
Fișierul WordPress robots.txt... Ce este și ce face
Publicat: 2020-11-25V-ați întrebat vreodată ce este fișierul robots.txt și ce face acesta? Robots.txt este folosit pentru a comunica cu crawlerele web (cunoscute sub numele de roboți) utilizate de Google și de alte motoare de căutare. Le spune ce părți ale site-ului dvs. să indexeze și pe care să le ignore. Ca atare, fișierul robots.txt vă poate ajuta să faceți (sau potențial să rupă!) eforturile dvs. de SEO. Dacă doriți ca site-ul dvs. să se claseze bine, atunci o bună înțelegere a robots.txt este esențială!
Unde se află Robots.txt?
WordPress rulează de obicei un așa-numit fișier robots.txt „virtual”, ceea ce înseamnă că nu este accesibil prin SFTP. Cu toate acestea, puteți vedea conținutul său de bază, accesând domeniul dumneavoastră.com/robots.txt. Probabil vei vedea ceva de genul asta:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.phpPrima linie specifică la ce roboți se vor aplica regulile. În exemplul nostru, asteriscul înseamnă că regulile vor fi aplicate tuturor roboților (de exemplu, celor de la Google, Bing și așa mai departe).
A doua linie definește o regulă care împiedică accesul roboților la folderul /wp-admin, iar a treia linie afirmă că roboții au voie să analizeze fișierul /wp-admin/admin-ajax.php.
Adăugați propriile reguli
Pentru un site web WordPress simplu, regulile implicite aplicate de WordPress fișierului robots.txt pot fi mai mult decât adecvate. Dacă, totuși, doriți mai mult control și posibilitatea de a adăuga propriile reguli pentru a oferi instrucțiuni mai specifice roboților motoarelor de căutare despre cum să indexați site-ul dvs., atunci va trebui să vă creați propriul fișier robots.txt fizic și să-l puneți sub rădăcină. directorul instalării dvs.
Există mai multe motive pentru care ar putea dori să vă reconfigurați fișierul robots.txt și să definiți ce anume acești roboți vor putea accesa cu crawlere. Unul dintre motivele cheie este de a face cu timpul petrecut de un bot care vă accesează site-ul. Google (și alții) nu le permite roboților să petreacă timp nelimitat pe fiecare site... cu trilioane de pagini, trebuie să adopte o abordare mai nuanțată a ceea ce roboții lor vor accesa cu crawlere și ce vor ignora în încercarea de a extrage cele mai utile informații despre un site web.

Găzduiește-ți site-ul web cu Pressidium
GARANTIE 60 DE ZILE BANI RAPIS
Când permiteți roboților să acceseze cu crawlere toate paginile de pe site-ul dvs., o parte din timpul de accesare cu crawlere este cheltuită pe pagini care nu sunt importante sau chiar relevante. Acest lucru le lasă mai puțin timp pentru a-și face drum prin zonele mai relevante ale site-ului dvs. Prin interzicerea accesului botului la unele părți ale site-ului dvs., creșteți timpul disponibil pentru roboți pentru a extrage informații din cele mai relevante părți ale site-ului dvs. (care, sperăm, vor ajunge indexate). Deoarece accesarea cu crawlere este mai rapidă, este mai probabil ca Google să revină site-ul dvs. și să păstreze indexul site-ului dvs. la zi. Aceasta înseamnă că noile postări de blog și alt conținut proaspăt vor fi indexate mai repede, ceea ce este o veste bună.
Exemple de editare Robots.txt
Robots.txt oferă mult spațiu pentru personalizare. Ca atare, am oferit o serie de exemple de reguli care pot fi folosite pentru a dicta modul în care roboții indexează site-ul dvs.
Permiterea sau interzicerea roboților
Mai întâi, să vedem cum putem restricționa un anumit bot. Pentru a face acest lucru, tot ce trebuie să facem este să înlocuim asteriscul (*) cu numele user-agent-ului bot pe care dorim să-l blocăm, de exemplu „MSNBot”. O listă cuprinzătoare a agenților utilizator cunoscuți este disponibilă aici.
