
Создайте надежный набор реплик MongoDB в рекордно короткие сроки (4 метода)
Опубликовано: 2023-03-11MongoDB — это база данных NoSQL, которая использует JSON-подобные документы с динамическими схемами. При работе с базами данных всегда полезно иметь план действий на случай отказа одного из серверов баз данных. Боковая панель, вы можете уменьшить вероятность этого, используя отличный инструмент управления для вашего сайта WordPress.
Вот почему полезно иметь много копий ваших данных. Это также уменьшает задержки чтения. В то же время это может улучшить масштабируемость и доступность базы данных. Именно здесь вступает в действие репликация. Она определяется как практика синхронизации данных между несколькими базами данных.
В этой статье мы углубимся в различные важные аспекты репликации MongoDB, такие как ее функции и механизм, и это лишь некоторые из них.
Что такое репликация в MongoDB?
В MongoDB наборы реплик выполняют репликацию. Это группа серверов, поддерживающих один и тот же набор данных посредством репликации. Вы даже можете использовать репликацию MongoDB как часть балансировки нагрузки. Здесь вы можете распределить операции записи и чтения по всем экземплярам в зависимости от варианта использования.
Что такое набор реплик MongoDB?
Каждый экземпляр MongoDB, являющийся частью данного набора реплик, является членом. В каждом наборе реплик должен быть основной элемент и по крайней мере один дополнительный элемент.
Основной член является основной точкой доступа для транзакций с набором реплик. Кроме того, это единственный член, который может принимать операции записи. Репликация сначала копирует oplog (журнал операций) основного сервера. Затем он повторяет зарегистрированные изменения в соответствующих вторичных наборах данных. Следовательно, в каждом наборе реплик может быть только один первичный член одновременно. Различные первичные устройства, получающие операции записи, могут вызывать конфликты данных.
Обычно приложения запрашивают только основной член для операций записи и чтения. Вы можете спроектировать свою установку для чтения с одного или нескольких вторичных членов. Асинхронная передача данных может привести к тому, что операции чтения вторичных узлов будут обслуживать старые данные. Таким образом, такое расположение не является идеальным для каждого варианта использования.
Особенности набора реплик
Механизм автоматического перехода на другой ресурс отличает наборы реплик MongoDB от конкурентов. При отсутствии первичного узла автоматический выбор среди вторичных узлов выбирает новый первичный узел.
Набор реплик MongoDB против кластера MongoDB
Набор реплик MongoDB будет создавать различные копии одного и того же набора данных на узлах набора реплик. Основная цель набора реплик:
- Предложите встроенное решение для резервного копирования
- Повышение доступности данных
Кластер MongoDB — это совсем другая игра. Он распределяет данные по множеству узлов с помощью ключа сегмента. Этот процесс будет фрагментировать данные на множество частей, называемых осколками. Затем он копирует каждый осколок на другой узел. Кластер предназначен для поддержки больших наборов данных и операций с высокой пропускной способностью. Это достигается за счет горизонтального масштабирования рабочей нагрузки.
Вот разница между набором реплик и кластером с точки зрения непрофессионала:
- Кластер распределяет рабочую нагрузку. Он также хранит фрагменты данных (осколки) на многих серверах.
- Набор реплик полностью дублирует набор данных.
MongoDB позволяет вам комбинировать эти функции, создавая сегментированный кластер. Здесь вы можете реплицировать каждый осколок на вторичный сервер. Это позволяет сегменту обеспечивать высокую избыточность и доступность данных.
Обслуживание и настройка набора реплик может быть технически сложной и трудоемкой задачей. И найти правильный хостинг? Это совсем другая головная боль. Имея так много вариантов, легко потратить часы на исследования вместо того, чтобы строить свой бизнес.
Позвольте мне вкратце рассказать вам об инструменте, который делает все это и многое другое, чтобы вы могли вернуться к его сокрушению со своей услугой/продуктом.
Решение Kinsta для хостинга приложений, которому доверяют более 55 000 разработчиков, можно настроить и запустить, выполнив всего 3 простых шага. Если это звучит слишком хорошо, чтобы быть правдой, вот еще несколько преимуществ использования Kinsta:
- Наслаждайтесь более высокой производительностью благодаря внутренним подключениям Kinsta : забудьте о проблемах с общими базами данных. Переключитесь на выделенные базы данных с внутренними соединениями, которые не имеют ограничений на количество запросов или строк. Kinsta быстрее, безопаснее и не будет взимать плату за внутреннюю пропускную способность / трафик.
