
Вводящая в заблуждение статистика может быть опасной (некоторые примеры)
Опубликовано: 2022-12-06Люди полагаются на статистику, чтобы получить важную информацию. В деловом мире статистика может быть полезна для отслеживания тенденций и повышения производительности. Но иногда статистические данные могут быть представлены в искаженном виде . Например, в 2007 году Управление по стандартам рекламы (ADA) Великобритании получило жалобу на рекламу Colgate.
В рекламе утверждается, что 80% стоматологов рекомендуют использовать зубную пасту Colgate. В жалобе, полученной ADA, утверждалось, что это было нарушением правил рекламы в Великобритании. Изучив этот вопрос, ADA обнаружило, что в рекламе использовались вводящие в заблуждение статистические данные.
Это правда, что многие стоматологи рекомендуют зубную пасту Colgate. Но не все из них назвали Colgate своей рекомендацией номер один. Большинство стоматологов рекомендовали и другие виды зубной пасты, и Колгейт обычно упоминался в какой-то момент позже.
Это всего лишь один пример того, как используется вводящая в заблуждение статистика. Люди сталкиваются с вводящими в заблуждение статистическими примерами в самых разных сферах жизни. Вы можете найти примеры в новостях, в рекламе, в политике и даже в науке.
Этот пост поможет вам научиться распознавать вводящую в заблуждение статистику и другие вводящие в заблуждение данные . Будет обсуждаться, как эти данные вводят людей в заблуждение. Вы также узнаете, когда и как использовать данные при принятии важных решений.
Что такое вводящая в заблуждение статистика?
Статистика является результатом сбора числовых данных, их тщательного анализа и последующей интерпретации . Особенно полезно иметь статистику, если вы имеете дело с большим объемом данных, но все, что можно измерить, может стать статистикой. Статистика часто многое говорит о мире и о том, как он устроен.
Однако, когда эта информация используется неправильно, даже случайно, она становится вводящей в заблуждение статистикой. Вводящая в заблуждение статистика дает людям ложную информацию, которая вводит их в заблуждение, а не информирует .
Когда люди вырывают статистику из контекста, она теряет свою ценность и может привести к неверным выводам. Термин «вводящая в заблуждение статистика» описывает любой статистический метод, который неверно представляет данные. Было ли это намеренно или нет , это все равно будет считаться вводящей в заблуждение статистикой.
При сборе данных для статистики необходимо помнить о трех принципиальных моментах. Во время любой из этих точек может возникнуть проблема с анализом данных.
- Сбор: при сборе данных
- Обработка: при анализе данных и их последствий
- Презентация: Когда вы делитесь своими выводами с другими
Небольшой размер выборки
Обследования размера выборки являются одним из примеров создания вводящей в заблуждение статистики. Опросы или исследования, проводимые на выборочной аудитории, часто дают результаты, настолько вводящие в заблуждение, что их невозможно использовать.
Например, в опросе 20 человек задают вопрос, на который можно ответить «да» или «нет». 19 человек ответили утвердительно на опрос. Таким образом, результаты показывают, что 95% людей ответят утвердительно на этот вопрос. Но это не очень хороший обзор, потому что информация ограничена.
Эта статистика не имеет реальной ценности. Теперь, если вы зададите тот же вопрос 1000 человек, и 950 из них ответят «да», то это гораздо более надежная статистика, показывающая, что 95% людей ответят «да».
Чтобы провести надежное исследование размера выборки, вам необходимо учитывать три вещи:
- Один : Что за вопрос ты задаешь?
- Два : Каково значение статистики, которую вы пытаетесь найти?
- И третий : какой статистический метод вы будете использовать?
Чтобы получить надежные результаты, количественный анализ любого размера выборки должен включать не менее 200 человек.
Загруженные вопросы

Важно искать данные из нейтрального источника . В противном случае информация искажена. Нагруженные вопросы используют противоречивое или необоснованное предположение для манипулирования ответом. Одним из примеров этого является вопрос, начинающийся со слов «Что вам нравится?». Этот вопрос помогает собрать положительные отзывы, но ничему полезному вас не научит. Это не дает человеку возможности высказать свои честные мысли и мнения.
