
Robots.txt: o que é e como criá-lo (guia completo)
Publicados: 2023-05-05Se você possui um site ou gerencia seu conteúdo, provavelmente já ouviu falar do robots.txt. É um arquivo que instrui os robôs do mecanismo de pesquisa sobre como rastrear e indexar as páginas do seu site. Apesar de sua importância na otimização de mecanismo de busca (SEO), muitos proprietários de sites ignoram a importância de um arquivo robots.txt bem projetado.
Neste guia completo, exploraremos o que é o robots.txt, por que ele é importante para o SEO e como criar um arquivo robots.txt para o seu site.
O que é o arquivo Robots.txt?
Um robots.txt é um arquivo que informa aos robôs do mecanismo de pesquisa (também conhecidos como rastreadores ou aranhas) quais páginas ou seções de um site devem ser rastreadas ou não. É um arquivo de texto simples localizado no diretório raiz de um site e normalmente inclui uma lista de diretórios, arquivos ou URLs que o webmaster deseja bloquear da indexação ou rastreamento do mecanismo de pesquisa.
É assim que um arquivo robots.txt se parece:

Por que o Robots.txt é importante?
Existem três razões principais pelas quais o robots.txt é importante para o seu site:
1. Maximize o orçamento de rastreamento
“Orçamento de rastreamento” representa o número de páginas que o Google rastreará em seu site a qualquer momento. O número depende do tamanho, saúde e quantidade de backlinks em seu site.
O orçamento de rastreamento é importante porque se o número de páginas em seu site ultrapassar o orçamento de rastreamento, você terá páginas que não são indexadas.
Além disso, as páginas que não são indexadas não serão classificadas para nada.
Ao usar o robots.txt para bloquear páginas inúteis, o Googlebot (rastreador da Web do Google) pode gastar mais de seu orçamento de rastreamento em páginas importantes.
2. Bloquear páginas não públicas
Você tem muitas páginas em seu site que não deseja indexar.
Por exemplo, você pode ter uma página interna de resultados de pesquisa ou uma página de login. Essas páginas precisam existir. No entanto, você não quer que pessoas aleatórias caiam sobre eles.
Nesse caso, você usaria robots.txt para impedir que rastreadores e bots de mecanismos de pesquisa acessem determinadas páginas.
3. Impedir a indexação de recursos
Às vezes, você deseja que o Google exclua recursos como PDFs, vídeos e imagens dos resultados da pesquisa.
Possivelmente você deseja manter esses recursos privados ou deseja que o Google se concentre mais em conteúdo importante.
Nesses casos, usar robots.txt é a melhor abordagem para evitar que sejam indexados.
Como funciona um arquivo Robots.txt?
Os arquivos robots.txt instruem os bots dos mecanismos de pesquisa sobre quais páginas ou diretórios do site eles devem ou não rastrear ou indexar.
Durante o rastreamento, os bots dos mecanismos de pesquisa encontram e seguem os links. Esse processo os leva do site X ao site Y ao site Z por meio de bilhões de links e sites.
Quando um bot visita um site, a primeira coisa que faz é procurar um arquivo robots.txt.
Se detectar um, ele lerá o arquivo antes de fazer qualquer outra coisa.
Por exemplo, suponha que você queira permitir que todos os bots, exceto DuckDuckGo, rastreiem seu site:
User-agent: DuckDuckBot Disallow: /
Observação: um arquivo robots.txt pode fornecer apenas instruções; não pode impô-los. É semelhante a um código de conduta. Bots bons (como bots de mecanismos de pesquisa) seguirão as regras, enquanto bots ruins (como bots de spam) irão ignorá-las.
Como encontrar um arquivo Robots.txt?
O arquivo robots.txt, como qualquer outro arquivo em seu site, está hospedado em seu servidor.
Você pode acessar o arquivo robots.txt de qualquer site inserindo o URL completo da página inicial e adicionando /robots.txt no final, como https://pickupwp.com/robots.txt.