- Набор функций, специально предназначенный для разработчиков . Масштабируйте свое приложение на надежной платформе, поддерживающей Gmail, YouTube и поиск Google. Будьте уверены, здесь вы в надежных руках.
- Наслаждайтесь непревзойденной скоростью с выбранным центром обработки данных : выберите регион, который лучше всего подходит для вас и ваших клиентов. С более чем 25 центрами обработки данных на выбор более 275 точек присутствия Kinsta обеспечивают максимальную скорость и глобальное присутствие для вашего веб-сайта.
Попробуйте решение для хостинга приложений Kinsta бесплатно уже сегодня!
Как работает репликация в MongoDB?
В MongoDB вы отправляете операции записи на основной сервер (узел). Первичный назначает операции на вторичных серверах, реплицируя данные.
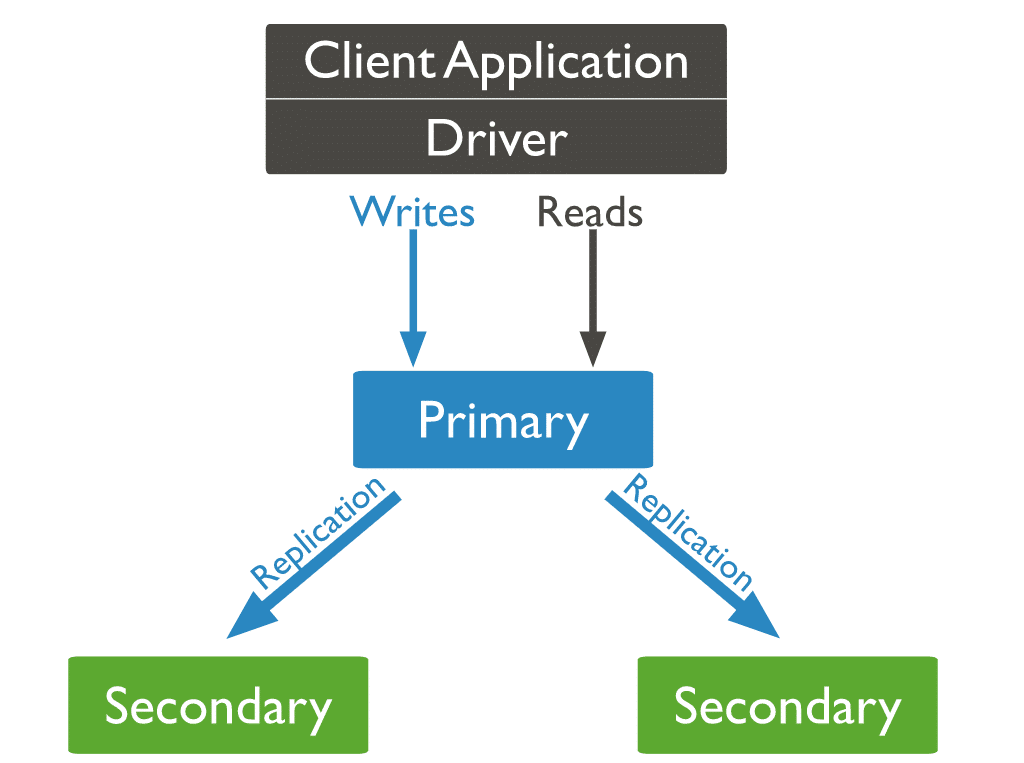
Три типа узлов MongoDB
Из трех типов узлов MongoDB ранее появились два: первичные и вторичные узлы. Третий тип узла MongoDB, который пригодится во время репликации, — это арбитр. Узел-арбитр не имеет копии набора данных и не может стать основным. При этом арбитр принимает участие в выборах на предварительных выборах.
Ранее мы упоминали, что происходит, когда первичный узел выходит из строя, но что, если вторичные узлы убьют пыль? В этом сценарии первичный узел становится вторичным, а база данных становится недоступной.
Выборы члена
Выборы могут происходить по следующим сценариям:
- Инициализация набора реплик
- Потеря подключения к основному узлу (что может быть обнаружено по пульсу)
- Обслуживание набора реплик с помощью методов
rs.reconfigилиstepDown - Добавление нового узла в существующий набор реплик
Набор реплик может содержать до 50 членов, но только 7 или меньше могут голосовать на любых выборах.
