
Crie um conjunto robusto de réplicas do MongoDB em tempo recorde (4 métodos)
Publicados: 2023-03-11MongoDB é um banco de dados NoSQL que usa documentos do tipo JSON com esquemas dinâmicos. Ao trabalhar com bancos de dados, é sempre bom ter um plano de contingência caso um de seus servidores de banco de dados falhe. Barra lateral, você pode reduzir as chances disso acontecer aproveitando uma ferramenta de gerenciamento bacana para o seu site WordPress.
É por isso que é útil ter muitas cópias de seus dados. Também reduz as latências de leitura. Ao mesmo tempo, pode melhorar a escalabilidade e a disponibilidade do banco de dados. É aqui que entra a replicação. É definida como a prática de sincronizar dados em vários bancos de dados.
Neste artigo, vamos nos aprofundar nos vários aspectos importantes da replicação do MongoDB, como seus recursos e mecanismo, para citar alguns.
O que é replicação no MongoDB?
No MongoDB, os conjuntos de réplicas executam a replicação. Este é um grupo de servidores que mantém o mesmo conjunto de dados por meio da replicação. Você pode até usar a replicação do MongoDB como parte do balanceamento de carga. Aqui, você pode distribuir as operações de gravação e leitura em todas as instâncias, com base no caso de uso.
O que é um conjunto de réplicas do MongoDB?
Cada instância do MongoDB que faz parte de um determinado conjunto de réplicas é um membro. Cada conjunto de réplicas precisa ter um membro primário e pelo menos um membro secundário.
O membro primário é o ponto de acesso primário para transações com o conjunto de réplicas. Também é o único membro que pode aceitar operações de gravação. A replicação primeiro copia o oplog primário (log de operações). Em seguida, ele repete as alterações registradas nos respectivos conjuntos de dados dos secundários. Portanto, cada conjunto de réplicas pode ter apenas um membro primário por vez. Vários primários que recebem operações de gravação podem causar conflitos de dados.
Normalmente, os aplicativos consultam apenas o membro principal para operações de gravação e leitura. Você pode projetar sua configuração para ler de um ou mais dos membros secundários. A transferência de dados assíncrona pode fazer com que as leituras dos nós secundários veiculem dados antigos. Portanto, esse arranjo não é ideal para todos os casos de uso.
Recursos do conjunto de réplicas
O mecanismo de failover automático diferencia os conjuntos de réplicas do MongoDB de seus concorrentes. Na ausência de um primário, uma eleição automatizada entre os nós secundários escolhe um novo primário.
Conjunto de réplicas do MongoDB versus cluster do MongoDB
Um conjunto de réplicas do MongoDB criará várias cópias do mesmo conjunto de dados nos nós do conjunto de réplicas. O principal objetivo de um conjunto de réplicas é:
- Ofereça uma solução de backup integrada
- Aumentar a disponibilidade de dados
Um cluster MongoDB é um jogo completamente diferente. Ele distribui os dados em muitos nós por meio de uma chave de fragmentação. Esse processo fragmentará os dados em várias partes chamadas fragmentos. Em seguida, ele copia cada fragmento para um nó diferente. Um cluster visa suportar grandes conjuntos de dados e operações de alto rendimento. Ele consegue isso escalando horizontalmente a carga de trabalho.
Aqui está a diferença entre um conjunto de réplicas e um cluster, em termos leigos:
- Um cluster distribui a carga de trabalho. Ele também armazena fragmentos de dados (estilhaços) em muitos servidores.
- Um conjunto de réplicas duplica o conjunto de dados completamente.
O MongoDB permite que você combine essas funcionalidades criando um cluster fragmentado. Aqui, você pode replicar cada fragmento para um servidor secundário. Isso permite que um shard ofereça alta redundância e disponibilidade de dados.
Manter e configurar um conjunto de réplicas pode ser tecnicamente trabalhoso e demorado. E encontrar o serviço de hospedagem certo? Essa é uma outra dor de cabeça. Com tantas opções por aí, é fácil perder horas pesquisando, em vez de construir o seu negócio.
Deixe-me dar um resumo sobre uma ferramenta que faz tudo isso e muito mais para que você possa voltar a esmagá-la com seu serviço/produto.
