
Zbuduj solidny zestaw replik MongoDB w rekordowym czasie (4 metody)
Opublikowany: 2023-03-11MongoDB to baza danych NoSQL, która wykorzystuje dokumenty podobne do JSON z dynamicznymi schematami. Podczas pracy z bazami danych zawsze warto mieć plan awaryjny na wypadek awarii jednego z serwerów baz danych. Sidebar, możesz zmniejszyć szanse, że tak się stanie, wykorzystując sprytne narzędzie do zarządzania witryną WordPress.
Dlatego warto mieć wiele kopii swoich danych. Zmniejsza również opóźnienia odczytu. Jednocześnie może poprawić skalowalność i dostępność bazy danych. W tym miejscu pojawia się replikacja. Jest ona zdefiniowana jako praktyka synchronizacji danych w wielu bazach danych.
W tym artykule zagłębimy się w różne najistotniejsze aspekty replikacji MongoDB, takie jak jej funkcje i mechanizm, by wymienić tylko kilka.
Co to jest replikacja w MongoDB?
W MongoDB zestawy replik wykonują replikację. Jest to grupa serwerów utrzymujących ten sam zestaw danych poprzez replikację. Możesz nawet użyć replikacji MongoDB jako części równoważenia obciążenia. Tutaj możesz rozłożyć operacje zapisu i odczytu na wszystkie instancje, w oparciu o przypadek użycia.
Co to jest zestaw replik MongoDB?
Każda instancja MongoDB, która jest częścią danego zestawu replik, jest członkiem. Każdy zestaw replik musi mieć podstawowy element członkowski i co najmniej jeden dodatkowy element członkowski.
Podstawowy element członkowski jest podstawowym punktem dostępu dla transakcji z zestawem replik. Jest to również jedyny element członkowski, który może akceptować operacje zapisu. Replikacja najpierw kopiuje oplog podstawowego (dziennik operacji). Następnie powtarza zarejestrowane zmiany w odpowiednich zestawach danych pomocniczych. W związku z tym każdy zestaw replik może mieć jednocześnie tylko jednego głównego członka. Różne podstawowe operacje zapisu mogą powodować konflikty danych.
Zwykle aplikacje wysyłają zapytania tylko do podstawowego elementu członkowskiego w celu wykonania operacji zapisu i odczytu. Możesz zaprojektować konfigurację tak, aby odczytywała z jednego lub większej liczby drugorzędnych elementów członkowskich. Asynchroniczny transfer danych może spowodować, że odczyty węzłów pomocniczych będą obsługiwać stare dane. W związku z tym taki układ nie jest idealny dla każdego przypadku użycia.
Funkcje zestawu replik
Mechanizm automatycznego przełączania awaryjnego odróżnia zestawy replik MongoDB od konkurencji. W przypadku braku głównego, zautomatyzowany wybór spośród węzłów drugorzędnych wybiera nowy główny.
Zestaw replik MongoDB a klaster MongoDB
Zestaw replik MongoDB utworzy różne kopie tego samego zestawu danych w węzłach zestawu replik. Podstawowym celem zestawu replik jest:
- Oferuj wbudowane rozwiązanie do tworzenia kopii zapasowych
- Zwiększ dostępność danych
Klaster MongoDB to zupełnie inna gra w piłkę. Dystrybuuje dane w wielu węzłach za pomocą klucza fragmentu. Ten proces spowoduje pofragmentowanie danych na wiele fragmentów zwanych fragmentami. Następnie kopiuje każdy fragment do innego węzła. Klaster ma na celu obsługę dużych zbiorów danych i operacji o dużej przepustowości. Osiąga to poprzez poziome skalowanie obciążenia.
Oto różnica między zestawem replik a klastrem, w kategoriach laika:
- Klaster rozdziela obciążenie. Przechowuje również fragmenty danych (fragmenty) na wielu serwerach.
- Zestaw replik całkowicie powiela zestaw danych.
MongoDB pozwala łączyć te funkcje, tworząc podzielony na fragmenty klaster. Tutaj możesz replikować każdy fragment na serwer pomocniczy. Dzięki temu fragment może oferować wysoką nadmiarowość i dostępność danych.
Konserwacja i konfigurowanie zestawu replik może być technicznie wyczerpujące i czasochłonne. A znalezienie odpowiedniej usługi hostingowej? To zupełnie inny ból głowy. Przy tak wielu dostępnych opcjach łatwo jest marnować godziny na badanie, zamiast budować swój biznes.
Pozwól, że opowiem ci krótko o narzędziu, które robi to wszystko i wiele więcej, abyś mógł wrócić do miażdżenia go swoją usługą/produktem.
Rozwiązanie Kinsta Application Hosting, któremu zaufało ponad 55 000 programistów, możesz rozpocząć z nim pracę w zaledwie 3 prostych krokach. Jeśli to brzmi zbyt dobrze, aby mogło być prawdziwe, oto kilka innych zalet korzystania z Kinsta:
- Ciesz się lepszą wydajnością dzięki wewnętrznym połączeniom Kinsta : Zapomnij o zmaganiach ze współdzielonymi bazami danych. Przełącz się na dedykowane bazy danych z połączeniami wewnętrznymi, które nie mają limitów liczby zapytań ani liczby wierszy. Kinsta jest szybsza, bezpieczniejsza i nie obciąży Cię za wewnętrzną przepustowość/ruch.
