
Przechowywanie trwałe: pamięć długoterminowa w erze kontenerów
Opublikowany: 2023-04-17Trwałe przechowywanie odnosi się do przechowywania danych w sposób nieulotny, dzięki czemu pozostają one dostępne nawet po wyłączeniu lub ponownym uruchomieniu urządzenia lub aplikacji. Przechowywanie i odzyskiwanie danych umożliwia aplikacjom internetowym zapisywanie informacji i stanów użytkownika oraz niezawodne działanie.
W aplikacjach monolitycznych dostęp do pamięci masowej jest prosty, ponieważ serwer i pamięć masowa działają razem. Jednak geograficznie rozproszone systemy sprawiają, że dostęp jest bardziej złożony, ponieważ system pamięci masowej musi pozostać dostępny dla wszystkich komponentów na całym świecie.
Konteneryzacja dodatkowo komplikuje problem, ponieważ kontenery są lekkie, bezstanowe i efemeryczne — cechy nieodpowiednie do przechowywania danych. Dlatego każde trwałe rozwiązanie pamięci masowej musi bezproblemowo współpracować z kontenerami, dodając kolejną warstwę złożoności.
Ten artykuł zagłębia się w pamięć trwałą, eksplorując jej typy, architekturę i przypadki użycia. Zapewnia również praktyczną demonstrację ilustrującą różnicę między przechowywaniem woluminów a przechowywaniem woluminów trwałych w Dockerze.
Rodzaje pamięci trwałej
Istnieje kilka rodzajów pamięci nieulotnej, w tym tradycyjne dyski obrotowe (dyski twarde lub dyski twarde), dyski półprzewodnikowe (SSD), pamięć masowa podłączona do sieci (NAS) i sieci pamięci masowej (SAN).
- Dyski twarde to elektromechaniczne urządzenia do przechowywania danych, które przechowują i odzyskują dane cyfrowe za pomocą wirujących dysków z nośników magnetycznych. Dyski wykorzystują głowice magnetyczne na ruchomym ramieniu siłownika, które odczytują i zapisują dane.
- Dyski SSD , czasami nazywane półprzewodnikowymi urządzeniami pamięci masowej, urządzeniami półprzewodnikowymi lub dyskami półprzewodnikowymi, wykorzystują zespoły obwodów scalonych do trwałego przechowywania danych, zwykle za pomocą połączonych ze sobą urządzeń flash, które nie zawierają ruchomych części. Ich stacjonarny charakter sprawia, że są szybsze i bardziej niezawodne niż dyski twarde.
- Pamięć podłączona do sieci to grupa dysków twardych, dysków SSD lub obu tych dysków połączonych przez sieć lokalną przy użyciu systemu plików, takiego jak system plików nowej technologii (NTFS) lub czwarty rozszerzony system plików (EXT4).
- Sieci SAN to sieciowe, szybkie, blokowe urządzenia pamięci masowej, takie jak biblioteki taśmowe lub macierze dyskowe. Ich połączenie pojawia się w systemie operacyjnym jako pamięć lokalna i nie jest dostępne przez sieć lokalną (LAN).
Trwała architektura pamięci masowej
Istnieją trzy podejścia do trwałej pamięci masowej, z których każda ma unikalne przypadki użycia i ograniczenia.
Trwała architektura obiektu
Podejście oparte na trwałej architekturze obiektów wykorzystuje mapowanie obiektowo-relacyjne (ORM) do przechowywania danych jako obiektów w relacyjnej bazie danych lub bazie danych typu klucz-wartość. Takie podejście jest przydatne, gdy dane nie mają zdefiniowanego schematu, ponieważ ORM obsługuje ich przechowywanie i pobieranie.
Zablokuj trwałą architekturę
Trwała architektura bloków wykorzystuje urządzenia pamięci masowej na poziomie bloków, które są przydatne podczas przechowywania dużych plików. Takie podejście jest korzystne w przypadku przechowywania dużych ilości danych, ponieważ można użyć wielu bloków w celu zwiększenia pojemności magazynu.