No entanto, se o site não tiver um arquivo robots.txt, você receberá uma mensagem de erro “404 Not Found”.
Como criar um arquivo Robots.txt?
Antes de mostrar como criar um arquivo robots.txt, vejamos primeiro a sintaxe do robots.txt.
A sintaxe de um arquivo robots.txt pode ser dividida nos seguintes componentes:
- User-agent: especifica o robô ou rastreador ao qual o registro se aplica. Por exemplo, “User-agent: Googlebot” se aplicaria apenas ao rastreador de pesquisa do Google, enquanto “User-agent: *” se aplicaria a todos os rastreadores.
- Não permitir: especifica as páginas ou diretórios que o robô não deve rastrear. Por exemplo, “Disallow: /private/” impediria que os robôs rastreassem qualquer página dentro do diretório “private”.
- Permitir: especifica as páginas ou diretórios que o robô deve ter permissão para rastrear, mesmo que o diretório pai não seja permitido. Por exemplo, “Permitir: /público/” permite que os robôs rastreiem qualquer página dentro do diretório “público”, mesmo que o diretório pai não seja permitido.
- Atraso no rastreamento: especifica a quantidade de tempo em segundos que o robô deve esperar antes de rastrear o site. Por exemplo, “Crawl-delay: 10” instruiria o robô a aguardar 10 segundos antes de rastrear o site.
- Mapa do site: especifica a localização do mapa do site do site. Por exemplo, “Sitemap: https://www.example.com/sitemap.xml” informaria ao robô a localização do sitemap do site.
Aqui está um exemplo de um arquivo robots.txt:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
Observação: é importante observar que os arquivos robots.txt diferenciam maiúsculas de minúsculas, por isso é importante usar as maiúsculas e minúsculas corretas ao especificar URLs.
Por exemplo, /public/ não é o mesmo que /Public/.
Por outro lado, diretivas como “Permitir” e “Proibir” não diferenciam maiúsculas de minúsculas, então cabe a você capitalizá-las ou não.
Depois de aprender sobre a sintaxe do robots.txt, você pode criar um arquivo robots.txt usando uma ferramenta geradora de robots.txt ou criar um você mesmo.
Veja como criar um arquivo robots.txt em apenas quatro etapas:
1. Crie um novo arquivo e nomeie-o como Robots.txt
Basta abrir um documento .txt com qualquer editor de texto ou navegador da web.
Em seguida, dê ao documento o nome robots.txt. Para funcionar, ele deve ser nomeado robots.txt.
Uma vez feito isso, agora você pode começar a digitar diretivas.
2. Adicione Diretivas ao Arquivo Robots.txt
Um arquivo robots.txt contém um ou mais grupos de diretivas, cada um com várias linhas de instruções.
Cada grupo começa com um “User-agent” e contém os seguintes dados:
- A quem o grupo se aplica (o agente do usuário)
- Quais diretórios (páginas) ou arquivos o agente pode acessar?
- Quais diretórios (páginas) ou arquivos o agente não pode acessar?
- Um mapa do site (opcional) para informar os mecanismos de pesquisa sobre os sites e arquivos que você acredita serem importantes.
As linhas que não correspondem a nenhuma dessas diretivas são ignoradas pelos crawlers.

Por exemplo, você deseja impedir que o Google rastreie seu diretório /private/.
Ficaria assim:
User-agent: Googlebot Disallow: /private/
Se você tivesse mais instruções como esta para o Google, você as colocaria em uma linha separada logo abaixo, assim:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
Além disso, se você concluiu as instruções específicas do Google e deseja criar um novo grupo de diretivas.
Por exemplo, se você quiser impedir que todos os mecanismos de pesquisa rastreiem seus diretórios /archive/ e /support/.
Ficaria assim:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
Quando terminar, você pode adicionar seu sitemap.
