
Robots.txt: co to jest i jak go utworzyć (kompletny przewodnik)
Opublikowany: 2023-05-05Jeśli jesteś właścicielem witryny internetowej lub zarządzasz jej zawartością, prawdopodobnie słyszałeś o pliku robots.txt. Jest to plik, który instruuje roboty wyszukiwarek, jak przeszukiwać i indeksować strony Twojej witryny. Pomimo jego znaczenia w optymalizacji pod kątem wyszukiwarek (SEO), wielu właścicieli witryn pomija znaczenie dobrze zaprojektowanego pliku robots.txt.
W tym kompletnym przewodniku dowiemy się, czym jest plik robots.txt, dlaczego jest ważny dla SEO i jak utworzyć plik robots.txt dla swojej witryny.
Co to jest plik Robots.txt?
Plik robots.txt to plik informujący roboty wyszukiwarek (znane również jako roboty indeksujące lub pająki), które strony lub sekcje witryny internetowej powinny być indeksowane, a które nie. Jest to zwykły plik tekstowy znajdujący się w katalogu głównym witryny internetowej i zazwyczaj zawiera listę katalogów, plików lub adresów URL, które webmaster chce zablokować przed indeksowaniem lub indeksowaniem w wyszukiwarkach.
Tak wygląda plik robots.txt:

Dlaczego plik Robots.txt jest ważny?
Istnieją trzy główne powody, dla których plik robots.txt jest ważny dla Twojej witryny:
1. Zmaksymalizuj budżet indeksowania
„Budżet indeksowania” oznacza liczbę stron, które Google zaindeksuje w Twojej witrynie w danym momencie. Liczba zależy od rozmiaru, kondycji i ilości linków zwrotnych w Twojej witrynie.
Budżet indeksowania jest ważny, ponieważ jeśli liczba stron w Twojej witrynie przekroczy budżet indeksowania, strony nie zostaną zindeksowane.
Ponadto strony, które nie są indeksowane, nie będą miały żadnego rankingu.
Używając pliku robots.txt do blokowania bezużytecznych stron, Googlebot (robot indeksujący Google) może przeznaczyć większą część Twojego budżetu na indeksowanie na ważne strony.
2. Blokuj strony niepubliczne
Masz w witrynie wiele stron, których nie chcesz indeksować.
Na przykład możesz mieć wewnętrzną stronę wyników wyszukiwania lub stronę logowania. Te strony muszą istnieć. Jednak nie chcesz, aby wylądowali na nich przypadkowi ludzie.
W takim przypadku użyjesz pliku robots.txt, aby uniemożliwić robotom indeksującym i botom wyszukiwarek dostęp do niektórych stron.
3. Zapobiegaj indeksowaniu zasobów
Czasami będziesz chciał, aby Google wykluczył zasoby, takie jak pliki PDF, filmy i obrazy z wyników wyszukiwania.
Być może chcesz zachować te zasoby jako prywatne lub chcesz, aby Google skupił się bardziej na ważnych treściach.
W takich przypadkach użycie pliku robots.txt jest najlepszym sposobem zapobiegania ich indeksowaniu.
Jak działa plik Robots.txt?
Pliki robots.txt instruują roboty wyszukiwarek, które strony lub katalogi witryny powinny, a których nie powinny indeksować lub indeksować.
Podczas indeksowania roboty wyszukiwarek znajdują linki i podążają za nimi. Ten proces prowadzi ich od strony X do strony Y do strony Z przez miliardy linków i stron internetowych.
Gdy bot odwiedza witrynę, pierwszą rzeczą, jaką robi, jest szukanie pliku robots.txt.
Jeśli go wykryje, odczyta plik przed zrobieniem czegokolwiek innego.
Załóżmy na przykład, że chcesz zezwolić wszystkim botom z wyjątkiem DuckDuckGo na indeksowanie Twojej witryny:
User-agent: DuckDuckBot Disallow: /
Uwaga: plik robots.txt może zawierać tylko instrukcje; nie może ich narzucić. To jest podobne do kodeksu postępowania. Dobre boty (takie jak boty wyszukiwarek) będą przestrzegać zasad, podczas gdy złe boty (takie jak boty spamujące) będą je ignorować.
Jak znaleźć plik Robots.txt?
Plik robots.txt, podobnie jak każdy inny plik w Twojej witrynie, znajduje się na Twoim serwerze.
