이터 세트로 채우기 위한 초기 동기화. 전체 데이터 세트에 대한 지속적인 변경을 실행하기 위한 복제.
초기 동기화
초기 동기화 중에 보조 노드는 init sync 명령을 실행하여 기본 노드의 모든 데이터를 최신 데이터가 포함된 다른 보조 노드로 동기화합니다. 따라서 보조 노드는 지속적으로 tailable cursor 기능을 활용하여 기본 노드의 local.oplog.rs 컬렉션 내에서 최신 oplog 항목을 쿼리하고 이러한 oplog 항목 내에서 이러한 작업을 적용합니다.
MongoDB 5.2부터 초기 동기화는 파일 복사 기반 또는 논리적일 수 있습니다.
논리적 동기화
논리적 동기화를 실행하면 MongoDB는 다음을 수행합니다.
- 문서가 각 컬렉션에 대해 복사될 때 모든 컬렉션 인덱스를 개발합니다.
- 로컬 데이터베이스를 제외한 모든 데이터베이스를 복제합니다.
mongod모든 소스 데이터베이스의 모든 컬렉션을 스캔하고 이러한 컬렉션의 복제본에 모든 데이터를 삽입합니다. - 데이터 세트에 대한 모든 변경 사항을 실행합니다. 소스의 oplog를 활용하여
mongod데이터 세트를 업그레이드하여 복제본 세트의 현재 상태를 나타냅니다. - 데이터 복사 중에 새로 추가된 oplog 레코드를 추출합니다. 이 데이터 복사 단계 동안 이러한 oplog 레코드를 잠정적으로 저장할 수 있도록 대상 구성원에 로컬 데이터베이스 내에 충분한 디스크 공간이 있는지 확인하십시오.
초기 동기화가 완료되면 구성원이 STARTUP2 에서 SECONDARY 로 전환됩니다.
파일 복사 기반 초기 동기화
즉시 MongoDB Enterprise를 사용하는 경우에만 실행할 수 있습니다. 이 프로세스는 파일 시스템에서 파일을 복제하고 이동하여 초기 동기화를 실행합니다. 이 동기화 방법은 경우에 따라 논리적 초기 동기화보다 빠를 수 있습니다. 쿼리 조건자 없이 count() 메서드를 실행하면 파일 복사 기반 초기 동기화로 인해 계산이 정확하지 않을 수 있습니다.
그러나 이 방법에는 다음과 같은 제한 사항도 있습니다.
- 파일 복사 기반 초기 동기화 중에는 동기화 중인 구성원의 로컬 데이터베이스에 쓸 수 없습니다. 또한 동기화 중인 구성원 또는 동기화 중인 구성원에서 백업을 실행할 수 없습니다.
- 암호화된 스토리지 엔진을 활용할 때 MongoDB는 소스 키를 사용하여 대상을 암호화합니다.
- 한 번에 한 구성원의 초기 동기화만 실행할 수 있습니다.
복제
보조 구성원은 초기 동기화 후 일관되게 데이터를 복제합니다. 보조 구성원은 소스의 동기화에서 oplog를 복제하고 비동기 프로세스에서 이러한 작업을 실행합니다.
Secondary는 다른 구성원의 복제 상태 및 ping 시간의 변경 사항에 따라 필요에 따라 소스에서 동기화를 자동으로 수정할 수 있습니다.
스트리밍 복제
MongoDB 4.4부터 소스의 동기화는 oplog 항목의 연속 스트림을 동기화 보조 항목으로 보냅니다. 스트리밍 복제는 부하가 높고 대기 시간이 긴 네트워크에서 복제 지연을 줄입니다. 또한 다음을 수행할 수 있습니다.
- 기본 장애 조치로 인해
w:1로 쓰기 작업이 손실될 위험을 줄입니다. - 보조에서 읽기에 대한 부실을 줄입니다.
-
w:“majority”및w:>1사용하여 쓰기 작업의 대기 시간을 줄입니다. 즉, 복제 대기가 필요한 모든 쓰기 문제입니다.