Seu arquivo robots.txt completo deve ficar assim:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
Em seguida, salve seu arquivo robots.txt. Lembre-se, ele deve ser nomeado robots.txt.
Para regras de robots.txt mais úteis, confira este guia útil do Google.
3. Carregue o arquivo Robots.txt
Depois de salvar o arquivo robots.txt em seu computador, carregue-o em seu site e disponibilize-o para que os mecanismos de pesquisa o rastreiem.
Infelizmente, não há nenhuma ferramenta que possa ajudar nessa etapa.
O upload do arquivo robots.txt depende da estrutura de arquivos do seu site e da hospedagem na web.
Para obter instruções sobre como carregar seu arquivo robots.txt, pesquise on-line ou entre em contato com seu provedor de hospedagem.
4. Teste seu arquivo Robots.txt
Depois de fazer o upload do arquivo robots.txt, você pode verificar se alguém pode vê-lo e se o Google pode lê-lo.
Basta abrir uma nova guia em seu navegador e procurar seu arquivo robots.txt.
Por exemplo, https://pickupwp.com/robots.txt.
Se você vir seu arquivo robots.txt, está pronto para testar a marcação (código HTML).
Para isso, você pode usar um testador de robots.txt do Google.
Observação: você tem uma conta do Search Console configurada para testar seu arquivo robots.txt usando o robots.txt Tester.
O testador do robots.txt encontrará quaisquer avisos de sintaxe ou erros de lógica e os destacará.
Além disso, também mostra os avisos e erros abaixo do editor.
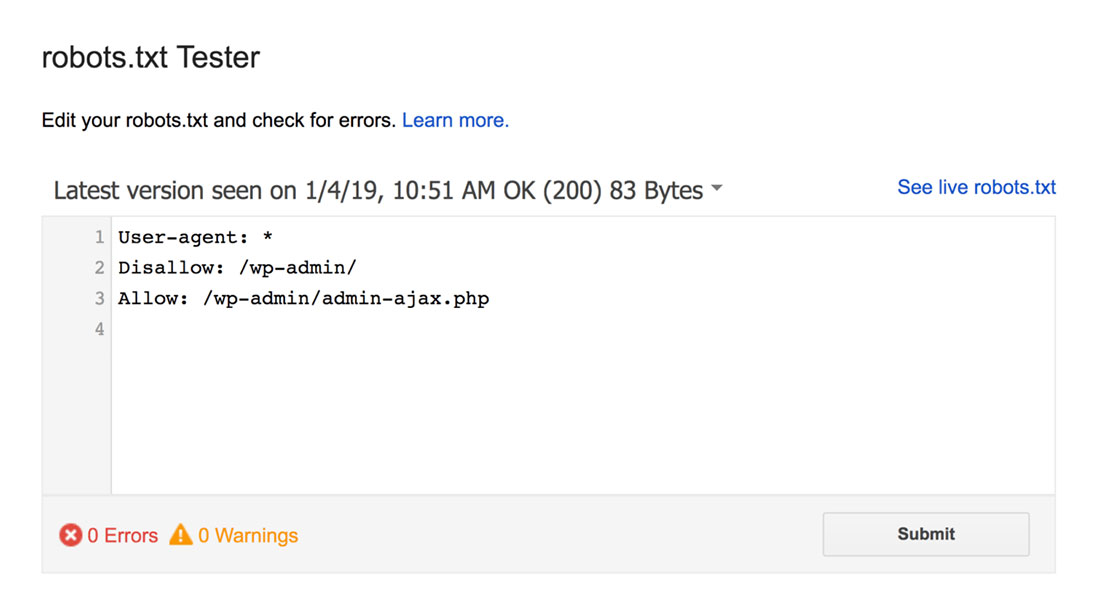
Você pode editar erros ou avisos na página e testar novamente quantas vezes for necessário.
Lembre-se de que as alterações feitas na página não são salvas em seu site.