Dostęp do pliku robots.txt dowolnej witryny internetowej można uzyskać, wprowadzając pełny adres URL strony głównej, a następnie dodając na końcu plik /robots.txt, na przykład https://pickupwp.com/robots.txt.
Jeśli jednak witryna nie zawiera pliku robots.txt, pojawi się komunikat o błędzie „404 Not Found”.
Jak utworzyć plik Robots.txt?
Zanim pokażemy, jak utworzyć plik robots.txt, przyjrzyjmy się składni pliku robots.txt.
Składnię pliku robots.txt można podzielić na następujące komponenty:
- User-agent: Określa robota lub robota, którego dotyczy rekord. Na przykład „User-agent: Googlebot” odnosi się tylko do robota wyszukiwarki Google, a „User-agent: *” do wszystkich robotów.
- Nie zezwalaj: Określa strony lub katalogi, których robot nie powinien indeksować. Na przykład „Nie zezwalaj: /prywatny/” uniemożliwi robotom indeksowanie jakichkolwiek stron w katalogu „prywatnym”.
- Zezwól: Określa strony lub katalogi, które robot powinien zezwolić na indeksowanie, nawet jeśli katalog nadrzędny jest zabroniony. Na przykład „Zezwalaj: /publiczny/” umożliwi robotom indeksowanie dowolnych stron w katalogu „publicznym”, nawet jeśli katalog nadrzędny jest zabroniony.
- Crawl-delay: Określa ilość czasu w sekundach, przez którą robot powinien czekać przed zaindeksowaniem witryny. Na przykład „Opóźnienie indeksowania: 10” poinstruuje robota, aby poczekał 10 sekund przed zaindeksowaniem witryny.
- Mapa witryny: określa lokalizację mapy witryny. Na przykład „Mapa witryny: https://www.example.com/sitemap.xml” poinformuje robota o lokalizacji mapy witryny.
Oto przykład pliku robots.txt:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
Uwaga: należy pamiętać, że w plikach robots.txt rozróżniana jest wielkość liter, dlatego podczas określania adresów URL należy używać właściwej wielkości liter.
Na przykład /publiczny/ to nie to samo co /publiczny/.
Z drugiej strony, w dyrektywach takich jak „Zezwalaj” i „Nie zezwalaj” nie jest rozróżniana wielkość liter, więc to od ciebie zależy, czy je zapiszesz wielką literą, czy nie.
Po zapoznaniu się ze składnią pliku robots.txt możesz utworzyć plik robots.txt za pomocą narzędzia do generowania plików robots.txt lub utworzyć go samodzielnie.
Oto jak utworzyć plik robots.txt w zaledwie czterech krokach:
1. Utwórz nowy plik i nazwij go Robots.txt
Wystarczy otworzyć dokument .txt w dowolnym edytorze tekstu lub przeglądarce internetowej.
Następnie nadaj dokumentowi nazwę robots.txt. Aby działał, musi mieć nazwę robots.txt.
Po zakończeniu możesz teraz rozpocząć wpisywanie dyrektyw.
2. Dodaj dyrektywy do pliku Robots.txt
Plik robots.txt zawiera co najmniej jedną grupę dyrektyw, z których każda zawiera wiele wierszy instrukcji.
Każda grupa zaczyna się od „User-agent” i zawiera następujące dane:
- Do kogo odnosi się grupa (klient użytkownika)
- Do jakich katalogów (stron) lub plików ma dostęp agent?
- Do jakich katalogów (stron) lub plików agent nie ma dostępu?
- Mapa witryny (opcjonalnie), aby informować wyszukiwarki o witrynach i plikach, które Twoim zdaniem są ważne.
Wiersze, które nie pasują do żadnej z tych dyrektyw, są ignorowane przez roboty indeksujące.

Na przykład chcesz uniemożliwić Google indeksowanie Twojego katalogu /private/.
Wyglądałoby to tak:
User-agent: Googlebot Disallow: /private/
Gdybyś miał dalsze instrukcje dla Google, umieściłbyś je w osobnym wierszu bezpośrednio poniżej, tak jak poniżej:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
Ponadto, jeśli skończyłeś z konkretnymi instrukcjami Google i chcesz utworzyć nową grupę dyrektyw.
Na przykład, jeśli chcesz uniemożliwić wszystkim wyszukiwarkom przeszukiwanie katalogów /archive/ i /support/.