다중 스레드 복제
MongoDB는 동시성을 향상시키기 위해 여러 스레드를 통해 일괄 작업을 작성했습니다. MongoDB는 다른 스레드로 각 작업 그룹을 적용하는 동안 문서 ID별로 배치를 그룹화합니다.
MongoDB는 항상 지정된 문서에서 원래 쓰기 순서대로 쓰기 작업을 실행합니다. 이것은 MongoDB 4.0에서 변경되었습니다.
MongoDB 4.0부터 보조를 대상으로 하고 “majority” 또는 “local” 의 읽기 관심 수준으로 구성된 읽기 작업은 이제 복제 일괄 처리가 적용되는 보조에서 읽기가 발생하는 경우 데이터의 WiredTiger 스냅샷에서 읽습니다. 스냅샷에서 읽으면 일관된 데이터 보기가 보장되며 잠금 없이 진행 중인 복제와 동시에 읽기가 발생할 수 있습니다.
따라서 이러한 읽기 관련 수준이 필요한 보조 읽기는 더 이상 복제 일괄 처리가 적용될 때까지 기다릴 필요가 없으며 수신되는 대로 처리할 수 있습니다.
MongoDB 복제 세트를 생성하는 방법
앞에서 언급했듯이 MongoDB는 복제본 세트를 통해 복제를 처리합니다. 다음 몇 섹션에서는 사용 사례에 대한 복제 세트를 생성하는 데 사용할 수 있는 몇 가지 방법을 강조합니다.
방법 1: Ubuntu에서 새 MongoDB 복제 세트 생성
시작하기 전에 Ubuntu 20.04를 실행하는 서버가 3대 이상 있고 각 서버에 MongoDB가 설치되어 있는지 확인해야 합니다.
레플리카 세트를 설정하려면 각 레플리카 세트 구성원이 세트의 다른 구성원에 도달할 수 있는 주소를 제공하는 것이 중요합니다. 이 경우 세트에 3개의 멤버를 유지합니다. IP 주소를 사용할 수 있지만 주소가 예기치 않게 변경될 수 있으므로 권장하지 않습니다. 더 나은 대안은 복제 세트를 구성할 때 논리적 DNS 호스트 이름을 사용하는 것입니다.
각 복제 구성원에 대한 하위 도메인을 구성하여 이를 수행할 수 있습니다. 이는 프로덕션 환경에 이상적일 수 있지만 이 섹션에서는 각 서버의 해당 호스트 파일을 편집하여 DNS 확인을 구성하는 방법을 간략하게 설명합니다. 이 파일을 사용하면 읽을 수 있는 호스트 이름을 숫자 IP 주소에 할당할 수 있습니다. 따라서 IP 주소가 변경되는 경우 복제 세트를 처음부터 다시 구성하지 않고 세 서버에서 호스트 파일을 업데이트하기만 하면 됩니다!
대부분 hosts /etc/ 디렉토리에 저장됩니다. 세 서버 각각에 대해 아래 명령을 반복합니다.
sudo nano /etc/hosts위의 명령에서는 nano를 텍스트 편집기로 사용하고 있지만 원하는 텍스트 편집기를 사용할 수 있습니다. localhost를 구성하는 처음 몇 줄 뒤에 복제 세트의 각 구성원에 대한 항목을 추가합니다. 이러한 항목은 IP 주소와 사용자가 선택한 사람이 읽을 수 있는 이름의 형식을 취합니다. 원하는 대로 이름을 지정할 수 있지만 각 구성원을 구별할 수 있도록 설명이 포함되어야 합니다. 이 자습서에서는 아래 호스트 이름을 사용합니다.
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
이러한 호스트 이름을 사용하면 /etc/hosts 파일이 다음 강조 표시된 줄과 유사하게 보입니다.

파일을 저장하고 닫습니다.
