
Construiți un set robust de replică MongoDB într-un timp record (4 metode)
Publicat: 2023-03-11MongoDB este o bază de date NoSQL care utilizează documente asemănătoare JSON cu scheme dinamice. Când lucrați cu baze de date, este întotdeauna bine să aveți un plan de urgență în cazul în care unul dintre serverele dvs. de baze de date eșuează. Bara laterală, puteți reduce șansele ca acest lucru să se întâmple utilizând un instrument de management ingenios pentru site-ul dvs. WordPress.
Acesta este motivul pentru care este util să aveți multe copii ale datelor dvs. De asemenea, reduce latența de citire. În același timp, poate îmbunătăți scalabilitatea și disponibilitatea bazei de date. Aici intervine replicarea. Este definită ca practica de sincronizare a datelor în mai multe baze de date.
În acest articol, ne vom scufunda în diferitele aspecte importante ale replicării MongoDB, cum ar fi caracteristicile și mecanismul acesteia, pentru a numi câteva.
Ce este replicarea în MongoDB?
În MongoDB, seturile de replici efectuează replicarea. Acesta este un grup de servere care mențin același set de date prin replicare. Puteți chiar să utilizați replicarea MongoDB ca parte a echilibrării încărcării. Aici, puteți distribui operațiunile de scriere și citire în toate instanțele, pe baza cazului de utilizare.
Ce este un set de replica MongoDB?
Fiecare instanță a MongoDB care face parte dintr-un anumit set de replică este membru. Fiecare set de replică trebuie să aibă un membru principal și cel puțin un membru secundar.
Membrul principal este punctul de acces principal pentru tranzacțiile cu setul de replică. De asemenea, este singurul membru care poate accepta operațiuni de scriere. Replicarea copiază mai întâi oplog-ul primarului (jurnalul de operațiuni). Apoi, repetă modificările înregistrate pe seturile de date respective ale secundare. Prin urmare, fiecare set de replică poate avea doar un membru principal la un moment dat. Diverse primare care primesc operațiuni de scriere pot provoca conflicte de date.
De obicei, aplicațiile interoghează doar membrul principal pentru operațiuni de scriere și citire. Vă puteți proiecta configurația pentru a citi de la unul sau mai mulți membri secundari. Transferul asincron de date poate face ca citirile nodurilor secundare să servească date vechi. Astfel, un astfel de aranjament nu este ideal pentru fiecare caz de utilizare.
Caracteristici ale setului de replică
Mecanismul de failover automată deosebește seturile de replică MongoDB de concurența sa. În absența unui primar, o alegere automată între nodurile secundare alege un nou primar.
MongoDB Replica Set vs MongoDB Cluster
Un set de replici MongoDB va crea diferite copii ale aceluiași set de date în nodurile setului de replici. Scopul principal al unui set de replici este:
- Oferiți o soluție de rezervă încorporată
- Creșteți disponibilitatea datelor
Un cluster MongoDB este un joc cu minge cu totul diferit. Distribuie datele pe mai multe noduri printr-o cheie shard. Acest proces va fragmenta datele în multe bucăți numite cioburi. Apoi, copiază fiecare fragment într-un alt nod. Un cluster își propune să susțină seturi mari de date și operațiuni de mare debit. Se realizează prin scalarea orizontală a volumului de lucru.
Iată diferența dintre un set de replică și un cluster, în termeni profani:
- Un cluster distribuie volumul de lucru. De asemenea, stochează fragmente de date (fragmente) pe mai multe servere.
- Un set de replică dublează complet setul de date.
MongoDB vă permite să combinați aceste funcționalități prin crearea unui cluster fragmentat. Aici, puteți replica fiecare fragment pe un server secundar. Acest lucru permite unui fragment să ofere o redundanță ridicată și disponibilitatea datelor.
Întreținerea și configurarea unui set de replică poate fi dificilă din punct de vedere tehnic și consumatoare de timp. Și găsiți serviciul de găzduire potrivit? Asta e cu totul altă durere de cap. Cu atât de multe opțiuni, este ușor să pierzi ore în șir cercetând, în loc să-ți construiești afacerea.
Permiteți-mi să vă ofer un scurt despre un instrument care face toate acestea și multe altele, astfel încât să puteți reveni la zdrobirea acestuia cu serviciul/produsul dumneavoastră.
Soluția de găzduire a aplicațiilor Kinsta, în care peste 55.000 de dezvoltatori au încredere, o puteți începe și rula în doar 3 pași simpli. Dacă acest lucru sună prea bine pentru a fi adevărat, iată câteva beneficii suplimentare ale utilizării Kinsta:
- Bucurați-vă de performanțe mai bune cu conexiunile interne Kinsta : Uitați-vă de luptele cu bazele de date partajate. Treceți la baze de date dedicate cu conexiuni interne care nu au limite de număr de interogări sau de rânduri. Kinsta este mai rapid, mai sigur și nu vă va factura pentru lățime de bandă/trafic intern.