- Zestaw funkcji dostosowany do programistów : Skaluj swoją aplikację na niezawodnej platformie obsługującej Gmaila, YouTube i wyszukiwarkę Google. Bądź pewny, jesteś tutaj w najbezpieczniejszych rękach.
- Ciesz się niezrównanymi prędkościami w wybranym centrum danych : wybierz region, który najlepiej odpowiada Tobie i Twoim klientom. Z ponad 25 centrami danych do wyboru, ponad 275 punktów POP Kinsta zapewnia maksymalną prędkość i globalną obecność Twojej witryny.
Wypróbuj rozwiązanie hostingu aplikacji Kinsta za darmo już dziś!
Jak działa replikacja w MongoDB?
W MongoDB wysyłasz operacje zapisu do głównego serwera (węzła). Podstawowy przypisuje operacje na serwerach pomocniczych, replikując dane.
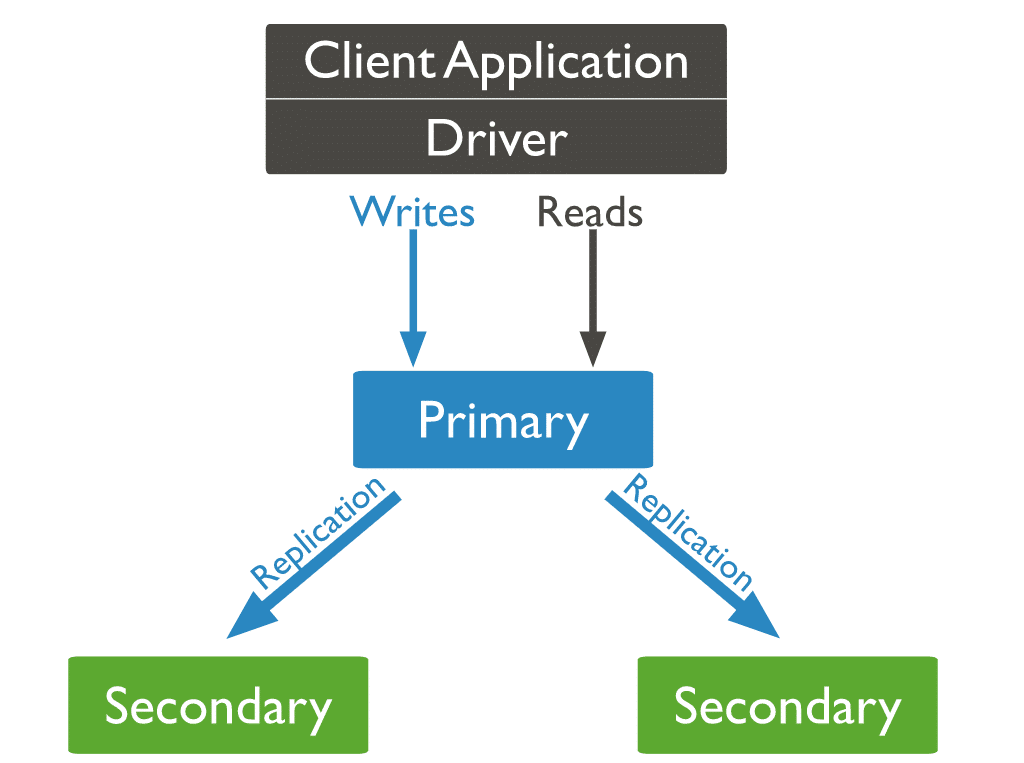
Trzy typy węzłów MongoDB
Spośród trzech typów węzłów MongoDB dwa pojawiły się wcześniej: węzły podstawowe i drugorzędne. Trzecim typem węzła MongoDB, który przydaje się podczas replikacji, jest arbiter. Węzeł arbitra nie ma kopii zestawu danych i nie może stać się węzłem podstawowym. To powiedziawszy, arbiter bierze udział w wyborach do prawyborów.
Wspomnieliśmy wcześniej, co się dzieje, gdy główny węzeł ulegnie awarii, ale co, jeśli węzły drugorzędne ugryzą kurz? W tym scenariuszu węzeł podstawowy staje się drugorzędny, a baza danych staje się nieosiągalna.
Wybory członkowskie
Wybory mogą się odbyć w następujących scenariuszach:
- Inicjowanie zestawu replik
- Utrata łączności z węzłem głównym (którą można wykryć na podstawie uderzeń serca)
- Konserwacja zestawu replik przy użyciu metod
rs.reconfiglubstepDown - Dodanie nowego węzła do istniejącego zestawu replik
Zestaw replik może mieć do 50 członków, ale tylko 7 lub mniej może głosować w dowolnych wyborach.