복제 세트에 대한 DNS 확인을 구성한 후 서로 통신할 수 있도록 방화벽 규칙을 업데이트해야 합니다. mongo0에서 다음 ufw 명령을 실행하여 mongo0의 포트 27017에 대한 mongo1 액세스를 제공합니다.
sudo ufw allow from mongo1_server_ip to any port 27017 mongo1_server_ip 매개변수 대신 mongo1 서버의 실제 IP 주소를 입력하십시오. 또한 기본이 아닌 포트를 사용하도록 이 서버에서 Mongo 인스턴스를 업데이트한 경우 MongoDB 인스턴스가 사용 중인 포트를 반영하도록 27017을 변경해야 합니다.
이제 다른 방화벽 규칙을 추가하여 동일한 포트에 대한 mongo2 액세스 권한을 부여합니다.
sudo ufw allow from mongo2_server_ip to any port 27017 mongo2_server_ip 매개변수 대신 mongo2 서버의 실제 IP 주소를 입력하십시오. 그런 다음 다른 두 서버에 대한 방화벽 규칙을 업데이트합니다. mongo1 서버에서 다음 명령을 실행하여 각각 mongo0 및 mongo2의 IP 주소를 반영하도록 server_ip 매개변수 대신 IP 주소를 변경해야 합니다.
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017마지막으로 mongo2에서 이 두 명령을 실행합니다. 다시 말하지만 각 서버에 대해 올바른 IP 주소를 입력했는지 확인하십시오.
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017다음 단계는 외부 연결을 허용하도록 각 MongoDB 인스턴스의 구성 파일을 업데이트하는 것입니다. 이를 허용하려면 각 서버의 구성 파일을 수정하여 IP 주소를 반영하고 복제 세트를 표시해야 합니다. 원하는 텍스트 편집기를 사용할 수 있지만 나노 텍스트 편집기를 다시 한 번 사용합니다. 각 mongod.conf 파일에서 다음과 같이 수정해 보겠습니다.
mongo0에서:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"몽고1에서:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"몽고2에서:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongod이것으로 각 서버의 MongoDB 인스턴스에 대한 복제를 활성화했습니다.
이제 rs.initiate() 메서드를 사용하여 복제 세트를 초기화할 수 있습니다. 이 메서드는 복제 세트의 단일 MongoDB 인스턴스에서만 실행해야 합니다. 복제본 세트 이름 및 구성원이 이전에 각 구성 파일에서 만든 구성과 일치하는지 확인하십시오.
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })메서드가 출력에서 "ok": 1을 반환하면 복제본 세트가 올바르게 시작된 것입니다. 다음은 출력 결과의 예입니다.
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }MongoDB 서버 종료
db.shutdownServer() 메서드를 사용하여 MongoDB 서버를 종료할 수 있습니다. 아래는 동일한 구문입니다. force 및 timeoutsecs 모두 선택적 매개변수입니다.
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) 이 방법은 mongod 복제 세트 구성원이 특정 작업을 인덱스 빌드로 실행하는 경우 실패할 수 있습니다. 작업을 중단하고 구성원을 강제로 종료하려면 부울 매개 변수 force true로 입력할 수 있습니다.
-replSet을 사용하여 MongoDB를 다시 시작합니다.
구성을 재설정하려면 복제 세트의 모든 노드가 중지되었는지 확인하십시오. 그런 다음 모든 노드의 로컬 데이터베이스를 삭제합니다. –replSet 플래그를 사용하여 다시 시작하고 복제 세트에 대한 하나의 mongod 인스턴스에서만 rs.initiate() 실행하십시오.
mongod --replSet "rs0" rs.initiate() 선택적 replica set 구성 문서, 즉 다음을 취할 수 있습니다.
-
Replication.replSetName또는—replSet옵션은_id필드에 복제 세트 이름을 지정합니다. - 각 복제 세트 구성원에 대해 하나의 문서를 포함하는 구성원 배열.
rs.initiate() 메소드는 선택을 트리거하고 구성원 중 하나를 기본으로 선택합니다.