A solução de hospedagem de aplicativos da Kinsta, na qual mais de 55.000 desenvolvedores confiam, você pode colocá-la em funcionamento em apenas 3 etapas simples. Se isso parece bom demais para ser verdade, aqui estão mais alguns benefícios de usar Kinsta:
- Desfrute de um melhor desempenho com as conexões internas de Kinsta : Esqueça suas lutas com bancos de dados compartilhados. Mude para bancos de dados dedicados com conexões internas que não tenham contagem de consultas ou limites de contagem de linhas. Kinsta é mais rápido, mais seguro e não cobra pela largura de banda/tráfego interno.
- Um conjunto de recursos sob medida para desenvolvedores : dimensione seu aplicativo na plataforma robusta compatível com Gmail, YouTube e Pesquisa do Google. Fique tranquilo, você está em boas mãos aqui.
- Desfrute de velocidades inigualáveis com um data center de sua escolha : escolha a região que funciona melhor para você e seus clientes. Com mais de 25 centros de dados para escolher, os mais de 275 PoPs de Kinsta garantem velocidade máxima e uma presença global para o seu site.
Experimente a solução de hospedagem de aplicativos da Kinsta gratuitamente hoje!
Como funciona a replicação no MongoDB?
No MongoDB, você envia operações de gravação para o servidor principal (nó). O primário atribui as operações em servidores secundários, replicando os dados.
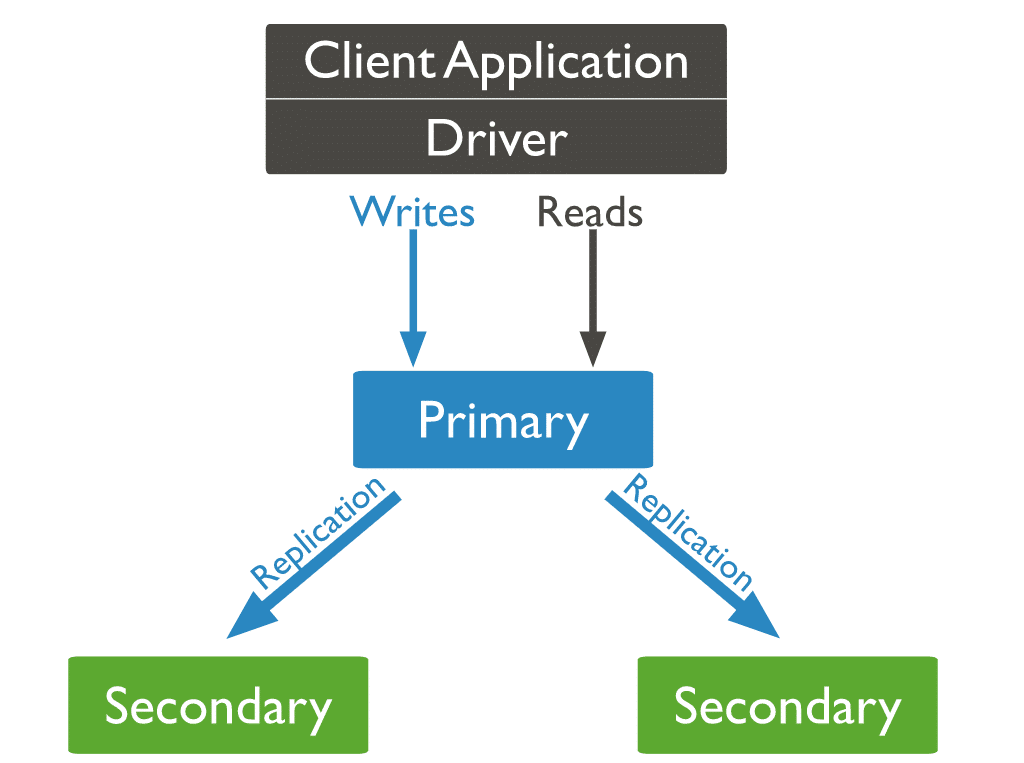
Três tipos de nós do MongoDB
Dos três tipos de nós do MongoDB, dois surgiram antes: nós primários e secundários. O terceiro tipo de nó do MongoDB que é útil durante a replicação é um árbitro. O nó do árbitro não tem uma cópia do conjunto de dados e não pode se tornar um primário. Dito isto, o árbitro participa nas eleições primárias.
Mencionamos anteriormente o que acontece quando o nó primário fica inativo, mas e se os nós secundários morderem o pó? Nesse cenário, o nó primário se torna secundário e o banco de dados fica inacessível.