Среднее время до того, как кластер выберет новый первичный сервер, не должно превышать 12 секунд. Алгоритм выборов будет пытаться иметь вторичный доступ с наивысшим приоритетом. При этом члены со значением приоритета 0 не могут стать праймерами и не участвуют в выборах.
Проблема записи
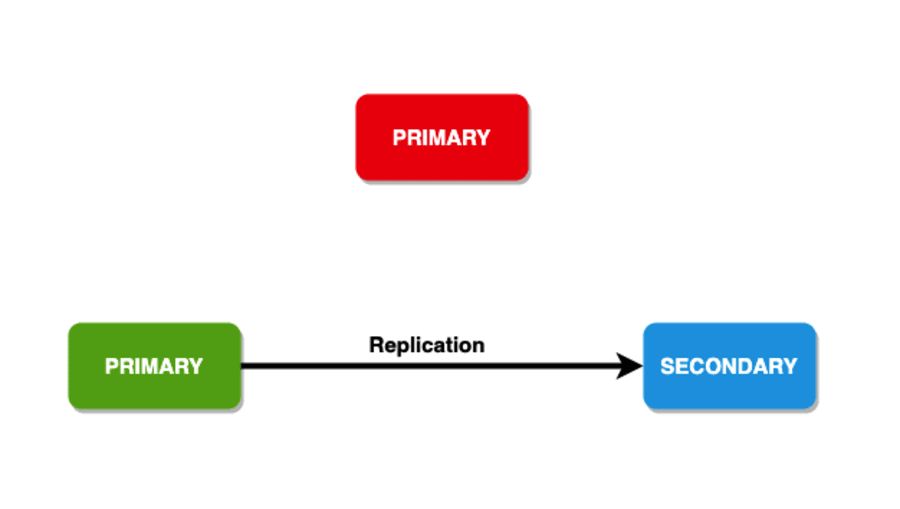
Для надежности операции записи имеют структуру для копирования данных в указанное количество узлов. Вы даже можете предложить обратную связь с клиентом с этим. Эта структура также известна как «забота о написании». У него есть члены, несущие данные, которым необходимо подтвердить запись, прежде чем операция вернется как успешная. Как правило, наборы реплик имеют значение 1 в качестве проблемы записи. Таким образом, только первичный сервер должен подтвердить запись, прежде чем возвратить подтверждение о записи.
Вы даже можете увеличить количество членов, необходимых для подтверждения операции записи. Максимального количества членов, которое вы можете иметь, не существует. Но, если цифры высоки, вам нужно иметь дело с высокой задержкой. Это связано с тем, что клиенту необходимо дождаться подтверждения от всех участников. Кроме того, вы можете установить ответственность за запись «большинства». Это вычисляет более половины членов после получения их подтверждения.
Читать предпочтения
Для операций чтения вы можете указать предпочтение чтения, которое описывает, как база данных направляет запрос членам набора реплик. Как правило, первичный узел получает операцию чтения, но клиент может указать предпочтение чтения для отправки операций чтения вторичным узлам. Вот варианты предпочтения чтения:
- primaryPreferred : обычно операции чтения выполняются с основного узла, но если он недоступен, данные извлекаются из дополнительных узлов.
- первичный : все операции чтения исходят из основного узла.
- вторичный : все операции чтения выполняются вторичными узлами.
- ближайший : здесь запросы на чтение направляются на ближайший доступный узел, который можно обнаружить, выполнив команду
ping. Результат операций чтения может исходить от любого члена набора реплик, независимо от того, является ли он первичным или вторичным. - secondPreferred : Здесь большинство операций чтения исходят от вторичных узлов, но если ни один из них недоступен, данные берутся с основного узла.
Синхронизация данных набора репликации
Для поддержания актуальных копий общего набора данных вторичные элементы набора реплик реплицируют или синхронизируют данные от других участников.
MongoDB использует две формы синхронизации данных. Начальная синхронизация для заполнения новых участников полным набором данных. Репликация для выполнения текущих изменений полного набора данных.
Начальная синхронизация
Во время начальной синхронизации вторичный узел запускает команду init sync для синхронизации всех данных с первичного узла на другой вторичный узел, содержащий самые последние данные. Поэтому вторичный узел постоянно использует функцию tailable cursor для запроса последних записей oplog в коллекции local.oplog.rs основного узла и применяет эти операции в этих записях oplog.
Начиная с MongoDB 5.2, начальная синхронизация может быть на основе копирования файлов или логической.
Логическая синхронизация
Когда вы выполняете логическую синхронизацию, MongoDB:
- Разрабатывает индексы всех коллекций по мере копирования документов для каждой коллекции.