복제 세트에 구성원 추가
세트에 구성원을 추가하려면 다양한 시스템에서 mongod 인스턴스를 시작하십시오. 다음으로 mongo 클라이언트를 시작하고 rs.add() 명령을 사용합니다.
rs.add() 명령의 기본 구문은 다음과 같습니다.
rs.add(HOST_NAME:PORT)예를 들어,
mongo1이 mongod 인스턴스이고 포트 27017에서 수신 중이라고 가정합니다. Mongo 클라이언트 명령 rs.add() 사용하여 이 인스턴스를 복제 세트에 추가합니다.
rs.add("mongo1:27017") 기본 노드에 연결된 후에만 복제 세트에 mongod 인스턴스를 추가할 수 있습니다. 기본에 연결되어 있는지 확인하려면 db.isMaster() 명령을 사용하십시오.
사용자 제거
구성원을 제거하려면 rs.remove() 사용할 수 있습니다.
이렇게 하려면 먼저 위에서 설명한 db.shutdownServer() 메서드를 사용하여 제거하려는 mongod 인스턴스를 종료합니다.

그런 다음 복제 세트의 현재 기본에 연결하십시오. 현재 기본을 확인하려면 복제 세트의 구성원에 연결된 상태에서 db.hello() 사용하십시오. 기본을 결정했으면 다음 명령 중 하나를 실행합니다.
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 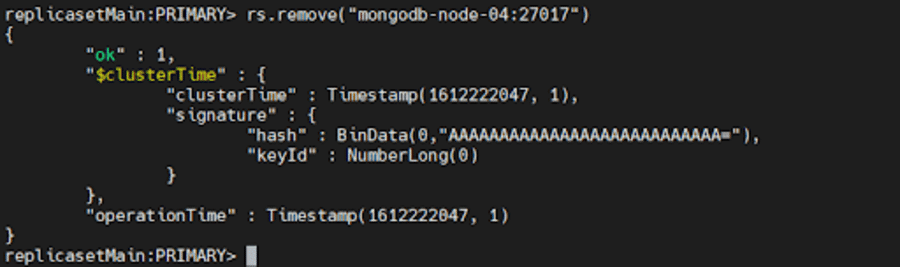
레플리카 세트가 새로운 기본을 선택해야 하는 경우 MongoDB는 셸 연결을 잠시 끊을 수 있습니다. 이 시나리오에서는 자동으로 다시 한 번 다시 연결됩니다. 또한 명령이 성공하더라도 DBClientCursor::init call() 실패 오류가 표시될 수 있습니다.
방법 2: 배포 및 테스트를 위한 MongoDB 복제 세트 구성
일반적으로 RBAC를 활성화하거나 비활성화하여 테스트용 복제 세트를 설정할 수 있습니다. 이 방법에서는 테스트 환경에 배포하기 위해 액세스 제어가 비활성화된 복제 세트를 설정합니다.
먼저 다음 명령을 사용하여 복제 세트의 일부인 모든 인스턴스에 대한 디렉토리를 작성하십시오.
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2이 명령은 3개의 MongoDB 인스턴스 replicaset0-0, replicaset0-1 및 replicaset0-2에 대한 디렉토리를 생성합니다. 이제 다음 명령 집합을 사용하여 각각에 대해 MongoDB 인스턴스를 시작합니다.
서버 1의 경우:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128서버 2의 경우:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128서버 3의 경우:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 –oplogSize 매개변수는 테스트 단계에서 기계가 과부하되는 것을 방지하는 데 사용됩니다. 각 디스크가 소비하는 디스크 공간을 줄이는 데 도움이 됩니다.
이제 아래 포트 번호를 사용하여 연결하여 Mongo 셸을 사용하는 인스턴스 중 하나에 연결합니다.
mongo --port 27017 rs.initiate() 명령을 사용하여 복제 프로세스를 시작할 수 있습니다. hostname 매개변수를 시스템 이름으로 바꿔야 합니다.