- Un set de funcții adaptat dezvoltatorilor : scalați-vă aplicația pe platforma robustă care acceptă Gmail, YouTube și Căutarea Google. Fii sigur, ești în cele mai sigure mâini aici.
- Bucurați-vă de viteze de neegalat cu un centru de date la alegere : alegeți regiunea care funcționează cel mai bine pentru dvs. și clienții dvs. Cu peste 25 de centre de date din care să alegeți, cele peste 275 de PoP-uri Kinsta asigură viteză maximă și o prezență globală pentru site-ul dvs.
Încercați gratuit soluția de găzduire a aplicațiilor Kinsta astăzi!
Cum funcționează replicarea în MongoDB?
În MongoDB, trimiteți operațiuni de scriere către serverul principal (nodul). Primarul atribuie operațiunile pe serverele secundare, replicând datele.
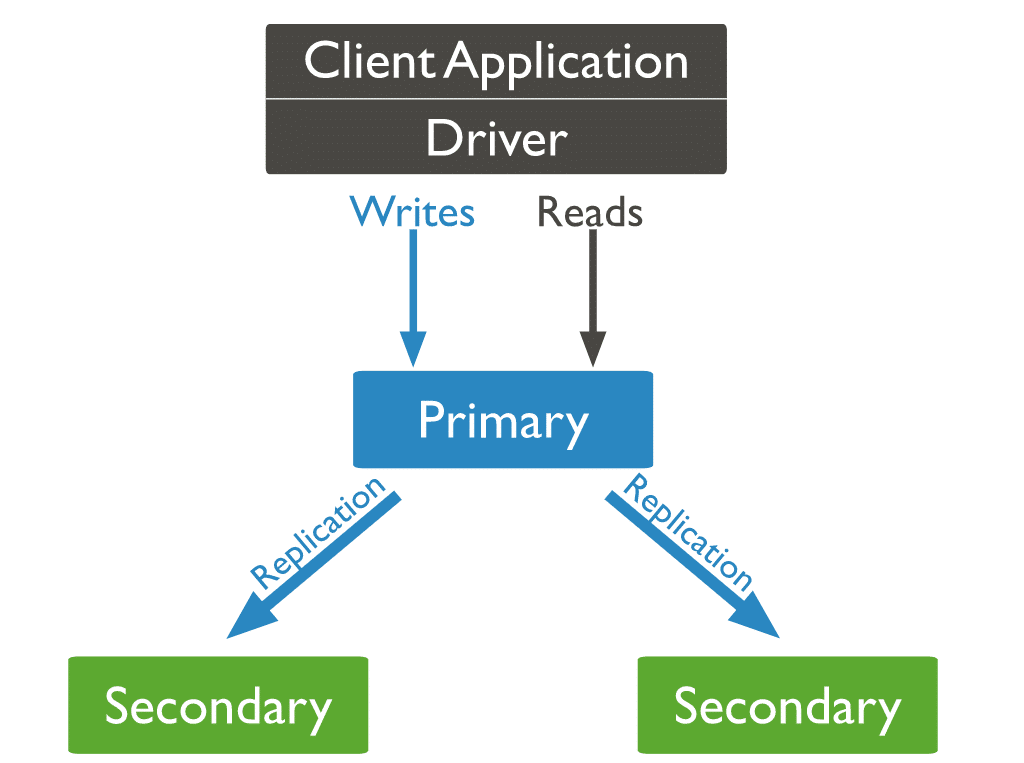
Trei tipuri de noduri MongoDB
Dintre cele trei tipuri de noduri MongoDB, două au mai apărut: noduri primare și secundare. Al treilea tip de nod MongoDB care este util în timpul replicării este un arbitru. Nodul de arbitru nu are o copie a setului de date și nu poate deveni principal. Acestea fiind spuse, arbitrul participă la alegerile pentru primare.
Am menționat anterior ce se întâmplă atunci când nodul primar scade, dar ce se întâmplă dacă nodurile secundare mușcă praful? În acest scenariu, nodul primar devine secundar, iar baza de date devine inaccesibilă.
Alegerea membrilor
Alegerile pot avea loc în următoarele scenarii:
- Inițializarea unui set de replici
- Pierderea conectivității la nodul primar (care poate fi detectată prin bătăile inimii)
- Întreținerea unui set de replici folosind metodele
rs.reconfigsaustepDown - Adăugarea unui nou nod la un set de replică existent
Un set de replică poate avea până la 50 de membri, dar doar 7 sau mai puțini pot vota la orice alegere.
Timpul mediu înainte ca un cluster să aleagă un nou primar nu ar trebui să depășească 12 secunde. Algoritmul electoral va încerca să aibă disponibil secundarul cu cea mai mare prioritate. În același timp, membrii cu prioritate 0 nu pot deveni primari și nu participă la alegeri.