- Дублирует все базы данных, кроме локальной базы данных.
mongodсканирует каждую коллекцию во всех исходных базах данных и вставляет все данные в свои дубликаты этих коллекций. - Выполняет все изменения в наборе данных. Используя oplog из источника,
mongodобновляет свой набор данных, чтобы отобразить текущее состояние набора реплик. - Извлекает недавно добавленные записи oplog во время копирования данных. Убедитесь, что у целевого члена достаточно дискового пространства в локальной базе данных для предварительного хранения этих записей оплога на время этого этапа копирования данных.
Когда первоначальная синхронизация завершена, член переходит из STARTUP2 в SECONDARY .
Начальная синхронизация на основе копирования файлов
Сразу же вы можете выполнить это, только если используете MongoDB Enterprise. Этот процесс запускает первоначальную синхронизацию путем дублирования и перемещения файлов в файловой системе. В некоторых случаях этот метод синхронизации может быть быстрее, чем логическая начальная синхронизация. Имейте в виду, что первоначальная синхронизация на основе копирования файлов может привести к неточным подсчетам, если вы запустите метод count() без предиката запроса.
Но у этого метода есть и свои ограничения:
- Во время начальной синхронизации на основе копирования файла вы не можете выполнять запись в локальную базу данных синхронизируемого элемента. Вы также не можете выполнить резервное копирование на участнике, с которым выполняется синхронизация, или на участнике, с которого выполняется синхронизация.
- При использовании механизма зашифрованного хранилища MongoDB использует исходный ключ для шифрования места назначения.
- Вы можете запустить первоначальную синхронизацию только от одного участника за раз.
Репликация
Вторичные элементы последовательно реплицируют данные после начальной синхронизации. Вторичные участники будут дублировать oplog из своей синхронизации из источника и выполнять эти операции в асинхронном процессе.
Вторичные серверы могут автоматически изменять свою синхронизацию из источника по мере необходимости на основе изменений времени проверки связи и состояния репликации других участников.
Потоковая репликация
Начиная с MongoDB 4.4, синхронизация из источников отправляет непрерывный поток записей oplog на их синхронизирующие вторичные узлы. Потоковая репликация уменьшает задержку репликации в сетях с высокой нагрузкой и высокой задержкой. Он также может:
- Уменьшите риск потери операций записи с помощью
w:1из-за основного аварийного переключения. - Уменьшите устаревание для чтений из вторичных серверов.
- Уменьшите задержку операций записи с помощью
w:“majority”иw:>1. Короче говоря, любая проблема записи, требующая ожидания репликации.
Многопоточная репликация
MongoDB раньше записывал операции пакетами через несколько потоков для улучшения параллелизма. MongoDB группирует пакеты по идентификатору документа, применяя каждую группу операций с другим потоком.
MongoDB всегда выполняет операции записи для данного документа в исходном порядке записи. Это изменилось в MongoDB 4.0.
Начиная с MongoDB 4.0, операции чтения, нацеленные на вторичные серверы и настроенные с уровнем чтения “majority” или “local” теперь будут считываться из моментального снимка данных WiredTiger, если чтение происходит на вторичном сервере, где применяются пакеты репликации. Чтение из моментального снимка гарантирует согласованное представление данных и позволяет выполнять чтение одновременно с текущей репликацией без необходимости блокировки.
Таким образом, вторичные операции чтения, требующие этих уровней ответственности за чтение, больше не должны ждать применения пакетов репликации и могут обрабатываться по мере их получения.
Как создать набор реплик MongoDB
Как упоминалось ранее, MongoDB обрабатывает репликацию через наборы реплик. В следующих нескольких разделах мы рассмотрим несколько методов, которые можно использовать для создания наборов реплик для вашего варианта использования.
Способ 1: создание нового набора реплик MongoDB в Ubuntu
Прежде чем мы начнем, вам необходимо убедиться, что у вас есть как минимум три сервера с Ubuntu 20.04, на каждом из которых установлена MongoDB.
Чтобы настроить набор реплик, необходимо указать адрес, по которому каждый член набора реплик может быть доступен другим участникам набора. В этом случае мы сохраняем три члена в наборе. Хотя мы можем использовать IP-адреса, это не рекомендуется, поскольку адреса могут неожиданно измениться. Лучшей альтернативой может быть использование логических имен хостов DNS при настройке наборов реплик.