Wyglądałoby to tak:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
Po zakończeniu możesz dodać mapę witryny.
Gotowy plik robots.txt powinien wyglądać tak:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
Następnie zapisz plik robots.txt. Pamiętaj, że musi mieć nazwę robots.txt.
Więcej przydatnych reguł pliku robots.txt znajdziesz w tym pomocnym przewodniku od Google.
3. Prześlij plik Robots.txt
Po zapisaniu pliku robots.txt na komputerze prześlij go na swoją stronę internetową i udostępnij wyszukiwarkom do indeksowania.
Niestety nie ma narzędzia, które mogłoby pomóc w tym kroku.
Przesłanie pliku robots.txt zależy od struktury plików Twojej witryny i hostingu.
Aby uzyskać instrukcje dotyczące przesyłania pliku robots.txt, wyszukaj w Internecie lub skontaktuj się ze swoim dostawcą usług hostingowych.
4. Przetestuj swój plik robots.txt
Po przesłaniu pliku robots.txt możesz sprawdzić, czy ktoś może go zobaczyć i czy Google może go odczytać.
Po prostu otwórz nową kartę w przeglądarce i wyszukaj plik robots.txt.
Na przykład https://pickupwp.com/robots.txt.
Jeśli zobaczysz plik robots.txt, możesz przetestować znaczniki (kod HTML).
W tym celu możesz użyć testera pliku robots.txt Google.
Uwaga: masz skonfigurowane konto Search Console do testowania pliku robots.txt za pomocą Testera pliku robots.txt.
Tester pliku robots.txt znajdzie i podświetli wszelkie ostrzeżenia dotyczące składni lub błędy logiczne.
Ponadto pokazuje także ostrzeżenia i błędy pod edytorem.
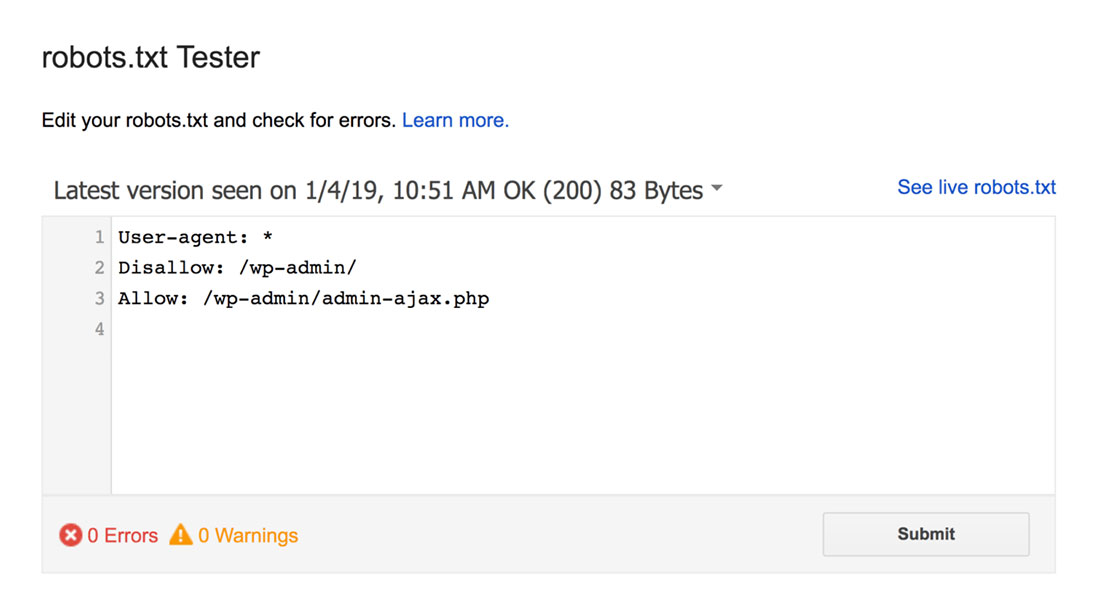
Możesz edytować błędy lub ostrzeżenia na stronie i ponownie testować tak często, jak to konieczne.
Pamiętaj tylko, że zmiany wprowadzone na stronie nie są zapisywane w Twojej witrynie.
Aby wprowadzić zmiany, skopiuj i wklej to do pliku robots.txt w swojej witrynie.
Najlepsze praktyki w pliku Robots.txt
Pamiętaj o tych sprawdzonych metodach podczas tworzenia pliku robots.txt, aby uniknąć typowych błędów.
