
Desmascarado: o que 10 milhões de senhas revelam sobre as pessoas que as escolhem
Publicados: 2022-07-11Muito se sabe sobre senhas. A maioria é curta, simples e muito fácil de decifrar. Mas muito menos se sabe sobre as razões psicológicas pelas quais uma pessoa escolhe uma senha específica. A maioria dos especialistas recomenda criar uma senha forte para evitar a violação de dados. Mas por que tantos internautas ainda preferem senhas fracas?
Analisamos as opções de senha de 10 milhões de pessoas, de CEOs a cientistas, para descobrir o que elas revelam sobre as coisas que consideramos fáceis de lembrar e difíceis de adivinhar.
Quem é o primeiro super-herói que vem à mente? Que tal um número entre um e 10? E por fim, uma cor vibrante? Pense rapidamente em cada uma dessas coisas, se ainda não o fez, e combine todas as três em uma única frase.
Agora, é hora de adivinhar.
É Superman7red ? Não, não: Batman3Laranja ? Se adivinhamos qualquer uma das respostas individuais corretamente, é porque os humanos são previsíveis. E esse é o problema com senhas. É verdade que nos demos a vantagem de algumas perguntas sorrateiramente escolhidas, mas isso não é nada comparado à sorrateira em escala industrial do software de quebra de senha criado para esse fim. HashCat, por exemplo, pode levar 300.000 tentativas de sua senha por segundo (dependendo de como ela é hash), então mesmo se você escolher Hawkeye6yellow , sua frase secreta, mais cedo ou mais tarde, não será mais secreta.
As senhas são muitas vezes fáceis de adivinhar porque muitos de nós pensam em palavras e números óbvios e os combinam de maneiras simples. Queríamos explorar esse conceito e, ao fazê-lo, ver o que poderíamos descobrir sobre como a mente de uma pessoa funciona quando ela organiza palavras, números e (espero) símbolos em uma ordem (provavelmente não muito) única.
Começamos escolhendo dois conjuntos de dados para analisar.
Dois conjuntos de dados, várias advertências
O primeiro conjunto de dados é um despejo de 5 milhões de credenciais que apareceu pela primeira vez em setembro de 2014 em um fórum russo de BitCoin. 1 Eles pareciam ser contas do Gmail (e alguns Yandex.ru), mas uma inspeção mais aprofundada mostrou que, enquanto a maioria dos e-mails incluídos eram endereços válidos do Gmail, a maioria das senhas de texto simples eram antigas do Gmail (ou seja, não estão mais ativas) ou senhas que não foram usadas com os endereços do Gmail associados. No entanto, o WordPress.com redefiniu 100.000 contas e disse que outras 600.000 estavam potencialmente em risco. 2 O despejo parece ser o equivalente a vários anos de senhas que foram coletadas de vários lugares, por vários meios. Para nossos propósitos acadêmicos, no entanto, isso não importava. As senhas ainda eram escolhidas pelos titulares de contas do Gmail, mesmo que não fossem para suas próprias contas do Gmail e, como 98% não estavam mais em uso, sentimos que poderíamos explorá-las com segurança. 3
Usamos esse conjunto de dados, que chamaremos de “despejo do Gmail”, para responder a perguntas demográficas (especialmente aquelas relacionadas a gêneros e idades dos usuários de senhas). Extraímos esses fatos pesquisando os 5 milhões de endereços de e-mail para qualquer um que continha nomes e anos de nascimento. Por exemplo, se um endereço foi [protegido por e-mail], ele foi codificado como um homem nascido em 1984. Esse método de inferência pode ser complicado. Não vamos aborrecê-lo com muitos detalhes técnicos aqui, mas ao final do processo de codificação, tínhamos 485.000 dos 5 milhões de endereços do Gmail codificados por sexo e 220.000 codificados por idade. Neste ponto, vale a pena ter em mente a pergunta: “Os usuários que incluem seus primeiros nomes e anos de nascimento em seus endereços de e-mail escolhem senhas diferentes daqueles que não o fazem?” — porque é teoricamente possível que o façam. Discutiremos isso um pouco mais tarde.
Por enquanto, porém, veja como os usuários que codificamos foram divididos por década de nascimento e gênero.