Trwała architektura Filestore
Jak sama nazwa wskazuje, podejście oparte na trwałej architekturze magazynu plików wykorzystuje system plików do przechowywania danych. Jedna metoda polega na użyciu serwerów baz danych, które zapewniają scentralizowany sposób przechowywania danych. Rozwiązania hostingowe w chmurze, takie jak Kinsta, wykorzystują serwery baz danych, które można łatwo podłączyć do aplikacji i zapewniają trwałość.
Trwała architektura Filestore jest pomocna w aplikacjach wymagających częstego pobierania plików i gdy potrzebny jest interfejs do zarządzania nimi.
Przypadki użycia pamięci trwałej
W tej sekcji omówiono niektóre przypadki użycia każdego typu magazynu.
Trwałe przechowywanie obiektów
- Przechowywanie w chmurze: Obiektowe trwałe przechowywanie jest powszechnie stosowane w rozwiązaniach do przechowywania w chmurze do przechowywania i pobierania dużych ilości nieustrukturyzowanych danych, takich jak obrazy, filmy i dokumenty. Dostawcy chmury wykorzystują obiektową pamięć masową, aby zapewnić klientom skalowalne, wysoce dostępne i trwałe usługi pamięci masowej.
- Analiza dużych zbiorów danych: trwała pamięć obiektów jest używana w analizie dużych zbiorów danych do przechowywania dużych zestawów danych i zarządzania nimi, często używanych do analizy danych, uczenia maszynowego i sztucznej inteligencji. Obiektowa pamięć masowa umożliwia szybki i wydajny dostęp do danych, co czyni ją kluczowym elementem architektury dużych zbiorów danych.
- Sieci dostarczania treści: obiektowa pamięć trwała jest używana w sieciach dostarczania treści (CDN) do przechowywania i dystrybucji treści, takich jak obrazy, filmy i pliki statyczne, w globalnej sieci serwerów. Obiektowa pamięć masowa umożliwia sieciom CDN dostarczanie szybkich treści użytkownikom na całym świecie, niezależnie od lokalizacji.
Blokuj trwałe przechowywanie
- Obliczenia o wysokiej wydajności (HPC) : środowiska HPC umożliwiają szybkie i wydajne przetwarzanie dużych ilości danych. Blokowa trwała pamięć masowa umożliwia klastrom HPC przechowywanie i pobieranie dużych zestawów danych, takich jak symulacje naukowe, modelowanie pogody i analizy finansowe. Pamięć blokowa jest często preferowana dla HPC, ponieważ zapewnia wysoką wydajność, dostęp do danych z małymi opóźnieniami i pozwala na równoległe operacje wejścia/wyjścia (I/O), co może znacznie skrócić czas przetwarzania.
- Edycja wideo: aplikacje do edycji wideo wymagają dostępu do dużych plików wideo o wysokiej wydajności i małych opóźnieniach. Muszą również obsługiwać znaczną liczbę operacji we/wy na sekundę i niskie opóźnienia, aby renderować i edytować pliki wideo w czasie rzeczywistym. Blokowa pamięć masowa zapewnia te możliwości, dzięki czemu jest idealnym rozwiązaniem dla przepływów pracy związanych z edycją wideo.
- Gry: aplikacje do gier wymagają również wysokiej wydajności i małych opóźnień, aby uzyskać dostęp do zasobów gier i danych graczy. Pamięć blokowa szybko przechowuje i pobiera duże ilości danych, zapewniając szybkie ładowanie środowisk gry i responsywność podczas gry.
Trwała pamięć Filestore
- Media i rozrywka: aplikacje do edycji, animacji i renderowania wideo często korzystają z pamięci trwałej. Te aplikacje wymagają dostępu do dużych plików multimedialnych, takich jak wideo, audio i obrazy, o wysokiej wydajności i małych opóźnieniach. Filestore zapewnia współdzielony system plików, do którego dostęp może mieć wielu klientów, co czyni go idealnym rozwiązaniem do przechowywania danych dla tych aplikacji.
