
O arquivo robots.txt do WordPress… O que é e o que faz
Publicados: 2020-11-25Você já se perguntou o que é o arquivo robots.txt e o que ele faz? Robots.txt é usado para se comunicar com os rastreadores da web (conhecidos como bots) usados pelo Google e outros mecanismos de pesquisa. Ele informa quais partes do seu site devem ser indexadas e quais devem ser ignoradas. Como tal, o arquivo robots.txt pode ajudar a fazer (ou potencialmente quebrar!) seus esforços de SEO. Se você deseja que seu site tenha uma boa classificação, é essencial ter uma boa compreensão do robots.txt!
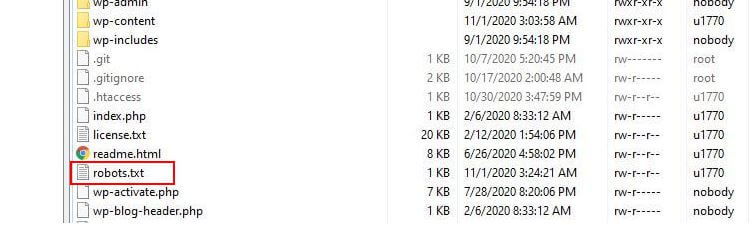
Onde está localizado o Robots.txt?
O WordPress normalmente executa o chamado arquivo robots.txt 'virtual', o que significa que não é acessível via SFTP. No entanto, você pode visualizar seu conteúdo básico acessando seudomínio.com/robots.txt. Você provavelmente verá algo assim:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpA primeira linha especifica em quais bots as regras serão aplicadas. Em nosso exemplo, o asterisco significa que as regras serão aplicadas a todos os bots (por exemplo, os do Google, Bing e assim por diante).
A segunda linha define uma regra que impede o acesso de bots à pasta /wp-admin e a terceira linha afirma que os bots têm permissão para analisar o arquivo /wp-admin/admin-ajax.php.
Adicione suas próprias regras
Para um site WordPress simples, as regras padrão aplicadas pelo WordPress ao arquivo robots.txt podem ser mais do que adequadas. Se, no entanto, você quiser mais controle e a capacidade de adicionar suas próprias regras para fornecer instruções mais específicas aos bots de mecanismos de pesquisa sobre como indexar seu site, será necessário criar seu próprio arquivo robots.txt físico e colocá-lo na raiz diretório de sua instalação.
Há vários motivos que podem querer reconfigurar seu arquivo robots.txt e definir o que exatamente esses bots terão permissão para rastrear. Um dos principais motivos é o tempo gasto por um bot rastreando seu site. O Google (e outros) não permite que os bots passem tempo ilimitado em todos os sites… com trilhões de páginas, eles precisam adotar uma abordagem mais sutil sobre o que seus bots rastrearão e o que ignorarão na tentativa de extrair as informações mais úteis sobre um site.

Hospede seu site com a Pressidium
GARANTIA DE DEVOLUÇÃO DO DINHEIRO DE 60 DIAS
Quando você permite que os bots rastreiem todas as páginas do seu site, uma parte do tempo de rastreamento é gasto em páginas que não são importantes ou mesmo relevantes. Isso os deixa com menos tempo para percorrer as áreas mais relevantes do seu site. Ao proibir o acesso de bots a algumas partes do seu site, você aumenta o tempo disponível para os bots extrairem informações das partes mais relevantes do seu site (que esperamos acabar indexadas). Como o rastreamento é mais rápido, é mais provável que o Google revisite seu site e mantenha o índice do seu site atualizado. Isso significa que novas postagens de blog e outros conteúdos novos provavelmente serão indexados mais rapidamente, o que é uma boa notícia.
Exemplos de edição de Robots.txt
O robots.txt oferece muito espaço para personalização. Como tal, fornecemos uma série de exemplos de regras que podem ser usadas para ditar como os bots indexam seu site.