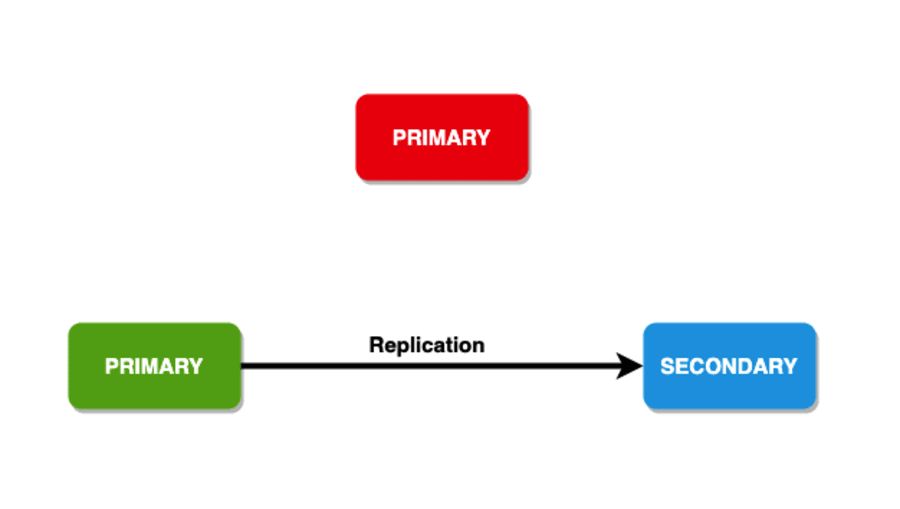
Preocuparea Scrierii
Pentru durabilitate, operațiunile de scriere au un cadru pentru a copia datele într-un număr specificat de noduri. Puteți chiar oferi feedback clientului cu aceasta. Acest cadru este cunoscut și sub numele de „preocuparea scrisului”. Are membri purtători de date care trebuie să recunoască o problemă de scriere înainte ca operațiunea să revină ca reușită. În general, seturile de replică au o valoare de 1 ca problemă de scriere. Astfel, doar primarul ar trebui să confirme scrierea înainte de a returna confirmarea preocupării de scriere.
Puteți chiar să creșteți numărul de membri necesari pentru a confirma operația de scriere. Nu există plafon pentru numărul de membri pe care îi puteți avea. Dar, dacă cifrele sunt mari, trebuie să faci față unei latențe mari. Acest lucru se datorează faptului că clientul trebuie să aștepte confirmarea tuturor membrilor. De asemenea, puteți seta preocuparea de scriere a „majorității”. Acest lucru calculează mai mult de jumătate dintre membri după ce au primit confirmarea lor.
Citiți Preferința
Pentru operațiunile de citire, puteți menționa preferința de citire care descrie modul în care baza de date direcționează interogarea către membrii setului de replici. În general, nodul primar primește operația de citire, dar clientul poate menționa o preferință de citire pentru a trimite operațiunile de citire către nodurile secundare. Iată opțiunile pentru preferința de citire:
- primaryPreferred : De obicei, operațiunile de citire provin de la nodul primar, dar dacă acesta nu este disponibil, datele sunt extrase de la nodurile secundare.
- primar : Toate operațiunile de citire provin de la nodul primar.
- secundar : Toate operațiunile de citire sunt executate de nodurile secundare.
- cel mai apropiat : aici, cererile de citire sunt direcționate către cel mai apropiat nod accesibil, care poate fi detectat prin rularea comenzii
ping. Rezultatul operațiunilor de citire poate veni de la orice membru al setului de replici, indiferent dacă este primar sau secundar. - secondaryPreferred : Aici, majoritatea operațiilor de citire provin de la nodurile secundare, dar dacă niciunul dintre ele nu este disponibil, datele sunt preluate de la nodul primar.
Sincronizarea datelor setului de replicare
Pentru a menține copii actualizate ale setului de date partajat, membrii secundari ai unui set de replică replic sau sincronizează datele de la alți membri.
MongoDB folosește două forme de sincronizare a datelor. Sincronizare inițială pentru a completa membri noi cu setul complet de date. Replicare pentru a executa modificări în curs la setul complet de date.
Sincronizare inițială
În timpul sincronizării inițiale, un nod secundar rulează comanda init sync pentru a sincroniza toate datele de la nodul primar la un alt nod secundar care conține cele mai recente date. Prin urmare, nodul secundar folosește în mod consecvent caracteristica tailable cursor pentru a interoga cele mai recente intrări oplog din colecția local.oplog.rs a nodului primar și aplică aceste operații în aceste intrări oplog.
Din MongoDB 5.2, sincronizările inițiale pot fi bazate pe copierea fișierelor sau logice.
Sincronizare logică
Când executați o sincronizare logică, MongoDB:
- Elaborează toți indexurile de colecție pe măsură ce documentele sunt copiate pentru fiecare colecție.