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }이제 시작 명령의 매개변수로 구성 개체 파일을 전달하고 다음과 같이 사용할 수 있습니다.
rs.initiate(rsconf)그리고 당신은 그것을 가지고 있습니다! 개발 및 테스트 목적으로 MongoDB 복제 세트를 성공적으로 생성했습니다.
방법 3: 독립 실행형 인스턴스를 MongoDB 복제 세트로 변환
MongoDB를 사용하면 사용자가 독립형 인스턴스를 복제 세트로 변환할 수 있습니다. 독립 실행형 인스턴스는 주로 테스트 및 개발 단계에 사용되지만 복제 세트는 프로덕션 환경의 일부입니다.
시작하려면 다음 명령을 사용하여 mongod 인스턴스를 종료하겠습니다.
db.adminCommand({"shutdown":"1"}) 명령에서 –repelSet 파라미터를 사용하여 사용할 복제 세트를 지정하여 인스턴스를 다시 시작합니다.
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>명령에서 고유한 주소와 함께 서버 이름을 지정해야 합니다.
셸을 MongoDB 인스턴스와 연결하고 초기화 명령을 사용하여 복제 프로세스를 시작하고 인스턴스를 복제 세트로 성공적으로 변환합니다. 다음 명령을 사용하여 인스턴스 추가 또는 제거와 같은 모든 기본 작업을 수행할 수 있습니다.
rs.add(“<host_name:port>”) rs.remove(“host-name”) 또한 rs.status() 및 rs.conf() 명령을 사용하여 MongoDB 복제 세트의 상태를 확인할 수 있습니다.
방법 4: MongoDB Atlas - 더 간단한 대안
복제와 샤딩은 함께 작동하여 샤딩된 클러스터라는 것을 형성할 수 있습니다. 설치 및 구성은 간단하지만 시간이 많이 소요될 수 있지만 MongoDB Atlas는 앞서 언급한 방법보다 더 나은 대안입니다.
복제 세트를 자동화하여 프로세스를 쉽게 구현할 수 있습니다. 클릭 몇 번으로 전역적으로 샤딩된 복제 세트를 배포할 수 있으므로 재해 복구, 손쉬운 관리, 데이터 지역성 및 다중 지역 배포가 가능합니다.
MongoDB Atlas에서는 클러스터를 생성해야 합니다. 클러스터는 레플리카 세트이거나 샤드된 클러스터일 수 있습니다. 특정 프로젝트의 경우 다른 지역의 클러스터에 있는 노드 수는 총 40개로 제한됩니다.
여기에는 무료 또는 공유 클러스터와 서로 통신하는 Google 클라우드 리전이 제외됩니다. 두 지역 사이의 총 노드 수는 이 제약 조건을 충족해야 합니다. 예를 들어 다음과 같은 프로젝트가 있는 경우:
- 지역 A에는 15개의 노드가 있습니다.
- 영역 B에는 25개의 노드가 있습니다.
- 영역 C에는 10개의 노드가 있습니다.
지역 C에 노드를 5개만 더 할당할 수 있습니다.
- 영역 A+ 영역 B = 40; 허용되는 최대 노드 수인 40이라는 제약 조건을 충족합니다.
- 영역 B+ 영역 C = 25+10+5(C에 할당된 추가 노드) = 40; 허용되는 최대 노드 수인 40이라는 제약 조건을 충족합니다.
- 영역 A+ 영역 C =15+10+5(C에 할당된 추가 노드) = 30; 허용되는 최대 노드 수인 40이라는 제약 조건을 충족합니다.
영역 C에 노드를 10개 더 할당하여 영역 C에 20개의 노드가 있는 경우 영역 B + 영역 C = 45개 노드입니다. 이는 주어진 제약 조건을 초과하므로 다중 지역 클러스터를 생성하지 못할 수 있습니다.
