
Plik robots.txt WordPress… Co to jest i co robi
Opublikowany: 2020-11-25Czy zastanawiałeś się kiedyś, czym jest plik robots.txt i do czego służy? Plik robots.txt służy do komunikacji z robotami indeksującymi (tzw. botami) używanymi przez Google i inne wyszukiwarki. Mówi im, które części witryny mają indeksować, a które ignorować. Jako taki plik robots.txt może pomóc (lub potencjalnie złamać!) Twoje wysiłki SEO. Jeśli chcesz, aby Twoja witryna była dobrze pozycjonowana, dobre zrozumienie pliku robots.txt jest niezbędne!
Gdzie znajduje się plik Robots.txt?
WordPress zazwyczaj uruchamia tak zwany „wirtualny” plik robots.txt, co oznacza, że nie jest dostępny przez SFTP. Możesz jednak wyświetlić jego podstawową zawartość, przechodząc do twojadomena.com/robots.txt. Prawdopodobnie zobaczysz coś takiego:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpPierwsza linia określa, do których botów mają zastosowanie zasady. W naszym przykładzie gwiazdka oznacza, że reguły zostaną zastosowane do wszystkich botów (np. tych z Google, Bing itd.).
Druga linia definiuje regułę, która uniemożliwia botom dostęp do folderu /wp-admin, a trzecia linia mówi, że boty mogą analizować plik /wp-admin/admin-ajax.php.
Dodaj własne zasady
W przypadku prostej witryny WordPress domyślne reguły zastosowane przez WordPress do pliku robots.txt mogą być więcej niż wystarczające. Jeśli jednak chcesz mieć większą kontrolę i możliwość dodawania własnych reguł, aby dać bardziej szczegółowe instrukcje robotom wyszukiwarek na temat indeksowania Twojej witryny, będziesz musiał utworzyć własny fizyczny plik robots.txt i umieścić go w katalogu głównym katalog twojej instalacji.
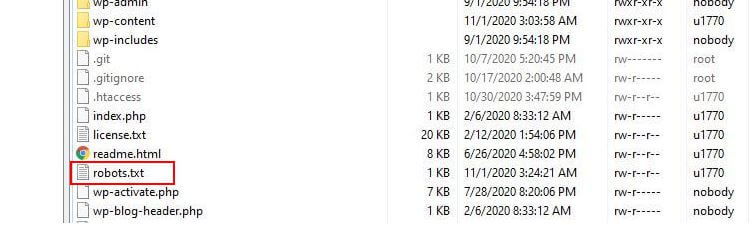
Istnieje kilka powodów, dla których warto zmienić konfigurację pliku robots.txt i określić, co dokładnie te boty będą mogły indeksować. Jednym z głównych powodów jest czas spędzony przez bota na indeksowaniu Twojej witryny. Google (i inni) nie pozwalają botom spędzać nieograniczonego czasu w każdej witrynie… z bilionami stron muszą bardziej zniuansować to, co ich boty będą indeksować, a co zignorują, próbując wydobyć najbardziej przydatne informacje o stronie internetowej.

Hostuj swoją stronę internetową z Pressidium
60- DNIOWA GWARANCJA ZWROTU PIENIĘDZY
Gdy zezwalasz botom na indeksowanie wszystkich stron w Twojej witrynie, część czasu indeksowania jest spędzana na stronach, które nie są ważne lub nawet nie są istotne. Dzięki temu mają mniej czasu na poruszanie się po bardziej odpowiednich obszarach witryny. Uniemożliwiając botom dostęp do niektórych części Twojej witryny, zwiększasz czas dostępny dla botów na wyodrębnianie informacji z najbardziej odpowiednich części Twojej witryny (które, miejmy nadzieję, zostaną zindeksowane). Ponieważ indeksowanie jest szybsze, Google z większym prawdopodobieństwem ponownie odwiedzi Twoją witrynę i będzie aktualizować jej indeks. Oznacza to, że nowe posty na blogu i inne świeże treści będą prawdopodobnie szybciej indeksowane, co jest dobrą wiadomością.