Permitindo ou não bots
Primeiro, vamos ver como podemos restringir um bot específico. Para fazer isso, tudo o que precisamos fazer é substituir o asterisco (*) pelo nome do user-agent do bot que queremos bloquear, por exemplo 'MSNBot'. Uma lista abrangente de agentes de usuário conhecidos está disponível aqui.
User-agent: MSNBot Disallow: /Colocar um traço na segunda linha restringirá o acesso do bot a todos os diretórios.
Para permitir que apenas um único bot rastreie nosso site, usaríamos um processo de duas etapas. Primeiro, definimos este bot como uma exceção e, em seguida, desabilitamos todos os bots como este:
User-agent: Google Disallow: User-agent: * Disallow: /Para permitir o acesso a todos os bots em todo o conteúdo, adicionamos estas duas linhas:
User-agent: * Disallow:O mesmo efeito seria obtido simplesmente criando um arquivo robots.txt e deixando-o vazio.
Bloqueando o acesso a arquivos específicos
Deseja impedir que os bots indexem determinados arquivos em seu site? Isso é fácil! No exemplo abaixo, impedimos que os mecanismos de pesquisa acessassem todos os arquivos .pdf em nosso site.
User-agent: * Disallow: /*.pdf$O símbolo “$” é usado para definir o final da URL. Como isso diferencia maiúsculas de minúsculas, um arquivo com o nome my.PDF ainda será rastreado (observe o CAPS).
Expressões Lógicas Complexas
Alguns mecanismos de busca, como o Google, entendem o uso de expressões regulares mais complicadas. No entanto, é importante observar que nem todos os mecanismos de pesquisa podem entender expressões lógicas em robots.txt.

Um exemplo disso é usar o símbolo $. Em arquivos robots.txt este símbolo indica o fim de uma url. Portanto, no exemplo a seguir, bloqueamos os bots de pesquisa de ler e indexar arquivos que terminam com .php
Disallow: /*.php$Isso significa que /index.php não pode ser indexado, mas /index.php?p=1 poderia ser. Isso só é útil em circunstâncias muito específicas e precisa ser usado com cautela ou você corre o risco de bloquear o acesso do bot a arquivos que não pretendia!
Você também pode definir regras diferentes para cada bot especificando as regras que se aplicam a eles individualmente. O código de exemplo abaixo restringirá o acesso à pasta wp-admin para todos os bots e, ao mesmo tempo, bloqueará o acesso a todo o site para o mecanismo de pesquisa do Bing. Você não necessariamente gostaria de fazer isso, mas é uma demonstração útil de como as regras em um arquivo robots.txt podem ser flexíveis.
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /Mapas de site XML
Os sitemaps XML realmente ajudam os bots de pesquisa a entender o layout do seu site. Mas, para ser útil, o bot precisa saber onde o mapa do site está localizado. A 'diretiva de mapa do site' é usada para informar especificamente aos mecanismos de pesquisa que a) existe um mapa do site do seu site eb) onde eles podem encontrá-lo.
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:Você também pode especificar vários locais do mapa do site:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* DisallowAtrasos de rastreamento de bot
Outra função que pode ser alcançada através do arquivo robots.txt é dizer aos bots para 'retardar' o rastreamento do seu site. Isso pode ser necessário se você descobrir que seu servidor está sobrecarregado por altos níveis de tráfego de bot. Para fazer isso, você deve especificar o agente do usuário que deseja desacelerar e adicionar um atraso.