- Duplică toate bazele de date, cu excepția bazei de date locale.
mongodscanează fiecare colecție din toate bazele de date sursă și inserează toate datele în duplicatele sale ale acestor colecții. - Execută toate modificările setului de date. Utilizând oplog-ul de la sursă,
mongodul își actualizează setul de date pentru a descrie starea curentă a setului de replici. - Extrage înregistrările oplog nou adăugate în timpul copierii datelor. Asigurați-vă că membrul țintă are suficient spațiu pe disc în baza de date locală pentru a stoca provizoriu aceste înregistrări oplog pe durata acestei etape de copiere a datelor.
Când sincronizarea inițială este finalizată, membrul trece de la STARTUP2 la SECONDARY .
Sincronizare inițială pe bază de copiere a fișierelor
Din start, puteți executa acest lucru numai dacă utilizați MongoDB Enterprise. Acest proces rulează sincronizarea inițială prin duplicarea și mutarea fișierelor pe sistemul de fișiere. Această metodă de sincronizare poate fi mai rapidă decât sincronizarea inițială logică în unele cazuri. Rețineți că sincronizarea inițială bazată pe copie de fișiere poate duce la numărări inexacte dacă rulați metoda count() fără un predicat de interogare.
Dar, această metodă are și o parte echitabilă de limitări:
- În timpul unei sincronizări inițiale bazate pe copie de fișiere, nu puteți scrie în baza de date locală a membrului care este sincronizat. De asemenea, nu puteți executa o copie de rezervă pentru membrul cu care este sincronizat sau membrul cu care este sincronizat.
- Când folosește motorul de stocare criptat, MongoDB folosește cheia sursă pentru a cripta destinația.
- Puteți rula o sincronizare inițială doar de la un membru dat la un moment dat.
Replicare
Membrii secundari replică datele în mod constant după sincronizarea inițială. Membrii secundari vor duplica oplog-ul din sincronizarea lor de la sursă și vor executa aceste operațiuni într-un proces asincron.
Secundarii sunt capabili să-și modifice automat sincronizarea de la sursă, după cum este necesar, pe baza modificărilor timpului de ping și a stării replicării altor membri.
Replicare în flux
Din MongoDB 4.4, sincronizarea din surse trimite un flux continuu de intrări oplog către secundarele lor de sincronizare. Replicarea în flux reduce decalajul de replicare în rețelele cu încărcare mare și cu latență ridicată. Poate deasemenea:
- Reduceți riscul de a pierde operațiunile de scriere cu
w:1din cauza failoverului primar. - Reduceți oboseala pentru citirile din secundare.
- Reduceți latența la operațiile de scriere cu
w:“majority”șiw:>1. Pe scurt, orice preocupare de scris care trebuie să aștepte pentru replicare.
Replicare cu mai multe fire
MongoDB obișnuia să scrie operațiuni în loturi prin mai multe fire pentru a îmbunătăți concurența. MongoDB grupează loturile după id-ul documentului în timp ce aplică fiecare grup de operații cu un fir diferit.
MongoDB execută întotdeauna operațiuni de scriere pe un document dat în ordinea sa inițială de scriere. Acest lucru sa schimbat în MongoDB 4.0.
Din MongoDB 4.0, operațiunile de citire care vizează secundare și sunt configurate cu un nivel de preocupare de citire de “majority” sau “local” vor citi acum dintr-un instantaneu WiredTiger a datelor dacă citirea are loc pe un secundar în care sunt aplicate loturile de replicare. Citirea dintr-un instantaneu garantează o vizualizare consecventă a datelor și permite citirea să aibă loc simultan cu replicarea în curs, fără a necesita o blocare.
Prin urmare, citirile secundare care au nevoie de aceste niveluri de preocupare de citire nu mai trebuie să aștepte ca loturile de replicare să fie aplicate și pot fi gestionate pe măsură ce sunt primite.
Cum se creează un set de replică MongoDB
După cum sa menționat anterior, MongoDB gestionează replicarea prin seturi de replici. În următoarele câteva secțiuni, vom evidenția câteva metode pe care le puteți utiliza pentru a crea seturi de replică pentru cazul dvs. de utilizare.
Metoda 1: Crearea unui nou set de replică MongoDB pe Ubuntu
Înainte de a începe, va trebui să vă asigurați că aveți cel puțin trei servere care rulează Ubuntu 20.04, cu MongoDB instalat pe fiecare server.
Pentru a configura un set de replică, este esențial să furnizați o adresă la care fiecare membru al setului de replică să poată fi contactat de alții din set. În acest caz, păstrăm trei membri în set. Deși putem folosi adrese IP, nu este recomandat, deoarece adresele se pot schimba în mod neașteptat. O alternativă mai bună poate fi utilizarea numelor de gazdă DNS logice atunci când configurați seturi de replica.