Przykłady edycji pliku Robots.txt
Plik robots.txt oferuje dużo miejsca na dostosowanie. W związku z tym przedstawiliśmy szereg przykładów reguł, które mogą być używane do dyktowania sposobu indeksowania witryny przez boty.
Zezwalanie lub blokowanie botów
Najpierw spójrzmy, jak możemy ograniczyć konkretnego bota. Aby to zrobić, wystarczy zastąpić gwiazdkę (*) nazwą klienta użytkownika bota, którego chcemy zablokować, na przykład „MSNBot”. Pełna lista znanych klientów użytkownika jest dostępna tutaj.
User-agent: MSNBot Disallow: /Umieszczenie myślnika w drugiej linii ograniczy dostęp bota do wszystkich katalogów.
Aby zezwolić tylko jednemu botowi na indeksowanie naszej witryny, użyjemy dwuetapowego procesu. Najpierw ustawimy tego jednego bota jako wyjątek, a następnie zabronimy wszystkim botom takim jak ten:
User-agent: Google Disallow: User-agent: * Disallow: /Aby umożliwić dostęp do wszystkich botów na wszystkich treściach, dodajemy te dwie linie:
User-agent: * Disallow:Ten sam efekt można by osiągnąć, po prostu tworząc plik robots.txt, a następnie pozostawiając go pustym.
Blokowanie dostępu do określonych plików
Chcesz zatrzymać roboty indeksujące określone pliki w Twojej witrynie? To łatwe! W poniższym przykładzie uniemożliwiliśmy wyszukiwarkom dostęp do wszystkich plików .pdf w naszej witrynie.
User-agent: * Disallow: /*.pdf$Symbol „$” służy do określenia końca adresu URL. Ponieważ wielkość liter jest rozróżniana, plik o nazwie my.PDF nadal będzie przeszukiwany (zwróć uwagę na CAPS).
Złożone wyrażenia logiczne
Niektóre wyszukiwarki, takie jak Google, rozumieją użycie bardziej skomplikowanych wyrażeń regularnych. Należy jednak pamiętać, że nie wszystkie wyszukiwarki mogą zrozumieć wyrażenia logiczne zawarte w pliku robots.txt.

Jednym z przykładów jest użycie symbolu $. W plikach robots.txt ten symbol oznacza koniec adresu URL. Tak więc w poniższym przykładzie zablokowaliśmy botom wyszukiwania odczytywanie i indeksowanie plików, które kończą się na .php
Disallow: /*.php$Oznacza to, że /index.php nie może być indeksowany, ale /index.php?p=1 może być. Jest to przydatne tylko w bardzo szczególnych okolicznościach i należy go używać ostrożnie, w przeciwnym razie istnieje ryzyko zablokowania dostępu bota do plików, których nie chciałeś!
Możesz także ustawić różne zasady dla każdego bota, określając zasady, które mają do nich zastosowanie indywidualnie. Poniższy przykładowy kod ograniczy dostęp do folderu wp-admin dla wszystkich botów, jednocześnie blokując dostęp do całej witryny dla wyszukiwarki Bing. Niekoniecznie chciałbyś to zrobić, ale jest to przydatna demonstracja tego, jak elastyczne mogą być reguły w pliku robots.txt.
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /Mapy witryn XML
Mapy witryn XML naprawdę pomagają botom wyszukiwania zrozumieć układ Twojej witryny. Aby jednak być użytecznym, bot musi wiedzieć, gdzie znajduje się mapa witryny. Dyrektywa „sitemap” służy do informowania wyszukiwarek, że a) istnieje mapa witryny oraz b) gdzie mogą ją znaleźć.
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:Możesz też określić wiele lokalizacji w mapach witryn:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* DisallowOpóźnienia indeksowania botów
Inną funkcją, którą można osiągnąć za pomocą pliku robots.txt, jest nakazanie botom „zwolnienia” indeksowania Twojej witryny. Może to być konieczne, jeśli zauważysz, że Twój serwer jest przeciążony wysokim natężeniem ruchu botów. Aby to zrobić, określ klienta użytkownika, którego chcesz spowolnić, a następnie dodaj opóźnienie.