User-agent: MSNBot Disallow: /Punerea unei liniuțe în a doua linie va restricționa accesul botului la toate directoarele.
Pentru a permite doar unui singur robot să acceseze cu crawlere site-ul nostru, am folosi un proces în doi pași. Mai întâi am seta acest bot ca o excepție și apoi am interzice toți roboții astfel:
User-agent: Google Disallow: User-agent: * Disallow: /Pentru a permite accesul la toți roboții pe tot conținutul, adăugăm aceste două rânduri:
User-agent: * Disallow:Același efect ar fi obținut prin simpla creare a unui fișier robots.txt și apoi pur și simplu lăsându-l gol.
Blocarea accesului la anumite fișiere
Doriți să opriți roboții să indexeze anumite fișiere de pe site-ul dvs.? Asta e ușor! În exemplul de mai jos am împiedicat motoarele de căutare să acceseze toate fișierele .pdf de pe site-ul nostru.
User-agent: * Disallow: /*.pdf$Simbolul „$” este folosit pentru a defini sfârșitul adresei URL. Întrucât este diferențiat cu majuscule și minuscule, un fișier cu numele my.PDF va fi în continuare accesat cu crawlere (rețineți MAJUSCULE).
Expresii logice complexe
Unele motoare de căutare, cum ar fi Google, înțeleg utilizarea expresiilor regulate mai complicate. Cu toate acestea, este important să rețineți că nu toate motoarele de căutare ar putea înțelege expresiile logice din robots.txt.

Un exemplu în acest sens este utilizarea simbolului $. În fișierele robots.txt, acest simbol indică sfârșitul unei adrese URL. Deci, în exemplul următor am blocat roboții de căutare să citească și să indexeze fișierele care se termină cu .php
Disallow: /*.php$Aceasta înseamnă că /index.php nu poate fi indexat, dar /index.php?p=1 ar putea fi. Acest lucru este util doar în circumstanțe foarte specifice și trebuie utilizat cu prudență, altfel riscați să blocați accesul botului la fișierele pe care nu ați vrut să le faceți!
De asemenea, puteți seta reguli diferite pentru fiecare bot, specificând regulile care li se aplică în mod individual. Exemplul de cod de mai jos va restricționa accesul la folderul wp-admin pentru toți roboții, blocând în același timp accesul la întregul site pentru motorul de căutare Bing. Nu ați dori neapărat să faceți acest lucru, dar este o demonstrație utilă a cât de flexibile pot fi regulile dintr-un fișier robots.txt.
User-agent: * Disallow: /wp-admin/ User-agent: Bingbot Disallow: /Sitemaps XML
Hărțile de site XML ajută cu adevărat roboții de căutare să înțeleagă aspectul site-ului dvs. Dar pentru a fi util, botul trebuie să știe unde se află harta site-ului. „Directiva sitemap” este utilizată pentru a le spune în mod special motoarelor de căutare că a) există o hartă a site-ului dvs. și b) unde o pot găsi.
Sitemap: http://www.example.com/sitemap.xml User-agent: * Disallow:De asemenea, puteți specifica mai multe locații ale sitemapului:
Sitemap: http://www.example.com/sitemap_1.xml Sitemap: http://www.example.com/sitemap_2.xml User-agent:* DisallowÎntârzieri de accesare cu crawlere bot
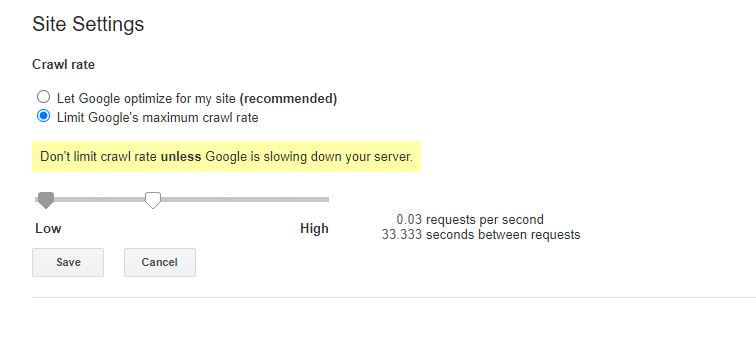
O altă funcție care poate fi realizată prin fișierul robots.txt este de a le spune roboților să „încetinească” accesarea cu crawlere a site-ului dvs. Acest lucru ar putea fi necesar dacă descoperiți că serverul dvs. este supraîncărcat de niveluri ridicate de trafic bot. Pentru a face acest lucru, trebuie să specificați agentul utilizator pe care doriți să îl încetiniți și apoi să adăugați o întârziere.
