
Wprowadzające w błąd statystyki mogą być niebezpieczne (niektóre przykłady)
Opublikowany: 2022-12-06Ludzie polegają na statystykach, aby uzyskać ważne informacje. W świecie biznesu statystyki mogą być przydatne do śledzenia trendów i maksymalizacji produktywności. Czasami jednak statystyki mogą być przedstawiane w mylący sposób . Na przykład w 2007 r. Urząd ds. Standardów Reklamy (ADA) w Wielkiej Brytanii otrzymał skargę dotyczącą reklamy Colgate.
Reklama głosi, że 80% dentystów zaleca stosowanie pasty do zębów Colgate. W skardze, którą otrzymała ADA, argumentowano, że było to naruszenie przepisów dotyczących reklamy w Wielkiej Brytanii. Po zbadaniu sprawy ADA odkryła, że reklama wykorzystywała wprowadzające w błąd statystyki.
Prawdą jest, że wielu dentystów poleca pastę do zębów Colgate. Jednak nie wszyscy wymienili Colgate jako rekomendację numer jeden. Większość dentystów zalecała również inne rodzaje past do zębów, a Colgate zwykle pojawiał się później.
To tylko jeden z przykładów wykorzystania wprowadzających w błąd statystyk. Ludzie spotykają się z wprowadzającymi w błąd przykładami statystyk w wielu różnych dziedzinach życia. Przykłady można znaleźć w wiadomościach, reklamach, polityce, a nawet w nauce.
Ten post pomoże Ci nauczyć się rozpoznawać wprowadzające w błąd statystyki i inne wprowadzające w błąd dane . Omówimy, w jaki sposób te dane wprowadzają ludzi w błąd. Dowiesz się również, kiedy i jak wykorzystywać dane przy podejmowaniu krytycznych decyzji.
Czym są wprowadzające w błąd statystyki?
Statystyka jest wynikiem zbierania danych liczbowych, dokładnej ich analizy, a następnie interpretacji . Statystyki są szczególnie przydatne, jeśli masz do czynienia z dużą ilością danych, ale wszystko, co można zmierzyć, może stać się statystyką. Statystyki często ujawniają wiele o świecie i sposobie, w jaki działa.
Jednak gdy informacje te są niewłaściwie wykorzystywane, nawet przez przypadek, stają się mylącą statystyką. Wprowadzające w błąd statystyki dostarczają ludziom fałszywych informacji, które raczej ich oszukują niż informują .
Gdy ludzie wyjmą statystykę z kontekstu, traci ona swoją wartość i może prowadzić do wyciągania błędnych wniosków. Termin „wprowadzające w błąd statystyki” opisuje każdą metodę statystyczną, która nieprawidłowo przedstawia dane. Niezależnie od tego, czy było to zamierzone, czy nie , nadal będzie się liczyć jako wprowadzająca w błąd statystyka.
Podczas zbierania danych do statystyki należy pamiętać o trzech podstawowych kwestiach. W każdym z tych punktów może wystąpić problem z analizą danych.
- Kolekcja: Podczas zbierania danych
- Przetwarzanie: Podczas analizy danych i ich implikacji
- Prezentacja: Kiedy dzielisz się swoimi odkryciami z innymi
Mały rozmiar próbki
Ankiety wielkości próby są jednym z przykładów tworzenia wprowadzających w błąd statystyk. Ankiety lub badania przeprowadzane na próbie odbiorców często dają wyniki, które są tak mylące, że są bezużyteczne.
Aby to zilustrować, w ankiecie zadano 20 osobom pytanie typu „tak” lub „nie”. 19 osób odpowiedziało twierdząco na ankietę. Wyniki pokazują więc, że 95% osób odpowiedziałoby twierdząco na to pytanie. Ale to nie jest dobre badanie, ponieważ informacje są ograniczone.
Ta statystyka nie ma prawdziwej wartości. Teraz, jeśli zadasz to samo pytanie 1000 osobom, a 950 odpowie tak, to jest to o wiele bardziej wiarygodna statystyka pokazująca, że 95% ludzi odpowiedziałoby tak.