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10Cyfry (10) w tym przykładzie to opóźnienie, jakie ma wystąpić między indeksowaniem poszczególnych stron w Twojej witrynie. Tak więc w powyższym przykładzie poprosiliśmy Bing Bota, aby zatrzymał się na dziesięć sekund między każdą przemierzaną stroną, dając w ten sposób naszemu serwerowi trochę wytchnienia.
Jedyną nieco złą wiadomością na temat tej konkretnej reguły robots.txt jest to, że bot Google jej nie przestrzega. Możesz jednak poinstruować ich boty, aby zwalniały z poziomu Google Search Console.
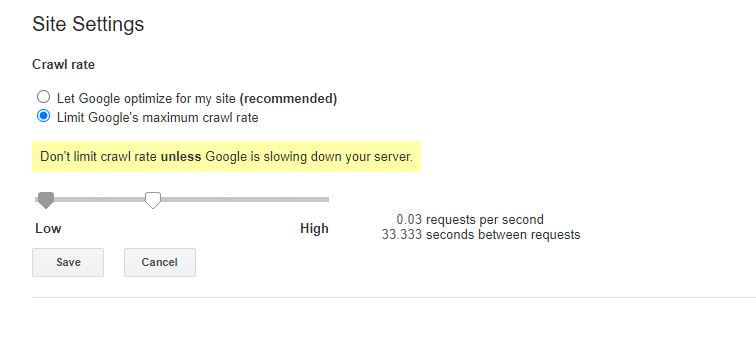
Uwagi dotyczące reguł pliku robots.txt:
- We wszystkich regułach pliku robots.txt rozróżniana jest wielkość liter. Pisz ostrożnie!
- Upewnij się, że przed poleceniem na początku wiersza nie ma spacji.
- Zmiany wprowadzone w pliku robots.txt mogą potrwać od 24 do 36 godzin, zanim boty zostaną zauważone.
Jak przetestować i przesłać plik robots.txt WordPress?
Po utworzeniu nowego pliku robots.txt warto sprawdzić, czy nie ma w nim błędów. Możesz to zrobić za pomocą Google Search Console.
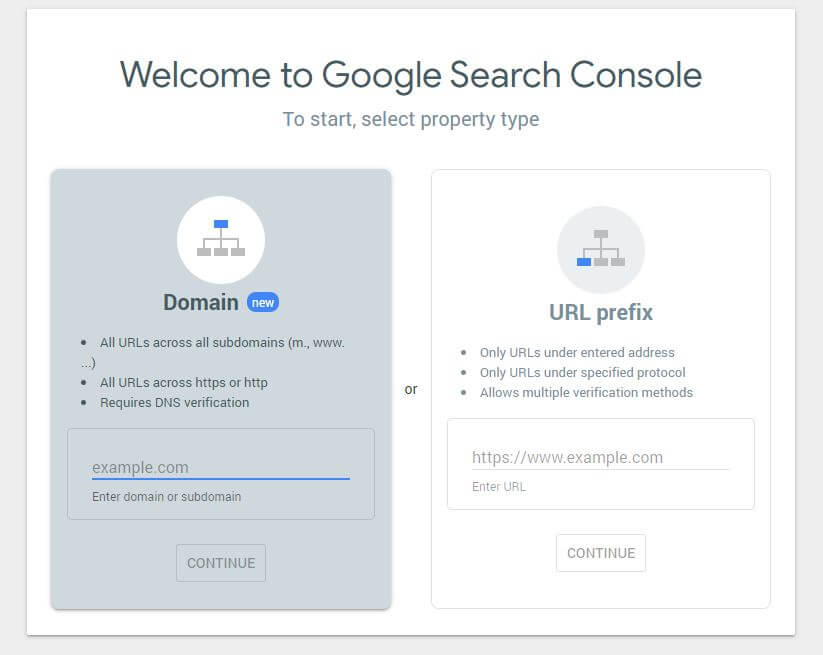
Najpierw musisz przesłać swoją domenę (jeśli nie masz jeszcze konta Search Console do konfiguracji swojej witryny). Google dostarczy Ci rekord TXT, który należy dodać do systemu DNS, aby zweryfikować domenę.
