
Podstawa do zrozumienia fragmentacji bazy danych
Opublikowany: 2022-11-05Stworzenie strony internetowej to pierwszy krok przy konfigurowaniu swojej obecności w Internecie. Aby prosperować w dłuższej perspektywie, musisz również upewnić się, że Twoja witryna może się skalować, aby dostosować się do wzrostu. Jednym z pierwszych kroków jest wdrożenie bazy danych, którą można skalować razem z Tobą. W przeciwnym razie istnieje ryzyko niskiej wydajności zapytań i awarii bazy danych.
W tym poście omówimy, w jaki sposób można użyć fragmentowania bazy danych, aby uzyskać wysoką skalowalność i dostępność danych. Dotkniemy również wad shardingu i różnych architektur shardingu, których możesz użyć.
Co to jest fragmentowanie bazy danych?
Sharding to technika optymalizacji, która rozdziela tabele na inne serwery baz danych. Przypomina to partycjonowanie w tym sensie, że oba obejmują rozbicie danych na mniejsze podzbiory. Różnica polega na tym, że sharding dystrybuuje te podzbiory na różne serwery podczas partycjonowania przechowuje je w jednej bazie danych. Serwery te używają tego samego aparatu bazy danych i tego samego typu sprzętu, aby osiągnąć podobny poziom wydajności dla wszystkich fragmentów.
Sharding ma na celu osiągnięcie architektury bez udostępniania, eliminując wąskie gardła przetwarzania i pojedyncze punkty awarii.
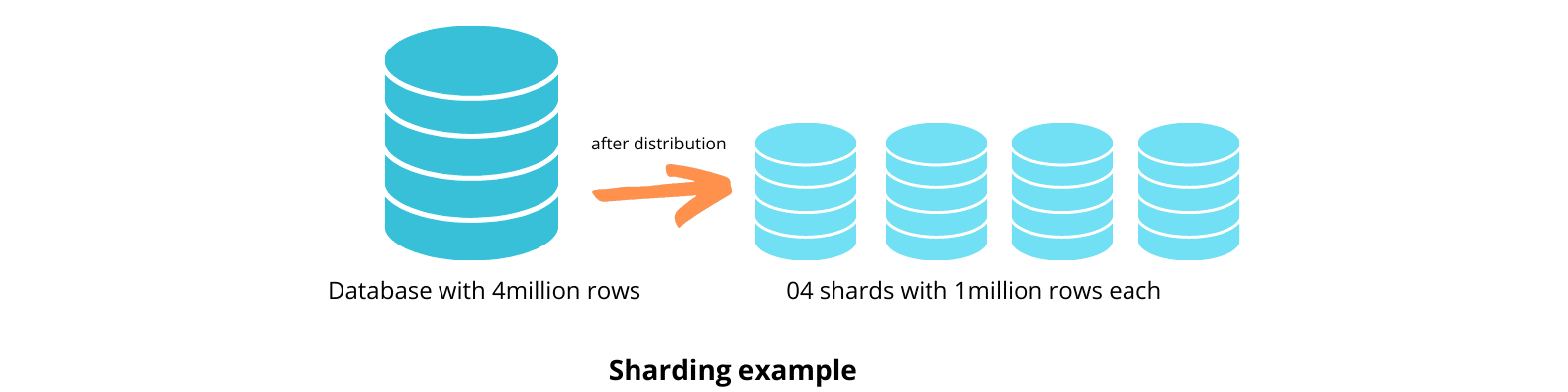
Sharding możesz zaimplementować na dwa sposoby — poziomo i pionowo. Fragmentacja pozioma dzieli tabelę na podstawie wierszy, a fragmentacja pionowa dzieli tabele na podstawie kolumn.
Pod tym względem sharding przypomina partycjonowanie, które dzieli duże tabele na mniejsze.
Fragmentowanie poziome jest skuteczne w przypadku baz danych, w których większość zapytań zwraca podzbiór wierszy, takich jak baza danych klientów, która jednocześnie zwraca dane (takie jak imię i nazwisko, adres, adres e-mail itd.).
Fragmentacja w pionie jest skuteczna w przypadku baz danych, których zapytania zwracają pojedyncze kolumny. Na przykład, jeśli baza danych klientów zwróciła nazwę klienta lub adres e-mail oddzielnie, możesz oddzielić nazwę i adres e-mail do różnych klastrów.
Korzyści z dzielenia bazy danych
Poniżej znajdują się niektóre zalety shardingu bazy danych.