Aby przeprowadzić wiarygodne badanie wielkości próby, należy wziąć pod uwagę trzy rzeczy:
- Pierwszy : Jakiego rodzaju pytanie zadajesz?
- Dwa : Jakie jest znaczenie statystyk, które próbujesz znaleźć?
- I po trzecie : Jakiej techniki statystycznej użyjesz?
Aby uzyskać wiarygodne wyniki, każda analiza ilościowa wielkości próby powinna obejmować co najmniej 200 osób.
Załadowane pytania

Ważne jest, aby szukać danych z neutralnego źródła . W przeciwnym razie informacja jest przekrzywiona. Załadowane pytania wykorzystują kontrowersyjne lub nieuzasadnione założenie do manipulowania odpowiedzią. Jednym z przykładów jest zadanie pytania rozpoczynającego się od słów: „Co kochasz?”. To pytanie świetnie zbiera pozytywne opinie, ale nie uczy niczego przydatnego. Nie daje takiej osobie możliwości wyrażenia szczerych myśli i opinii.
Rozważ różnicę w następujących dwóch pytaniach:
- Czy popierasz reformę podatkową, która wiązałaby się z wyższymi podatkami?
- Czy popierasz reformę podatkową, która byłaby korzystna dla redystrybucji społecznej?
Pytanie zasadniczo dotyczy tego samego tematu, ale wyniki każdego z tych pytań byłyby zupełnie inne. Sondaże powinny być przeprowadzane w sposób bezstronny i bezstronny. Chcesz uzyskać szczere opinie ludzi i pełny obraz tego, co ludzie myślą. Aby to osiągnąć, twoje pytania nie powinny sugerować odpowiedzi ani wywoływać reakcji emocjonalnej .
Powoływanie się na wprowadzające w błąd „średnie”
Niektórzy ludzie używają terminu „średnia”, aby ukryć prawdę lub kłamać, aby informacje wyglądały lepiej.
Ta technika jest szczególnie przydatna, jeśli ktoś chce, aby liczba wydawała się większa lub lepsza niż jest w rzeczywistości. Na przykład uczelnia chcąca przyciągnąć nowych studentów może zapewnić „przeciętne” roczne wynagrodzenie absolwentom swojej uczelni. Ale może być tylko garstka studentów, którzy faktycznie mają wysokie pensje. Ale ich pensje sprawiają, że średni dochód dla wszystkich studentów jest wyższy. To wygląda lepiej dla całej średniej.
Średnie są również przydatne do ukrywania nierówności. Jako inny przykład załóżmy, że jedna firma płaci 20 000 USD rocznie swoim 90 pracownikom. Ale ich szef otrzymuje 200 000 $ rocznie. Jeśli połączymy wynagrodzenie szefa z wynagrodzeniem pracowników, średni dochód każdego członka firmy wynosi 21 978 USD.
Na papierze wygląda to świetnie. Ale ta liczba nie mówi całej historii, ponieważ jeden z pracowników (szef) zarabia znacznie więcej niż inni pracownicy. Dlatego tego rodzaju wyniki są traktowane jako wprowadzające w błąd statystyki.
Dane skumulowane a dane roczne
Dane skumulowane śledzą informacje na wykresie w czasie. Za każdym razem, gdy wprowadzasz dane do wykresów, wykres rośnie.
Dane roczne przedstawiają wszystkie dane za dany rok.
Śledzenie informacji dla każdego roku zapewnia wierniejszy obraz ogólnych trendów.
Przykładem wykresu zbiorczego jest wykres Worldometer COVID-19. Podczas pandemii COVID-19 pojawiło się wiele przykładów skumulowanych wykresów. Często odzwierciedlają skumulowaną liczbę przypadków COVID na określonym obszarze.