- Zarządzanie zawartością sieci Web: Systemy zarządzania treścią sieci Web (CMS) wykorzystują trwałe przechowywanie plików we współdzielonych systemach plików do przechowywania treści witryn internetowych, takich jak tekst, obrazy i pliki multimedialne, oraz do zarządzania nimi. Filestore zapewnia centralną lokalizację zawartości strony internetowej, ułatwiając zarządzanie i aktualizację. Umożliwia także wielu użytkownikom jednoczesną pracę nad tymi samymi treściami, poprawiając współpracę i produktywność.
Trwałe przechowywanie w kontenerach
Kontenery są lekkie, przenośne, bezpieczne i proste, oferując połączenie różnych zastosowań. Muszą mieć mechanizm utrwalania danych między ponownym uruchomieniem kontenera a jego usunięciem. Kontenery mają pamięć masową lub system plików, jak tradycyjne aplikacje, ale za każdym razem, gdy odbudowujesz je z nowymi zmianami, tracisz wszystkie nietrwałe dane.
Dlatego kontenery oferują opcję dołączenia magazynu woluminów lub zamontowania woluminu magazynu. Kontenery traktują woluminy magazynu jako katalog. Wszelkie dane zapisane na woluminie trafiają do systemu plików hosta.
Trwałe przechowywanie kontenerów musi działać w ten sposób, ponieważ ponowne uruchomienie kontenera tworzy nową instancję i odrzuca starą instancję. Jeśli kontener nie ma spójnego widoku danych, dane znikną po ponownym uruchomieniu kontenera. Wolumin magazynu zachowuje dane między sesjami i ponownymi uruchomieniami kontenera, umożliwiając zachowanie stanu kontenera nawet po przeniesieniu lub ponownym uruchomieniu.

Głośność a stała głośność
Kontenery zapewniają 2 sposoby przechowywania trwałych danych: przy użyciu woluminów i trwałych woluminów. Jest między nimi znacząca różnica. Kontener zarządza danymi w magazynie woluminów. Po zatrzymaniu kontenera dane pozostają i są dostępne po ponownym uruchomieniu kontenera. Jednak po usunięciu lub usunięciu kontenera dane zostaną utracone, ponieważ usuniesz również bazowy magazyn woluminów.
Trwałe przechowywanie woluminów lub podłączanie powiązań to sposób przechowywania danych poza systemem plików kontenera. W ten sposób dane nie zostaną utracone nawet po usunięciu kontenera. Jest trwały, dopóki nie zostanie ręcznie usunięty.
W poniższej sekcji przedstawiono oba typy woluminów wraz z przykładami.
Kontenerowa wersja demonstracyjna trwałej pamięci masowej
Stworzyliśmy małą aplikację internetową, aby zademonstrować trwałe przechowywanie za pomocą kontenerów Docker. Możesz śledzić dalej, instalując Dockera i pobierając kod z tego repozytorium GitHub.
Aplikacja jest podstawowym formularzem z 2 polami do wprowadzania danych przez użytkownika:
- Tytuł
- Tekst dokumentu
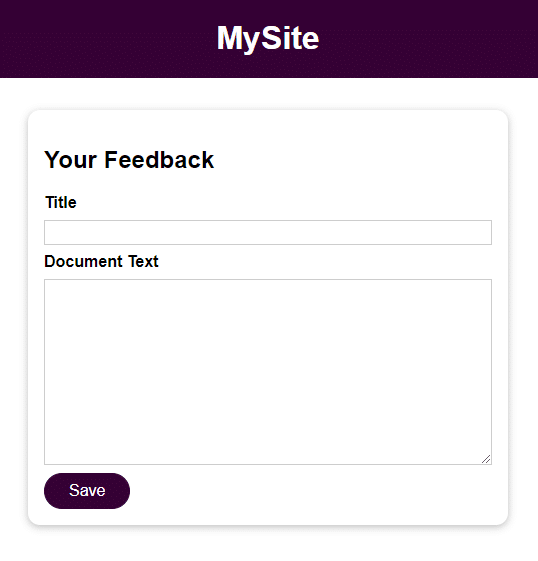
Po zapisaniu danych wprowadzonych przez użytkownika można uzyskać do nich dostęp, otwierając plik w katalogu opinii o nazwie podanej w polu Tytuł . Dane wejściowe z pola Tekst dokumentu to zawartość pliku.