Eleição de membro
As eleições podem ocorrer nos seguintes cenários:
- Inicializando um conjunto de réplicas
- Perda de conectividade com o nó primário (que pode ser detectado por heartbeats)
- Manutenção de um conjunto de réplicas usando métodos
rs.reconfigoustepDown - Adicionando um novo nó a um conjunto de réplicas existente
Um conjunto de réplicas pode ter até 50 membros, mas apenas 7 ou menos podem votar em qualquer eleição.
O tempo médio antes de um cluster eleger um novo primário não deve ultrapassar 12 segundos. O algoritmo de eleição tentará ter o secundário com a maior prioridade disponível. Ao mesmo tempo, os membros com valor de prioridade 0 não podem se tornar primários e não participam da eleição.
A Preocupação com a Escrita
Para maior durabilidade, as operações de gravação têm uma estrutura para copiar os dados em um número especificado de nós. Você pode até oferecer feedback ao cliente com isso. Essa estrutura também é conhecida como “preocupação com a gravação”. Ele tem membros portadores de dados que precisam reconhecer uma preocupação de gravação antes que a operação retorne como bem-sucedida. Geralmente, os conjuntos de réplicas têm um valor de 1 como preocupação de gravação. Assim, apenas o primário deve confirmar a gravação antes de retornar a confirmação de gravação.
Você pode até aumentar o número de membros necessários para confirmar a operação de gravação. Não há limite para o número de membros que você pode ter. Mas, se os números forem altos, você precisa lidar com a alta latência. Isso ocorre porque o cliente precisa aguardar o reconhecimento de todos os membros. Além disso, você pode definir a preocupação de gravação da “maioria”. Isso calcula mais da metade dos membros após receber sua confirmação.
Preferência de leitura
Para as operações de leitura, você pode mencionar a preferência de leitura que descreve como o banco de dados direciona a consulta aos membros do conjunto de réplicas. Geralmente, o nó primário recebe a operação de leitura, mas o cliente pode mencionar uma preferência de leitura para enviar as operações de leitura aos nós secundários. Aqui estão as opções para a preferência de leitura:
- primaryPreferred : Normalmente, as operações de leitura vêm do nó primário, mas se isso não estiver disponível, os dados são extraídos dos nós secundários.
- primary : Todas as operações de leitura vêm do nó primário.
- secundário : Todas as operações de leitura são executadas pelos nós secundários.
- mais próximo : Aqui, as solicitações de leitura são roteadas para o nó alcançável mais próximo, que pode ser detectado executando o comando
ping. O resultado das operações de leitura pode vir de qualquer membro do conjunto de réplicas, independentemente de ser o primário ou o secundário. - secondPreferred : Aqui, a maioria das operações de leitura vem dos nós secundários, mas se nenhum deles estiver disponível, os dados são obtidos do nó primário.
Sincronização de dados do conjunto de replicação
Para manter cópias atualizadas do conjunto de dados compartilhado, membros secundários de um conjunto de réplicas replicam ou sincronizam dados de outros membros.
O MongoDB utiliza duas formas de sincronização de dados. Sincronização inicial para preencher novos membros com o conjunto de dados completo. Replicação para executar alterações contínuas no conjunto de dados completo.
Sincronização inicial
Durante a sincronização inicial, um nó secundário executa o comando init sync para sincronizar todos os dados do nó primário para outro nó secundário que contém os dados mais recentes. Portanto, o nó secundário aproveita consistentemente o recurso tailable cursor para consultar as entradas oplog mais recentes na coleção local.oplog.rs do nó primário e aplica essas operações nessas entradas oplog.
A partir do MongoDB 5.2, as sincronizações iniciais podem ser baseadas em cópia de arquivo ou lógicas.
Sincronização Lógica
Quando você executa uma sincronização lógica, o MongoDB:
- Desenvolve todos os índices de coleção à medida que os documentos são copiados para cada coleção.
- Duplica todos os bancos de dados, exceto o banco de dados local.
mongodverifica cada coleção em todos os bancos de dados de origem e insere todos os dados em suas duplicatas dessas coleções. - Executa todas as alterações no conjunto de dados. Aproveitando o oplog da fonte, o
mongodatualiza seu conjunto de dados para representar o estado atual do conjunto de réplicas. - Extrai registros oplog recém-adicionados durante a cópia de dados. Certifique-se de que o membro de destino tenha espaço em disco suficiente no banco de dados local para armazenar provisoriamente esses registros oplog durante esse estágio de cópia de dados.
Quando a sincronização inicial é concluída, o membro faz a transição de STARTUP2 para SECONDARY .