Średni czas, zanim klaster wybierze nową organizację podstawową, nie powinien przekraczać 12 sekund. Algorytm wyboru spróbuje mieć dostęp do drugorzędnego o najwyższym priorytecie. Jednocześnie członkowie z wartością priorytetu równą 0 nie mogą zostać prawyborami i nie biorą udziału w wyborach.
Koncern pisarski
Aby zapewnić trwałość, operacje zapisu mają ramy umożliwiające kopiowanie danych w określonej liczbie węzłów. Dzięki temu możesz nawet przekazać klientowi informację zwrotną. Ta struktura jest również znana jako „problem zapisu”. Ma elementy przenoszące dane, które muszą potwierdzić problem z zapisem, zanim operacja zwróci się jako pomyślna. Ogólnie zestawy replik mają wartość 1 jako problem z zapisem. Dlatego tylko główny powinien potwierdzić zapis przed zwróceniem potwierdzenia dotyczącego zapisu.
Możesz nawet zwiększyć liczbę członków potrzebnych do potwierdzenia operacji zapisu. Nie ma limitu liczby członków, których możesz mieć. Ale jeśli liczby są wysokie, musisz poradzić sobie z dużym opóźnieniem. Dzieje się tak, ponieważ klient musi czekać na potwierdzenie od wszystkich członków. Możesz także ustawić opcję zapisu dla „większości”. Oblicza to ponad połowę członków po otrzymaniu ich potwierdzenia.
Przeczytaj Preferencje
W przypadku operacji odczytu można wspomnieć o preferencjach odczytu opisujących sposób, w jaki baza danych kieruje zapytanie do elementów zestawu replik. Zasadniczo węzeł główny otrzymuje operację odczytu, ale klient może wskazać preferencję odczytu, aby wysłać operacje odczytu do węzłów drugorzędnych. Oto opcje preferencji odczytu:
- primaryPreferred : Zwykle operacje odczytu pochodzą z węzła podstawowego, ale jeśli nie jest to dostępne, dane są pobierane z węzłów drugorzędnych.
- primary : Wszystkie operacje odczytu pochodzą z węzła podstawowego.
- wtórny : Wszystkie operacje odczytu są wykonywane przez węzły drugorzędne.
- near : Tutaj żądania odczytu są kierowane do najbliższego osiągalnego węzła, który można wykryć, uruchamiając polecenie
ping. Wynik operacji odczytu może pochodzić od dowolnego członka zestawu replik, niezależnie od tego, czy jest to podstawowy, czy pomocniczy. - wtórnyPreferred : Tutaj większość operacji odczytu pochodzi z węzłów drugorzędnych, ale jeśli żaden z nich nie jest dostępny, dane są pobierane z węzła podstawowego.
Synchronizacja danych zestawu replikacji
Aby zachować aktualne kopie udostępnionego zestawu danych, drugorzędni członkowie zestawu replik replikują lub synchronizują dane od innych członków.
MongoDB wykorzystuje dwie formy synchronizacji danych. Początkowa synchronizacja w celu wypełnienia nowych członków pełnym zestawem danych. Replikacja w celu wykonania bieżących zmian w całym zbiorze danych.
Początkowa synchronizacja
Podczas początkowej synchronizacji węzeł dodatkowy uruchamia polecenie init sync w celu zsynchronizowania wszystkich danych z węzła podstawowego z innym węzłem dodatkowym, który zawiera najnowsze dane. W związku z tym węzeł pomocniczy konsekwentnie wykorzystuje funkcję tailable cursor do wysyłania zapytań o najnowsze wpisy oplog w kolekcji local.oplog.rs węzła podstawowego i stosuje te operacje w tych wpisach oplog.
Począwszy od MongoDB 5.2, początkowe synchronizacje mogą być oparte na kopiowaniu plików lub logiczne.
Synchronizacja logiczna
Podczas wykonywania synchronizacji logicznej MongoDB:
- Opracowuje wszystkie indeksy kolekcji w miarę kopiowania dokumentów dla każdej kolekcji.
- Duplikuje wszystkie bazy danych z wyjątkiem lokalnej bazy danych.
mongodskanuje każdą kolekcję we wszystkich źródłowych bazach danych i wstawia wszystkie dane do swoich duplikatów tych kolekcji. - Wykonuje wszystkie zmiany w zbiorze danych. Wykorzystując oplog ze źródła,
mongodaktualizuje swój zestaw danych, aby przedstawić aktualny stan zestawu replik. - Wyodrębnia nowo dodane rekordy oplogu podczas kopiowania danych. Upewnij się, że docelowy element członkowski ma wystarczającą ilość miejsca na dysku w lokalnej bazie danych, aby wstępnie przechowywać te rekordy oplogu na czas trwania tego etapu kopiowania danych.
Po zakończeniu początkowej synchronizacji element członkowski przechodzi z STARTUP2 do SECONDARY .