Putem face acest lucru prin configurarea subdomeniului pentru fiecare membru de replicare. Deși acest lucru poate fi ideal pentru un mediu de producție, această secțiune va descrie cum să configurați rezoluția DNS prin editarea fișierelor gazdelor respective ale fiecărui server. Acest fișier ne permite să atribuim nume de gazdă care pot fi citite adreselor IP numerice. Astfel, dacă în orice caz adresa dvs. de IP se schimbă, tot ce trebuie să faceți este să actualizați fișierele gazdelor de pe cele trei servere, mai degrabă decât să reconfigurați replica setată de la zero!
În mare parte, hosts sunt stocate în directorul /etc/ . Repetați comenzile de mai jos pentru fiecare dintre cele trei servere:
sudo nano /etc/hostsÎn comanda de mai sus, folosim nano ca editor de text, cu toate acestea, puteți folosi orice editor de text pe care îl preferați. După primele câteva rânduri care configurează localhost, adăugați o intrare pentru fiecare membru al setului de replici. Aceste intrări iau forma unei adrese IP urmate de numele care poate fi citit de către om la alegere. Deși le puteți numi cum doriți, asigurați-vă că sunteți descriptiv, astfel încât să știți să faceți diferența între fiecare membru. Pentru acest tutorial, vom folosi numele de gazdă de mai jos:
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
Folosind aceste nume de gazdă, fișierele dvs. /etc/hosts ar arăta similar cu următoarele linii evidențiate:

Salvați și închideți fișierul.
După configurarea rezoluției DNS pentru setul de replici, trebuie să actualizăm regulile firewall pentru a le permite să comunice între ele. Rulați următoarea comandă ufw pe mongo0 pentru a oferi acces mongo1 la portul 27017 pe mongo0:
sudo ufw allow from mongo1_server_ip to any port 27017 În locul parametrului mongo1_server_ip , introduceți adresa IP reală a serverului mongo1. De asemenea, dacă ați actualizat instanța Mongo de pe acest server pentru a utiliza un port care nu este implicit, asigurați-vă că schimbați 27017 pentru a reflecta portul pe care îl folosește instanța dvs. MongoDB.
Acum adăugați o altă regulă de firewall pentru a oferi mongo2 acces la același port:
sudo ufw allow from mongo2_server_ip to any port 27017 În locul parametrului mongo2_server_ip , introduceți adresa IP reală a serverului dvs. mongo2. Apoi, actualizați regulile paravanului de protecție pentru celelalte două servere. Rulați următoarele comenzi pe serverul mongo1, asigurându-vă că schimbați adresele IP în locul parametrului server_ip pentru a le reflecta pe cele ale mongo0 și, respectiv, mongo2:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017În cele din urmă, rulați aceste două comenzi pe mongo2. Din nou, asigurați-vă că introduceți adresele IP corecte pentru fiecare server:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017Următorul pas este să actualizați fișierul de configurare al fiecărei instanțe MongoDB pentru a permite conexiuni externe. Pentru a permite acest lucru, trebuie să modificați fișierul de configurare din fiecare server pentru a reflecta adresa IP și a indica setul de replică. Deși puteți folosi orice editor de text preferat, folosim din nou editorul de text nano. Să facem următoarele modificări în fiecare fișier mongod.conf.
Pe mongo0:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"Pe mongo1:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"Pe mongo2:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodCu aceasta, ați activat replicarea pentru fiecare instanță MongoDB a serverului.
Acum puteți inițializa setul de replici folosind metoda rs.initiate() . Această metodă este necesară doar pentru a fi executată pe o singură instanță MongoDB din setul de replică. Asigurați-vă că numele și membrul setului de replică se potrivesc cu configurațiile pe care le-ați făcut anterior în fiecare fișier de configurare.
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })Dacă metoda returnează „ok”: 1 în rezultat, înseamnă că setul de replică a fost pornit corect. Mai jos este un exemplu despre cum ar trebui să arate rezultatul:
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }Închideți serverul MongoDB
Puteți închide un server MongoDB utilizând metoda db.shutdownServer() . Mai jos este sintaxa pentru același lucru. Atât force , cât și timeoutsecs sunt parametri opționali.
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) Această metodă poate eșua dacă membrul setului de replica mongod rulează anumite operațiuni pe măsură ce se construiește index. Pentru a întrerupe operațiunile și a forța membrul să se închidă, puteți introduce parametrul boolean force la true.
Reporniți MongoDB cu –replSet
Pentru a reseta configurația, asigurați-vă că fiecare nod din setul de replică este oprit. Apoi ștergeți baza de date locală pentru fiecare nod. Porniți-l din nou folosind indicatorul –replSet și rulați rs.initiate() pe o singură instanță mongod pentru setul de replici.
mongod --replSet "rs0" rs.initiate() poate lua un document opțional de configurare a setului de replici, și anume:

- Opțiunea
Replication.replSetNamesau—replSetpentru a specifica numele setului de replici în câmpul_id. - Matricea membrilor, care conține câte un document pentru fiecare membru al setului de replici.