Sincronização inicial baseada em cópia de arquivo
Logo de cara, você só pode executar isso se usar o MongoDB Enterprise. Esse processo executa a sincronização inicial duplicando e movendo os arquivos no sistema de arquivos. Este método de sincronização pode ser mais rápido que a sincronização inicial lógica em alguns casos. Lembre-se de que a sincronização inicial baseada em cópia de arquivo pode levar a contagens imprecisas se você executar o método count() sem um predicado de consulta.
Mas esse método também tem seu quinhão de limitações:
- Durante uma sincronização inicial baseada em cópia de arquivo, você não pode gravar no banco de dados local do membro que está sendo sincronizado. Você também não pode executar um backup no membro que está sendo sincronizado ou no membro que está sendo sincronizado.
- Ao aproveitar o mecanismo de armazenamento criptografado, o MongoDB usa a chave de origem para criptografar o destino.
- Você só pode executar uma sincronização inicial de um determinado membro por vez.
Replicação
Os membros secundários replicam os dados de forma consistente após a sincronização inicial. Os membros secundários duplicarão o oplog de sua sincronização da origem e executarão essas operações em um processo assíncrono.
Os secundários são capazes de modificar automaticamente sua sincronização da origem conforme necessário com base nas alterações no tempo de ping e no estado da replicação de outros membros.
Replicação de streaming
No MongoDB 4.4, a sincronização das origens envia um fluxo contínuo de entradas oplog para seus secundários de sincronização. A replicação de streaming reduz o atraso de replicação em redes de alta carga e alta latência. Também pode:
- Diminua o risco de perder operações de gravação com
w:1devido ao failover primário. - Diminuir desatualização para leituras de secundários.
- Reduza a latência nas operações de gravação com
w:“majority”ew:>1. Resumindo, qualquer problema de gravação que precise aguardar a replicação.
Replicação multithread
O MongoDB costumava gravar operações em lotes por meio de vários encadeamentos para melhorar a simultaneidade. O MongoDB agrupa os lotes por id de documento enquanto aplica cada grupo de operações com um thread diferente.
O MongoDB sempre executa operações de gravação em um determinado documento em sua ordem de gravação original. Isso mudou no MongoDB 4.0.
A partir do MongoDB 4.0, as operações de leitura direcionadas a secundários e configuradas com um nível de preocupação de leitura de “majority” ou “local” agora serão lidas de um instantâneo WiredTiger dos dados se a leitura ocorrer em um secundário onde os lotes de replicação estão sendo aplicados. A leitura de um instantâneo garante uma exibição consistente dos dados e permite que a leitura ocorra simultaneamente com a replicação em andamento sem a necessidade de um bloqueio.
Portanto, as leituras secundárias que precisam desses níveis de interesse de leitura não precisam mais esperar que os lotes de replicação sejam aplicados e podem ser tratadas à medida que são recebidas.
Como criar um conjunto de réplicas do MongoDB
Conforme mencionado anteriormente, o MongoDB lida com a replicação por meio de conjuntos de réplicas. Nas próximas seções, destacaremos alguns métodos que você pode usar para criar conjuntos de réplicas para seu caso de uso.
Método 1: Criando um novo conjunto de réplicas do MongoDB no Ubuntu
Antes de começarmos, você precisará garantir que possui pelo menos três servidores executando o Ubuntu 20.04, com o MongoDB instalado em cada servidor.
Para configurar um conjunto de réplicas, é essencial fornecer um endereço onde cada membro do conjunto de réplicas possa ser acessado por outros no conjunto. Neste caso, mantemos três membros no conjunto. Embora possamos usar endereços IP, isso não é recomendado, pois os endereços podem mudar inesperadamente. Uma alternativa melhor pode ser usar os nomes de host DNS lógicos ao configurar conjuntos de réplicas.
Podemos fazer isso configurando o subdomínio para cada membro de replicação. Embora isso possa ser ideal para um ambiente de produção, esta seção descreve como configurar a resolução de DNS editando os respectivos arquivos de host de cada servidor. Este arquivo nos permite atribuir nomes de host legíveis a endereços IP numéricos. Assim, se em qualquer caso o seu endereço IP mudar, tudo o que você precisa fazer é atualizar os arquivos dos hosts nos três servidores, em vez de reconfigurar a réplica definida do zero!