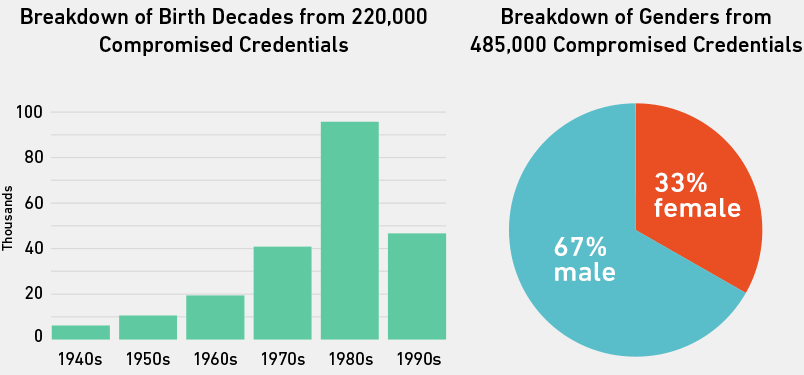
O despejo do Gmail, ou pelo menos aquelas pessoas com primeiro nome e/ou anos de nascimento em seus endereços, era voltado para homens e pessoas nascidas nos anos 80. Isso provavelmente se deve aos perfis demográficos dos sites cujos bancos de dados foram comprometidos para formar o dump. A pesquisa de endereços no dump que continha o símbolo + (adicionado por usuários do Gmail para rastrear o que os sites fazem com seus endereços de e-mail) revelou que um grande número de credenciais se originou do File Dropper, eHarmony, um site de tubo adulto e Friendster.
O segundo conjunto de dados, e aquele que usamos para reunir a maioria de nossos resultados, foi generosamente divulgado pelo consultor de segurança Mark Burnett, por meio de seu site xato.net. 4 Consiste em 10 milhões de senhas, que foram coletadas de todos os cantos da web durante um período de vários anos. Mark coletou listas publicamente despejadas, vazadas e publicadas de milhares de fontes para construir possivelmente uma das mais abrangentes listas de senhas reais de todos os tempos. Para ler mais sobre esse conjunto de dados, confira o FAQ em seu blog. 5
Não vamos gastar muito tempo dando a você fatos realmente básicos sobre esse conjunto de dados (como todas as médias). Isso já foi feito muitas vezes antes. Em vez disso, vamos apenas olhar para as 50 senhas mais usadas dos 10 milhões. Então entraremos em território potencialmente mais interessante.
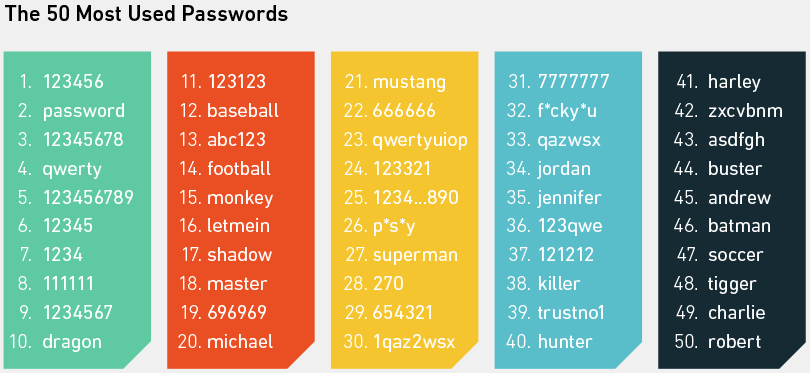
Como você pode ver, e provavelmente já sabe, as senhas mais comuns são exemplos brilhantes de coisas que imediatamente surgem na mente de alguém quando um site solicita que ele crie uma senha. Eles são todos extremamente fáceis de lembrar e, em virtude desse fato, uma brincadeira de criança para adivinhar usando um ataque de dicionário. Quando Mark Burnett analisou 3,3 milhões de senhas para determinar as mais comuns em 2014 (todas em sua lista maior de 10 milhões), ele descobriu que 0,6% eram 123456 . E usando as 10 principais senhas, um hacker poderia, em média, adivinhar 16 de 1.000 senhas.