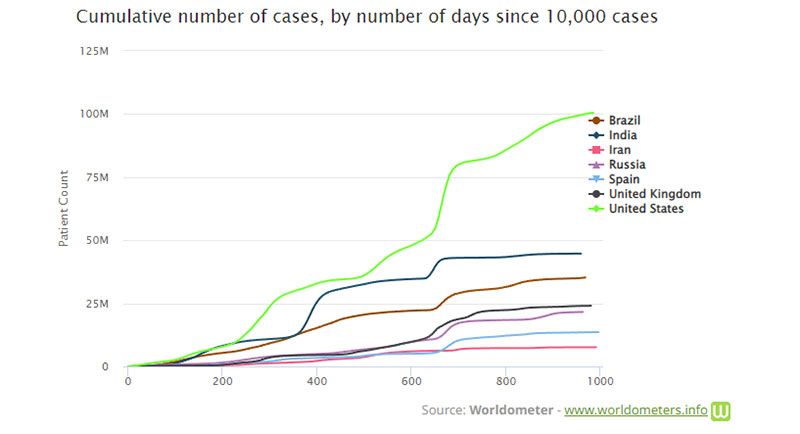
Niektóre firmy używają takich wykresów, aby sprzedaż wydawała się większa niż jest w rzeczywistości. W 2013 roku dyrektor generalny Apple, Tim Cook, został skrytykowany za użycie prezentacji pokazującej tylko łączną liczbę sprzedaży iPhone'a. Wielu w tamtym czasie uważało, że zrobił to celowo, aby ukryć fakt, że sprzedaż iPhone'ów spadała.
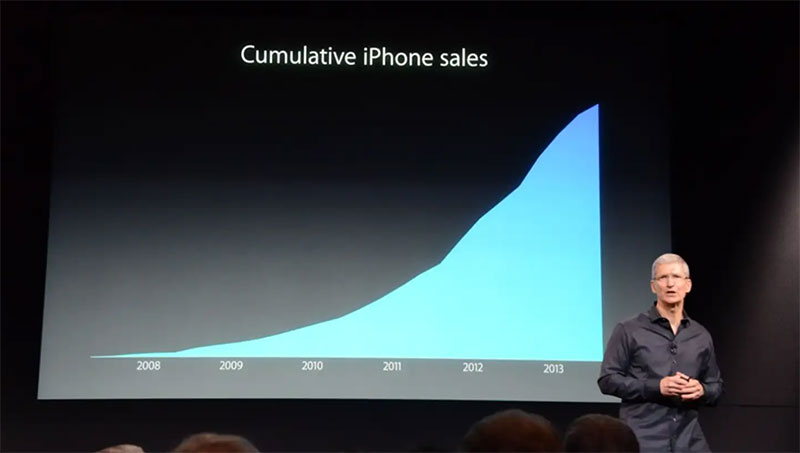
Nie oznacza to, że wszystkie dane skumulowane są złe lub fałszywe. W rzeczywistości może być przydatny do śledzenia zmian lub wzrostu i różnych sum. Ale ważne jest, aby zwracać uwagę na zmiany w danych. Następnie przyjrzyj się dokładniej, co je spowodowało, zamiast polegać na wykresie, który powie ci wszystko.
Nadmierna generalizacja i tendencyjne próbki
Nadmierna generalizacja ma miejsce, gdy ktoś zakłada, że to, co jest prawdą dla jednej osoby, musi być prawdą dla wszystkich innych. Zwykle ten błąd pojawia się, gdy ktoś przeprowadza badanie z pewną grupą ludzi. Następnie zakładają, że wyniki będą prawdziwe dla innej, niepowiązanej grupy ludzi.
Próby niereprezentatywne lub próby stronnicze to ankiety, które nie odzwierciedlają dokładnie populacji ogólnej.
Jeden przykład stronniczych prób miał miejsce podczas wyborów prezydenckich w 1936 roku w Stanach Zjednoczonych Ameryki.
Popularny wówczas magazyn „Literary Digest” przeprowadził ankietę, aby przewidzieć, kto wygra wybory. Wyniki przewidywały, że Alfred Landon wygra przez osuwisko.