Metoda rs.initiate() declanșează o alegere și alege unul dintre membri pentru a fi primar.
Adăugați membri la setul de replici
Pentru a adăuga membri la set, porniți instanțe mongod pe diferite mașini. Apoi, porniți un client mongo și utilizați comanda rs.add() .
Comanda rs.add() are următoarea sintaxă de bază:
rs.add(HOST_NAME:PORT)De exemplu,
Să presupunem că mongo1 este instanța ta mongod și că ascultă pe portul 27017. Utilizați comanda client Mongo rs.add() pentru a adăuga această instanță la setul de replică.
rs.add("mongo1:27017") Numai după ce sunteți conectat la nodul primar puteți adăuga o instanță mongod la setul de replică. Pentru a verifica dacă sunteți conectat la primar, utilizați comanda db.isMaster() .
Eliminați utilizatori
Pentru a elimina un membru, putem folosi rs.remove()
Pentru a face acest lucru, în primul rând, închideți instanța mongod pe care doriți să o eliminați folosind metoda db.shutdownServer() de care am discutat mai sus.
Apoi, conectați-vă la primarul curent al setului de replici. Pentru a determina primarul curent, utilizați db.hello() în timp ce vă conectați la orice membru al setului de replici. După ce ați determinat primarul, rulați oricare dintre următoarele comenzi:
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 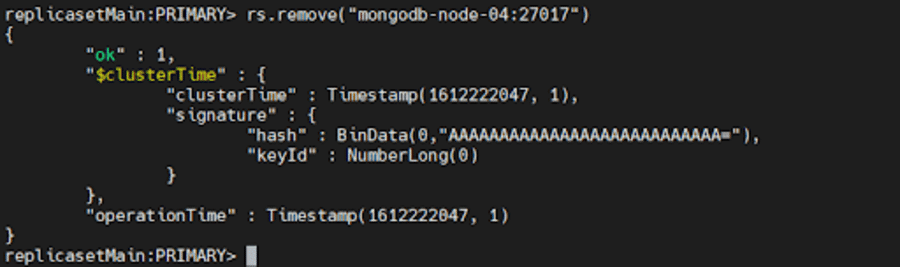
Dacă setul de replică trebuie să aleagă un nou primar, MongoDB ar putea deconecta pentru scurt timp shell-ul. În acest scenariu, se va reconecta automat încă o dată. De asemenea, poate afișa o eroare eșuată DBClientCursor::init call() chiar dacă comanda reușește.
Metoda 2: Configurarea unui set de replica MongoDB pentru implementare și testare
În general, puteți configura seturi de replică pentru testare fie cu RBAC activat, fie dezactivat. În această metodă, vom configura seturi de replici cu controlul accesului dezactivat pentru implementarea acestuia într-un mediu de testare.
Mai întâi, creați directoare pentru toate instanțele care fac parte din setul de replici folosind următoarea comandă:
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2Această comandă va crea directoare pentru trei instanțe MongoDB replicaset0-0, replicaset0-1 și replicaset0-2. Acum, porniți instanțele MongoDB pentru fiecare dintre ele folosind următorul set de comenzi:
Pentru Server 1:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Pentru Server 2:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Pentru Server 3:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 Parametrul –oplogSize este utilizat pentru a preveni supraîncărcarea mașinii în timpul fazei de testare. Ajută la reducerea cantității de spațiu pe disc pe care o consumă fiecare disc.
Acum, conectați-vă la una dintre instanțe folosind shell-ul Mongo, conectându-vă folosind numărul de port de mai jos.
mongo --port 27017 Putem folosi comanda rs.initiate() pentru a porni procesul de replicare. Va trebui să înlocuiți parametrul hostname cu numele sistemului dumneavoastră.
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }Acum puteți trece fișierul obiect de configurare ca parametru pentru comanda de inițiere și îl puteți utiliza după cum urmează:
rs.initiate(rsconf)Și iată-l! Ați creat cu succes un set de replică MongoDB pentru dezvoltare și testare.
Metoda 3: Transformarea unei instanțe autonome într-un set de replica MongoDB
MongoDB permite utilizatorilor săi să-și transforme instanțele autonome în seturi de replici. În timp ce instanțele de sine stătătoare sunt utilizate în principal pentru faza de testare și dezvoltare, seturile de replici fac parte din mediul de producție.
Pentru a începe, să închidem instanța noastră mongod folosind următoarea comandă:
db.adminCommand({"shutdown":"1"}) Reporniți instanța utilizând parametrul –repelSet din comandă pentru a specifica setul de replică pe care îl veți folosi:
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>Trebuie să specificați numele serverului dvs. împreună cu adresa unică în comandă.