Рассмотрим разницу в следующих двух вопросах:
- Поддерживаете ли вы налоговую реформу, которая подразумевала бы более высокие налоги?
- Поддерживаете ли вы налоговую реформу, которая способствовала бы социальному перераспределению?
Вопрос по существу относится к одному и тому же предмету, но результаты каждого из этих вопросов будут совершенно разными. Опросы должны проводиться беспристрастно, непредвзято. Вы хотите получить честное мнение людей и полную картину того, что они думают. Для этого ваши вопросы не должны подразумевать ответ или вызывать эмоциональную реакцию .
Ссылаясь на вводящие в заблуждение «средние значения»
Некоторые люди используют термин «средний», чтобы скрыть правду или ложь, чтобы информация выглядела лучше.
Этот метод особенно полезен, если кто-то хочет, чтобы число выглядело больше или лучше, чем оно есть на самом деле. Например, университет, желающий привлечь новых студентов, может установить «среднюю» годовую зарплату для выпускников своей школы. Но может быть только горстка студентов, которые действительно имеют высокие зарплаты. Но их зарплаты делают средний доход всех студентов выше. Это выглядит лучше для всего среднего.
Средние значения также полезны для сокрытия неравенства. В качестве другого примера предположим, что одна компания платит 20 000 долларов в год своим 90 сотрудникам. Но их босс получает 200 000 долларов в год. Если вы объедините заработную плату босса и заработную плату сотрудников, средний доход каждого члена компании составит 21 978 долларов.
На бумаге это выглядит великолепно. Но эта цифра не раскрывает всей картины, потому что один из сотрудников (начальник) зарабатывает гораздо больше, чем другие работники. Таким образом, такие результаты считаются вводящей в заблуждение статистикой.
Совокупные и годовые данные
Совокупные данные отслеживают информацию на графике с течением времени. Каждый раз, когда вы вводите данные в диаграммы, график поднимается.
Годовые данные представляют все данные за конкретный год.
Отслеживание информации за каждый год дает более точную картину общих тенденций.
Одним из примеров кумулятивного графика является график Worldometer COVID-19. Во время пандемии COVID-19 появилось много примеров кумулятивных графиков. Они часто отражают совокупное количество случаев COVID в конкретной области.
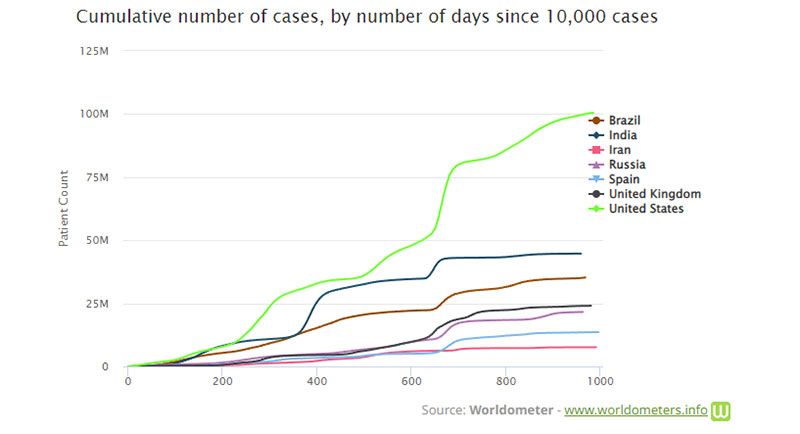
Некоторые компании используют подобные графики, чтобы продажи казались больше, чем они есть на самом деле. В 2013 году генеральный директор Apple Тим Кук подвергся критике за использование презентации, показывающей только совокупное количество продаж iPhone. Многие в то время считали, что он сделал это намеренно, чтобы скрыть тот факт, что продажи iPhone сокращаются.