Pismo to znane było z trafnego przewidywania wyników wyborów. Jednak w tym roku całkowicie się mylili. Franklin Roosevelt wygrał z prawie dwukrotnie większą liczbą głosów niż jego przeciwnik.
Niektóre dalsze badania ujawniły, że w grę weszły dwie zmienne, które zniekształciły wyniki.
Po pierwsze , większość uczestników badania stanowiły osoby znajdujące się w książce telefonicznej i na listach autorejestracyjnych. Tak więc ankieta została przeprowadzona tylko z osobami o określonym statusie społeczno-ekonomicznym.
Drugim czynnikiem było to, że ci, którzy głosowali na Landona, byli bardziej skłonni odpowiedzieć na ankietę niż ci, którzy zdecydowali się głosować na Roosevelta. Tak więc wyniki odzwierciedlały to nastawienie.
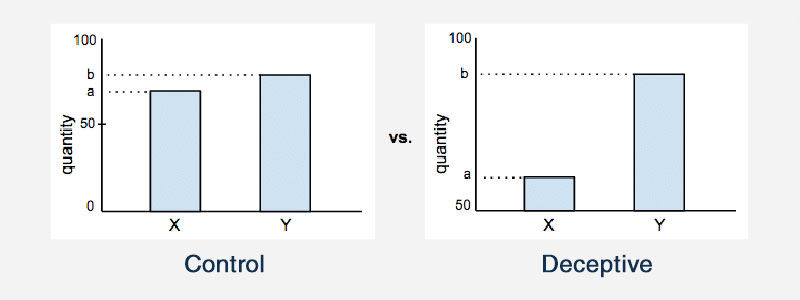
Obcinanie osi
Obcinanie osi na wykresie to kolejny przykład wprowadzających w błąd statystyk. Na większości wykresów statystycznych zarówno oś x, jak i oś y prawdopodobnie zaczynają się od zera. Ale obcięcie osi oznacza, że wykres faktycznie zaczyna osie od innej wartości. Wpływa to na wygląd wykresu i na wnioski, jakie wyciągnie dana osoba.
Oto jeden przykład, który to ilustruje:
Inny tego przykład miał miejsce niedawno, we wrześniu 2021 r. W jednej z audycji Fox News prezenter użył wykresu pokazującego liczbę Amerykanów, którzy twierdzili, że są chrześcijanami. Wykres pokazuje, że liczba Amerykanów, którzy identyfikują się jako chrześcijanie, drastycznie spadła w ciągu ostatnich 10 lat.
Na poniższym wykresie widzimy, że w 2009 roku 77% Amerykanów identyfikowało się jako chrześcijanie.
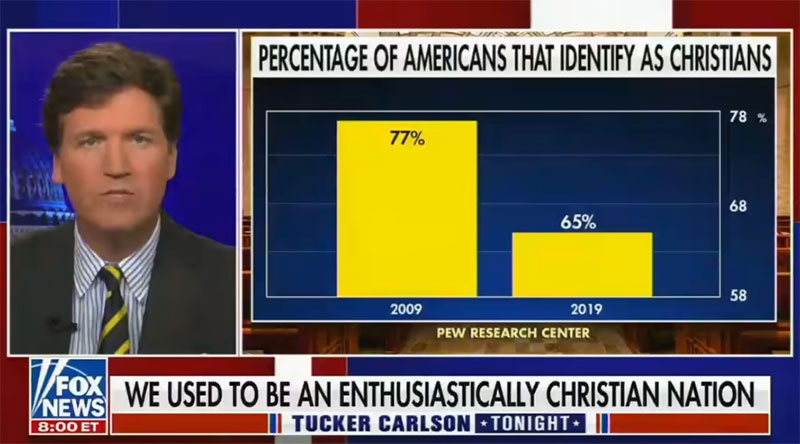
Do 2019 roku liczba ta spadła do 65%. W rzeczywistości nie jest to duży spadek. Ale oś na tym wykresie zaczyna się od 58% i kończy na 78%. Tak więc spadek o 12% w latach 2009-2019 wydaje się znacznie bardziej drastyczny niż jest w rzeczywistości.