No entanto, menos pessoas do que nos anos anteriores estão usando os tipos de senhas vistos acima. Os usuários estão se tornando um pouco mais conscientes do que torna uma senha forte. Por exemplo, adicionar um número ou dois no final de uma frase de texto. Isso torna melhor, certo?
“Vou adicionar um número para torná-lo mais seguro.”
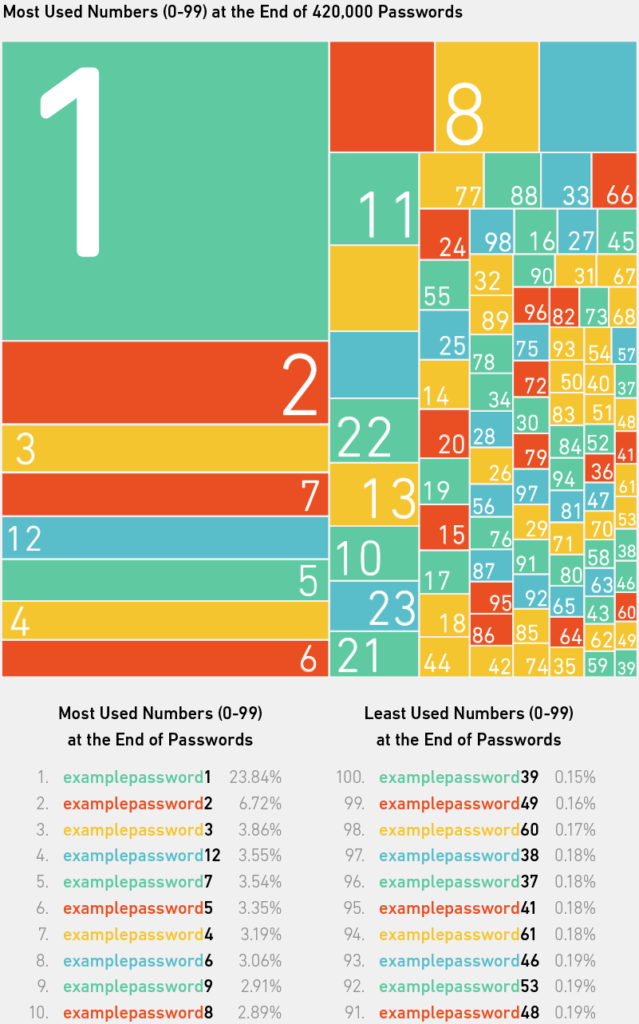
Quase meio milhão, ou 420.000 (8,4%), das 10 milhões de senhas terminavam com um número entre 0 e 99. E mais de uma em cada cinco pessoas que somaram esses números simplesmente escolheram 1 . Talvez eles achassem que isso era o mais fácil de lembrar. Ou talvez eles tenham sido solicitados pelo site a incluir um número com sua escolha de palavra base. As outras escolhas mais comuns eram 2, 3, 12 (presumivelmente pensado como um-dois, em vez de 12), 7 e assim por diante. Foi observado que quando você pede a uma pessoa para pensar em um número entre um e 10, a maioria diz sete ou três (daí nossas suposições na introdução), e as pessoas parecem ter uma tendência a pensar em números primos. 6, 7 Isso pode estar em jogo aqui, mas também é possível que dígitos únicos sejam escolhidos como alternativas às senhas que as pessoas já usam, mas querem usar novamente sem “comprometer” suas credenciais em outros sites.
É um ponto discutível, porém, quando você considera que um cracker de senhas decente pode facilmente anexar um número, ou vários milhares, ao seu dicionário de palavras ou abordagem de força bruta. A força de uma senha realmente se resume à entropia.
Avaliando a entropia da senha
Em termos simples, quanto mais entropia uma senha tiver, mais forte ela tende a ser. A entropia aumenta com o comprimento da senha e com a variação dos caracteres que a compõem. No entanto, embora a variação nos caracteres usados afete sua pontuação de entropia (e quão difícil é adivinhar), o comprimento da senha é mais significativo. Isso ocorre porque, à medida que a senha fica mais longa, o número de maneiras pelas quais suas partes constituintes podem ser embaralhadas em uma nova combinação fica exponencialmente maior e, portanto, muito mais difícil de adivinhar.