Jak korzystać z pamięci masowej
Po zainstalowaniu aplikacji na własnym komputerze może ona korzystać z pamięci masowej, jak pokazano w pliku Dockerfile .
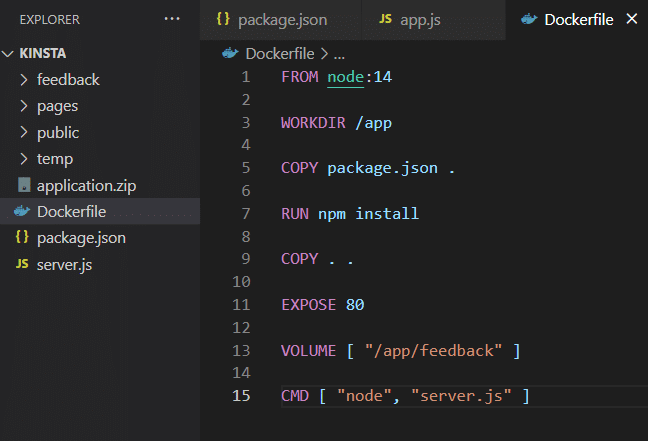
Teraz budujesz obraz i uruchamiasz kontener. Aby to zrobić, wykonaj następujące polecenia.
docker build -t feedback-node:volumes . docker run -d -p 3000:80 --name feedback-app feedback-node:volumes 
Po uruchomieniu aplikacji przejdź do localhost:3000, aby przesłać opinię.
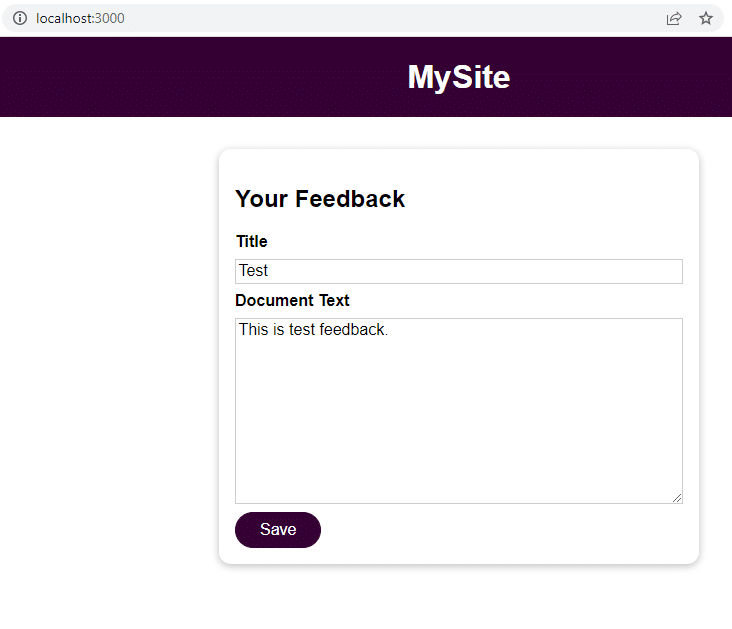
Kliknij Zapisz i przejdź do localhost:3000/feedback/test.txt , aby sprawdzić, czy dane wejściowe zostały pomyślnie zapisane.
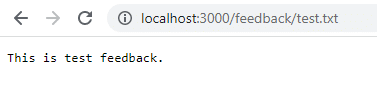
Usuń i uruchom ponownie kontener, aby zobaczyć, czy dane wejściowe będą się powtarzać.
docker stop feedback-app docker start feedback-appJeśli teraz odwiedzisz ten sam adres URL, zobaczysz, że opinia nadal tam jest. Ale co się stanie, jeśli usuniesz kontener i uruchomisz go ponownie?
docker stop feedback-app docker rm feedback-app docker run -d -p 3000:80 --name feedback-app feedback-node:volumesJeśli po ponownym uruchomieniu wrócisz do tego adresu URL, już nie istnieje, ponieważ dane zostały utracone po usunięciu kontenera. Dane woluminu są zachowywane tylko podczas zatrzymywania kontenera, a nie podczas jego usuwania.