Мы можем сделать это, настроив поддомен для каждого члена репликации. Хотя это может быть идеальным для производственной среды, в этом разделе будет описано, как настроить разрешение DNS, отредактировав файлы соответствующих хостов каждого сервера. Этот файл позволяет нам назначать читаемые имена хостов числовым IP-адресам. Таким образом, если в любом случае ваш IP-адрес изменится, все, что вам нужно сделать, это обновить файлы хостов на трех серверах, а не перенастраивать реплику, установленную с нуля!
Чаще всего hosts хранится в каталоге /etc/ . Повторите приведенные ниже команды для каждого из трех ваших серверов:
sudo nano /etc/hostsВ приведенной выше команде мы используем nano в качестве нашего текстового редактора, однако вы можете использовать любой текстовый редактор, который вы предпочитаете. После первых нескольких строк, которые настраивают локальный хост, добавьте запись для каждого члена набора реплик. Эти записи имеют форму IP-адреса, за которым следует удобочитаемое имя по вашему выбору. Хотя вы можете называть их как хотите, обязательно дайте им описательное описание, чтобы вы знали, как различать каждого члена. Для этого урока мы будем использовать следующие имена хостов:
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
Используя эти имена хостов, ваши файлы /etc/hosts будут выглядеть примерно так:

Сохраните и закройте файл.
После настройки разрешения DNS для набора реплик нам необходимо обновить правила брандмауэра, чтобы они могли взаимодействовать друг с другом. Выполните следующую команду ufw на mongo0, чтобы предоставить mongo1 доступ к порту 27017 на mongo0:
sudo ufw allow from mongo1_server_ip to any port 27017 Вместо параметра mongo1_server_ip введите фактический IP-адрес вашего сервера mongo1. Кроме того, если вы обновили экземпляр Mongo на этом сервере, чтобы использовать порт не по умолчанию, обязательно измените 27017, чтобы отразить порт, который использует ваш экземпляр MongoDB.
Теперь добавьте еще одно правило брандмауэра, чтобы предоставить mongo2 доступ к тому же порту:
sudo ufw allow from mongo2_server_ip to any port 27017 Вместо параметра mongo2_server_ip введите фактический IP-адрес вашего сервера mongo2. Затем обновите правила брандмауэра для двух других серверов. Выполните следующие команды на сервере mongo1, изменив IP-адреса вместо параметра server_ip, чтобы они отражали адреса mongo0 и mongo2 соответственно:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017Наконец, запустите эти две команды на mongo2. Опять же, убедитесь, что вы вводите правильные IP-адреса для каждого сервера:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017Ваш следующий шаг — обновить файл конфигурации каждого экземпляра MongoDB, чтобы разрешить внешние подключения. Чтобы разрешить это, вам необходимо изменить файл конфигурации на каждом сервере, чтобы отразить IP-адрес и указать набор реплик. Хотя вы можете использовать любой предпочтительный текстовый редактор, мы снова используем текстовый редактор nano. Давайте внесем следующие изменения в каждый файл mongod.conf.
На монго0:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"На монго1:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"На монго2:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodПри этом вы включили репликацию для экземпляра MongoDB каждого сервера.
Теперь вы можете инициализировать набор реплик с помощью метода rs.initiate() . Этот метод требуется для выполнения только на одном экземпляре MongoDB в наборе реплик. Убедитесь, что имя набора реплик и член соответствуют конфигурациям, которые вы сделали в каждом файле конфигурации ранее.
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })Если метод возвращает «ok»: 1 на выходе, это означает, что набор реплик был запущен правильно. Ниже приведен пример того, как должен выглядеть вывод:
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }Выключить сервер MongoDB
Вы можете отключить сервер MongoDB, используя метод db.shutdownServer() . Ниже приведен синтаксис для того же самого. force и timeoutsecs являются необязательными параметрами.
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) Этот метод может дать сбой, если член набора реплик mongod выполняет определенные операции при построении индекса. Чтобы прервать операции и принудительно отключить элемент, вы можете ввести для логического параметра force значение true.
Перезапустите MongoDB с помощью –replSet
Чтобы сбросить конфигурацию, убедитесь, что все узлы в вашем наборе реплик остановлены. Затем удалите локальную базу данных для каждого узла. Запустите его снова, используя флаг –replSet , и запустите rs.initiate() только на одном экземпляре mongod для набора реплик.
mongod --replSet "rs0" rs.initiate() может принимать необязательный документ конфигурации набора реплик, а именно:
- Параметр
Replication.replSetNameили—replSetдля указания имени набора реплик в поле_id. - Массив участников, который содержит один документ для каждого члена набора реплик.