Conectați shell-ul cu instanța dvs. MongoDB și utilizați comanda de inițiere pentru a porni procesul de replicare și pentru a converti cu succes instanța într-un set de replică. Puteți efectua toate operațiunile de bază, cum ar fi adăugarea sau eliminarea unei instanțe folosind următoarele comenzi:
rs.add(“<host_name:port>”) rs.remove(“host-name”) În plus, puteți verifica starea setului de replici MongoDB folosind comenzile rs.status() și rs.conf() .
Metoda 4: MongoDB Atlas — O alternativă mai simplă
Replicarea și fragmentarea pot lucra împreună pentru a forma ceva numit un cluster fragmentat. În timp ce setarea și configurarea pot consuma destul de mult timp, deși simple, MongoDB Atlas este o alternativă mai bună decât metodele menționate anterior.
Automatizează seturile dvs. de replici, făcând procesul ușor de implementat. Poate implementa seturi de replici fragmentate la nivel global cu câteva clicuri, permițând recuperarea în caz de dezastru, o gestionare mai ușoară, localitatea datelor și implementările în mai multe regiuni.
În MongoDB Atlas, trebuie să creăm clustere – acestea pot fi fie un set de replică, fie un cluster fragmentat. Pentru un anumit proiect, numărul de noduri dintr-un cluster din alte regiuni este limitat la un total de 40.
Aceasta exclude clusterele gratuite sau partajate și regiunile cloud Google care comunică între ele. Numărul total de noduri dintre oricare două regiuni trebuie să îndeplinească această constrângere. De exemplu, dacă există un proiect în care:
- Regiunea A are 15 noduri.
- Regiunea B are 25 de noduri
- Regiunea C are 10 noduri
Putem aloca doar încă 5 noduri regiunii C ca,
- Regiunea A+ Regiunea B = 40; îndeplinește constrângerea de 40 fiind numărul maxim de noduri permise.
- Regiunea B+ Regiunea C = 25+10+5 (Noduri suplimentare alocate lui C) = 40; îndeplinește constrângerea de 40 fiind numărul maxim de noduri permise.
- Regiunea A+ Regiunea C =15+10+5 (Noduri suplimentare alocate lui C) = 30; îndeplinește constrângerea de 40 fiind numărul maxim de noduri permise.
Dacă am alocat încă 10 noduri regiunii C, făcând ca regiunea C să aibă 20 de noduri, atunci Regiunea B + Regiunea C = 45 de noduri. Acest lucru ar depăși constrângerea dată, așa că este posibil să nu puteți crea un cluster cu mai multe regiuni.
Când creați un cluster, Atlas creează un container de rețea în proiect pentru furnizorul de cloud, dacă acesta nu era acolo anterior. Pentru a crea un cluster de set de replici în MongoDB Atlas, rulați următoarea comandă în Atlas CLI:
atlas clusters create [name] [options]Asigurați-vă că dați un nume descriptiv pentru cluster, deoarece acesta nu poate fi schimbat după ce clusterul este creat. Argumentul poate conține litere ASCII, cifre și cratime.
Există mai multe opțiuni disponibile pentru crearea clusterului în MongoDB, în funcție de cerințele dvs. De exemplu, dacă doriți backup continuu în cloud pentru clusterul dvs., setați --backup la true.
Confruntarea cu întârzierea replicării
Întârzierea replicării poate fi destul de dezamăgitoare. Este o întârziere între o operație pe primar și aplicarea acelei operațiuni de la oplog la secundar. Dacă afacerea dvs. se ocupă de seturi mari de date, este de așteptat o întârziere într-un anumit prag. Cu toate acestea, uneori, factori externi pot contribui și pot crește întârzierea. Pentru a beneficia de o replicare actualizată, asigurați-vă că:
- Vă direcționați traficul de rețea într-o lățime de bandă stabilă și suficientă. Latența rețelei joacă un rol important în afectarea replicării dvs. și, dacă rețeaua este insuficientă pentru a răspunde nevoilor procesului de replicare, vor exista întârzieri în replicarea datelor în întregul set de replici.
- Aveți o capacitate suficientă a discului. Dacă sistemul de fișiere și dispozitivul de disc de pe secundar nu reușesc să șteargă datele pe disc la fel de repede ca cel principal, atunci secundarul va avea dificultăți să țină pasul. Prin urmare, nodurile secundare procesează interogările de scriere mai lent decât nodul primar. Aceasta este o problemă comună în majoritatea sistemelor multi-chiriași, inclusiv instanțele virtualizate și implementările la scară largă.
- Solicitați o preocupare de scriere de confirmare a scrierii după un interval pentru a oferi secundariilor posibilitatea de a ajunge din urmă cu primarul, mai ales atunci când doriți să efectuați o operațiune de încărcare în bloc sau asimilare de date care necesită un număr mare de scrieri către primar. Secundarii nu vor putea citi oplog-ul suficient de repede pentru a ține pasul cu modificările; în special cu preocupările nerecunoscute privind scrisul.