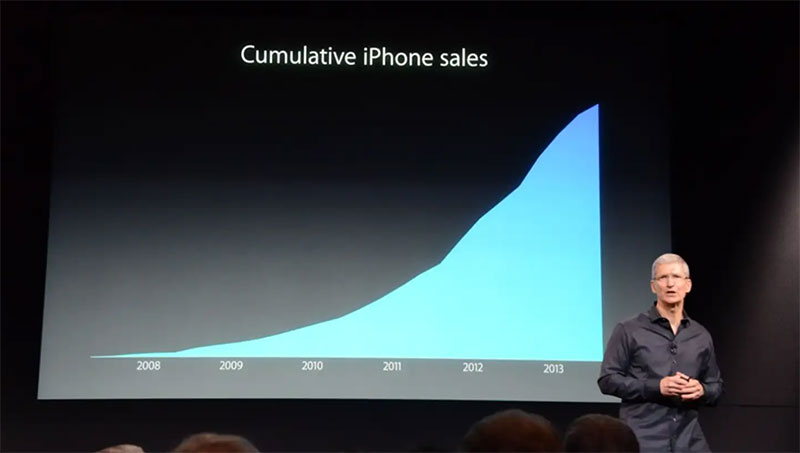
Это не означает, что все совокупные данные плохи или ложны. На самом деле, это может быть полезно для отслеживания изменений или роста и различных итогов. Но важно обращать внимание на изменения в данных. Затем посмотрите глубже на то, что их вызвало, а не полагайтесь на график, который расскажет вам обо всем.
Чрезмерное обобщение и необъективные выборки
Чрезмерное обобщение происходит, когда кто-то предполагает, что то, что верно для одного человека, должно быть верно для всех остальных. Обычно это заблуждение возникает, когда кто-то проводит исследование с определенной группой людей. Затем они предполагают, что результаты будут верны для другой, неродственной группы людей.
Нерепрезентативные выборки или предвзятые выборки — это опросы, которые не точно представляют генеральную совокупность.
Один из примеров необъективной выборки произошел во время президентских выборов 1936 года в Соединенных Штатах Америки.
Популярный в то время журнал «Литературный дайджест» провел опрос, чтобы предсказать, кто победит на выборах. Результаты предсказывали, что Альфред Лэндон победит с большим отрывом.
Этот журнал был известен тем, что точно предсказывал исход выборов. Однако в этом году они были совершенно неправы. Франклин Рузвельт победил, набрав почти вдвое больше голосов, чем его оппонент.
Еще одно исследование показало, что в игру вступили две переменные, которые исказили результаты.
Во- первых , большую часть участников опроса составили люди, найденные в телефонной книге и в авторегистрационных списках. Таким образом, опрос проводился только среди лиц определенного социально-экономического статуса.
Второй фактор заключался в том, что те, кто голосовал за Лэндона, охотнее отвечали на опрос, чем те, кто голосовал за Рузвельта. Таким образом, результаты отражали это предубеждение.
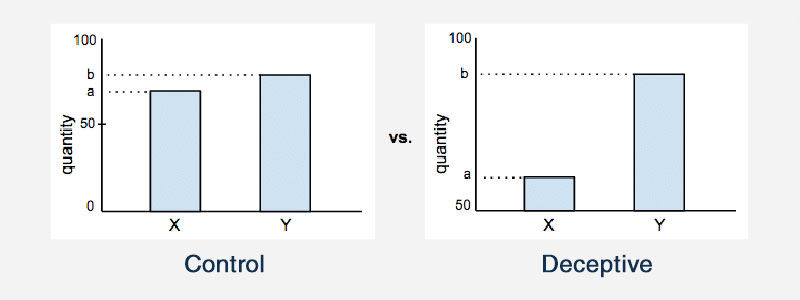
Усечение оси
Усечение оси на графике — еще один пример вводящей в заблуждение статистики. На большинстве статистических графиков оси x и y предположительно начинаются с нуля. Но усечение оси означает, что график фактически начинает оси с какого-то другого значения. Это влияет на то, как будет выглядеть график, и влияет на выводы, которые сделает человек.