Метод rs.initiate() инициирует выборы и выбирает одного из участников в качестве основного.

Добавить участников в набор реплик
Чтобы добавить членов в набор, запустите экземпляры mongod на разных машинах. Затем запустите клиент mongo и используйте команду rs.add() .
Команда rs.add() имеет следующий базовый синтаксис:
rs.add(HOST_NAME:PORT)Например,
Предположим, что mongo1 — это ваш экземпляр mongod, и он прослушивает порт 27017. Используйте клиентскую команду Mongo rs.add() , чтобы добавить этот экземпляр в набор реплик.
rs.add("mongo1:27017") Только после подключения к основному узлу вы можете добавить экземпляр mongod в набор реплик. Чтобы проверить, подключены ли вы к основному серверу, используйте команду db.isMaster() .
Удалить пользователей
Чтобы удалить участника, мы можем использовать rs.remove()
Для этого сначала выключите экземпляр mongod, который вы хотите удалить, с помощью метода db.shutdownServer() который мы обсуждали выше.
Затем подключитесь к текущему основному набору реплик. Чтобы определить текущий первичный, используйте db.hello() при подключении к любому члену набора реплик. После того, как вы определили основной, выполните одну из следующих команд:
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 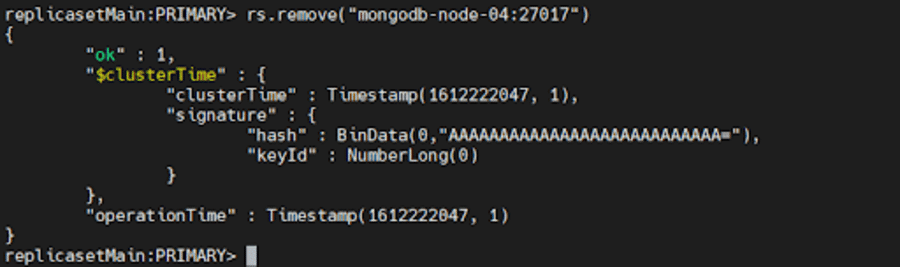
Если набор реплик должен выбрать новый первичный сервер, MongoDB может ненадолго отключить оболочку. В этом случае он автоматически снова подключится. Кроме того, он может отображать ошибку DBClientCursor::init call() failed, даже если команда выполнена успешно.
Способ 2: настройка набора реплик MongoDB для развертывания и тестирования
Как правило, вы можете настроить наборы реплик для тестирования как с включенным, так и с отключенным RBAC. В этом методе мы будем настраивать наборы реплик с отключенным контролем доступа для его развертывания в тестовой среде.
Сначала создайте каталоги для всех экземпляров, входящих в набор реплик, с помощью следующей команды:
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2Эта команда создаст каталоги для трех экземпляров MongoDB: replicaset0-0, replicaset0-1 и replicaset0-2. Теперь запустите экземпляры MongoDB для каждого из них, используя следующий набор команд:
Для сервера 1:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Для сервера 2:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Для сервера 3:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 Параметр –oplogSize используется для предотвращения перегрузки компьютера на этапе тестирования. Это помогает уменьшить объем дискового пространства, потребляемого каждым диском.
Теперь подключитесь к одному из экземпляров с помощью оболочки Mongo, используя указанный ниже номер порта.
mongo --port 27017 Мы можем использовать команду rs.initiate() для запуска процесса репликации. Вам нужно будет заменить параметр hostname на имя вашей системы.
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }Теперь вы можете передать объектный файл конфигурации в качестве параметра для команды инициации и использовать его следующим образом:
rs.initiate(rsconf)И вот оно! Вы успешно создали набор реплик MongoDB для разработки и тестирования.
Способ 3: преобразование автономного экземпляра в набор реплик MongoDB
MongoDB позволяет своим пользователям преобразовывать свои автономные экземпляры в наборы реплик. Хотя автономные экземпляры в основном используются на этапе тестирования и разработки, наборы реплик являются частью производственной среды.
Для начала давайте выключим наш экземпляр mongod, используя следующую команду:
db.adminCommand({"shutdown":"1"}) Перезапустите свой экземпляр, используя параметр –repelSet в вашей команде, чтобы указать набор реплик, который вы собираетесь использовать:
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>Вы должны указать имя своего сервера вместе с уникальным адресом в команде.