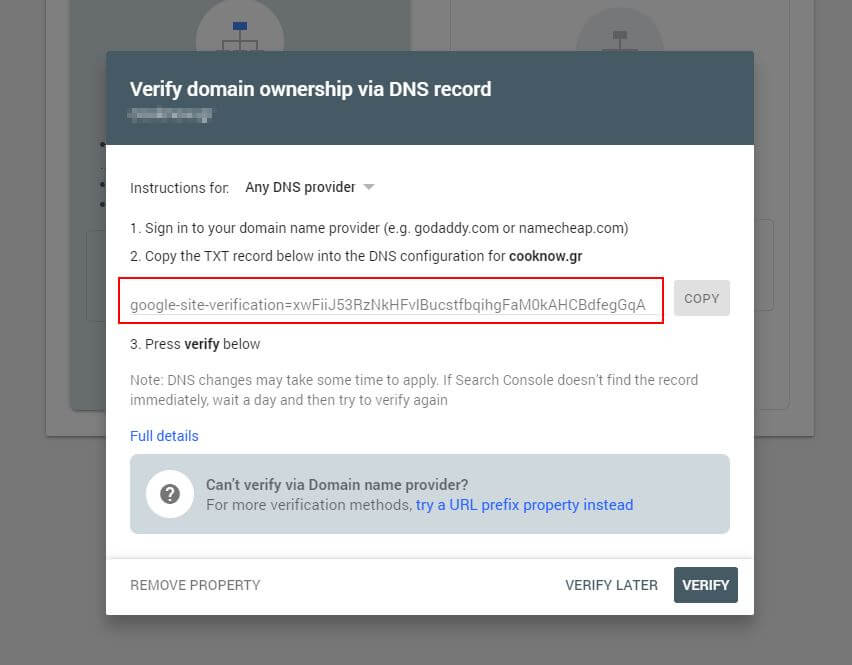
Po rozprzestrzenieniu się tej aktualizacji DNS (czujesz się niecierpliwy… spróbuj użyć Cloudflare do zarządzania DNS) możesz odwiedzić tester robots.txt i sprawdzić, czy są jakieś ostrzeżenia dotyczące zawartości pliku robots.txt.
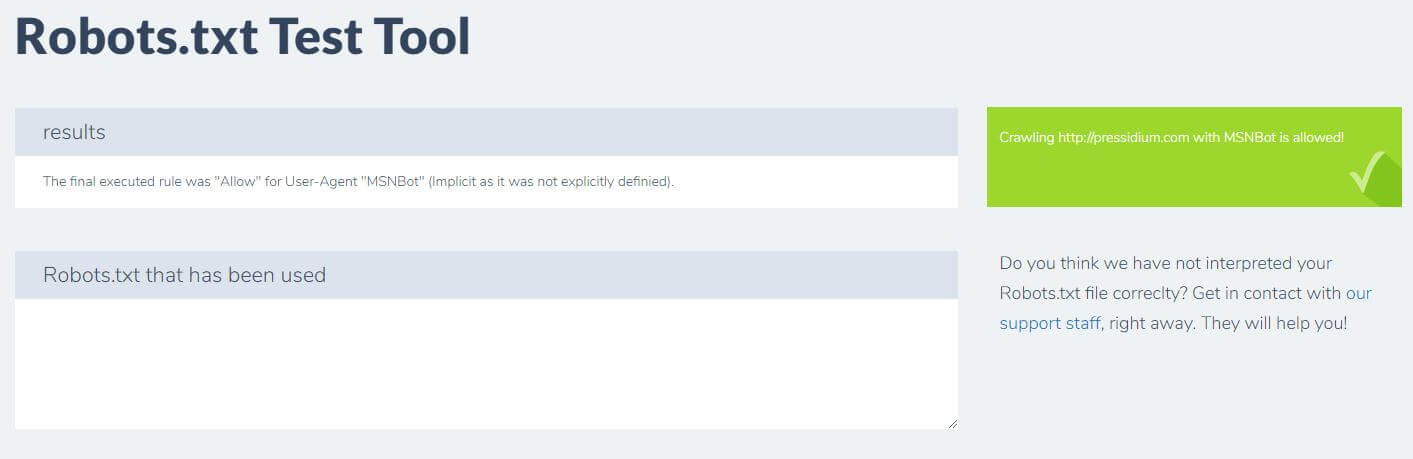
Inną rzeczą, którą możesz zrobić, aby przetestować, czy obowiązujące zasady przynoszą pożądany efekt, jest użycie narzędzia testowego robots.txt, takiego jak Ryte.