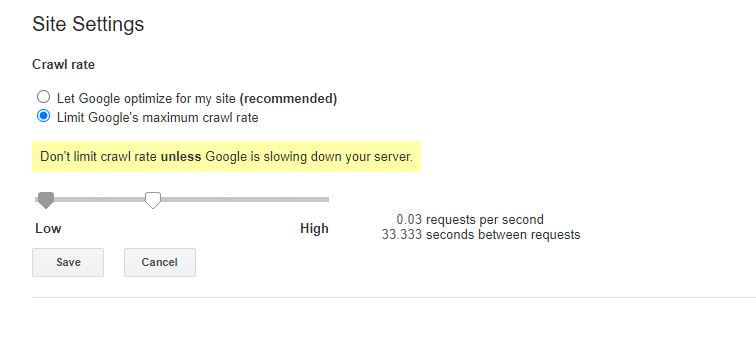
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10As aspas numéricas (10) neste exemplo são o atraso que você deseja que ocorra entre o rastreamento de páginas individuais em seu site. Portanto, no exemplo acima, pedimos ao Bing Bot para pausar por dez segundos entre cada página rastreada e, ao fazer isso, dar ao nosso servidor um pouco de espaço para respirar.
A única notícia um pouco ruim sobre essa regra específica do robots.txt é que o bot do Google não a respeita. No entanto, você pode instruir seus bots a desacelerar no Google Search Console.
Observações sobre as regras do robots.txt:
- Todas as regras do robots.txt diferenciam maiúsculas de minúsculas. Digite com cuidado!
- Certifique-se de que não existam espaços antes do comando no início da linha.
- As alterações feitas no robots.txt podem levar de 24 a 36 horas para serem notadas pelos bots.
Como testar e enviar seu arquivo robots.txt do WordPress
Quando você tiver criado um novo arquivo robots.txt, vale a pena verificar se não há erros nele. Você pode fazer isso usando o Google Search Console.
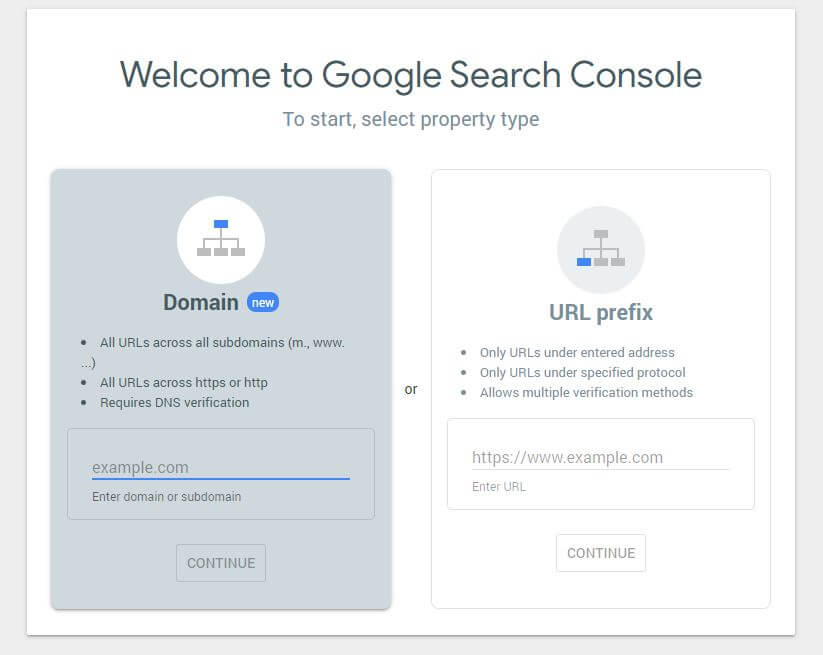
Primeiro, você terá que enviar seu domínio (se ainda não tiver uma conta do Search Console para a configuração do seu site). O Google fornecerá a você um registro TXT que precisa ser adicionado ao seu DNS para verificar seu domínio.