Principalmente, hosts são armazenados no diretório /etc/ . Repita os comandos abaixo para cada um dos seus três servidores:
sudo nano /etc/hostsNo comando acima, estamos usando o nano como nosso editor de texto, porém, você pode usar qualquer editor de texto de sua preferência. Após as primeiras linhas que configuram o localhost, adicione uma entrada para cada membro do conjunto de réplicas. Essas entradas assumem a forma de um endereço IP seguido pelo nome legível por humanos de sua escolha. Embora você possa nomeá-los como quiser, certifique-se de ser descritivo para saber diferenciar cada membro. Para este tutorial, usaremos os nomes de host abaixo:
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
Usando esses nomes de host, seus arquivos /etc/hosts seriam semelhantes às seguintes linhas destacadas:

Salve e feche o arquivo.
Depois de configurar a resolução DNS para o conjunto de réplicas, precisamos atualizar as regras do firewall para permitir que eles se comuniquem. Execute o seguinte comando ufw em mongo0 para fornecer acesso mongo1 à porta 27017 em mongo0:
sudo ufw allow from mongo1_server_ip to any port 27017 No lugar do parâmetro mongo1_server_ip , insira o endereço IP real do seu servidor mongo1. Além disso, se você atualizou a instância do Mongo neste servidor para usar uma porta não padrão, certifique-se de alterar 27017 para refletir a porta que sua instância do MongoDB está usando.
Agora adicione outra regra de firewall para dar ao mongo2 acesso à mesma porta:
sudo ufw allow from mongo2_server_ip to any port 27017 No lugar do parâmetro mongo2_server_ip , insira o endereço IP real do seu servidor mongo2. Em seguida, atualize as regras de firewall para seus outros dois servidores. Execute os seguintes comandos no servidor mongo1, certificando-se de alterar os endereços IP no lugar do parâmetro server_ip para refletir os de mongo0 e mongo2, respectivamente:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017Por fim, execute esses dois comandos no mongo2. Novamente, certifique-se de inserir os endereços IP corretos para cada servidor:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017Sua próxima etapa é atualizar o arquivo de configuração de cada instância do MongoDB para permitir conexões externas. Para permitir isso, você precisa modificar o arquivo de configuração em cada servidor para refletir o endereço IP e indicar o conjunto de réplicas. Embora você possa usar qualquer editor de texto de sua preferência, estamos usando o editor de texto nano mais uma vez. Vamos fazer as seguintes modificações em cada arquivo mongod.conf.
No mongo0:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"No mongo1:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"No mongo2:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodCom isso, você habilitou a replicação para cada instância do MongoDB do servidor.
Agora você pode inicializar o conjunto de réplicas usando o método rs.initiate() . Este método só precisa ser executado em uma única instância do MongoDB no conjunto de réplicas. Certifique-se de que o nome e o membro do conjunto de réplicas correspondam às configurações feitas anteriormente em cada arquivo de configuração.
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })Se o método retornar “ok”: 1 na saída, significa que o conjunto de réplicas foi iniciado corretamente. Abaixo está um exemplo de como deve ser a saída:
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }Desligue o servidor MongoDB
Você pode desligar um servidor MongoDB usando o método db.shutdownServer() . Abaixo está a sintaxe para o mesmo. Ambos force e timeoutsecs são parâmetros opcionais.
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) Esse método pode falhar se o membro do conjunto de réplicas mongod executar determinadas operações como construções de índice. Para interromper as operações e forçar o desligamento do membro, você pode inserir o parâmetro booleano force como true.
Reinicie o MongoDB com –replSet
Para redefinir a configuração, certifique-se de que cada nó em seu conjunto de réplicas esteja parado. Em seguida, exclua o banco de dados local para cada nó. Inicie-o novamente usando o sinalizador –replSet e execute rs.initiate() em apenas uma instância mongod para o conjunto de réplicas.
mongod --replSet "rs0" rs.initiate() pode receber um documento de configuração do conjunto de réplicas opcional, a saber:

- A opção
Replication.replSetNameou—replSetpara especificar o nome do conjunto de réplicas no campo_id. - A matriz de membros, que contém um documento para cada membro do conjunto de réplicas.
O método rs.initiate() aciona uma eleição e elege um dos membros para ser o principal.
Adicionar membros ao conjunto de réplicas
Para adicionar membros ao conjunto, inicie instâncias mongod em várias máquinas. Em seguida, inicie um cliente mongo e use o comando rs.add() .