Synchronizacja początkowa oparta na kopiowaniu plików
Od samego początku możesz to wykonać tylko wtedy, gdy używasz MongoDB Enterprise. Ten proces uruchamia początkową synchronizację poprzez zduplikowanie i przeniesienie plików w systemie plików. W niektórych przypadkach ta metoda synchronizacji może być szybsza niż początkowa synchronizacja logiczna. Należy pamiętać, że początkowa synchronizacja oparta na kopiach plików może prowadzić do niedokładnych obliczeń, jeśli metoda count() zostanie uruchomiona bez predykatu zapytania.
Ale ta metoda ma również swoje ograniczenia:
- Podczas początkowej synchronizacji opartej na kopiach plików nie można zapisywać danych w lokalnej bazie danych członka, który jest synchronizowany. Nie można również uruchomić kopii zapasowej członka, z którym jest synchronizowana, ani członka, z którego jest synchronizowana.
- Wykorzystując zaszyfrowany silnik pamięci masowej, MongoDB używa klucza źródłowego do zaszyfrowania miejsca docelowego.
- Możesz uruchomić początkową synchronizację tylko od jednego danego członka na raz.
Replikacja
Członkowie drugorzędni konsekwentnie replikują dane po początkowej synchronizacji. Członkowie drugorzędni zduplikują oplog ze swojej synchronizacji ze źródła i wykonają te operacje w procesie asynchronicznym.
Serwery pomocnicze są w stanie automatycznie modyfikować swoją synchronizację ze źródła zgodnie z potrzebami na podstawie zmian w czasie pingowania i stanie replikacji innych członków.
Replikacja strumieniowa
Z MongoDB 4.4 synchronizacja ze źródeł wysyła ciągły strumień wpisów oplog do ich synchronizujących części pomocniczych. Replikacja strumieniowa zmniejsza opóźnienie replikacji w sieciach o dużym obciążeniu i opóźnieniach. Może też:
- Zmniejsz ryzyko utraty operacji zapisu dzięki
w:1z powodu podstawowego przełączania awaryjnego. - Zmniejsz przestarzałość odczytów z zasobów pomocniczych.
- Zmniejsz opóźnienie operacji zapisu za pomocą
w:“majority”iw:>1. Krótko mówiąc, każdy problem związany z zapisem, który wymaga oczekiwania na replikację.
Replikacja wielowątkowa
MongoDB używane do zapisywania operacji w partiach przez wiele wątków w celu poprawy współbieżności. MongoDB grupuje partie według identyfikatora dokumentu, stosując każdą grupę operacji z innym wątkiem.
MongoDB zawsze wykonuje operacje zapisu na danym dokumencie w oryginalnej kolejności zapisu. Zmieniło się to w MongoDB 4.0.
Z MongoDB 4.0 operacje odczytu, które były ukierunkowane na serwery pomocnicze i są skonfigurowane z poziomem zainteresowania odczytem “majority” lub “local” będą teraz odczytywać z migawki danych WiredTiger, jeśli odczyt nastąpi na serwerze pomocniczym, w którym stosowane są partie replikacji. Odczyt z migawki gwarantuje spójny widok danych i pozwala na równoczesny odczyt z trwającą replikacją bez konieczności blokowania.
W związku z tym dodatkowe odczyty wymagające tych poziomów obaw o odczyty nie muszą już czekać na zastosowanie partii replikacji i mogą być obsługiwane w miarę ich odbierania.
Jak utworzyć zestaw replik MongoDB
Jak wspomniano wcześniej, MongoDB obsługuje replikację za pomocą zestawów replik. W kilku następnych sekcjach przedstawimy kilka metod, których możesz użyć do stworzenia zestawów replik dla swojego przypadku użycia.
Metoda 1: Tworzenie nowego zestawu replik MongoDB w systemie Ubuntu
Zanim zaczniemy, musisz upewnić się, że masz co najmniej trzy serwery z systemem Ubuntu 20.04, z zainstalowanym MongoDB na każdym serwerze.
Aby skonfigurować zestaw replik, konieczne jest podanie adresu, pod którym każdy członek zestawu replik będzie dostępny dla innych członków zestawu. W tym przypadku zachowujemy trzy elementy w zbiorze. Chociaż możemy używać adresów IP, nie jest to zalecane, ponieważ adresy mogą się nieoczekiwanie zmienić. Lepszą alternatywą może być użycie logicznych nazw hostów DNS podczas konfigurowania zestawów replik.
Możemy to zrobić, konfigurując subdomenę dla każdego członka replikacji. Chociaż może to być idealne rozwiązanie dla środowiska produkcyjnego, w tej sekcji opisano, jak skonfigurować rozpoznawanie nazw DNS, edytując pliki odpowiednich hostów każdego serwera. Ten plik pozwala nam przypisać czytelne nazwy hostów do numerycznych adresów IP. Tak więc, jeśli w każdym przypadku zmieni się Twój adres IP, wystarczy zaktualizować pliki hostów na trzech serwerach, zamiast ponownie konfigurować zestaw replik od podstaw!