User-agent: BingBot Disallow: /wp-admin/ Crawl-delay: 10Ghilimelele numerice (10) din acest exemplu reprezintă întârzierea pe care doriți să apară între accesarea cu crawlere a paginilor individuale de pe site-ul dvs. Așadar, în exemplul de mai sus i-am cerut Bing Bot-ului să facă o pauză de zece secunde între fiecare pagină pe care o accesează cu crawlere și, astfel, oferind serverului nostru un pic de spațiu de respirație.
Singura veste puțin proastă despre această regulă robots.txt este că botul Google nu o respectă. Cu toate acestea, puteți instrui roboții lor să încetinească din Google Search Console.
Note despre regulile robots.txt:
- Toate regulile robots.txt țin cont de majuscule și minuscule. Tastați cu atenție!
- Asigurați-vă că nu există spații înaintea comenzii de la începutul liniei.
- Modificările făcute în robots.txt pot dura 24-36 de ore pentru a fi observate de către roboți.
Cum să testați și să trimiteți fișierul WordPress robots.txt
Când ați creat un fișier robots.txt nou, merită să verificați că nu există erori în el. Puteți face acest lucru utilizând Google Search Console.
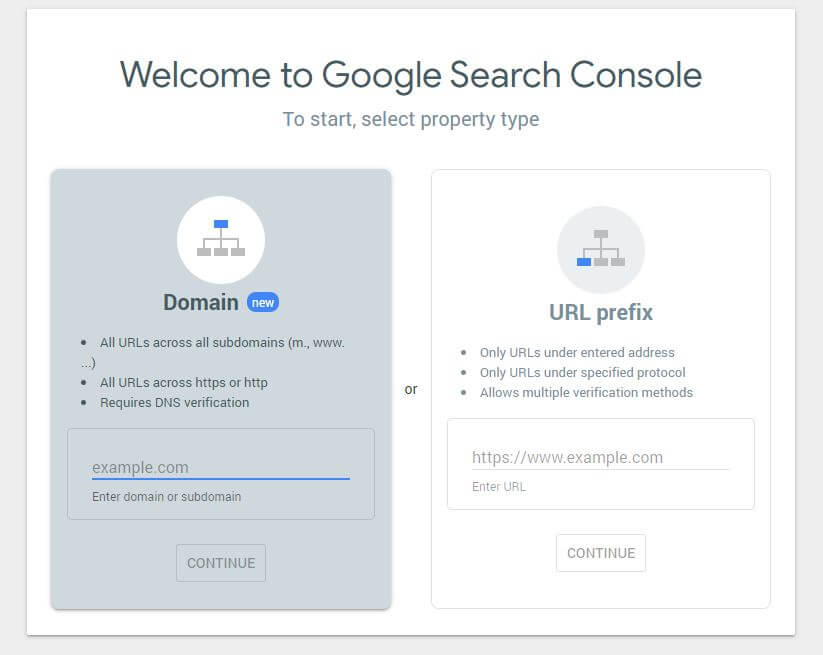
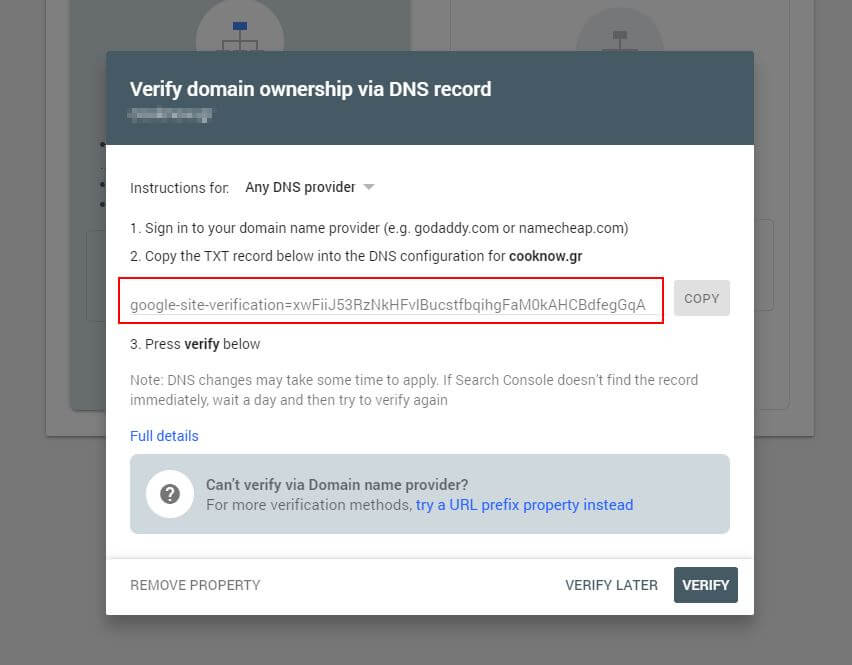
Mai întâi, va trebui să trimiteți domeniul dvs. (dacă nu aveți deja un cont Search Console pentru configurarea site-ului dvs.). Google vă va furniza o înregistrare TXT care trebuie adăugată la DNS pentru a vă verifica domeniul.
Odată ce această actualizare DNS s-a propagat (s-a simțit nerăbdător... încercați să utilizați Cloudflare pentru a vă gestiona DNS-ul), puteți vizita testerul robots.txt și puteți verifica dacă există avertismente despre conținutul fișierului dvs. robots.txt.
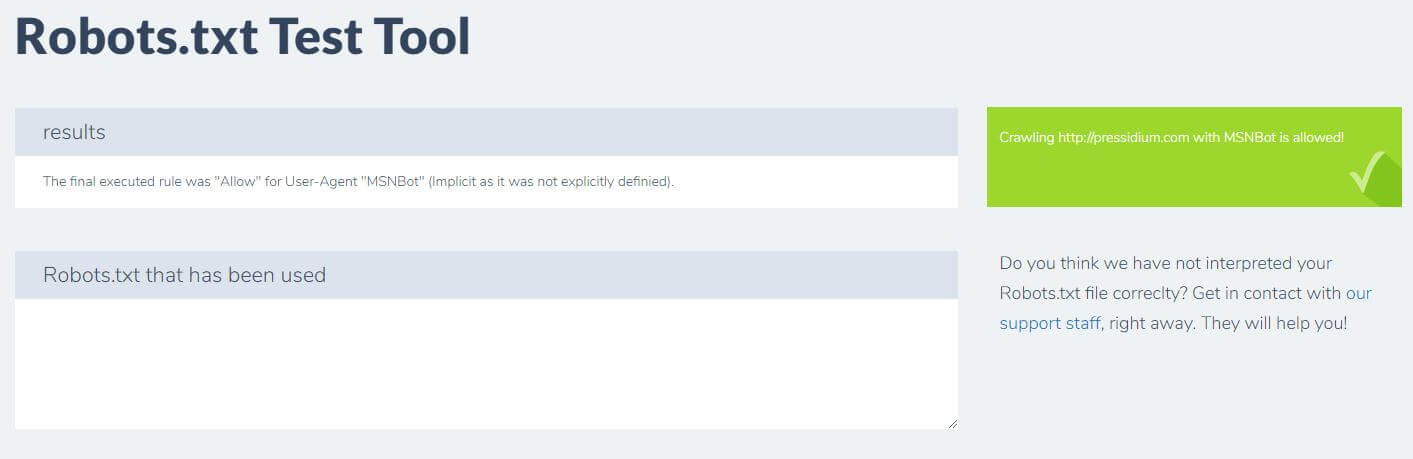
Un alt lucru pe care îl puteți face pentru a testa regulile pe care le aveți în vigoare au efectul dorit este să utilizați un instrument de testare robots.txt precum Ryte.