Вот один пример, иллюстрирующий это:
Другой пример этого произошел недавно, в сентябре 2021 года. В одной из передач Fox News ведущий использовал диаграмму, показывающую количество американцев, называющих себя христианами. Диаграмма показала, что число американцев, считающих себя христианами, резко сократилось за последние 10 лет.
На следующем графике мы видим, что в 2009 году 77% американцев идентифицировали себя как христиане.
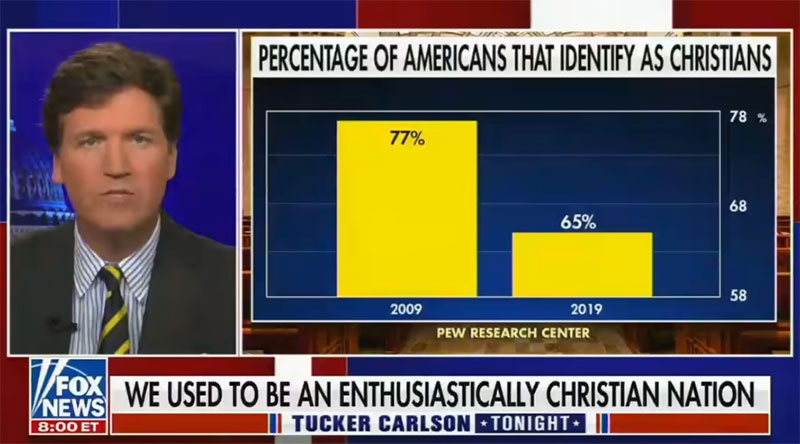
К 2019 году количество снизилось до 65%. На самом деле это не такое уж большое снижение. Но ось на этом графике начинается с 58% и заканчивается на 78%. Таким образом, снижение на 12% с 2009 по 2019 год кажется гораздо более резким, чем оно есть на самом деле.

Причинность и корреляция
Можно легко предположить наличие связи между двумя, казалось бы, связанными точками данных. Тем не менее, говорят, что корреляция не подразумевает причинно-следственной связи . Почему это так?
Этот график показывает, почему корреляция — это не то же самое, что причинно-следственная связь.
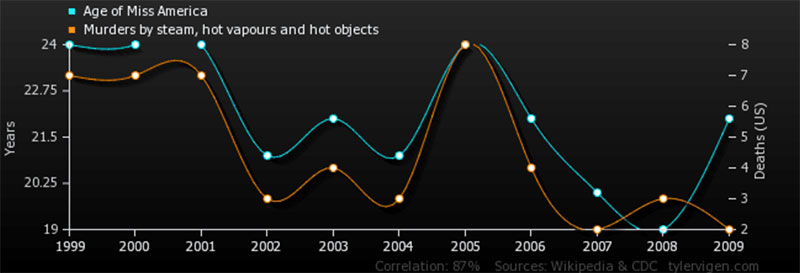
Исследователи часто находятся под большим давлением, чтобы обнаружить новые полезные данные. Так что соблазн поторопиться и сделать преждевременные выводы есть всегда. Вот почему так важно в каждой ситуации искать реальную причину и следствие .
Использование процентов для сокрытия чисел и вычислений
Процент может скрыть точные цифры и сделать результаты более авторитетными и надежными, чем они есть на самом деле.
Например, если двое из трех человек предпочитают определенный чистящий продукт, можно сказать, что 66,667% людей предпочитают этот продукт. Это делает число более официальным, особенно с включенными числами после запятой.
Вот еще несколько способов, которыми десятичные дроби и проценты могут скрыть правду:
- Сокрытие необработанных чисел и небольших размеров выборки . Проценты скрывают абсолютное значение необработанных чисел. Это делает их полезными для людей, которые хотят скрыть нелестные цифры или результаты небольшого размера выборки.