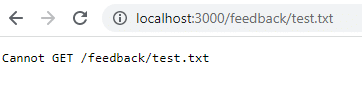
Aby złagodzić ten problem i zachować dane nawet po usunięciu kontenera, należy użyć trwałego magazynu woluminów lub magazynu nazwanego. Najpierw należy wyczyścić pojemniki i obrazy.
docker stop feedback-app docker rm feedback-app docker rmi feedback-node:volumesJak korzystać z trwałego przechowywania woluminów
Przed przetestowaniem tego musisz usunąć atrybut VOLUME z pliku Docker i odbudować obraz.
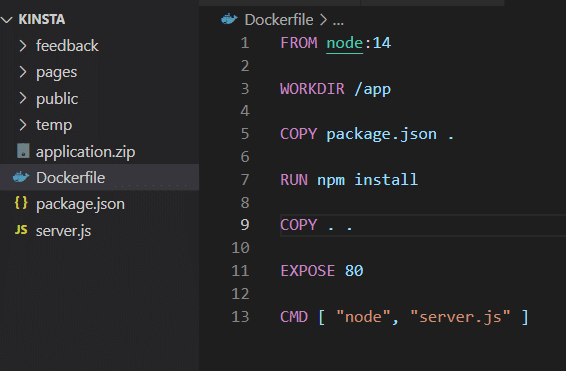
docker build -t feedback-node:volumes . docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumes Jak widać, w drugim poleceniu używasz flagi -v do zdefiniowania trwałego woluminu poza kontenerem, który utrzymuje się nawet po usunięciu kontenera.
Podobnie jak w poprzednim kroku, spróbuj dodać opinię i uzyskać do niej dostęp po zatrzymaniu, usunięciu i ponownym uruchomieniu kontenera.
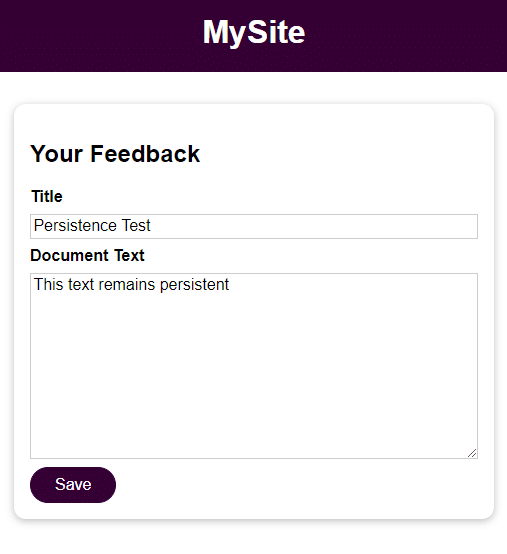
docker stop feedback-app docker rm feedback-app docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesJak widać, nawet po zatrzymaniu i usunięciu kontenera dane są dostępne i pozostają.
Streszczenie
Trwałe przechowywanie ma zasadnicze znaczenie dla aplikacji kontenerowych, ponieważ umożliwia utrwalanie danych poza cyklem życia kontenera. Dwa główne typy pamięci trwałej dla aplikacji kontenerowych to woluminy i montowania powiązań, z których każdy ma swoje zalety i przypadki użycia.
Woluminy są przechowywane w systemie plików kontenera, podczas gdy montowania powiązań są dostępne bezpośrednio na komputerze hosta.
Trwałe przechowywanie umożliwia współdzielenie danych między kontenerami, umożliwiając tworzenie złożonych, wielowarstwowych aplikacji. Trwałe przechowywanie ma zasadnicze znaczenie dla zapewnienia stabilności i ciągłości aplikacji kontenerowych, zapewniając niezawodny i elastyczny sposób przechowywania kluczowych danych.
A jeśli używasz Dockera do tworzenia aplikacji internetowych, przekonasz się, że konfiguracja wdrożeń plików Dockerfile za pomocą usługi Kinsta Application Hosting jest bardzo prosta.