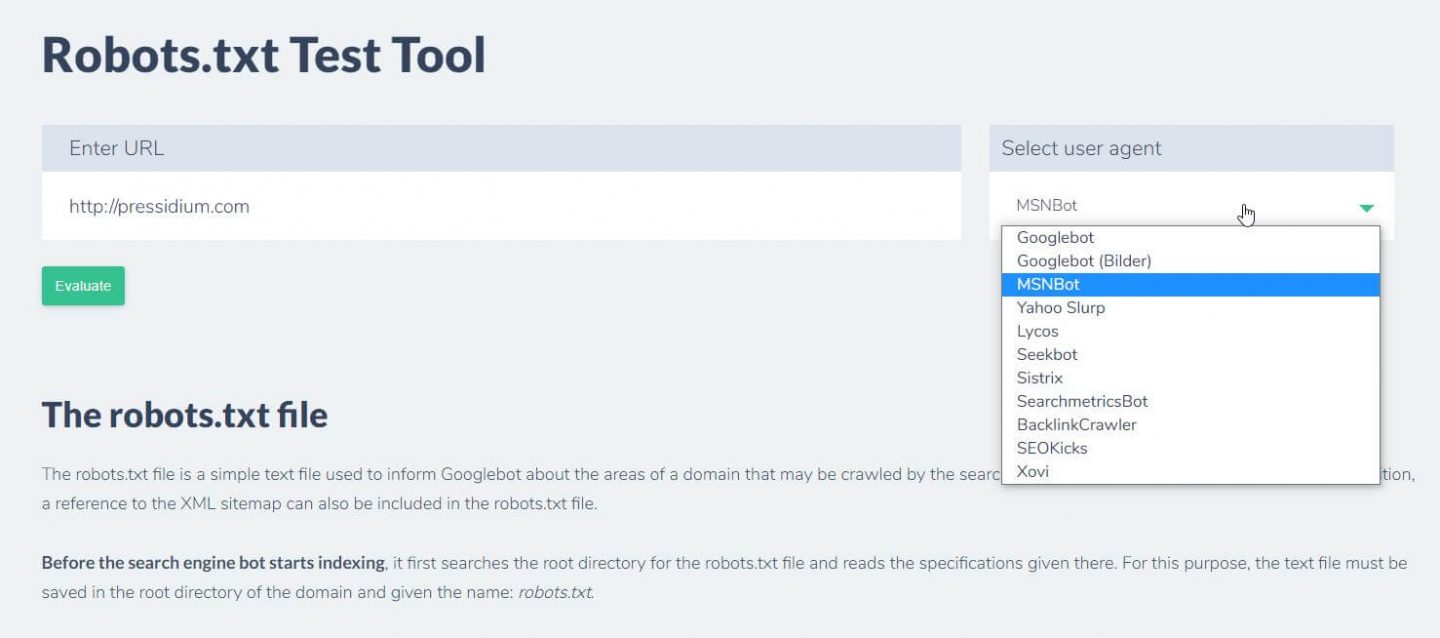
Doar introduceți domeniul și alegeți un agent de utilizator din panoul din dreapta. După ce ați trimis acest lucru, veți vedea rezultatele.
Concluzie
A ști cum să folosești robots.txt este un alt instrument util din setul de instrumente al dezvoltatorului. Dacă singurul lucru pe care îl iei din acest tutorial este capacitatea de a verifica dacă fișierul robots.txt nu blochează roboții precum Google (ceea ce este foarte puțin probabil să vrei să faci), atunci nu este un lucru rău! În egală măsură, după cum puteți vedea, robots.txt oferă o serie întreagă de control suplimentar fin asupra site-ului dvs., care poate fi util într-o zi.