- Использование разных баз. Поскольку проценты не дают исходных чисел, на которых они основаны, можно легко исказить результаты. Если кто-то хотел, чтобы одно число выглядело лучше, он мог вычислить это число на основе другого основания.
Это произошло однажды в отчете New York Times о профсоюзных работниках. В один год зарплата рабочих была снижена на 20%, а в следующем году Times сообщила, что профсоюзные рабочие получили повышение на 5%. Таким образом, утверждалось, что им вернули четверть их урезанной зарплаты.
Однако рабочие получили прибавку на 5% в зависимости от их текущей заработной платы, а не от заработной платы, которую они имели до сокращения заработной платы. Таким образом, несмотря на то, что на бумаге это выглядело хорошо, сокращение заработной платы на 20% и повышение на 5% были рассчитаны на основе разных базовых чисел. Эти два числа вообще не сравнивались.
Вишневый сбор/отбрасывание неблагоприятных данных
Термин «сбор вишни» основан на идее сбора только лучших плодов с дерева. Любой, кто увидит этот плод, обязательно подумает, что все плоды на дереве одинаково здоровы. Очевидно, что это не обязательно так.
Тот же принцип действует и в случае изменения климата. Многие диаграммы ограничивают свои рамки данных, чтобы показать только изменения климата с 2000 по 2013 годы.
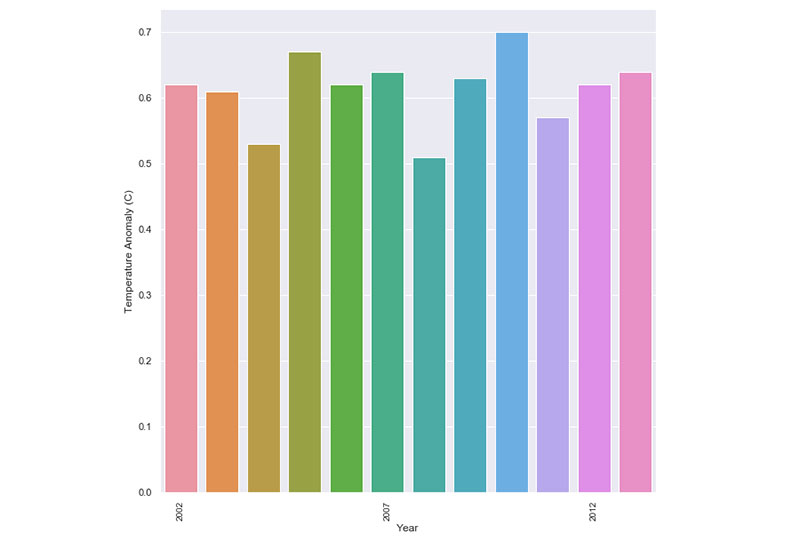
В результате оказывается, что изменения температуры и аномалии постоянны и не сильно меняются. Однако, когда вы делаете шаг назад и смотрите на общую картину, становится ясно, где находятся изменения и аномалии.
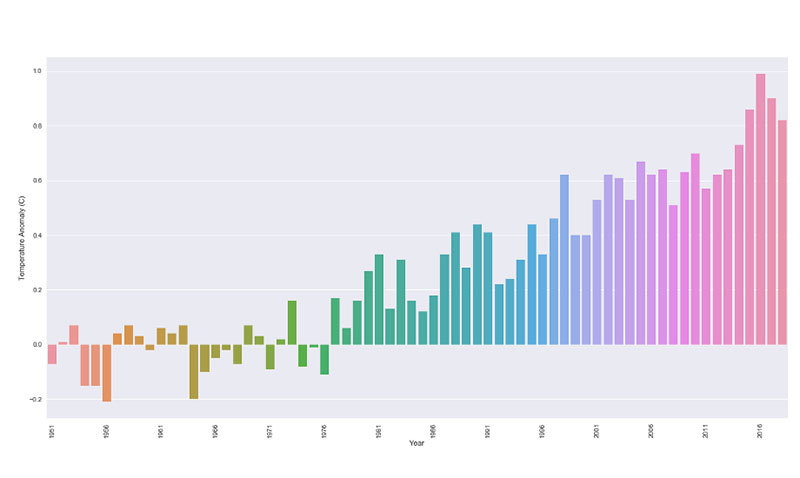
Это также происходит в области ветеринарии. Когда ветеринаров просят представить результаты нового пробного лекарства, они, как правило, представляют наилучшие результаты. В частности, если фармацевтическая компания поддерживает испытания, они хотят видеть только наилучшие результаты.