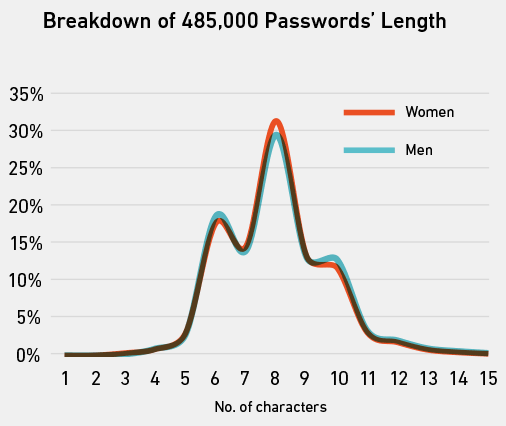
O comprimento médio de uma senha do despejo do Gmail era de oito caracteres (por exemplo, senha ), e não houve diferença significativa entre o comprimento médio das senhas dos homens em comparação com as das mulheres.
E a entropia? Qual é um reflexo mais preciso da força da senha do que apenas o comprimento do caractere?
A entropia média de uma senha do despejo do Gmail foi de 21,6, o que não é algo particularmente fácil de conceituar. O gráfico à esquerda dá uma imagem mais clara. Novamente, havia apenas uma diferença insignificante entre homens e mulheres, mas havia muito mais senhas com entropia próxima de zero do que mais de 60.
As senhas de exemplo variam em um caractere ou dois conforme os intervalos de entropia. De um modo geral, a entropia aumenta com o comprimento, e aumentar o intervalo de caracteres incluindo números, maiúsculas e símbolos também ajuda.
Então, como calculamos a entropia para todos os 5 milhões de senhas do dump do Gmail?
Existem muitas maneiras de calcular a entropia da senha, e alguns métodos são mais rudimentares (e menos realistas) do que outros. O mais básico assume que uma senha só pode ser adivinhada tentando cada combinação de seus caracteres. Uma abordagem mais inteligente, no entanto, reconhece que os humanos — como vimos — são viciados em padrões e, portanto, certas suposições podem ser feitas sobre a maioria de suas senhas. E com base nessas suposições, regras para tentar adivinhar suas senhas podem ser estabelecidas e usadas para acelerar significativamente o processo de cracking (ao agrupar combinações de caracteres em padrões comumente usados). É tudo muito inteligente e não podemos levar nenhum crédito por isso. Em vez disso, o crédito vai para Dan Wheeler, que criou o estimador de entropia que usamos. Chama-se Zxcvbn, e pode ser visto e lido em detalhes aqui. 8
Em resumo, ele constrói um “conhecimento” de como as pessoas inconscientemente incluem padrões em suas senhas em sua estimativa do que um bom cracker de senhas precisaria fazer para determinar esses padrões. Por exemplo, password , por uma estimativa ingênua, tem uma entropia de 37,6 bits. Zxcvbn, no entanto, pontua zero (a menor e a pior pontuação de entropia) porque leva em conta o fato de que cada lista de palavras usada por crackers de senha contém a palavra password . Ele faz uma coisa semelhante com outros padrões mais comuns, como leet speak (adicionando numb3rs a palavras para [email protected] aparentemente menos gue55able).
Ele também pontua outras senhas, que à primeira vista parecem muito aleatórias, como tendo entropia zero. qaz2wsx (a 30ª senha mais comum), por exemplo, parece bem aleatória, certo? Na verdade, é tudo menos isso. Na verdade, é um padrão de teclado (uma “caminhada” facilmente repetível de uma tecla para a próxima). O próprio Zxcvbn tem o nome de um desses padrões.
Retiramos os 20 padrões de teclado mais usados do conjunto de dados de 10 milhões de senhas. Optamos por excluir padrões de números, como 123456 , porque eles são apenas uma espécie de teclado, e também há tantos deles no topo da lista de senhas mais usadas que não haveria espaço para ver algumas os mais interessantes se os tivéssemos incluído.

Dezenove dos 20 padrões de teclado acima parecem tão previsíveis quanto você poderia esperar, exceto pelo último: Adgjmptw . Você consegue adivinhar por que isso se classificou entre os padrões mais usados?