Przeważnie hosts są przechowywane w katalogu /etc/ . Powtórz poniższe polecenia dla każdego z trzech serwerów:
sudo nano /etc/hostsW powyższym poleceniu używamy nano jako naszego edytora tekstu, jednak możesz użyć dowolnego preferowanego edytora tekstu. Po kilku pierwszych wierszach, które konfigurują hosta lokalnego, dodaj wpis dla każdego elementu zestawu replik. Wpisy te mają postać adresu IP, po którym następuje wybrana nazwa czytelna dla człowieka. Chociaż możesz nazwać ich, jak chcesz, pamiętaj, aby były opisowe, abyś wiedział, jak rozróżnić każdego członka. W tym samouczku użyjemy poniższych nazw hostów:
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
Używając tych nazw hostów, twoje pliki /etc/hosts będą wyglądać podobnie do następujących podświetlonych linii:

Zapisz i zamknij plik.
Po skonfigurowaniu rozdzielczości DNS dla zestawu replik musimy zaktualizować reguły zapory, aby umożliwić im komunikację między sobą. Uruchom następującą komendę ufw na mongo0, aby zapewnić mongo1 dostęp do portu 27017 na mongo0:
sudo ufw allow from mongo1_server_ip to any port 27017 Zamiast parametru mongo1_server_ip wprowadź rzeczywisty adres IP serwera mongo1. Ponadto, jeśli zaktualizowałeś instancję Mongo na tym serwerze, aby korzystała z portu innego niż domyślny, pamiętaj o zmianie 27017, aby odzwierciedlić port używany przez instancję MongoDB.
Teraz dodaj kolejną regułę zapory, aby dać mongo2 dostęp do tego samego portu:
sudo ufw allow from mongo2_server_ip to any port 27017 Zamiast parametru mongo2_server_ip wprowadź rzeczywisty adres IP serwera mongo2. Następnie zaktualizuj reguły zapory dla pozostałych dwóch serwerów. Uruchom następujące polecenia na serwerze mongo1, pamiętając o zmianie adresów IP zamiast parametru server_ip, aby odzwierciedlały odpowiednio adresy mongo0 i mongo2:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017Na koniec uruchom te dwa polecenia na mongo2. Ponownie upewnij się, że wpisujesz prawidłowe adresy IP dla każdego serwera:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017Następnym krokiem jest aktualizacja pliku konfiguracyjnego każdej instancji MongoDB, aby zezwolić na połączenia zewnętrzne. Aby to umożliwić, należy zmodyfikować plik konfiguracyjny na każdym serwerze, aby odzwierciedlał adres IP i wskazywał zestaw replik. Chociaż możesz użyć dowolnego preferowanego edytora tekstu, my ponownie używamy edytora tekstu nano. Wprowadźmy następujące modyfikacje w każdym pliku mongod.conf.
na mongo0:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"Na mongo1:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"Na mongo2:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodW ten sposób włączyłeś replikację dla instancji MongoDB każdego serwera.
Możesz teraz zainicjować zestaw replik za pomocą metody rs.initiate() . Ta metoda jest wymagana tylko do wykonania na pojedynczej instancji MongoDB w zestawie replik. Upewnij się, że nazwa i element zestawu replik są zgodne z konfiguracjami wykonanymi wcześniej w każdym pliku konfiguracyjnym.
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })Jeśli metoda zwróci „ok”: 1 na wyjściu, oznacza to, że zestaw replik został uruchomiony poprawnie. Poniżej znajduje się przykład tego, jak powinien wyglądać wynik:
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }Zamknij serwer MongoDB
Możesz zamknąć serwer MongoDB za pomocą metody db.shutdownServer() . Poniżej znajduje się składnia tego samego. Zarówno force , jak i timeoutsecs są parametrami opcjonalnymi.
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) Ta metoda może się nie powieść, jeśli element zestawu replik mongod wykona określone operacje podczas kompilacji indeksu. Aby przerwać operacje i wymusić zamknięcie elementu, można wprowadzić wartość parametru boolowskiego force na wartość true.
Uruchom ponownie MongoDB za pomocą opcji –replSet
Aby zresetować konfigurację, upewnij się, że każdy węzeł w zestawie replik jest zatrzymany. Następnie usuń lokalną bazę danych dla każdego węzła. Uruchom go ponownie, używając flagi –replSet i uruchom rs.initiate() tylko na jednej instancji mongod dla zestawu replik.
mongod --replSet "rs0" rs.initiate() może pobrać opcjonalny dokument konfiguracyjny zestawu replik, a mianowicie:
- Opcja
Replication.replSetNamelub—replSetsłużąca do określenia nazwy zestawu replik w polu_id. - Tablica członków, która zawiera jeden dokument dla każdego elementu członkowskiego zestawu replik.
Metoda rs.initiate() wyzwala wybory i wybiera jednego z członków jako głównego.

Dodaj członków do zestawu replik
Aby dodać członków do zestawu, uruchom instancje mongod na różnych komputerach. Następnie uruchom klienta mongo i użyj komendy rs.add() .