Przyczynowość i korelacja
Łatwo założyć połączenie między dwoma pozornie połączonymi punktami danych. Jednak mówi się, że korelacja nie implikuje związku przyczynowego . Dlaczego to jest takie?
Ten wykres ilustruje, dlaczego korelacja to nie to samo, co związek przyczynowy.
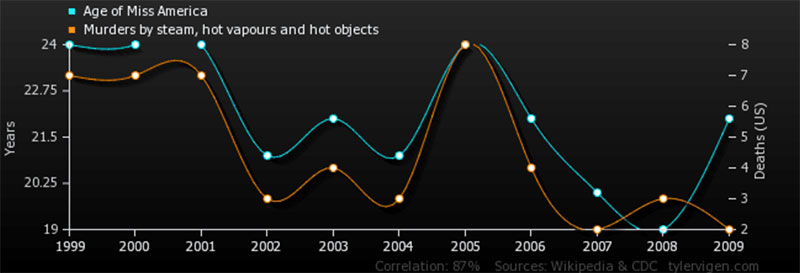
Badacze często znajdują się pod dużą presją, aby odkrywać nowe, przydatne dane. Tak więc pokusa, by wyskoczyć z pistoletu i przedwcześnie wyciągnąć wnioski, jest zawsze obecna. Dlatego tak ważne jest , aby w każdej sytuacji szukać rzeczywistej przyczyny i skutku .
Używanie procentów do ukrywania liczb i obliczeń
Wartość procentowa może ukryć dokładne liczby i sprawić, że wyniki będą wyglądać na bardziej wiarygodne i wiarygodne niż w rzeczywistości.
Na przykład, jeśli dwie osoby na trzy preferują określony środek czyszczący, można powiedzieć, że 66,667% osób preferuje ten produkt. To sprawia, że liczba wygląda bardziej oficjalnie, zwłaszcza z uwzględnieniem liczb po przecinku.
Oto kilka innych sposobów, w jakie ułamki dziesiętne i procenty mogą zaciemniać prawdę:
- Ukrywanie surowych liczb i małych rozmiarów próbek . Procenty przesłaniają bezwzględną wartość surowych liczb. Dzięki temu są przydatne dla osób, które chcą ukryć niepochlebne liczby lub wyniki małej próby.
- Korzystanie z różnych baz. Ponieważ wartości procentowe nie dostarczają oryginalnych liczb, na których są oparte, łatwo można zniekształcić wyniki. Jeśli ktoś chciał, aby jedna liczba wyglądała lepiej, mógł obliczyć tę liczbę na podstawie innej podstawy.
Stało się to raz w raporcie opublikowanym przez New York Times na temat związkowców. Pracownikom obniżono pensje o 20% w ciągu jednego roku, aw następnym roku Times doniósł, że związkowcy otrzymali podwyżkę o 5%. Twierdzono więc, że zwrócono im jedną czwartą obniżki wynagrodzenia.
Jednak pracownicy otrzymali 5% podwyżkę w oparciu o ich obecne wynagrodzenie, a nie wynagrodzenie, które mieli przed obniżką płac. Więc nawet jeśli wyglądało to dobrze na papierze, 20-procentowa obniżka płac i 5-procentowa podwyżka zostały obliczone na podstawie różnych liczb bazowych. Te dwie liczby w ogóle się nie porównywały.
Wybieranie wiśni/odrzucanie niekorzystnych danych
Termin „zbieranie wiśni” opiera się na idei zbierania tylko najlepszych owoców z drzewa. Każdy, kto zobaczy ten owoc, z pewnością pomyśli, że wszystkie owoce na drzewie są równie zdrowe. Oczywiście niekoniecznie tak musi być.