Você provavelmente não precisa, pois quase certamente já olhou abaixo.

Embora duvidemos que sejamos os primeiros a identificá-lo, ainda não encontramos nenhuma outra referência a esse padrão de teclado entre os mais usados em senhas. No entanto, ocupa o 20º lugar acima.
Caso você não tenha percebido, ele é gerado pressionando de 2 a 9 no teclado de discagem de um smartphone (a primeira letra de cada correspondente a cada letra do padrão de teclas na senha).
Inicialmente ficamos confusos com esse padrão porque a maioria das pessoas não digita letras com um teclado de discagem; eles usam o layout QWERTY. Então nos lembramos de telefones como Blackberries, que possuem um teclado físico com números sempre à vista nas teclas.
Esse padrão apresenta uma pergunta interessante: como a seleção de senhas mudará à medida que mais pessoas as criarem em dispositivos de toque que tornam certos caracteres (como símbolos e maiúsculas) mais difíceis de selecionar do que ao usar um teclado normal?
É claro que os padrões de teclado, especialmente os acima, não são problema para qualquer bom cracker de senhas. O Passpat usa vários layouts de teclado e um algoritmo inteligente para medir a probabilidade de uma senha ser criada a partir de um padrão de teclado. 9 E existem outras ferramentas para gerar milhões de padrões de teclado, para compilá-los e usá-los como uma lista, em vez de perder tempo tentando decifrar as mesmas combinações pela força bruta. 10
A maioria das pessoas não usa padrões de teclado. Eles seguem o método clássico e frequentemente inseguro de escolher uma palavra aleatória.

Agora você pode ver por que adivinhamos Batman e Superman no início deste artigo: eles são os nomes de super-heróis mais usados no conjunto de dados de 10 milhões de senhas. Um ponto importante sobre as listas acima é que às vezes é difícil saber em que sentido uma pessoa usa uma palavra quando a inclui em sua senha. Por exemplo, na lista de cores, preto às vezes pode se referir ao sobrenome Black ; o mesmo vale para outras palavras com contextos duais. Para minimizar esse problema ao contar as frequências das palavras acima, abordamos cada lista separadamente. As cores, por exemplo, só eram contadas quando as senhas começavam com o nome da cor e terminavam com números ou símbolos. Dessa forma, evitamos contar vermelho em Alfred e azul em BluesBrothers . Usar essa abordagem conservadora, é claro, significa que perdemos muitos nomes legítimos de cores, mas parece melhor saber que a lista acima contém apenas “definitivos”.
Outras listas tinham regras diferentes. Não incluímos gatos e cachorros na lista de animais porque gato aparece em muitas outras palavras. Em vez disso, contamos cães e gatos separadamente e descobrimos que eles são usados quase o mesmo número de vezes. No entanto, gatos é usado muito mais em conjunto com Wild- e Bob- (equipes esportivas) do que cães são usados em outras frases. Então, diríamos que os cães provavelmente vencem.
Os substantivos e verbos mais comuns só foram contados se aparecessem entre os 1.000 principais substantivos e os 1.000 principais verbos usados no dia-a-dia do inglês. Caso contrário, as listas estariam cheias de substantivos como senha e verbos como amor .
Não que o amor não seja uma palavra interessante. Na verdade, é usado com frequência surpreendente em senhas. Encontramos 40.000 vezes separadas nos 10 milhões de senhas e muito nas 5 milhões de credenciais do Gmail também.
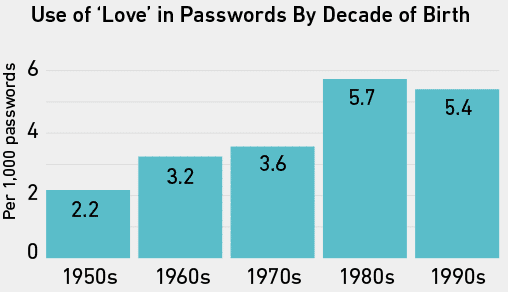
Quando contamos a frequência do amor nas senhas das pessoas cujas idades inferimos de seus nomes de usuário, os nascidos nos anos 80 e 90 o usavam com um pouco mais de frequência do que as pessoas mais velhas.