Ваши прекрасные данные заслуживают того, чтобы быть онлайн
wpDataTables может сделать это таким образом. Есть веская причина, по которой это плагин WordPress №1 для создания адаптивных таблиц и диаграмм.
И очень легко сделать что-то вроде этого:
- Вы предоставляете данные таблицы
- Настройте и настройте его
- Опубликовать в посте или на странице
И это не только красиво, но и практично. Вы можете создавать большие таблицы с миллионами строк, или вы можете использовать расширенные фильтры и поиск, или вы можете сделать их редактируемыми.
«Да, но я просто слишком люблю Excel, а на веб-сайтах ничего подобного нет». Да, есть. Вы можете использовать условное форматирование, как в Excel или Google Sheets.
Я говорил вам, что вы тоже можете создавать диаграммы с вашими данными? И это только малая часть. Есть много других функций для вас.
Ловля данных
Вылов данных, также известный как углубление данных, представляет собой анализ больших объемов данных с целью поиска корреляции. Однако, как обсуждалось ранее в этом посте, корреляция не подразумевает причинно-следственную связь. Настаивая на том, что это приводит только к вводящей в заблуждение статистике.
Вы можете видеть примеры ловли данных в отраслевых областях каждый день. Через неделю выходит скандал о интеллектуальном анализе данных, а еще через неделю его опровергает еще более возмутительный отчет.
Еще одна проблема такого рода анализа данных заключается в том, что люди выбирают только те данные, которые подтверждают их точку зрения, и игнорируют остальные. Опуская противоречивую информацию, они делают результаты более убедительными .
Запутанные метки графиков и диаграмм
Когда началась пандемия COVID-19, больше людей, чем когда-либо, обратились к визуализации данных о распространении вируса. Люди, которым никогда не приходилось работать с визуальным представлением статистики, внезапно оказывались отброшены вглубь статистических данных.
Кроме того, организации часто пытались быстро получить информацию о людях. Иногда это означало жертвовать точной статистикой. Это вызвало всплеск вводящей в заблуждение статистики и неправильной интерпретации данных.
Примерно через пять месяцев после того, как COVID-19 начал распространяться, Департамент общественного здравоохранения США в Джорджии опубликовал эту диаграмму:
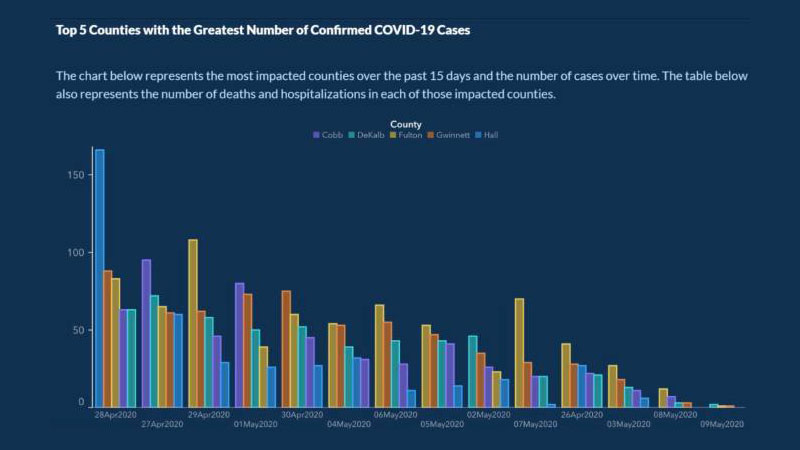
Цель диаграммы состояла в том, чтобы показать 5 стран с наибольшим количеством случаев COVID за предыдущие 15 дней, а также количество случаев за определенный период времени.