Para fazer alterações, copie e cole no arquivo robots.txt do seu site.
Práticas recomendadas de robots.txt
Lembre-se dessas práticas recomendadas ao criar seu arquivo robots.txt para evitar alguns erros comuns.
1. Use novas linhas para cada diretiva
Para evitar confusão para os rastreadores do mecanismo de pesquisa, adicione cada diretiva a uma nova linha em seu arquivo robots.txt. Isso se aplica às regras Permitir e Proibir.
Por exemplo, se você não deseja que um rastreador da Web rastreie seu blog ou página de contato, adicione as seguintes regras:
Disallow: /blog/ Disallow: /contact/
2. Use cada agente de usuário apenas uma vez
Os bots não têm nenhum problema se você usar o mesmo agente de usuário repetidamente.
No entanto, usá-lo apenas uma vez mantém as coisas organizadas e reduz a chance de erro humano.
3. Use curingas para simplificar as instruções
Se você tiver um grande número de páginas para bloquear, adicionar uma regra para cada uma pode ser demorado. Felizmente, você pode usar curingas para simplificar suas instruções.
Um curinga é um caractere que pode representar um ou mais caracteres. O curinga mais comumente usado é o asterisco (*).
Por exemplo, se você deseja bloquear todos os arquivos que terminam em .jpg, adicione a seguinte regra:
Disallow: /*.jpg
4. Use “$” para especificar o final de uma URL
O cifrão ($) é outro curinga que pode ser usado para identificar o final de uma URL. Isso é útil se você deseja restringir uma página específica, mas não as seguintes.
Suponha que você queira bloquear a página de contato, mas não a página de sucesso do contato, adicione a seguinte regra:
Disallow: /contact$
5. Use o Hash (#) para adicionar comentários
Tudo o que começa com um hash (#) é ignorado pelos crawlers.
Como resultado, os desenvolvedores costumam usar o hash para adicionar comentários ao arquivo robots.txt. Ele mantém o documento organizado e legível.
Por exemplo, se você quiser evitar que todos os arquivos terminem com .jpg, você pode adicionar o seguinte comentário:
# Block all files that end in .jpg Disallow: /*.jpg
Isso ajuda qualquer pessoa a entender para que serve a regra e por que ela existe.
6. Use arquivos Robots.txt separados para cada subdomínio
Se você tiver um site com vários subdomínios, é recomendável criar um arquivo robots.txt individual para cada um. Isso mantém as coisas organizadas e ajuda os rastreadores dos mecanismos de pesquisa a entender suas regras com mais facilidade.
Empacotando!
O arquivo robots.txt é uma ferramenta de SEO útil, pois instrui os bots dos mecanismos de pesquisa sobre o que indexar e o que não indexar.
No entanto, é importante usá-lo com cautela. Uma vez que uma configuração incorreta pode resultar na desindexação completa do seu site (por exemplo, usando Disallow: /).
Geralmente, a boa maneira é permitir que os mecanismos de pesquisa verifiquem o máximo possível do seu site, mantendo informações confidenciais e evitando conteúdo duplicado. Por exemplo, você pode usar a diretiva Disallow para impedir páginas ou diretórios específicos ou a diretiva Allow para substituir uma regra de proibição para uma página específica.
Também vale a pena mencionar que nem todos os bots seguem as regras fornecidas no arquivo robots.txt, portanto, não é um método perfeito para controlar o que é indexado. Mas ainda é uma ferramenta valiosa para sua estratégia de SEO.
Esperamos que este guia ajude você a aprender o que é um arquivo robots.txt e como criá-lo.
Para saber mais, você pode conferir estes outros recursos úteis:
- 15 dicas de blog acionáveis para novos blogueiros
- Desbloqueando o poder das palavras-chave de cauda longa (guia para iniciantes)
Por fim, siga-nos no Twitter para atualizações regulares sobre novos artigos.