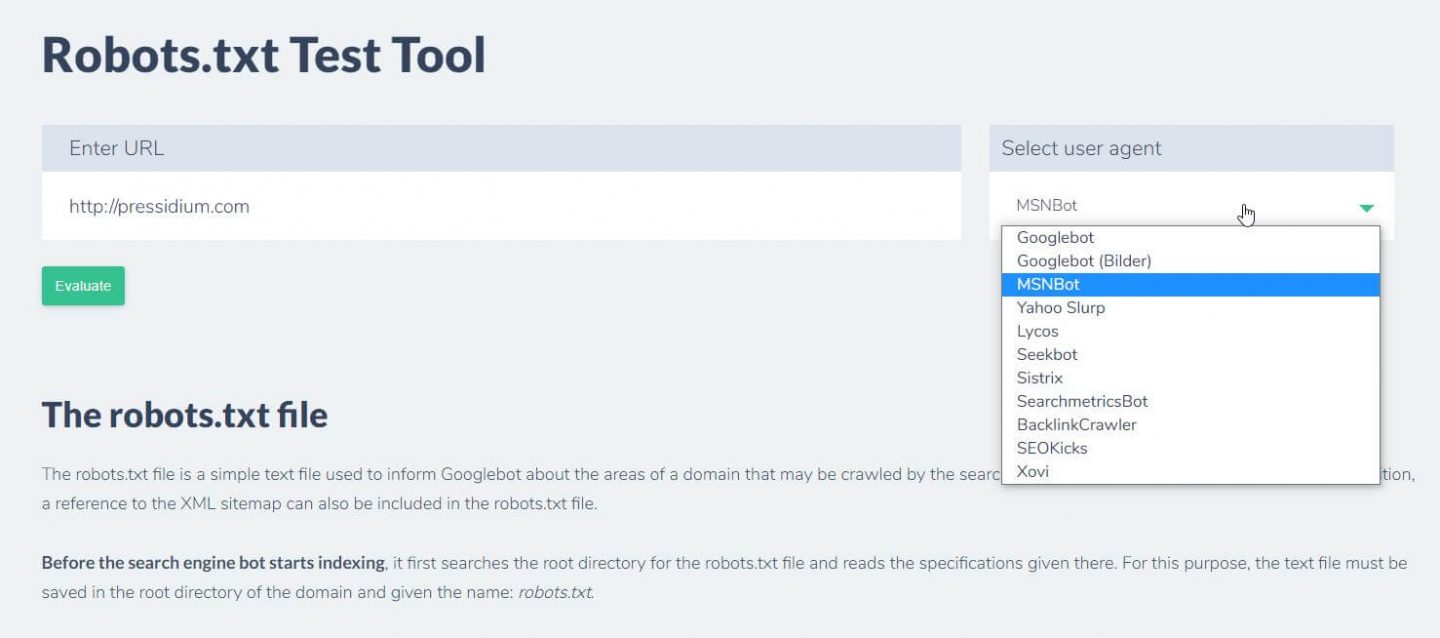
Wystarczy wpisać swoją domenę i wybrać klienta użytkownika z panelu po prawej stronie. Po przesłaniu zobaczysz swoje wyniki.
Wniosek
Umiejętność korzystania z pliku robots.txt to kolejne przydatne narzędzie w zestawie narzędzi programisty. Jeśli jedyną rzeczą, którą wyniesiesz z tego samouczka, jest możliwość sprawdzenia, czy Twój plik robots.txt nie blokuje botów takich jak Google (czego prawdopodobnie nie będziesz chciał zrobić), to nie jest to złe! Podobnie, jak widać, plik robots.txt oferuje cały szereg dokładniejszej kontroli nad Twoją witryną, co pewnego dnia może się przydać.