Ulepszone skalowanie poziome
Bazę danych można skalować w pionie lub poziomie. Skalowanie pionowe odnosi się do dodawania do serwera większej liczby jednostek centralnych (CPU) i pamięci o dostępie swobodnym (RAM) w celu poprawy wydajności. Skalowanie w pionie to pomocne rozwiązanie dla małych i średnich baz danych. Jednak wraz ze wzrostem ilości danych skalowanie w pionie staje się niewykonalne. Do jednego serwera można dodać tylko tyle mocy.
Skalowanie poziome jest bardziej elastyczne. Umożliwia skalowanie bazy danych zgodnie z potrzebami poprzez dodanie większej liczby serwerów do systemu. Każdy z tych serwerów udostępnia zasoby różnym fragmentom bazy danych. Rozkłada to obciążenie i poprawia zdolność systemu do obsługi większej liczby żądań.
Szybsze czasy odpowiedzi na zapytania
Odłamki mają tylko kilka wierszy i kolumn. Z tego powodu przetwarzanie zapytań do bazy danych zajmuje mniej czasu. Natomiast zapytanie z bazy danych nie podzielonej na fragmenty może wymagać przeszukania setek, a nawet tysięcy wierszy.
Zwiększona niezawodność w sytuacjach przestojów
Awarie bazy danych zdarzają się z różnych powodów, w tym przypadkowego usunięcia danych, błędów połączenia i ataków cyberbezpieczeństwa. Sharding minimalizuje skutki przestojów. Ponieważ każdy fragment jest autonomiczny, tylko fragment, którego dotyczy problem, podlega przestojowi. Na przykład, jeśli masz cztery fragmenty i wystąpi awaria jednego z nich, dotyczy to tylko 25% operacji.
Wady shardingu
Chociaż fragmentowanie poprawia niezawodność i dostępność bazy danych, jej wdrożenie jest złożone. Użycie niewłaściwej architektury shardingu może spowolnić wydajność i doprowadzić do utraty danych.
Pamiętaj, aby wybrać technikę fragmentowania, która umożliwia zrównoważoną dystrybucję danych we wszystkich fragmentach. Bez tej równowagi ryzykujesz tworzenie punktów aktywnych bazy danych, co ma miejsce, gdy jeden fragment przechowuje większość danych, podczas gdy inne fragmenty pozostają praktycznie puste. Zmniejsza to przepustowość zapisu do pojedynczego fragmentu.
Aby rozwiązać ten problem, możesz jeszcze bardziej podzielić niezrównoważony fragment, ale ten proces jest trudny i może spowodować uszkodzenie bazy danych podczas migracji danych.
Chcesz wiedzieć, jak zwiększyliśmy ruch o ponad 1000%?
Dołącz do ponad 20 000 innych osób, które otrzymują nasz cotygodniowy biuletyn z poufnymi wskazówkami dotyczącymi WordPressa!

Inną wadą shardingu jest to, że sprzężenia SQL obejmujące wiele tabel w różnych fragmentach mogą stać się zbyt wolne i obniżyć wydajność. Jednak przy odpowiedniej architekturze można uniknąć tego problemu.
Architektury shardingu
Możesz zaimplementować sharding przy użyciu trzech architektur:
- Fragmentacja oparta na kluczu
- Sharding na podstawie zakresu
- Fragmentacja oparta na katalogach
Wybrana architektura zależy od przypadku użycia.
Fragmentacja oparta na kluczu
W architekturze fragmentowania opartej na kluczu lub skrótach aplikacja bazy danych używa klucza fragmentu do zlokalizowania fragmentu. Funkcja mieszająca miesza wartość klucza fragmentowania, a dane wyjściowe mapują dane do określonego fragmentu. Prostą funkcją mieszającą może być moduł klucza i liczba odłamków.
Funkcja skrótu może zająć więcej niż jeden klucz fragmentowania. Z tego powodu fragmentacja na podstawie klucza jest odpowiednia dla rekordów danych, które mogą mieć klucze współdzielone. Algorytmiczna dystrybucja danych minimalizuje możliwość tworzenia hotspotów bazy danych, w których jeden fragment zawiera więcej danych niż drugi.
Ponieważ jednak dystrybucja opiera się tylko na funkcji mieszającej, nie można logicznie pogrupować danych. W związku z tym operacje bazy danych, które wymagają danych z wielu fragmentów, mogą być nieefektywne, ponieważ wymagają odczytywania danych z każdego fragmentu.