Komenda rs.add() ma następującą podstawową składnię:
rs.add(HOST_NAME:PORT)Na przykład,
Załóżmy, że mongo1 jest twoją instancją mongod i nasłuchuje na porcie 27017. Użyj polecenia rs.add() klienta Mongo, aby dodać tę instancję do zestawu replik.
rs.add("mongo1:27017") Dopiero po połączeniu z głównym węzłem możesz dodać instancję mongod do zestawu replik. Aby sprawdzić, czy masz połączenie z podstawowym, użyj polecenia db.isMaster() .
Usuń użytkowników
Aby usunąć członka, możemy użyć rs.remove()
Aby to zrobić, najpierw zamknij instancję mongod, którą chcesz usunąć, używając metody db.shutdownServer() omówionej powyżej.
Następnie połącz się z bieżącym podstawowym zestawem replik. Aby określić bieżący element podstawowy, użyj db.hello() podczas połączenia z dowolnym elementem zestawu replik. Po określeniu podstawowego uruchom jedno z następujących poleceń:
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 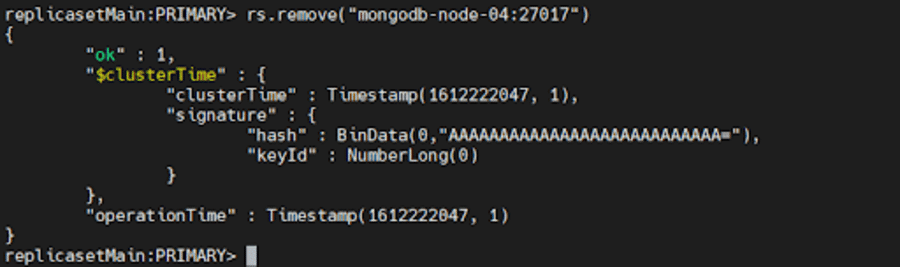
Jeśli zestaw replik musi wybrać nowy element podstawowy, MongoDB może na krótko rozłączyć powłokę. W tym scenariuszu automatycznie połączy się ponownie. Może również wyświetlić błąd DBClientCursor::init call() nie powiodło się, nawet jeśli polecenie powiedzie się.
Metoda 2: Konfigurowanie zestawu replik MongoDB na potrzeby wdrażania i testowania
Ogólnie rzecz biorąc, można skonfigurować zestawy replik do testowania z włączoną lub wyłączoną kontrolą RBAC. W tej metodzie będziemy konfigurować zestawy replik z wyłączoną kontrolą dostępu w celu wdrożenia ich w środowisku testowym.
Najpierw utwórz katalogi dla wszystkich instancji wchodzących w skład zestawu replik za pomocą następującego polecenia:
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2To polecenie utworzy katalogi dla trzech instancji MongoDB zestaw replik 0-0, zestaw replik 0-1 i zestaw replik 0-2. Teraz uruchom instancje MongoDB dla każdej z nich, używając następującego zestawu poleceń:
Dla Serwera 1:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Dla serwera 2:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Dla serwera 3:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 Parametr –oplogSize służy do zapobiegania przeciążeniu maszyny podczas fazy testowej. Pomaga zmniejszyć ilość miejsca na dysku zajmowanego przez każdy dysk.
Teraz połącz się z jedną z instancji przy użyciu powłoki Mongo, łącząc się za pomocą poniższego numeru portu.
mongo --port 27017 Do uruchomienia procesu replikacji możemy użyć polecenia rs.initiate() . Będziesz musiał zastąpić parametr hostname nazwą swojego systemu.
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }Możesz teraz przekazać plik obiektu konfiguracji jako parametr polecenia inicjowania i użyć go w następujący sposób:
rs.initiate(rsconf)I masz to! Pomyślnie utworzyłeś zestaw replik MongoDB do celów programistycznych i testowych.
Metoda 3: Przekształcanie autonomicznej instancji w zestaw replik MongoDB
MongoDB pozwala użytkownikom przekształcać ich samodzielne instancje w zestawy replik. Podczas gdy samodzielne instancje są najczęściej używane w fazie testowania i rozwoju, zestawy replik są częścią środowiska produkcyjnego.
Aby rozpocząć, zamknijmy naszą instancję mongod za pomocą następującego polecenia:
db.adminCommand({"shutdown":"1"}) Zrestartuj instancję, używając parametru –repelSet w swoim poleceniu, aby określić zestaw replik, którego zamierzasz użyć:
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>W poleceniu musisz podać nazwę swojego serwera wraz z unikalnym adresem.
Połącz powłokę z instancją MongoDB i użyj polecenia inicjowania, aby rozpocząć proces replikacji i pomyślnie przekonwertować instancję na zestaw replik. Możesz wykonać wszystkie podstawowe operacje, takie jak dodawanie lub usuwanie instancji, używając następujących poleceń:
rs.add(“<host_name:port>”) rs.remove(“host-name”) Dodatkowo możesz sprawdzić stan swojego zestawu replik MongoDB za pomocą poleceń rs.status() i rs.conf() .