Ta sama zasada obowiązuje w przypadku zmian klimatycznych. Wiele wykresów ogranicza ramkę danych do pokazywania zmian klimatycznych tylko w latach 2000-2013.
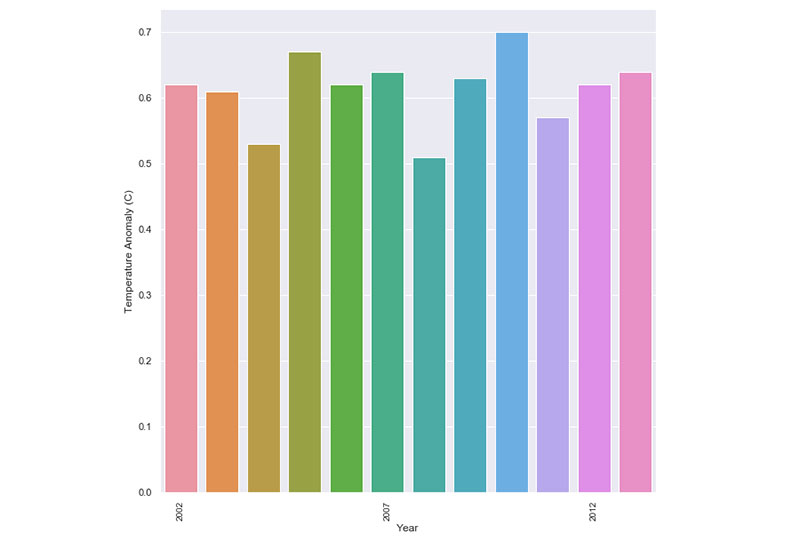
W rezultacie wydaje się, że zmiany temperatury i anomalie są spójne i niewiele się zmieniają. Kiedy jednak cofniesz się o krok i spojrzysz na duży obraz, staje się jasne, gdzie są zmiany i anomalie.
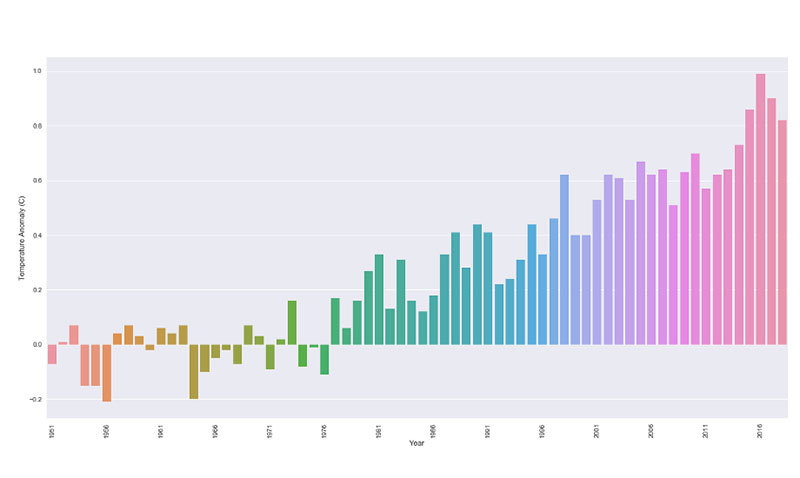
Dzieje się tak również w dziedzinie medycyny weterynaryjnej. Kiedy weterynarze są proszeni o przedstawienie wyników nowego leku próbnego, zwykle przedstawiają najlepsze wyniki. Zwłaszcza jeśli firma farmaceutyczna popiera badanie, chce zobaczyć tylko najlepsze wyniki.
Twoje piękne dane zasługują na to, by być online
wpDataTables może to zrobić w ten sposób. Jest dobry powód, dla którego jest to wtyczka WordPress nr 1 do tworzenia responsywnych tabel i wykresów.
I naprawdę łatwo jest zrobić coś takiego:
- Podajesz dane tabeli
- Skonfiguruj i dostosuj go
- Opublikuj go w poście lub na stronie
I jest nie tylko ładny, ale także praktyczny. Możesz tworzyć duże tabele zawierające nawet miliony wierszy, możesz użyć zaawansowanych filtrów i wyszukiwania lub możesz zaszaleć i udostępnić je do edycji.