Nos dados do Gmail, 1,4% das senhas das mulheres continham amor , em comparação com 0,7% das dos homens. Em outras palavras, com base nesses dados, pelo menos, as mulheres parecem usar a palavra amor em suas senhas duas vezes mais que os homens. Essa descoberta segue os passos de outras pesquisas recentes sobre a palavra amor em senhas. Uma equipe do Instituto de Tecnologia da Universidade de Ontário relatou que ilove [nome masculino] era quatro vezes mais comum do que ilove [nome feminino]; iloveyou era 10 vezes mais comum que iloveme ; e <3 foi o segundo método mais comum de combinar um símbolo com um número. 11
Agora que aprendemos um pouco sobre as palavras e números mais comuns em senhas, os padrões de teclado mais usados, o conceito de entropia de senha e a relativa futilidade de métodos simples de ofuscação de senha como leet speak, podemos passar para nossa porta final de chamada. É o mais pessoal e, potencialmente, o mais interessante.
Senhas dos ricos e poderosos
Mark Burnett observa em seu site que os dumps de senha são preocupantemente frequentes. 12 Afinal, rastreando novos despejos foi como ele compilou o conjunto de dados de 10 milhões de senhas. Os outros eventos que parecem estar chegando às manchetes com cada vez mais frequência são hacks de celebridades e corporações. Jennifer Lawrence et ai. e Sony imediatamente vêm à mente. Estávamos curiosos sobre como os dados do Gmail poderiam ser usados para determinar quais pessoas de alto perfil foram afetadas por esse despejo em particular. Em outras palavras, cujas senhas foram publicadas? Fizemos isso usando a API Person do Full Contact, que pega uma lista de endereços de e-mail e os executa por meio das APIs de vários sites de redes sociais importantes, como Twitter, LinkedIn e Google+. Em seguida, ele fornece novos pontos de dados para qualquer um que encontrar, como idade, sexo e ocupação. 13
Já sabíamos que algumas pessoas de alto perfil estavam no despejo do Gmail. Por exemplo, o Mashable observou um mês depois que a lista foi divulgada que um de seus repórteres foi incluído (a senha listada para ele era sua senha do Gmail, mas há vários anos e não está mais em uso). 14 Mas não achávamos que a Full Contact apareceria muito mais.
Dentro das 78.000 correspondências que encontramos, havia centenas de pessoas de alto perfil. Selecionamos cerca de 40 dos mais notáveis abaixo. Alguns pontos muito importantes:
1. Nós deliberadamente não identificamos ninguém pelo nome.
2. Os logotipos da empresa representam as organizações para as quais os indivíduos trabalham agora e não necessariamente quando estavam usando a senha listada para eles.
3. Não há como saber onde as senhas foram usadas originalmente. Podem ter sido senhas pessoais do Gmail, mas é mais provável que tenham sido usadas em outros sites como o File Dropper. Portanto, é possível que muitas das senhas fracas não sejam representativas das senhas que os indivíduos usam atualmente no trabalho ou em qualquer outro lugar.
4. O Google confirmou que, quando a lista foi publicada, menos de 2% (100.000) das senhas poderiam ter funcionado com os endereços do Gmail com os quais estavam pareadas. E todos os titulares de contas afetados foram obrigados a redefinir suas senhas. Em outras palavras, as senhas abaixo – embora ainda educacionais – não estão mais em uso. Em vez disso, eles foram substituídos por outras combinações, esperançosamente mais seguras.
Se as senhas não tivessem sido redefinidas, no entanto, a situação seria mais preocupante. Vários estudos mostraram que muitos de nós usam as mesmas senhas para vários serviços. 15 E dado que a lista abaixo inclui alguns CEOs, muitos jornalistas e alguém muito alto na empresa de gestão de talentos de Justin Bieber e Ariana Grande, esse despejo poderia ter causado muito caos. Felizmente isso não aconteceu, e agora não pode.