Sharding na podstawie zasięgu
Fragmentowanie na podstawie zakresu obejmuje fragmentowanie bazy danych w zależności od określonego zakresu wartości.
Używa klucza fragmentowania, aby określić, do którego fragmentu przypisać wartość. Aplikacja bazy danych sprawdza fragment odpowiadający kluczowi fragmentowania w tabeli przeglądowej i przechowuje dane. Z tego powodu sharding na podstawie zakresu jest łatwy do zaprojektowania i wdrożenia.
Na przykład można użyć wartości identyfikatora użytkownika w bazie danych użytkowników jako klucza fragmentowania. Możesz przechowywać użytkowników z identyfikatorami od 0 do 2000 na jednym fragmencie, od 2000 do 4000 na innym fragmencie i tak dalej.
Fragmentowanie na podstawie zakresu może powodować powstawanie hotspotów bazy danych. Rozważmy bazę danych użytkowników, w której większość identyfikatorów użytkowników mieści się w przedziale od 2001 do 4000. Proces przypisuje je do jednego fragmentu, tworząc z czasem nierównowagę. Dlatego fragmentowanie na podstawie zakresu działa najlepiej w przypadku równomiernie rozproszonych danych.
Fragmentacja oparta na katalogach
Fragmentacji opartej na katalogu grupuje logicznie powiązane dane w tym samym fragmencie. Używa tabeli przeglądowej zawierającej listę mapowań dla każdej jednostki w bazie danych. Każde mapowanie odpowiada fragmentowi bazy danych.
Fragmentowanie oparte na katalogach jest bardziej elastyczne niż fragmentowanie oparte na zakresie lub na podstawie klucza, ponieważ można dynamicznie dodawać dane do fragmentów. Nie ma funkcji shardingu do naśladowania ani wartości zakresu, w których można by pozostać. Ta elastyczność zwiększa wydajność bazy danych: możesz przechowywać powiązane dane w jednym fragmencie, co oznacza, że wykonywanie typowych zapytań zajmuje mniej czasu.
Na przykład, jeśli używasz fragmentowania opartego na katalogu i pogrupowano użytkowników według ich lokalizacji, pobierając użytkowników z określonego miejsca, wysyłasz zapytanie tylko do jednego fragmentu.
Sharding bazy danych z Kinsta
Większość nowoczesnych aparatów baz danych zapewnia obsługę fragmentowania bazy danych. Jednym z takich silników baz danych jest MariaDB, komercyjnie obsługiwany fork MySQL. Jest to wysokowydajny system baz danych typu open source, przyjęty przez firmy takie jak IBM, GitHub i Wikimedia. Jest to również część wysokowydajnego stosu serwerów w Kinsta.
MariaDB oferuje wbudowane funkcje dzielenia na fragmenty za pośrednictwem aparatu magazynu pająka. Aparat magazynu pająka to aparat tworzenia klastrów, który obsługuje partycjonowanie i transakcje architektury rozszerzonej (XA). Pozwala na traktowanie zdalnych tabel z różnych instancji tak, jakby znajdowały się w tej samej instancji. Po utworzeniu tabeli w aparacie magazynu pająka tabela łączy się z inną tabelą na zdalnym serwerze MariaDB. Po nawiązaniu połączenia aparat pamięci udostępnia łącze wszystkim tabelom, które są częścią tej samej transakcji.
Streszczenie
Fragmentowanie bazy danych to technika skalowania, która dzieli tabele na mniejsze podzbiory i dystrybuuje je na różne serwery zwane fragmentami. Fragmentowanie można zaimplementować na różne sposoby, takie jak fragmentowanie oparte na kluczu, fragmentowanie oparte na zakresach i fragmentowanie oparte na katalogach.
Chociaż fragmentowanie poprawia skalowalność, niezawodność i dostępność bazy danych, jej wdrożenie jest bardzo złożone. Co więcej, po utworzeniu fragmentu nie jest łatwo przywrócić bazę danych do stanu bez fragmentów. Z tego powodu używaj fragmentowania do optymalizacji tylko wtedy, gdy masz pewność, że inne opcje skalowalności nie będą działać.
Niezależnie od tego, czy Twoja firma jest organizacją non-profit, czy przedsięwzięciem na poziomie przedsiębiorstwa, rozwiązania eksperckie Kinsta mogą rozwiać obawy związane z hostingiem witryn, umożliwiając Ci skupienie się na tym, co najważniejsze.