Подключите оболочку к вашему экземпляру MongoDB и используйте команду инициации, чтобы запустить процесс репликации и успешно преобразовать экземпляр в набор реплик. Вы можете выполнить все основные операции, такие как добавление или удаление экземпляра, с помощью следующих команд:
rs.add(“<host_name:port>”) rs.remove(“host-name”) Кроме того, вы можете проверить состояние набора реплик MongoDB с помощью команд rs.status() и rs.conf() .
Метод 4: MongoDB Atlas — более простая альтернатива
Репликация и сегментирование могут работать вместе, образуя нечто, называемое сегментированным кластером. Хотя установка и настройка могут занять довольно много времени, хотя и несложны, MongoDB Atlas является лучшей альтернативой методам, упомянутым ранее.
Он автоматизирует ваши наборы реплик, упрощая реализацию процесса. Он может развертывать глобально сегментированные наборы реплик несколькими щелчками мыши, обеспечивая аварийное восстановление, более простое управление, локализацию данных и развертывание в нескольких регионах.
В MongoDB Atlas нам нужно создать кластеры — это может быть либо набор реплик, либо сегментированный кластер. Для конкретного проекта количество нод в кластере в других регионах ограничено до 40.
Это исключает бесплатные или общие кластеры и облачные регионы Google, взаимодействующие друг с другом. Общее количество узлов между любыми двумя областями должно соответствовать этому ограничению. Например, если есть проект, в котором:
- Регион А имеет 15 узлов.
- Регион B имеет 25 узлов
- Регион C имеет 10 узлов
Мы можем выделить еще 5 узлов в область C, так как,
- Регион А+ Регион В = 40; соответствует ограничению 40 — максимально допустимому количеству узлов.
- Регион B+ Регион C = 25+10+5 (дополнительные узлы, выделенные для C) = 40; соответствует ограничению 40 — максимально допустимому количеству узлов.
- Регион A+ Регион C =15+10+5 (дополнительные узлы, выделенные для C) = 30; соответствует ограничению 40 — максимально допустимому количеству узлов.
Если мы выделили еще 10 узлов для региона C, в результате чего регион C будет иметь 20 узлов, то регион B + регион C = 45 узлов. Это превысит заданное ограничение, поэтому вы не сможете создать кластер с несколькими регионами.
Когда вы создаете кластер, Atlas создает в проекте сетевой контейнер для облачного провайдера, если его раньше не было. Чтобы создать кластер набора реплик в MongoDB Atlas, выполните следующую команду в интерфейсе командной строки Atlas:
atlas clusters create [name] [options]Убедитесь, что вы дали описательное имя кластера, так как его нельзя изменить после создания кластера. Аргумент может содержать буквы ASCII, цифры и дефисы.
Существует несколько вариантов создания кластера в MongoDB в зависимости от ваших требований. Например, если вы хотите непрерывное резервное копирование в облако для своего кластера, задайте для параметра --backup значение true.
Работа с задержкой репликации
Задержка репликации может быть довольно неприятной. Это задержка между операцией на первичном сервере и применением этой операции от оплога к вторичному. Если ваш бизнес имеет дело с большими наборами данных, ожидается задержка в пределах определенного порога. Однако иногда внешние факторы также могут способствовать увеличению задержки. Чтобы воспользоваться актуальной репликацией, убедитесь, что:
- Вы маршрутизируете свой сетевой трафик со стабильной и достаточной пропускной способностью. Сетевая задержка играет огромную роль в репликации, и если сеть недостаточна для удовлетворения потребностей процесса репликации, будут задержки в репликации данных по всему набору реплик.
- У вас достаточная пропускная способность диска. Если файловая система и дисковое устройство на вторичном диске не могут сбрасывать данные на диск так же быстро, как на первичном, то вторичному устройству будет трудно идти в ногу со временем. Следовательно, вторичные узлы обрабатывают запросы на запись медленнее, чем первичный узел. Это распространенная проблема в большинстве мультитенантных систем, включая виртуализированные экземпляры и крупномасштабные развертывания.
- Вы запрашиваете подтверждение записи после определенного интервала, чтобы предоставить вторичным серверам возможность догнать первичный, особенно если вы хотите выполнить операцию массовой загрузки или прием данных, требующую большого количества операций записи в первичный. Вторичные серверы не смогут читать оплог достаточно быстро, чтобы не отставать от изменений; особенно с непризнанными проблемами записи.