O comando rs.add() tem a seguinte sintaxe básica:
rs.add(HOST_NAME:PORT)Por exemplo,
Suponha que mongo1 seja sua instância mongod e esteja atendendo na porta 27017. Use o comando do cliente Mongo rs.add() para adicionar essa instância ao conjunto de réplicas.
rs.add("mongo1:27017") Somente depois de estar conectado ao nó primário, você pode adicionar uma instância mongod ao conjunto de réplicas. Para verificar se você está conectado ao primário, use o comando db.isMaster() .
Remover usuários
Para remover um membro, podemos usar rs.remove()
Para fazer isso, em primeiro lugar, desligue a instância mongod que deseja remover usando o método db.shutdownServer() que discutimos acima.
Em seguida, conecte-se ao primário atual do conjunto de réplicas. Para determinar o primário atual, use db.hello() enquanto estiver conectado a qualquer membro do conjunto de réplicas. Depois de determinar o primário, execute um dos seguintes comandos:
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 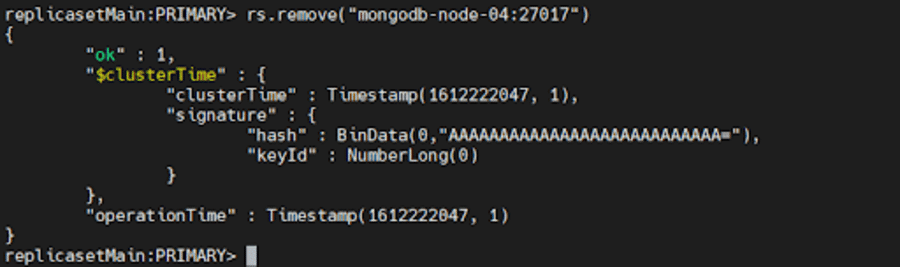
Se o conjunto de réplicas precisar eleger um novo primário, o MongoDB pode desconectar o shell brevemente. Nesse cenário, ele se reconectará automaticamente novamente. Além disso, pode exibir um erro DBClientCursor::init call() com falha, mesmo que o comando seja bem-sucedido.
Método 2: Configurando um conjunto de réplicas do MongoDB para implantação e teste
Em geral, você pode configurar conjuntos de réplicas para teste com RBAC habilitado ou desabilitado. Neste método, configuraremos conjuntos de réplicas com o controle de acesso desabilitado para implantá-lo em um ambiente de teste.
Primeiro, crie diretórios para todas as instâncias que fazem parte do conjunto de réplicas usando o seguinte comando:
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2Este comando criará diretórios para três instâncias do MongoDB replicaset0-0, replicaset0-1 e replicaset0-2. Agora, inicie as instâncias do MongoDB para cada um deles usando o seguinte conjunto de comandos:
Para o Servidor 1:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Para o Servidor 2:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Para o servidor 3:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 O parâmetro –oplogSize é usado para evitar que a máquina fique sobrecarregada durante a fase de teste. Isso ajuda a reduzir a quantidade de espaço em disco que cada disco consome.
Agora, conecte-se a uma das instâncias usando o shell Mongo conectando-se usando o número da porta abaixo.
mongo --port 27017 Podemos usar o comando rs.initiate() para iniciar o processo de replicação. Você terá que substituir o parâmetro hostname pelo nome do seu sistema.
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }Agora você pode passar o arquivo de objeto de configuração como parâmetro para o comando de inicialização e usá-lo da seguinte maneira:
rs.initiate(rsconf)E aí está! Você criou com sucesso um conjunto de réplicas do MongoDB para fins de desenvolvimento e teste.
Método 3: Transformando uma Instância Independente em um Conjunto de Réplicas do MongoDB
O MongoDB permite que seus usuários transformem suas instâncias autônomas em conjuntos de réplicas. Embora as instâncias autônomas sejam usadas principalmente para a fase de teste e desenvolvimento, os conjuntos de réplicas fazem parte do ambiente de produção.
Para começar, vamos encerrar nossa instância mongod usando o seguinte comando:
db.adminCommand({"shutdown":"1"}) Reinicie sua instância usando o parâmetro –repelSet em seu comando para especificar o conjunto de réplicas que você usará:
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>Você deve especificar o nome do seu servidor junto com o endereço exclusivo no comando.
Conecte o shell com sua instância do MongoDB e use o comando de inicialização para iniciar o processo de replicação e converter a instância com êxito em um conjunto de réplicas. Você pode executar todas as operações básicas, como adicionar ou remover uma instância, usando os seguintes comandos:
rs.add(“<host_name:port>”) rs.remove(“host-name”) Além disso, você pode verificar o status do conjunto de réplicas do MongoDB usando os comandos rs.status() e rs.conf() .