„Tak, ale po prostu za bardzo lubię Excela, a na stronach internetowych nie ma czegoś takiego”. Tak, jest. Możesz użyć formatowania warunkowego, takiego jak w Excelu lub Arkuszach Google.
Czy mówiłem ci, że możesz także tworzyć wykresy ze swoimi danymi? A to tylko niewielka część. Istnieje wiele innych funkcji dla Ciebie.
Łowienie danych
Połów danych, znany również jako pogłębianie danych, to analiza dużych ilości danych w celu znalezienia korelacji. Jednak, jak omówiono wcześniej w tym poście, korelacja nie oznacza związku przyczynowego. Upieranie się, że prowadzi to jedynie do wprowadzających w błąd statystyk.
Przykłady łowienia danych na polach branżowych można zobaczyć na co dzień. Tydzień później ujawnia się skandal dotyczący eksploracji danych, a tydzień później obala go jeszcze bardziej skandaliczny raport.
Innym problemem związanym z tego rodzaju analizą danych jest to, że ludzie wybierają tylko te dane, które wspierają ich pogląd, a resztę ignorują. Pomijając sprzeczne informacje, sprawiają, że wyniki wyglądają bardziej przekonująco .
Mylące etykiety wykresów i wykresów
Kiedy rozpoczęła się pandemia COVID-19, więcej osób niż kiedykolwiek zwróciło się ku wizualizacjom danych dotyczących rozprzestrzeniania się wirusa. Ludzie, którzy nigdy nie musieli pracować z wizualną reprezentacją statystyk, zostali nagle wyrzuceni na głęboką wodę danych statystycznych.
Poza tym organizacje często starały się szybko uzyskać informacje o ludziach. Czasami oznaczało to poświęcenie dokładnych statystyk. Spowodowało to gwałtowny wzrost liczby wprowadzających w błąd statystyk i błędnej interpretacji danych.
Około pięć miesięcy po rozpoczęciu rozprzestrzeniania się COVID-19 Departament Zdrowia Publicznego stanu Georgia opublikował następujący wykres:
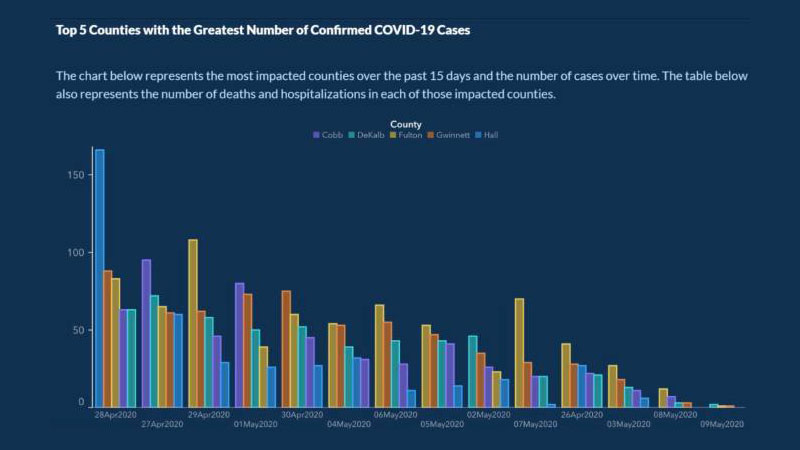
Celem wykresu było pokazanie 5 krajów o największej liczbie przypadków COVID w ciągu ostatnich 15 dni oraz liczby przypadków w danym okresie.
Ten wykres zawiera kilka błędów, które ułatwiają błędne zrozumienie. Na przykład oś x nie ma etykiety wyjaśniającej, że przedstawia postęp przypadków w czasie.