A coisa mais notável sobre as senhas acima é quantas delas seriam muito fáceis de adivinhar se um processo de cracking offline fosse usado contra elas. O mais forte do grupo já pertenceu a um desenvolvedor do GitHub ( ns8vfpobzmx098bf4coj ) e, com uma entropia de 96, parece quase aleatório demais. Provavelmente foi criado por um gerador de senhas aleatório ou gerenciador de senhas. O mais fraco pertencia a um gerente sênior da IBM ( 123456 ), que - por outro lado - parece tão básico que certamente foi usado para uma inscrição descartável em algum lugar. Muitos dos outros encontram um equilíbrio suficiente entre complexidade e simplicidade para sugerir que seus proprietários se preocupavam em torná-los seguros e queriam proteger as contas para as quais foram escolhidos.
Alguns destaques interessantes para terminar: o chefe de divisão do Departamento de Estado dos EUA cuja senha (mas não o nome) era linco1n (Lincoln) e o escritor do Huffington Post que seguiu os passos de Mulder (dos Arquivos X) e escolheu trustno1 . E de forma mais geral, é interessante ver quantas das pessoas de alto perfil que selecionamos fizeram exatamente o que muitos de nós fazemos: combinar nossos nomes, datas de nascimento, palavras simples e alguns números para tornar senhas. Nós achamos que faz sentido embora. Até o presidente Obama admitiu recentemente que já usou a senha 1234567 . Uma senha com uma pontuação de entropia muito maior teria sido PoTuS.1776 . Embora, para um cracker inteligente, isso possa ter sido um pouco óbvio.
***
E as suas próprias senhas? Ao ler este post, você provavelmente pensou em si mesmo e se perguntou: “Alguém poderia adivinhar a senha do meu banco online, e-mail ou blog?” Se você usa um dos grandes provedores de e-mail, como o Gmail, não precisa se preocupar muito com a descoberta de sua senha por meio de um ataque de força bruta. O Gmail elimina tentativas ilegítimas quase imediatamente. Seu banco on-line provavelmente está protegido da mesma forma. No entanto, se você tem um blog, a situação é mais complicada porque, em termos simples, há mais maneiras potenciais de um invasor encontrar uma maneira de entrar, portanto, cada uma deve ser protegida proativamente para mantê-los afastados. O ponto é nunca tomar a segurança da senha como garantida e criar um sistema fácil, mas ainda difícil de descobrir, para criar uma senha segura.
A equipe do WP Engine gasta muito tempo e esforço contínuo para manter os sites WordPress de nossos clientes seguros. Nossa plataforma segura de hospedagem WordPress se integra ao próprio WordPress e protege os sites de nossos clientes contra ataques de força bruta em suas senhas com um software inteligente e reativo que aprende e se adapta constantemente às ameaças e toma medidas. Também protegemos nossos clientes contra ataques que não têm nada a ver com adivinhação de senha, como sniffing de tentativas de login e injeções de SQL. O WP Engine fornece a melhor plataforma de hospedagem WordPress gerenciada, capacitando marcas e empresas a alcançar públicos globais com a tecnologia WordPress.
Baixe nosso white paper de segurança do WordPress e conheça as 10 melhores práticas para proteger uma implantação do WordPress, incluindo como gerar, armazenar e alterar senhas regularmente com segurança.
Referências
1. http://www.dailydot.com/crime/google-gmail-5-million-passwords-leaked/
2. http://www.eweek.com/blogs/security-watch/wordpress-resets-100000-passwords-after-google-account-leak.html
3. https://xato.net/passwords/ten-million-passwords
4. https://xato.net/passwords/ten-million-passwords-faq/
5. http://groups.csail.mit.edu/uid/deneme/?p=628
6. http://micro.magnet.fsu.edu/creatures/pages/random.html
7. http://www.dailymail.co.uk/news/article-2601281/Why-lucky-7-really-magic-number.html
8. https://blogs.dropbox.com/tech/2012/04/zxcvbn-realistic-password-strength-estimation/
9. http://digi.ninja/projects/passpat.php
10. https://github.com/Rich5/Keyboard-Walk-Generators
11. http://www.thestar.com/news/gta/2015/02/13/is-there-love-in-your-online-passwords.html
12. https://xato.net/passwords/understanding-password-dumps
13. https://www.fullcontact.com/developer/person-api/
14. http://mashable.com/2014/09/10/5-million-gmail-passwords-leak/
15. http://www.jbonneau.com/doc/DBCBW14-NDSS-tangled_web.pdf