Metoda 4: Atlas MongoDB — prostsza alternatywa
Replikacja i sharding mogą ze sobą współpracować, tworząc coś, co nazywa się klastrem shardingu. Podczas gdy instalacja i konfiguracja mogą być dość czasochłonne, choć proste, Atlas MongoDB jest lepszą alternatywą niż metody wspomniane wcześniej.
Automatyzuje zestawy replik, ułatwiając wdrożenie procesu. Może wdrażać globalnie podzielone zestawy replik za pomocą kilku kliknięć, umożliwiając odzyskiwanie po awarii, łatwiejsze zarządzanie, lokalizację danych i wdrożenia w wielu regionach.
W Atlasie MongoDB musimy tworzyć klastry – mogą to być zestawy replik lub klastry podzielone na fragmenty. W przypadku konkretnego projektu liczba węzłów w klastrze w innych regionach jest ograniczona do łącznie 40.
Wyklucza to bezpłatne lub udostępnione klastry oraz komunikujące się ze sobą regiony chmury Google. Całkowita liczba węzłów między dowolnymi dwoma regionami musi spełniać to ograniczenie. Na przykład, jeśli istnieje projekt, w którym:
- Region A ma 15 węzłów.
- Region B ma 25 węzłów
- Region C ma 10 węzłów
Możemy przydzielić tylko 5 węzłów więcej do regionu C, ponieważ
- Region A+ Region B = 40; spełnia ograniczenie 40, czyli maksymalnej dozwolonej liczby węzłów.
- Region B+ Region C = 25+10+5 (Dodatkowe węzły przydzielone do C) = 40; spełnia ograniczenie 40, czyli maksymalnej dozwolonej liczby węzłów.
- Region A+ Region C =15+10+5 (Dodatkowe węzły przydzielone do C) = 30; spełnia ograniczenie 40, czyli maksymalnej dozwolonej liczby węzłów.
Jeśli przydzielimy 10 dodatkowych węzłów do regionu C, dzięki czemu region C będzie miał 20 węzłów, to Region B + Region C = 45 węzłów. Przekroczyłoby to podane ograniczenie, więc utworzenie klastra obejmującego wiele regionów może nie być możliwe.
Kiedy tworzysz klaster, Atlas tworzy w projekcie kontener sieciowy dla dostawcy chmury, jeśli wcześniej go tam nie było. Aby utworzyć klaster zestawu replik w MongoDB Atlas, uruchom następującą komendę w Atlas CLI:
atlas clusters create [name] [options]Upewnij się, że podajesz opisową nazwę klastra, ponieważ nie można jej zmienić po utworzeniu klastra. Argument może zawierać litery ASCII, cyfry i łączniki.
Dostępnych jest kilka opcji tworzenia klastrów w MongoDB w oparciu o Twoje wymagania. Na przykład, jeśli chcesz mieć ciągłą kopię zapasową w chmurze dla swojego klastra, ustaw opcję --backup na wartość true.
Radzenie sobie z opóźnieniem replikacji
Opóźnienie replikacji może być dość odpychające. Jest to opóźnienie między operacją na podstawowym a zastosowaniem tej operacji z oplogu do drugorzędnego. Jeśli Twoja firma zajmuje się dużymi zbiorami danych, oczekiwane jest opóźnienie w granicach określonego progu. Czasami jednak czynniki zewnętrzne mogą również przyczynić się i zwiększyć opóźnienie. Aby skorzystać z aktualnej replikacji, upewnij się, że:
- Kierujesz ruch sieciowy ze stabilną i wystarczającą przepustowością. Opóźnienia w sieci odgrywają ogromną rolę w procesie replikacji, a jeśli sieć jest niewystarczająca do zaspokojenia potrzeb procesu replikacji, wystąpią opóźnienia w replikacji danych w całym zestawie replik.
- Masz wystarczającą przepustowość dysku. Jeśli system plików i urządzenie dyskowe na dysku pomocniczym nie są w stanie przenieść danych na dysk tak szybko, jak na dysku podstawowym, wówczas serwer pomocniczy będzie miał trudności z nadążaniem. W związku z tym węzły drugorzędne przetwarzają zapytania zapisu wolniej niż węzeł główny. Jest to powszechny problem w większości systemów wielodostępnych, w tym w instancjach zwirtualizowanych i wdrożeniach na dużą skalę.
- Żądasz potwierdzenia zapisu zapisu po przerwie, aby umożliwić drugorzędnym nadążanie za podstawowym, zwłaszcza gdy chcesz wykonać operację ładowania zbiorczego lub pozyskiwanie danych, które wymaga dużej liczby zapisów do podstawowego. Pomocnicy nie będą w stanie odczytać oplogu wystarczająco szybko, aby nadążyć za zmianami; szczególnie w przypadku niepotwierdzonych problemów z zapisem.
- Identyfikujesz uruchomione zadania w tle. Niektóre zadania, takie jak zadania crona, aktualizacje serwera i sprawdzanie bezpieczeństwa, mogą mieć nieoczekiwany wpływ na wykorzystanie sieci lub dysku, powodując opóźnienia w procesie replikacji.