Co gorsza, daty na wykresie nie są ułożone chronologicznie. Daty z kwietnia i maja są rozrzucone po całym wykresie, aby wyglądało na to, że liczba przypadków stale spada. Każdy kraj jest również wymieniony w taki sposób, aby wyglądało na to, że liczba przypadków spada.
Później ponownie opublikowali wykres z lepiej zorganizowanymi datami i hrabstwami:
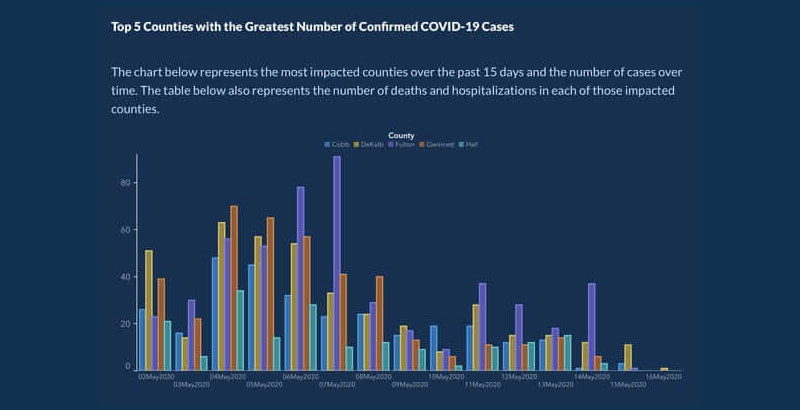
Niedokładne liczby
Innym przykładem wprowadzających w błąd statystyk są niedokładne liczby. Zwróć uwagę na to stwierdzenie ze starej kampanii Reeboka.
Reklama twierdzi, że but działa na ścięgna podkolanowe i łydki o 11% mocniej i może ujędrnić pośladki nawet o 28% bardziej niż inne tenisówki . Wszystko, co osoba musi zrobić, to chodzić w tenisówkach.
Te liczby sugerują, że Reebok przeprowadził szeroko zakrojone badania nad zaletami buta.
Rzeczywistość była taka, że liczby te zostały całkowicie zmyślone. Za stosowanie tak wprowadzających w błąd statystyk marka otrzymała karę. Musieli też zmienić oświadczenie i usunąć fałszywe numery.
Jak unikać i identyfikować niewłaściwe wykorzystanie statystyk
Statystyki mogą być niezwykle przydatne. Ale wprowadzające w błąd statystyki mogą również wprowadzać w błąd i oszukiwać ludzi. Statystyka nadaje autorytet oświadczeniu i przekonuje ludzi do zaufania danemu argumentowi.
Rzetelne, prawdziwe statystyki dają ludziom wgląd i pomagają im podejmować decyzje. Jednak wprowadzające w błąd statystyki są niebezpieczne . Zamiast pomagać ludziom w unikaniu pułapek i wybojów, prowadzą ich prosto w sytuacje, których chcieli uniknąć.
Ale możliwe jest zidentyfikowanie wprowadzających w błąd statystyk i danych. Kiedy natkniesz się na statystyki, zatrzymaj się i zadaj następujące pytania:
- Skąd pochodzą te dane?
- Czy źródło jest kontrolowane? A może jest to eksperyment wielkości próbki?
- Jakie inne czynniki mogą mieć wpływ na ten wynik?
- Czy informacje mają na celu poinformowanie mnie, czy też kierują mnie do z góry ustalonego wniosku?
Niezależnie od tego, czy zbierasz dane, czy przeglądasz wyniki badań innych osób, upewnij się, że dane są dokładne. W ten sposób nie przyczyniasz się do rozpowszechniania wprowadzających w błąd statystyk .
Jeśli podobał Ci się artykuł o wprowadzających w błąd statystykach, przeczytaj również te:
- Najbardziej imponująca interaktywna wizualizacja danych, jaką znajdziesz w Internecie
- Najlepsze narzędzia do wizualizacji danych WordPress, jakie możesz znaleźć
- Najlepsze narzędzia i platformy do wizualizacji danych dla Ciebie