- Вы определяете запущенные фоновые задачи. Некоторые задачи, такие как задания cron, обновления сервера и проверки безопасности, могут неожиданно повлиять на использование сети или диска, вызывая задержки в процессе репликации.
Если вы не уверены, есть ли задержка репликации в вашем приложении, не беспокойтесь — в следующем разделе обсуждаются стратегии устранения неполадок!
Устранение неполадок с наборами реплик MongoDB
Вы успешно настроили свои наборы реплик, но заметили, что ваши данные несовместимы между серверами. Это очень тревожно для крупных предприятий, однако с помощью быстрых методов устранения неполадок вы можете найти причину или даже устранить проблему! Ниже приведены некоторые распространенные стратегии устранения неполадок при развертывании наборов реплик, которые могут пригодиться:
Проверить статус реплики
Мы можем проверить текущий статус набора реплик и статус каждого члена, выполнив следующую команду в сеансе mongosh, который подключен к основному набору реплик.
rs.status()Проверьте задержку репликации
Как обсуждалось ранее, задержка репликации может быть серьезной проблемой, поскольку она делает «запаздывающие» элементы неподходящими для быстрого превращения в основной и увеличивает вероятность того, что распределенные операции чтения будут несогласованными. Мы можем проверить текущую длину журнала репликации, используя следующую команду:
rs.printSecondaryReplicationInfo() Это возвращает значение syncedTo , которое представляет собой время, когда последняя запись оплога была записана во вторичный файл для каждого члена. Вот пример, демонстрирующий то же самое:
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary Отложенный участник может отображаться как отставание от основного на 0 секунд, если период бездействия на основном больше, чем значение members[n].secondaryDelaySecs .
Проверка соединений между всеми участниками
Каждый член набора реплик должен иметь возможность подключаться к любому другому члену. Всегда проверяйте соединения в обоих направлениях. В большинстве случаев конфигурации брандмауэра или сетевые топологии препятствуют нормальному и необходимому подключению, что может блокировать репликацию.
Например, предположим, что экземпляр mongod связывается как с локальным хостом, так и с именем хоста «ExampleHostname», которое связано с IP-адресом 198.41.110.1:
mongod --bind_ip localhost, ExampleHostnameЧтобы подключиться к этому экземпляру, удаленные клиенты должны указать имя хоста или IP-адрес:
mongosh --host ExampleHostname mongosh --host 198.41.110.1Если набор реплик состоит из трех членов, m1, m2 и m3, использующих порт по умолчанию 27017, вы должны протестировать соединение, как показано ниже:
На м1:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017На м2:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017На м3:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 Если какое-либо соединение в любом направлении терпит неудачу, вам придется проверить конфигурацию вашего брандмауэра и перенастроить его, чтобы разрешить соединения.
Обеспечение безопасной связи с аутентификацией ключевого файла
По умолчанию аутентификация ключевого файла в MongoDB основана на механизме аутентификации с ответом на вызов с солью (SCRAM). Для этого MongoDB должен прочитать и проверить предоставленные пользователем учетные данные, которые включают комбинацию имени пользователя, пароля и базы данных аутентификации, о которой знает конкретный экземпляр MongoDB. Это именно тот механизм, который используется для аутентификации пользователей, вводящих пароль при подключении к базе данных.
Когда вы включаете аутентификацию в MongoDB, для набора реплик автоматически включается управление доступом на основе ролей (RBAC), и пользователю предоставляется одна или несколько ролей, которые определяют его доступ к ресурсам базы данных. Когда RBAC включен, это означает, что только действительный аутентифицированный пользователь Mongo с соответствующими привилегиями сможет получить доступ к ресурсам в системе.
Ключевой файл действует как общий пароль для каждого члена кластера. Это позволяет каждому экземпляру mongod в наборе реплик использовать содержимое ключевого файла в качестве общего пароля для аутентификации других участников развертывания.
Только те экземпляры mongod с правильным ключевым файлом могут присоединиться к набору реплик. Длина ключа должна быть от 6 до 1024 символов и может содержать только символы из набора base64. Обратите внимание, что MongoDB удаляет пробельные символы при чтении ключей.
Вы можете сгенерировать ключевой файл , используя различные методы. В этом руководстве мы используем openssl для создания сложной строки из 1024 случайных символов для использования в качестве общего пароля. Затем он использует chmod для изменения прав доступа к файлам, чтобы предоставить права на чтение только для владельца файла. Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. Например:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
And voila! You have successfully enabled keyfile authentication!
Краткое содержание
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!