- Identificați sarcinile de fundal care rulează. Anumite sarcini precum joburi cron, actualizări de server și verificări de securitate pot avea efecte neașteptate asupra rețelei sau utilizării discului, provocând întârzieri în procesul de replicare.
Dacă nu sunteți sigur dacă există un întârziere de replicare în aplicația dvs., nu vă îngrijorați - secțiunea următoare discută strategiile de depanare!
Depanarea setului de replică MongoDB
Ați configurat cu succes seturile de replici, dar observați că datele dvs. sunt inconsecvente pe servere. Acest lucru este extrem de alarmant pentru companiile la scară largă, cu toate acestea, cu metode rapide de depanare, puteți găsi cauza sau chiar corectați problema! Mai jos sunt prezentate câteva strategii comune pentru depanarea implementărilor setului de replici care ar putea fi utile:
Verificați starea copiei
Putem verifica starea curentă a setului de replici și starea fiecărui membru prin rularea următoarei comenzi într-o sesiune mongosh care este conectată la primarul unui set de replici.
rs.status()Verificați întârzierea de replicare
După cum sa discutat mai devreme, decalajul de replicare poate fi o problemă serioasă, deoarece face ca membrii „întârziați” să nu fie eligibili pentru a deveni rapid primari și crește posibilitatea ca operațiunile de citire distribuite să fie inconsecvente. Putem verifica lungimea curentă a jurnalului de replicare utilizând următoarea comandă:
rs.printSecondaryReplicationInfo() Aceasta returnează valoarea syncedTo , care este momentul în care ultima intrare oplog a fost scrisă în secundar pentru fiecare membru. Iată un exemplu pentru a demonstra același lucru:
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary Un membru întârziat se poate afișa cu 0 secunde în spatele principalului atunci când perioada de inactivitate pe primar este mai mare decât valoarea members[n].secondaryDelaySecs .
Testați conexiunile între toți membrii
Fiecare membru al unui set de replică trebuie să se poată conecta cu orice alt membru. Asigurați-vă întotdeauna că verificați conexiunile în ambele direcții. În mare parte, configurațiile firewall sau topologiile de rețea împiedică conectivitatea normală și necesară, care poate bloca replicarea.
De exemplu, să presupunem că instanța mongod se leagă atât la gazdă locală, cât și la numele gazdă „ExampleHostname”, care este asociat cu adresa IP 198.41.110.1:
mongod --bind_ip localhost, ExampleHostnamePentru a se conecta la această instanță, clienții la distanță trebuie să specifice numele de gazdă sau adresa IP:
mongosh --host ExampleHostname mongosh --host 198.41.110.1Dacă un set de replică este format din trei membri, m1, m2 și m3, folosind portul implicit 27017, ar trebui să testați conexiunea după cum urmează:
Pe m1:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017Pe m2:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017Pe m3:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 Dacă vreo conexiune în orice direcție eșuează, va trebui să verificați configurația firewall-ului și să o reconfigurați pentru a permite conexiunile.
Asigurarea comunicațiilor securizate cu autentificarea fișierelor cheie
În mod implicit, autentificarea fișierelor cheie în MongoDB se bazează pe mecanismul de autentificare a răspunsului la provocare (SCRAM). Pentru a face acest lucru, MongoDB trebuie să citească și să valideze acreditările furnizate de utilizator, care includ o combinație a numelui de utilizator, a parolei și a bazei de date de autentificare pe care o cunoaște instanța MongoDB. Acesta este mecanismul exact folosit pentru autentificarea utilizatorilor care furnizează o parolă atunci când se conectează la baza de date.
Când activați autentificarea în MongoDB, Controlul accesului bazat pe roluri (RBAC) este activat automat pentru setul de replici, iar utilizatorului i se acordă unul sau mai multe roluri care determină accesul la resursele bazei de date. Când RBAC este activat, înseamnă că numai utilizatorul Mongo valid autentificat cu privilegiile corespunzătoare ar putea accesa resursele din sistem.
Fișierul cheie acționează ca o parolă partajată pentru fiecare membru din cluster. Acest lucru permite fiecărei instanțe mongod din setul de replică să folosească conținutul fișierului cheie ca parolă partajată pentru autentificarea altor membri în implementare.
Numai acele instanțe mongod cu fișierul cheie corect se pot alătura setului de replică. Lungimea unei chei trebuie să fie între 6 și 1024 de caractere și poate conține doar caractere din setul de bază64. Vă rugăm să rețineți că MongoDB elimină caracterele spațiilor albe atunci când citesc cheile.
Puteți genera un fișier cheie utilizând diverse metode. În acest tutorial, folosim openssl pentru a genera un șir complex de 1024 de caractere aleatoare pe care să îl folosim ca parolă partajată. It then uses chmod to change file permissions to provide read permissions for the file owner only. Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. De exemplu:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
And voila! You have successfully enabled keyfile authentication!
rezumat
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!