클러스터를 생성할 때 Atlas는 이전에 클라우드 공급자가 없었던 경우 프로젝트에 클라우드 공급자를 위한 네트워크 컨테이너를 생성합니다. MongoDB Atlas에서 복제 세트 클러스터를 생성하려면 Atlas CLI에서 다음 명령을 실행합니다.
atlas clusters create [name] [options]클러스터가 생성된 후에는 변경할 수 없으므로 설명이 포함된 클러스터 이름을 지정해야 합니다. 인수에는 ASCII 문자, 숫자 및 하이픈이 포함될 수 있습니다.
요구 사항에 따라 MongoDB에서 클러스터 생성에 사용할 수 있는 몇 가지 옵션이 있습니다. 예를 들어 클러스터에 대한 지속적인 클라우드 백업을 원하는 경우 --backup true로 설정합니다.
복제 지연 처리
복제 지연은 상당히 불쾌할 수 있습니다. 기본 작업과 해당 작업을 oplog에서 보조로 적용하는 것 사이의 지연입니다. 비즈니스에서 대규모 데이터 세트를 처리하는 경우 특정 임계값 내에서 지연이 예상됩니다. 그러나 때때로 외부 요인도 지연에 기여하고 이를 증가시킬 수 있습니다. 최신 복제를 활용하려면 다음을 확인하십시오.
- 안정적이고 충분한 대역폭으로 네트워크 트래픽을 라우팅합니다. 네트워크 대기 시간은 복제에 큰 영향을 미치며 네트워크가 복제 프로세스의 요구 사항을 충족하기에 충분하지 않은 경우 복제 세트 전체에서 데이터 복제가 지연됩니다.
- 디스크 처리량이 충분합니다. 보조의 파일 시스템과 디스크 장치가 기본만큼 빠르게 데이터를 디스크로 플러시할 수 없는 경우 보조는 유지하기가 어렵습니다. 따라서 보조 노드는 기본 노드보다 쓰기 쿼리를 느리게 처리합니다. 이는 가상화된 인스턴스 및 대규모 배포를 포함하여 대부분의 다중 테넌트 시스템에서 공통적인 문제입니다.
- 특히 대량 로드 작업 또는 기본에 많은 수의 쓰기가 필요한 데이터 수집을 수행하려는 경우 보조가 기본을 따라잡을 수 있는 기회를 제공하기 위해 일정 간격 후에 쓰기 승인 쓰기 문제를 요청합니다. 보조 서버는 변경 사항을 따라잡을 수 있을 만큼 빠르게 oplog를 읽을 수 없습니다. 특히 승인되지 않은 쓰기 문제가 있습니다.
- 실행 중인 백그라운드 작업을 식별합니다. cron 작업, 서버 업데이트 및 보안 점검과 같은 특정 작업은 네트워크 또는 디스크 사용량에 예기치 않은 영향을 미쳐 복제 프로세스를 지연시킬 수 있습니다.
애플리케이션에 복제 지연이 있는지 확실하지 않은 경우 걱정하지 마십시오. 다음 섹션에서 문제 해결 전략에 대해 설명합니다!
MongoDB 복제 세트 문제 해결
복제본 세트를 성공적으로 설정했지만 서버 간에 데이터가 일치하지 않는 것을 발견했습니다. 이것은 대규모 기업에게는 매우 놀라운 일이지만 빠른 문제 해결 방법을 사용하면 원인을 찾거나 문제를 해결할 수도 있습니다! 다음은 유용할 수 있는 복제 세트 배포 문제 해결을 위한 몇 가지 일반적인 전략입니다.
복제 상태 확인
Replica Set의 Primary에 연결된 Mongosh 세션에서 다음 명령을 실행하여 Replica Set의 현재 상태와 각 구성원의 상태를 확인할 수 있습니다.
rs.status()복제 지연 확인
앞서 논의한 바와 같이 복제 지연은 "지연된" 구성원이 빠르게 기본이 될 수 없게 만들고 분산 읽기 작업이 일관되지 않을 가능성을 증가시키므로 심각한 문제가 될 수 있습니다. 다음 명령을 사용하여 복제 로그의 현재 길이를 확인할 수 있습니다.
rs.printSecondaryReplicationInfo() 이는 마지막 oplog 항목이 각 구성원의 보조에 기록된 시간인 syncedTo 값을 반환합니다. 동일한 것을 보여주는 예는 다음과 같습니다.