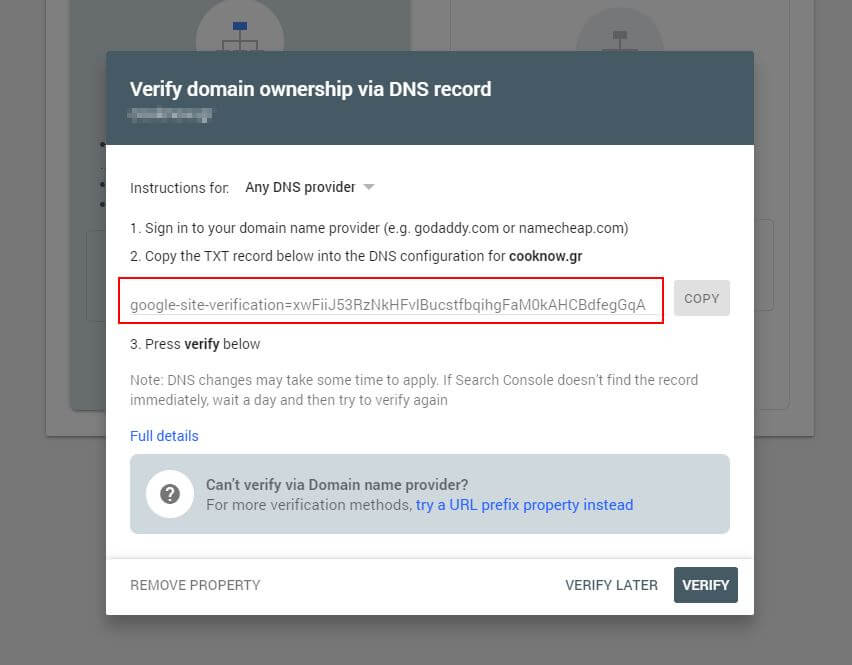
Assim que esta atualização de DNS for propagada (sentindo-se impaciente... tente usar a Cloudflare para gerenciar seu DNS), você pode visitar o testador robots.txt e verificar se há algum aviso sobre o conteúdo do seu arquivo robots.txt.
Outra coisa que você pode fazer para testar se as regras que você tem estão surtindo o efeito desejado é usar uma ferramenta de teste robots.txt como o Ryte.
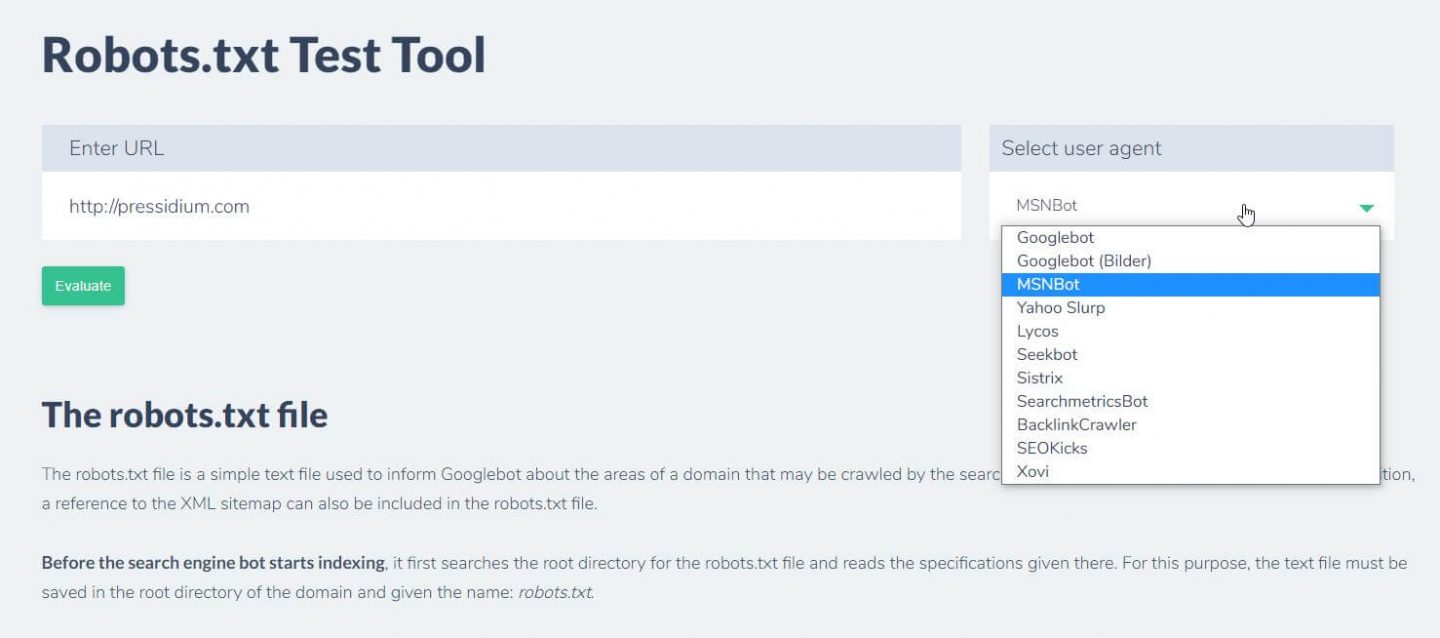
Basta digitar seu domínio e escolher um agente de usuário no painel à direita. Depois de enviar isso, você verá seus resultados.