1. Użyj nowych wierszy dla każdej dyrektywy
Aby zapobiec zamieszaniu robotów wyszukiwarek, dodaj każdą dyrektywę do nowego wiersza w pliku robots.txt. Dotyczy to zarówno reguł Zezwalaj, jak i Nie zezwalaj.
Na przykład, jeśli nie chcesz, aby robot indeksujący indeksował Twojego bloga lub stronę kontaktową, dodaj następujące reguły:
Disallow: /blog/ Disallow: /contact/
2. Użyj każdego agenta użytkownika tylko raz
Boty nie mają żadnego problemu, jeśli ciągle używasz tego samego agenta użytkownika.
Jednak użycie go tylko raz zapewnia porządek i zmniejsza ryzyko błędu ludzkiego.
3. Użyj symboli wieloznacznych, aby uprościć instrukcje
Jeśli masz dużą liczbę stron do zablokowania, dodanie reguły dla każdej z nich może być czasochłonne. Na szczęście możesz użyć symboli wieloznacznych, aby uprościć instrukcje.
Symbol wieloznaczny to znak, który może reprezentować jeden lub więcej znaków. Najczęściej używanym symbolem wieloznacznym jest gwiazdka (*).
Na przykład, jeśli chcesz zablokować wszystkie pliki z rozszerzeniem .jpg, dodaj następującą regułę:
Disallow: /*.jpg
4. Użyj „$”, aby określić koniec adresu URL
Znak dolara ($) to kolejny symbol wieloznaczny, którego można użyć do identyfikacji końca adresu URL. Jest to przydatne, jeśli chcesz ograniczyć określoną stronę, ale nie następujące po niej.
Załóżmy, że chcesz zablokować stronę kontaktową, ale nie stronę pomyślnego kontaktu, dodaj następującą regułę:
Disallow: /contact$
5. Użyj skrótu (#), aby dodać komentarze
Wszystko, co zaczyna się od hasha (#), jest ignorowane przez roboty indeksujące.
W rezultacie programiści często używają skrótu do dodawania komentarzy do pliku robots.txt. Utrzymuje porządek i czytelność dokumentu.
Na przykład, jeśli chcesz zapobiec wszystkim plikom kończącym się na .jpg, możesz dodać następujący komentarz:
# Block all files that end in .jpg Disallow: /*.jpg
Pomaga to każdemu zrozumieć, do czego służy ta reguła i dlaczego istnieje.
6. Użyj oddzielnych plików Robots.txt dla każdej subdomeny
Jeśli masz witrynę z wieloma subdomenami, zalecamy utworzenie osobnego pliku robots.txt dla każdej z nich. Dzięki temu wszystko jest uporządkowane i pomaga robotom indeksującym wyszukiwarek łatwiej zrozumieć Twoje zasady.
Podsumowanie!
Plik robots.txt jest przydatnym narzędziem SEO, ponieważ instruuje roboty wyszukiwarek, co indeksować, a czego nie.
Jednak ważne jest, aby używać go z rozwagą. Ponieważ błędna konfiguracja może spowodować całkowitą deindeksację Twojej witryny (np. użycie Disallow: /).
Ogólnie rzecz biorąc, dobrym sposobem jest umożliwienie wyszukiwarkom przeskanowania jak największej części Twojej witryny przy jednoczesnym zachowaniu poufnych informacji i unikaniu powielania treści. Na przykład możesz użyć dyrektywy Disallow, aby uniemożliwić określone strony lub katalogi, lub dyrektywy Allow, aby zastąpić regułę Disallow dla określonej strony.
Warto również wspomnieć, że nie wszystkie boty przestrzegają zasad podanych w pliku robots.txt, więc nie jest to idealna metoda kontrolowania tego, co jest indeksowane. Ale nadal jest to cenne narzędzie, które warto mieć w swojej strategii SEO.
Mamy nadzieję, że ten przewodnik pomoże Ci dowiedzieć się, czym jest plik robots.txt i jak go utworzyć.
Więcej informacji znajdziesz w innych przydatnych zasobach:
- 15 praktycznych wskazówek dotyczących blogowania dla nowych blogerów
- Odblokowanie mocy słów kluczowych z długim ogonem (przewodnik dla początkujących)
Na koniec śledź nas na Twitterze, aby regularnie otrzymywać informacje o nowych artykułach.