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary 지연된 구성원은 기본의 비활성 기간이 members[n].secondaryDelaySecs 값보다 큰 경우 기본보다 0초 뒤처진 것으로 표시될 수 있습니다.
모든 구성원 간의 연결 테스트
복제 세트의 각 구성원은 다른 모든 구성원과 연결할 수 있어야 합니다. 항상 양방향 연결을 확인하십시오. 대부분 방화벽 구성 또는 네트워크 토폴로지는 복제를 차단할 수 있는 정상적인 필수 연결을 방지합니다.
예를 들어 mongod 인스턴스가 IP 주소 198.41.110.1과 연결된 localhost 및 호스트 이름 'ExampleHostname' 모두에 바인딩한다고 가정해 보겠습니다.
mongod --bind_ip localhost, ExampleHostname이 인스턴스에 연결하려면 원격 클라이언트가 호스트 이름 또는 IP 주소를 지정해야 합니다.
mongosh --host ExampleHostname mongosh --host 198.41.110.1복제본 세트가 기본 포트 27017을 사용하여 m1, m2 및 m3의 세 구성원으로 구성된 경우 아래와 같이 연결을 테스트해야 합니다.
m1에서:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017m2에서:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017m3에서:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 어떤 방향으로든 연결이 실패하면 방화벽 구성을 확인하고 연결을 허용하도록 다시 구성해야 합니다.
키 파일 인증으로 보안 통신 보장
기본적으로 MongoDB의 키 파일 인증은 솔티드 챌린지 응답 인증 메커니즘(SCRAM)에 의존합니다. 이를 위해 MongoDB는 특정 MongoDB 인스턴스가 알고 있는 사용자 이름, 암호 및 인증 데이터베이스의 조합을 포함하는 사용자가 제공한 자격 증명을 읽고 유효성을 검사해야 합니다. 이는 데이터베이스에 연결할 때 암호를 제공하는 사용자를 인증하는 데 사용되는 정확한 메커니즘입니다.
MongoDB에서 인증을 활성화하면 복제 세트에 대해 RBAC(역할 기반 액세스 제어)가 자동으로 활성화되고 사용자에게 데이터베이스 리소스에 대한 액세스를 결정하는 하나 이상의 역할이 부여됩니다. RBAC가 활성화되면 적절한 권한이 있는 인증된 유효한 Mongo 사용자만 시스템의 리소스에 액세스할 수 있음을 의미합니다.
키 파일은 클러스터의 각 구성원에 대한 공유 암호처럼 작동합니다. 이렇게 하면 복제 세트의 각 mongod 인스턴스가 키 파일의 내용을 배포의 다른 구성원을 인증하기 위한 공유 암호로 사용할 수 있습니다.
올바른 키 파일이 있는 mongod 인스턴스만 복제 세트에 가입할 수 있습니다. 키 길이는 6자에서 1024자 사이여야 하며 base64 세트의 문자만 포함할 수 있습니다. MongoDB는 키를 읽을 때 공백 문자를 제거합니다.
다양한 방법을 사용하여 키 파일을 생성 할 수 있습니다. 이 자습서에서는 openssl 사용하여 공유 암호로 사용할 복잡한 1024개의 무작위 문자열을 생성합니다. 그런 다음 chmod 사용하여 파일 권한을 변경하여 파일 소유자에게만 읽기 권한을 제공합니다. USB 드라이브 또는 네트워크 연결 저장 장치와 같이 mongod 인스턴스를 호스팅하는 하드웨어에서 쉽게 분리할 수 있는 저장 매체에 키 파일을 저장하지 마십시오. 다음은 키 파일을 생성하는 명령입니다.
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. 예를 들어:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
짜잔! You have successfully enabled keyfile authentication!
요약
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? 아래 댓글 섹션에서 알려주세요!