Método 4: MongoDB Atlas — Uma alternativa mais simples
A replicação e a fragmentação podem funcionar juntas para formar algo chamado cluster fragmentado. Embora a instalação e a configuração possam ser bastante demoradas, embora diretas, o MongoDB Atlas é uma alternativa melhor do que os métodos mencionados anteriormente.
Ele automatiza seus conjuntos de réplicas, facilitando a implementação do processo. Ele pode implantar conjuntos de réplicas fragmentadas globalmente com apenas alguns cliques, permitindo recuperação de desastres, gerenciamento mais fácil, localidade de dados e implantações multirregionais.
No MongoDB Atlas, precisamos criar clusters – eles podem ser um conjunto de réplicas ou um cluster fragmentado. Para um determinado projeto, o número de nós em um cluster em outras regiões é limitado a um total de 40.
Isso exclui os clusters gratuitos ou compartilhados e as regiões de nuvem do Google que se comunicam entre si. O número total de nós entre quaisquer duas regiões deve atender a essa restrição. Por exemplo, se houver um projeto em que:
- A região A tem 15 nós.
- A região B tem 25 nós
- A região C tem 10 nós
Só podemos alocar mais 5 nós para a região C como,
- Região A+ Região B = 40; atende a restrição de 40 sendo o número máximo de nós permitido.
- Região B+ Região C = 25+10+5 (nós adicionais alocados para C) = 40; atende a restrição de 40 sendo o número máximo de nós permitido.
- Região A+ Região C =15+10+5 (Nodos adicionais alocados para C) = 30; atende a restrição de 40 sendo o número máximo de nós permitido.
Se alocarmos mais 10 nós para a região C, fazendo com que a região C tenha 20 nós, então a Região B + a Região C = 45 nós. Isso excederia a restrição fornecida, portanto, talvez você não consiga criar um cluster multirregional.
Quando você cria um cluster, o Atlas cria um contêiner de rede no projeto para o provedor de nuvem, caso não existisse anteriormente. Para criar um cluster de conjunto de réplicas no MongoDB Atlas, execute o seguinte comando na CLI do Atlas:
atlas clusters create [name] [options]Certifique-se de fornecer um nome de cluster descritivo, pois ele não pode ser alterado após a criação do cluster. O argumento pode conter letras ASCII, números e hífens.
Existem várias opções disponíveis para criação de cluster no MongoDB com base em seus requisitos. Por exemplo, se você deseja backup em nuvem contínuo para seu cluster, defina --backup como true.
Lidando com atraso de replicação
O atraso na replicação pode ser bastante desanimador. É um atraso entre uma operação no primário e a aplicação dessa operação do oplog para o secundário. Se sua empresa lida com grandes conjuntos de dados, espera-se um atraso dentro de um determinado limite. No entanto, às vezes, fatores externos também podem contribuir e aumentar o atraso. Para se beneficiar de uma replicação atualizada, certifique-se de que:
- Você roteia o tráfego de sua rede em uma largura de banda estável e suficiente. A latência da rede desempenha um papel importante ao afetar sua replicação e, se a rede for insuficiente para atender às necessidades do processo de replicação, haverá atrasos na replicação de dados em todo o conjunto de réplicas.
- Você tem uma taxa de transferência de disco suficiente. Se o sistema de arquivos e o dispositivo de disco no secundário não puderem liberar dados para o disco tão rapidamente quanto o primário, o secundário terá dificuldade em acompanhar. Portanto, os nós secundários processam as consultas de gravação mais lentamente que o nó primário. Esse é um problema comum na maioria dos sistemas multilocatários, incluindo instâncias virtualizadas e implantações em larga escala.
- Você solicita uma preocupação de gravação de confirmação de gravação após um intervalo para fornecer a oportunidade para os secundários alcançarem o primário, especialmente quando você deseja executar uma operação de carregamento em massa ou ingestão de dados que requer um grande número de gravações no primário. Os secundários não conseguirão ler o oplog rápido o suficiente para acompanhar as mudanças; particularmente com problemas de gravação não reconhecidos.
- Você identifica as tarefas em segundo plano em execução. Certas tarefas como cron jobs, atualizações de servidor e verificações de segurança podem ter efeitos inesperados na rede ou no uso do disco, causando atrasos no processo de replicação.