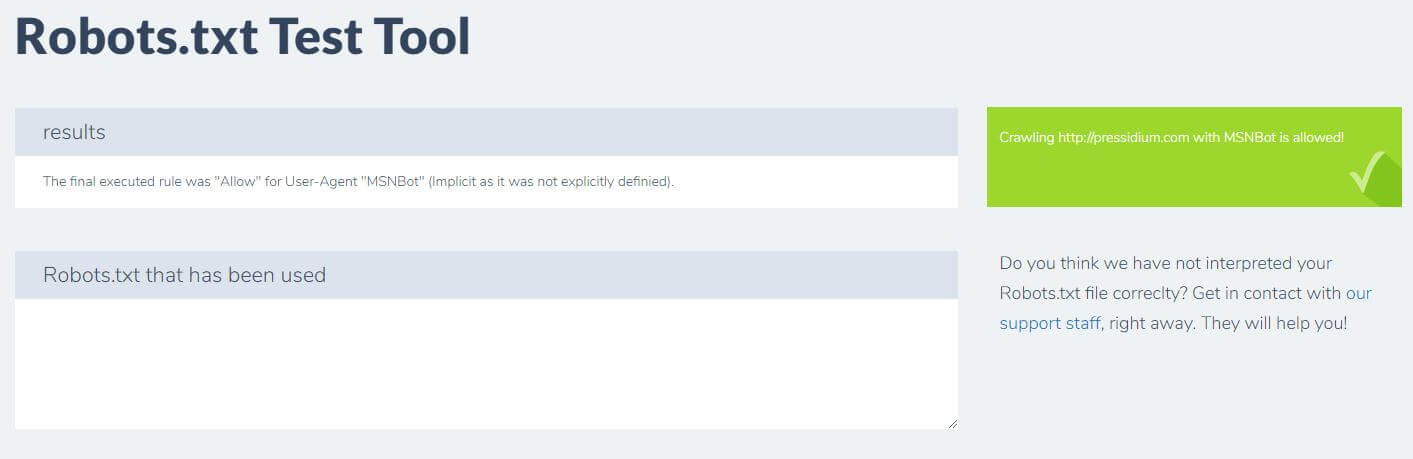
Conclusão
Saber usar o robots.txt é outra ferramenta útil no kit de ferramentas do seu desenvolvedor. Se a única coisa que você tira deste tutorial é a capacidade de verificar se o seu arquivo robots.txt não está bloqueando bots como o Google (o que você provavelmente não gostaria de fazer), então isso não é ruim! Da mesma forma, como você pode ver, o robots.txt oferece uma série de controles mais refinados sobre o seu site que um dia podem ser úteis.