В этой диаграмме есть несколько ошибок, из-за которых ее легко понять неправильно. Например, ось X не имеет метки, поясняющей, что она представляет развитие случаев с течением времени.
Что еще хуже, даты на диаграмме не расположены в хронологическом порядке. Даты за апрель и май разбросаны по всей диаграмме, чтобы создать впечатление, что число случаев неуклонно снижается. Каждая страна также указана таким образом, чтобы создать впечатление, что число случаев снижается.
Позже они переиздали диаграмму с более организованными датами и округами:
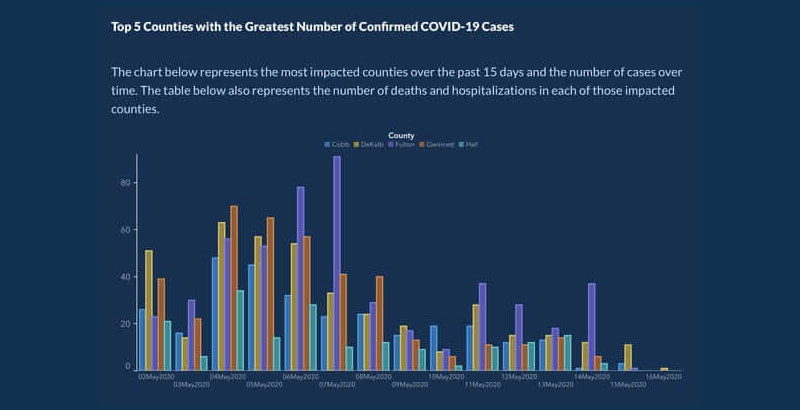
Неточные цифры
Еще одним примером вводящей в заблуждение статистики являются неточные цифры. Обратите внимание на это заявление из старой кампании Reebok.
В рекламе утверждается, что эта обувь воздействует на подколенные сухожилия и икры человека на 11% сильнее и может привести в тонус ягодицы на 28% больше, чем другие кроссовки . Все, что нужно сделать человеку, это ходить в кроссовках.
Эти цифры говорят о том, что Reebok провел обширное исследование преимуществ обуви.
На самом деле эти цифры были полностью выдуманы. Бренд получил штраф за использование такой вводящей в заблуждение статистики. Им также пришлось изменить заявление и удалить поддельные номера.
Как избежать и выявить неправомерное использование статистики
Статистика может быть чрезвычайно полезной. Но вводящая в заблуждение статистика также может запутать и обмануть людей. Статистика придает авторитет утверждению и убеждает людей доверять определенному аргументу.
Твердые, правдивые статистические данные помогают людям понять и принять решение. Но вводящая в заблуждение статистика опасна . Вместо того, чтобы помочь людям избежать ловушек и выбоин, они ведут людей прямо в ситуации, которых они хотели избежать.
Но можно выявить вводящие в заблуждение статистические данные и данные. Когда вы столкнетесь со статистикой, остановитесь и задайте следующие вопросы:
- Откуда берутся эти данные?
- Источник контролируется? Или это выборочный эксперимент?
- Какие еще факторы могли повлиять на этот результат?
- Информация пытается информировать меня или направляет меня к заранее определенному выводу?
Независимо от того, собираете ли вы данные или просматриваете результаты чужих исследований, убедитесь, что данные точны. Таким образом, вы не способствуете распространению вводящей в заблуждение статистики .
Если вам понравилась эта статья о вводящей в заблуждение статистике, прочтите и эти:
- Самая впечатляющая интерактивная визуализация данных, которую вы найдете в Интернете
- Лучшие инструменты визуализации данных WordPress, которые вы можете найти
- Лучшие инструменты и платформы визуализации данных для вас