Se você não tem certeza se há um atraso de replicação em seu aplicativo, não se preocupe – a próxima seção discute estratégias de solução de problemas!
Solução de problemas de conjuntos de réplicas do MongoDB
Você configurou com êxito seus conjuntos de réplicas, mas percebe que seus dados são inconsistentes entre os servidores. Isso é muito alarmante para empresas de grande porte, no entanto, com métodos rápidos de solução de problemas, você pode encontrar a causa ou até mesmo corrigir o problema! Abaixo estão algumas estratégias comuns para solucionar problemas de implantações de conjuntos de réplicas que podem ser úteis:
Verifique o status da réplica
Podemos verificar o status atual do conjunto de réplicas e o status de cada membro executando o seguinte comando em uma sessão mongosh conectada ao primário de um conjunto de réplicas.
rs.status()Verifique o atraso de replicação
Conforme discutido anteriormente, o atraso da replicação pode ser um problema sério, pois torna os membros “atrasados” inelegíveis para se tornarem primários rapidamente e aumenta a possibilidade de que as operações de leitura distribuídas sejam inconsistentes. Podemos verificar o tamanho atual do log de replicação usando o seguinte comando:
rs.printSecondaryReplicationInfo() Isso retorna o valor syncedTo , que é a hora em que a última entrada do oplog foi gravada no secundário para cada membro. Aqui está um exemplo para demonstrar o mesmo:
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary Um membro atrasado pode aparecer como 0 segundos atrás do primário quando o período de inatividade no primário é maior que o valor members[n].secondaryDelaySecs .
Testar conexões entre todos os membros
Cada membro de um conjunto de réplicas deve ser capaz de se conectar com todos os outros membros. Certifique-se sempre de verificar as conexões em ambas as direções. Principalmente, configurações de firewall ou topologias de rede impedem a conectividade normal e necessária que pode bloquear a replicação.
Por exemplo, vamos supor que a instância mongod se vincule ao host local e ao nome do host 'ExampleHostname', que está associado ao endereço IP 198.41.110.1:
mongod --bind_ip localhost, ExampleHostnamePara se conectar a esta instância, os clientes remotos devem especificar o nome do host ou o endereço IP:
mongosh --host ExampleHostname mongosh --host 198.41.110.1Se um conjunto de réplicas consistir em três membros, m1, m2 e m3, usando a porta padrão 27017, você deve testar a conexão conforme abaixo:
Em m1:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017Em m2:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017Em m3:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 Se alguma conexão em qualquer direção falhar, você terá que verificar a configuração do firewall e reconfigurá-lo para permitir as conexões.
Garantindo comunicações seguras com autenticação de arquivo de chave
Por padrão, a autenticação de arquivo-chave no MongoDB depende do mecanismo de autenticação de resposta de desafio salgado (SCRAM). Para fazer isso, o MongoDB deve ler e validar as credenciais fornecidas pelo usuário, que incluem uma combinação de nome de usuário, senha e banco de dados de autenticação que a instância específica do MongoDB conhece. Este é o mecanismo exato usado para autenticar usuários que fornecem uma senha ao se conectar ao banco de dados.
Ao ativar a autenticação no MongoDB, o controle de acesso baseado em função (RBAC) é ativado automaticamente para o conjunto de réplicas e o usuário recebe uma ou mais funções que determinam seu acesso aos recursos do banco de dados. Quando o RBAC está ativado, significa que apenas o usuário Mongo autenticado válido com os privilégios apropriados poderá acessar os recursos no sistema.
O arquivo-chave age como uma senha compartilhada para cada membro do cluster. Isso permite que cada instância mongod no conjunto de réplicas use o conteúdo do arquivo-chave como a senha compartilhada para autenticar outros membros na implantação.
Somente as instâncias mongod com o arquivo de chave correto podem ingressar no conjunto de réplicas. O comprimento de uma chave deve estar entre 6 e 1024 caracteres e pode conter apenas caracteres no conjunto base64. Observe que o MongoDB remove os caracteres de espaço em branco ao ler as chaves.
Você pode gerar um arquivo-chave usando vários métodos. Neste tutorial, usamos openssl para gerar uma string complexa de 1024 caracteres aleatórios para usar como uma senha compartilhada. It then uses chmod to change file permissions to provide read permissions for the file owner only. Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. Por exemplo:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
And voila! You have successfully enabled keyfile authentication!
Resumo
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!