Jeśli nie masz pewności, czy w Twojej aplikacji występuje opóźnienie replikacji, nie martw się — w następnej sekcji omówiono strategie rozwiązywania problemów!
Rozwiązywanie problemów z zestawami replik MongoDB
Pomyślnie skonfigurowałeś zestawy replik, ale zauważyłeś, że Twoje dane są niespójne na różnych serwerach. Jest to bardzo niepokojące dla dużych firm, jednak dzięki szybkim metodom rozwiązywania problemów możesz znaleźć przyczynę, a nawet rozwiązać problem! Poniżej podano kilka typowych strategii rozwiązywania problemów z wdrożeniami zestawów replik, które mogą się przydać:
Sprawdź status repliki
Możemy sprawdzić bieżący stan zestawu replik i status każdego elementu członkowskiego, uruchamiając następujące polecenie w sesji mongosh, która jest połączona z podstawowym zestawem replik.
rs.status()Sprawdź opóźnienie replikacji
Jak omówiono wcześniej, opóźnienie replikacji może stanowić poważny problem, ponieważ powoduje, że „opóźnione” elementy członkowskie nie kwalifikują się do szybkiego przekształcenia w podstawowe i zwiększają prawdopodobieństwo, że rozproszone operacje odczytu będą niespójne. Bieżącą długość dziennika replikacji możemy sprawdzić za pomocą następującego polecenia:
rs.printSecondaryReplicationInfo() Spowoduje to zwrócenie syncedTo wartości, która jest czasem, w którym ostatni wpis oplogu został zapisany w drugorzędnym dla każdego elementu członkowskiego. Oto przykład demonstrujący to samo:
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary Opóźniony element członkowski może być wyświetlany jako 0 sekund za elementem podstawowym, gdy okres bezczynności elementu podstawowego jest większy niż wartość members[n].secondaryDelaySecs .
Przetestuj połączenia między wszystkimi członkami
Każdy element zestawu replik musi mieć możliwość łączenia się z każdym innym elementem. Zawsze sprawdzaj połączenia w obu kierunkach. Zwykle konfiguracje zapory lub topologie sieci uniemożliwiają normalną i wymaganą łączność, co może blokować replikację.
Załóżmy na przykład, że instancja mongod wiąże się zarówno z hostem lokalnym, jak i nazwą hosta „ExampleHostname”, która jest powiązana z adresem IP 198.41.110.1:
mongod --bind_ip localhost, ExampleHostnameAby połączyć się z tą instancją, zdalni klienci muszą podać nazwę hosta lub adres IP:
mongosh --host ExampleHostname mongosh --host 198.41.110.1Jeśli zestaw replik składa się z trzech elementów, m1, m2 i m3, korzystających z domyślnego portu 27017, należy przetestować połączenie w następujący sposób:
na m1:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017na m2:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017na m3:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 Jeśli jakiekolwiek połączenie w dowolnym kierunku nie powiedzie się, musisz sprawdzić konfigurację zapory i ponownie ją skonfigurować, aby zezwalała na połączenia.
Zapewnienie bezpiecznej komunikacji z uwierzytelnianiem pliku klucza
Domyślnie uwierzytelnianie plików kluczy w MongoDB opiera się na mechanizmie uwierzytelniania solonej odpowiedzi na wezwanie (SCRAM). W tym celu MongoDB musi odczytać i zweryfikować dane uwierzytelniające podane przez użytkownika, które obejmują kombinację nazwy użytkownika, hasła i bazy danych uwierzytelniania, o której wie dana instancja MongoDB. Jest to dokładny mechanizm używany do uwierzytelniania użytkowników, którzy podają hasło podczas łączenia się z bazą danych.
Po włączeniu uwierzytelniania w MongoDB kontrola dostępu oparta na rolach (RBAC) jest automatycznie włączana dla zestawu replik, a użytkownik otrzymuje jedną lub więcej ról, które określają jego dostęp do zasobów bazy danych. Gdy funkcja RBAC jest włączona, oznacza to, że tylko prawidłowy uwierzytelniony użytkownik Mongo z odpowiednimi uprawnieniami będzie mógł uzyskać dostęp do zasobów w systemie.
Plik klucza działa jak wspólne hasło dla każdego członka w klastrze. Dzięki temu każda instancja mongod w zestawie replik może używać zawartości pliku klucza jako wspólnego hasła do uwierzytelniania innych członków we wdrożeniu.
Tylko instancje mongod z poprawnym plikiem klucza mogą dołączyć do zestawu replik. Długość klucza musi zawierać się w przedziale od 6 do 1024 znaków i może zawierać tylko znaki z zestawu base64. Należy pamiętać, że MongoDB usuwa białe znaki podczas odczytywania kluczy.
Plik klucza można wygenerować przy użyciu różnych metod. W tym samouczku używamy openssl do wygenerowania złożonego ciągu 1024 losowych znaków, który będzie używany jako wspólne hasło. It then uses chmod to change file permissions to provide read permissions for the file owner only. Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. For example:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
And voila! You have successfully enabled keyfile authentication!
Summary
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!